
Всем привет! Я Игорь Белов, iOS-разработчик в Тинькофф Бизнесе, выпускник Университета Иннополис и энтузиаст в области Computer Science. Занимаюсь iOS-разработкой почти четыре года, мне нравится изучать фундаментальные темы программирования и разбираться, как все работает под капотом.
Расскажу, почему Accelerate — это не так уж страшно и какая теория лежит в его основе. На конкретных примерах я покажу, насколько Accelerate способен помочь или не помочь в улучшении производительности. А еще оставлю практические советы и рекомендации по работе с Accelerate, которые накопил за время своей практики.
Что такое Accelerate и как с ним работать
Accelerate — один из моих любимых экзотических фреймворков. Под «экзотическим» я подразумеваю инструмент, который разработчик не использует для решения повседневных задач, а применяет только в редких случаях. Важная вещь, которую я бы хотел отметить:
Accelerate — это, на мой взгляд, один из самых игнорируемых фреймворков Apple.
Это утверждение основано на двух фактах: документации и проведенном опросе.
Во-первых, по Accelerate очень мало релевантных статей и сессий WWDC. Единственный источник существенной информации — официальная документация Apple.
Во-вторых, в ходе проведенного мной опроса среди почти ста iOS-разработчиков выяснилось, что большинство из них никогда не слышали о существовании Accelerate.

Исправим эту статистику и ответим на вопрос, что такое Accelerate.
Accelerate — нативный фреймворк, который позволяет совершать оптимизированные высокопроизводительные векторные вычисления.
Для лучшего понимания определения отмечу, что в основе Accelerate лежит линейная алгебра. Основные математические объекты линейной алгебры — векторы и матрицы. Мы, как программисты, можем ассоциировать векторы с обычными массивами, а матрицы — с многомерными массивами, в частности двумерными. С этими математическими объектами можно выполнять различные математические операции, например арифметические.
Если необходимо сложить две матрицы, мы проходим по каждому элементу матрицы и складываем его с соответствующим элементом второй матрицы.

Accelerate позволяет оптимизировать операции над матрицами и векторами. Для этого фреймворк использует концепцию Single Instruction Multiple Data. Под этим термином подразумевается целый комплекс компьютерных архитектур, предназначенных для выполнения одной и той же операции над большим объемом данных.

Пример устройства, где применяется SIMD — графический процессор, в котором постоянно приходится одновременно выполнять операции над большим количеством данных: точек, векторов и так далее.
В случае с приведенным выше примером при использовании оптимизаций SIMD сложение происходит не поэлементно, а одновременно. Так сложность операции будет не линейной, когда мы проходим по каждому элементу матрицы, а константной. Оценка очень грубая, поскольку операции выполняются не совсем одновременно из-за необходимости разделения большого массива на отдельные части — об этих деталях я расскажу немного позже.
Хотя самый популярный представитель SIMD-архитектуры — это GPU, операции Accelerate выполняются на векторном сопроцессоре CPU. Это позволяет совершать высокопроизводительные векторные операции энергоэффективно, поскольку каждый запрос к графическому процессору для выполнения вычислений — ресурсоемкая операция.
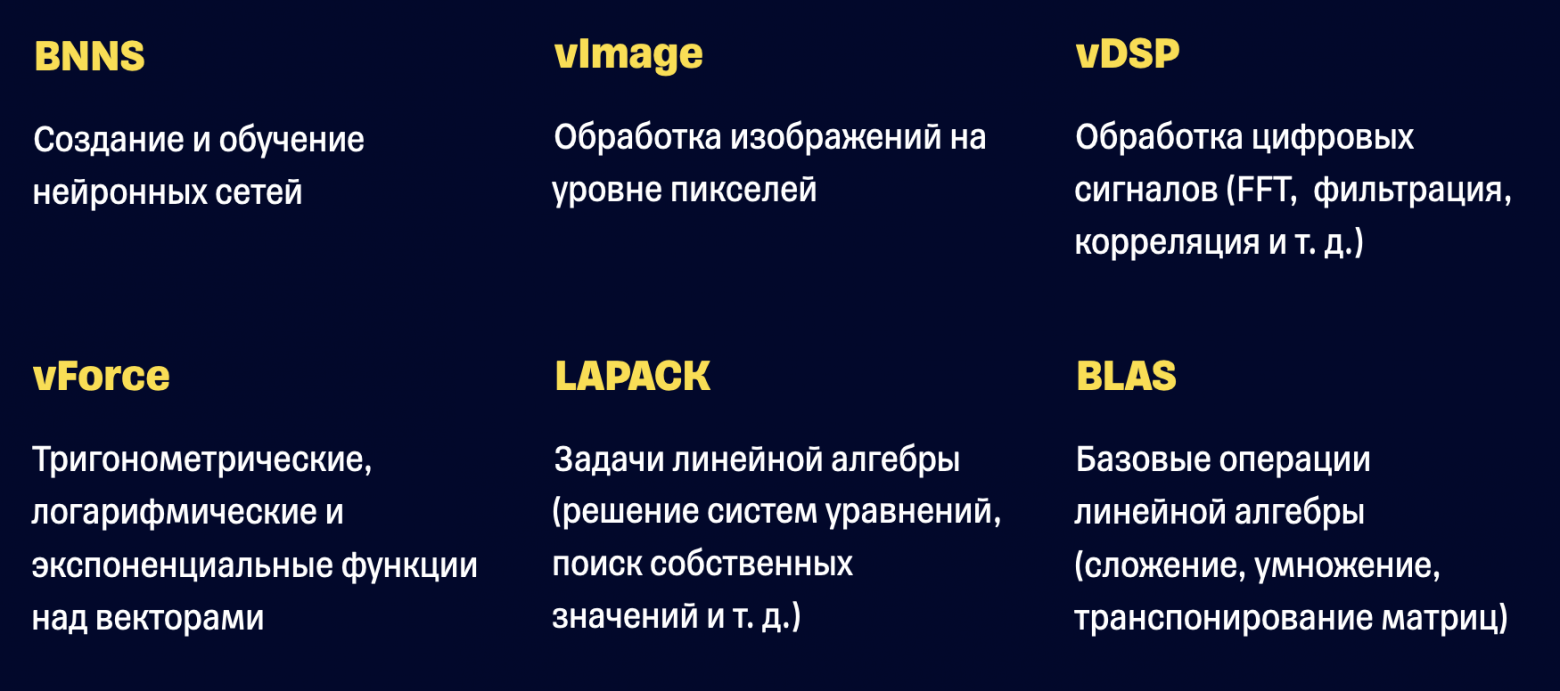
Accelerate состоит из шести библиотек:
Кажется, что все довольно понятно и просто. Но почему тогда в названии «Accelerate — это не страшно»? Что может напугать? Для ответа на этот вопрос я подготовил пример кода обычной программы на Swift с использованием Accelerate:
realSignal.withUnsafeMutableBufferPointer { realPtr in
imaginarySignal.withUnsafeMutableBufferPointer { imagPtr in
var splitComplexSignal = DSPSplitComplex(
realp: realPtr.baseAddress!,
imagp: imagPtr.baseAddress!
)
vDSP_vgen([1], [2], splitComplexSignal.realp, 1, vDSP_Length(n))
vDSP_vgen([1], [2], splitComplexSignal.imagp, 1, vDSP_Length(n))
var setupReal = vDSP_DFT_zop_CreateSetup(nil, vDSP_Length(n), vDSP_DFT_Direction.FORWARD)
realOutput.withUnsafeMutableBufferPointer { realOutputPtr in
imaginaryOutput.withUnsafeMutableBufferPointer { imaginaryOutputPtr in
var splitComplexOutput = DSPSplitComplex(
realp: realOutputPtr.baseAddress!,
imagp: imaginaryOutputPtr.baseAddress!
)
vDSP_DFT_Execute(
setupReal!,
splitComplexSignal.realp, splitComplexSignal.imagp,
splitComplexOutput.realp, splitComplexOutput.imagp
)
vDSP_DFT_DestroySetup(setupReal)
}
}
}
}Код выглядит страшно и сложно, хотя это искусственный пример: он выполняет дискретное преобразование Фурье над случайным набором значений. Нам не нужно вдаваться в подробности кода, рассмотрим два основных момента:
Accelerate работает не с массивами напрямую, а с указателями на область памяти, где хранятся эти массивы.
Вызовы функций Accelerate отличаются от привычного Swift-кода, так как Accelerate — это библиотека, написанная на языке C. При работе с ней из Swift мы используем сигнатуры функций на языке C, которые доступны в Swift благодаря возможностям бриджинга его компилятора.
Разберем на более простом примере, как работать с Accelerate. Допустим, нам нужно сложить два массива. Для этого в документации ищем подходящую функцию — vDSP_vadd. Сигнатура пугает, и непонятно, за что отвечает каждый параметр:

В функции мы передаем входные данные в виде указателей на область памяти, а именно два вектора — A и B. Еще передаем указатель на вектор C, в который будем записывать результат.
Важно отметить, что функция не возвращает результат, а записывает его в зарезервированный заранее буфер. Это может быть полезно для оптимизации работы с памятью при обработке большого количества элементов, поскольку при таком подходе не требуется создание промежуточных буферов.
Для каждого из этих буферов мы передаем параметр шага. Обычно значение этого параметра равно единице, он указывает на то, с какой периодичностью мы берем элементы из соответствующих буферов. Указание другого значения шага может быть полезно в случаях, когда требуется выполнить операцию над подмножеством значений массива. Таким образом можно работать, например, с каждым вторым, третьим и так далее элементом.
Последний параметр этой функции — количество элементов, которое мы обрабатываем. Почти во всех функциях Accelerate требуется его указать. Это связано с тем, что мы работаем не с массивами напрямую, а с указателями на область памяти и нам нужно знать, сколько значений мы хотим оттуда взять.
Используя функцию vDSP_vadd, мы можем написать короткую программу, чтобы эффективно сложить два массива значений:
import Accelerate
let arrayA: [Float] = [1, 2, 3, 4, 5]
let arrayB: [Float] = [6, 7, 8, 9, 10]
var result: [Float] = Array(repeating: 0, count: arrayA.count)
vDSP_vadd(arrayA, 1, arrayB, 1, &result, 1, vDSP_Length(arrayA.count))Несмотря на то, что сигнатура функции vDSP_vadd в качестве параметров требует векторы в виде указателей на область памяти, здесь я передаю два обычных свифтовых массива, потому что Swift за счет бриджинга позволяет передавать их в функции, где ожидается указатель.
В этом случае мы работаем со значениями типа Float, так как функция выполняет операции над значениями одинарной точности. Но еще существуют функции для выполнения операций над значениями двойной точности — в Accelerate для каждой функции имеется аналогичная функция с суффиксом D, которая позволяет работать со значениями типа Double.
import Accelerate
let arrayA: [Double] = [1, 2, 3, 4, 5]
let arrayB: [Double] = [6, 7, 8, 9, 10]
var result: [Double] = Array(repeating: 0, count: arrayA.count)
vDSP_vaddD(arrayA, 1, arrayB, 1, &result, 1, vDSP_Length(arrayA.count))Синтаксис может показаться неприятным, но не все так страшно. Вызовы Accelerate можно записывать в более читаемой форме, используя современные обертки в Swift над старыми вызовами из языка C.
Для каждого модуля — BNNS, vDSP и так далее — существует пространство имен, реализованное с помощью Swift-перечислений (enum). Эти перечисления содержат обертки вокруг функций на языке C и позволяют писать код в более привычном для нас виде.
vDSP_vadd(arrayA, 1, arrayB, 1, &resultA, 1, vDSP_Length(arrayA.count))
vDSP_vmul(resultA, 1, arrayC, 1, &resultB, 1, vDSP_Length(arrayA.count))
vDSP_sve(resultB, 1, &finalResult, vDSP_Length(arrayA.count))let sum = vDSP.add(arrayA, arrayB)
let product = vDSP.multiply(sum, arrayC)
let finalResult = vDSP.sum(product)Код выглядит компактно и аккуратно. Есть только одно ограничение: при вызове функции мы передаем два буфера для выполнения операции и получаем новый буфер на выходе. Это ограничение не позволяет оптимизировать работу с памятью, так как при каждом вызове функции-обертки мы создаем новый буфер и не можем повторно использовать уже существующий, если это требуется.
Примеры использования Accelerate
Я смоделировал несколько примеров на MacBook 16 — 2021, M1 Max.
Пример 1. Поиск минимального и максимального значений в массиве из 1 000 000 элементов.
Если искать обычным итеративным способом, получится довольно простой алгоритм:
var minValue = largeArray[0]
var maxValue = largeArray[0]
for value in largeArray {
if value < minValue { minValue = value }
if value > maxValue { maxValue = value }
}
print("Min: \(minValue), Max: \(maxValue)")Мы пробегаемся по каждому элементу, сравниваем его с предыдущими максимальным и минимальным значениями, а затем выводим результат.
При отключенных оптимизациях компилятора такой алгоритм выполнится в среднем примерно за 0,05 секунды для случайного набора из миллиона элементов. Я специально отключил оптимизации, чтобы показать сравнение, так как современные компиляторы умеют векторизировать некоторые виды операций.
Перепишем тот же код с использованием Accelerate. Внутри модуля vDSP есть функции, предназначенные для поиска минимального и максимального значений:
import Accelerate
let minValue = vDSP.minimum(largeArray)
let maxValue = vDSP.maximum(largeArray)Использование Accelerate позволило ускорить поиск в среднем в 160 раз по сравнению с обычным подходом на случайном наборе данных из миллиона элементов. Теперь поиск занимает 0,0003 секунды.
Может возникнуть вопрос: за счет чего происходит оптимизация, если мы все равно проходим по каждому элементу массива, чтобы провести сравнение?
Ответ прост: при вызове функций Accelerate большой массив значений разделяется на чанки — это позволяет сравнивать несколько элементов сразу, по аналогии с функцией сложения, о которой говорилось выше. Благодаря этому сложность алгоритма оценивается логарифмически, а не линейно. Оценка все еще грубая, поскольку не все элементы одновременно участвуют в сравнении — некоторые ждут своей очереди, так как количество регистров ограничено.
Пример 2. Получение доступа к сырым байтам большого изображения.
Когда мы работаем с камерой либо обрабатываем изображение или видео на мобильном устройстве, часто возникает необходимость получить сырые байты текущего обрабатываемого кадра, чтобы использовать информацию для его дальнейшей обработки или анализа.
Один из популярных способов получения сырых байтов — использование Core Graphics, а именно CGContext, и рендеринг изображения в буфер, который можно получить из этого контекста. На изображениях размером 6000 × 6000 такой алгоритм в среднем выполняется за 0,04 секунды:
let context = CGContext(
data: nil,
width: width,
height: height,
bitsPerComponent: bitsPerComponent,
bytesPerRow: bytesPerRow,
space: colorSpace,
bitmapInfo: bitmapInfo.rawValue
)!
context.draw(cgImage, in: CGRect(x: 0, y: 0, width: width, height: height))
let pixelBuffer = context.data!Выполнение программы можно ускорить, применив Accelerate. В библиотеке vImage есть подходящая функция, позволяющая преобразовать CGImage в буфер байтов, из которых оно состоит. Такой подход будет чуть более эффективным при обработке случайного набора изображений размером 6000 × 6000. В среднем алгоритм выполняется за 0,02 секунды:
var format = vImage_CGImageFormat(
bitsPerComponent: 8,
bitsPerPixel: 32,
colorSpace: Unmanaged<CGColorSpace>.passUnretained(colorSpace),
bitmapInfo: bitmapInfo,
version: 0,
decode: nil,
renderingIntent: .defaultIntent
)
var sourceBuffer = vImage_Buffer()
defer { free(sourceBuffer.data) }
vImageBuffer_InitWithCGImage(&sourceBuffer, &format, nil, cgImage, numericCast(kvImageNoFlags))Может показаться, что это недостаточно серьезная оптимизация, но если мы имеем дело с потоковой обработкой видео, где нам нужно обрабатывать каждый N-й кадр, то это существенная оптимизация, которая может повлиять на производительность приложения.
Пример 3. Вычисление гистограммы изображения с использованием полученных сырых байтов.
Гистограмма изображения показывает, сколько того или иного цвета содержится на изображении, которое мы обрабатываем. Результатом вычисления гистограммы будет несколько массивов размером 256 ячеек для каждого соответствующего канала. В каждой ячейке содержится количество пикселей с соответствующим значением цвета.
Применяя простой итеративный подход, мы можем вычислить гистограмму с помощью цикла, проходя по каждому байту изображения и подсчитывая значения пикселей, которые затем записываем в соответствующие массивы результатов:
// ...
let length = height * width
var histogramR = [Int](repeating: 0, count: 256)
var histogramG = [Int](repeating: 0, count: 256)
var histogramB = [Int](repeating: 0, count: 256)
var histogramA = [Int](repeating: 0, count: 256)
for i in 0..<length {
let pixelData = pixelBuffer.load(
fromByteOffset: i*4,
as: UInt32.self
)
let red = Int((pixelData >> 24) & 255)
let green = Int((pixelData >> 16) & 255)
let blue = Int((pixelData >> 8) & 255)
let alpha = Int((pixelData >> 0) & 255)
histogramR[red] += 1
histogramG[green] += 1
histogramB[blue] += 1
histogramA[alpha] += 1
}Такой подход неэффективен, особенно при обработке изображений размером 6000 на 6000 пикселей. В этом случае нам придется обработать 36 млн значений, пройдя по каждому из них в цикле и выполнив соответствующие операции.
Я протестировал алгоритм на изображениях 6000 на 6000 пикселей, и он выполнялся в среднем 15 секунд с включенными оптимизациями. Это слишком долго. У компилятора оптимизировать алгоритм не получилось. Решение не подходит для production-приложений, так как время отклика становится непозволительным.
Мы можем переписать все с использованием Accelerate, применяя специальную функцию vImageHistogramCalculation из модуля vImage, которая позволяет точно так же вычислять гистограмму и записывать ее в массив из массивов:
// ...
var histBins = [
alphaPtr.baseAddress,
redPtr.baseAddress,
greenPtr.baseAddress,
bluePtr.baseAddress
]
histBins.withUnsafeMutableBufferPointer { bins in
let error = vImageHistogramCalculation_ARGB8888(
&histogramSourceBuffer,
bins.baseAddress!,
vImage_Flags(kvImageNoFlags)
)
}При обработке случайного набора изображений размером 6000 на 6000 пикселей алгоритм, использующий Accelerate, выполняется в среднем за 0,009 секунды. Такая производительность подходит нам намного больше: например, мы можем использовать этот метод вычисления гистограммы при обработке потокового видео.
Несколько советов
1. Изучите задачу, которую вы пытаетесь решить. Возможно, найдется более эффективное решение, основанное на использовании этого инструмента, или, наоборот, применение Accelerate может оказаться неэффективным для ваших потребностей.
Рассмотрим пример, где мы проходимся по двум буферам изображений и ищем количество пикселей, которыми они различаются. Если применять обычный итеративный подход, то получится то же самое, что и при вычислении гистограммы, — нам нужно пройти по каждому элементу массива и сравнить его с соответствующим элементом другого массива:
let firstBuffer: [Float] = convertImageToFloatBytes(image1)
let secondBuffer: [Float] = convertImageToFloatBytes(image2)
var differentPixelsNumber = 0
for i in 0..<firstBuffer.count {
if firstBuffer[i] != secondBuffer[i] {
differentPixelsNumber += 1
}
}Неэффективно, но мы можем улучшить решение, используя Accelerate:
let firstBuffer: [Float] = convertImageToFloatBytes(image1)
let secondBuffer: [Float] = convertImageToFloatBytes(image2)
var difference = vDSP.subtract(firstBuffer, secondBuffer)
difference = vDSP.absolute(difference)
difference = vDSP.clip(difference, to: 0...1)
let differentPixelsNumber = vDSP.sum(difference)Например, можем вычесть одно изображение из другого, привести полученные значения по модулю и ограничить их в диапазоне от 0 до 1. Затем мы сложим эти значения, чтобы определить количество пикселей, которыми различаются изображения. Даже несмотря на использование нескольких функций подряд, мы достигнем значительно большей эффективности по сравнению с итеративным подходом.
2. По возможности переиспользуйте буферы. Используя классические C-вызовы Accelerate внутри Swift, мы можем переиспользовать буферы, с которыми работаем. Это полезно для оптимизации использования памяти, чтобы избежать лишних затрат ресурсов и времени на выделение новых буферов.
let firstBuffer: UnsafeMutablePointer<Float> = convertImageToFloatBytes(image1)
let secondBuffer: UnsafeMutablePointer<Float> = convertImageToFloatBytes(image2)
var difference = firstBuffer
vDSP_vsub(firstBuffer, 1, secondBuffer, 1, difference, 1, length)
vDSP_vabs(firstBuffer, 1, difference, 1, length)
vDSP_vclip(firstBuffer, 1, &low, &high, difference, 1, length)
var differentPixelsNumber: Float = 0
vDSP_sve(firstBuffer, 1, &differentPixelsNumber, length)Я переписал задачу со сравнением двух изображений, переиспользуя полученные изначально буферы. В каждом случае повторно используем буфер, что позволяет избежать лишних затрат на инициализацию. Это сокращает время выполнения программы.
Важно не забыть про читабельность кода. Даже если вам может быть понятно, почему один и тот же буфер используется в нескольких местах с одним и тем же названием в качестве операнда или результата, другие разработчики, которые будут читать код, могут запутаться.
3. Изучите Unsafe Swift и используйте его осторожно. Поскольку Accelerate работает с указателями, важно уметь работать с ними в Swift. Работа с указателями в Swift выполняется через Unsafe Swift. Концепция содержит много терминов и функций, которые можно использовать, чтобы напрямую работать с памятью, выделять буферы, изменять их и обращаться к участкам памяти. Это может быть эффективным при работе с Accelerate, однако важно помнить, что использование Unsafe Swift — это большая ответственность.
let pointer: UnsafeMutablePointer<Int> = .allocate(capacity: 3)
defer {
pointer.deinitialize(count: 3)
pointer.deallocate()
}
pointer.initialize(repeating: 0, count: 3)
pointer.advanced(by: 0).pointee = 10
pointer.advanced(by: 1).pointee = 20
pointer.advanced(by: 2).pointee = 30
let buffer = UnsafeMutableBufferPointer(start: pointer, count: 3)Когда переходим к ручному управлению памятью, нам необходимо постоянно помнить, что память, которую мы создали, нам нужно также деаллоцировать, поскольку это ресурс и мы его забираем.
Что дальше
Хочу завершить статью утверждением, что Accelerate — это не серебряная пуля, не все задачи он способен оптимизировать.
Например, при обработке совсем небольших массивов добавление дополнительного запроса к векторному сопроцессору CPU будет только накладными расходами и не принесет никакой пользы. В этом случае может оказаться более эффективным выполнять эти операции на обычном процессоре. Важно помнить об этом и проводить оптимизации постепенно, сравнивая производительность и оценивая, какой подход приносит наибольшую пользу в каждом конкретном случае.
Несколько источников, которые можно использовать для углубления в Accelerate:
