
8 мая состоялся первый квалификационный раунд всероссийского кубка по программированию Russian Code Cup. Победителем раунда стал Евгений Капун, который решил все 5 задач со штрафным временем 130 минут.
Всего в первом квалификационном раунде приняли участие 756 человек. Лучшие 200 участников по результатам раунда были допущены к участию в отборочном раунде, который состоится в 19 июня.
14 и 15 мая состоятся 2-й и 3-й квалификационные раунды, на которых будут отобраны еще 400 человек.
В этой статье мы проанализируем различную статистику первого этапа RCC, проведем разбор задач и ответим на наиболее часто задаваемые вопросы, которые поступили во время тура.
Для решения участникам жюри предложило 5 задач. Хотя бы одну задачу решил 691 участник. Самой простой оказалась задача A, ее решили 685 участников. В целом правильные решения распределились по задачам следующим образом:

Диаграмма 1. Количество правильных решений по задачам.
Как видно из диаграммы, задачи A, B и C покорились большинству участников, а вот D и E оказались гораздо сложнее. Эти задачи и стали ключом к успешной квалификации — решение трех простых задач и хотя бы одной из двух сложных, гарантировали проход в отборочный тур — всего 87 участников справились с четырьмя и более задачами.
А вот участникам с тремя решенными задачами необходимо было продемонстрировать высокую скорость решения задач. «Отсечка» двухсотого места прошла по штрафному времени: для прохода в отборочный тур с тремя задачами необходимо было иметь штрафное время не больше 141, то есть тратить на задачу в среднем 23.5 минуты.

Диаграмма 2. Количество участников в зависимости от числа решенных задач.
Наибольшее число попыток было сделано по задаче B: 1952, при этом лишь 461 из них, то есть около 24% были успешными. В целом процент успешных попыток по задачам выглядит так:
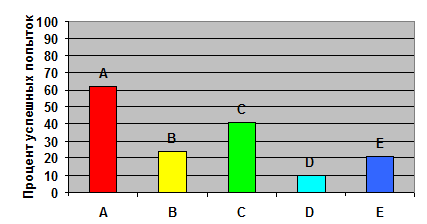
Диаграмма 3. Процент успешных попыток по задачам.
Видно, что хотя задачу C решили меньше участников, она доставила им меньше проблем, чем B. Аналогично более сложная задача E содержала меньше «подводных камней», чем задача D.
Интересно посмотреть статистику по языкам программирования, которые были использованы участниками Russian Code Cup. Если перенести суммарное количество на круговую диаграмму, получается следующая картина:
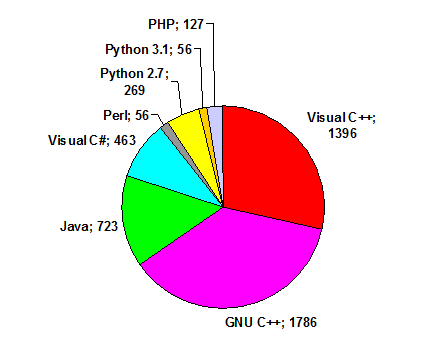
Диаграмма 4. Количество решений в зависимости от языка программирования.
С довольно большим отрывом лидирует GNU C, Java и C# суммарно занимают примерно втрое меньше, на остальных языках было сделано еще меньше подходов.
Интересно, что пятую задача, в которой требовалась длинная арифметика, в основном решали на языке Java:
В целом распределение отправленных решений по минутам соревнования можно посмотреть на следующем графике:
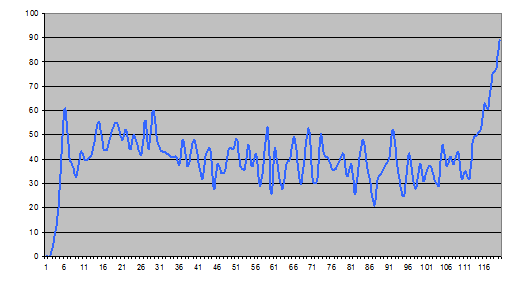
График 4. Количество подходов в зависимости от минуты соревнования.
Видно, что на первых минутах участники читали задачи, затем произошел резкий всплеск, когда основная масса сильных участников справилась с первой задачей, небольшой спад, и дальше количество подходов колебалось от 30 до 50 в минуту, с всплеском почти до 90 в конце раунда. При этом, если в начале соревнования в основном на проверку отправлялись правильные решения, то ближе к концу доля правильных решений неуклонно снижалась. На следующем графике приведена зависимость доли правильных решений среди отправленных на проверку, в зависимости от минуты соревнования.
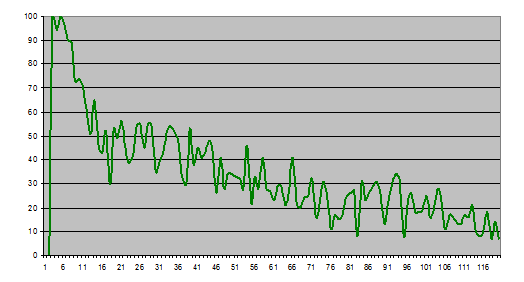
График 5. Доля успешных подходов в зависимости от минуты соревнования.
Разбор задач
Задача А. Конкатенация строк
Во многих прикладных задачах необходимо осуществлять различные операции со строками. Две достаточно часто встречающиеся операции — это разворот строки и конкатенация двух или нескольких строк.
В результате разворота строки s получается строка sR, которая состоит из тех же символов, что и s, но идущих в обратном порядке. Например, в результате разворота строки “abcde” получается строка “edcba”. Далее в этой задаче вместо обозначения sR будет использоваться обозначение (s).
В результате конкатенации двух строк s и t получается строка st, в которой сначала записаны символы строки s, а затем — символы строки t. Аналогичным образом определяется конкатенация трех, четырех и большего числа строк. Например, при конкатенации строк “abc” и “cda” получается строка “abccda”
Ваша задача — определить результат конкатенации нескольких строк, часть из которых необходимо развернуть.
Формат входных данных
Входные данные состоят из единственной строки, которая содержит только строчные буквы латинского алфавита и круглые скобки. Ее длина не превышает 200 символов. Эта строка описывает конкатенацию нескольких строк, часть из которых необходимо развернуть.
В заданной строке правее каждой открывающей скобки есть закрывающая, левее каждой закрывающей есть открывающая, причем между соответствующими друг другу открывающей и закрывающей скобками других скобок нет и обязательно есть хотя бы одна буква.
Формат выходных данных
Выведите результат конкатенации.
Решение
Эта задача была самой простой на соревновании. Ограничения очень маленькие и можно решать задачу любым разумным способом. Например, считать строку, разбить ее на фрагменты, используя в качестве разделителей круглые скобки и развернуть все четные блоки. В языках во встроенной обработкой регулярных выражений (например, Perl) решение этой задачи вообще выглядит особенно компактно и естественно.
Мы приведем решение этой задачи на всех языках программирования, доступных на Russian Code Cup. Заодно обратим внимание на то, как считывать данные со стандартного потока ввода — многие участники задавали во время соревнования вопрос о том, откуда брать входные данные.
Мы не претендуем на оптимальность решений и даже наоборот, постарались на разных языках привести немного разные решения.
Java:
C++:
C#:
Perl:
Python
PHP
Обратите внимание, что решение этой задачи оказалось особенно простым и компактным на языках Perl и PHP.
Задача B. Тарифы
В настоящее время практически каждый оператор сотовой связи имеет обширный набор тарифов, которые позволяют каждому человеку выбрать наиболее подходящий для себя. К сожалению, зачастую осуществить этот выбор вручную очень тяжело.
У одного из сотовых операторов каждый тариф характеризуется тремя числами: абонентная плата ci (задается в рублях), минимальная тарифицируемая единица времени ti (задается в секундах), стоимость минимальной тарифицируемой единицы времени pi (задается в копейках, в одном рубле 100 копеек). Суммарная стоимость вызовов за месяц складывается из абонентной платы и стоимостей каждого из исходящих вызовов. Стоимость вызова при использовании i-ого тарифа вычисляется следующим образом: пусть время разговора равно T секунд. Если T < ti, то стоимость вызова равна нулю. Иначе стоимость вызова равна произведению k на pi, где k — минимальное целое число, такое что k•ti ≥ T.
Задано описание тарифов и статистика исходящих вызовов абонента в течение месяца — их число m и длительности d1, ..., dm в секундах. Необходимо найти тариф, при котором суммарная стоимость этих вызовов была бы минимальной.
Формат входных данных
Первая строка содержит два целых числа n и m — соответственно количество тарифов и исходящих вызовов абонента (1 ≤ n, m ≤ 100). Каждая из последующих n строк описывает один тариф и содержит три целых числа: ci (0 ≤ ci ≤ 100), ti (1 ≤ ti ≤ 3600), pi (0 ≤ pi ≤ 1000).
Последняя строка содержит m целых чисел d1, ..., dm (1 ≤ di ≤ 3600 для всех i от 1 до m).
Формат выходных данных
Выведите одно число — номер тарифа, при использовании которого суммарная стоимость исходящих вызовов абонента за рассматриваемый месяц минимальна. Тарифы нумеруются целыми числами от 1 до n в том порядке, в котором они заданы во входном файле. Если таких тарифов несколько, выведите номер любого из них.
Решение
Эта задача проверяла участников на внимательность при чтении условия. Основных «тонких» момента в этой задаче два: абонентная плата задается в рублях, а стоимость вызова в копейках, а также особенности округления времени разговора: разговор меньше одной тарифицируемой единицы округляется до нуля, а разговор сверх одной тарифицируемой единицы округляется вверх.
Если заметить эти два момента, то решение заключается в непосредственной реализации подсчета стоимости разговоров на каждом из заданных тарифов и выборе оптимального из них.
Задача C. K-cортировка
Задача сортировки состоит в упорядочивании заданного массива чисел (или других объектов) по возрастанию или убыванию. У этой задачи существует достаточно многих вариантов, для многих из которых существуют весьма эффективные алгоритмы. Одним из важных параметров этих алгоритмов является число обменов элементов массива, необходимых для упорядочивания.
Далее будем рассматривать вариант сортировки, который мы будем называть k-сортировкой. В этом варианте разрешается за одну операцию (называемую k-обменом) поменять местами значения двух элементов массива с номерами, отличающимися ровно на k. Например, если исходный массив имеет вид [6, 10, 4, 1, 2], а k = 3, то этот массив можно упорядочить по возрастанию за две операции (после первого обмена массив будет иметь вид [1, 10, 4, 6, 2], а после второго — [1, 2, 4, 6, 10]).
Задан массив целых чисел a1, ..., an. Ваша задача состоит в том, чтобы определить минимальное число k-обменов, необходимое для упорядочивания этого массива по не убыванию.
Формат входных данных
Первая строка содержит целое число n (1 ≤ n ≤ 300). Вторая строка содержит n целых чисел a1, ..., an (1 ≤ ai ≤ 109 для всех i от 1 до n). Третья строка содержит целое число k (1 ≤ k ≤ n — 1).
Формат выходных данных
Если заданный массив можно упорядочить по неубыванию с использованием операций описанного типа, то выведите минимальное число k-обменов, необходимое для сортировки. Иначе, выведите одно число -1.
Решение
Разделим массив на k частей, в зависимости от остатка позиции по модулю k. В каждой из этих частей соседние элементы находятся на расстоянии k, поэтому их можно обменять между собой. Элементы же из различных частей массива обменять между собой невозможно.
Заметим, что в отсортированном массиве каждая из частей также будет отсортирована. Следовательно, наша задача свелась к следующей: отсортировать каждую из частей за минимальное количество действий и проверить, что получившийся массив оказался отсортированным. Если это так, то ответ — суммарное количество действий, необходимых для сортировки частей. Если массив получился неупорядоченным, то решения не существует.
Осталось понять, какое минимальное количество действий необходимо для сортировки массива, если разрешается выполнять обмен только соседних элементов (а именно такими операциями мы должны отсортировать каждую из частей). Оказывается, минимальное количество действий выполняет обычная сортировка пузырьком. Пусть n — длина массива a[0..n – 1], который требуется отсортировать. Тогда искомое количество обменов выполняет следующий алгоритм:
Докажем это: для этого рассмотрим следующую характеристику массива, которая называется количеством инверсий: количество пар позиций (i, j), где i < j и a[i] > a[j]. Ясно, что в отсортированном массиве количество инверсий равно нулю. С другой стороны обмен двух соседних элементов может поменять количество таких пар не более чем на единицу. При этом сортировка пузырьком при каждом обмене уменьшает количество инверсий на единицу.
Следовательно количество обменов в сортировке пузырьком равно количеству инверсий в массиве, то есть минимальному количеству обменов, которое необходимо осуществить для сортировки массива.
Задача D. Рельсы
Важным параметром железной дороги является ширина колеи — расстояние между двумя рельсами, по которым едет поезд. Именно этот параметр определяет типы поездов и других машин, которые могут ездить по железной дороге.
Недавно космическая экспедиция на планету RCC-0805 выяснила, что железные дороги есть и на этой планете. Было даже найдено железнодорожное депо, однако определить ширину колеи пока не удалось. Дело в том, что железные дороги на этой планете укладывались без шпал, поэтому определить, какие рельсы друг другу соответствуют не всегда просто.
Задан план расположения рельсов на территории железнодорожного депо. Для простоты будем считать, что территория представляет собой бесконечную плоскость, а каждый рельс представлен в виде прямой. Необходимо найти минимальную ширину колеи d, при которой рельсы можно разбить на пары так, что в каждой паре они параллельны и расстояние между ними равно d.
Формат входных данных
Первая строка содержит целое число n (1 ≤ n ≤ 2000). Каждая из последующих 2n строк содержит по четыре целых числа xi, 1, yi, 1, xi, 2, yi, 2 — координаты двух различных точек, через которые проходит рельс. Все координаты не превосходят 1000 по абсолютной величине. Прямые, соответствующие различным рельсам, не совпадают.
Формат выходных данных
Выведите вещественное число — минимальную возможную ширину колеи. Она должна быть определена с точностью не хуже 10-6.
Если ни при одной ширине колеи разбить рельсы на пары с выполнением требований задачи невозможно, выведите число −1.
Решение.
Сначала разобьем рельсы на классы эквивалентности по направлению прямой — параллельные прямые попадут в один класс. После этого в каждом классе найдем все возможные допустимые значения ширины колеи для данного класса. Ответом является минимальное возможное расстояние, которое подходит для всех классов.
Теперь рассмотрим подробнее каждый из этапов решения.
Для распределения прямых по классам эквивалентности построим уравнение каждой из прямых. Пусть прямая проходит через точки (x1, y1), (x2, y2). Тогда ее уравнение вида ax + by + c = 0 можно найти следующим образом: a = y1 – y2, b = x2 – x1, c = –(ax1 + by1). Теперь полезно нормировать коэффициенты прямой, поделив a, b и c на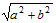 . Теперь у каждой прямой есть два представления: с точностью до умножения коэффициентов на –1. Чтобы у каждой прямой было единственное уравнение, удобно потребовать дополнительно условия «a > 0 or (a = 0 and b > 0)». При выполнении этого требования параллельные прямые имеют одинаковую пару (a, b). В таком представлении также удобно вычислять расстояние между прямыми: для двух параллельных прямых ax + by + c1 = 0 и ax + by + c2 = 0 расстояние равно |c1 – c2|.
. Теперь у каждой прямой есть два представления: с точностью до умножения коэффициентов на –1. Чтобы у каждой прямой было единственное уравнение, удобно потребовать дополнительно условия «a > 0 or (a = 0 and b > 0)». При выполнении этого требования параллельные прямые имеют одинаковую пару (a, b). В таком представлении также удобно вычислять расстояние между прямыми: для двух параллельных прямых ax + by + c1 = 0 и ax + by + c2 = 0 расстояние равно |c1 – c2|.
Рассмотрим класс параллельных прямых. Отсортируем их по коэффициенту c. Рассмотрим первую прямую — она находится в паре с одной из других прямых этого класса. Переберем эту прямую. Пусть расстояние между ними равно d. Теперь жадно построим разбиение прямых на пары находящихся на расстоянии d. Если это удастся сделать, то d может быть шириной колеи для данного класса. Будем рассматривать прямые в порядке возрастания c. Если у очередной прямой c = ci и еще нет пары, то она ей должны быть параллельна прямая на расстоянии d с c = ci + d. Если такая прямая есть, объединяем ее в пару с рассматриваемой прямой. Разбиение на пары можно реализовать за линейное время, используя метод двух указателей: достаточно заметить, что c + d при увеличении c также увеличивается.
Наконец, рассмотрим поиск ответа: пусть имеются списки возможных ответов для каждого из классов. Естественным образом они оказываются отсортированы по возрастанию. Два таких списка можно легко пересечь за один проход. Выполнив пересечение всех списков, мы за время, пропорциональное сумме их длин, получим список-пересечение, минимальный элемент которого и является ответом на задачу.
Проанализируем время работы алгоритма. Распределение по классам выполняется за O(n). Для данного класса размера k построение списка допустимых расстояний выполняется за O(k2) и его длина не превышает k. Следовательно последний шаг выполняется за O(n), а весь алгоритм за O(n2).
Задача E. Угадай число
Недавно в одной популярной социальной сети появилось приложение «Угадай число!». Его пользователям предлагается игра, на каждом из уровней которой необходимо определить загаданное число по некоторой информации о нем.
В частности, на одном из самых сложных уровней необходимо угадать рациональное число x (0 < x < 1), о котором известно, что в результате умножения на натуральное число k в его десятичной записи произошло ровно одно изменение — в ней поменялись местами i-ая и j-ая цифры после десятичной точки (цифры нумеруются с единицы в направлении слева направо). При этом цифра до десятичной точки не изменилась, то есть выполнено неравенство 0 < kx < 1. Отметим, что исходно в десятичной записи x может быть бесконечно много знаков после десятичной точки.
Ваша задача состоит в том, чтобы написать программу, которая будет определять значение x по числам i, j, k.
Формат входных данных
Первая строка содержит три целых числа i, j, k (1 ≤ i < j ≤ 1000; 2 ≤ k ≤ 109).
Формат выходных данных
Если искомое число существует, то выведите два целых числа — числитель a и знаменатель b несократимой дроби, задающей искомое число (a, b > 0). В противном случае выведите фразу NO SOLUTION.
Решение
Пусть исходно на i-й позиции стоит цифра s, а на j-й — цифра t. Тогда после умножения на k число оказывается равно x – 10–is + 10–i t – 10–i t + 10–i s. Следовательно искомое число является решением уравнения kx = x – 10–i s + 10–i t – 10–i t + 10–i s.
Заметим, что на самом деле решение не зависит от конкретных значений s и t, а только от их разности: (k – 1) x = (10–i – 10–i) (t – s). Кроме того, s < t. Поэтому достаточно перебирать разность (t – s) в диапазоне от 1 до 9. Для каждого значения разности находим решение уравнения и проверяем его: убеждаемся, что действительно при умножении числа на k цифры на i-й и j-й позициях в десятичной записи меняются местами, а целая часть остается равной нулю.
Проверка необходима, поскольку из-за переносов решение приведенного уравнения может не соответствовать решению задачи.
Ответы на часто задаваемые вопросы
Во время соревнования участники могли отправлять вопросы жюри. Некоторые вопросы встречались особенно часто, и мы решили дать на них ответ в этой статье.
Вопрос: следует отправлять на проверку исходный код или скомпилированный файл?
Ответ: отправлять на проверку следует исходный код. Проверяющая система сама компилирует решение участника, командные строки указаны в правилах Russian Code Cup
Вопрос: откуда следует вводить данные?
Ответ: данные следует вводить с так называемого стандартного потока ввода. Это соответствует вводу с клавиатуры, если запустить программу, читающие данные со стандартного потока ввода, без дополнительных параметров, то ввод будет осуществляться с клавиатуры.
При этом низкоуровневый ввод с клавиатуры, наподобие анализа нажатых клавиш или получение сообщений операционной системы о нажатии клавиш — неправильный подход. Читать следует «с консоли».
Вопрос: куда следует вводить ответ?
Ответ надо выводить на стандартный поток вывода (по-умолчанию он направляется на экран). Опять же не следует пытаться делать это низкоуровневыми средствами.
Приведем примеры чтения стандартного потока ввода и записи в стандартный поток вывода на всех языках программирования, которые поддерживаются на Russian Code Cup.
Java
Для ввода следует использовать поток System.in. Наиболее удобным средствами для разбора ввода на Java являются классы BufferedReader и Scanner. BufferedReader быстрее в чтении и позволяет быстро считать по строкам большой объем данных. Scanner медленнее из-за использования регулярных выражений, но позволяет очень гибко разобрать входную строку, например, считывать по одному числа из ввода.
Для чтения из стандартного потока ввода с помощью BufferedReader следует написать в программе строку:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
Для чтения из стандартного потока ввода с помощью Scanner следует написать в программе строку:
Scanner in = new Scanner(System.in);
Для вывода следует использовать System.out. При этом System.out является некеширующим (сразу сбрасывает свой буфер), если следует вывести большой объем информации, лучше обернуть его в PrintWriter.
С++
Для ввода в стиле классического C можно использовать scanf. Эта функция читает данные как раз со стандартного потока ввода.
Ввод через потоки осуществляется с помощью потока cin. По-умолчанию он настроен на стандартный поток ввода. Обратите внимание, что ввод с помощью потоков существенно медленнее ввода с помощью scanf, поэтому большие объемы данных программа может не успеть считать.
Для вывода опять же можно воспользоваться классическим printf или потоковым cout. Все замечания о производительности остаются в силе и для них — printf быстрее.
C#
Для ввода следует использовать Console. Console.ReadLine() читает очередную строку ввода. Для ее разбора следует использовать метод split(). Превращение данных в числа осуществляет класс Convert.
Для вывода также следует использовать Console. Например, для вывода числа x можно написать Console.WriteLine(x).
Python
Для ввода можно использовать функции input или raw_input. Также можно использовать файловый дескриптор sys.stdin, который настроен на стандартный поток ввода.
Для вывода рекомендуем использовать print.
Perl
Ввод со стандартного ввода в Perl осуществляется командой <>. Эта команда считывает строку из файла и возвращает ее.
Для вывода рекомендуем использовать print.
PHP
Ввод со стандартного ввода в PHP осуществляется из дескриптора STDIN. Очередную строку можно считать, например, командой fgets.
Для вывода можно использовать print или echo.
При использовании различных функций чтения строки мы также рекомендуем внимательно прочитать документацию и обратить внимание, возвращает ли функция перевод строки вместе со строкой. В тестах жюри все строки, включая последнюю, заканчиваются переводом строки, тестирование ведется под ОС Windows 7, используется принятая в Windows комбинация для перевода строки, состоящая из символов с кодами 13 и 10.
Кроме того, следует обратить внимание, что тестирование производится автоматически. Поэтому не следует пытаться выводить различные «приглашения ко вводу» или пытаться «украсить» вывод. Следует ввести данные, решить задачу и вывести данные, четко следуя формату вывода.
Вопрос: правильный ли тест в примере?
Ответ: тест в примере обычно правильный — его проверяют несколько человек, в том числе несколько человек прорешивают задачи, не зная их заранее. Если вам кажется, что тест примере неправильный, то прочитайте более внимательно условие, вероятно вы что-то понимаете неправильно.
Если вам все еще кажется, что пример неправильный, включите в запрос подробное описание, почему вы считаете пример неправильным, какой ответ правильный, в чем по-вашему неточность или неоднозначность.
Вопрос: правильный ли 239-й тест в задаче X?
Ответ: скорее всего тест правильный. Если вы считаете, что тест неправильный, напишите, почему вы так считаете. Просто вопрос «правильный ли такой-то тест» бессмысленно задавать. В процессе соревнования жюри внимательно следит за происходящим и если на каком-то тесте многие выдают отличный от жюри ответ или «падают» с какой-то специфичной ошибкой, то этот тест внимательно исследуется.
Вопрос: если несколько правильных ответов, какой выводить?
Ответ: если возможно несколько правильных выводов на некоторый тест, выводить следует любой.
Желаем успехов участникам следующих туров!
Команда Russian Code Cup
Всего в первом квалификационном раунде приняли участие 756 человек. Лучшие 200 участников по результатам раунда были допущены к участию в отборочном раунде, который состоится в 19 июня.
14 и 15 мая состоятся 2-й и 3-й квалификационные раунды, на которых будут отобраны еще 400 человек.
В этой статье мы проанализируем различную статистику первого этапа RCC, проведем разбор задач и ответим на наиболее часто задаваемые вопросы, которые поступили во время тура.
Для решения участникам жюри предложило 5 задач. Хотя бы одну задачу решил 691 участник. Самой простой оказалась задача A, ее решили 685 участников. В целом правильные решения распределились по задачам следующим образом:

Диаграмма 1. Количество правильных решений по задачам.
Как видно из диаграммы, задачи A, B и C покорились большинству участников, а вот D и E оказались гораздо сложнее. Эти задачи и стали ключом к успешной квалификации — решение трех простых задач и хотя бы одной из двух сложных, гарантировали проход в отборочный тур — всего 87 участников справились с четырьмя и более задачами.
А вот участникам с тремя решенными задачами необходимо было продемонстрировать высокую скорость решения задач. «Отсечка» двухсотого места прошла по штрафному времени: для прохода в отборочный тур с тремя задачами необходимо было иметь штрафное время не больше 141, то есть тратить на задачу в среднем 23.5 минуты.
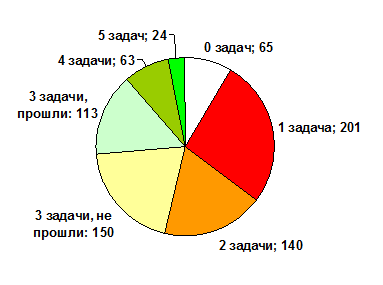
Диаграмма 2. Количество участников в зависимости от числа решенных задач.
Наибольшее число попыток было сделано по задаче B: 1952, при этом лишь 461 из них, то есть около 24% были успешными. В целом процент успешных попыток по задачам выглядит так:

Диаграмма 3. Процент успешных попыток по задачам.
Видно, что хотя задачу C решили меньше участников, она доставила им меньше проблем, чем B. Аналогично более сложная задача E содержала меньше «подводных камней», чем задача D.
Интересно посмотреть статистику по языкам программирования, которые были использованы участниками Russian Code Cup. Если перенести суммарное количество на круговую диаграмму, получается следующая картина:
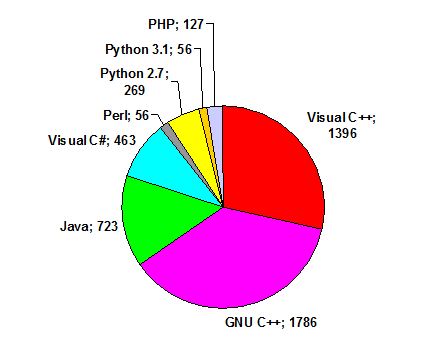
Диаграмма 4. Количество решений в зависимости от языка программирования.
С довольно большим отрывом лидирует GNU C, Java и C# суммарно занимают примерно втрое меньше, на остальных языках было сделано еще меньше подходов.
Интересно, что пятую задача, в которой требовалась длинная арифметика, в основном решали на языке Java:
В целом распределение отправленных решений по минутам соревнования можно посмотреть на следующем графике:
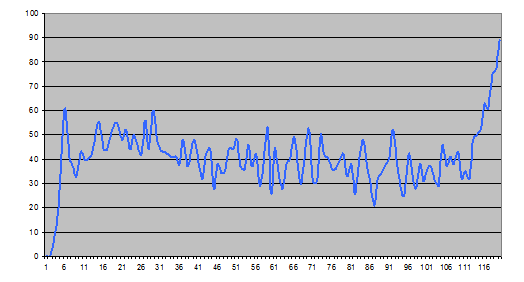
График 4. Количество подходов в зависимости от минуты соревнования.
Видно, что на первых минутах участники читали задачи, затем произошел резкий всплеск, когда основная масса сильных участников справилась с первой задачей, небольшой спад, и дальше количество подходов колебалось от 30 до 50 в минуту, с всплеском почти до 90 в конце раунда. При этом, если в начале соревнования в основном на проверку отправлялись правильные решения, то ближе к концу доля правильных решений неуклонно снижалась. На следующем графике приведена зависимость доли правильных решений среди отправленных на проверку, в зависимости от минуты соревнования.

График 5. Доля успешных подходов в зависимости от минуты соревнования.
Разбор задач
Задача А. Конкатенация строк
Во многих прикладных задачах необходимо осуществлять различные операции со строками. Две достаточно часто встречающиеся операции — это разворот строки и конкатенация двух или нескольких строк.
В результате разворота строки s получается строка sR, которая состоит из тех же символов, что и s, но идущих в обратном порядке. Например, в результате разворота строки “abcde” получается строка “edcba”. Далее в этой задаче вместо обозначения sR будет использоваться обозначение (s).
В результате конкатенации двух строк s и t получается строка st, в которой сначала записаны символы строки s, а затем — символы строки t. Аналогичным образом определяется конкатенация трех, четырех и большего числа строк. Например, при конкатенации строк “abc” и “cda” получается строка “abccda”
Ваша задача — определить результат конкатенации нескольких строк, часть из которых необходимо развернуть.
Формат входных данных
Входные данные состоят из единственной строки, которая содержит только строчные буквы латинского алфавита и круглые скобки. Ее длина не превышает 200 символов. Эта строка описывает конкатенацию нескольких строк, часть из которых необходимо развернуть.
В заданной строке правее каждой открывающей скобки есть закрывающая, левее каждой закрывающей есть открывающая, причем между соответствующими друг другу открывающей и закрывающей скобками других скобок нет и обязательно есть хотя бы одна буква.
Формат выходных данных
Выведите результат конкатенации.
Решение
Эта задача была самой простой на соревновании. Ограничения очень маленькие и можно решать задачу любым разумным способом. Например, считать строку, разбить ее на фрагменты, используя в качестве разделителей круглые скобки и развернуть все четные блоки. В языках во встроенной обработкой регулярных выражений (например, Perl) решение этой задачи вообще выглядит особенно компактно и естественно.
Мы приведем решение этой задачи на всех языках программирования, доступных на Russian Code Cup. Заодно обратим внимание на то, как считывать данные со стандартного потока ввода — многие участники задавали во время соревнования вопрос о том, откуда брать входные данные.
Мы не претендуем на оптимальность решений и даже наоборот, постарались на разных языках привести немного разные решения.
Java:
import java.io.*;
public class concat_as {
public static void main(String[] args) throws IOException {
BufferedReader in = new BufferedReader(
new InputStreamReader(System.in));
String[] s = in.readLine().split("[()]");
for (int i = 0; i < s.length; i++) {
if (i % 2 == 0) {
System.out.print(s[i]);
} else {
System.out.print(new StringBuilder(s[i]).reverse());
}
}
}
}
C++:
#include <string>
#include <iostream>
#include <algorithm>
using namespace std;
int main ()
{
string s;
cin >> s;
int l = 0;
while (l < s.length()) {
if (s[l] == '(') {
int r = l;
while (s[r] != ')')
r++;
string tmp = s.substr(l + 1, r - l - 1);
reverse(tmp.begin(), tmp.end());
cout << tmp;
l = r + 1;
} else {
cout << s[l];
l++;
}
}
return 0;
}
C#:
using System;
using System.Linq;
class concat_as
{
static void Main(string[] args)
{
string s = Console.ReadLine();
int L, R;
do {
L = s.IndexOf("(");
R = s.IndexOf(")");
if (L >= 0) {
Console.Write(s.Substring(0, L));
Console.Write(new string(
s.Substring(L + 1, R - L - 1).Reverse().ToArray()));
s = s.Substring(R + 1);
}
} while (L >= 0);
Console.WriteLine(s);
}
}
Perl:
$s = <>;
$s =~ s/\(([^)]*)\)/reverse($1)/eg;
print $s
Python
s = raw_input()
ans = ''
for t in s.split('('):
if ')' in t:
l = t.split(')')
ans += l[0][::-1] + l[1]
else:
ans += t
print ans
PHP
<?php
$s = trim(fgets(STDIN));
$s = preg_replace('#\((\w+)\)#se', 'strrev("\1")', $s);
echo "$s\n";
?>
Обратите внимание, что решение этой задачи оказалось особенно простым и компактным на языках Perl и PHP.
Задача B. Тарифы
В настоящее время практически каждый оператор сотовой связи имеет обширный набор тарифов, которые позволяют каждому человеку выбрать наиболее подходящий для себя. К сожалению, зачастую осуществить этот выбор вручную очень тяжело.
У одного из сотовых операторов каждый тариф характеризуется тремя числами: абонентная плата ci (задается в рублях), минимальная тарифицируемая единица времени ti (задается в секундах), стоимость минимальной тарифицируемой единицы времени pi (задается в копейках, в одном рубле 100 копеек). Суммарная стоимость вызовов за месяц складывается из абонентной платы и стоимостей каждого из исходящих вызовов. Стоимость вызова при использовании i-ого тарифа вычисляется следующим образом: пусть время разговора равно T секунд. Если T < ti, то стоимость вызова равна нулю. Иначе стоимость вызова равна произведению k на pi, где k — минимальное целое число, такое что k•ti ≥ T.
Задано описание тарифов и статистика исходящих вызовов абонента в течение месяца — их число m и длительности d1, ..., dm в секундах. Необходимо найти тариф, при котором суммарная стоимость этих вызовов была бы минимальной.
Формат входных данных
Первая строка содержит два целых числа n и m — соответственно количество тарифов и исходящих вызовов абонента (1 ≤ n, m ≤ 100). Каждая из последующих n строк описывает один тариф и содержит три целых числа: ci (0 ≤ ci ≤ 100), ti (1 ≤ ti ≤ 3600), pi (0 ≤ pi ≤ 1000).
Последняя строка содержит m целых чисел d1, ..., dm (1 ≤ di ≤ 3600 для всех i от 1 до m).
Формат выходных данных
Выведите одно число — номер тарифа, при использовании которого суммарная стоимость исходящих вызовов абонента за рассматриваемый месяц минимальна. Тарифы нумеруются целыми числами от 1 до n в том порядке, в котором они заданы во входном файле. Если таких тарифов несколько, выведите номер любого из них.
Решение
Эта задача проверяла участников на внимательность при чтении условия. Основных «тонких» момента в этой задаче два: абонентная плата задается в рублях, а стоимость вызова в копейках, а также особенности округления времени разговора: разговор меньше одной тарифицируемой единицы округляется до нуля, а разговор сверх одной тарифицируемой единицы округляется вверх.
Если заметить эти два момента, то решение заключается в непосредственной реализации подсчета стоимости разговоров на каждом из заданных тарифов и выборе оптимального из них.
Задача C. K-cортировка
Задача сортировки состоит в упорядочивании заданного массива чисел (или других объектов) по возрастанию или убыванию. У этой задачи существует достаточно многих вариантов, для многих из которых существуют весьма эффективные алгоритмы. Одним из важных параметров этих алгоритмов является число обменов элементов массива, необходимых для упорядочивания.
Далее будем рассматривать вариант сортировки, который мы будем называть k-сортировкой. В этом варианте разрешается за одну операцию (называемую k-обменом) поменять местами значения двух элементов массива с номерами, отличающимися ровно на k. Например, если исходный массив имеет вид [6, 10, 4, 1, 2], а k = 3, то этот массив можно упорядочить по возрастанию за две операции (после первого обмена массив будет иметь вид [1, 10, 4, 6, 2], а после второго — [1, 2, 4, 6, 10]).
Задан массив целых чисел a1, ..., an. Ваша задача состоит в том, чтобы определить минимальное число k-обменов, необходимое для упорядочивания этого массива по не убыванию.
Формат входных данных
Первая строка содержит целое число n (1 ≤ n ≤ 300). Вторая строка содержит n целых чисел a1, ..., an (1 ≤ ai ≤ 109 для всех i от 1 до n). Третья строка содержит целое число k (1 ≤ k ≤ n — 1).
Формат выходных данных
Если заданный массив можно упорядочить по неубыванию с использованием операций описанного типа, то выведите минимальное число k-обменов, необходимое для сортировки. Иначе, выведите одно число -1.
Решение
Разделим массив на k частей, в зависимости от остатка позиции по модулю k. В каждой из этих частей соседние элементы находятся на расстоянии k, поэтому их можно обменять между собой. Элементы же из различных частей массива обменять между собой невозможно.
Заметим, что в отсортированном массиве каждая из частей также будет отсортирована. Следовательно, наша задача свелась к следующей: отсортировать каждую из частей за минимальное количество действий и проверить, что получившийся массив оказался отсортированным. Если это так, то ответ — суммарное количество действий, необходимых для сортировки частей. Если массив получился неупорядоченным, то решения не существует.
Осталось понять, какое минимальное количество действий необходимо для сортировки массива, если разрешается выполнять обмен только соседних элементов (а именно такими операциями мы должны отсортировать каждую из частей). Оказывается, минимальное количество действий выполняет обычная сортировка пузырьком. Пусть n — длина массива a[0..n – 1], который требуется отсортировать. Тогда искомое количество обменов выполняет следующий алгоритм:
for i from 0 to n – 1:
for j from 0 to n – 2:
if a[j] > a[j + 1]:
swap(a[j], a[j + 1])Докажем это: для этого рассмотрим следующую характеристику массива, которая называется количеством инверсий: количество пар позиций (i, j), где i < j и a[i] > a[j]. Ясно, что в отсортированном массиве количество инверсий равно нулю. С другой стороны обмен двух соседних элементов может поменять количество таких пар не более чем на единицу. При этом сортировка пузырьком при каждом обмене уменьшает количество инверсий на единицу.
Следовательно количество обменов в сортировке пузырьком равно количеству инверсий в массиве, то есть минимальному количеству обменов, которое необходимо осуществить для сортировки массива.
Задача D. Рельсы
Важным параметром железной дороги является ширина колеи — расстояние между двумя рельсами, по которым едет поезд. Именно этот параметр определяет типы поездов и других машин, которые могут ездить по железной дороге.
Недавно космическая экспедиция на планету RCC-0805 выяснила, что железные дороги есть и на этой планете. Было даже найдено железнодорожное депо, однако определить ширину колеи пока не удалось. Дело в том, что железные дороги на этой планете укладывались без шпал, поэтому определить, какие рельсы друг другу соответствуют не всегда просто.
Задан план расположения рельсов на территории железнодорожного депо. Для простоты будем считать, что территория представляет собой бесконечную плоскость, а каждый рельс представлен в виде прямой. Необходимо найти минимальную ширину колеи d, при которой рельсы можно разбить на пары так, что в каждой паре они параллельны и расстояние между ними равно d.
Формат входных данных
Первая строка содержит целое число n (1 ≤ n ≤ 2000). Каждая из последующих 2n строк содержит по четыре целых числа xi, 1, yi, 1, xi, 2, yi, 2 — координаты двух различных точек, через которые проходит рельс. Все координаты не превосходят 1000 по абсолютной величине. Прямые, соответствующие различным рельсам, не совпадают.
Формат выходных данных
Выведите вещественное число — минимальную возможную ширину колеи. Она должна быть определена с точностью не хуже 10-6.
Если ни при одной ширине колеи разбить рельсы на пары с выполнением требований задачи невозможно, выведите число −1.
Решение.
Сначала разобьем рельсы на классы эквивалентности по направлению прямой — параллельные прямые попадут в один класс. После этого в каждом классе найдем все возможные допустимые значения ширины колеи для данного класса. Ответом является минимальное возможное расстояние, которое подходит для всех классов.
Теперь рассмотрим подробнее каждый из этапов решения.
Для распределения прямых по классам эквивалентности построим уравнение каждой из прямых. Пусть прямая проходит через точки (x1, y1), (x2, y2). Тогда ее уравнение вида ax + by + c = 0 можно найти следующим образом: a = y1 – y2, b = x2 – x1, c = –(ax1 + by1). Теперь полезно нормировать коэффициенты прямой, поделив a, b и c на
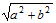 . Теперь у каждой прямой есть два представления: с точностью до умножения коэффициентов на –1. Чтобы у каждой прямой было единственное уравнение, удобно потребовать дополнительно условия «a > 0 or (a = 0 and b > 0)». При выполнении этого требования параллельные прямые имеют одинаковую пару (a, b). В таком представлении также удобно вычислять расстояние между прямыми: для двух параллельных прямых ax + by + c1 = 0 и ax + by + c2 = 0 расстояние равно |c1 – c2|.
. Теперь у каждой прямой есть два представления: с точностью до умножения коэффициентов на –1. Чтобы у каждой прямой было единственное уравнение, удобно потребовать дополнительно условия «a > 0 or (a = 0 and b > 0)». При выполнении этого требования параллельные прямые имеют одинаковую пару (a, b). В таком представлении также удобно вычислять расстояние между прямыми: для двух параллельных прямых ax + by + c1 = 0 и ax + by + c2 = 0 расстояние равно |c1 – c2|.Рассмотрим класс параллельных прямых. Отсортируем их по коэффициенту c. Рассмотрим первую прямую — она находится в паре с одной из других прямых этого класса. Переберем эту прямую. Пусть расстояние между ними равно d. Теперь жадно построим разбиение прямых на пары находящихся на расстоянии d. Если это удастся сделать, то d может быть шириной колеи для данного класса. Будем рассматривать прямые в порядке возрастания c. Если у очередной прямой c = ci и еще нет пары, то она ей должны быть параллельна прямая на расстоянии d с c = ci + d. Если такая прямая есть, объединяем ее в пару с рассматриваемой прямой. Разбиение на пары можно реализовать за линейное время, используя метод двух указателей: достаточно заметить, что c + d при увеличении c также увеличивается.
Наконец, рассмотрим поиск ответа: пусть имеются списки возможных ответов для каждого из классов. Естественным образом они оказываются отсортированы по возрастанию. Два таких списка можно легко пересечь за один проход. Выполнив пересечение всех списков, мы за время, пропорциональное сумме их длин, получим список-пересечение, минимальный элемент которого и является ответом на задачу.
Проанализируем время работы алгоритма. Распределение по классам выполняется за O(n). Для данного класса размера k построение списка допустимых расстояний выполняется за O(k2) и его длина не превышает k. Следовательно последний шаг выполняется за O(n), а весь алгоритм за O(n2).
Задача E. Угадай число
Недавно в одной популярной социальной сети появилось приложение «Угадай число!». Его пользователям предлагается игра, на каждом из уровней которой необходимо определить загаданное число по некоторой информации о нем.
В частности, на одном из самых сложных уровней необходимо угадать рациональное число x (0 < x < 1), о котором известно, что в результате умножения на натуральное число k в его десятичной записи произошло ровно одно изменение — в ней поменялись местами i-ая и j-ая цифры после десятичной точки (цифры нумеруются с единицы в направлении слева направо). При этом цифра до десятичной точки не изменилась, то есть выполнено неравенство 0 < kx < 1. Отметим, что исходно в десятичной записи x может быть бесконечно много знаков после десятичной точки.
Ваша задача состоит в том, чтобы написать программу, которая будет определять значение x по числам i, j, k.
Формат входных данных
Первая строка содержит три целых числа i, j, k (1 ≤ i < j ≤ 1000; 2 ≤ k ≤ 109).
Формат выходных данных
Если искомое число существует, то выведите два целых числа — числитель a и знаменатель b несократимой дроби, задающей искомое число (a, b > 0). В противном случае выведите фразу NO SOLUTION.
Решение
Пусть исходно на i-й позиции стоит цифра s, а на j-й — цифра t. Тогда после умножения на k число оказывается равно x – 10–is + 10–i t – 10–i t + 10–i s. Следовательно искомое число является решением уравнения kx = x – 10–i s + 10–i t – 10–i t + 10–i s.
Заметим, что на самом деле решение не зависит от конкретных значений s и t, а только от их разности: (k – 1) x = (10–i – 10–i) (t – s). Кроме того, s < t. Поэтому достаточно перебирать разность (t – s) в диапазоне от 1 до 9. Для каждого значения разности находим решение уравнения и проверяем его: убеждаемся, что действительно при умножении числа на k цифры на i-й и j-й позициях в десятичной записи меняются местами, а целая часть остается равной нулю.
Проверка необходима, поскольку из-за переносов решение приведенного уравнения может не соответствовать решению задачи.
Ответы на часто задаваемые вопросы
Во время соревнования участники могли отправлять вопросы жюри. Некоторые вопросы встречались особенно часто, и мы решили дать на них ответ в этой статье.
Вопрос: следует отправлять на проверку исходный код или скомпилированный файл?
Ответ: отправлять на проверку следует исходный код. Проверяющая система сама компилирует решение участника, командные строки указаны в правилах Russian Code Cup
Вопрос: откуда следует вводить данные?
Ответ: данные следует вводить с так называемого стандартного потока ввода. Это соответствует вводу с клавиатуры, если запустить программу, читающие данные со стандартного потока ввода, без дополнительных параметров, то ввод будет осуществляться с клавиатуры.
При этом низкоуровневый ввод с клавиатуры, наподобие анализа нажатых клавиш или получение сообщений операционной системы о нажатии клавиш — неправильный подход. Читать следует «с консоли».
Вопрос: куда следует вводить ответ?
Ответ надо выводить на стандартный поток вывода (по-умолчанию он направляется на экран). Опять же не следует пытаться делать это низкоуровневыми средствами.
Приведем примеры чтения стандартного потока ввода и записи в стандартный поток вывода на всех языках программирования, которые поддерживаются на Russian Code Cup.
Java
Для ввода следует использовать поток System.in. Наиболее удобным средствами для разбора ввода на Java являются классы BufferedReader и Scanner. BufferedReader быстрее в чтении и позволяет быстро считать по строкам большой объем данных. Scanner медленнее из-за использования регулярных выражений, но позволяет очень гибко разобрать входную строку, например, считывать по одному числа из ввода.
Для чтения из стандартного потока ввода с помощью BufferedReader следует написать в программе строку:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
Для чтения из стандартного потока ввода с помощью Scanner следует написать в программе строку:
Scanner in = new Scanner(System.in);
Для вывода следует использовать System.out. При этом System.out является некеширующим (сразу сбрасывает свой буфер), если следует вывести большой объем информации, лучше обернуть его в PrintWriter.
С++
Для ввода в стиле классического C можно использовать scanf. Эта функция читает данные как раз со стандартного потока ввода.
Ввод через потоки осуществляется с помощью потока cin. По-умолчанию он настроен на стандартный поток ввода. Обратите внимание, что ввод с помощью потоков существенно медленнее ввода с помощью scanf, поэтому большие объемы данных программа может не успеть считать.
Для вывода опять же можно воспользоваться классическим printf или потоковым cout. Все замечания о производительности остаются в силе и для них — printf быстрее.
C#
Для ввода следует использовать Console. Console.ReadLine() читает очередную строку ввода. Для ее разбора следует использовать метод split(). Превращение данных в числа осуществляет класс Convert.
Для вывода также следует использовать Console. Например, для вывода числа x можно написать Console.WriteLine(x).
Python
Для ввода можно использовать функции input или raw_input. Также можно использовать файловый дескриптор sys.stdin, который настроен на стандартный поток ввода.
Для вывода рекомендуем использовать print.
Perl
Ввод со стандартного ввода в Perl осуществляется командой <>. Эта команда считывает строку из файла и возвращает ее.
Для вывода рекомендуем использовать print.
PHP
Ввод со стандартного ввода в PHP осуществляется из дескриптора STDIN. Очередную строку можно считать, например, командой fgets.
Для вывода можно использовать print или echo.
При использовании различных функций чтения строки мы также рекомендуем внимательно прочитать документацию и обратить внимание, возвращает ли функция перевод строки вместе со строкой. В тестах жюри все строки, включая последнюю, заканчиваются переводом строки, тестирование ведется под ОС Windows 7, используется принятая в Windows комбинация для перевода строки, состоящая из символов с кодами 13 и 10.
Кроме того, следует обратить внимание, что тестирование производится автоматически. Поэтому не следует пытаться выводить различные «приглашения ко вводу» или пытаться «украсить» вывод. Следует ввести данные, решить задачу и вывести данные, четко следуя формату вывода.
Вопрос: правильный ли тест в примере?
Ответ: тест в примере обычно правильный — его проверяют несколько человек, в том числе несколько человек прорешивают задачи, не зная их заранее. Если вам кажется, что тест примере неправильный, то прочитайте более внимательно условие, вероятно вы что-то понимаете неправильно.
Если вам все еще кажется, что пример неправильный, включите в запрос подробное описание, почему вы считаете пример неправильным, какой ответ правильный, в чем по-вашему неточность или неоднозначность.
Вопрос: правильный ли 239-й тест в задаче X?
Ответ: скорее всего тест правильный. Если вы считаете, что тест неправильный, напишите, почему вы так считаете. Просто вопрос «правильный ли такой-то тест» бессмысленно задавать. В процессе соревнования жюри внимательно следит за происходящим и если на каком-то тесте многие выдают отличный от жюри ответ или «падают» с какой-то специфичной ошибкой, то этот тест внимательно исследуется.
Вопрос: если несколько правильных ответов, какой выводить?
Ответ: если возможно несколько правильных выводов на некоторый тест, выводить следует любой.
Желаем успехов участникам следующих туров!
Команда Russian Code Cup
