Комментарии 92
В нативном JS есть же более универсальные функции querySelectorAll и querySelector и довольно много кто поддерживает caniuse.com/queryselector.
jQuery — хоть и самая медленная, но, имхо, самая удобная и продуманная библиотека. И в большинстве скорость разработки окупает скорость работы.
Вот бы в браузерах оптимизации для jQuery (учитывая повсеместное использование), но, может, я слишком многого прошу…
Вот бы в браузерах оптимизации для jQuery (учитывая повсеместное использование), но, может, я слишком многого прошу…
По поводу медленности ее всегда можно оптимизировать, она с недавних пор стала модульной + убраны поддержки old browsers.
Я готов поспорить. В d3js (который в принципе для другого предназначен, но манипуляции с DOM там тоже есть) некоорые вещи сделаны более приятно, например:
d3.select('body')
.append('div')
.append('span')
.attr('class', 'foo')
НЛО прилетело и опубликовало эту надпись здесь
А версии библиотек можно увидеть?
Вот смотрю на цифры и первое впечатление это время в мс за 1000 итераций. Но если так, то JQuery самая быстрая.
Что означают эти цифры? Хочется более объективного сравнения.
А вообще для чего используются библиотеки? Для манипуляции с DOM и выполнения GET и POST запросов к серверу. Еще разбор JSON и XML. Хотелось бы рассмотреть и эти моменты и уже решить какую библиотеку лучше выбрать для проектов, где критична скорость.
Буду очень признателен.
Что означают эти цифры? Хочется более объективного сравнения.
А вообще для чего используются библиотеки? Для манипуляции с DOM и выполнения GET и POST запросов к серверу. Еще разбор JSON и XML. Хотелось бы рассмотреть и эти моменты и уже решить какую библиотеку лучше выбрать для проектов, где критична скорость.
Буду очень признателен.
Не хватает jQuery версии 2.x — она должна быть побыстрее.
Заменил code.jquery.com/jquery-1.10.2.min.js на code.jquery.com/jquery-2.0.3.min.js
Изменения в результатах не заметил.
Изменения в результатах не заметил.
Результаты jQuery можно немного улучшить:
'Append span':
приблизительно скорость увеличивается на 20% в Хроме (в других не проверял), но это всё равно мало.
'Styling':
+ 40% относительно исходного результата…
ps. порадовало, что extjs по некотором тестам немного native превосходит в некоторых браузерах))) надо как-нить заглянуть в его «кишки»
'Append span':
вместо jQuery(document.body).append(jQuery('<span class="testspan">'));
записать jQuery(document.body).append('<span class="testspan">');
приблизительно скорость увеличивается на 20% в Хроме (в других не проверял), но это всё равно мало.
'Styling':
вместо jElement.css({'background-color': '#aaa'});
записать jElement.css('background-color', '#aaa');
+ 40% относительно исходного результата…
ps. порадовало, что extjs по некотором тестам немного native превосходит в некоторых браузерах))) надо как-нить заглянуть в его «кишки»
Раньше я особо не задумывался о способе написания вызовов в jQuery, да и окружающие, видимо, тоже (судя по исходникам) — тот же css выствляют поочередно каждым из способов. :)
Меня тоже результаты ExtJS порадовали. Но я это списываю на свои кривые руки при вызове native
методов.
Меня тоже результаты ExtJS порадовали. Но я это списываю на свои кривые руки при вызове native
методов.
Для 'Read classes':
А для 'Toggle class':
вот теперь extjs отстает от native)
у вас, по сути, отставание на 10-20%, причем в операциях в миллисекунду, т.е. пользователь этого точно не заметит, даже при количестве в 1000 операций на одно его действие, что является редкостью.
var classes = nElement.className.split(' ');
А для 'Toggle class':
var classes = " " + nElement.className + " ";
if (classes.indexOf(" " + 'testToggle' + " ") == -1) {
nElement.className += " " + 'testToggle';
} else {
nElement.className = classes.replace(" " + 'testToggle' + " ", " ").replace(/^ /, "").replace(/ $/, "");
}
вот теперь extjs отстает от native)
у вас, по сути, отставание на 10-20%, причем в операциях в миллисекунду, т.е. пользователь этого точно не заметит, даже при количестве в 1000 операций на одно его действие, что является редкостью.
Это значит только что native код был плохо оптимизирован.
Мне тоже показалось странным, что extjs быстрее native. Это как такое возможно? Всегда думал, что библиотеки сводят свой код к native.
Пожалуйста, указывайте рядом с таблицами и/или диаграммами в каких попугаях данные представлены. Не у всех есть время вчитываться в каждое словосочетание в поисках «количества операций в миллисекунду».
ПС: поздно увидел аналогичное замечание выше.
ПС: поздно увидел аналогичное замечание выше.
Может лучше заюзать SlickSpeed для тестирование выборок по DOM?
Ну и ещё замечания:
— Как часто вам приходится получать все классы элемента? Я вот не припомню такого…
— Добавление элементов в дом полагаясь на $("<....>") — ну очень спорный момент, я даже используя jQuery обычно пишу document.createElement() — это не только быстрее, но и зачастую удобней.
— При применении CSS стиля в jQuery используете хэш, но зачем? В итоге же получаем дополнительный перебор свойств…
P.S. Я не ставил перед собой задачу защищать jQuery, просто тест какой-то за уши притянутым мне кажется, такой вот, пользовательский, ну и подборка очень узкая, как будто вы решили потестить только те фреймворки, по котором холиварите между собой.
Ну и ещё замечания:
— Как часто вам приходится получать все классы элемента? Я вот не припомню такого…
— Добавление элементов в дом полагаясь на $("<....>") — ну очень спорный момент, я даже используя jQuery обычно пишу document.createElement() — это не только быстрее, но и зачастую удобней.
— При применении CSS стиля в jQuery используете хэш, но зачем? В итоге же получаем дополнительный перебор свойств…
P.S. Я не ставил перед собой задачу защищать jQuery, просто тест какой-то за уши притянутым мне кажется, такой вот, пользовательский, ну и подборка очень узкая, как будто вы решили потестить только те фреймворки, по котором холиварите между собой.
А можно добавить zeptojs.com/? Он имеет совместимость с jQuery API, интересно сравнить.
Поддерживаю. Статье не хватает Zepto.
Перешел по вашей ссылке. Вдохновился описанием — добавил zepto в тест. Ну а результаты сильно разочаровали
chrome
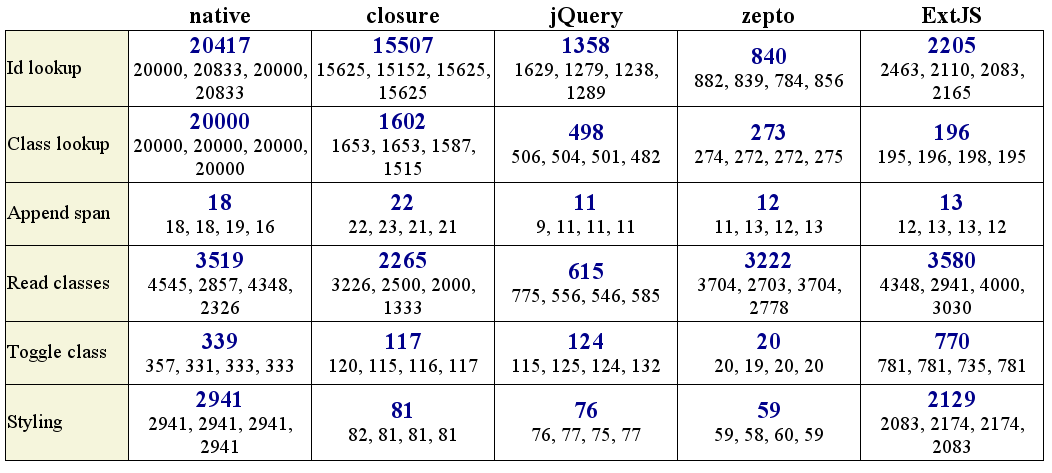
Он везде оказался медленней чем jQuery (ну кроме «чтения классов»), плюс нет поддержки IE, скрипач не нужен.
chrome

Он везде оказался медленней чем jQuery (ну кроме «чтения классов»), плюс нет поддержки IE, скрипач не нужен.
Хотелось бы увидеть вот эту библиотеку в таблице: yass.webo.in
Сразу отвечаю и akira и bolk — зная где взять библиотеку, и как с ее использованием описанные выше операции выглядят — можно легко расширить тест. Займусь этим на досуге. Ну а если любители библиотек пришлют мне вызовы для выполнения операций, аналогичных тем, что в статье, то дело будет быстрее.
Хочется еще операций, которые очень часто используются: POST, GET запрос и парсинг JSON
Выше я уже писал — POST, GET слишком сильно от сети и сервера зависят и влияние библиотек померить трудно будет. А вот парсин json попробую к следующему разу добавить.
Во вменяемых браузерах парсинг JSON нативен.
Ну а если библиотека не использует нативный парсинг при его наличии, то это плохая библиотека.
Ну а если библиотека не использует нативный парсинг при его наличии, то это плохая библиотека.
да ладно тебе :) Даже имея библиотеку, которая быстрее closure, это ничего не дает — все равно все jQuery используют
Оставлю тут, может кому пригодится: Ускорение работы с DOM
Интересно, если собрать jQuery с родным querySelectorAll вместо Sizzle (в jQuery 2.0 это возможно) — как изменятся результаты теста?
Sizzle всегда пытается вызвать querySelectorAll обернув его в try/catch и только в том случае если браузер упал при попытке это разобрать, запускает свой внутренний поиск.
А еще перед этим у него есть отдельные проверки если селектор является просто ID — запускается getElementById(), если просто класс — getElemenstByClassName() — это как раз случаи из статьи.
Т.е. здесь собственного поиска Sizzle не изменрялась. Измерялось время на обертки, регексп чтобы понять является ли селектор просто ид/классом/тегом и собственно вызов getElementById/getElemenstByClassName.
Поэтому становится еще непонятнее почему так медленно?
А еще перед этим у него есть отдельные проверки если селектор является просто ID — запускается getElementById(), если просто класс — getElemenstByClassName() — это как раз случаи из статьи.
Т.е. здесь собственного поиска Sizzle не изменрялась. Измерялось время на обертки, регексп чтобы понять является ли селектор просто ид/классом/тегом и собственно вызов getElementById/getElemenstByClassName.
Поэтому становится еще непонятнее почему так медленно?
Было дело, тоже интересовался сравнительно недавно. На самом деле, счет идет на такое нереальное количество операций в секунду, что на практике там совершенно неважно, что — jQuery или native — пользователь не видит разницы ни в одном браузере (особенно, если простые скрипты, коих большинство).
Тем не менее! Всегда было интересно — почему результаты того же jQuery НАСТОЛЬКО отличаются? Почему они для селекторов не используют native-варианты, если они присутствуют? Или, если используют, то почему такой оверхед. Странно, учитывая популярность jQuery.
Тем не менее! Всегда было интересно — почему результаты того же jQuery НАСТОЛЬКО отличаются? Почему они для селекторов не используют native-варианты, если они присутствуют? Или, если используют, то почему такой оверхед. Странно, учитывая популярность jQuery.
А можете добавить в тест Dojo? dojotoolkit.org/
Ну и V8, конечно, просто монстр :)
Не знаю, как там в библиотеках, но нативный код можно написать от задачи и результат будет разный, к примеру:
И так далее…
Так что нужно еще учитывать и то, что в итоге нужно получить.
document.getElementById('id');
document.querySelector('#id');
document.getElementsByClassName('class');
document.querySelectorAll('.class');
var spn = document.createElement('span');
spn.setAttribute('class','testspan');
document.body.appendChild(spn);
document.body.innerHTML='<span class="testspan"></span>';
document.body.insertAdjacentHTML('afterbegin'/*beforeend*/,'<span class="testspan"></span>');
nElement.getAttribute('class').split(' ');// Что это???
nElement.classList;
var classes = nElement.className.split(' ');// ...
var ind = classes.indexOf('testToggle');
if(ind==-1) classes.push('testToggle');
else classes.splice(ind,1);
nElement.className = classes.join(" ");
nElement.classList.toggle('testToggle');
И так далее…
Так что нужно еще учитывать и то, что в итоге нужно получить.
интересно было бы посмотреть еще в этом перечне производительность такой библиотеки как d3.js
небольшой результат habrahabr.ru/company/mailru/blog/188254/#comment_6543202
В jQuery медленно работает функция $(), которая создает обьект с кучей вспомогательных методов. С этим обьектом очень удобно работать выстраивая цепочки, но при этом приходится жертвовать скоростью.
Обычная практика оптимизации jQuery — это минимизация вызовов $() и сохранения результата в переменные.
Зная эту особенность можно свободно использовать эту либу в больших проектах.
Обычная практика оптимизации jQuery — это минимизация вызовов $() и сохранения результата в переменные.
Зная эту особенность можно свободно использовать эту либу в больших проектах.
НЛО прилетело и опубликовало эту надпись здесь
Вы просто по другому назвали функцию, медленно работает именно вызов.
Этот кусок кода будет работать значительно медленнее, чем вот такой:
То есть объект jQuery создается медленно, после чего с ним легко и быстро работать.
$('.sel').mousemove(function() {
$('.sel2').css({...});
});
Этот кусок кода будет работать значительно медленнее, чем вот такой:
var $sel2 = $('.sel2');
$('.sel').mousemove(function() {
$sel2.css({...});
});
То есть объект jQuery создается медленно, после чего с ним легко и быстро работать.
Но второй вариант — не просто оптимизация первого, там может быть другая логика. Элемента ".sel2" может еще не существовать при объявлении callback-а на событие. И не всегда есть возможность отследить его появление. Придется делать проверку внутри обработчика события. Ну, впрочем, понятное дело — жертвуем простотой ради производительности.
Ну правильно, каждый раз, когда вы печатаете символ $, то jQuery начинает бегать по всему dom в поисках элемента, а вот если таких будет тысячи?) Всегда надо стараться кешировать результат в переменную.
А это то чем поможет? Просто алиас функции. Он также создаст обертку вокруг объекта элемента, которую в документации они называют «jQuery object».
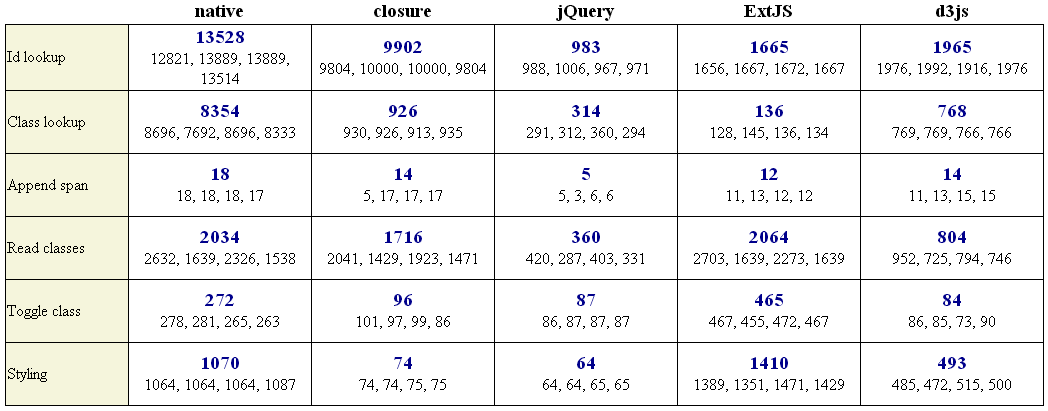
так ну я не стал ждать с моря погоды (пока потестят мою любимую библиотеку d3.js) и сам провел тест правда только в Chrome Версия 30.0.1573.2 dev-m.
И так:
Поиск элемента по идентификатору
Поиск элементов по классу
Добавление элемента
Определение класса элемента
Изменение класса элемента
собственно метод сlassed без второго параметра нужен для определения наличия класса у объекта
Изменение стиля элемента
И так:
Поиск элемента по идентификатору
"native": function(){var element = document.getElementById('testid');},
"closure": function(){var element = goog.dom.getElement('testid');},
"jQuery": function(){var element = jQuery('#testid');},
"ExtJS": function(){var element = Ext.get('testid');},
"d3js": function(){var element = d3.select("#testid");}
Поиск элементов по классу
"native": function(){var elements = document.getElementsByClassName('testclass');},
"closure": function(){var elements = goog.dom.getElementByClass('testclass');},
"jQuery": function(){var elements = jQuery('.testclass');},
"ExtJS": function(){var elements = Ext.select('.testclass');},
"d3js": function(){var elements = d3.select('.testclass');}
Добавление элемента
"jQuery": function(){jQuery(document.body).append(jQuery('<span class="testspan">'));},
"closure": function(){goog.dom.appendChild(document.body, goog.dom.createDom('span',{class:'testspan'}));},
"ExtJS": function(){Ext.DomHelper.append(document.body, {tag : 'span', cls : 'testspan'});},
"d3js": function() {d3.select(document.body).append("span").attr("class", "testspan");},
//native
Определение класса элемента
"native": function(){var classes = nElement.getAttribute('class').split(' ');},
"closure": function(){var classes = goog.dom.classes.get(gElement);},
"jQuery": function(){var classes = jElement.attr('class').split(' ');},
"ExtJS": function(){var classes = eElement.getAttribute('class').split(' ');},
"d3js": function(){var classes = d3Element.attr("class").split(' ');}
Изменение класса элемента
собственно метод сlassed без второго параметра нужен для определения наличия класса у объекта
"closure": function(){goog.dom.classes.toggle(gElement, 'testToggle');},
"jQuery": function(){jElement.toggleClass('testToggle');},
"ExtJS": function(){var classes = eElement.toggleCls('testToggle');},
"d3js": function() {d3Element.classed('testToggle', !d3Element.classed('testToggle'));},
//native
Изменение стиля элемента
"native": function(){nElement.style.backgroundColor = '#aaa';},
"closure": function(){goog.style.setStyle(gElement, {'background-color': '#aaa'});},
"jQuery": function(){jElement.css({'background-color': '#aaa'});},
"ExtJS": function(){eElement.setStyle('backgroundColor','#aaa');},
"d3js": function(){ d3Element.style('background-color', '#aaa'); }

Uncaught ReferenceError: goog is not definedВидимо из-за того, что Dropbox по https отдаёт, а хром после этого не разрешает использовать не-https js-файлы:
[blocked] The page at https://dl.dropboxusercontent.com/spa/6x4vg7uwuzglgh3/testJsF/public/index.html ran insecure content from http://code.jquery.com/jquery-1.10.2.min.js.Приятней смотреть на график, если не затруднит.
Слышал что выборка происходит справа налево, в связи с этим вопрос: какой способ будет быстрее:
или
Предполагается что есть много разных
$('.wrapper1 a').blabla();или
$('.wrapper1').find('a').blabla();Предполагается что есть много разных
<div class='wrapper'>... </div> и в каждом много <a.....>В современных браузерах селекторы будут обрататываться браузерным .querySelectorAll, а значит второй будет медленнее (ибо 2 вызова querySelectorAll + js-ный бутерброд между ними).
Кроме того разница будет заметна еще больше в старых ИЕ (6-8). Если вы хорошо относитесь к пользователям ИЕ 6-8, то да: стоит избегать ситуации когда самый правый элемент селектора состоит только из класса (в старых ИЕ из-за отсутсвия getElementsByClassName() это приведет к полному перебору ВСЕХ элементов, и проверке имеет ли элемент класс), и добавлять к самому правому элементу селектора хотя бы имя тега.
А вот второй ваш способ есть смысл применять только в случае когда в вашем селекторе есть нечто что 100% не может быть обработанно querySelectorAll. Обычно это Sizzle-овый селекторовый сахар, типа псевдоклассов :eq() :not() :contains(), :first, :last, :even, :odd, :gt, :lt, :eq (они перечислены на главной странице Sizzle). Тогда ту часть которая может быть распарсена querySelectorAll стоит запускать сначала через $(), а остальное через .find()
Кроме того разница будет заметна еще больше в старых ИЕ (6-8). Если вы хорошо относитесь к пользователям ИЕ 6-8, то да: стоит избегать ситуации когда самый правый элемент селектора состоит только из класса (в старых ИЕ из-за отсутсвия getElementsByClassName() это приведет к полному перебору ВСЕХ элементов, и проверке имеет ли элемент класс), и добавлять к самому правому элементу селектора хотя бы имя тега.
А вот второй ваш способ есть смысл применять только в случае когда в вашем селекторе есть нечто что 100% не может быть обработанно querySelectorAll. Обычно это Sizzle-овый селекторовый сахар, типа псевдоклассов :eq() :not() :contains(), :first, :last, :even, :odd, :gt, :lt, :eq (они перечислены на главной странице Sizzle). Тогда ту часть которая может быть распарсена querySelectorAll стоит запускать сначала через $(), а остальное через .find()
НЛО прилетело и опубликовало эту надпись здесь
Вы правы отчасти. Вообще, с ИЕ8 все интересно: с одной стороны в нем уже есть querySelectorAll, но с другой стороны в нем все еще нет getElementsByClassName.
Поэтому если селектор простой (т.е. содержит только ид/классы/теги/неймы и отношения " " и >) то да, querySelectorAll справится и все будет гуд.
А вот если в селекторе будет что угодно кроме этого, то запустится Sizzle-овый внутренний поиск, который уже не пытается использовать querySelectorAll, а использует только getElementById, getElementsByClassName, и т.д. И поскольку getElementsByClassName в ИЕ8 нет, по факту довольно безобидный с виду запрос
превратится в
а это нереально медленно, ибо перебирает совсем все элементы, начиная от html/head/body/script и заканчивая последней a/b/i/sup. И в этом случае простое добавление тега input в селектор ускорит его в ИЕ8 в сотни раз.
Поэтому если селектор простой (т.е. содержит только ид/классы/теги/неймы и отношения " " и >) то да, querySelectorAll справится и все будет гуд.
А вот если в селекторе будет что угодно кроме этого, то запустится Sizzle-овый внутренний поиск, который уже не пытается использовать querySelectorAll, а использует только getElementById, getElementsByClassName, и т.д. И поскольку getElementsByClassName в ИЕ8 нет, по факту довольно безобидный с виду запрос
$('.second-choice:checked')превратится в
$('*').filter('.second-choice:checked');а это нереально медленно, ибо перебирает совсем все элементы, начиная от html/head/body/script и заканчивая последней a/b/i/sup. И в этом случае простое добавление тега input в селектор ускорит его в ИЕ8 в сотни раз.
Благодарю за удовольствие от чтения статьи.
Тесты немного синтетичные. Ведь в родном подходе closure-library используется лишь половина вышеуказанного. Первое и второе не используется вообще. Последнее используется очень ограниченно.
Перед созданием клиента html-5 игрушки проводил массу подобных бенчмарков и сравнений (приводить не буду изза-специфики). В результате обнаружил, что отзывчивость и субъективное восприятие скорости в реализации на closure-library, extjs, zepto, jquery отличалось на порядки. При этом на много большее влияние на общую отзывчивость имела архитектура библиотеки компонент. Так к примеру sencha контроллы работали на одном уровне с closure, а jquery плагины прилично отставали. Когда-же стравнил реализацию анимаций, то closure отстала от jquery (что легко вылечилось заменой одной функции).
Я был-бы рад увидеть сранение более высокоуровневых вещей.
Тесты немного синтетичные. Ведь в родном подходе closure-library используется лишь половина вышеуказанного. Первое и второе не используется вообще. Последнее используется очень ограниченно.
Перед созданием клиента html-5 игрушки проводил массу подобных бенчмарков и сравнений (приводить не буду изза-специфики). В результате обнаружил, что отзывчивость и субъективное восприятие скорости в реализации на closure-library, extjs, zepto, jquery отличалось на порядки. При этом на много большее влияние на общую отзывчивость имела архитектура библиотеки компонент. Так к примеру sencha контроллы работали на одном уровне с closure, а jquery плагины прилично отставали. Когда-же стравнил реализацию анимаций, то closure отстала от jquery (что легко вылечилось заменой одной функции).
Я был-бы рад увидеть сранение более высокоуровневых вещей.
Я старался сравнивать самые простые операции, умещающиеся в одну строчку (да и то, судя по комментам, далеко не везде наилучшим образом написал). Для более сложных вещей найдется уже несколько вариантов реализации на каждой из библиотек. И производительность от выбора вариавнта будет зависеть больше, чем от выбора библиотеки.
Хотя можно было бы организовать своеобразный тест TPC — коллективным разумом выбрать наиболее характерные операции и сравнить их реализации.
Хотя можно было бы организовать своеобразный тест TPC — коллективным разумом выбрать наиболее характерные операции и сравнить их реализации.
Сравнивать надо возможности, остальное вторично.
Например:
1) Кто из этих фреймворков поддерживает псевдоселектор ":header"? Или что-то типа этого.
2) Кто и на каком уровне поддерживает расширение?
3) Кто и где упадет при разборе гигантских данных? Например, переполнит стек вызовов.
И так далее.
Пока вы только создали ситуацию, когда джуниор придет и скажет «я буду везде писать $('#id'), а не сохранять его в переменную, потому что наш фреймворк писец как для этого оптимизирован».
Можно все написать на нативном яваскрипте и оптимизировать все, например под V8.
Или использовать фреймворк с перегрузкой аргументов.
Или строго типизированный фреймворк с неймспейсами.
Или модульный.
Или…
Вот из-за этих «или» и надо сравнивать возможности. Потому что скорость, вопрос относительный. Усатый мужик с языком еще доказал.
Например:
1) Кто из этих фреймворков поддерживает псевдоселектор ":header"? Или что-то типа этого.
2) Кто и на каком уровне поддерживает расширение?
3) Кто и где упадет при разборе гигантских данных? Например, переполнит стек вызовов.
И так далее.
Пока вы только создали ситуацию, когда джуниор придет и скажет «я буду везде писать $('#id'), а не сохранять его в переменную, потому что наш фреймворк писец как для этого оптимизирован».
Можно все написать на нативном яваскрипте и оптимизировать все, например под V8.
Или использовать фреймворк с перегрузкой аргументов.
Или строго типизированный фреймворк с неймспейсами.
Или модульный.
Или…
Вот из-за этих «или» и надо сравнивать возможности. Потому что скорость, вопрос относительный. Усатый мужик с языком еще доказал.
Возможности это хорошо. Но сколько возможностей неюзабельны по причинам производительности.
Например?
О, примеров огромное количество.
Последний с которым сталкивался — плагин с inline редактированием таблици. Красиво, просто, функионально, удобно. Но слишком медленно (на i7). Думаю у всех есть достаточно подобного опыта.
Последний с которым сталкивался — плагин с inline редактированием таблици. Красиво, просто, функионально, удобно. Но слишком медленно (на i7). Думаю у всех есть достаточно подобного опыта.
Я правильно вас понял: криворукий плагин одного из фреймворков бросил в ваших глазах тень на производительность ведущих фреймворков, которые пишут лучшие программисты со всего мира?
Пример очень равнорукий, красивый и качественно написаный ;). Просто в нём в жертву функциональности итп была потеряна производительность.
Это лишь пример к этому посту.
P.S.
А по поводу
Не впадайте в идолопоклонничество ;)
Лучший меч галактики не сравнится с дешевым скальпелем в избавлении от аппендицита. Нет совершенства в программировании, всегда чем-то жертвуют и лучшие программисты. По этому при выборе инструментальных средств для конкретной задачи нужно использовать обьективные критерии а не авторитет лучших собаководов.
Это лишь пример к этому посту.
P.S.
А по поводу
ведущих фреймворков, которые пишут лучшие программисты
Не впадайте в идолопоклонничество ;)
Лучший меч галактики не сравнится с дешевым скальпелем в избавлении от аппендицита. Нет совершенства в программировании, всегда чем-то жертвуют и лучшие программисты. По этому при выборе инструментальных средств для конкретной задачи нужно использовать обьективные критерии а не авторитет лучших собаководов.
Я не впадаю в поклонничество или что-то там, вы просто подумайте — вы лично сколько сделали фреймворков? И сколько людей ими пользуются?.. Вы даже не вступили с эти людьми в интелектуальную гонку, а уже считаете их людьми не первого сорта.
По поводу криворукости кода, то надо просто понимать, что есть стек в языке и что надо его грамотно заполнять, что в старом эксплорере, что в последнем хроме. Например, с помощью Raphael можно нарисовать в старом браузере сотни тысяч точек на графике и не заблокировать пользовательский интерфейс. А можно сделать простой плагин для jQuery и повалить браузер.
По поводу криворукости кода, то надо просто понимать, что есть стек в языке и что надо его грамотно заполнять, что в старом эксплорере, что в последнем хроме. Например, с помощью Raphael можно нарисовать в старом браузере сотни тысяч точек на графике и не заблокировать пользовательский интерфейс. А можно сделать простой плагин для jQuery и повалить браузер.
вы лично сколько сделали фреймворков?Открытых ни одного. На за 20+ лет наследил прилично (скорее всего Вы тоже пользуетесь чем-то к чему приложил голову).
Вы даже не вступили с эти людьми в интелектуальную гонку,
Я вообще в гонках не участвую. Предпочитаю просто делать работу и иногда слать патчи.
а уже считаете их людьми не первого сорта.
С чего вы это взяли? Я не людей на сорты делю. Есть фраза «не боги горшки обжигают».
По поводу криворукости… и повалить браузер.
Разговор ни о чем. В чем Ваш посыл? Какая криворукость в отличном плагине? Да тормозит с большими простынями. Так он предназначен для мелких. Баланс не в нужную кому-то сторону не критерий криворукости, а лишь еще один момент в пользу того что выражение
Сравнивать надо возможности, остальное вторично.не всегда верно. И данная статья есть полезна для оценки.
Дальше отвечать не буду. Ибо этот разговор — немого с глухим.
Ну так с этого я статью и начал — сравнивались функциональные возможности, а вопрос быстродействия был второстепенным. Но эту статью я посвятил именно производительности.
Почему для тестов не использовали проверенный годами benchmark.js (в основе jsperf.com)?
Во-вторых, использовать методы
На данный момент, большинство либ и селекторных движков по типу jQuery работают по одинаковому принципу ± свои оптимизации. Если мы видим значительную разницу в скорости (порядки), значит используются свои обёртки, другие подходы (например просто ф-я, которая парсит селектор, выбирает и возвращает тот же live NodeList/HTMLCollection) или недопустимые хаки (модификация оригинального DOM), но тогда мы теряем в удобстве и скорости разработки, которую даёт jQuery, что гораздо важнее.
Во-вторых, использовать методы
getElements{ByTagName, ByClassName /*, etc */} можно просто ради интереса (зная что они возвращают «live» NodeList/HTMLCollection, которые малопригодны для чего-то сложнее простых операций выборки/перебора и своих велосипедов). Но тогда где querySelector{All}?На данный момент, большинство либ и селекторных движков по типу jQuery работают по одинаковому принципу ± свои оптимизации. Если мы видим значительную разницу в скорости (порядки), значит используются свои обёртки, другие подходы (например просто ф-я, которая парсит селектор, выбирает и возвращает тот же live NodeList/HTMLCollection) или недопустимые хаки (модификация оригинального DOM), но тогда мы теряем в удобстве и скорости разработки, которую даёт jQuery, что гораздо важнее.
Попробую ответить
Почему для тестов не использовали проверенный годами benchmark.js (в основе jsperf.com)?Потому-что мне было проще написать несколько строчек самому и получить готовую отформатированную табличку с результатами.
Во-вторых, использовать методы getElements{ByTagName, ByClassName /*, etc */} можно просто ради интереса (зная что они возвращают «live» NodeList/HTMLCollection, которые малопригодны для чего-то сложнее простых операций выборки/перебора и своих велосипедов). Но тогда где querySelector{All}?Как я уже писал — для тестов использовались вызовы, которые широко встречаются в имеющемся коде. jQuery селектор вида $('.class') я встречаю очень часто. Естественно пришлось сделать его аналоги (конечно же не полный эквивалент) и для других библиотек.
возникает вопрос, как так получилось, что в тесте Read Classes ExtJs опережает native? Там есть кэш?
Для начала сделать нужно так
Поиск элемента по идентификатору
Поиск элементов по классу
Поиск элемента по идентификатору
"jQuery": function(){var element = jQuery('#testid')[0];},Поиск элементов по классу
"jQuery": function(){var elements = jQuery('.testclass')[0];},Интересно, спасибо за информацию.
ИМХО, важный момент касаемо Google Closure, то, что в первую очередь это компилятор, так что имеет смысл тесты компилировать, желательно с использованием advanced compilation.
ИМХО, важный момент касаемо Google Closure, то, что в первую очередь это компилятор, так что имеет смысл тесты компилировать, желательно с использованием advanced compilation.
Как один из разработчиков «медленной» библиотеки позволю себе прокомментировать результаты:
Самописной, не протестированной, не возвращающих статистически значимых результатов «библиотеке» перфоманс тестов, во всяком случае, мы, доверять не смогли бы.
Многие тесты как jQuery так и остальных библиотек написаны довольно спорно, это видно как и по результатам: ванильный джаваскрипт не может быть медленнее библиотечных аналогов; так и по самим тестам: как пример тесты селекторов нужно выполнять в отдельном фрейме, для того что бы обеспечить изолированность выполнения каждого теста, например как сделано у нас – github.com/jquery/sizzle/blob/master/speed/
Скорость имеет значение, но мы так же обязаны балансировать между размером гзипованного кода и стабильностью АПИ библиотеки, как пример: мы думали использовать Element Traversing API и новые ДОМ-методы типа insertAdjacentHTML, в некоторых браузерах прирост был до 80-90%, но в некоторых случаях размер, в других, опасность возникновения появления эджевых багов нас остановили.
Иными словами даже если результаты нового кода хороши, в абсолютных числах производительность будет все еще высока и в старом коде, сравнительная скорость может быть хуже, но это всего лишь детали.
Тем не менее, сейчас, мы разрабатываем возможность автоматического тестирования скорости после каждого коммита, это позволит нам видеть регрессии сразу после их возникновения, надеюсь мы успеем это сделать ко времени выхода 2.1/1.11.
Самописной, не протестированной, не возвращающих статистически значимых результатов «библиотеке» перфоманс тестов, во всяком случае, мы, доверять не смогли бы.
Многие тесты как jQuery так и остальных библиотек написаны довольно спорно, это видно как и по результатам: ванильный джаваскрипт не может быть медленнее библиотечных аналогов; так и по самим тестам: как пример тесты селекторов нужно выполнять в отдельном фрейме, для того что бы обеспечить изолированность выполнения каждого теста, например как сделано у нас – github.com/jquery/sizzle/blob/master/speed/
Скорость имеет значение, но мы так же обязаны балансировать между размером гзипованного кода и стабильностью АПИ библиотеки, как пример: мы думали использовать Element Traversing API и новые ДОМ-методы типа insertAdjacentHTML, в некоторых браузерах прирост был до 80-90%, но в некоторых случаях размер, в других, опасность возникновения появления эджевых багов нас остановили.
Иными словами даже если результаты нового кода хороши, в абсолютных числах производительность будет все еще высока и в старом коде, сравнительная скорость может быть хуже, но это всего лишь детали.
Тем не менее, сейчас, мы разрабатываем возможность автоматического тестирования скорости после каждого коммита, это позволит нам видеть регрессии сразу после их возникновения, надеюсь мы успеем это сделать ко времени выхода 2.1/1.11.
Во-первых, jQuery в первую очередь я бы характеризовал не как «медленную», а как «удобную». Пролизводительность в данном случае вторичный фактор.
Во-вторых, я ничуть не рассматриваю данный тест, как основание для серьезных выводов. Это лишь повод задуматься. Если кто-то возьмется организовать серьезный тест с учетом всех сайд эффектов, то я буду рад посмотреть на его результаты. Правда по собственному опыту могу сказать, что при любой организации тестов «проигравшая» сторона всегда обвиняет организаторов в неправильном подходе к тестированию :)
Во-вторых, я ничуть не рассматриваю данный тест, как основание для серьезных выводов. Это лишь повод задуматься. Если кто-то возьмется организовать серьезный тест с учетом всех сайд эффектов, то я буду рад посмотреть на его результаты. Правда по собственному опыту могу сказать, что при любой организации тестов «проигравшая» сторона всегда обвиняет организаторов в неправильном подходе к тестированию :)
Последнее вроде решается предложением сторонам участвовать в тестах самим. То есть ставятся задачи (желательно более-менее реальные) и представители сторон (может разработчики непосредственно, может «продвинутые пользователи», знающие сабж чуть ли не лучше разработчиков) решают их сами, скорее всего оптимальным для сабжа способом.
В общем, можно устроить хабратестирование — создать топик-обсуждение, где выложить тестовые сценарии и предложить всем выкладывать варианты их решения, после чего отобрать лучшие и опубликовать результаты в другом топике. А можно ещё сначала создать топик для обсуждения самих тестовых сценариев, чтобы были более-менее близки к практике, а не сферической вакуумной синтетикой.
И, кстати, наверное неплохо было бы гонять тесты на минимум двух конфигурациях железа: более-менее современной и достаточной для типовых задач в вебе и минимальной — увы, не редкость ситуация, когда на мощных девелоперских машинах всё летает, а на каком-нибудь нетбуке, бюджетном десктопе или вообще P4 с гигом памяти, который считался современным лет 10 назад (где нибудь в госконторах) нещадно тормозит, уходя, например, в своп, что приводит к потери части аудитории.
В общем, можно устроить хабратестирование — создать топик-обсуждение, где выложить тестовые сценарии и предложить всем выкладывать варианты их решения, после чего отобрать лучшие и опубликовать результаты в другом топике. А можно ещё сначала создать топик для обсуждения самих тестовых сценариев, чтобы были более-менее близки к практике, а не сферической вакуумной синтетикой.
И, кстати, наверное неплохо было бы гонять тесты на минимум двух конфигурациях железа: более-менее современной и достаточной для типовых задач в вебе и минимальной — увы, не редкость ситуация, когда на мощных девелоперских машинах всё летает, а на каком-нибудь нетбуке, бюджетном десктопе или вообще P4 с гигом памяти, который считался современным лет 10 назад (где нибудь в госконторах) нещадно тормозит, уходя, например, в своп, что приводит к потери части аудитории.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Сравнение производительности JS-библиотек