
Несмотря на то, что сейчас
Я уже полгода веду проект VseGPT.ru с доступом к разным LLM из России по OpenAI API (ну, и через вебчат). Львиная доля работы — подключение новых нейросетей. Сейчас их уже свыше 60, и каждую я попробовал хотя бы раз, ну, когда подключал.
Правда, сайт LLMExplorer, собирающий данные об опенсорс нейросетях с портала Hugging Face, говорит, что их там уже более 33 000 штук. М-да.
В общем, вероятно, я не знаю о текстовых сетках всё, но определенно знаю кое-что — хотя бы в пределах своего скромного опыта в 60 сеток. Так что кому интересно — прошу под кат.
❯ Небольшие вводные
Коротко для тех, кто не знает: текстовые нейросети делятся на проприетарные и опенсорсные.
Проприетарные предоставляются соответствующими компаниями по API (т.е. веса для них недоступны, запустить их у себя нельзя). Самые известные из них это:
- OpenAI: ChatGPT, GPT-4, GPT-4-Turbo
- Claude: 1, 2, 3 Haiku, Sonnet, Opus
- Google: Palm, Gemini Pro
- ну и некоторые другие, например Mistral, Perplexity.
Компании эти запускают эти модели на своих серверах (это быстро, это плюс), но под своими условиями доступа к API (это минус, условия бывают очень разные).
Также есть опенсорсные текстовые нейросети — веса для них выложены, любой желающий может их дотюнить (дотренировать) под свои задачи, и запускать совершенно независимо от оригинального автора (детали лицензий мы сейчас опускаем)
Это конечно, несомненный плюс, но несомненным минусом является то, что предоставлять инстанс (т.е. сервер, обрабатывающий модель) никто не будет, и нужно запускать её самостоятельно — что часто очень дорого (т.к. надо арендовать машину с GPU) или медленно (если вы используете оптимизации и гоняете модель на CPU).
В опенсорсе также есть понятие базовых моделей и дотюненных моделей.
Базовая модель тренируется с нуля какой-то большой компанией (потому что затраты на тренировку с нуля велики), а затем выкладывается в опенсорс. Дальше, уже небольшими усилиями энтузиасты дотренировывают базовую модель на своих данных под конкретные задачи.
Наиболее известные и часто используемые базовые модели сейчас это:
- Llama2 7B, 13B, 70B от компании Meta* (признана экстремистской и запрещена в России)
- Mistral 7B, Mixtral 8x7B от французского стартапа Mistral
- Yi-34B (от китайской компании 01.ai с фокусом на английском и китайских языках)
Цифры в конце означают число параметров в модели — чем больше, тем модель в целом умнее в плане следования логике, но тем дороже обходится её дотренировка и запуск. Дотюненные модели обычно сохраняют имена или размеры базовых моделей в своем названии, так что обычно всегда можно понять, на какой базе дотренировывалась модель.
Давайте теперь быстро по общим принципам подбора.
❯ Общие принципы подбора моделей под свои задачи
Больше — лучше, но дороже и медленнее
Как правило, у компаний есть более слабые и более сильные модели (тот же ChatGPT против GPT-4) — и это связано с числом параметром в них.
Если вам нужно максимальное качество, нужно выбирать самую дорогую модель (или модель с большим числом параметров в опенсорсе, и там она обычно тоже будет дорогой — т.к. чем больше модель, тем дороже аренда сервера для её запуска)
Если вы решаете массово какие-то простые задачи в духе “определи тональность этого текста”, имеет смысл выбрать более дешевые и простые модели.
Выбирайте свежее
Как правило, чем позже была выпущена модель, тем на большем числе данных и с большими известными оптимизациями она тренировалась (например, более поздняя Mistral 7B находится на уровне более крупной Lllama 13B). Также обычно более поздние модели предоставляются дешевле, т.к. для них уже придуманы какие-то оптимизации.
Исключение — OpenAI со своими моделями; более поздние они “затачивают” под какие-то одни задачи (вроде как под то, что нужно пользователям), но иногда происходит ухудшение на каких-то других задачах. Например, более поздняя GPT-4-Turbo на некоторых задачах рассуждения уступает оригинальной GPT-4; но в часто встречающихся задачах кодинга она показывает лучшие результаты.
Не стоит СЛИШКОМ доверять бенчмаркам
Уже есть достаточно много стандартизированных бенчмарков для сравнения моделей — например, для решения математических задач, задач программирования, общих вопросов по специальным сферам и пр.
Вроде надо выбирать лучшее по бенчмаркам, нет?
По моему личному опыту — скорее, нет.
Во-первых, бенчмарки, как правило, опираются на английские, а не на русские тесты.
Во-вторых, в бенчмарках, задача, как правило, ставится очень узко и конкретно. Конечно, если у вас задача один-в-один повторяет какие-то задачи бенчмарка, то, конечно, имеет смысл его учитывать. Но, к сожалению, я видел ситуации, когда модель хорошо показывает себя на бенчмарках, но при этом плохо себя показывает в реальных условиях (Google Gemma 7B, привет!)
Есть, правда, один рейтинг, который имеют хорошую репутацию в профессиональных кругах — это Arena Leaderboard. Там юзеры сами делают запрос к двум нейросетям, а затем оценивают, какой ответ лучше. Возникает набор оценок “выиграл-проиграл”, на основании которых считается рейтинг ЭЛО — и чем выше рейтинг, тем выше вероятность того, что модель ответит лучше, чем другая модель с более низким рейтингом.
Однако число моделей в этом рейтинге невелико (иначе было бы слишком сложно все это поддерживать), и часто к нему прибегают только, чтобы поспорить о том, какая модель “самая лучшая” (сейчас верхние строки таблицы занимают Claude 3 Opus и GPT-4-Turbo, причем за время написания этой статьи Опус успел обогнать GPT-4, что стало целой новостью в тематических каналах)

Ну, а теперь давайте перейдем к конкретным рекомендациям.
❯ Конкретные задачи
В качестве примеров я обычно буду приводить модели, доступные на VseGPT — просто потому, что я с ними сам работал.
Для начала…
Я бы предложил поработать с:
- Старым добрым ChatGPT
- Google Gemini Pro (модель у Гугла получилась неплохая и недорогая)
- Claude 3 Sonnet (последний Claude 3 выдает очень приличные эмоциональные ответы)
Если с нейросетью работает бизнес и нельзя передавать данные зарубеж…
…то надо обратиться к провайдерам, которые держат обработку в России — предполагаю, что сейчас это в основном Яндекс c YaGPT и Сбер с GigaChat.
Либо использовать опенсорсные нейросети с хорошей поддержкой русского. Из того, что знаю:
- OpenChat 7B (пробовал, очень приличная опенсорс для 7B модели, сравнима с ChatGPT),
- Starling 7B DPO (не пробовал, но слышал хорошие отзывы),
- Сайга-Мистраль-7B (имхо, несколько устарела, но делалась нашим разработчиком),
- Mixtral 8x7B (на удивление неплохо обрабатывает русский)
Если есть требование “не выпускать данные за контур предприятия”, то вообще останутся только указанные выше опенсорсные сети.
Если нужно максимально дешево…
…используйте:
- Google Gemini Pro
- Claude 3 Haiku
- OpenChat 7B (можно дать этой опенсорсной сети шанс)
При работе с этими сетями генерации получаются в 1.5-2 раза дешевле, чем с самым последним ChatGPT (01-25).
Если нужно решать задачи программирования…
…я использую GPT-4-Turbo. Возможно, Opus или опенсорсная сеть типа Codellama 70B Instruct также решила бы мои задачи, но это надо сидеть и экспериментировать — а времени очень не хватает.
Полгода назад я использовал для программирования простой ChatGPT и очень об этом жалею — мне приходилось править мелкие недостатки в коде руками, но тогда я считал это нормальным. GPT-4-Turbo при хорошей постановке задачи сразу пишет весьма хороший объемный код.
Если нужно обработать большие файлы…
…то надо смотреть, какой размер контекста у модели. Чем больше контекст, тем больше данных влезет в модель для обработки.
Но тут эволюция идет очень быстро, имеет смысл следить за изменениями.
Где-то в июне 2023, базовая ChatGPT имела контекст в 4096 токенов, 16к-версия была прилично дороже, а базовая GPT-4 имела контекст в 8000 токенов. Опенсорсные модели же запускались на 2К контекста, и пользователи жаловались, что диалог туда почти не влезает.
Сейчас же базовая ChatGPT имеет контекст на 16К токенов, опенсорс варьируется от 4К до 32К, а GPT-4-Turbo использует контекст в 128К (хотя это дорого).
Так что — если вы обрабатываете небольшие статьи, то вы обычно можете выбирать модель по своему вкусу.
Если же все-таки нужен большой контекст, то рекомендую смотреть в сторону вышедшей в начале марта Claude 3.
Anthropic, компания, выпускающая Claude, пытается конкурировать с OpenAI на поле “у кого больше контекст”.
Сейчас самый большой доступный контекст у серии Claude 3 — 200К токенов, при этом можно выбрать из нескольких моделей:
- Haiku позволит обработать этот контекст очень дешево (несравнимо с GPT-4), но достаточно тупо.
- Sonnet — средняя по качеству
- Opus — самая качественная
В общем, рекомендую.
Также, из альтернатив есть:
- GPT-4-Turbo на 128К контекста (но выйдет дорого)
- Google Gemini Pro 1.5 на 1M контекста — де факто, конечно, самый большой контекст у неё. Но она только что вышла, и не очень недоступна в сторонних API, только у самого Гугла (не в России) и вообще там очень жесткие ограничения на число запросов. Но отзывы я слышал хорошие.
Совет: если будете отправлять большой текст в Claude в качестве контекста — обрамляйте его в XML-теги, как рекомендует официальная инструкция. Без этого конкретно модели Claude, по опыту, работают несколько хуже.
Если нужен перевод…
…то можно ознакомиться с бенчмарком по переводам, который лично я веду в рамках своего опенсорс проекта, и в котором тестирую всё свежевыходящее.
Коротко — чем умнее сеть, тем лучше перевод.
Но особенно могу рекомендовать Claude 3 Opus. Сложно сказать, что у Claude с логическим мышлением, но именно с художественностью текста они работают на прекрасном уровне.
По бенчмарку Claude 3 Opus сопоставим с хитрым агрегатором, который выбирал лучшие из переводов Яндекс.Переводчика, DeepL и Claude 2 (добавление в эту тройку Google Translate даже понижало метрики).
Если же вам нужен самый дешевый переводчик — рекомендую взять Google Gemini Pro или Claude 3 Haiku; или даже бесплатный совершенно обычный Google Translate — по моим метрикам он вполне на уровне.
Если нужен сторителлинг (написание художественного текста) или ролеплей (взаимодействие с выдуманным персонажем)…
…то есть два пути.
Официальные модели от больших компании используют фильтры, чтобы не отвечать на некоторые вопросы по “чувствительным” темам.
Например, сейчас запрос про попа в ChatGPT проходит нормально, а раньше вызывал срабатывание фильтра.
Если вы уверены, что вы не затронете чувствительные темы в своем диалоге — моя рекомендация — Claude 3 Sonnet или более дорогая Opus.
Я до этого пробовал ролеплеить с ChatGPT и было несколько… механистично. Ролевики посоветовали Claude и, должен сказать, художественный текст у неё получается сильно лучше.
Кроме того, контекст в 200К для больших текстов — это прям конечно очень хорошо. Я в своей практике добирался до 20К в диалоге, и было очень приятно, когда модель помнила что-то из самого начала.
Если же на ваш запрос вы получаете постоянно что-то в духе “Я большая языковая модель, и мне некомфортно говорить на эту тему, давайте о чем-нибудь другом” — имеет смысл обратиться к опенсорсным моделям.
Но тут есть нюанс — как правило, эти модели тренировались на английском языке. И, опять же, возможны несколько вариантов:
- Взаимодействовать на английском. Качество хорошее, но лично мне несколько некомфортно в качестве развлечения писать и читать на иностранном.
- Взаимодействовать на русском. Большие модели (70B) это даже потянут, но качество будет просто на порядок хуже, чем на английском.
- Встроить в середину переводчик — переводить весь вход на английский язык, а генерации модели — на русский. На мой взгляд, этот вариант работает лучше всего.
Например, в довольно известной программе для ролеплея Silly Tavern вариант с переводчиком можно включить с помощью плагинов — потому что много пользователей по всему миру просило. На VseGPT я напрягся и сделал для большинства open source-моделей их translate-версии — когда сервис при вызове генерации переводит весь вход на английский, а выход — на русский.
Что из моделей можно посоветовать? (Буду писать только то, что на сервисе, и что я немного пробовал)
- Toppy M 7B, Mythomist 7B — 7B модели, к сожалению, глуповаты по поводу фактов, но у них большой контекст — 32000 токенов. Квазихудожественный текст генерируют неплохо.
- Mythalion 13B, Psyfighter 13B — 13B модели, которые тренировались в том числе на фанфиках. Неплохо выдают художественный текст, но хуже следуют инструкциям.
- Dolphin 2.6 Mixtral 8x7B, Noromaid Mixtral 8x7B Instruct, Nous: Hermes 2 Mixtral 8x7B DPO — 8x7B модели, хорошо следуют инструкциям, но креативность у них, на мой взгляд, не очень.
- lzlv 70B, Midnight Rose 70B — довольно хорошие 70B модели с балансом между следованию промту и художественности текста. lzlv более склонна к коротким ответам, и тренировалась довольно давно. Midnight Rose склонна к более длинным художественным описаниям, и довольно свежая.
Совет: опенсорс модели более капризные в настройке, чем проприетарные. Я рекомендую при взаимодействии с ними сразу устанавливать температуру меньше 1 — от 0.7 до 0.95, а также задавать штраф за повторы — очень любят повторяться.
Если нужно получать в ответе актуальную информацию…
…используйте модели Perplexity.
Нет, понятно, что если вы работаете руками, можно воспользоваться онлайновым Google Bard или Bing — они тоже по запросу попытаются найти информацию в интернете. Но если нужно сделать в вашем приложении запрос по API и получить ответ на основе актуальной информации — такую фичу предоставляет только Perplexity. (Я слышал, что Сбер хочет выпустить GigaSearch с подобной функцией, но пока он не доступен)
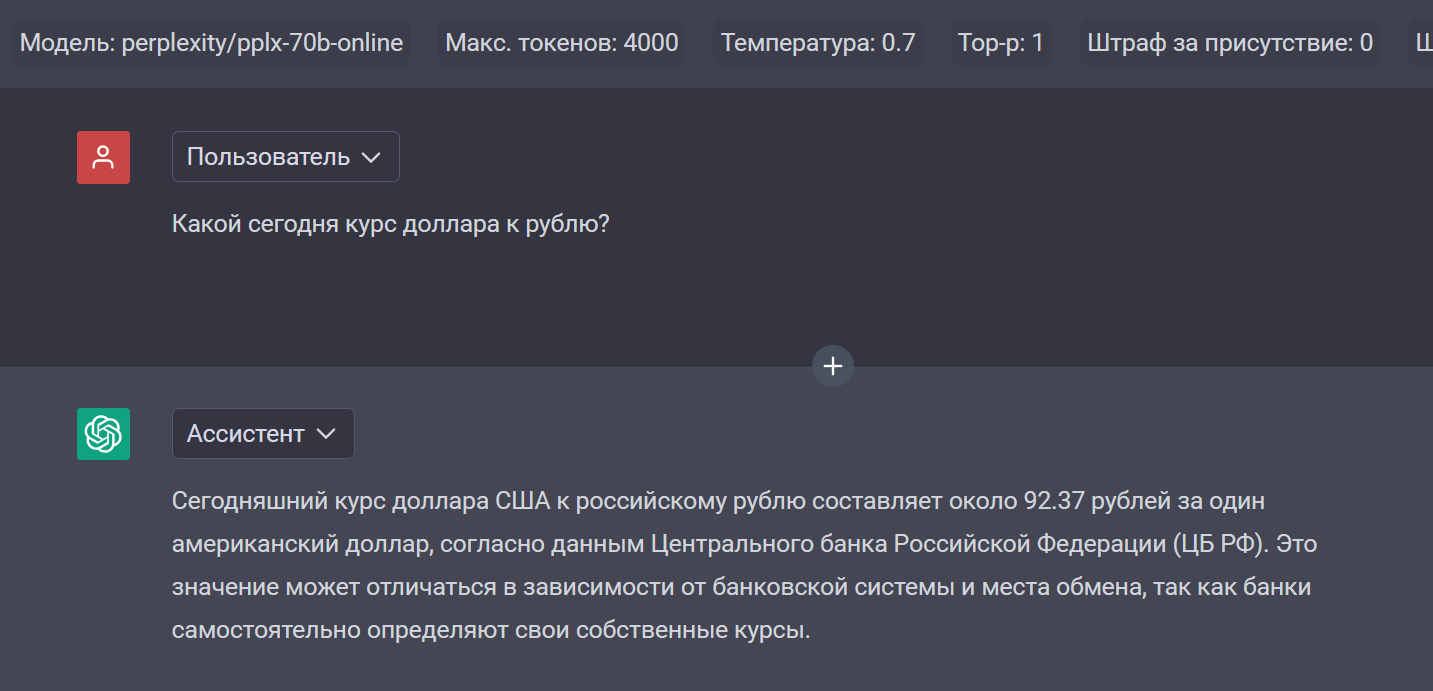
Совет: из всех предложенных Perplexity моделей используйте pplx-70b-online — она лучше всего отвечает на русском языке. Еще у Perplexity есть 7b-модель, а также модели sonar — по моему опыту русские ответы там значительно хуже.
Примеры:
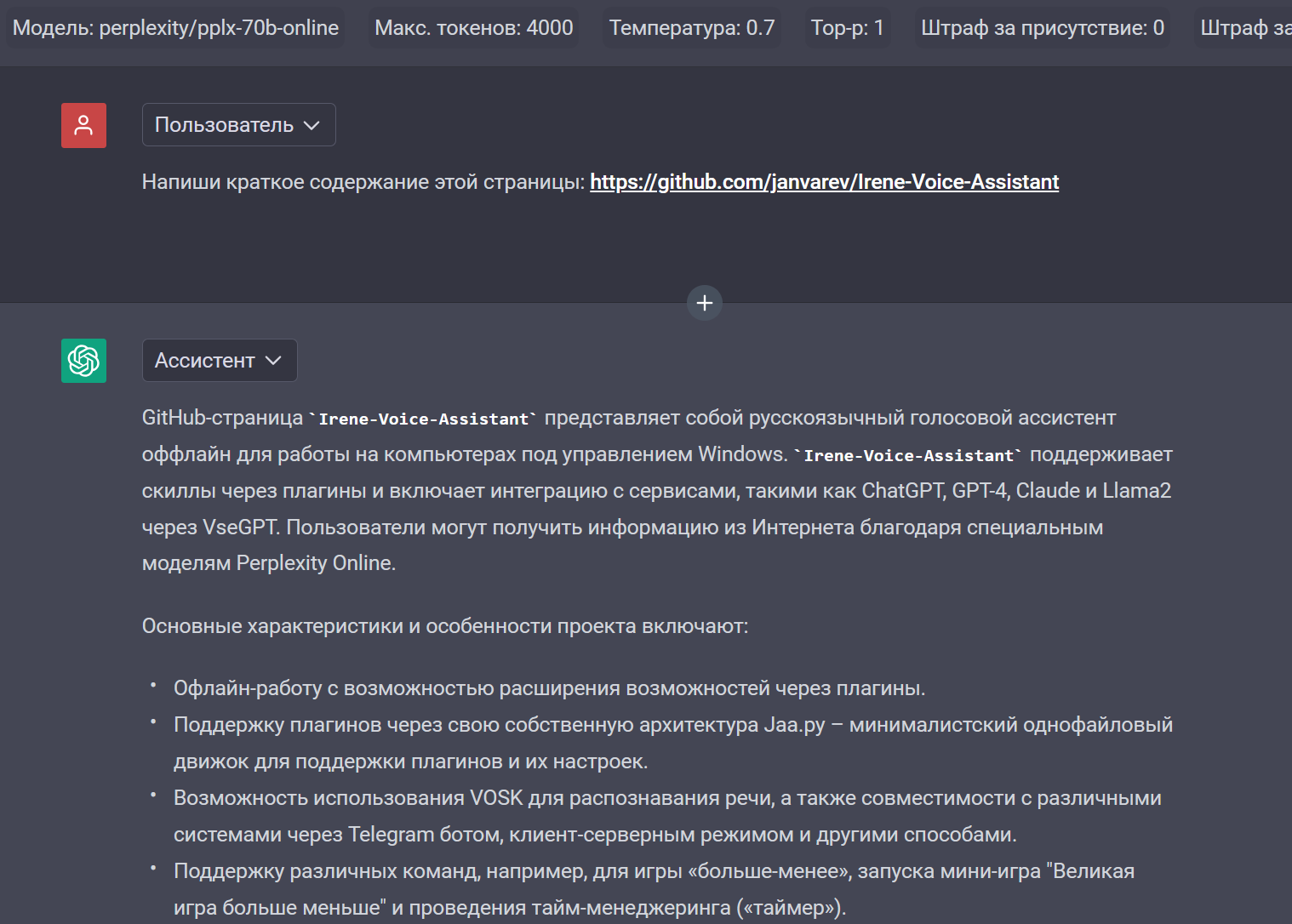
Также можно попросить проанализировать ссылку:
Интересный факт:
На сайте Peprlexity в своем собственном интерфейсе выдает ответы на вопросы со ссылками на источники — так, что можно проверить, откуда сеть взяла свои факты. Пользователи очень просят добавить возможность получать список источников при вызове по API — но пока, несмотря на все просьбы, этой функциональности нет.
Если нужно решать задачи SEO и копирайтинга…
…я бы рекомендовал попробовать модели с неплохим русским языком, отличные от ChatGPT — например, Google Gemini Pro или Claude 3 Sonnet.
Попробуйте несколько и посмотрите, что вам лучше подойдет.
❯ А что дальше?
В LLM-сообществе ожидаются 2 вещи:
Во-первых, OpenAI не будут мириться с тем, что Anthropic со своим Opus отнимает у них рынок и выкатят GPT-5, которая, вероятно, вновь станет лучшей сеткой. Учитывая, что GPT-4 была выпущена в марте 2023, у них был целый год, чтобы натренировать новую модель — и думаю, характеристики у неё будут высокие.
Во-вторых, LLama3, как новый базис для опенсорсных сетей, обещают в июне-июле. По слухам, для тренировок закупают какие-то тонны GPU, и вычислительных мощностей на новую Ламу потратят чуть ли не больше чем на GPT-4, что положительно скажется на качестве. Как только выпустят, вероятно, большинство энтузиастов возьмут свои собранные датасеты, быстро затюнят новые Ламы и выложат свои модели уже на новой базе — и придется подключать, подключать, подключать…
Модели, конечно, будут меняться, а, значит, этот туториал будет устаревать, но, надеюсь, базовые принципы подбора сеток под свои задаче, указанные вначале — искать больше и свежее — останутся неизменными.
Если есть какие-то вопросы по сетям — задавайте в комментариях, постараюсь по мере своего скромного опыта ответить.

