Несколько дней назад стала доступна версия Data ONTAP 8.3.2RC1. “RC” означает Release Candidate, а следовательно, в соответствии с принятыми в NetApp правилами именования версий, этот релиз уже прошел все внутренние тесты и может использоваться заказчиками не только для оценки новых возможностей, но и для продуктива, включая системы, на которых работают бизнес-критичные задачи. Поддержка вендора полностью распространяется на системы, работающие на “RC” версиях Data ONTAP.
Продавцы NetApp (да, это и мы тоже ;) не устают напоминать (и делают это совершенно правильно), что высокая утилизация дисковых ресурсов в системах NetApp достигается за счет использования программных средств оптимизации — дедупликации и компрессии.
Информация ниже — это краткий обзор возможностей NetApp Data ONTAP 8.3.2RC1, который будет полезен «еще не зубрам».
Дедупликация доступна заказчикам уже очень давно и, с момента своего появления, работает исключительно в “оффлайн” режиме — по расписанию запускается процесс, который ищет повторяющиеся блоки данных и оставляет на диске только один из них. Система при этом не только сравнивает хэш-суммы от блоков, но и сами данные, что гарантирует отсутствие хэш-коллизий.
Это позволяет избежать проблем с производительностью — включение дедупликации не приведет ни к каким изменениям в нагрузке на процессор/память СХД. Однако для целого ряда задач такой механизм дедупликации не является оптимальным. Представьте себе, что у вас есть ферма из множества виртуальных рабочих мест (VDI) и вам нужно произвести обновление ПО на всех дестктопах или установить патч для ОС. В это время на диски будет записано множество идентичных блоков данных. Да, конечно, потом пройдет процесс дедупликации и “лишнее” дисковое пространство освободится, но само обновление приведет к огромному числу операций записи. А значит, мы получим перегруженный бэк-енд и, как следствие, это может сказаться на производительности других сервисов, работающих с данной СХД.
С появлением cDOT 8.3.2 у владельцев СХД NetApp есть решение — inline dedupe (дедупликация “на лету”). Для All Flash СХД поддержка inline dedupe включена “из коробки” на всех вновь создаваемых томах, а также может быть включена на уже существующих томах с данными (без пересоздания тома). Для СХД, использующих Flash Pool, онлайн-дедупликация работает только для операций записи на SSD и может быть также включена как на новых, так и на уже созданных томах. Для систем, построенных на обычных дисках, новый режим необходимо включать принудительно. Управлять работой инлайн-дедупликации можно командой
volume efficiency через опцию -inline-deduplication (true / false):
volume efficiency modify -vserver SVM_test -volume /vol/ volume-001 -inline-deduplication true
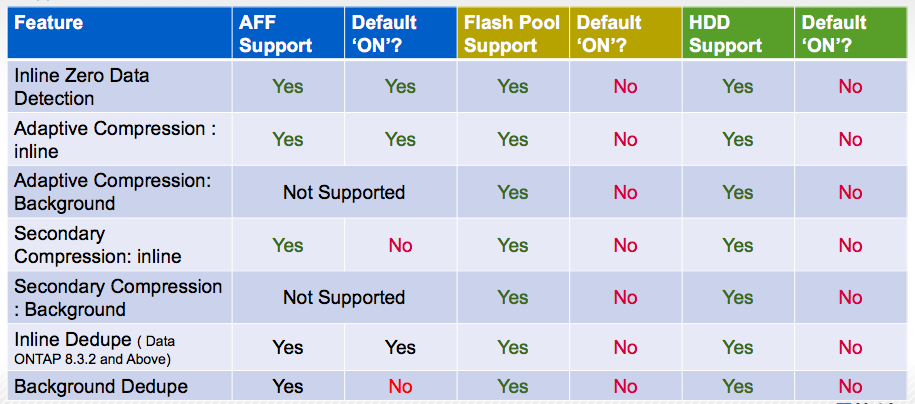
Ниже таблица поддерживаемых режимов оптимизации для AFF и других систем NetApp FAS:
Dtata ONTAP выделяет примерно 1% от общей оперативной памяти для хранения хешей записываемых блоков. Чтобы сохранить высокую производительность, разработчикам пришлось отказаться от глобальной дедупликации — она бы потребовала слишком много памяти и процессорных ресурсов для реализации. В памяти хранятся только хэш записанных недавно блоков — при перезагрузке хранилище будет очищено и статистика будет накапливаться заново.
Еще одна важная особенность — миграция тома (Data Motion) приведет к тому, что все преимущества от дедупликации исчезнут до тех пор, пока не отработает постпроцессинг. Это нужно учитывать при планировании переноса дедуплицированных данных внутри системы.
Чтобы повысить эффективность от inline dedupe, возможно совместное использование с “классической” постпроцессинговой схемой. Для All Flash СХД постпроцессинг изначально отключен (для минимизации общего числа операций записи), поэтому его нужно будет принудительно включить.
Использование инлайн-дедупликации не отменяет других возможностей по повышению эффективности хранения данных в системах хранения NetApp. При одновременном включении онлайн компрессии и дедупликации, порядок работы будет таким:
За счет отказа от глобальной дедупликации, разработчикам Data ONTAP удалось реализовать довольно интересный механизм оптимизации операций записи, который хорошо работает для ряда видов нагрузки и отличается минимальным влиянием на производительность системы. А за счет снижения нагрузки на бэк-енд, в некоторых случаях можно говорить и об увеличении интегральной производительности системы. Любой обладатель системы NetApp (поддерживающей cDOT 8.3) может проверить эффективность от инлайн-дедупликации, обновившись до версии 8.3.2RC1. Конечно, желательно проводить эксперименты на тестовых системах или в рамках пилотов — перенастраивать работающий продуктив перед Новым Годом мы не посоветуем никому :)
В своей работе нам приходилось сталкиваться с самыми разными ситуациями, вплоть до того, что во время работы постпроцессинговой дедупликации переставало хватать производительности системы на основную нагрузку. Все это можно и нужно оценивать еще на этапе разработки проекта, закладывая необходимый запас мощности при выборе системы хранения данных. Специалисты Тринити обладают обширными знаниями и богатым опытом для проведения предпроектных исследований и сайзинга СХД под самые различные требования заказчиков.
Читайте больше обзоров в блоге Тринити.
А также воспользуйтесь наработками Тринити:
Продавцы NetApp (да, это и мы тоже ;) не устают напоминать (и делают это совершенно правильно), что высокая утилизация дисковых ресурсов в системах NetApp достигается за счет использования программных средств оптимизации — дедупликации и компрессии.
Информация ниже — это краткий обзор возможностей NetApp Data ONTAP 8.3.2RC1, который будет полезен «еще не зубрам».
Дедупликация доступна заказчикам уже очень давно и, с момента своего появления, работает исключительно в “оффлайн” режиме — по расписанию запускается процесс, который ищет повторяющиеся блоки данных и оставляет на диске только один из них. Система при этом не только сравнивает хэш-суммы от блоков, но и сами данные, что гарантирует отсутствие хэш-коллизий.
Это позволяет избежать проблем с производительностью — включение дедупликации не приведет ни к каким изменениям в нагрузке на процессор/память СХД. Однако для целого ряда задач такой механизм дедупликации не является оптимальным. Представьте себе, что у вас есть ферма из множества виртуальных рабочих мест (VDI) и вам нужно произвести обновление ПО на всех дестктопах или установить патч для ОС. В это время на диски будет записано множество идентичных блоков данных. Да, конечно, потом пройдет процесс дедупликации и “лишнее” дисковое пространство освободится, но само обновление приведет к огромному числу операций записи. А значит, мы получим перегруженный бэк-енд и, как следствие, это может сказаться на производительности других сервисов, работающих с данной СХД.
С появлением cDOT 8.3.2 у владельцев СХД NetApp есть решение — inline dedupe (дедупликация “на лету”). Для All Flash СХД поддержка inline dedupe включена “из коробки” на всех вновь создаваемых томах, а также может быть включена на уже существующих томах с данными (без пересоздания тома). Для СХД, использующих Flash Pool, онлайн-дедупликация работает только для операций записи на SSD и может быть также включена как на новых, так и на уже созданных томах. Для систем, построенных на обычных дисках, новый режим необходимо включать принудительно. Управлять работой инлайн-дедупликации можно командой
volume efficiency через опцию -inline-deduplication (true / false):
volume efficiency modify -vserver SVM_test -volume /vol/ volume-001 -inline-deduplication true
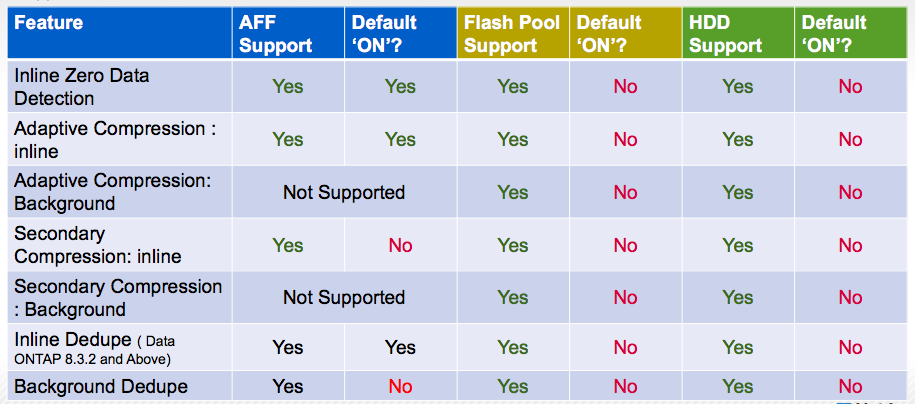
Ниже таблица поддерживаемых режимов оптимизации для AFF и других систем NetApp FAS:
Dtata ONTAP выделяет примерно 1% от общей оперативной памяти для хранения хешей записываемых блоков. Чтобы сохранить высокую производительность, разработчикам пришлось отказаться от глобальной дедупликации — она бы потребовала слишком много памяти и процессорных ресурсов для реализации. В памяти хранятся только хэш записанных недавно блоков — при перезагрузке хранилище будет очищено и статистика будет накапливаться заново.
Еще одна важная особенность — миграция тома (Data Motion) приведет к тому, что все преимущества от дедупликации исчезнут до тех пор, пока не отработает постпроцессинг. Это нужно учитывать при планировании переноса дедуплицированных данных внутри системы.
Чтобы повысить эффективность от inline dedupe, возможно совместное использование с “классической” постпроцессинговой схемой. Для All Flash СХД постпроцессинг изначально отключен (для минимизации общего числа операций записи), поэтому его нужно будет принудительно включить.
Использование инлайн-дедупликации не отменяет других возможностей по повышению эффективности хранения данных в системах хранения NetApp. При одновременном включении онлайн компрессии и дедупликации, порядок работы будет таким:
- inline zero-block reduplication — исключаются пустые (заполненные нулями) блоки
- inline compression — данные сжимаются
- inline deduplication — сжатые блоки проверяются на идентичность хешей; если хэши совпадает, сравниваются целиком при совпадении хэшей и повторяющиеся блоки исключаются из записи на диски
За счет отказа от глобальной дедупликации, разработчикам Data ONTAP удалось реализовать довольно интересный механизм оптимизации операций записи, который хорошо работает для ряда видов нагрузки и отличается минимальным влиянием на производительность системы. А за счет снижения нагрузки на бэк-енд, в некоторых случаях можно говорить и об увеличении интегральной производительности системы. Любой обладатель системы NetApp (поддерживающей cDOT 8.3) может проверить эффективность от инлайн-дедупликации, обновившись до версии 8.3.2RC1. Конечно, желательно проводить эксперименты на тестовых системах или в рамках пилотов — перенастраивать работающий продуктив перед Новым Годом мы не посоветуем никому :)
В своей работе нам приходилось сталкиваться с самыми разными ситуациями, вплоть до того, что во время работы постпроцессинговой дедупликации переставало хватать производительности системы на основную нагрузку. Все это можно и нужно оценивать еще на этапе разработки проекта, закладывая необходимый запас мощности при выборе системы хранения данных. Специалисты Тринити обладают обширными знаниями и богатым опытом для проведения предпроектных исследований и сайзинга СХД под самые различные требования заказчиков.
Читайте больше обзоров в блоге Тринити.
А также воспользуйтесь наработками Тринити:
- Конфигуратор серверов — удобен для любого уровня подготовки ИТ специалиста
- Конфигуратор СХД — можно быстро подобрать СХД или переговорить с менеджером
- Восстановленные серверы RS Тринити — супер доступно. Их любит телеком и SMB :)
