

Совсем недавно мы рассказывали о том, как деплоить приложения, написанные на Tarantool Cartridge. Но на деплое эксплуатация не заканчивается, поэтому сегодня мы обновим наше приложение и разберемся с тем, как управлять топологией, шардированием и авторизацией, а также изменять конфигурацию ролей.
Любознательных прошу под кат!
На чем мы остановились
В прошлый раз мы настроили следующую топологию:
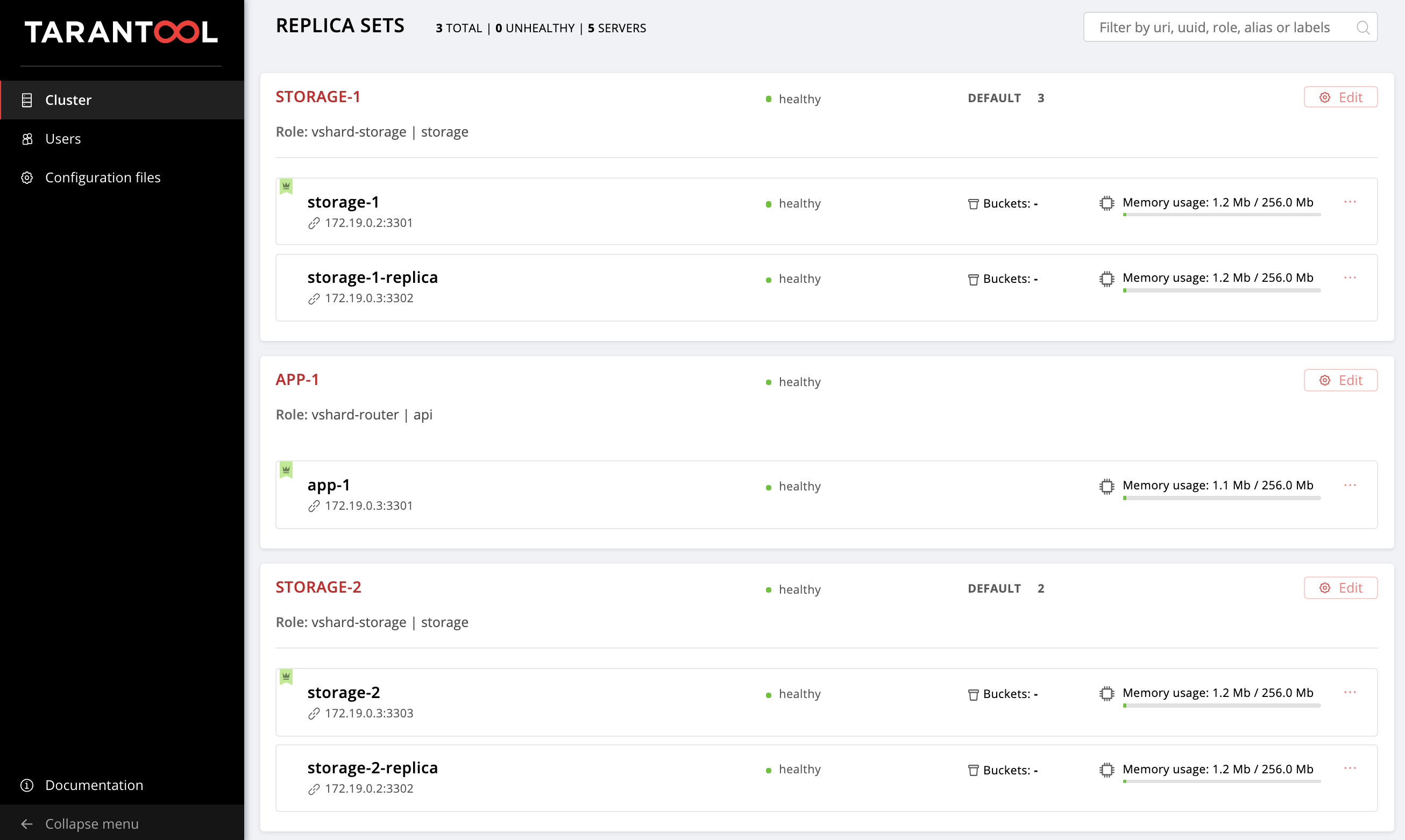
Репозиторий с примером успел немного измениться, там появились новые файлы, getting-started-app-2.0.0-0.rpm и hosts.updated.2.yml. Вам не обязательно пуллить новую версию, пакет вы можете просто скачать по ссылке, а hosts.updated.2.yml нужен только для того, чтобы вы могли подсмотреть туда при затруднениях с изменением текущего inventory.
Если вы проделали все шаги предыдущей части этого туториала, то сейчас у вас в файлике hosts.yml находится конфигурация кластера с двумя storage-репликасетами (в репозитории это hosts.updated.yml).
Поднимаем наши виртуалки:
$ vagrant upУстанавливаем новую версию Ansible-роли Tarantool Cartridge (она успела измениться, разумеется, в лучшую сторону):
$ ansible-galaxy install tarantool.cartridge,1.0.2Итак, текущая конфигурация кластера:
---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
storage-2:
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica:
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:
replicaset_storage_2:
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replicaset instances
storage-2:
storage-2-replica:Зайдите на http://localhost:8181/admin/cluster/dashboard и убедитесь, что ваш кластер находится в правильном состоянии.
Все как в прошлый раз: будем постепенно изменять этот файл и наблюдать за тем, как меняется кластер. Финальную версию вы всегда можете подсмотреть в hosts.updated.2.yml
Итак, начинаем!
Обновляем приложение
Для начала давайте обновим наше приложение. Убедитесь, что в текущей директории у вас находится файл getting-started-app-2.0.0-0.rpm (если нет, скачайте его из репозитория).
Указываем путь к новой версии пакета:
---
all:
vars:
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-2.0.0-0.rpm # <==
cartridge_enable_tarantool_repo: false # <==Мы указали cartridge_enable_tarantool_repo: false, чтобы роль не подключала репозиторий с пакетом Tarantool, который мы уже установили в прошлый раз. Это незначительно ускорит процесс деплоя, но совершенно не обязательно.
Запускаем плейбук с тегом cartridge-instances:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-instancesИ проверяем, что пакет обновился:
$ vagrant ssh vm1
[vagrant@svm1 ~]$ sudo yum list installed | grep getting-started-appПроверяем, что версия стала 2.0.0:
getting-started-app.x86_64 2.0.0-0 installedТеперь можно смело экспериментировать с новой версией приложения.
Включаем шардирование
Давайте включим шардирование, чтобы потом заняться управлением storage-репликасетами. Делается это очень просто. Добавляем в секцию all.vars переменную cartridge_bootstrap_vshard:
---
all:
vars:
...
cartridge_cluster_cookie: app-default-cookie # cluster cookie
cartridge_bootstrap_vshard: true # <==
...
hosts:
...
children:
...Запускаем:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-configОбратите внимание, мы указали тег cartridge-config, чтобы запустить только задачи, которые занимаются конфигурацией кластера.
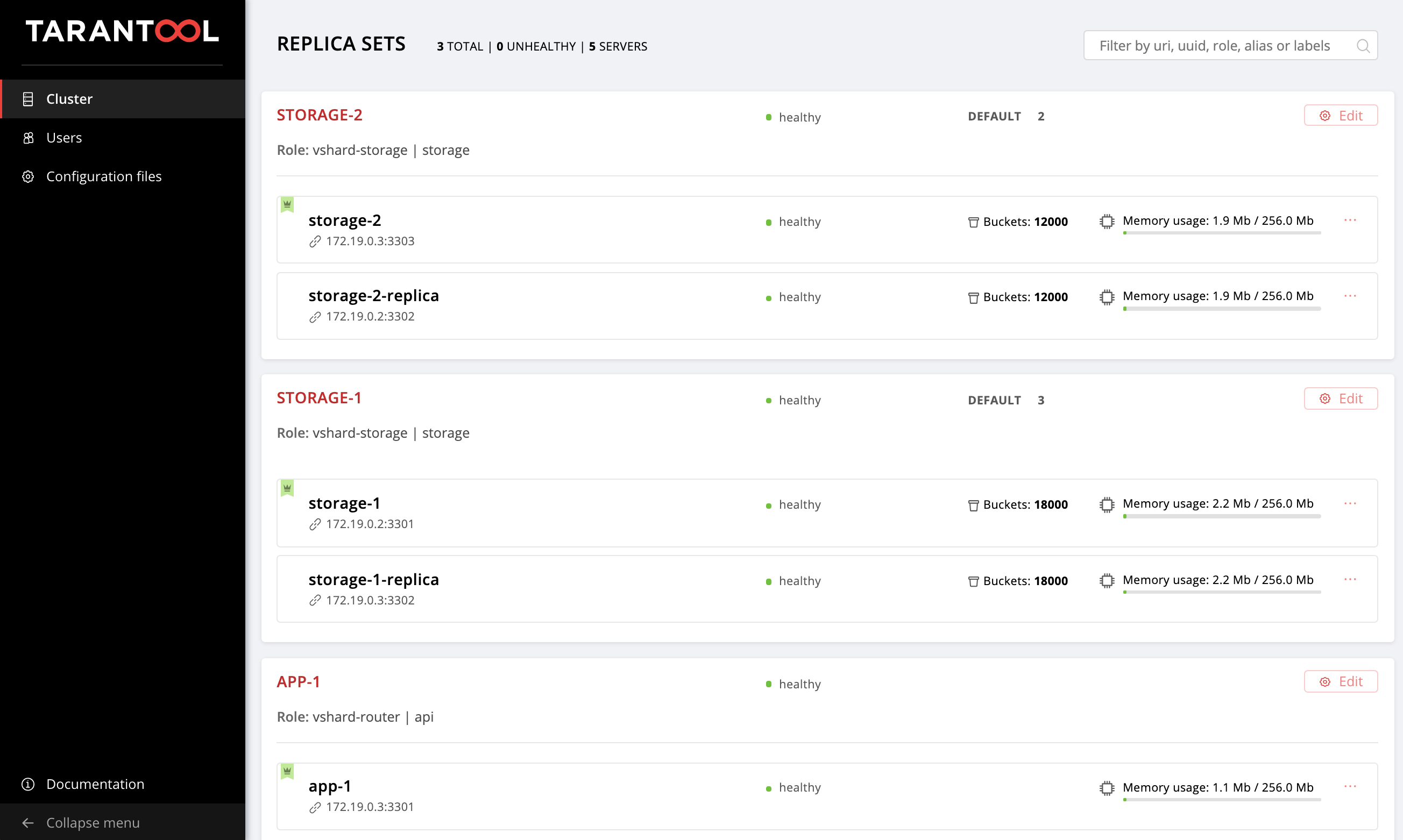
Открываем Web UI http://localhost:8181/admin/cluster/dashboard и видим, что наши бакеты распределились по storage-репликасетам в соотношении 2:3 (мы указали такие веса нашим репликасетам, помните?):
Включаем автоматический failover
А теперь включим режим автоматического failover-а, чтобы чуть позже на примере разобраться, что это и как оно работает.
Добавляем флаг cartridge_failover в конфиг:
---
all:
vars:
...
cartridge_cluster_cookie: app-default-cookie # cluster cookie
cartridge_bootstrap_vshard: true
cartridge_failover: true # <==
...
hosts:
...
children:
...Снова запускаем задачи по управлению кластером:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-configПосле успешного выполнения плейбука можете зайти в Web UI и убедиться, что свитчер Failover в правом верхнем углу переключился. Чтобы отключить режим автоматического failover-а, просто поменяйте значение cartridge_failover на false и запустите плейбук еще раз.
Самое время разобраться, что же это за режим такой и зачем мы его включили.
Разбираемся с failover-ом
Вы наверняка обратили внимание на переменную failover_priority, которую мы указали для каждого репликасета. Давайте разберемся, что это такое.
Tarantool Cartridge предоставляет режим автоматического восстановления после отказа (failover). У каждого репликасета есть лидер — инстанс, на который ведется запись. Если с лидером что-то случится, одна из реплик возьмет на себя его роль. Какая именно? Давайте посмотрим внимательно на репликасет storage-2:
---
all:
...
children:
...
replicaset_storage_2:
vars:
...
failover_priority:
- storage-2
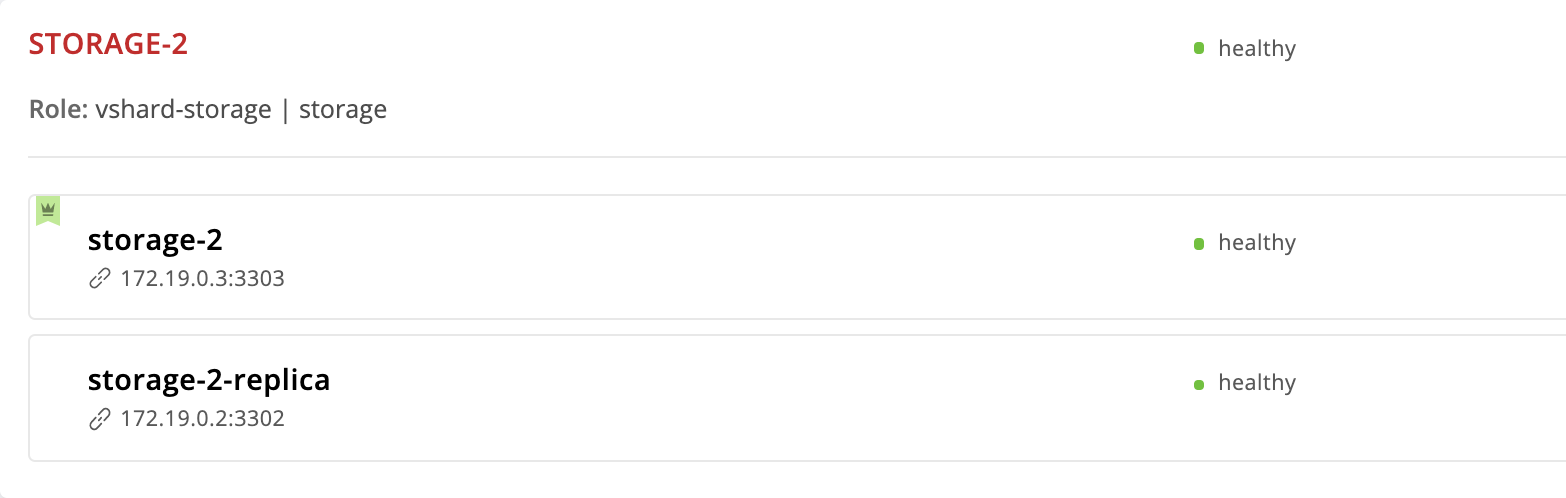
- storage-2-replicaИнстанс storage-2 мы указали первым в failover_priority. В Web UI он отображается первым в списке инстансов репликасета и помечен зеленой короной. Это и есть лидер — первый инстанс, указанный в failover_priority:
А теперь давайте посмотрим, что будет, если с лидером репликасета что-то случится. Заходим на виртуалку и останавливаем инстанс storage-2:
$ vagrant ssh vm2
[vagrant@vm2 ~]$ sudo systemctl stop getting-started-app@storage-2Возвращаемся в Web UI:

Корона у инстанса storage-2 стала красной — это значит, что назначенный лидер нездоров. А вот у storage-2-replica появилась зеленая корона — этот инстанс взял на себя обязанности лидера, пока storage-2 не вернется в строй. Это и есть автоматический failover в действии.
Давайте оживим storage-2:
$ vagrant ssh vm2
[vagrant@vm2 ~]$ sudo systemctl start getting-started-app@storage-2Все вернулось на круги своя:
Давайте поменяем порядок инстансов в приоритете failover-а. Инстанс storage-2-replica сделаем лидером, а storage-2 уберем из списка вообще:
---
all:
vars:
...
hosts:
...
children:
...
replicaset_storage_2:
vars: # replicaset configuration
...
failover_priority:
- storage-2-replica # <==
...Запускаем задачи cartridge-replicasets для инстансов из группы replicaset_storage_2:
$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasetsЗаходим на http://localhost:8181/admin/cluster/dashboard и видим, что лидер изменился:
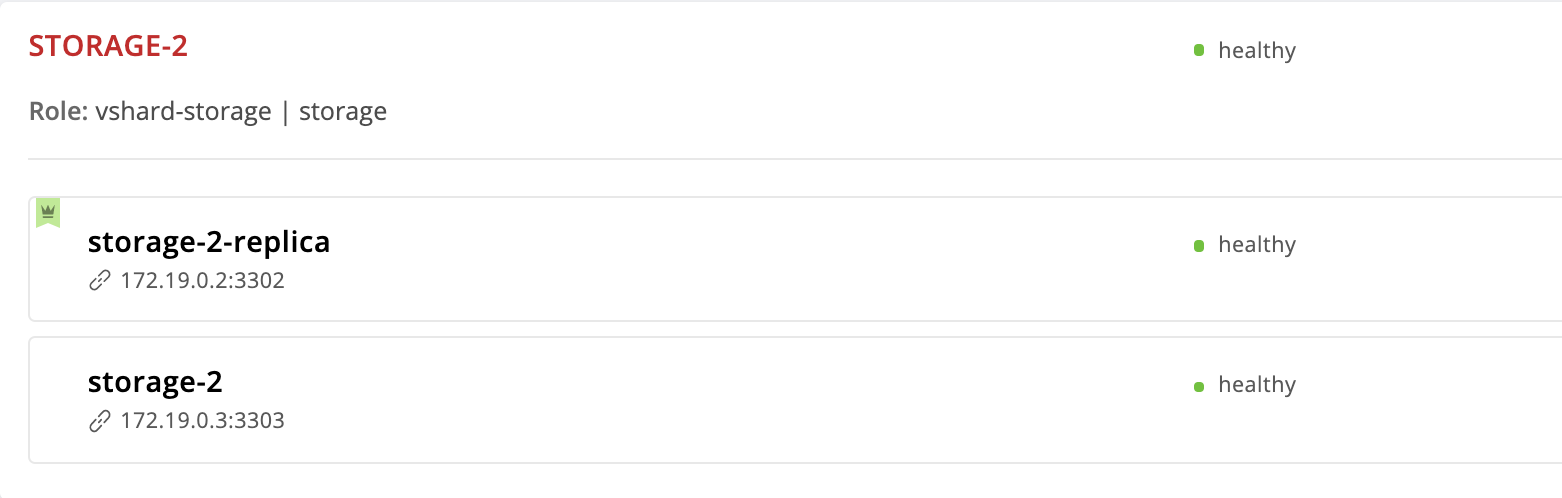
Но мы же убрали инстанс storage-2 из конфигурации, почему он все еще здесь? Дело в том, что Cartridge, получая на вход новое значение failover_priority упорядочивает инстансы следующим образом: лидером становится первый инстанс из списка, дальше следуют остальные указанные инстансы. Инстансы, не упомянутые в failover_priority будут упорядочены по UUID и добавлены в конец.
Изгнание инстанса
Но что делать, если мы хотим исключить инстанс из топологии? Все очень просто: нужно передать ему флаг expelled. Давайте исключим инстанс storage-2-replica. Сейчас он является лидером, поэтому Cartridge не разрешит нам этого сделать. Но мы не боимся трудностей, и все же попробуем:
---
all:
vars:
...
hosts:
storage-2-replica:
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
expelled: true # <==
...Указываем тег cartridge-replicasets, поскольку изгнание (expel) инстанса — это изменение топологии:
$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasetsЗапускаем плейбук и видим ошибку:

Как мы только что убедились, Cartridge не позволяет просто так выкинуть из топологии текущего лидера репликасета. Это вполне логично, поскольку репликация асинхронная, исключение лидера скорее всего повлечет за собой потерю данных. Нам нужно указать другого лидера и только после этого исключать инстанс. Роль сначала применит новую конфигурацию репликасета, а затем займется исключением. Поэтому меняем failover_priority и запускаем плейбук еще раз:
---
all:
vars:
...
hosts:
...
children:
...
replicaset_storage_2:
vars: # replicaset configuration
...
failover_priority:
- storage-2 # <==
...$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasetsВуаля, инстанс storage-2-replica исчез из топологии!

Обратите внимание, что изгнание инстанса действительно окончательное и безвозвратное. После удаления инстанса из топологии, наша ansible-роль остановит systemd-сервис и удалит все файлы этого инстанса.

Если вы вдруг передумали и решили, что репликасету storage-2 все же нужен второй инстанс, восстановить его не получится. Cartridge запоминает UUID всех инстансов, покинувших топологию, и не разрешит изгнаннику вернуться обратно. Вы можете поднять новый инстанс с таким же именем и конфигурацией, но UUID у него, очевидно, будет другой, поэтому Cartridge разрешит ему присоединиться.
Удаление репликасета
Мы уже выяснили, что изгнать лидера репликасета нам не разрешат. Но что делать, если мы захотим удалить репликасет storage-2 окончательно? Выход, разумеется, есть.
Чтобы не потерять данные, мы должны сначала перенести все бакеты в storage-1, для этого установим вес репликасета storage-2 равным 0:
---
all:
vars:
...
hosts:
...
children:
...
replicaset_storage_2:
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 0 # <==
...
...Запускаем управление топологией:
$ ansible-playbook -i hosts.yml playbook.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasetsОткрываем Web UI http://localhost:8181/admin/cluster/dashboard и наблюдаем, как все бакеты перетекают в storage-1:

Выставим лидеру storage-2 флаг expelled и попрощаемся с этим репликасетом:
---
all:
vars:
...
hosts:
...
storage-2:
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
expelled: true # <==
...$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-replicasetsОбратите внимание, на этот раз мы не указали опцию limit, поскольку хотя бы один инстанс из всех, для которых мы запустили плейбук, должен быть не помечен как expelled.
Вот мы и вернулись к изначальной топологии:
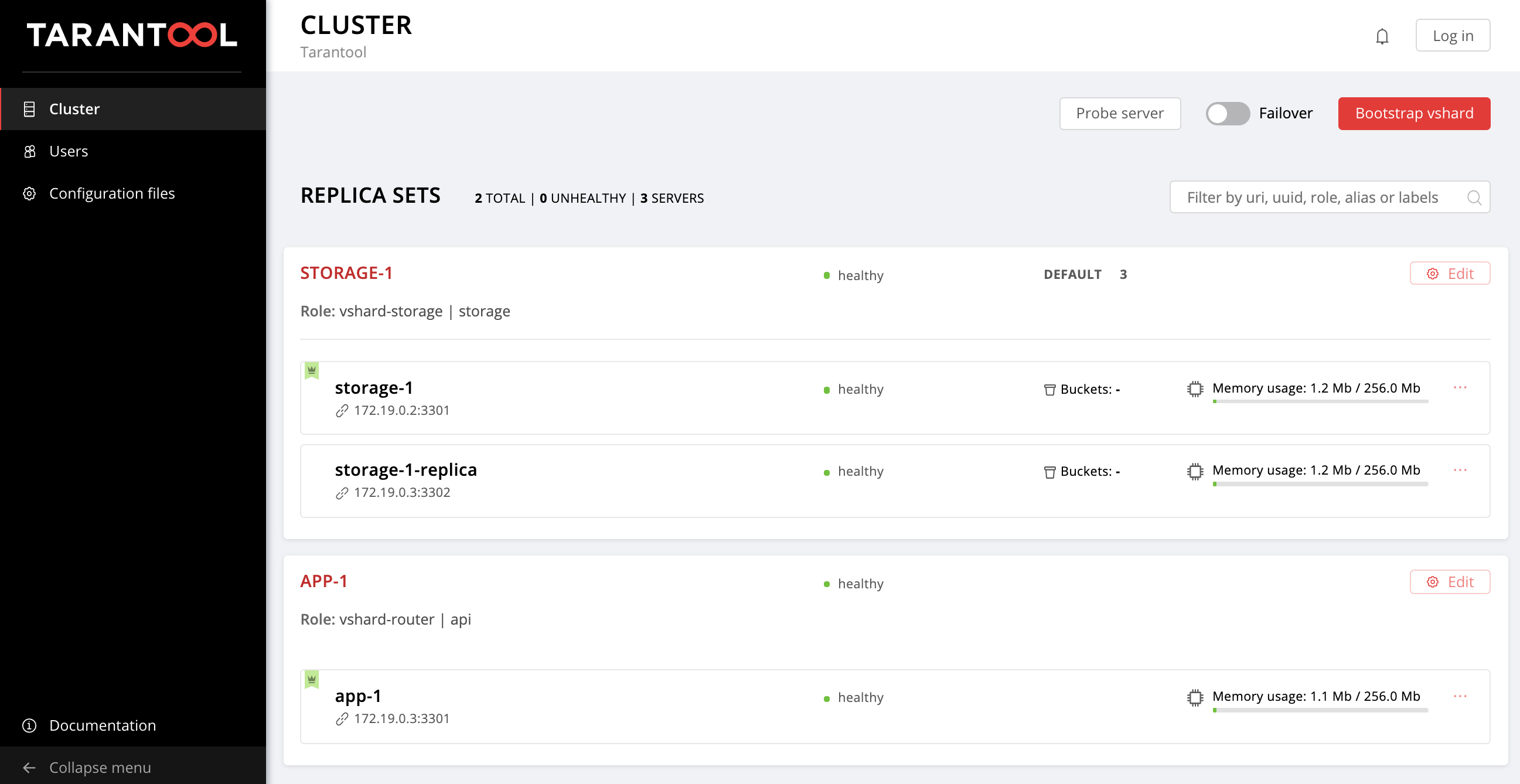
Авторизация
Предлагаю отвлечься от управления репликасетами и подумать о безопасности. Сейчас управлять кластером через Web UI может любой неавторизованный пользователь. Согласитесь, выглядит так себе.
Cartridge предоставляет возможность подключить свой собственный модуль авторизации, например LDAP (или что у вас там), и использовать его для управления пользователями и их доступом к приложению. Но мы воспользуемся встроенным модулем авторизации, который Cartridge использует по умолчанию. Этот модуль позволяет выполнять базовые операции с пользователями (удалять, добавлять, редактировать) и реализует функцию проверки пароля.
Обратите внимание, что наша ansible-роль требует от авторизационного бэкенда реализацию всех этих функций.
Итак, переходим от теории к практике. Для начала сделаем авторизацию обязательной, зададим параметры сессии и добавим нового пользователя:
---
all:
vars:
...
# authorization
cartridge_auth: # <==
enabled: true # enable authorization
cookie_max_age: 1000
cookie_renew_age: 100
users: # cartridge users to set up
- username: dokshina
password: cartridge-rullez
fullname: Elizaveta Dokshina
email: dokshina@example.com
# deleted: true # uncomment to delete user
...Управление авторизацией выполняется в рамках задач cartridge-config, укажем этот тег:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-configНа http://localhost:8181/admin/cluster/dashboard нас ждет сюрприз:
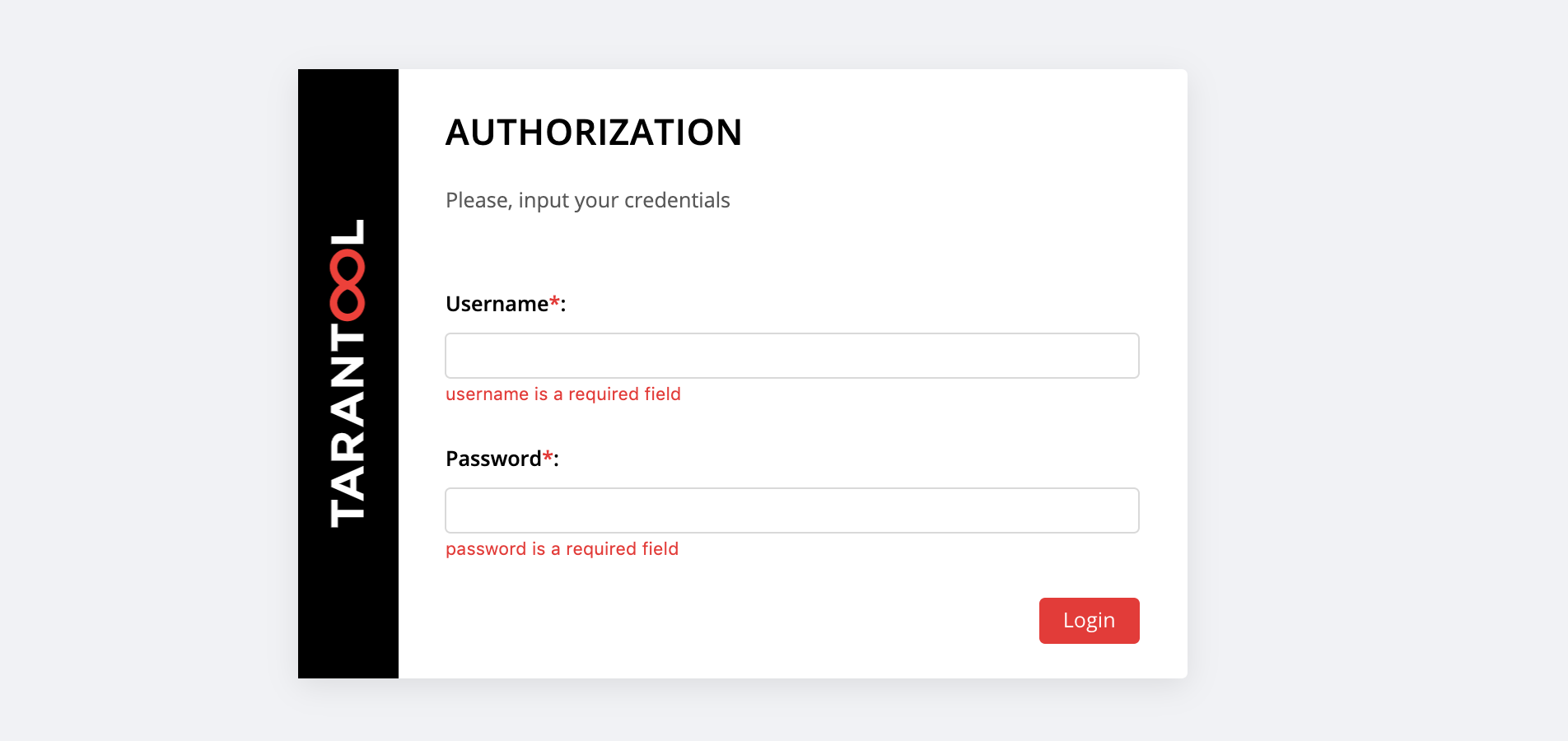
Вы можете залогиниться с username и password нашего нового пользователя или войти как admin — пользователь по умолчанию. Его пароль — это cluster cookie, мы указали это значение в переменной cartridge_cluster_cookie (это app-default-cookie, можете не подсматривать).
После успешного логина открываем вкладку Users, чтобы убедиться, что все прошло удачно:

Поэкспериментируйте с добавлением новых пользователей и изменением их параметров. Чтобы удалить пользователя, укажите для него флаг deleted: true. Значения email и fullname никак не используются Cartridge, но вы можете указать их для удобства.
Конфигурация приложения
Давайте вспомним, с чего все начиналось.
Мы с вами деплоили небольшое приложение, которое хранит данные о клиентах и их банковских счетах. Как вы помните, у этого приложения реализованы 2 роли: api и storage. Роль storage занимается хранением данных и реализует шардирование при помощи встроенной роли vshard-storage. Вторая роль, api, реализует HTTP-сервер с API для управления данными, плюс внутри у нее подключена еще одна стандартная роль, vshard-router, которая управляет шардированием.
Итак, делаем первый запрос к API приложения. Добавим нового клиента:
$ curl -X POST -H "Content-Type: application/json" \
-d '{"customer_id":1, "name":"Elizaveta", "accounts":[{"account_id": 1}]}' \
http://localhost:8182/storage/customers/createВ ответ получаем что-то такое:
{"info":"Successfully created"}Обратите внимание, что в URL мы указали порт инстанса app-1, 8082, поскольку именно он реализует данный API.
Теперь давайте обновим баланс нашего нового пользователя:
$ curl -X POST -H "Content-Type: application/json" \
-d "{\"account_id\": 1, \"amount\": \"1000\"}" \
http://localhost:8182/storage/customers/1/update_balanceВ ответе видим обновленный баланс:
{"balance":"1000.00"}Отлично, все работает! API реализован, шардированием данных занимается Cartridge, failover priority на экстренный случай мы уже настроили и даже авторизацию включили. Самое время заняться конфигурацией приложения.
Текущая конфигурация кластера хранится в распределенном конфиг-файле. Каждый инстанс хранит у себя копию этого файла, а Cartridge обеспечивает его синхронизацию среди всех узлов кластера. Мы можем указать в этом файле конфигурацию ролей нашего приложения, а Cartridge позаботится о том, чтобы распространить новую конфигурацию по всем инстансам.
Давайте посмотрим на текущее содержимое этого файла. Переходим на вкладку Cofiguration files и нажимаем на кнопку Download:

В скаченном файлике config.yml мы обнаружим пустую таблицу. Ничего удивительного, ведь мы еще не указали никаких параметров:
--- []
...На самом деле, конфиг-файл нашего кластера не пустой, в нем хранится текущая топология, настройки авторизации и параметры шардирования. Но Cartridge не станет так просто делиться этой информацией, она предназначена для внутреннего использования, и поэтому хранится в скрытых системных секциях, которые мы с вами не можем редактировать.
Каждая роль приложения может использовать одну или несколько секций конфигурации. Загрузка новой конфигурации происходит в два этапа: сначала все роли проверяют, что готовы принять новые параметры. Если возражений нет, то изменения применяются, если кто-то против, то происходит откат.
Вернемся к нашему приложению. Роль api использует секцию max-balance, где хранится максимальный допустимый баланс на одном счету клиента. Давайте настроим эту секцию, но, разумеется, не вручную, а с использованием нашей Ansible-роли.
Итак, сейчас конфиг приложения (точнее его часть, доступная нам) это пустая таблица. Добавим в него секцию max-balance со значением 100000. Прописываем переменную cartridge_app_config в наш inventory-файл:
---
all:
vars:
...
# cluster-wide config
cartridge_app_config: # <==
max-balance: # section name
body: 1000000 # section body
# deleted: true # uncomment to delete section max-balance
...Мы указали имя секции, max-balance, и ее содержимое, body. Содержимое секции может быть не только числом, это также может быть таблица или строка в зависимости от того, как написана роль, и какой тип значения вы хотите использовать.
Запускаем:
$ ansible-playbook -i hosts.yml playbook.yml \
--tags cartridge-configИ проверяем, что максимальный допустимый баланс действительно изменился:
$ curl -X POST -H "Content-Type: application/json" \
-d "{\"account_id\": 1, \"amount\": \"1000001\"}" \
http://localhost:8182/storage/customers/1/update_balanceВ ответ получаем ошибку, как мы и хотели:
{"info":"Error","error":"Maximum is 1000000"}Вы можете заново скачать файл с конфигурацией на вкладке Configuraion files, чтобы убедиться, что там появилась новая секция:
---
max-balance: 1000000
...Попробуйте добавить в конфигурацию приложения новые секции, поменять их содержимое или вовсе удалить (для этого нужно установить в секции флаг deleted: true).
О том, как использовать распределенный конфиг в ролях, вы можете узнать в документации Tarantool Cartridge.
Не забудьте вызвать vagrant halt, чтобы остановить виртуалки, когда закончите с ними работать.
В заключение
В прошлый раз мы научились деплоить распределенные Tarantool Cartridge-приложения при помощи специальной Ansible-роли. Сегодня мы обновили приложение, а также освоили управление топологией, шардированием, авторизацией и конфигурацией приложения.
Не останавливайтесь на достигнутом, изучайте различные подходы к написанию Ansible-плейбуков и эксплуатируйте свои приложения с максимальным комфортом.
Если у вас что-то не работает или есть идеи, как улучшить нашу ansible-роль, не стесняйтесь, заводите тикет. Мы всегда поможем с решением вашей проблемы и будем рады интересным предложениям!
