
Поднимите руки те, у кого есть номер телефона... Вау, лес рук! Но знаете ли вы, что скрывается за этим набором цифр?
Поднимите руки те, у кого есть номер телефона... Вау, лес рук! Но знаете ли вы, что скрывается за этим набором цифр?

В большинстве учетных систем, типа нашего СБИС, рано или поздно возникает проблема быстрого отображения реестра, в который по просьбам бизнес‑пользователей накручено несколько комбинируемых фильтров с очень редкой выборкой, ну никак не ложащихся в вашу красивую структуру базы данных и индексов базовой таблицы реестра — что‑нибудь типа "список продаж покупателям, чей день рождения выпадает на 29 февраля".
Универсального способа сделать «хорошо» тут нет, но я расскажу про модель запроса, которая позволит вам дать пользователю быстрый отклик, но при этом весьма эффективно с точки зрения PostgreSQL.

EXPLAIN, но с некоторыми странными узлами — вы знаете, куда идти.

WITH RECURSIVE появилась еще в незапамятные времена версии 8.4, но до сих пор можно регулярно встретить потенциально-уязвимые «беззащитные» запросы. Как избавить себя от проблем подобного рода?
ORDER BY dt, id или ORDER BY dt DESC, id DESC.ORDER BY dt, id DESC? Но второй индекс мы создавать не хотим — ведь это замедление вставки и лишний объем в базе.(dt, id)?Растут wait — приложение в кого-то «уперлось» на блокировках. Если это уже прошедшая разовая аномалия — повод разобраться в исходной причине.Такая ситуация — одна из самых неприятных для DBA:
process ... still waiting for ...


В этой челлендж-серии статей попробуем использовать PostgreSQL как среду для решения задач Advent of Code 2024.
Возможно, SQL не самый подходящий для этого язык, зато мы рассмотрим его различные возможности, о которых вы могли и не подозревать.
В этой части мы научимся вычислять состояния клеточного автомата без прямого моделирования и узнаем, как можно среди них найти интересное.

Привет, Хабр! Меня зовут Ирина Москалева. Работаю в компании около 12 лет, в области HR. Когда-то подбирала персонал сама, но уже несколько лет руковожу своей командой и разрабатываю стратегию в этой сфере подбора и управления персоналом.
Хочу разбавить технические темы насущными и, по моему мнению, касающимися многих компаний, вопросами. Так вот, много лет мы активно набирали перспективных джунов. Откуда мы их брали? Помогали наши различные авторские школы, мероприятия по профориентации в области ИТ, практика и другие эвенты.

Чем больше ты становишься экспертом, тем чаще HR видят в тебе не просто коллегу… а спикера на конференциях и митапах. Ну потому что нельзя скрывать такое сокровище!
Одно дело — подготовить доклад, другое — с ним выступить (тяжкий вздох). Словить атаческую панику за 5 минут до триумфального появления перед публикой может даже самый титулованный специалист. И это ок.
Чтобы не переживать и с удовольствием делиться опытом с аудиторией, нужно просто настроиться на выступление: привести в порядок голос и нервы.
Накануне Митапа в Уфе 28 марта собрали в статье лайфхаки, которые помогут чувствовать себя перед аудиторией комфортнее, а звучать — увереннее.
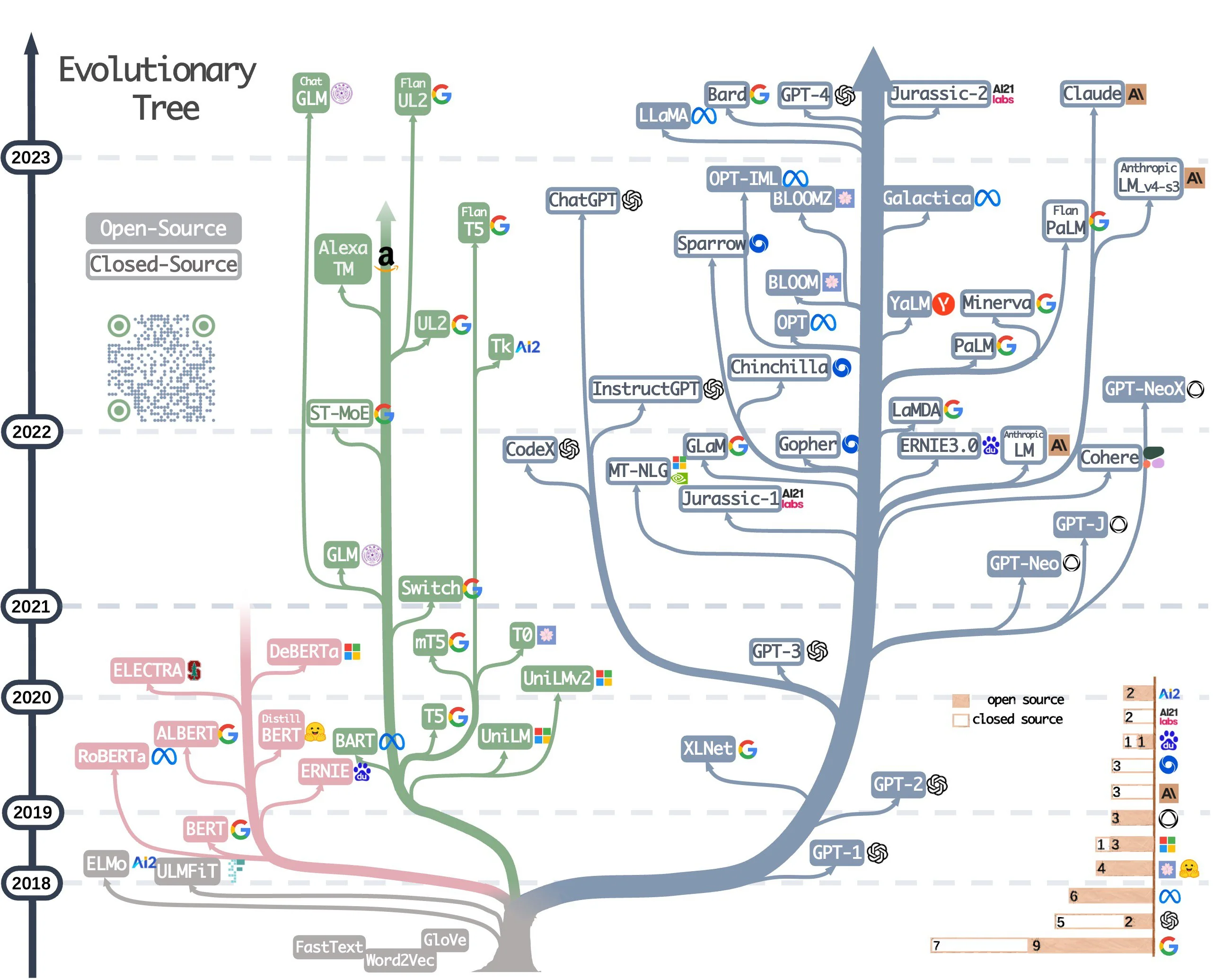
В прошлом году(2023) в мире больших языковых моделей(LLM) произошло много нового и нитересного. В новостях появились фразы о гонке искусственных интеллектов, а многие ведущие IT компании включились в эту гонку. Рассмотрим как все начиналось, кто сейчас занимает лидирующие позиции в гонке и когда роботы захватят мир.

Для пользователей explain.tensor.ru - нашего сервиса визуализации PostgreSQL-планов, мы создали плагин "Explain PostgreSQL" для всех IDE от JetBrains, теперь есть возможность форматировать запросы и анализировать планы непосредственно в IDE.
Как использовать плагин и детали о его разработке читайте ниже.

В последние месяцы в киберпространстве развернулась настоящая война, отчего незащищенные информационные активы значительно пострадали, а пользователи защитного инструментария от западных «партнеров» столкнулись с серьезнейшими санкциями, ограничивающими использование их ПО. Поэтому мы решили посмотреть на рынок отечественного ПО, разработанного для усиления «инфобеза».
Обычно на вопрос "Какой сканер безопасности купить?" вспоминаются лишь OpenVas и Nessus (Tenable). Но есть и другие достойные отечественные продукты, о которых мы сегодня и поговорим – это продукты для корпоративного сегмента, полностью лицензированные под все российские требования безопасности и имеющие сертификаты ФСТЭК и ФСБ:

В моей практике ускорения SQL-запросов для PostgreSQL, в большинстве случаев, все сводится к применению типовых методик - их не особенно-то и много, и прочитать про большинство из них можно в моем профиле.
Но иногда обнаруживаются очень странные вещи в поведении этой, безусловно, отличной СУБД.
Все началось с запроса, который мне показали с диагнозом "необъяснимо тормозит"...

Иногда при выполнении длительных или плохо написанных запросов в PostgreSQL происходят разные неприятные вещи типа внезапного сбоя процесса или краша всего сервера.
В таких случаях на носителе могут остаться "мертвые души" - файлы (иногда совсем немаленькие, а вполне сравнимые по объему со всей остальной базой), которые были созданы во время работы процесса в качестве временного хранилища промежуточных данных.
Эти данные уже никому не нужны, никем не могут быть использованы, но сервер не торопится избавиться от них как Плюшкин.

JOIN и предложим альтернативный вариант решения на ней той же задачи.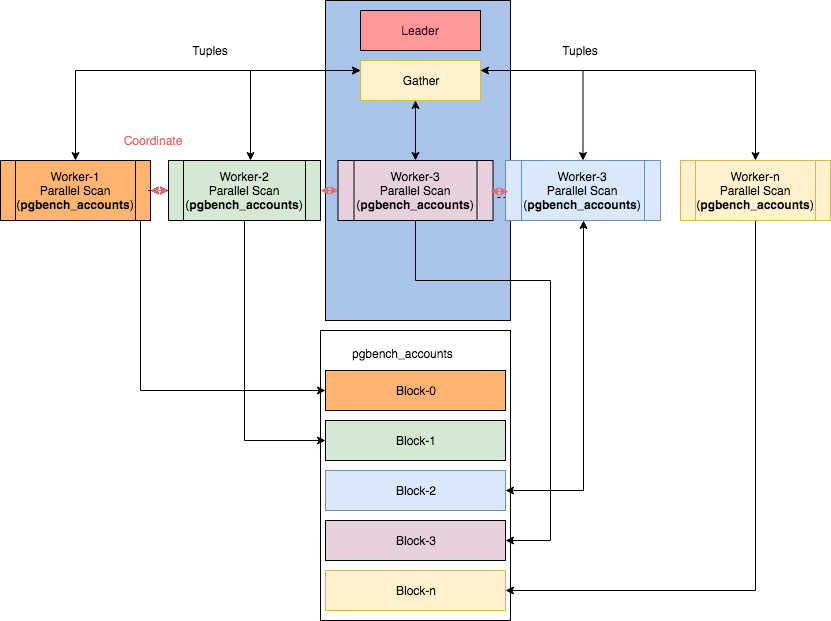
Со схемами работы некоторых параллельных узлов можно ознакомиться в статье «Parallelism in PostgreSQL» by Ibrar Ahmed, откуда взято и это изображение.Правда, читать планы в этом случае становится… нетривиально.
... LIKE '%роза%' — ведь тогда в результат попадают не только 'Розалия' и 'Магазин Роза', но и 'Гроза' и даже 'Дом Деда Мороза'.

Создавая сервис видеотрансляций, рано или поздно, при увеличении числа потребителей контента, возникает вопрос о масштабировании и доставке. Вы столкнетесь с проблемой не только вычислительных мощностей, но и пропускной способности вашей сети.
Я, как разработчик сервиса вебинаров, постараюсь в этой статье помочь разобраться с этими проблемами, по средствам P2P-сетей.