
С каждым днем в Интернете скапливается все больше и больше информации. И именно благодаря Интернету каждый человек может получить доступ к данным, необходимым именно ему. С другой стороны, ориентироваться в таком большом массиве без использования специальных инструментов практически невозможно. И таким инструментом конечно же становятся поисковые машины, помогающие человеку ориентироваться во все расширяющемся море информации.

С того момента, как поисковые машины сделали свои первые шаги, разработчики тратят огромное количество усилий на совершенствование организации, навигации и поиска документов. Сегодня, наверное, самая используемая техника — это поиск по ключевым словам, дающий пользователям возможность находить информацию по заданной теме. В тоже время, глобальное расширение Интернета приводит к тому, что количество найденной информации, получаемой человеком при поиске с использованием только ключевых слов, слишком велико. Напечатав в поисковой строке одно и тоже слово, разные люди, возможно, хотят получить различные результаты.
На рисунках видно, как выглядит один и тот же запрос, задаваемый пользователями, проживающими в городах Новосибирск и Екатеринбург. Ясно, что спрашивая у поисковой машины слово «аэропорт», люди хотят получить адрес сайта городского аэровокзала:
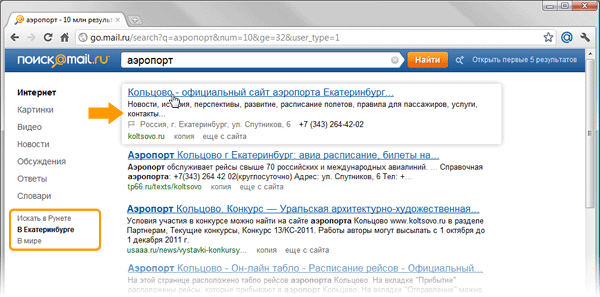
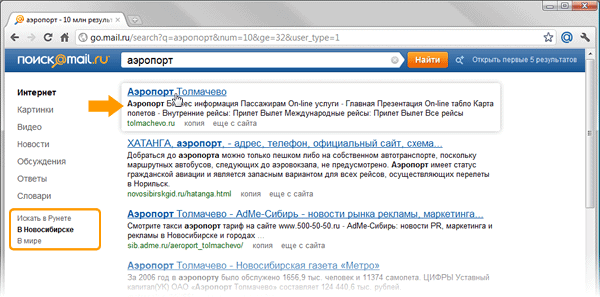
Решить такую задачу, используя поиск по ключевым словам, нельзя. В то же время. он становится отправной точкой формирования высокоуровневых семантических запросов, которые могут использоваться для нахождения такой информации. Таким образом, к странице можно прикрепить дополнительные метаданные, используя которые. повысить качество ответа поисковой машины. Например, для геозависимых запросов такими метаданными будет являться информация о географическом положении ресурса. Зная, где физически находится искомый объект и обладая знаниями о положении пользователя, можно связать эти данные и выдать человеку информацию об искомом объекте.
В общем случае задачу можно разбить на две части:
a) определение местоположения пользователя;
b) определение местоположения искомого ресурса.
В статье мы предлагаем решение второй части задачи, т.е. как определить местоположение интернет-ресурса.
Существует множество источников, откуда можно взять информацию о географии сайта. К ним можно отнести следующие: база WHOIS, каталоги, контекст страниц, и т. д. В нашей статье рассмотрим, как можно привязать сайт к географии на основе анализа контекста страниц.
Как правило, источниками, которые могут поставлять информацию о географии, являются сайты организаций, где публикуются данные о местах их расположения — адреса и телефоны. Решение задачи извлечения информации в нашем случае мы разобьем на несколько частей:
• определение типовых шаблонов сайтов, на которых может размещаться информация о месте расположения организации;
• извлечение кандидатов для последующей привязки сайта к географической информации;
• фильтрация кандидатов.
На этом этапе пробуем определить набор шаблонов поиска страниц, на которых располагается предполагаемый адрес. Одним из наиболее часто встречающихся мест расположения контактной информации является корневая страница. В тоже время, эта страница не всегда является достоверным источником информации, поскольку существуют сайты, например, размещающие объявления, включающие в себя хорошо читаемые адреса, часть из которых может попасть на главную страницу, поэтому в дальнейшем адреса, извлеченные из основной страницы, будем фильтровать. Еще одним наиболее часто встречающимся местом расположения контактной информации является страница «Контакты». Как правило, на нее существуют ссылки с главной страницы, и они в большинстве случаев подчиняются ряду правил. Например, текст ссылки может содержать слово «контакты», «О нас» и т. д.
Проанализировав структуру сайтов различных организаций, отберем наиболее часто встречающиеся типовые шаблоны страниц, на которых можно найти адрес. Кратко можно записать следующие три шага:
• Поиск адресов на корневой странице сайта.
• Поиск ссылок на страницу «Контакты».
• Поиск адресов на странице «Контакты».
Как мы говорили выше, на первом этапе мы получаем наиболее вероятные страницы, на которых может быть размещена контактная информация. Из этих страниц можно извлечь то, что очень похоже на адрес. Почему «очень похоже»?, Потому что для извлечения мы будем использовать скрытую Марковскую модель.
Прежде чем начать строить нашу модель, определимся с данными и попробуем немного все упростить. Для начала определимся с тем, что количество значимых городов России является конечным и соответственно может быть описано словарем. Получили первое упрощение — используя словарь городов, можно найти опорную точку на странице. Можно предположить, что если мы находимся на наиболее вероятной странице контактов, то найденный нами город может входить в адрес.
Идем дальше. Если двигаться от точки вхождения влево или вправо. можно получить адрес, но для этого нужна система оценки последовательности символов, вероятно входящих в адрес. В этом нам может помочь HMM или скрытая Марковская модель. Но для построения модели нам потребуется определить следующие данные:
• состояния модели s, принадлежащие множеству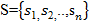 т. е. то, что можно принять за состояния;
т. е. то, что можно принять за состояния;
• элементы последовательности v, принадлежащие множеству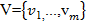 ; т. е. то, что можно принять за элементы последовательности.
; т. е. то, что можно принять за элементы последовательности.
Для примера возьмем адрес: 654007, Новокузнецк, ул. Орджоникидзе, 36, и выделим из него элементы последовательности V и состояния S.

Как видно таблицы 1, мы получили шесть элементов последовательности и пять состояний модели. Таким образом, если за элементы последовательности брать отдельные слова, то можно представить, к чему это приведет при расчете модели. Но мы сделаем несколько упрощений, чтобы уменьшить количество состояний множества S и количество элементов последовательности множества V. Если внимательно посмотреть на таблицу 1, то можно заметить, что элементы состояний s(2) и элементы последовательности v(2) повторяются. Если все элементы адреса разбить на типы, то это приведет нас к уменьшению состояний модели. Например, можно объединить все модификаторы улиц в один элемент. В этом случае — улица, шоссе, переулок… образуют элемент последовательности . Таким образом, получаем второе упрощение — трансляцию множества известных географических названий в один элемент последовательности. Приведем пример в виде таблицы:
. Таким образом, получаем второе упрощение — трансляцию множества известных географических названий в один элемент последовательности. Приведем пример в виде таблицы:

Таким образом, мы получаем всего 19 типизированных элементов множества V. То же самое можно проделать и с множеством S, т. е. с состояниями модели. Например, если во время анализа модель выдает информацию об улице, говорим, что модель находится в состоянии S(улица), если модель выдает информацию о городе, говорим. что модель находится в состоянии T(город). Получаем третье упрощение состояний модели. Примеры приведены в таблице 3.

Теперь, зная описание состояний модели и элементов последовательности, создаем обучающее множество, на котором строится наша модель. Из обучающего множества нам нужно получить матрицу вероятностей переходов A и B как матрицу вероятностей получения данных из множества V в тот момент, когда модель находится в состоянии s.
Например, в нашем случае фрагменты матрицы B и А выглядят следующим образом:

Для полноты картины нам нужно также учесть начальные распределения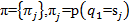 . А теперь, когда у нас построена модель, в краткой записи это выглядит как
. А теперь, когда у нас построена модель, в краткой записи это выглядит как 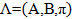 мы берем нашу последовательность D, окружающую найденный город и находим вероятность того, что слова, т. е. данные, похожи на модель. Считаем вероятность:
мы берем нашу последовательность D, окружающую найденный город и находим вероятность того, что слова, т. е. данные, похожи на модель. Считаем вероятность:
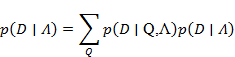
Поскольку в данной задаче требуется вычислить только вероятность появления последовательности адреса в окрестности города, то для решения используем алгоритм «forward-backward».
Извлеченные адреса проходят фильтрацию. Первый этап фильтрации заключается в том, что из страницы также извлекается дополнительная информация, как например, телефон, который ставится в соответствие одному или нескольким адресам, извлеченным из страницы.
Одно из сопоставлений — это проверка кода региона, указанного в номере телефона, на соответствие городу, указанному в адресе.
Второй этап фильтрации включает набор эмпирических правил, которые накладываются на выделенный адрес. К таким правилам, например, относится ограничение на возможное количество цифр, содержащихся в номере дома. После применения ряда правил извлеченный адрес либо принимается, как один из адресов, описывающий местоположение организации, либо отклоняется.
Для экспериментов была взята база страниц скачанных из Интернета, содержащая порядка 20 миллионов сайтов и 3,9 миллиарда страниц. Из этих данных на основе анализа контента страниц проводилась географическая привязка сайта алгоритмом, описанным выше. Результаты представлены в таблице 6.
Как показали эксперименты, описанный метод является достаточно точным. В его случае точность достигает 97%. Это обусловливается рядом ограничений, а именно: использованием предопределенных шаблонов для нахождения страницы с адресом; использованием словаря городов; сопоставление номера телефона и города, а также существующие формальные правила для записи адреса. Все эти ограничения позволяют достичь достаточно высокой точности при определении географии веб-ресурса. С другой стороны, эти ограничения приводят к снижению полноты, в случаях, если адрес записан без прямого указания города или с неизвестным городом, если страница с контактами расположена по адресу, который не описан в известных шаблонах поиска. На диаграмме 1 приведено распределение сайтов по регионам — как видно из диаграммы самым большим регионом, в который попадают сайты, является Москва.


В настоящий момент мы используем описанный метод, как один из методов, для извлечения информации о геопривязке сайтов и добавляем ее в индекс поисковой машины. Таким образом, человек может искать информацию по сайтам своего региона. Дополнительно, извлеченный адрес может показываться в адресных сниппетах.
Дмитрий Соловьёв
Разработчик Поиска@Mail.Ru
С того момента, как поисковые машины сделали свои первые шаги, разработчики тратят огромное количество усилий на совершенствование организации, навигации и поиска документов. Сегодня, наверное, самая используемая техника — это поиск по ключевым словам, дающий пользователям возможность находить информацию по заданной теме. В тоже время, глобальное расширение Интернета приводит к тому, что количество найденной информации, получаемой человеком при поиске с использованием только ключевых слов, слишком велико. Напечатав в поисковой строке одно и тоже слово, разные люди, возможно, хотят получить различные результаты.
На рисунках видно, как выглядит один и тот же запрос, задаваемый пользователями, проживающими в городах Новосибирск и Екатеринбург. Ясно, что спрашивая у поисковой машины слово «аэропорт», люди хотят получить адрес сайта городского аэровокзала:
Решить такую задачу, используя поиск по ключевым словам, нельзя. В то же время. он становится отправной точкой формирования высокоуровневых семантических запросов, которые могут использоваться для нахождения такой информации. Таким образом, к странице можно прикрепить дополнительные метаданные, используя которые. повысить качество ответа поисковой машины. Например, для геозависимых запросов такими метаданными будет являться информация о географическом положении ресурса. Зная, где физически находится искомый объект и обладая знаниями о положении пользователя, можно связать эти данные и выдать человеку информацию об искомом объекте.
В общем случае задачу можно разбить на две части:
a) определение местоположения пользователя;
b) определение местоположения искомого ресурса.
В статье мы предлагаем решение второй части задачи, т.е. как определить местоположение интернет-ресурса.
Существует множество источников, откуда можно взять информацию о географии сайта. К ним можно отнести следующие: база WHOIS, каталоги, контекст страниц, и т. д. В нашей статье рассмотрим, как можно привязать сайт к географии на основе анализа контекста страниц.
Анализируем содержимое страниц сайта
Как правило, источниками, которые могут поставлять информацию о географии, являются сайты организаций, где публикуются данные о местах их расположения — адреса и телефоны. Решение задачи извлечения информации в нашем случае мы разобьем на несколько частей:
• определение типовых шаблонов сайтов, на которых может размещаться информация о месте расположения организации;
• извлечение кандидатов для последующей привязки сайта к географической информации;
• фильтрация кандидатов.
Определяем типовые шаблоны
На этом этапе пробуем определить набор шаблонов поиска страниц, на которых располагается предполагаемый адрес. Одним из наиболее часто встречающихся мест расположения контактной информации является корневая страница. В тоже время, эта страница не всегда является достоверным источником информации, поскольку существуют сайты, например, размещающие объявления, включающие в себя хорошо читаемые адреса, часть из которых может попасть на главную страницу, поэтому в дальнейшем адреса, извлеченные из основной страницы, будем фильтровать. Еще одним наиболее часто встречающимся местом расположения контактной информации является страница «Контакты». Как правило, на нее существуют ссылки с главной страницы, и они в большинстве случаев подчиняются ряду правил. Например, текст ссылки может содержать слово «контакты», «О нас» и т. д.
Проанализировав структуру сайтов различных организаций, отберем наиболее часто встречающиеся типовые шаблоны страниц, на которых можно найти адрес. Кратко можно записать следующие три шага:
• Поиск адресов на корневой странице сайта.
• Поиск ссылок на страницу «Контакты».
• Поиск адресов на странице «Контакты».
Извлекаем адрес
Как мы говорили выше, на первом этапе мы получаем наиболее вероятные страницы, на которых может быть размещена контактная информация. Из этих страниц можно извлечь то, что очень похоже на адрес. Почему «очень похоже»?, Потому что для извлечения мы будем использовать скрытую Марковскую модель.
Прежде чем начать строить нашу модель, определимся с данными и попробуем немного все упростить. Для начала определимся с тем, что количество значимых городов России является конечным и соответственно может быть описано словарем. Получили первое упрощение — используя словарь городов, можно найти опорную точку на странице. Можно предположить, что если мы находимся на наиболее вероятной странице контактов, то найденный нами город может входить в адрес.
Идем дальше. Если двигаться от точки вхождения влево или вправо. можно получить адрес, но для этого нужна система оценки последовательности символов, вероятно входящих в адрес. В этом нам может помочь HMM или скрытая Марковская модель. Но для построения модели нам потребуется определить следующие данные:
• состояния модели s, принадлежащие множеству
т. е. то, что можно принять за состояния;• элементы последовательности v, принадлежащие множеству
; т. е. то, что можно принять за элементы последовательности.Для примера возьмем адрес: 654007, Новокузнецк, ул. Орджоникидзе, 36, и выделим из него элементы последовательности V и состояния S.
Как видно таблицы 1, мы получили шесть элементов последовательности и пять состояний модели. Таким образом, если за элементы последовательности брать отдельные слова, то можно представить, к чему это приведет при расчете модели. Но мы сделаем несколько упрощений, чтобы уменьшить количество состояний множества S и количество элементов последовательности множества V. Если внимательно посмотреть на таблицу 1, то можно заметить, что элементы состояний s(2) и элементы последовательности v(2) повторяются. Если все элементы адреса разбить на типы, то это приведет нас к уменьшению состояний модели. Например, можно объединить все модификаторы улиц в один элемент. В этом случае — улица, шоссе, переулок… образуют элемент последовательности
. Таким образом, получаем второе упрощение — трансляцию множества известных географических названий в один элемент последовательности. Приведем пример в виде таблицы:Таким образом, мы получаем всего 19 типизированных элементов множества V. То же самое можно проделать и с множеством S, т. е. с состояниями модели. Например, если во время анализа модель выдает информацию об улице, говорим, что модель находится в состоянии S(улица), если модель выдает информацию о городе, говорим. что модель находится в состоянии T(город). Получаем третье упрощение состояний модели. Примеры приведены в таблице 3.
Теперь, зная описание состояний модели и элементов последовательности, создаем обучающее множество, на котором строится наша модель. Из обучающего множества нам нужно получить матрицу вероятностей переходов A и B как матрицу вероятностей получения данных из множества V в тот момент, когда модель находится в состоянии s.
Например, в нашем случае фрагменты матрицы B и А выглядят следующим образом:
Для полноты картины нам нужно также учесть начальные распределения
. А теперь, когда у нас построена модель, в краткой записи это выглядит как мы берем нашу последовательность D, окружающую найденный город и находим вероятность того, что слова, т. е. данные, похожи на модель. Считаем вероятность:Поскольку в данной задаче требуется вычислить только вероятность появления последовательности адреса в окрестности города, то для решения используем алгоритм «forward-backward».
Фильтруем полученные данные
Извлеченные адреса проходят фильтрацию. Первый этап фильтрации заключается в том, что из страницы также извлекается дополнительная информация, как например, телефон, который ставится в соответствие одному или нескольким адресам, извлеченным из страницы.
Одно из сопоставлений — это проверка кода региона, указанного в номере телефона, на соответствие городу, указанному в адресе.
Второй этап фильтрации включает набор эмпирических правил, которые накладываются на выделенный адрес. К таким правилам, например, относится ограничение на возможное количество цифр, содержащихся в номере дома. После применения ряда правил извлеченный адрес либо принимается, как один из адресов, описывающий местоположение организации, либо отклоняется.
Что получили?
Для экспериментов была взята база страниц скачанных из Интернета, содержащая порядка 20 миллионов сайтов и 3,9 миллиарда страниц. Из этих данных на основе анализа контента страниц проводилась географическая привязка сайта алгоритмом, описанным выше. Результаты представлены в таблице 6.
Как показали эксперименты, описанный метод является достаточно точным. В его случае точность достигает 97%. Это обусловливается рядом ограничений, а именно: использованием предопределенных шаблонов для нахождения страницы с адресом; использованием словаря городов; сопоставление номера телефона и города, а также существующие формальные правила для записи адреса. Все эти ограничения позволяют достичь достаточно высокой точности при определении географии веб-ресурса. С другой стороны, эти ограничения приводят к снижению полноты, в случаях, если адрес записан без прямого указания города или с неизвестным городом, если страница с контактами расположена по адресу, который не описан в известных шаблонах поиска. На диаграмме 1 приведено распределение сайтов по регионам — как видно из диаграммы самым большим регионом, в который попадают сайты, является Москва.
В настоящий момент мы используем описанный метод, как один из методов, для извлечения информации о геопривязке сайтов и добавляем ее в индекс поисковой машины. Таким образом, человек может искать информацию по сайтам своего региона. Дополнительно, извлеченный адрес может показываться в адресных сниппетах.
Дмитрий Соловьёв
Разработчик Поиска@Mail.Ru
