

Среда исполнения Java в последние годы развивалась быстрее, чем раньше. Спустя 15 лет мы наконец-то получили сборщик мусора по умолчанию — G1. Ещё два в разработке и доступны в качестве экспериментальных функций — Oracle ZGC и OpenJDK Shenandoah. Мы решили протестировать все эти новые инструменты и выяснить, что лучше работает с нагрузками, типичными для распределённого opensource-движка потоковой обработки Hazelcast Jet.
Jet используется для решения всевозможных задач, с разными требованиями к задержке и пропускной способности. Задачи делятся на три важные категории:
- Неограниченная потоковая обработка с низкой задержкой. Пример: выявление тенденций в данных с датчиков 10 000 устройств, которые снимают информацию с частотой 100 Гц, и отправка поправок в течение 10-20 мс.
- Неограниченная потоковая обработка с высокой пропускной способностью. Пример: отслеживание GPS-координат миллионов пользователей с вычислением векторов их скоростей.
- Классическая пакетная обработка больших данных. Критерием является время, потраченное на обработку, а значит требуется высокая пропускная способность. Пример: анализ собранных за день данных по биржевым торгам для обновления уровня рисков для заданного портфеля активов.
Сначала мы можем наблюдать следующее:
- В первом сценарии требования к задержке попадают в опасную зону пауз сборщика мусора: 100 мс. Это считается прекрасным результатом для сборки мусора в самых тяжёлых случаях, и во многих ситуациях может стать камнем преткновения.
- Второй и третий сценарии идентичны по требованиям к сборке мусора. Требования к задержке менее суровые, но большая нагрузка на tenured-поколения.
- Второй сценарий труднее из-за требований к задержке, пусть даже и не таких жёстких, как в первом сценарии.
Мы попробовали такие комбинации:
- JDK 8 со сборщиком по умолчанию Parallel и опциональными ConcurrentMarkSweep и G1.
- JDK 11 со сборщиком по умолчанию G1 и опциональным Parallel.
- JDK 14 со сборщиком по умолчанию G1 и экспериментальными ZGC и Shenandoah.
Пришли к таким выводам:
- С современными версиями JDK сборщик G1 работает шикарно. Он с лёгкостью обрабатывает кучи (heap) в десятки гигабайтов (мы пробовали 60 Гб), с максимальными паузами в 200 мс. При экстремальной нагрузке G1 не переходит в кошмарные критические режимы. Вместо этого длительность пауз на полную сборку мусора возрастает до секунд. Слабым местом сборщика является верхняя граница пауз в благоприятных условиях низкой нагрузки. Нам удалось понизить её до 20-25 мс.
- JDK 8 — устаревшая среда исполнения. Сборщик по умолчанию Parallel работает с огромными паузами на полную сборку. С G1 такие паузы возникают реже, однако они ещё длиннее, потому что здесь применяется старая версия сборщика, которая использует лишь один поток. Даже на куче среднего размера в 12 Гб паузы достигали 20 секунд с Parallel и целой минуты с G1. ConcurrentMarkSweep во всех случаях работал гораздо хуже G1, а его критический режим приводил к многоминутным паузам на полную сборку.
- Хотя у ZGC пропускная способность намного ниже, чем у G1, однако он лучше вёл себя при небольшой нагрузке, когда G1 время от времени увеличивал задержку до 10 мс.
- Shenandoah разочаровал нас случайными регулярными увеличениями задержки до 220 мс при небольшой нагрузке.
- Ни ZGC, ни Shenandoah не вели себя в критических режимах так же устойчиво, как G1. Их работа была ненадёжной, в режиме с низкой задержкой неожиданно возникали очень долгие паузы, и даже OOME.
В этой статье описаны результаты наших тестов в двух сценариях потоковой обработки. Во второй части мы расскажем о результатах пакетной обработки.
Бенчмарк потоковой обработки
Для потокового бенчмарка мы взяли этот код и немного его меняли между тестами. Вот основная часть, конвейер Jet:
StreamStage<Long> source = p.readFrom(longSource(ITEMS_PER_SECOND))
.withNativeTimestamps(0)
.rebalance(); // Introduced in Jet 4.2
source.groupingKey(n -> n % NUM_KEYS)
.window(sliding(SECONDS.toMillis(WIN_SIZE_SECONDS), SLIDING_STEP_MILLIS))
.aggregate(counting())
.filter(kwr -> kwr.getKey() % DIAGNOSTIC_KEYSET_DOWNSAMPLING_FACTOR == 0)
.window(tumbling(SLIDING_STEP_MILLIS))
.aggregate(counting())
.writeTo(Sinks.logger(wr -> String.format("time %,d: latency %,d ms, cca. %,d keys",
simpleTime(wr.end()),
NANOSECONDS.toMillis(System.nanoTime()) - wr.end(),
wr.result() * DIAGNOSTIC_KEYSET_DOWNSAMPLING_FACTOR)));
Этот конвейер отражает сценарии использования с неограниченным потоком событий. Движок должен агрегировать данные методом «скользящего окна». Такая агрегация нужна, к примеру, для получения производной по времени от изменяющейся величины, для очистки данных от высокочастотного шума (сглаживания) или для измерения частоты возникновения какого-то события (событий в секунду). Движок может сначала разделить поток по категориям (скажем, все отдельные IoT-устройства или смартфоны) на подпотоки. А затем независимо отслеживать агрегированное значение по каждому подпотоку. В Hazelcast Jet скользящее окно движется дискретными шагами, размер которых вы задаёте. Например, при шаге в 1 секунду вы получаете полный набор результатов каждую секунду. А при шаге в 1 минуту результаты будут включать в себя всё, что произошло за последнюю минуту.
Некоторые примечания.
Код полностью самодостаточен. Внешние источники данных не используются. Мы используем источник-заглушку для эмуляции потока событий с нужной частотой. События происходят через равные промежутки времени. Источник не генерирует события, временные метки которых относятся к будущему, однако он генерирует их как можно быстрее.
Если конвейер отстаёт, то события «буферизируются» без сохранения. В этом случае конвейер должен всё наверстать, как можно скорее принимая данные. Поскольку наш источник не распараллелен, предел его пропускной способности достигал около 2,2 млн событий в секунду. Мы эмулировали 1 млн событий/с., оставив запас для навёрстывания в 1,2 млн событий/с.
Конвейер измеряет свою задержку, сравнивая временную метку результата скользящего окна с текущим временем. Применялись две стадии агрегации с промежуточным фильтрованием. Результат одного скользящего окна содержит много элементов, по одному для каждого подпотока, и нас интересует задержка для последнего из элементов. Поэтому сначала мы отфильтровываем большую часть результата, оставляя каждый десятитысячный элемент. А затем направляем уменьшенный поток во вторую стадию, с «переворачивающимся» окном без ключа. На этой стадии мы отмечаем размер полученного результата и измеряем задержку. Агрегирование без применения ключа не распараллелено, поэтому у нас одна точка измерения. Стадия фильтрации распараллелена и является data-local, поэтому влияние дополнительной стадии агрегации очень мало (гораздо ниже 1 мс).
Мы использовали простую агрегирующую функцию: подсчёт. Фактически, получали метрику частоты событий в потоке. У него минимальная структура (одно число типа
long), мусор не генерируется. При любом объёме использования кучи (в гигабайтах) такое маленькая структура на ключ подразумевает наихудший сценарий для сборщика мусора: очень большое количество объектов. Нагрузка на сборщик растёт не с размером кучи, а с количеством объектов. Также мы протестировали вариант с вычислением той же агрегирующей функции, но с другой реализацией, которая генерирует мусор.Большую часть потоковых бенчмарков мы прогнали на одной ноде, потому что нас интересовало влияние управления памятью на производительность конвейера. А сетевая задержка только добавляет шума в данные. Для проверки гипотезы о том, что производительность кластера не повлияет на наши выводы, мы повторили некоторые ключевые тесты на кластере Amazon EC2 из трёх узлов. Подробнее об этом будет рассказано ближе к концу второй статьи.
Мы убрали из результатов потоковой нагрузки сборщик Parallel, потому что создаваемые им пики задержки неприемлемы в большинстве реальных сценариев.
Первый сценарий: низкая задержка, средняя структура
Параметры сценария:
- OpenJDK 14
- Размер кучи JVM — 4 Гб.
- Для G1 задано
-XX:MaxGCPauseMillis=5 - 1 млн событий/с.
- 50 000 отдельных ключей.
- 30-секундное скользящее окно через 0,1 секунды.
При таком сценарии используется меньше 1 Гб кучи. Нагрузка на сборщик небольшая, у него достаточно времени для фоновой конкурентной сборки мусора. Вот максимальные задержки в работе конвейера с тремя протестированными сборщиками:
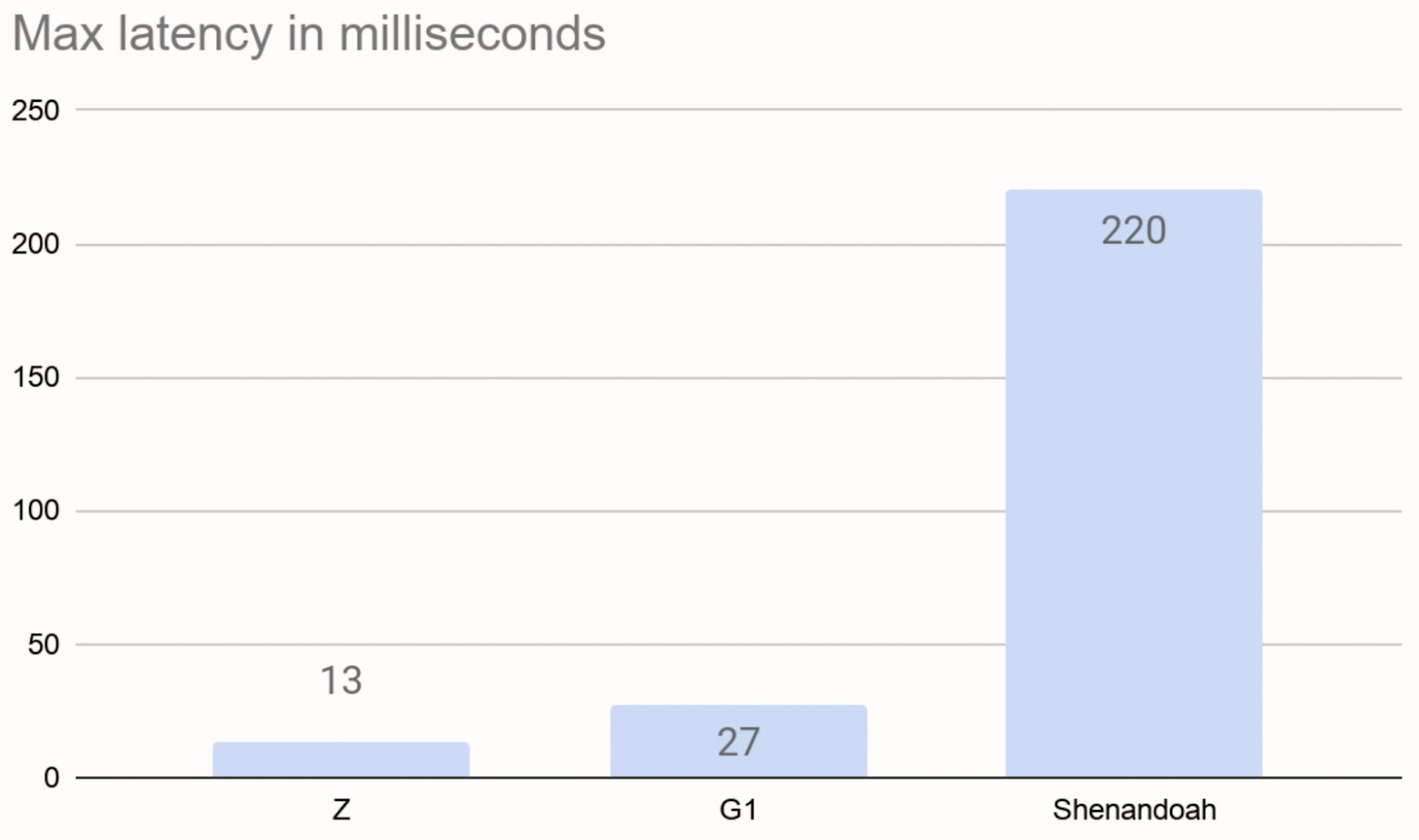
Эти значения включают в себя фиксированные промежутки примерно в 3 мс на передачу результатов окна. График говорит сам за себя: сборщик по умолчанию G1 отлично справляется, но если вам нужна задержка ещё ниже, можете использовать экспериментальный ZGC. Мы не смогли опустить пики задержки ниже 10 мс. Но в случае с ZGC и Shenandoah они возникают не из-за пауз на сборку мусора, а из-за коротких периодов возросшего объёма фоновой работы сборщиков. Иногда служебные процессы в Shenandoah поднимали задержку выше 200 мс.
Второй сценарий: большая структура, менее строгие требования к задержке
Мы предполагаем, что по не зависящим от нас причинам (например, из-за сотовой сети) задержка может возрастать до секунд. Это смягчает требования к конвейеру потоковой обработки. С другой стороны, мы можем столкнуться с куда более крупными данными, размером в миллионы или десятки миллионов ключей.
При таком сценарии мы можем подготовить оборудование к интенсивному использованию, с учётом того, что сборщик мусора будет оперировать большой кучей, а не распределять данные по многочисленным нодам кластера.
Мы прогнали много тестов в разных комбинациях, чтобы выяснить, как сочетания факторов влияют на эффективность работы среды исполнения. Выяснилось, что это зависит от двух параметров:
- Количество записей, хранящихся в агрегатах.
- Требование к пропускной способности для навёрстывания.
Первый параметр описывает количество объектов в tenured-поколении. При агрегировании по методу скользящего окна мы длительное время (на протяжении окна) удерживаем объекты, а затем освобождаем их. Это прямо противоречит гипотезе о сборке мусора с учётом разных поколений (Generational Garbage Hypothesis), которая утверждает, что объекты либо умирают молодыми, либо живут вечно. При таком режиме создаётся максимальная нагрузка на сборщик мусора. А поскольку интенсивность его работы растёт с количеством живых объектов, производительность сильно зависит от этого параметра.
Второй параметра связан с тем, какой объём ресурсов приложение может выделить сборщику мусора. Чтобы было понятнее, давайте построим несколько диаграмм. При агрегировании по методу скользящего окна конвейер проходит через три этапа:
- Обработка событий в реальном времени по мере их возникновения.
- Передача результатов скользящего окна.
- Навёрстывание событий, полученных в течение второго этапа.
Все три этапа можно визуализировать так:

Если передача результатов окна занимает больше времени, мы оказываемся в такой ситуации:

Теперь конвейер едва успевает, и все любые временные задержки вроде пауз на сборку мусора будут увеличивать задержку, и восстанавливаться она будет очень медленно.
Давайте изменим график и покажем только среднюю скорость поглощения событий после передачи результатов окна:
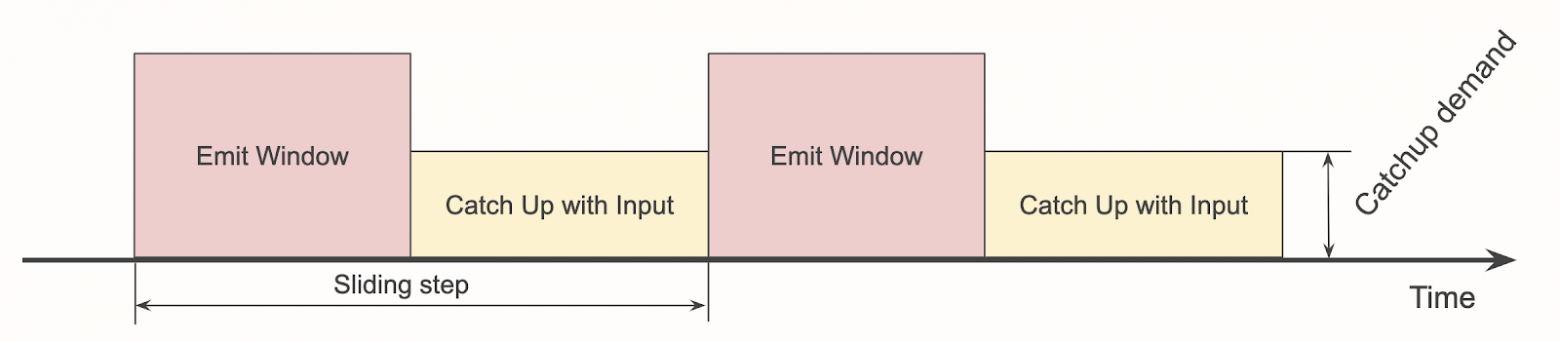
Назовём высоту жёлтого прямоугольника «требованием к навёрстыванию»: это требование к пропускной способности источника. Если она превышает фактическую пропускную способность конвейера, то он не справляется с нагрузкой.
Вот как это будет выглядеть, если передача результатов окна будет занимать слишком много времени:

Площадь красного и жёлтого прямоугольников фиксирована и соответствует объёму данных, которые должны пройти через конвейер. По сути, красный «сжимает» жёлтый. Но высота жёлтого прямоугольника ограничена, в нашем случае потолок — 2,2 млн событий/с. И когда высота превысит ограничение, мы получим не справляющийся с нагрузкой конвейер и неограниченно растущую задержку.
Мы вывели формулы прогнозирования размеров прямоугольников для заданной комбинации частоты событий, размера окна, шага скольжения и размера набора ключей. Так мы можем для любого случая определять требование к навёрстыванию.
Теперь у нас есть два более-менее независимых параметра, полученных на основе многих других параметров, которые описывают каждую отдельную комбинацию. Можно построить двумерный график, круги на котором обозначают прогнанные бенчмарки. Раскрасим круги в соответствии с успешностью или неудачностью комбинации. Например, для связки JDK 14 с G1, работающей на ноутбуке, мы получим такой график:

Мы выделили три категории:
- «да» — конвейер справляется,
- «нет» — конвейер не справляется из-за нехватки пропускной способности,
- «сборщик мусора» — конвейер не справляется из-за частых длинных пауз на сборку.
Обратите внимание, что нехватка пропускной способности может возникнуть также из-за конкурентной сборки мусора и частых коротких пауз на сборку. В целом, разница между двумя последними категориями невелика.
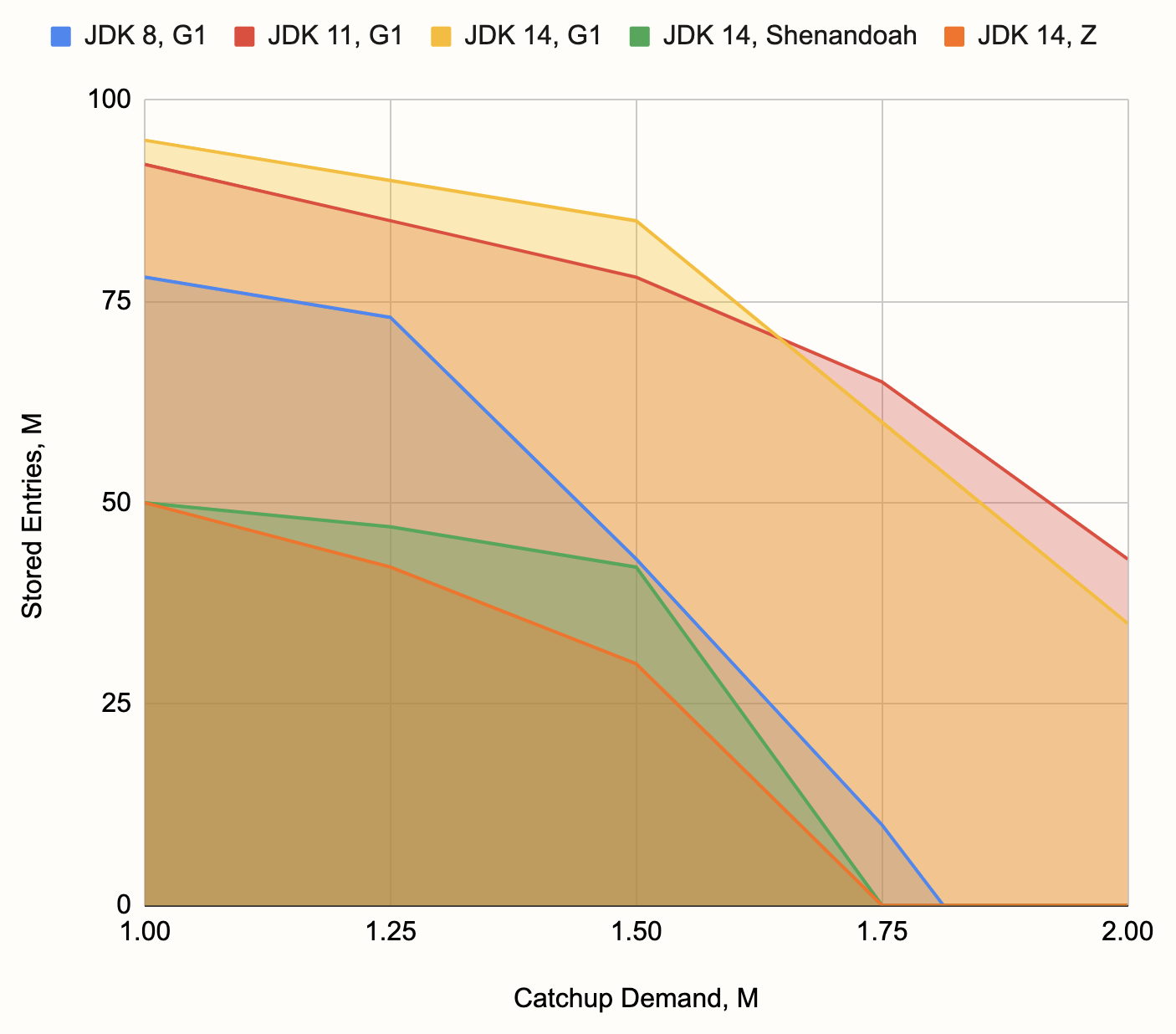
Вы можете увидеть границу, отделяющую нижнюю левую часть графика. В ней расположены точки успешно пройденных бенчмарков. Мы построили такой же график для других комбинаций JDK и сборщика мусора, выделили границы зон и получили такой результат:
У нас был MacBook Pro 2018 с 6-ядерным Intel Core i7 и 16 Гб DDR4 RAM. Для JVM было настроено
-Xmx10g. Однако мы считаем, что подобная картина будет наблюдаться и на многих других конфигурациях. График демонстрирует превосходство G1 над другими сборщиками, слабость G1 при использовании с JDK 8, а также слабость экспериментальных сборщиков с низкой задержкой при такого рода нагрузке.Базовая задержка — длительность передачи результатов окна — колебалась в районе 500 мс. Однако часто возникали всплески из-за основных пауз на сборку мусора (которые в случае с G1 были неоправданно длинными), вплость до 10 с в пограничных ситуациях (когда конвейер едва справлялся с работой) и снижается до 1-2 с. Мы также заметили влияние JIT-компиляции в пограничных ситуациях: конвейер начинает работать с постоянно растущей задержкой, а примерно через две минуты производительность улучшается и задержка возвращается к нормальным значениям.
