Первый прототип объектных хранилищ мир увидел в 1996 году. Через 10 лет Amazon Web Services запустит Amazon S3, и мир начнёт планомерно сходить с ума от плоского адресного пространства. Благодаря работе с метаданными и своей возможности масштабироваться, не проседая под нагрузкой, объектные хранилища быстро стали стандартом для большинства сервисов по хранению данных в облаках, и не только. Другая важная особенность — это хорошая приспособленность для хранения архивов и подобных им редко используемых файлов. Все, кто был связан с хранением данных, ликовали и носили новую технологию на руках.

Но людская молва полнилась слухами, что объектные хранилища — это только про большие облака, а если вам не нужны решения от проклятых капиталистов, то сделать своё будет очень сложно. Про развёртывание своего облака уже написано много, а вот про создание так называемых S3-compatible решений информации маловато.
Поэтому сегодня мы разберёмся, какие есть варианты "Чтобы как у взрослых, а не CEPH и напильник побольше", развернём один из них, а проверять, что всё работает, будем с помощью Veeam Backup & Replication. В нём заявлена поддержка работы с S3-совместимыми хранилищами, и вот это заявление мы будем проверять.
А как у других?
Начать предлагаю с небольшого обзора рынка и вариантов объектных хранилищ. Общепризнанный лидер и стандарт — это Amazon S3. Два ближайших преследователя — Microsoft Azure Blob Storage и IBM Cloud Object Storage.
Неужели и всё? Неужели нет других конкурентов? Конечно, конкуренты есть, но кто-то идёт своим путём, как Google Cloud или Oracle Cloud Object Storage, с неполной поддержкой S3 API. Кто-то использует старые версии API, как Baidu Cloud. А некоторые, вроде Hitachi Cloud, требуют применения особой логики, что непременно вызовет свои трудности. В любом случае, всех сравнивают с Амазоном, который и можно считать индустриальным стандартом.
А вот в on-premise решениях выбор намного больше, поэтому давайте обозначим важные нам критерии. В принципе, хватит всего двух: поддержка S3 API и использование v4 подписывания. Положа руку на сердце, нам как будущему клиенту интересны только интерфейсы для взаимодействия, а внутренняя кухня самого хранилища нас интересует уже не так сильно.
Под эти простые условия подходит ну очень много решений. Например, классические корпоративные тяжеловесы:
- DellEMC ECS
- NetApp S3 StorageGrid
- Nutanix Buckets
- Pure Storage FlashBlade и StorReduce
- Huawei FusionStorage
Есть ниша чисто софтовых решений, работающих из коробки:
- Red Hat Ceph
- SUSE Enterprise Storage
- Cloudian
И даже любителей тщательно обработать напильником после сборки не обидели:
- CEPH в чистом виде
- Minio (Linux версия, ибо к Windows версии есть много вопросов)
Список далеко не полный, его можно обсудить в комментариях. Только не забывайте перед внедрением проверять помимо API совместимости ещё и производительность системы. Последнее, что вам надо — это потеря терабайтов данных из-за подвисших запросов. Так что не стесняйтесь с нагрузочными тестами. Вообще весь взрослый софт, работающий с большими объёмами данных, имеет как минимум отчёты о совместимости. В случае с Veeam есть целая программа по взаимному тестированию, позволяющая смело заявлять о полной совместимости наших продуктов с конкретным оборудованием. Это уже двухсторонняя работа, не всегда быстрая, но мы постоянно расширяем список протестированных решений.
Собираем наш стенд
Хочется немного поговорить о выборе подопытного.
Во-первых, я хотел найти вариант, который сразу будет работать из коробки. Ну или хотя бы с максимальной вероятностью того, что он заработает без необходимости совершать лишние телодвижения. Танцы с бубном и ковыряние консоли в ночи — это очень увлекательно, но иногда хочется, чтобы работало сразу. Да и общая надёжность таких решений обычно повыше. И да, в нас пропал дух авантюризма, мы перестали лазить в окна к любимым женщинам и т.д.(с).
Во-вторых, если уж честно, необходимость работы с объектными хранилищами возникает у довольно больших компаний, так что это тот самый случай, когда смотреть в сторону решений enterprise-уровня не только не стыдно, а даже поощряется. Во всяком случае, я пока не знаю примеров, чтобы кого-то уволили за покупку подобных решений.
Исходя из всего вышесказанного, выбор мой пал на Dell EMC ECS Community Edition. Это очень интересный проект, и я считаю необходимым рассказать вам о нём.
Первое, что приходит в голову при виде дополнения Community Edition — что это просто калька с полноценного ECS с каким-то ограничениями, которые снимаются покупкой лицензии. Так вот нет!
Запомните:
!!!Community Edition — это отдельный проект, созданный для тестирования, и без техподдержки со стороны Dell!!
И его не превратить в полноценный ECS, даже если очень захочется.
Давайте разбираться
Многие считают, что Dell EMC ECS — чуть ли не самое лучшее решение, если у вас возникла необходимость в объектном хранилищe. Все проекты под маркой ECS, включая коммерческие и корпоративные, лежат на гитхабе. Этакий жест доброй воли от Dell. И помимо софта, который запускается на их брендовом железе, есть опенсорс-версия, которую можно развернуть хоть в облаке, хоть на виртуалке, хоть в контейнере, хоть на любом своём железе. Забегая вперёд — есть даже OVA версия, чем мы и воспользуемся.
Сам DELL ECS Community Edition — это мини-вариант полноценного софта, работающего на брендовых серверах Dell EMC ECS.
Я выделил четыре главных отличия:
- Нет поддержки шифрования. Обидно, но не критично.
- Отсутствует Fabric Layer. Эта штука отвечает за построение кластеров, менеджмент ресурсов, обновления, мониторинг и хранение Docker образов. Вот тут уже очень обидно, но Dell тоже можно понять.
- Самое противное следствие предыдущего пункта: размер ноды нельзя расширить после завершения инсталляции.
- Нет техподдержки. Это продукт для тестирования, который не возбраняется использовать в небольших инсталяциях, но заливать туда петабайты важных данных лично я бы не решился. Но технически помешать вам это сделать никто не может.

А что в большом варианте?
Галопом по Европам пробежимся по железным решениями, дабы иметь более полное представление об экосистеме.
Как-то подтверждать или опровергать утверждение, что DELL ECS — это лучшее on-prem объектное хранилище, я не буду, но если вам есть что сказать на эту тему, с удовольствием прочитаю в комментариях. Во всяком случае по версии IDC MarketScape 2018 Dell EMC уверенно входит в пятёрку лидеров OBS рынка. Хотя там не учитываются cloud-based решения, но это отдельный разговор.
С технической точки зрения ECS — это объектное хранилище, обеспечивающее доступ к данным по протоколам облачного хранения. Поддерживает AWS S3 и OpenStack Swift. Для file-enabled бакетов ECS поддерживает NFSv3 для возможности пофайлового экспорта.
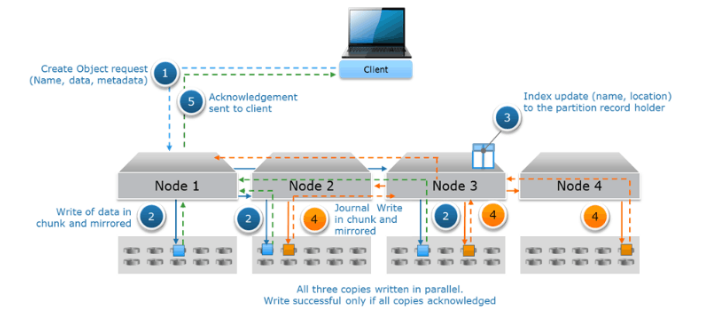
Процесс записи информации довольно необычен, особенно после классических систем блочного хранения.
- При поступлении новых данных создаётся новый объект, у которого есть имя, сами данные и метаданные.
- Объекты бьются на чанки по 128 Мб, и каждый чанк записывается сразу на три ноды.
- Происходит обновление файла индекса, где записаны идентификаторы и места хранения.
- Обновляется файл журнала (лог записи) и тоже записывается на три ноды.
- Клиенту отправляется сообщение об успешной записи
Все три копии данных записываются параллельно. Запись считается успешной, только если все три копии были записаны успешно.
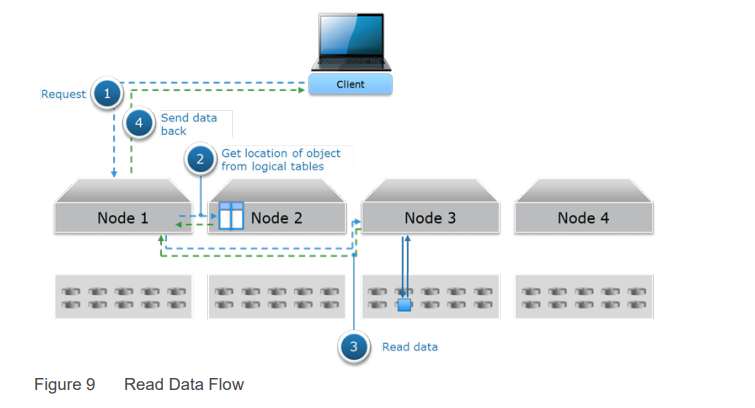
Чтение происходит попроще:
- Клиент запрашивает данные.
- В индексе ищется место хранения данных.
- Данные читаются с одной ноды и отправляются клиенту.
Самих серверов довольно много, поэтому посмотрим на самый маленький Dell EMC ECS EX300. Он начинается от 60Тб, имея возможность вырасти до 1,5Пб. А его старший брат Dell EMC ECS EX3000 позволяет уже хранить аж 8,6Пб на стойку.
Деплой
Технически Dell ECS CE можно развернуть сколь угодно большим. Во всяком случае, ограничений в явном виде я не нашёл. Однако всё масштабирование удобно делать методом клонирования самой первой ноды, для которой нам понадобятся:
- 8 vCPU
- 64GB RAM
- 16GB для операционки
- 1TB непосредственно для хранения
- Последний релиз CentOS minimal
Это вариант для случая, когда вы хотите устанавливать всё сами с самого начала. Для нас это вариант не актуален, т.к. я буду использовать для деплоя OVA образ.
Но в любом случае требования весьма злые даже для одной ноды, а если строго следовать букве закона, то таких нод надо четыре.
Однако разработчики ECS CE живут в реальном мире, и инсталляция проходит успешно даже с одной нодой, а минимальные требования таковы:
- 4 vCPU
- 16 GB RAM
- 16 GB для операционки
- 104 GB само хранилище
Именно такие ресурсы нужны для развёртывания OVA образа. Уже намного гуманнее и реалистичней.
Саму установочную ноду можно взять в официальном github. Там же есть подробная документация по деплою всё-в-одном, но можно ещё почитать на официальном readthedocs. Поэтому подробно останавливаться на разворачивании OVA мы не будем, там без фокусов. Главное — не забудьте перед её запуском или расширить диск до нужного объема, или прицепить необходимые.
Запускаем машину, открываем консоль и используем самые лучшие креды по умолчанию:
- логин: admin
- пароль: ChangeMe
Затем запускам sudo nmtui и настраиваем сетевой интерфейс — IP/маска, DNS и гейт. Памятуя, что в CentOS minimal нет net-tools, проверяем настройки через ip addr.
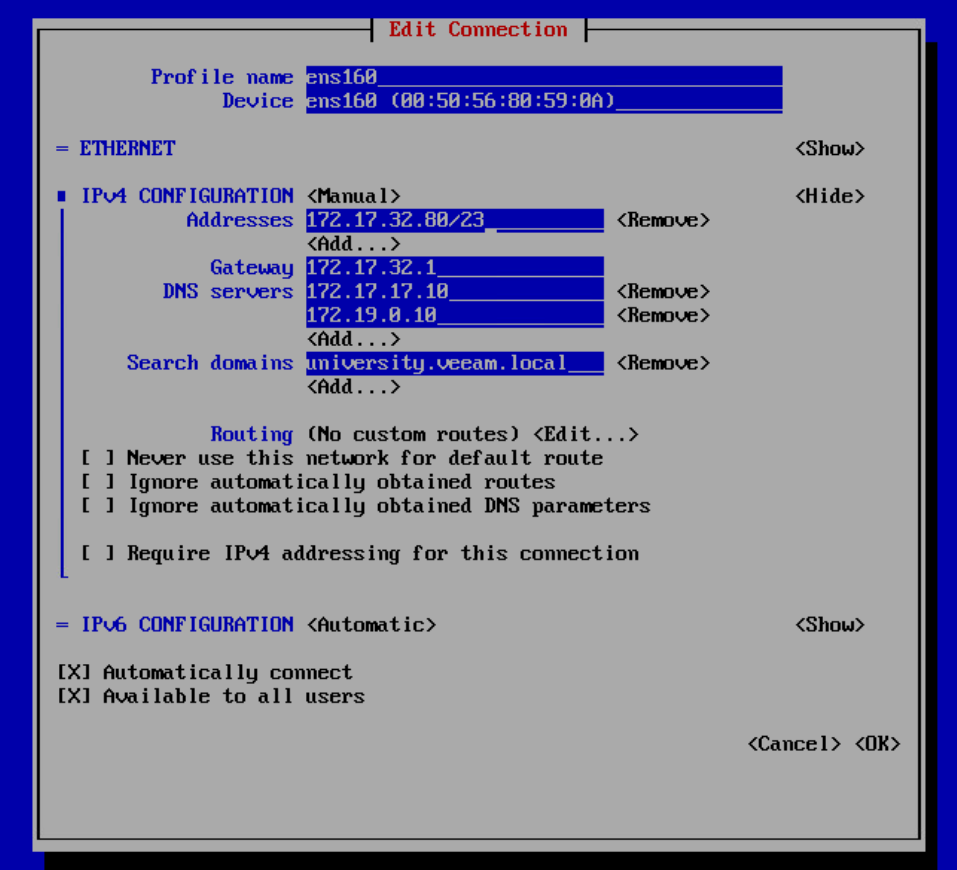
И поскольку только смелым покоряются моря, делаем yum update, после чего reboot. На самом деле это довольно безопасно, т.к. всё развертывание делается через плейбуки, а все важные пакеты докера залочены на текущей версии.
Теперь настало время отредактировать установочный скрипт. Никаких вам красивых окошек или псевдо UI — всё через ваш любимый текстовый редактор. Чисто технически есть два пути: можно запускать каждую команду ручками или сразу запустить конфигуратор videploy. Он просто откроет конфиг в vim, а по выходу запустит его проверку. Но сознательно упрощать себе жизнь не интересно, поэтому выполним на две команды больше. Хотя смысла в этом никакого, я вас предупредил =)
Итак, делаем vim ECS-CommunityEdition/deploy.xml и вносим оптимально-минимальные изменения, чтобы ECS включилась и работала. Список параметров можно подсократить, но я сделал вот так:
- licensed_accepted: true Можно и не менять, тогда при деплое вас в явном виде попросят его принять и покажут милую фразу. Возможно, это даже пасхалочка такая.

- Раскомментировать строчки autonames: и custom: Ввести как минимум одно желаемое имя для ноды — hostname будет заменён на него в процессе инсталляции.
- install_node: 192.168.1.1 Указать реальный IP ноды. В нашем случае указываем тот же, что и в nmtui
- dns_domain: вводим свой домен.
- dns_servers: вписываем свой dns.
- ntp_servers: можно указать любой. Я взял первый попавшийся из пула 0.pool.ntp.org (им стал 91.216.168.42)
- autonaming: custom Если не раскомментировать, то луна назовётся Luna.
- ecs_block_devices:
/dev/sdb
По неведомой причине тут может оказаться несуществующее устройство блочного хранения /dev/vda - storage_pools:
members:
192.168.1.1 Тут снова указываем реальный IP ноды - ecs_block_devices:
/dev/sdb Повторяем операцию вырезания несуществующих устройств.
Вообще весь файл очень подробно описан в документации, но кто же её читать будет в такое беспокойное время. Там же написано, что минимально-достаточное — это указать IP и маску, но у меня в лабе такой набор заводился плоховато, и пришлось расширить до указанного выше.

После выхода из редактора надо запустить update_deploy /home/admin/ECS-CommunityEdition/deploy.yml, и если всё сделано правильно, про это будет сообщено в явном виде.

Затем всё же придётся запустить videploy, дождаться обновления окружения, и можно запускать саму инсталляцию командой ova-step1, а после её успешного выполнения команду ova-step2. Важно: не останавливайте работу скриптов руками! Некоторые шаги могут занимать значительное время, выполняться не с первой попытки и выглядеть так, будто всё сломалось. В любом случае надо дождаться завершения скрипта естественным путём. В конце вы должны увидеть примерно такое сообщение.
Теперь наконец-то мы можем открыть WebUI панель управления по известному нам IP. Если на этапе конфигурации не изменяли, то дефолтная учётка будет root/ChangeMe. Можно даже сразу пользоваться нашим S3-совместимым хранилищем. Оно доступно на портах 9020 для HTTP, и 9021 для HTTPS. Опять же, если ничего не меняли, то access_key: object_admin1 и secret_key: ChangeMeChangeMeChangeMeChangeMeChangeMe.
Но давайте не будем забегать сильно вперёд и начнём по порядку.

При первом логине вас принудительно попросят сменить-таки пароль на адекватный, что абсолютно правильно. Главный дашборд предельно понятный, поэтому давайте сделаем что-то более интересное, чем объяснение очевидных метрик. Например, создадим пользователя, которого будем использовать для доступа к хранилищу. В мире сервис-провайдеров таких именуют tenant. Делается это в Manage > Users > New Object User

При создании пользователя нас просят указать namespace. Технически, ничего нам не мешает заводить их столько, сколько будет пользователей. И наоборот. Это позволяет управлять ресурсами независимо для каждого тенанта.
Соответственно, выбираем необходимые нам функции и генерим ключи пользователя. Мне будет достаточно S3/Atmos. И не забываем сохранить ключик ;)

Пользователя создали, теперь пора ему и бакет выделить. Переходим в Manage > Bucket и заполняем требуемые поля. Тут всё просто.
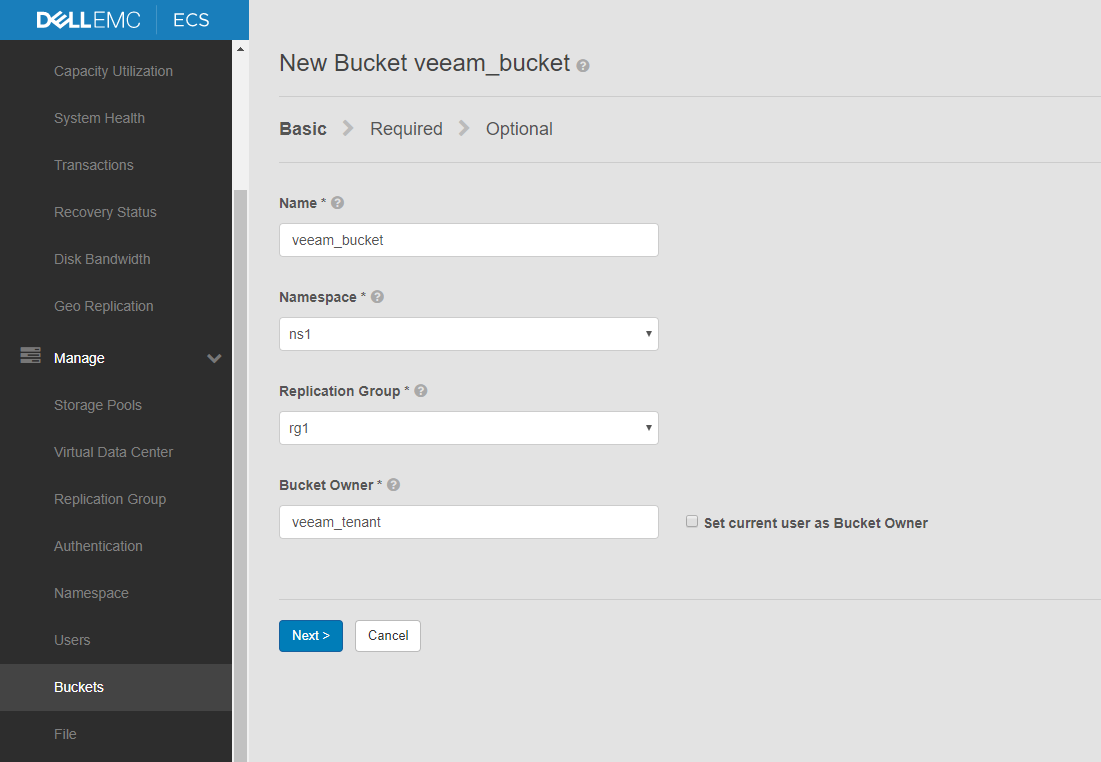
Теперь у нас всё готово для вполне себе боевого использования нашего S3 хранилища.
Настраиваем Veeam
Итак, как мы помним, одно из главных применений объектных хранилищ — это долговременное хранение информации, к которой редко обращаются. Идеальным примером служит необходимость хранения бекапов на удалённой площадке. В Veeam Backup & Replication эта функция называется Capacity Tier.
Начнём настройку с добавления нашего Dell ECS CE в интерфейс Veeam. На вкладке Backup Infrastructure запускаем мастер добавления нового репозитория и выбираем пункт Object Storage.
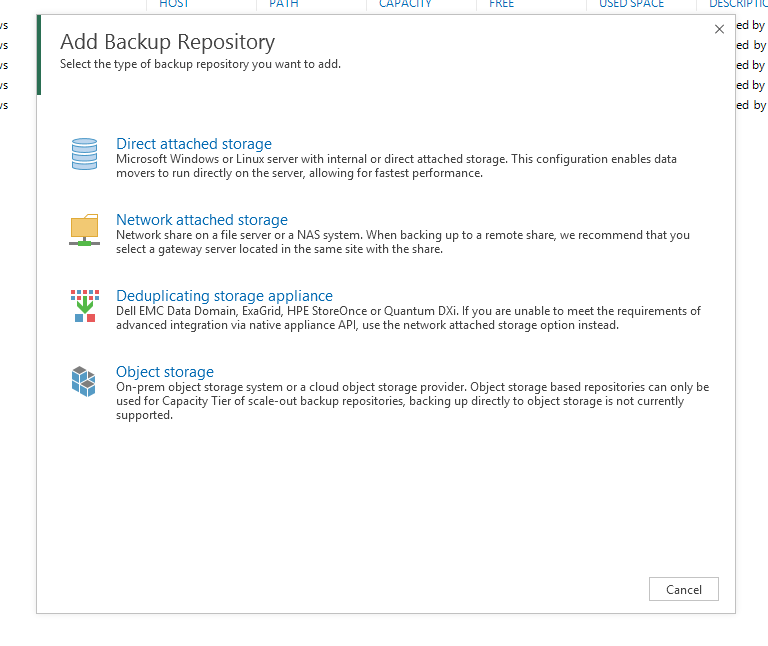
Выбираем то, ради чего всё затевалось — S3 Compatible.
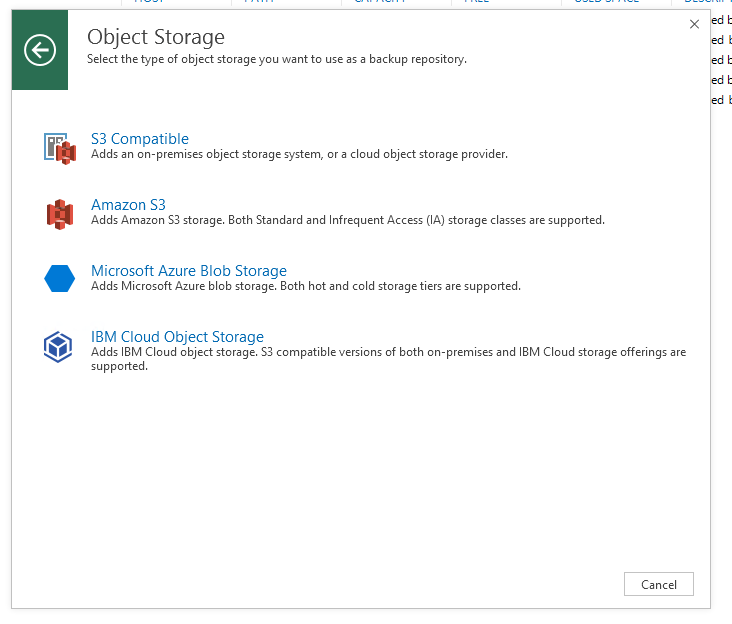
В появившемся окошке пишем желаемое имя и переходим на шаг Account. Здесь надо указать Service point в виде https://your_IP:9021, регион можно оставить как есть, и добавить созданного пользователя. Гейт-сервер необходим, если ваше хранилище находится на удалённой площадке, но это уже тема оптимизации инфраструктуры и отдельной статьи, так что здесь можно смело пропустить.

Если всё указано и настроено верно, вылезет предупреждение о сертификате и затем окно с бакетом, где можно создать папку для наших файлов.
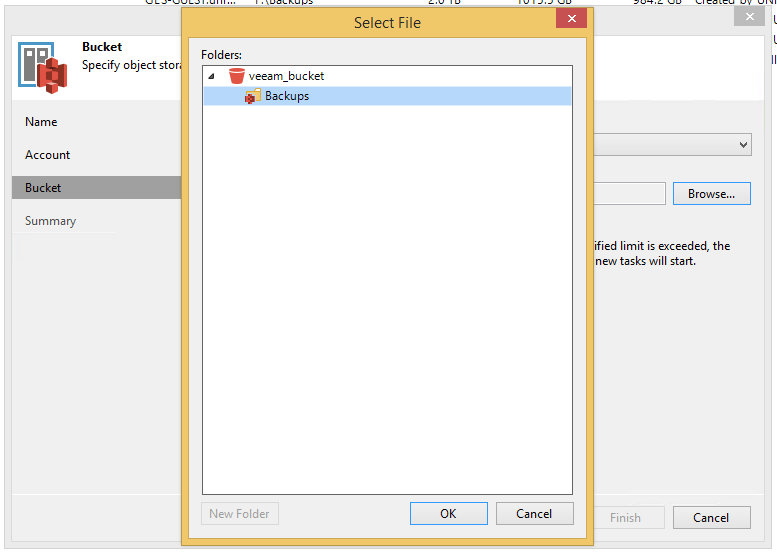
Проходим визард до конца и наслаждаемся результатом.
На следующем шаге нужно или создать новый Scale-out Backup Repository, или добавить наш S3 в существующий — он будет использован в качестве Capacity Tier для архивного хранения. Функции использовать S3-совместимые хранилища напрямую, как обычный репозиторий, в текущем релизе нет. Слишком много довольно неочевидных проблем для этого надо решить, но всё может быть.
Заходим в настройки репозитория и включаем Capacity Tier. Там всё прозрачно, но есть интересный нюанс: если хочется, чтобы все данные в кратчайшие сроки отправлялись на объектное хранилище, просто установите 0 дней.

После прохождения визарда, если не хочется ждать, можно нажать ctrl+ПКМ на репозитории, принудительно запустить Tiering job и наблюдать, как поползут графики.
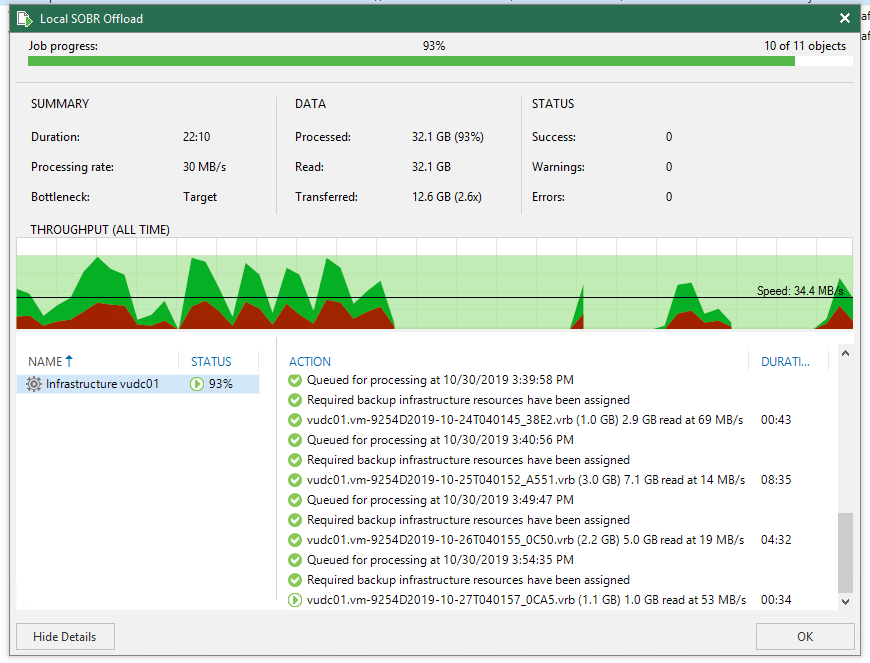
На этом пока всё. Считаю, с задачей показать, что блочные хранилища — это не так страшно, как принято думать, я справился. Да, решений и вариантов исполнения вагон и маленькая тележка, но за одну статью всего не охватить. Поэтому давайте делиться опытом в комментариях.
