

Storage Corridor by St-Pete
Всем привет! Я Mons Anderson, архитектор платформы Mail.ru Cloud Solutions, расскажу, как мы построили наше S3-хранилище, как оно работает, какие решения оказались удачными, а какие стоило изменить, если бы мы начали такой же проект с нуля сейчас.
Статья подготовлена на основе доклада на @Databases Meetup by Mail.ru Cloud Solutions & Tarantool. В статье поговорим:
- как было устроено хранилище Mail.ru, поверх которого мы строили S3-хранилище;
- что мы добавили, чтобы сделать Mail.ru Cloud Storage;
- как работает объектная модель хранения и какие сделаны шаги для выхода в продакшен;
- про доработки боевой системы: фейловер и масштабирование;
- как мы реализовали шардирование и решардинг;
- а также про работу с SSL-сертификатами.
Если не хотите читать, можно посмотреть.
Как было устроено хранилище Mail.ru, поверх которого мы строили S3-хранилище
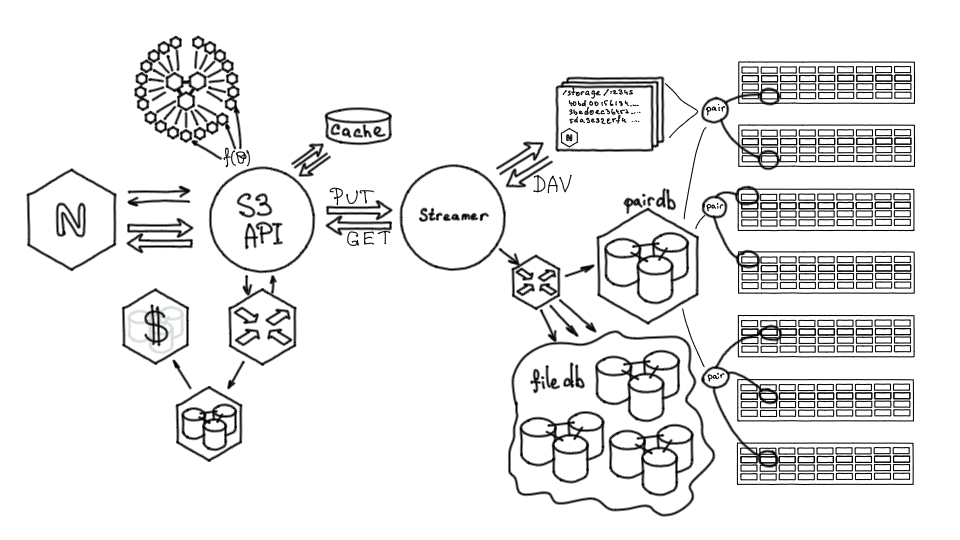
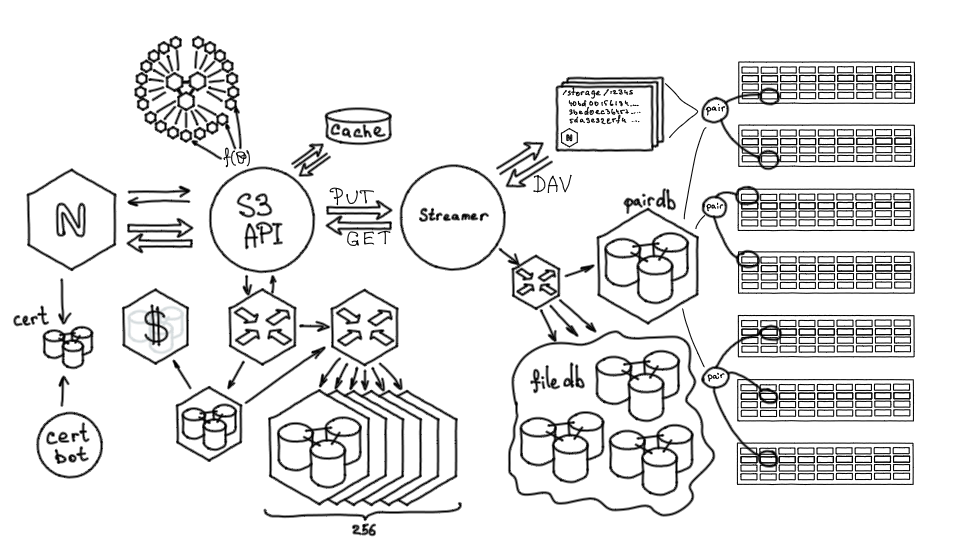
Разработка нашего S3 началась поверх хранилища Облака Mail.ru, поэтому изначально стоит рассказать, как оно устроено и что умеет.
Хранилище облака Mail.ru состоит из серверов с дисками. В среднем современный storage-сервер — это 36 дисков по 12–14 терабайт. Раньше диски были меньше, но за три года объемы дисков выросли и сегодня это почти полпетабайта сырых данных.
Диски с разных серверов хранилища объединяются в так называемые «пары» (pair). Пара — это единичный unit хранения файлов. По сути, это диск, смонтированный в определенный раздел по определенному пути, где могут лежать файлы, идентифицированные хэшами.
Пара — это историческое название, оно сохранилось до сегодняшнего дня, хотя сейчас в паре не обязательно только два диска. Дисков может быть три, а также могут быть различные гибридные хранения, например 3/2.
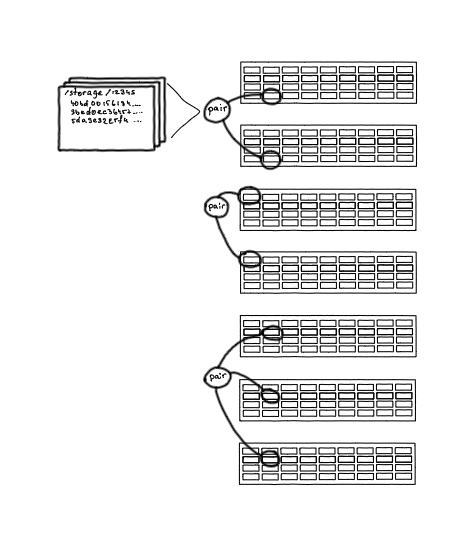
Пары (pair) — единицы хранения объектов
Все пары хранятся в PairDB — это приложение на базе Tarantool. Все базы в нашем хранилище, начиная с самых первых, — это Tarantool, других баз мы не используем.
PairDB хранит все пары, их состояния, свободное место, возможности отказа, последние ошибки. Также она может сама ходить на пары, актуализировать их состояние, проверять, работают они или нет. То есть PairDB — такой общий снимок состояния всех дисков нашей системы.

Pair DB: база данных с состоянием пар
На парах хранятся файлы, и, чтобы знать, на какой паре какой файл находится, нужна еще одна база — FileDB. Она хранит маппинг, определение соответствия: файл такой-то хранится на паре такой-то, а также небольшое количество нужных атрибутов.
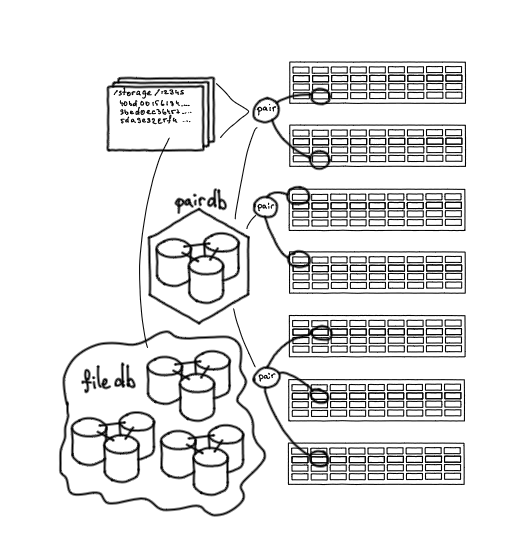
Еще одно важное звено — сервис Nylon, роутер для работы с базами данных. Он является единой точкой входа, позволяет работать через единый интерфейс как с PairDB, так и с FileDB. Это stateless-сервис, он выполняет балансировку запросов, понимает, на какой шард FileDB нужно идти, знает, какие пары активны, какие нет.
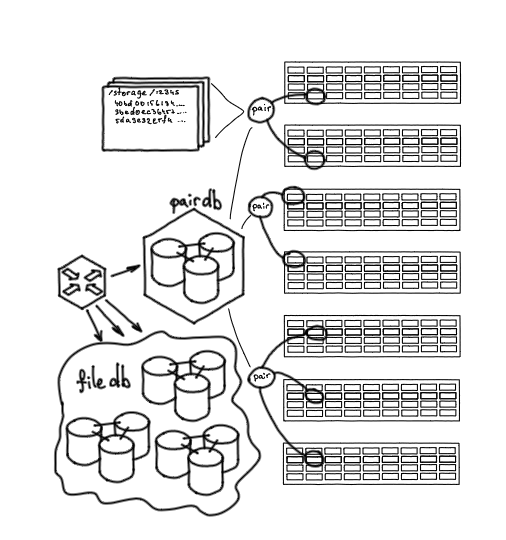
Nylon: роутер для работы с базами данных
Также в хранилище нужно как-то помещать контент. Для этого есть сервис — Streamer. Он предоставляет два HTTP-метода: метод PUT, чтобы заливать контент в хранилище, и метод GET, чтобы забирать его оттуда. HTTP — довольно популярный и удобный протокол для передачи данных.
Когда мы обращаемся к Streamer'y, он через Nylon обращается к PairDB, выясняет, на какую пару можно залить файл, после чего передает данные по WebDAV на эту пару.
По сути, любой storage сервер — это nginx плюс диски, которые смонтированы по заданным путям. Мы можем из Streamer залить в хранилище файл, удалить его, переименовать или проверить на целостность. То есть это удобный интерфейс для низкоуровневого взаимодействия с хранилищем.
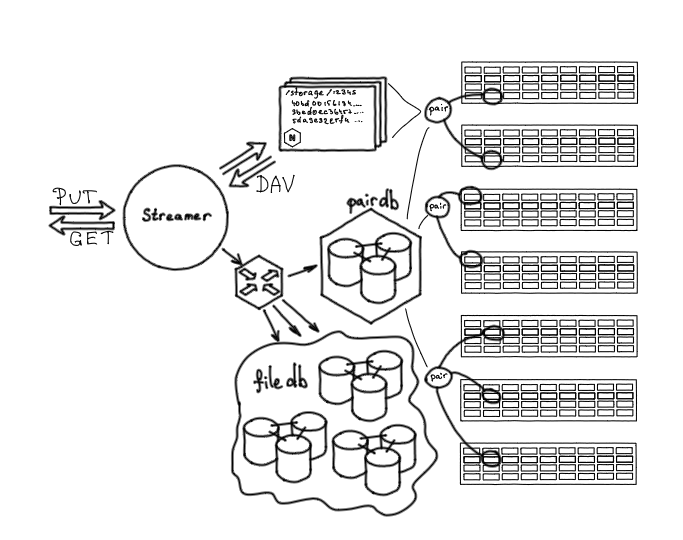
Streamer: точка входа в хранилище
Что мы добавили, чтобы сделать S3-хранилище
Итак, мы рассмотрели общее базовое устройство хранилища на момент, когда мы собрались запускать S3-хранилище. При помощи метода PUT мы могли поместить туда произвольный контент и получить в качестве идентификатора этих данных хэш. С этим идентификатором впоследствии можно было прийти и забрать исходный файл. Но этого недостаточно для реализации S3. В протоколе S3, помимо самого хранения объектов, есть:
- хранение метаданных — дополнительных свойств объектов;
- организация доступа к объектам посредством HTTP;
- группировка объектов в коллекции — бакеты;
- HTTP-S3 Endpoint. S3 организует данные в определенные структуры — бакеты, каждый из которых предоставляет точку входа для хранения файлов.
Для реализации этой логики был нужен отдельный сервис. Также хотелось сразу предусмотреть архитектуру для дальнейшего роста сервиса с линейной масштабируемостью.
Первые компоненты
Демон, реализующий S3 API. Это стандартный S3 API Amazon, который поддерживает работу по XML для метаданных и позволяет непосредственно передавать контент. Нам не пришлось что-то изобретать, всё описано и задокументировано.
Также перед сервисом мы поставили Nginx. Его мы использовали для терминации SSL, балансировки нарузки, а также для некоторой логики на Lua (метрики, логгирование и трейсинг).
Для хранения метаданных S3 мы также выбрали Tarantool. В первой версии за метаданными демон S3 ходил в эту базу, сам контент хранил в большом хранилище через Streamer.

Nginx + S3 API + метаданные
Объектная модель хранения
Посмотрим, как работает S3. Пользователь может создать бакет — коллекцию объектов. Бакет адресуется именем хоста и является поддоменом сервиса. В рамках бакета пользователь может создавать объекты. Идентификатором объекта будет URL. Содержимое объекта — blob, массив двоичных данных, который мы будем хранить в хранилище. Также у объекта есть атрибуты: имя — тот самый URL, ACL (список управления доступом), другие дополнительные или произвольные атрибуты — всё это сохраняется в метаданных.
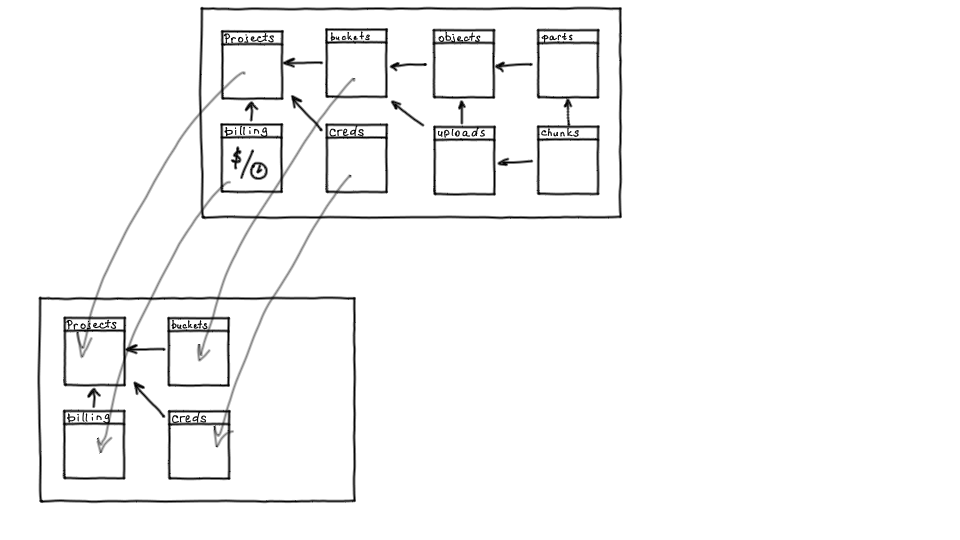
Нормализованная схема этих данных может выглядеть так: есть проекты, которым принадлежат бакеты, которым принадлежат объекты и объекты могут быть составные. Поскольку одним из способов объект можно загружать по частям, для загрузки есть две вспомогательные таблицы: uploads и chunks. Также у проектов есть учётные данные для доступа и биллинг.
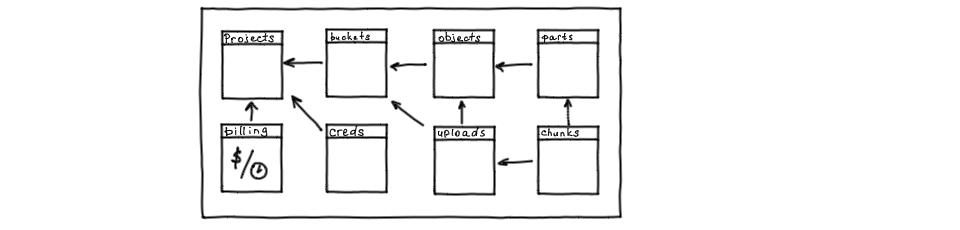
Схема данных
Поскольку мы делали b2b-сервис с платным доступом, то в этой схеме нужен был биллинг.
Сервис биллинга мы также реализовали на Tarantool.
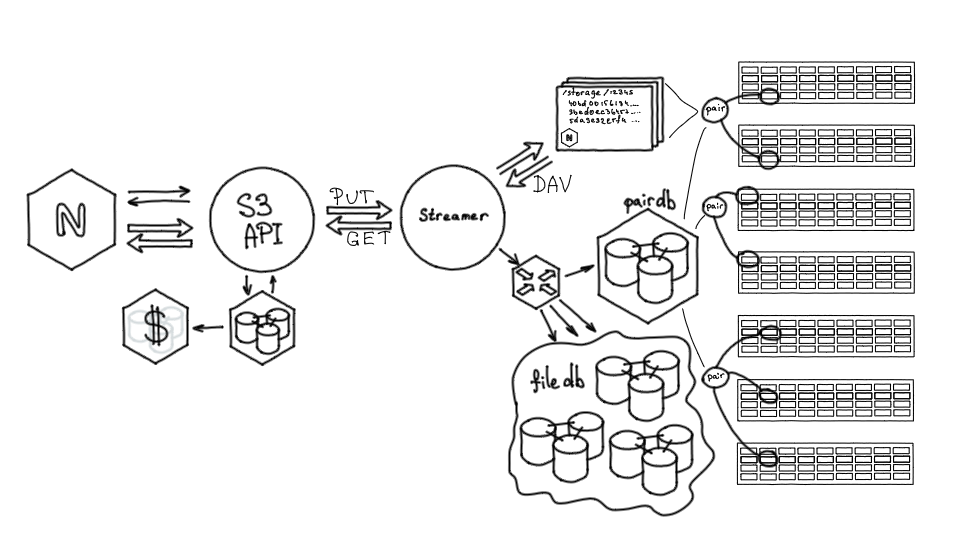
Доработки S3-хранилища: шаги к продакшену
Мы уже сделали работающую модель, которую можно использовать: объекты и метаданные хранились, но для выхода в продакшн не хватало нескольких моментов.
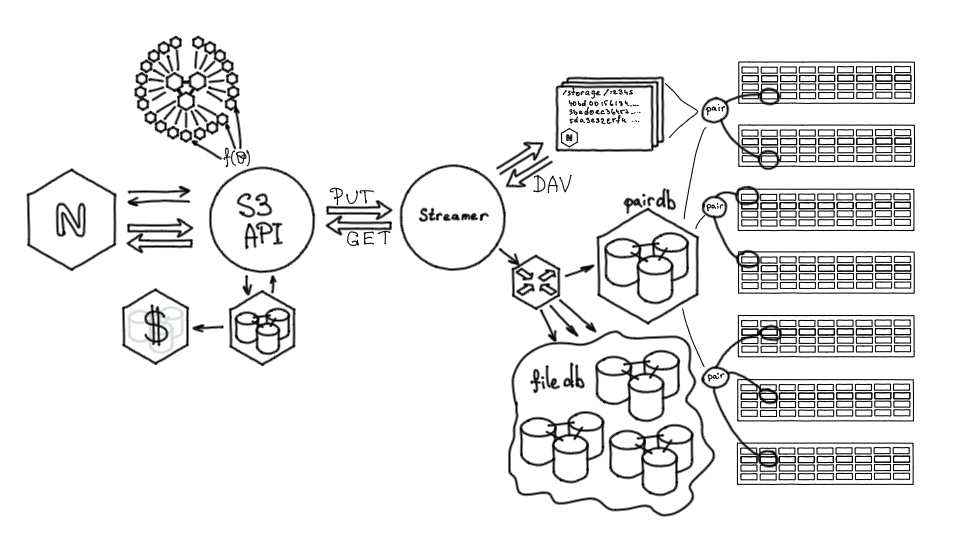
Во первых система рейт-лимитов. Если запустить сервис без нее, то при пиковой нагрузке мы могли непредсказуемо перегрузить какой-либо участок системы. Рейт-лимит должен работать так: любой S3-запрос приходит на конкретный хост, этот хост является идентификатором бакета, а бакет принадлежит какому-то клиенту. Нам нужно определить некоторую функцию от бакета, которая позволила бы рассчитать рейт-лимит.
Кроме того, система рейт-лимитов должна быть достаточно производительной, чтобы выдерживать нагрузку, которая приходит на S3.
Тут мы снова использовали Tarantool. Рейт-лимиты — это кластер из 21 инстанса, инстансы разбиты на группы, разнесены на три физических узла и объединены в большой топологический кластер. По нему автоматически распространяются конфигурационные изменения: задаются рейт-лимиты, дефолты и конфигурация. Каждый бакет обслуживается строго одним инстансом. Когда на конкретный бакет приходит запрос, для него вычисляется инстанс, отвечающий за этот бакет. В рамках этого узла производится подсчет текущего рейта обращений по алгоритму, похожему на Token Bucket. Далее система рейт-лимитов, на основании текущих показателей нагрузки и свойств, установленных для конкретного бакета, говорит, можно ли выполнить запрос или нет. Проверка лимитов выполняется на самой ранней стадии выполнения S3-запроса, защищая все остальные элементы системы от чрезмерной нагрузки.
Также под нагрузкой довольно сложно обойтись без кеша. В S3 подразумевается многократное обращение к одним и тем же объектам, то есть это горячее хранилище. В обычном случае обращение к единичному файлу обслуживается полной цепочкой: Streamer, FileDB, PairDB, Storage. Но при многократном обращении к файлу мы оптимизируем доступ к этому контенту при помощи локального кэша.
Кэш многослойный и реализован при помощи nginx, локальных, SSD и RAM-дисков. Тут мы не использовали Tarantool, потому что отдавать объекты удобнее из файловой системы, так мы можем сделать тиринг кэша. Кроме того, у нас крупные объекты с максимальным размером в 32 гигабайта, а в Tarantool кэшировать можно только маленькие объекты.
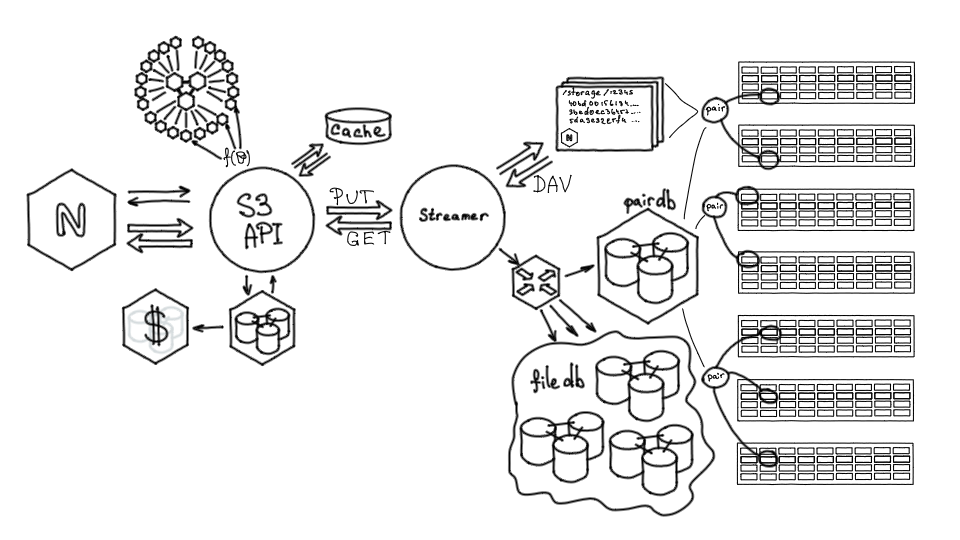
Эта первая система, с которой мы запустились, обладала некоторой рассчитанной capacity (емкостью), ее хватило для исследования, понимания продукта, того, что он будет работать.
Доработки боевой системы: фейловер и масштабирование
Система была уже в бою, при этом на старте мы кое-что упустили — нужно было добавить фейловер и масштабирование.
Наш S3-демон ходил за метаданными по протоколу Tarantool. На место оригинальной базы мы поставили Tarantool, который выступал в роли прокси-роутера запросов за метаданными. С точки зрения приложения, реализующего API, ничего не поменялось — оно продолжило обращаться к базе по протоколу Tarantool, но роутер смог обеспечить активный фейловер. То есть мы смогли проверять доступность узла, выдерживать паузу при переключениях и отказах и так далее. При этом само приложение мы не модифицировали.
Подробнее о том, как мы реализовали шардирование
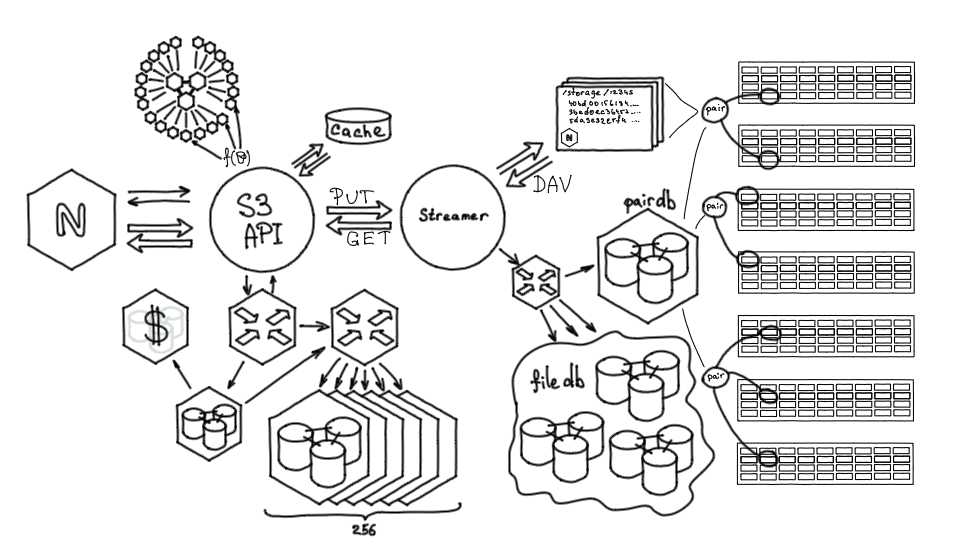
Следующий вопрос, которым пришлось озаботиться — это шардирование. Система росла, росло количество объектов и нужно было обеспечить возможности для дальнейшего роста.
Вернемся к схеме данных: есть проекты, есть бакеты, креды и биллинг. Это объекты, которые с большой вероятностью в обозримом будущем не вырастут за пределы одного инстанса ни по объему, ни по запросам. Значит, их нет смысла шардировать, и мы вынесли их в отдельный инстанс, который останется нешардированным. Это позволяет более консистентно управлять проектами и бакетами, поскольку есть единая нешардированная точка.
Также в схеме есть объекты, которые линейно растут — сначала их было сотни тысяч, сейчас их количество измеряется несколькими миллиардами. Такие объекты вместе с их частями надо было унести в шардированный кластер.
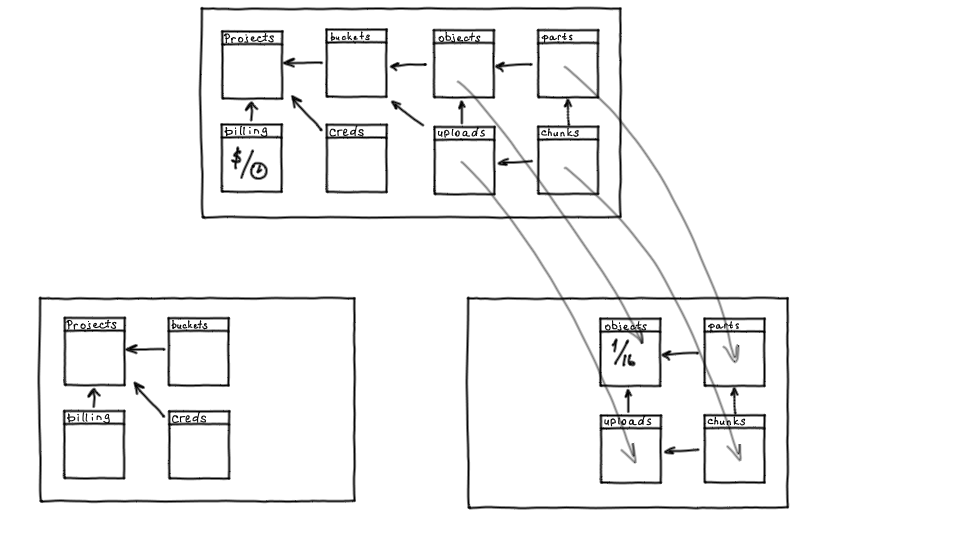
Схему мы разделили, но объектам нужно работать с бакетами: объект всегда принадлежит конкретному бакету, плюс на бакете работает ACL. Поэтому для каждого шарда с объектами мы держим теневую копию каждого бакета. Кроме того, во время модификации объектов и выполнения запросов, нужно считать объем для выполнения биллинга, поэтому на каждом шарде есть счетчики от биллинга.
Также мы добавили еще несколько таблиц и компонент:
- корзину, для уничтожения старых проектов, которые удаляются или замораживаются;
- очередь для фоновых задач, то есть основное хранилище может выполнять фоновые задачи, которые необходимо делать на кластере;
- поддержку lifecycle — механизма, который позволяет работать с объектами, управлять их жизненным циклом.
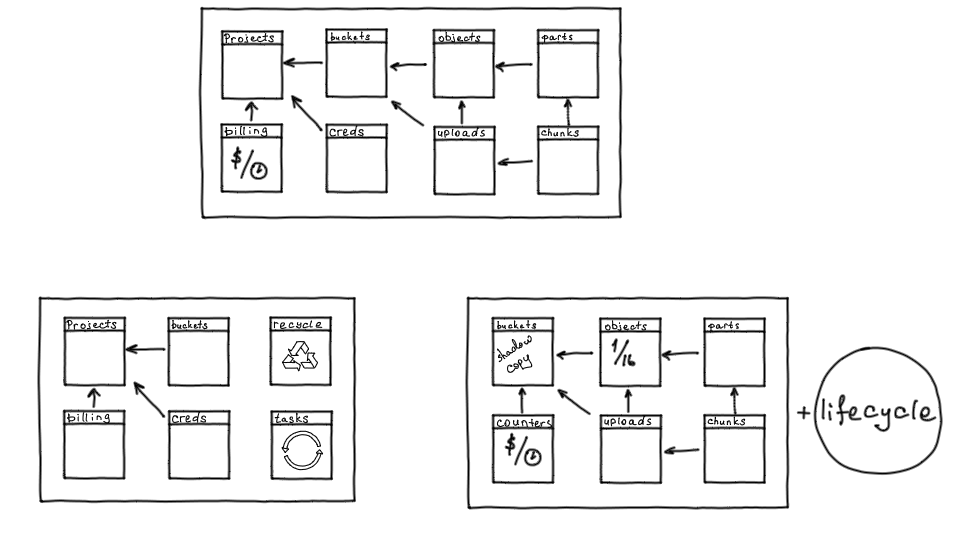
Так как часть данных мы унесли на шарды, понадобилась шардирующая прокси. Можно было бы переиспользовать роутер под эту роль, но отдельная шардирующая прокси, отвечающая только за шардирование данных, позволяет из роутера ходить за данными целиком, не думая о шардинге.

Отдельно расскажу, почему мы не взяли готовое решение, а хотели сделать кастомную функцию шардирования.
Посмотрим, как она устроена. У нас есть 256 доступных шардов. Мы для каждого бакета выделяем диапазон при помощи некой консистентной функции. Это просто — так же, как вы при помощи консистентной функции определяете принадлежность к одному шарду, вы определяете стартовый шард и выделяете диапазон:
f(bucket, shards) = subset
То есть если взять бакет, можно сказать, что он и его данные будут всегда лежать на конкретном подмножестве из всех шардов. Это позволяет снизить влияние одних бакетов на другие и упростить работу map-reduce запросов, когда нужно, например, сделать листинг объектов бакета. Для этого надо опросить все шарды, где эти объекты хранятся. Если бы объекты лежали на всех шардах, любой листинг задевал бы систему целиком, а здесь он задевает только конкретное подмножество.
Далее — каждый объект принадлежит конкретному бакету, поэтому когда мы обращаемся за объектом, то обращаемся за объектом по имени в конкретном бакете. То есть можем определить функцию для объекта не из всего доступного диапазона шардов, а только из подмножества его бакета:
f(object, subset) = shard
Мы берем конкретный объект, в качестве аргументов функции передаем туда не все шарды, а подмножество его бакета — и получаем конкретный шард.
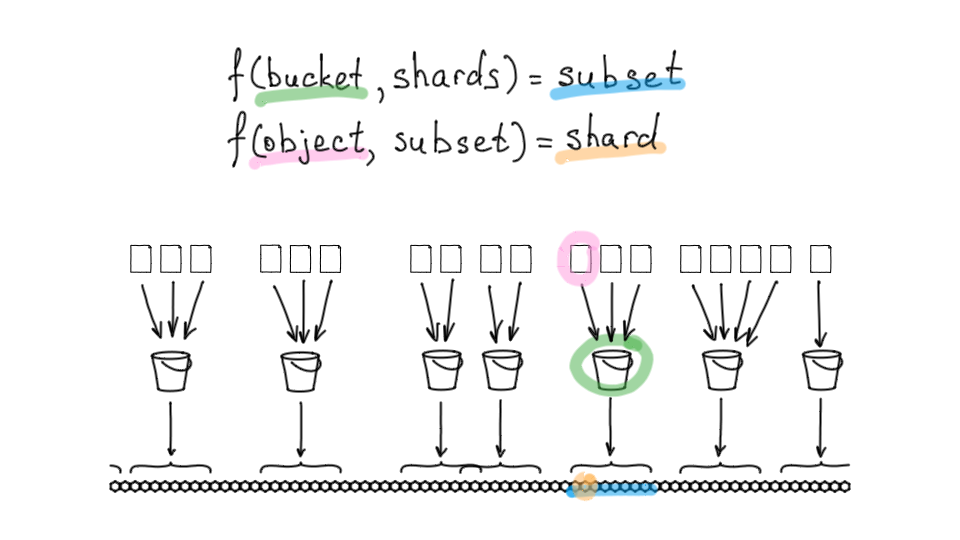
Итак, шардинг реализован, есть шардирующий прокси. Дальше осталось из роутера и базы с метаданными ходить в шардирующий прокси. Например, для создания объектов теневых копий — когда мы создаем бакет, основное хранилище должно создать представителя этого бакета на всех шардах, где он должен присутствовать.
Как мы реализовали решардинг
Самая большая проблема шардинга — это решардинг. Нам было важно сделать его без даунтайма, так как система уже была в продакшене. Покажу, как мы решили проблему на примере похожей задачи с живой миграцией данных из одного проекта в другой.
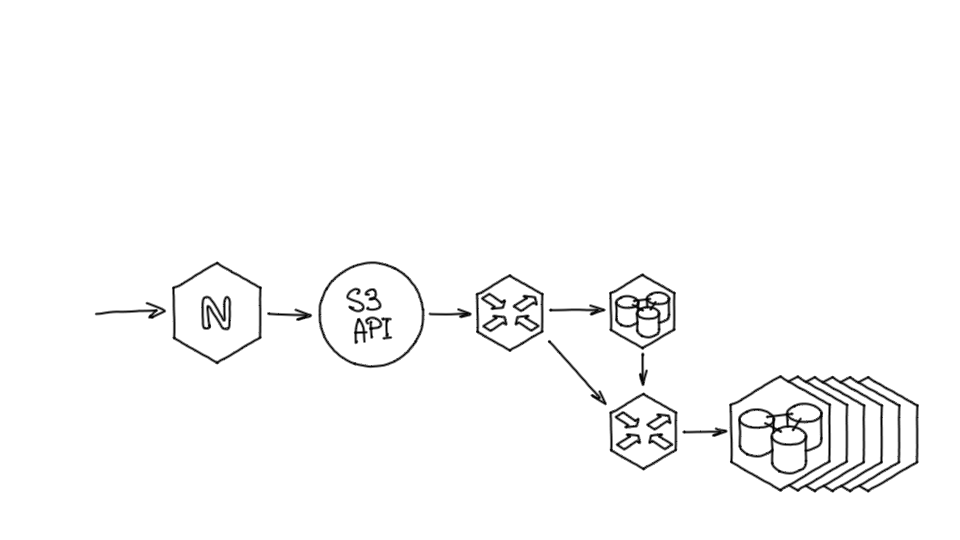
Ниже схема нашего кластера, которая получилась после внедрения шардинга. У нас есть nginx, S3 API, роутер, primary-база с проектами, шардирующий прокси и непосредственно шарды
Выше я упустил момент, что на определенном этапе проекта была продуктовая задача: «Запустить ещё одно хранилище, Айсбокс, — как Хотбокс, только для холодных данных». По сути, такое же хранилище, но по другим URL и без кэшей.
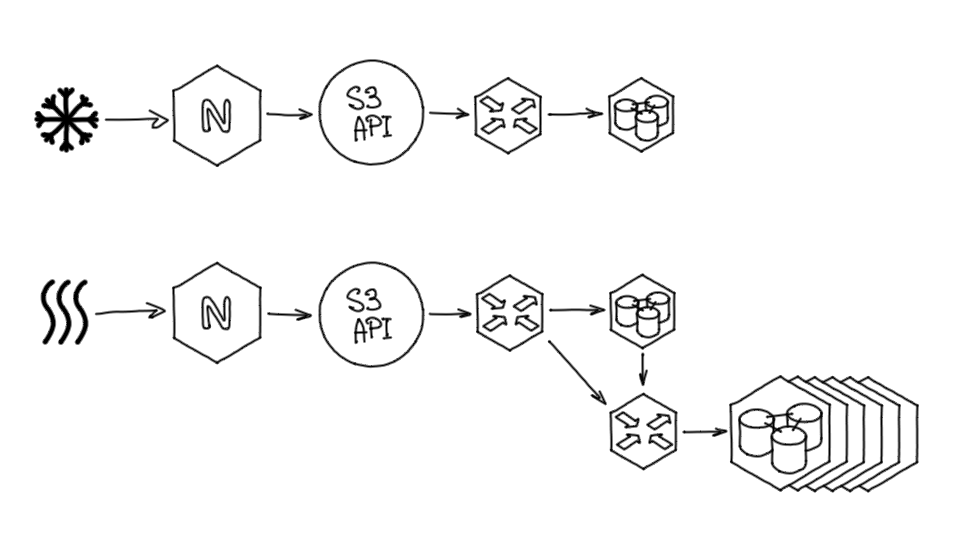
Icebox использовался меньше, чем Hotbox, поэтому он довольно долго обходился без какого-либо шардирования. В итоге мы решили отказаться от него и объединить Hotbox и Icebox в один сервис, просто разделив классы хранения.
Бакеты в хранилищах не пересекались, их легко можно было смержить и переместить, но клиенты пользовались и тем, и другим хранилищем, значит, нужно было решить проблему с отсутствием даунтайма. Нельзя было просто выключить и скопировать. Мы сделали миграцию в несколько этапов.
Для начала мы синхронизировали primary-хранилища. У нас был Tarantool и мы могли при создании объекта сделать так:
- к базе приходит запрос на создание бакета, например в Hotbox;
- Tarantool проверяет в другой базе (в этом случае — в Icebox), что такого бакета нет;
- если бакет есть, база говорит, что его создавать нельзя, и он синхронизировался как существующий.
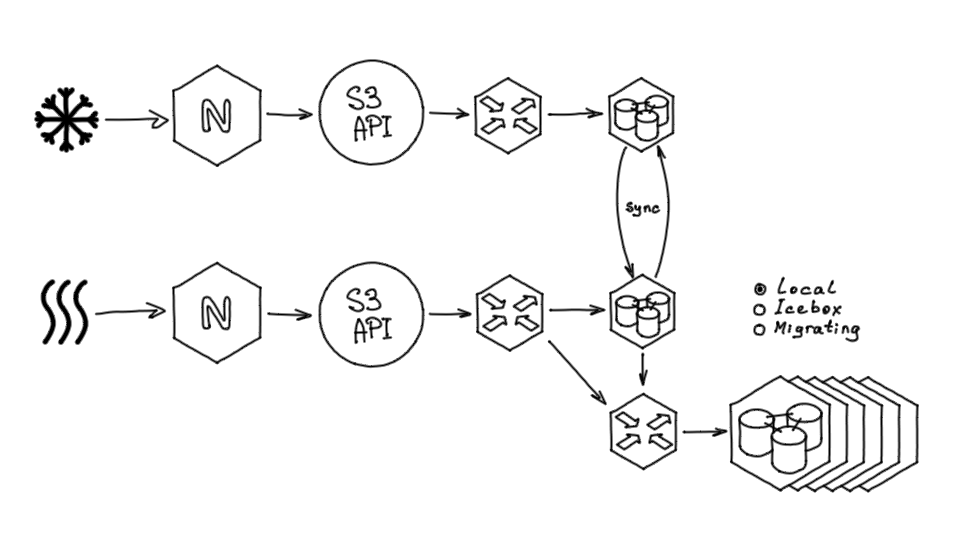
Синхронизация бакетов
В том хранилище, которое должно было принимать в себя все данные, ввели для проектов и бакетов признак, говорящий, где хранится этот объект. Он мог храниться локально, то есть в Hotbox, в Icebox — тогда в новом хранилище от него нет никаких данных, либо мог быть в состоянии миграции.
Если у проекта или бакета стоял признак Migrating, то во время миграции запрос выполнялся сначала в новое хранилище, в котором данные должны находиться, а если их там не было, то запросы пенаправлялись на альтернативное хранилище.
Далее мы переключили трафик. Поскольку API мог обслуживать и запросы Icebox, и запросы Hotbox, мы смогли без даунтайма переключить трафик, просто перенеся хосты и добавив соответствующие записи в Nginx.
После того, как трафик был перенаправлен, Nginx и API от Icebox можно было убрать.
Затем мы убрали Icebox nginx и S3 API — и всё заработало:
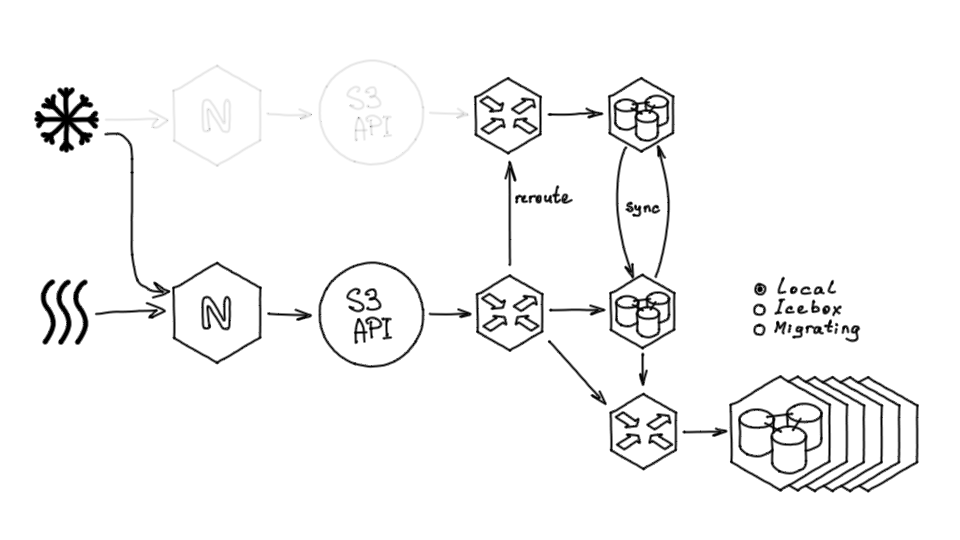
Далее мы запустили фоновый процесс миграции, который работает внутри базы — обходит поэлементно все проекты и их бакеты, выставляет для них признак Migrating, переносит данные и по завершению переноса выставляет признак Local.
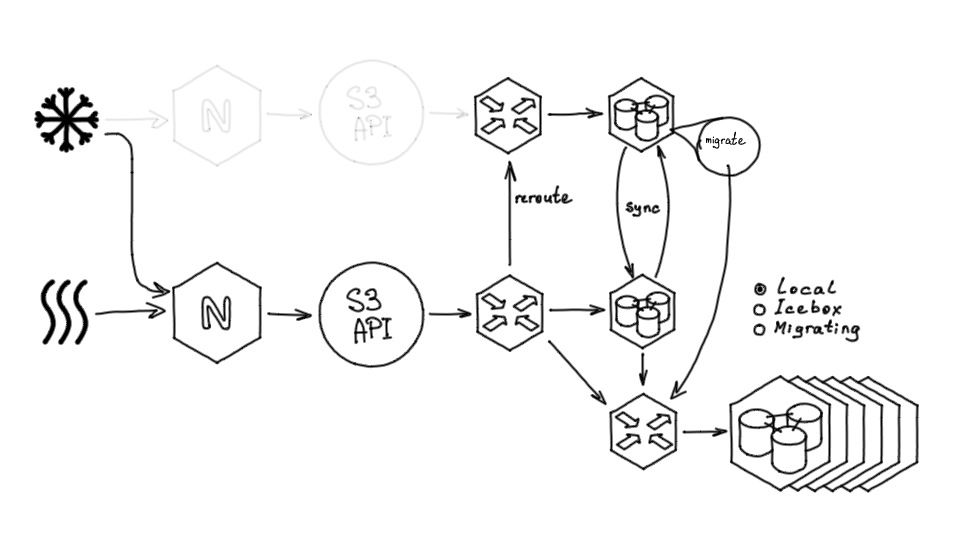
После переноса данных нам больше не нужно старое хранилище, и мы убираем оставшиеся части старой системы, а также убираем из кода поддержку статуса миграции.
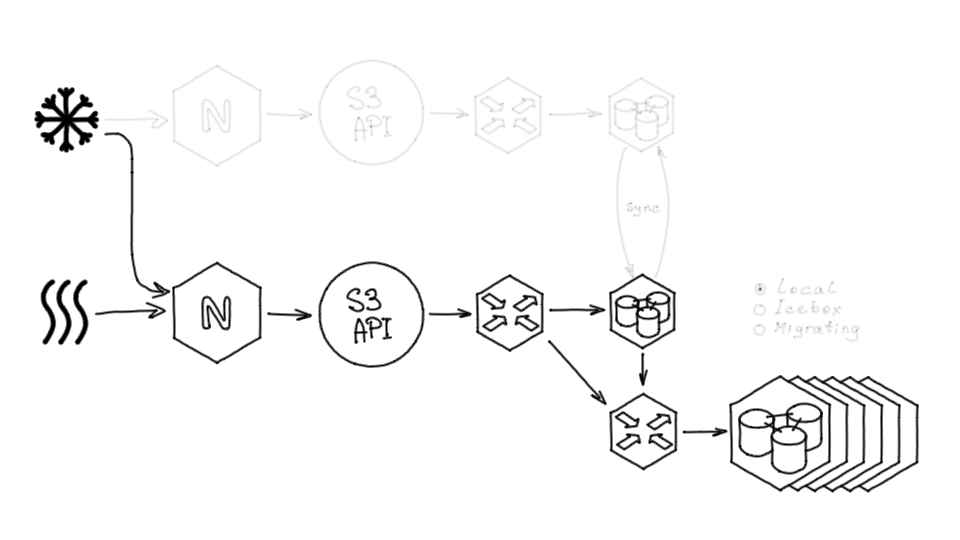
По тем же принципам был выполнен и решардинг из старого хранилища в шардированное:
- Пометили все бакеты как
Non-sharded. Все запросы к ним шли в оригинальное, нешардированное хранилище. - Новые бакеты создавались сразу в статусе
Sharded. - По одному брали бакеты, ставили статус
Migratingи переносили данные.
Запросы при этом обслуживались по принципу:
- Читаем в новом, потом в старом.
- Создаём только в новом.
- Обновляем двухфазно: если в новом нет, переносим из старого в новый, потом обновляем.
Работа с SSL-сертификатами
На фронтенде мы используем Nginx. В нашем случае это не обычный Nginx, а OpenResty, Nginx с поддержкой LuaJIT.
Еще один кусочек системы — работа с SSL-сертификатами. В S3-хранилище вы можете установить собственный домен для доступа к конкретному бакету, просто при помощи CNAME. Но без HTTPS на сегодняшний день нельзя: собственный домен подразумевает собственный SSL-сертификат.
Как я уже говорил, за балансировку и терминацию SSL у нас отвечает Nginx. В нашем случае это не обычный Nginx, а OpenResty, Nginx с поддержкой LuaJIT.
Это позволило нам довольно просто научить наш Nginx отдавать произвольные сертификаты. Причём нам было необходимо отдавать сертификаты динамически (без необходимости прописывать их в файл конфигурации). Мы воспользовались расширением ssl_certificate_by_lua, которое позволяет прочесть сертификат из произвольного источника непосредственно во время TLS-хэндшейка. В качестве хранилища сертификатов мы также взяли Tarantool: это позволяет управлять сертификатами извне и обеспечивает крайне быструю отдачу.
Также был реализован отдельный демон, в задачу которого входит регулярное обновление сертификатов, которые были выписаны при помощи Let's Encrypt.
Что бы я сохранил, а что сделал по-другому, если разрабатывать хранилище заново
Что нужно было использовать с самого начала
Шардинг сразу. Довольно много проблем доставил решардинг. Его легко сделать, но, тем не менее, если начинать проекты, которые нужно масштабировать, лучше сразу брать шардированный кластер, пусть даже и на минимуме узлов. Реализация шардинга на старте почти бесплатная в сравнении с внедрением шардинга в рабочую систему.
Работа с Tarantool через балансировщики. Сейчас мы все новые базы сразу подключаем в работу через балансировщики. Это позволяет расширять функциональность, добиваться более высокой отказоустойчивости.
Автофейловер. Установил бы все инструменты, которые требуются для автофейловера, так как первые неудачи после запуска были связаны с его отсутствием. После опыта с S3 все последующие продукты запускались с учётом этого.
Фича S3 «Версионирование». Изначально показалось, что это не очень востребованная функциональность. Встраивать эту возможность в архитектуру работающей системы крайне сложно.
Отдельный биллинг. То, как мы встроили биллинг в нашу систему, хорошо показало себя в начале, но впоследствии он стал мешать, лучше было бы его поставить в виде абсолютно отдельного сервиса.
Что было удачным решением
Модель данных. История показала, что по мере развития сервиса мы довольно точно совпадаем с моделью данных Amazon, поэтому можем реализовывать те фичи, которые есть там.
Схема шардирования. Я бы поддержал такие же диапазонные шардинги по бакетам, поскольку это позволяет хорошо распределять запросы от разных бакетов по большому кластеру.
Использование Tarantool. Tarantool сильно помог при развитии сервиса и его модификации, мы легко работали с данными, трансформировали и шардировали хранилище, при этом не понадобилось подниматься на слой приложения.
Этот доклад впервые прозвучал на @Databases Meetup by Mail.ru Cloud Solutions&Tarantool. Смотрите видео других выступлений и подписывайтесь на анонсы мероприятий в Telegram Вокруг Kubernetes в Mail.ru Group.
Также вы можете, посмотреть мой старый доклад про S3 или почитать статью моего коллеги про блочное хранилище.
