
Популярность алгоритма Raft в последние годы растёт. У него достаточно ясное описание, а реализации появляются во всё большем количестве проектов. На бумаге, будь то математика или рекламные статьи, выглядит хорошо. Но на практике не все обещания Raft можно реализовать без дополнительных решений.
Меня зовут Сергей Останевич. Я архитектор репликации в проекте Tarantool, платформе in-memory-вычислений с гибкой схемой данных для эффективного создания высоконагруженных приложений. Над материалом этой статьи мы работали вместе с Бориславом Демидовым. Мы поделимся нашим опытом реализации Raft, расскажем о поддержке работоспособности кластера Tarantool в условиях частичной связности и приведём реальные примеры того, как чистый Raft не справился с задачей.

Вначале коротко разберём, как устроен Raft, и поговорим про особенности репликации в Tarantool, а потом перейдем к основным проблемам и способам их решения.
Raft — это алгоритм достижения консенсуса в распределённых системах. Он довольно прост, поэтому популярен. Алгоритм обеспечивает консистентность данных в системе с помощью выбора одного лидера на весь кластер, который обеспечивает запись. Как следствие, записи между собой не перемешиваются, и не возникает ситуаций, когда информация в разных нодах различается.
Term — пронумерованные промежутки времени. В рамках одного промежутка Raft обеспечивает наличие всего одного лидера.
Log — специальный журнал, куда каждый из выбранных лидеров вносит записи, которые подаются в кластер. Журнал распространяется по всему кластеру, а Raft гарантирует идентичность записей на всех нодах.
Log index/log sequence number (LSN) — последовательный номер, который присваивается каждой записи в журнале.
Теперь коротко о том, как работает алгоритм.
Изначально все ноды в кластере запускаются в состоянии follower. Они принимают от текущего лидера информацию о том, что происходит и что им записать. Если никакой информации не приходит достаточно долго (election_timeout), ноды переходят в состояние candidate и первым делом повышают номер term на 1, рассылая всем вокруг: «Я хочу стать лидером».
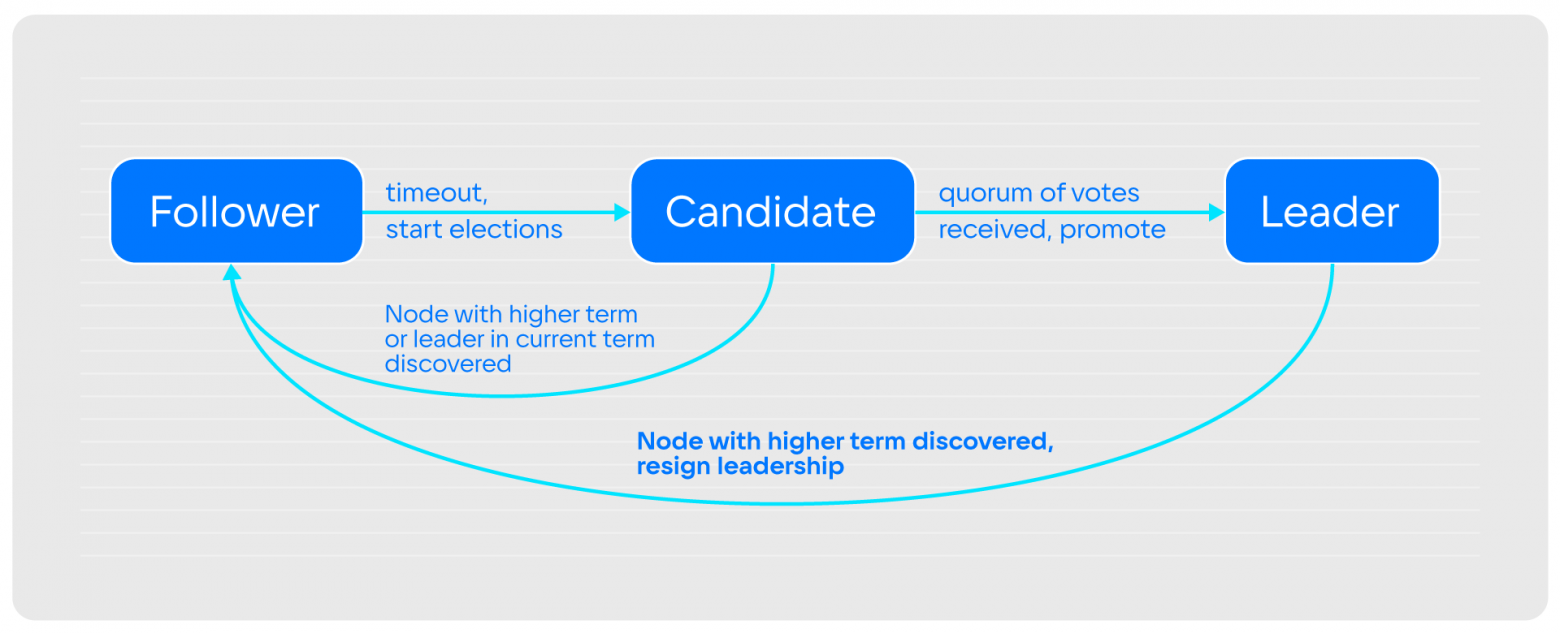
Если по прошествии определённого времени, которое предназначено для прохождения выборов, нода так и не получила ответа, то она повторяет процедуру выборов: повышает term и вновь запрашивает голосование. При этом, если кандидат ждал голосов, а одна из других нод в это время сообщила, что она стала лидером, или предложила голосование с бо̒льшим term, то кандидат становится follower.
Если кандидат стал лидером, значит большинство участвующих в кластере проголосовали за него. Нода переходит в состояние leader и начинает принимать запросы на запись. Это происходит до тех пор, пока кто-нибудь из кластера не скажет, что его term выше, чем у лидера. Тогда лидер вынужден снять с себя полномочия и возвратиться в состояние follower. Вот и весь алгоритм.
Алгоритм гарантирует:
Каждый из лидеров пишет в журнал последовательно. Он не пытается откатить назад предыдущие записи или модифицировать журнал. Всё, что было записано, везде будет отображаться одинаково. Это прописано в трёх пунктах:
Таким образом, в рамках одного term лидер рано или поздно найдётся, и он будет один. Это важно, потому что если лидера два, они будут писать одновременно, что нарушит работу кластера.
Всё работает хорошо, когда вы применяете алгоритм с ограничениями, которые в нём введены.
Часто из-за различных ограничений, например, бюджетных, кластер разворачивают в двух обрабатывающих центрах. Если один из них приходит в негодность, приходится выключить половину кластера. В результате алгоритм не может сам выбрать лидера, так как в этом месте нет абсолютного большинства.
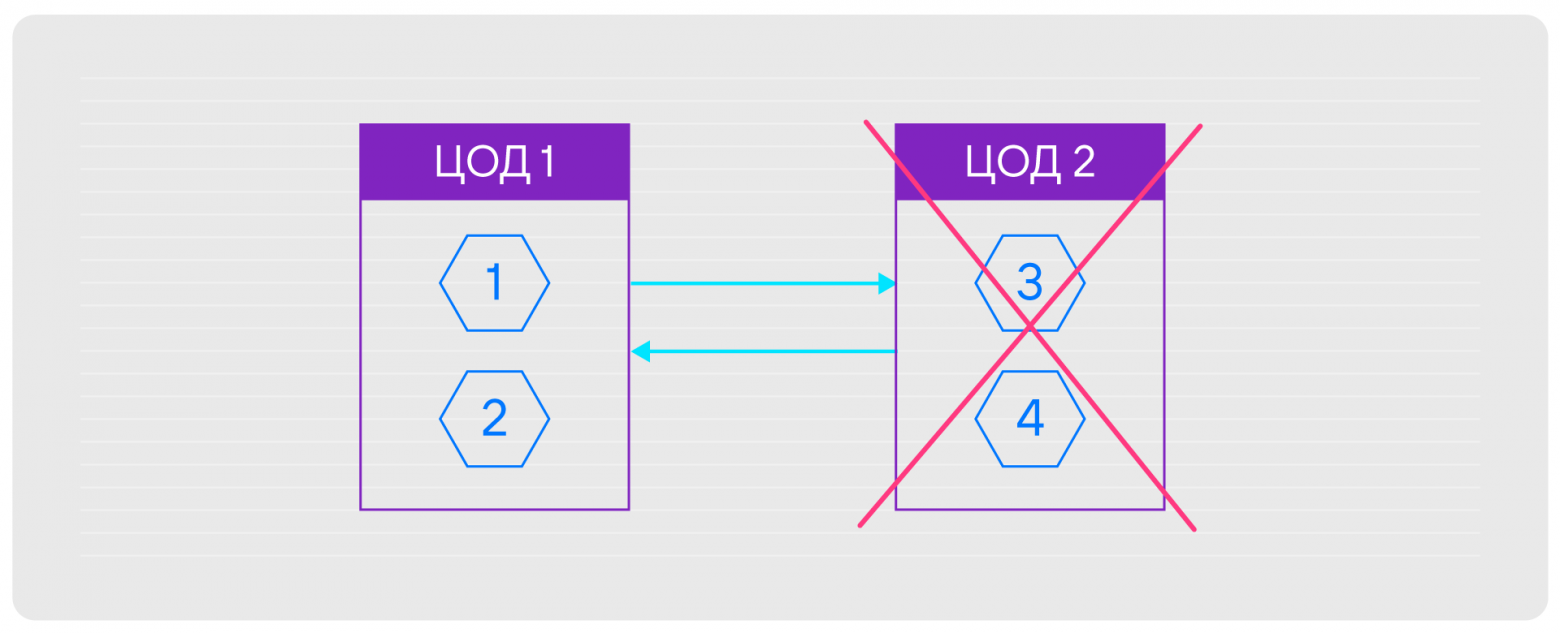
Если вам эта проблема знакома, рекомендую послушать доклад Сергея Петренко о том, как мы разрешили эту ситуацию, но не бесплатно, и почему важно помнить про ограничения. Ограничения, которые существуют в оригинальном Raft:
Здесь:
Tping — это средний RTT (round trip time) нашей сети. То есть усреднённая общая длительность получения ответа на сообщение, отправленное на другую ноду кластера.
Telection — установленная нами необходимая длительность ожидания до следующих перевыборов. Фактически это время, в течение которого нода не получает данных от лидера, но остаётся follower. Например, если сломался мастер, то через какое-то время кластер должен самоорганизоваться и выбрать нового. Соответственно, с этого момента кластер будет доступен на запись. Это значение вы задаёте сами, но важно установить его больше, чем длительность прохождения сообщения по сети, иначе процесс выборов не сможет завершиться.
Taccident — хотелось бы, чтобы это значение ушло в бесконечность, чтобы сеть не ломалась, машины не падали, трактора не работали поверх наших оптических сетей. Но увы!
И дальше мы сталкиваемся с неприятным явлением в работе Raft.
Итак, Raft дал гарантии по пунктам. Но это было чисто математическое обещание, потому что:
Связь term и времени неоднозначная. Некие отрезки времени есть, но ничего не сказано, плотно ли они идут друг за другом, или, может быть, пересекаются. Приведу пример. Есть очень простой кластер из трёх нод:
Жёлтая нода — лидер, находится в term 15. Все его признают, все получают от него записи, которые он принимает. И тут он отваливается от сети. Оставшиеся вторая и третья ноды, выждав таймаут, проводят выборы. Выбирают третью нода, теперь она лидер в term 16. Нода «2» знает, где новый лидер, и теперь он принимает записи.
Но на первую ноду по-прежнему ходят клиенты. И этот бывший лидер, если использует синхронную репликацию с кворумной записью, как в Tarantool, никогда не сможет подтвердить клиенту: «Да, я принял ваши данные». Он будет либо молчать, либо отвечать: «Ну нет возможности, таймаут!». Это неприятно, потому что половина ваших клиентов будет видеть, что лидер под номером «1», а вторая половина — что лидер под номером «3». Если мы работаем с асинхронной репликацией, то фактически получаем split-brain. В случае синхронной, соответственно, все клиенты лидера «1» будут висеть в ожидании и отваливаться по таймауту.
Raft хорошо работает при конфигурации full mesh, но если вытянуть кластер в линеечку, то возникают бесконечные перевыборы. Мы начали копать подробнее, при тестировании выявили проблему в конфигурации и почти сразу выяснили, что подобная проблема возникла не только у нас.

Похожая ситуация случилась в Cloudflare в 2020 году. Причём Cloudflare использовал очень распространённую базу данных ETCD. Так мы поняли, что проблему надо решать.
Теперь расскажем, какие особенности репликации есть в Tarantool.
Raft описывает, что журнал в кластере ведётся с единым индексом, который записывается каждым следующим лидером последовательно.
На схеме ниже я изобразил две ноды. Первая была лидером в первом term. Она сделала две записи (1 и 2), а потом новым лидером стала вторая нода и сделала одну запись. После чего первая нода забрала лидерство назад и сделала ещё три записи. В результате в логе шесть записей, поэтому для удобства понимания они сквозные и подсвечены. Но на самом деле никакой информации об источнике записи в лог Raft не требует. Главное, чтобы записи делались последовательно, везде реплицировались и были одинаковыми.
Изначально Tarantool был разработан для поддержки мультимастера. Это означает, что в кластере могут одновременно находиться несколько пишущих нод, и, соответственно, каждая должна писать со своим LSN. Поэтому был введён термин журнала vclock — векторные часы, которые помимо порядкового номера записи фиксируют ещё и сама нода, сделавшая запись. Поэтому жёлтые записи получают идентификатор 1, что означает, что их сделала нода «1». Потом нода «2» сделала следующую запись. После этого нода «1» продолжила со своей нумерацией (3, 4, 5). В этом и есть суть векторных часов, которые позволяют идентифицировать записи в общем реплицируемом журнале сделанные разными нодами.
Обратите внимание, что сумма по всем компонентам vclock всё равно 6: первая нода сделала пять записей, вторая — одну. Это такая особенность, давайте её запомним.
Вторая особенность Tarantool— это рассылка данных от всех ко всем, в отличие от Raft, где записи, которые сделал лидер, получают все, кто подключён к нему напрямую.
На рисунке слева — Raft, справа — Tarantool:

Запись, сделанная на первой ноде, по репликации доедет до второй ноды (появилась красная единица). То же самое сделает Tarantool: доедет по первому компоненту vclock во вторую ноду. Однако на следующем шаге классический Raft ничего не сделает, потому что связи между 1 и 3 нет, и эта запись не попадает в журнал третьей ноды. А Tarantool распространяет эту запись опосредованно. Мы фактически реплицируем ото всех ко всем. Если в моём журнале что-то появилось, я это обязательно отдам соседу, и неважно, записал я это сам или получил от кого-то.
Последняя, третья особенность, которая есть в Tarantool: результаты голосования за кандидата в лидеры мы распространяем по всем нодам. Поэтому все участники знают, что нода «1» выбрана лидером.
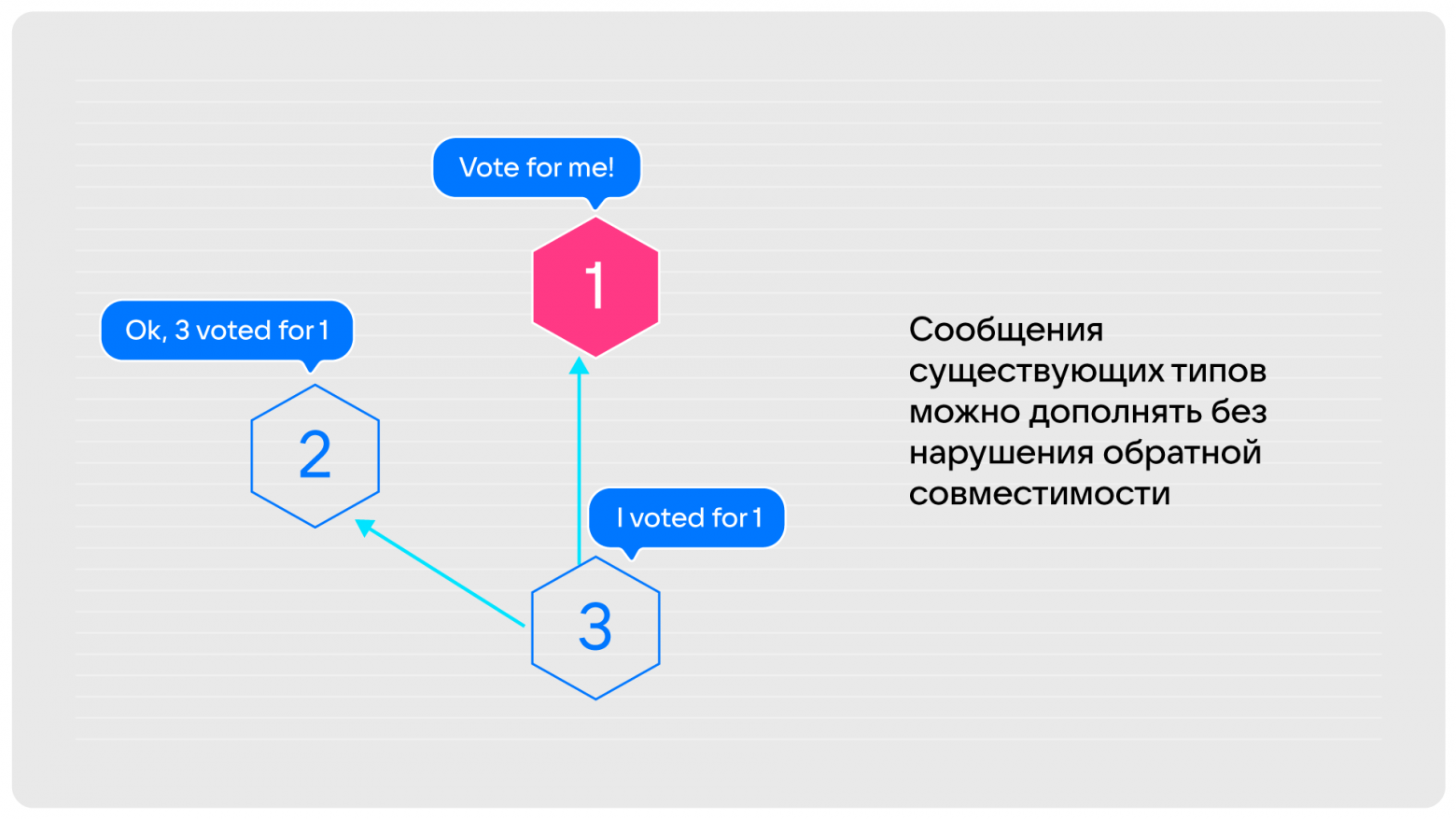
Более того, тут есть «потайной карман»: мы можем добавлять в сообщения существующего типа дополнительную информацию без нарушения обратной совместимости. Если у вас кластер из Tarantool определённой версии и вы вводите в него ноду более новой версии, то он начинает посылать расширенные сообщения, но это не приводит к ошибкам на нодах более ранних версий.
Теперь мы расскажем о проблемах, с которыми столкнулись, и как их решили.
Допустим, у вас был кластер, в котором всё как на рисунке ниже: лидер, остальные его слушают, но отвалилась какая-то нода. Она не лидер, не принимает активного участия в жизни кластера, возможно, с неё читают, или это запасной игрок.

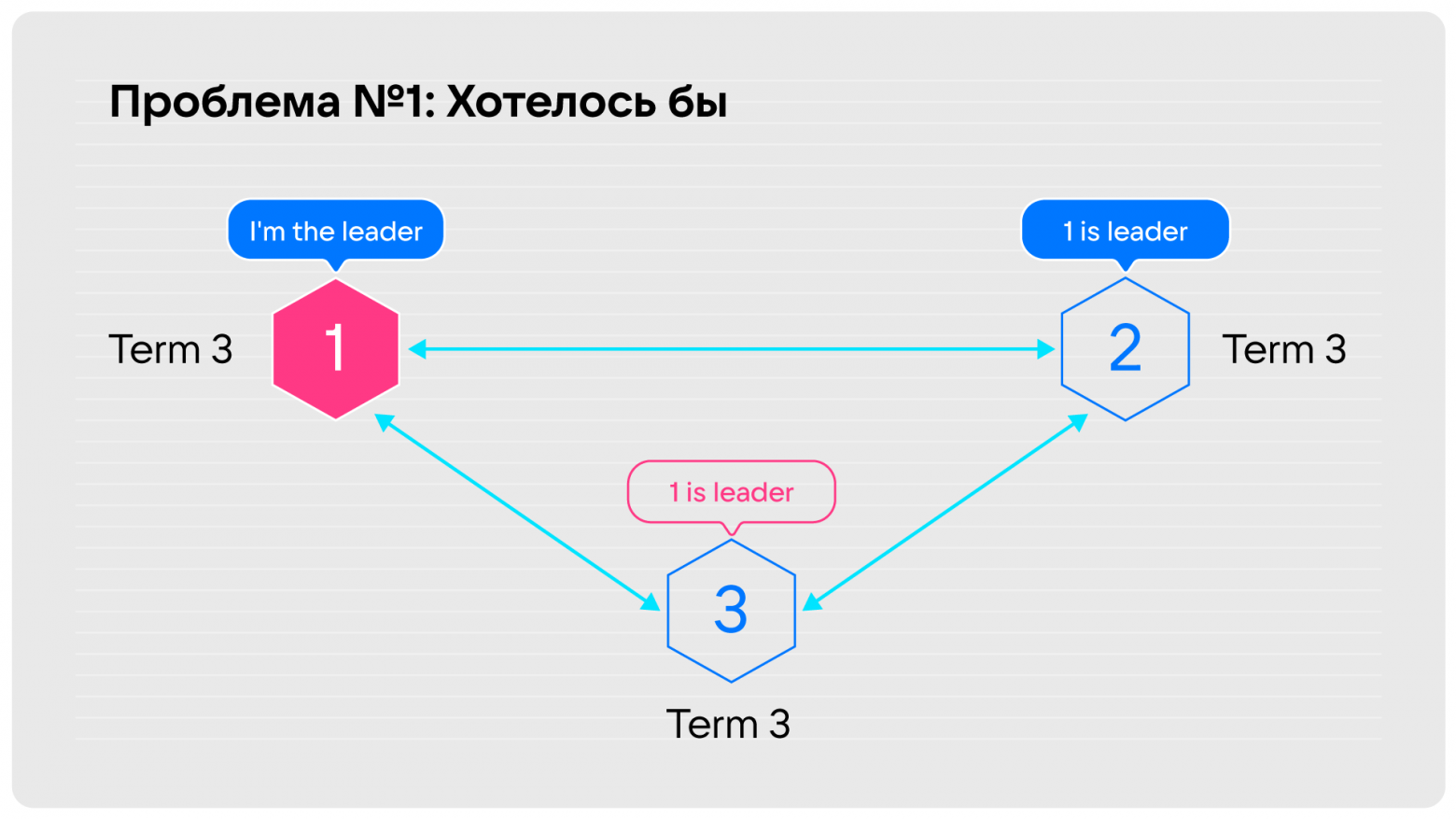
Когда какое-то время нода не видит лидера, она начинает запускать выборы, первым делом повышая себе term. Ну повысила term, и ладно, опять дождалась, что никого нет, ещё раз повысила — всё нормально. Однако, когда мы восстанавливаем связность, этот term доезжает до лидера, и всё, что он может сделать в этом случае по Raft, это снять с себя лидерские полномочия и принять участие в выборах. На этот промежуток времени мы получим кластер, недоступный на запись. Это очень неприятная ситуация. Хотелось бы, чтобы нода, которая пропадает, а потом снова появляется, не выводила в read only за собой весь кластер.
К примеру, если эта нода сидит на term 3 и ей никто не отвечает, она не запускает выборы. А когда у неё восстанавливается связность и она узнаёт, что лидер есть, то запускать уже нечего.
Вторая проблема с той же исходной точкой: сервер, который напрямую не видит лидера, будет постоянно его прерывать. С этим столкнулась компания Cloudflare, и билась над решением шесть часов.
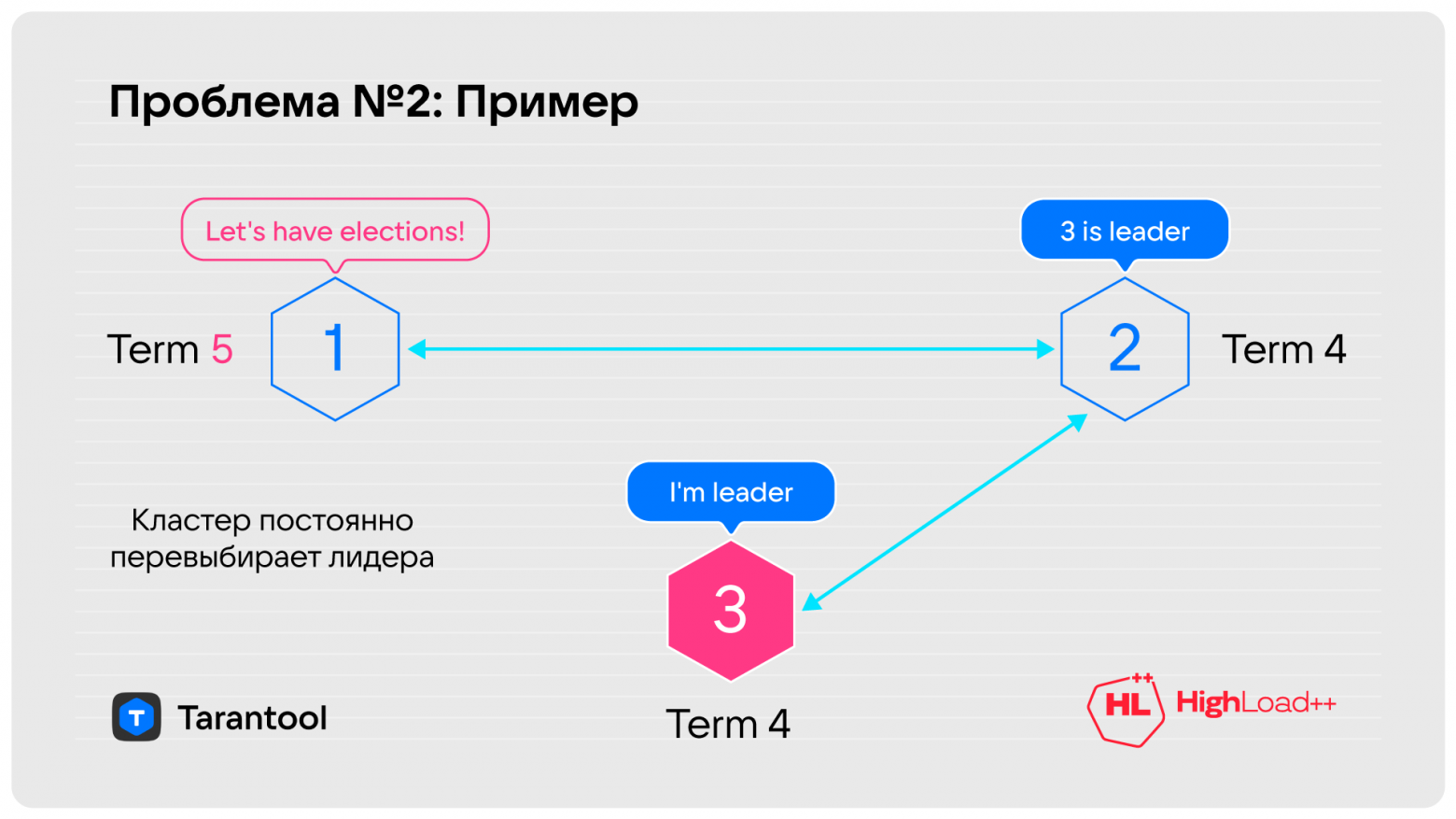
Опишу суть проблемы. Был кластер из трёх нод. Разорвалась связь между первой и третьей. Кажется, это не катастрофа.

Третья нода говорит: «А где мой лидер? Давайте уже жить нормально!», повышает term и запрашивает у второй ноды голосование. Вторая нода отвечает: «У меня тут term три, а эта хочет четыре — ну, давай, вперёд!» Теперь лидер стал третьим, первый снял с себя полномочия и через таймаут на выборы говорит: «Погодите, а где лидер? У меня term 5!» — и пошло-поехало. Кластер всё время пытается выбрать себе лидера.
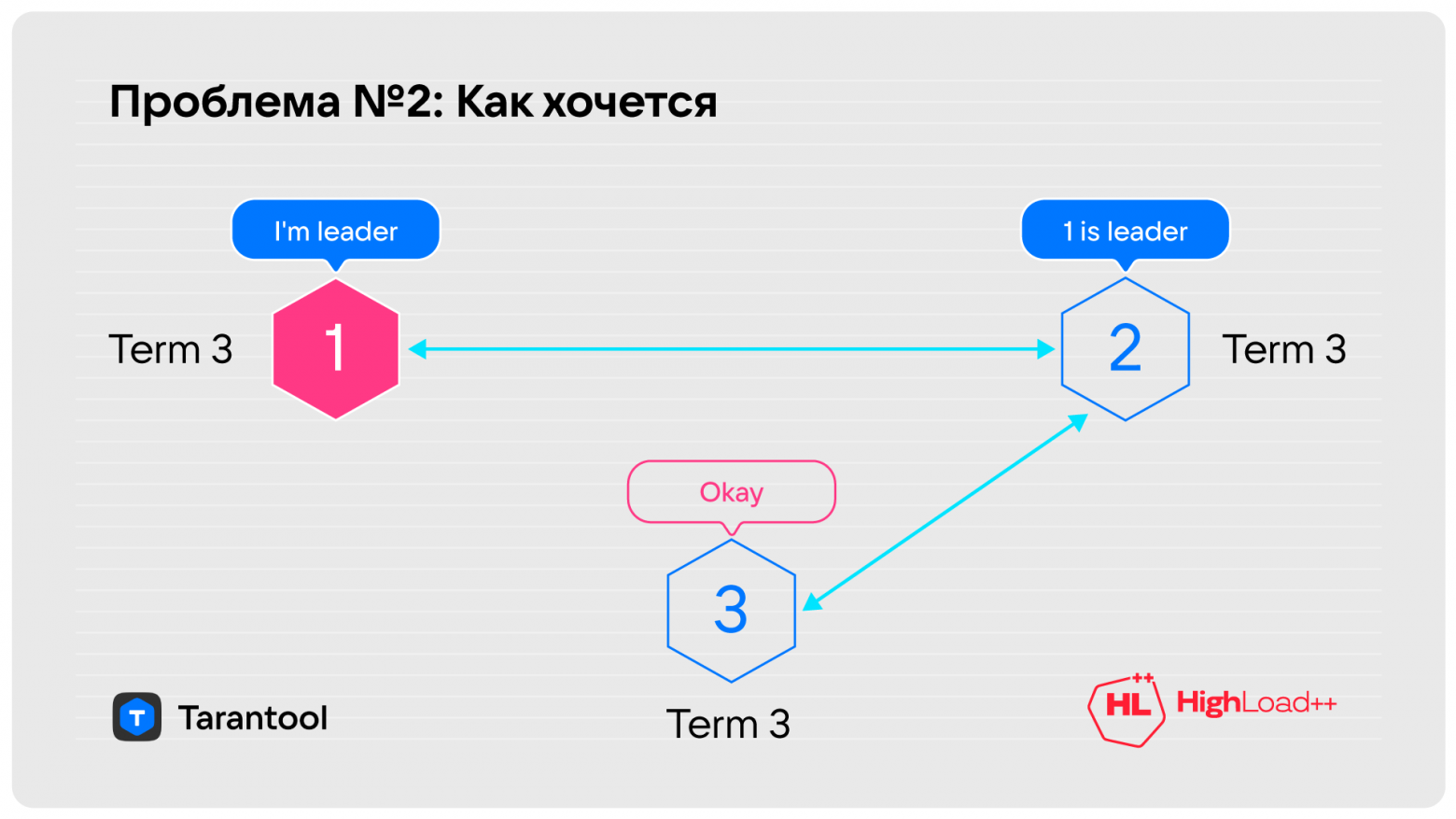
Как хочется видеть ситуацию?
Как только нода, которая не видит лидера, предлагает голосовать, тот, кому она прислала запрос, говорит: «Погоди, лидер у нас есть, всё нормально», и нода принимает ответ.
Как в жизни — мы хотим, чтобы действующего лидера зря никто не прерывал. Когда есть возможность продолжать лидерство, пусть так и будет.
Для этих проблем мы нашли три способа решения: предварительные выборы, игнорирование выборов голосующими, которые видят лидера, и Pre-Vote на основе метаинформации.
Этот вариант подробно описан в статье Диего Онгаро про Raft:
Например, перед началом выборов можно запускать предварительное голосование. То есть рассылать сообщение о желании избраться, не повышая term. На такое сообщение могут ответить отказом: «Не надо, у нас есть лидер». Если же большинство ответило положительно, то можно начать нормальное голосование и после получения кворума стать лидером.
Проверим работает это или нет. На схеме ниже третья оторванная нода в ожидании кворума запускает предварительное голосование. Ей никто не отвечает и она не может набрать необходимый кворум, поэтому остаётся в term 3. Если связность восстановить, никаких выборов не произойдёт.

Во втором примере мы тоже не видим лидера, и точно также спрашиваем у второй ноды: «Может, проголосуем?». Она отвечает, что лидер есть, поэтому не надо.
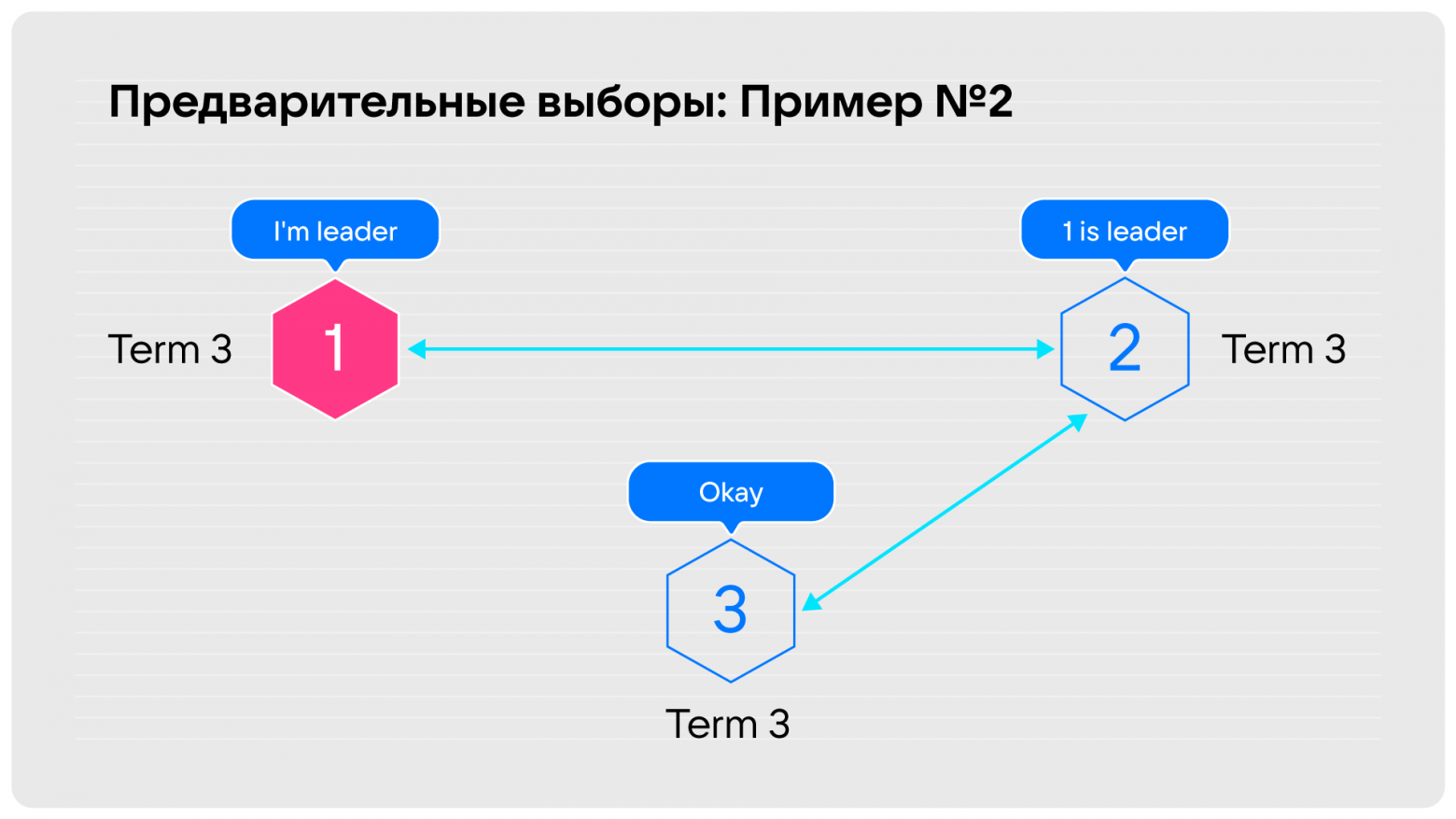
У этого решения есть недостаток: требуется новый тип сообщений, который сломает обратную совместимость с существующими инсталляциями. Это не уведомление второй ноды о начале выборов, а предложение об их проведении, требующее от неё согласия. Предыдущая версия Tarantool о таком сообщении не знает и не сможет дальше работать, поэтому мы решили, что такой способ нам подходит только как запасной.
Можно было бы игнорировать выборы голосующими, которые видят лидера. То есть, сервер, видящий лидера напрямую, игнорирует любые запросы на голос от соседей. К примеру, если я follower в term 3, и мне кто-то присылает term 4, то я его игнорирую и отвечаю, что лидер есть. Однако, если этот term 4 пришлют самому лидеру, он снимет с себя полномочия.

Недостаток решения в том, что оно неполноценное: не работает со временно оторванным сервером. При восстановлении подключения к лидеру он пришлёт ему более высокий term и спровоцирует ненужные выборы, вызвав тем самым простой кластера.
Мы пошли в сторону «секретного кармана», про который писали выше: каждый сервер знает состояние Raft у соседей благодаря широковещательной рассылке сообщений, которые идут для поддержания текущей репликации.
Мы регулярно либо рассылаем данные, либо присылаем друг другу пинги, и в пинг можно положить информацию о term лидера и о сложившейся в кластере политической ситуации:
Действительно, если кто-то прислал информацию, что лидер жив, зачем выбирать нового? Лидер где-то есть, и главное, что данные к нам попадут.
Проверим, поможет или нет. В одном случае, как только у третьей ноды восстанавливается связность с данными, которые реплицируются, она узнаёт, что первая нода до сих пор является лидером.

Во втором случае, который был у Cloudflare, эта информация будет постоянно приходить в третью ноду, независимо от того, виден ли лидер напрямую.
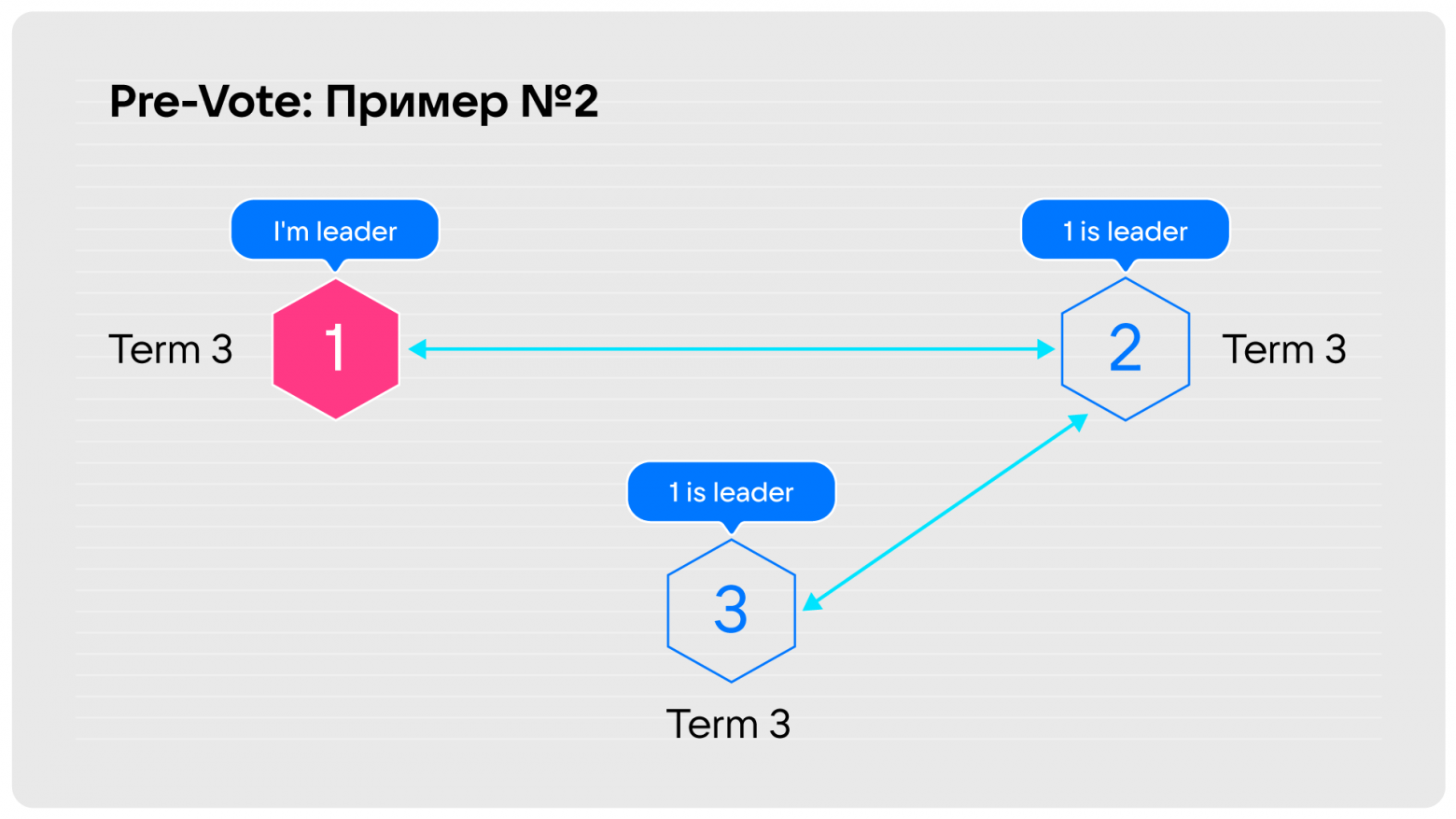
Мы сошлись на том, что третий способ эквивалентен решению с предварительными выборами, но зато мы сохраняем обратную совместимость. Это решение будем использовать в грядущей версии Tarantool.
Вторая надстройка, о которой хотим рассказать — выборы по Raft могут длиться со счастливым окончанием, но без гарантии по длительности. Время, необходимое для выборов, вообще неизвестно. Как результат, мы можем получить долгую недоступность кластера на запись после потери лидера. Это произойдёт потому, что каждый раунд выборов, в котором ни одна нода-кандидат не набрала большинства, заканчивается запуском нового раунда. Но прежде, чем новый раунд будет запущен, мы выжидаем полностью весь таймаут на случай, если прилетит решающий голос. Нам такое долгое ожидание не подходит.
В случае успешных выборов, если кто-то сразу набрал большинство, лидер появляется в самом начале раунда, потому что время пинга очень маленькое по сравнению с длительностью раунда. Выжидать весь таймаут нет нужды.
Итак, у нас есть рассылка отданных голосов. Осталось только научить ноды их считать. Как только в кластере из 6 нод мы видим у одной ноды три голоса и другой три голоса, а всего для победы требуется четыре, то сразу же понимаем, что дальше ждать голосования нет смысла.
Каждая нода может считать голоса, отданные за всех кандидатов. Допустим, у вас три кандидата и большинство голосов разделилось между двумя нодами. Тогда очевидно, что большинство уже никто не наберёт. Можно тут же начинать новые выборы. Мы это реализовали и получили экономию до 90 % времени на каждый раунд с разделившимися голосами.
Третья надстройка, которую мы сделали — это Fencing. Сразу предвосхищаю вопросы: под Fencing мы подразумеваем не защиту от старых записей, а стремление избежать появления двух лидеров в один момент времени.
Ситуация, когда один лидер уже есть, не исключает возможность существования нескольких нод, считающих себя лидерами в разных term одновременно. Этого хотелось бы избежать, потому что только один лидер может выполнять синхронную запись.
Допустим, один лидер в term 15, другой в term 16, и очень нехорошо, если наши пользователи по-прежнему ходят к обоим, в зависимости от конфигурации клиента. В таком случае, если у нас синхронная репликация, то на одном из двух лидеров запись не сработает, а если асинхронная — может случиться конфликт данных при записи на обоих нодах.

Кроме того, упомянутая Pre-Vote, которая информирует о состоянии текущего лидера, может привести нас в состояние заблокированного на запись кластера.

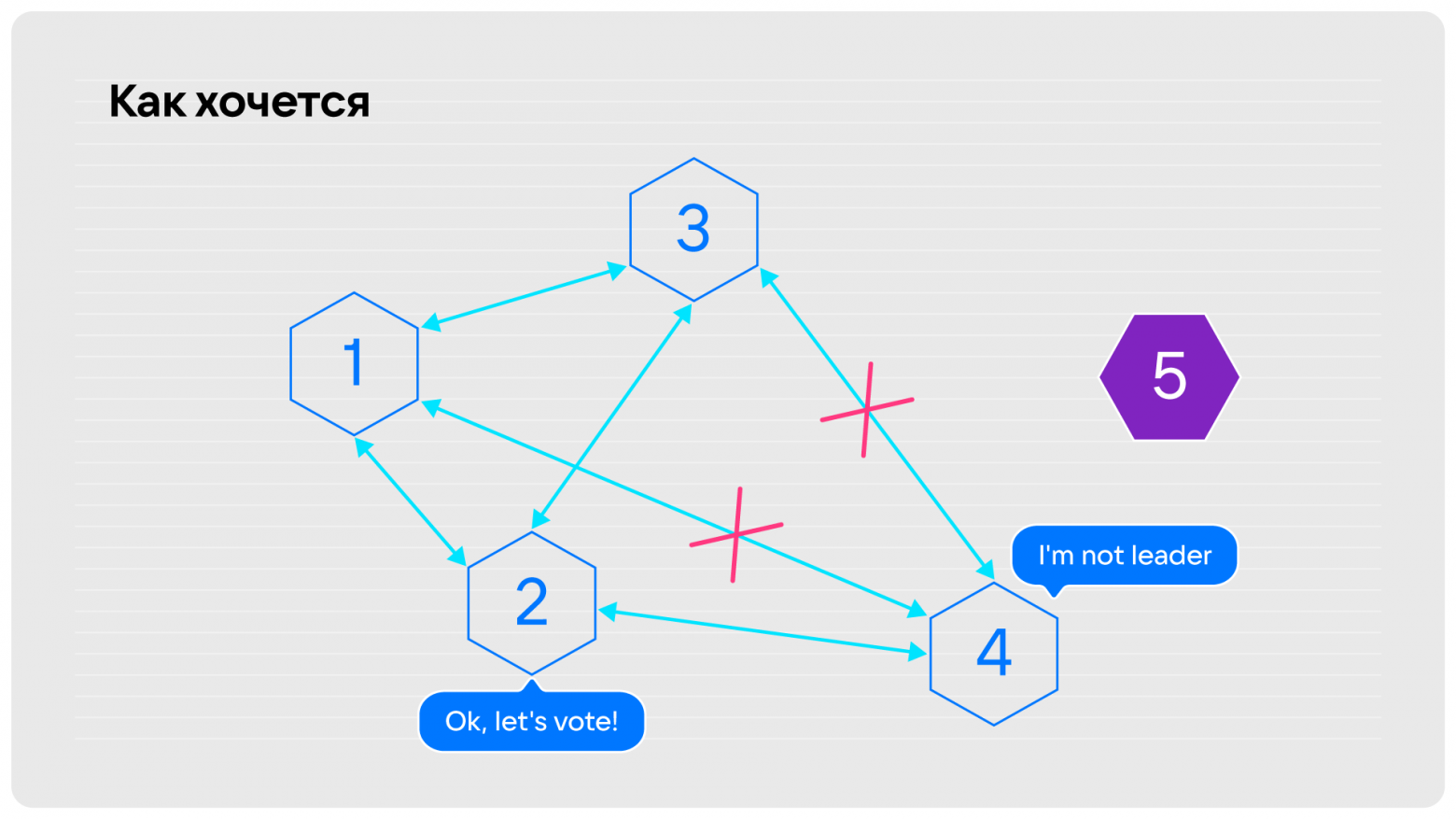
Допустим, в нашей конфигурации было пять нод, одна из которых вышла из строя. Но это только начало проблемы, потому что дальше у четвёртой ноды отвалился кворум связей. Остались лишь связи, достаточные, чтобы распространить информацию на кластер. Это лидер, но если мы попытаемся на него что-то записать, то записи либо не получат кворумного подтверждения и вы будете отваливаться по таймаутам, либо этому лидеру придётся снять полномочия. При этом никто из первых трёх нод не может запустить выборы, потому что лидер известен.
Теперь о том, как можно решить проблему с Fencing:
1. Для определения текущего лидера клиент может запрашивать у всех нод кластера текущий term и состояние ноды.
Когда мы спрашиваем всех подряд, лидер он или нет, это не решает проблему заблокированного кластера из примера 2, потому что лидер останется один, но писать он не сможет. Для примера 1 продолжительность недоступности на запись увеличивается: все клиенты, которые придут в кластер, должны будут сперва опросить, кто текущий лидер и в каком он term: «Лидера с самым большим term нашёл, я в него буду ходить!». Реализация этого во всех клиентах потребует много усилий.
2. Переложить определение лидера на внешнюю систему, гарантирующую его единственность, и довериться ей.
Это не хорошо, потому что у нас в инсталляции появится ещё одна система. Это будет сторонняя точка отказа, про которую мы ничего не знаем. К тому же потребуется дополнительная экспертиза по работе с такой системой, кластер будет сложнее администрировать.
3. Доработать RAFT в Tarantool.
Как бы нам хотелось это сделать в Tarantool? Во-первых, хотелось бы оповещать клиента. Проще всего сделать это, если он к кому-то обратился, а тот скажет, что больше не лидер и, может быть, сообщит, кто лидер.
Нода-лидер следит за обрывом соединений между репликами и может сказать: «У меня нет кворума, я больше не могу ничего подтверждать, поэтому я не буду лидером», снимет с себя полномочия и начнёт отвечать клиентам: «Я больше не лидер, ко мне больше не ходите».
Рассмотрим простой вариант:

Есть три ноды, лидер что-то пишет. Проходит некоторое время, пока запись доходит до Follower 1 и Follower 2, и те отправляют ответы-подтверждения.
Зелёным цветом выделены таймауты на репликацию. Допустим, Leader получил ответ как раз под самое окончание этого таймаута (t1), но Follower 1 начал свой таймаут на запуск выборов раньше — при отправке ответа. Допустим, после этого случился разрыв сети, и по прошествии таймаута Follower 1 запустит выборы. Сети нет, Follower 2 с Follower 1 могут очень быстро договориться к моменту t2 (стрелки синего цвета обозначают взаимодействие), тем более, что мы постарались ускорить выборы. И между t2 и t3, когда на Leader истечёт таймаут на репликацию, в кластере существует два лидера одновременно — неприятно!
Рассмотрим крайний случай. Сообщение от лидера до Follower летит очень быстро, а назад летит ровно столько, сколько длится таймаут. Это значит, что лидер получит весточку как раз под конец периода его легитимности. Поэтому нам, чтобы не начинать новые выборы, пока лидер может считать себя легитимным, надо иметь удвоенный таймаут, что мы и реализовали. Если на Followers поставить таймаут в два раза больше, то перевыборы запустятся после того, как лидер уже снимет с себя полномочия. При этом мы решили сохранить обратную совместимость даже с тем решением, которое у нас было до сих пор. Назвали это отдельным конфигурационным параметром Fencing.
Три варианта применения Fencing:
Более сильный Fencing приведёт к увеличенному периоду перевыборов, то есть Follower замедлится, но зато будет гарантия, что двух лидеров, хоть и в разных term, не окажется.
Мы ожидали от Raft:
Получили буквально то же самое:
Надеемся, что наше решение будет иметь большую практическую значимость, и что Tarantool станет вашим инструментом.
Меня зовут Сергей Останевич. Я архитектор репликации в проекте Tarantool, платформе in-memory-вычислений с гибкой схемой данных для эффективного создания высоконагруженных приложений. Над материалом этой статьи мы работали вместе с Бориславом Демидовым. Мы поделимся нашим опытом реализации Raft, расскажем о поддержке работоспособности кластера Tarantool в условиях частичной связности и приведём реальные примеры того, как чистый Raft не справился с задачей.
Вначале коротко разберём, как устроен Raft, и поговорим про особенности репликации в Tarantool, а потом перейдем к основным проблемам и способам их решения.
Обзор Raft: термины
Raft — это алгоритм достижения консенсуса в распределённых системах. Он довольно прост, поэтому популярен. Алгоритм обеспечивает консистентность данных в системе с помощью выбора одного лидера на весь кластер, который обеспечивает запись. Как следствие, записи между собой не перемешиваются, и не возникает ситуаций, когда информация в разных нодах различается.
Term — пронумерованные промежутки времени. В рамках одного промежутка Raft обеспечивает наличие всего одного лидера.
Log — специальный журнал, куда каждый из выбранных лидеров вносит записи, которые подаются в кластер. Журнал распространяется по всему кластеру, а Raft гарантирует идентичность записей на всех нодах.
Log index/log sequence number (LSN) — последовательный номер, который присваивается каждой записи в журнале.
Теперь коротко о том, как работает алгоритм.
Обзор Raft: выборы
Изначально все ноды в кластере запускаются в состоянии follower. Они принимают от текущего лидера информацию о том, что происходит и что им записать. Если никакой информации не приходит достаточно долго (election_timeout), ноды переходят в состояние candidate и первым делом повышают номер term на 1, рассылая всем вокруг: «Я хочу стать лидером».
Если по прошествии определённого времени, которое предназначено для прохождения выборов, нода так и не получила ответа, то она повторяет процедуру выборов: повышает term и вновь запрашивает голосование. При этом, если кандидат ждал голосов, а одна из других нод в это время сообщила, что она стала лидером, или предложила голосование с бо̒льшим term, то кандидат становится follower.
Если кандидат стал лидером, значит большинство участвующих в кластере проголосовали за него. Нода переходит в состояние leader и начинает принимать запросы на запись. Это происходит до тех пор, пока кто-нибудь из кластера не скажет, что его term выше, чем у лидера. Тогда лидер вынужден снять с себя полномочия и возвратиться в состояние follower. Вот и весь алгоритм.
Обзор Raft: гарантии
Алгоритм гарантирует:
- Election Safety: в каждом term только один лидер.
- Leader Append-Only: лидер только добавляет записи, без их модификации или удаления.
Каждый из лидеров пишет в журнал последовательно. Он не пытается откатить назад предыдущие записи или модифицировать журнал. Всё, что было записано, везде будет отображаться одинаково. Это прописано в трёх пунктах:
- Log Matching: записи с идентичными индексом и term совпадают во всех журналах.
- Leader Completeness: любой следующий лидер видит в журнале все записи предыдущего лидера и никак их не меняет.
- State Machine Safety: запись, применённая с определённым индексом на одном сервере, будет такой же и на остальных серверах.
Таким образом, в рамках одного term лидер рано или поздно найдётся, и он будет один. Это важно, потому что если лидера два, они будут писать одновременно, что нарушит работу кластера.
Всё работает хорошо, когда вы применяете алгоритм с ограничениями, которые в нём введены.
Часто из-за различных ограничений, например, бюджетных, кластер разворачивают в двух обрабатывающих центрах. Если один из них приходит в негодность, приходится выключить половину кластера. В результате алгоритм не может сам выбрать лидера, так как в этом месте нет абсолютного большинства.
Если вам эта проблема знакома, рекомендую послушать доклад Сергея Петренко о том, как мы разрешили эту ситуацию, но не бесплатно, и почему важно помнить про ограничения. Ограничения, которые существуют в оригинальном Raft:
- В кластере должна быть нода, которая имеет необходимое количество связей с другими нодами, чтобы выиграть выборы.
- Tping << Telection << Taccident
Здесь:
Tping — это средний RTT (round trip time) нашей сети. То есть усреднённая общая длительность получения ответа на сообщение, отправленное на другую ноду кластера.
Telection — установленная нами необходимая длительность ожидания до следующих перевыборов. Фактически это время, в течение которого нода не получает данных от лидера, но остаётся follower. Например, если сломался мастер, то через какое-то время кластер должен самоорганизоваться и выбрать нового. Соответственно, с этого момента кластер будет доступен на запись. Это значение вы задаёте сами, но важно установить его больше, чем длительность прохождения сообщения по сети, иначе процесс выборов не сможет завершиться.
Taccident — хотелось бы, чтобы это значение ушло в бесконечность, чтобы сеть не ломалась, машины не падали, трактора не работали поверх наших оптических сетей. Но увы!
И дальше мы сталкиваемся с неприятным явлением в работе Raft.
Обзор Raft: ожидания ≠ реальность
Итак, Raft дал гарантии по пунктам. Но это было чисто математическое обещание, потому что:
- Рано или поздно ≠ быстро.
- Term ≠ время.
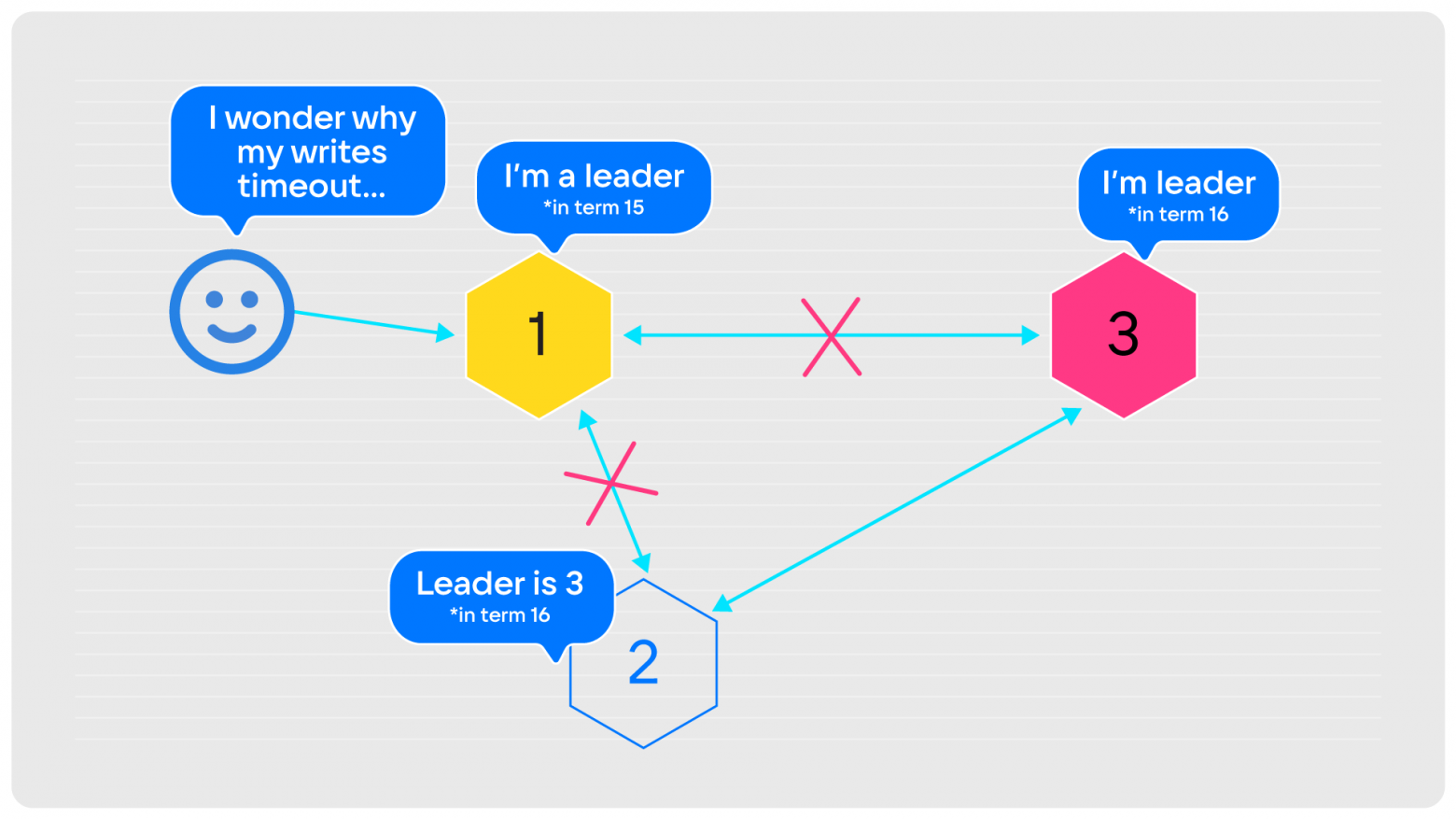
Связь term и времени неоднозначная. Некие отрезки времени есть, но ничего не сказано, плотно ли они идут друг за другом, или, может быть, пересекаются. Приведу пример. Есть очень простой кластер из трёх нод:
Жёлтая нода — лидер, находится в term 15. Все его признают, все получают от него записи, которые он принимает. И тут он отваливается от сети. Оставшиеся вторая и третья ноды, выждав таймаут, проводят выборы. Выбирают третью нода, теперь она лидер в term 16. Нода «2» знает, где новый лидер, и теперь он принимает записи.
Но на первую ноду по-прежнему ходят клиенты. И этот бывший лидер, если использует синхронную репликацию с кворумной записью, как в Tarantool, никогда не сможет подтвердить клиенту: «Да, я принял ваши данные». Он будет либо молчать, либо отвечать: «Ну нет возможности, таймаут!». Это неприятно, потому что половина ваших клиентов будет видеть, что лидер под номером «1», а вторая половина — что лидер под номером «3». Если мы работаем с асинхронной репликацией, то фактически получаем split-brain. В случае синхронной, соответственно, все клиенты лидера «1» будут висеть в ожидании и отваливаться по таймауту.
Чего бы нам хотелось
- Найти лидера быстро. Чтобы выборы в условный term были как можно короче. А пока мы ждём какое-то время, прежде чем начать выборы, а потом ещё какое-то время выбираем.
- Иметь не более одного лидера в кластере в конкретный момент времени, а не в каком-то эфемерном term.
- Чтобы возвращение или подключение нод в кластер не вызывало простоя. Если мы отключим ноду и затем снова подключим, это может привести к снятию с себя полномочий лидером.
Raft хорошо работает при конфигурации full mesh, но если вытянуть кластер в линеечку, то возникают бесконечные перевыборы. Мы начали копать подробнее, при тестировании выявили проблему в конфигурации и почти сразу выяснили, что подобная проблема возникла не только у нас.
Похожая ситуация случилась в Cloudflare в 2020 году. Причём Cloudflare использовал очень распространённую базу данных ETCD. Так мы поняли, что проблему надо решать.
Raft и Tarantool: особенности
Теперь расскажем, какие особенности репликации есть в Tarantool.
Tarantool: мультиплексированный журнал
Raft описывает, что журнал в кластере ведётся с единым индексом, который записывается каждым следующим лидером последовательно.
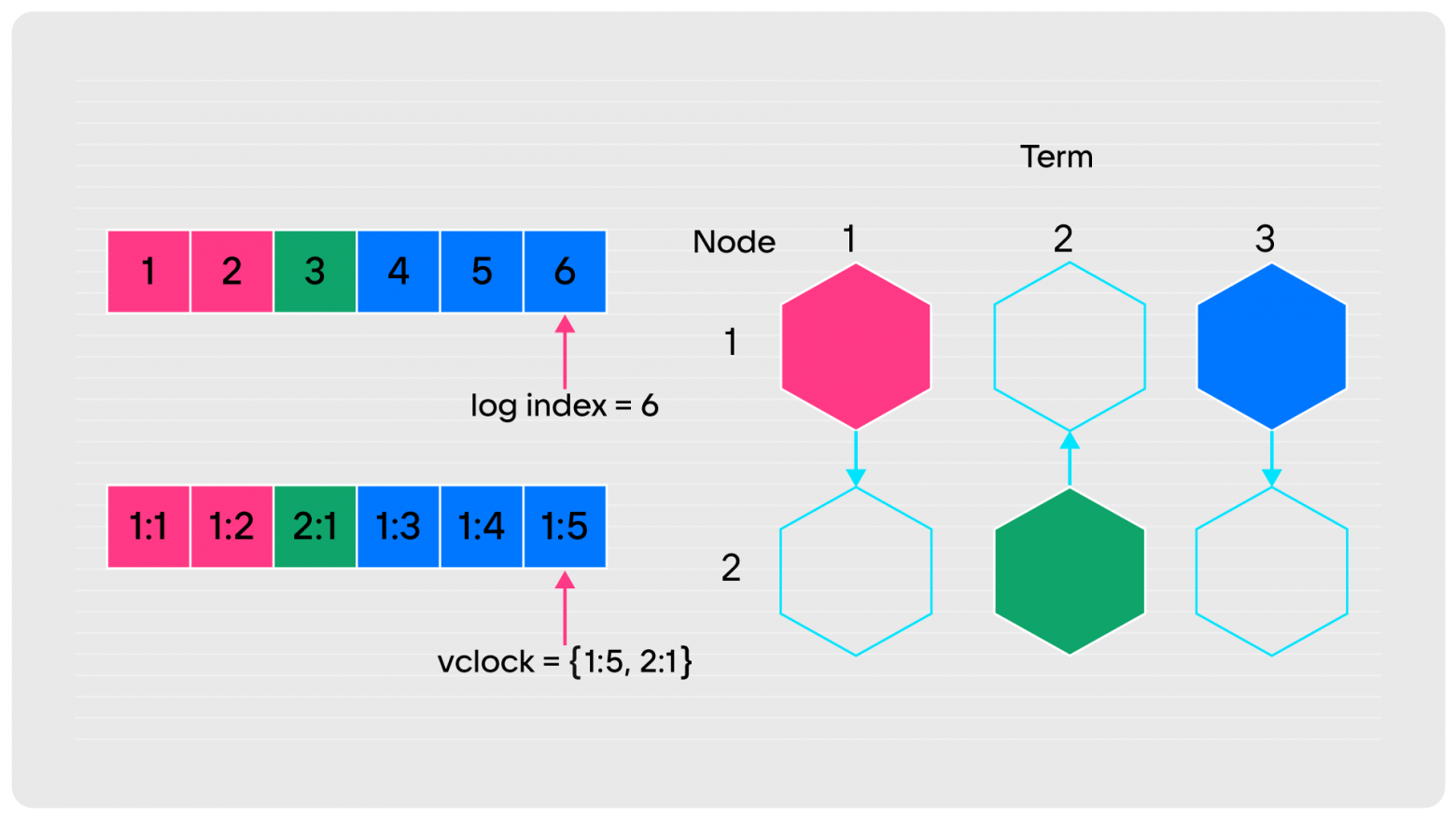
На схеме ниже я изобразил две ноды. Первая была лидером в первом term. Она сделала две записи (1 и 2), а потом новым лидером стала вторая нода и сделала одну запись. После чего первая нода забрала лидерство назад и сделала ещё три записи. В результате в логе шесть записей, поэтому для удобства понимания они сквозные и подсвечены. Но на самом деле никакой информации об источнике записи в лог Raft не требует. Главное, чтобы записи делались последовательно, везде реплицировались и были одинаковыми.
Изначально Tarantool был разработан для поддержки мультимастера. Это означает, что в кластере могут одновременно находиться несколько пишущих нод, и, соответственно, каждая должна писать со своим LSN. Поэтому был введён термин журнала vclock — векторные часы, которые помимо порядкового номера записи фиксируют ещё и сама нода, сделавшая запись. Поэтому жёлтые записи получают идентификатор 1, что означает, что их сделала нода «1». Потом нода «2» сделала следующую запись. После этого нода «1» продолжила со своей нумерацией (3, 4, 5). В этом и есть суть векторных часов, которые позволяют идентифицировать записи в общем реплицируемом журнале сделанные разными нодами.
Обратите внимание, что сумма по всем компонентам vclock всё равно 6: первая нода сделала пять записей, вторая — одну. Это такая особенность, давайте её запомним.
Tarantool: рассылка данных от всех ко всем
Вторая особенность Tarantool— это рассылка данных от всех ко всем, в отличие от Raft, где записи, которые сделал лидер, получают все, кто подключён к нему напрямую.
На рисунке слева — Raft, справа — Tarantool:
Запись, сделанная на первой ноде, по репликации доедет до второй ноды (появилась красная единица). То же самое сделает Tarantool: доедет по первому компоненту vclock во вторую ноду. Однако на следующем шаге классический Raft ничего не сделает, потому что связи между 1 и 3 нет, и эта запись не попадает в журнал третьей ноды. А Tarantool распространяет эту запись опосредованно. Мы фактически реплицируем ото всех ко всем. Если в моём журнале что-то появилось, я это обязательно отдам соседу, и неважно, записал я это сам или получил от кого-то.
Tarantool: распространение результатов голосования
Последняя, третья особенность, которая есть в Tarantool: результаты голосования за кандидата в лидеры мы распространяем по всем нодам. Поэтому все участники знают, что нода «1» выбрана лидером.
Более того, тут есть «потайной карман»: мы можем добавлять в сообщения существующего типа дополнительную информацию без нарушения обратной совместимости. Если у вас кластер из Tarantool определённой версии и вы вводите в него ноду более новой версии, то он начинает посылать расширенные сообщения, но это не приводит к ошибкам на нодах более ранних версий.
Теперь мы расскажем о проблемах, с которыми столкнулись, и как их решили.
Надстройки Raft
Pre-Vote. Проблема №1: кластер недоступен для записи после восстановления связности
Допустим, у вас был кластер, в котором всё как на рисунке ниже: лидер, остальные его слушают, но отвалилась какая-то нода. Она не лидер, не принимает активного участия в жизни кластера, возможно, с неё читают, или это запасной игрок.
Когда какое-то время нода не видит лидера, она начинает запускать выборы, первым делом повышая себе term. Ну повысила term, и ладно, опять дождалась, что никого нет, ещё раз повысила — всё нормально. Однако, когда мы восстанавливаем связность, этот term доезжает до лидера, и всё, что он может сделать в этом случае по Raft, это снять с себя лидерские полномочия и принять участие в выборах. На этот промежуток времени мы получим кластер, недоступный на запись. Это очень неприятная ситуация. Хотелось бы, чтобы нода, которая пропадает, а потом снова появляется, не выводила в read only за собой весь кластер.
К примеру, если эта нода сидит на term 3 и ей никто не отвечает, она не запускает выборы. А когда у неё восстанавливается связность и она узнаёт, что лидер есть, то запускать уже нечего.
Pre-Vote. Проблема №2: прерывание из-за отсутствия лидера в зоне видимости
Вторая проблема с той же исходной точкой: сервер, который напрямую не видит лидера, будет постоянно его прерывать. С этим столкнулась компания Cloudflare, и билась над решением шесть часов.
Опишу суть проблемы. Был кластер из трёх нод. Разорвалась связь между первой и третьей. Кажется, это не катастрофа.
Третья нода говорит: «А где мой лидер? Давайте уже жить нормально!», повышает term и запрашивает у второй ноды голосование. Вторая нода отвечает: «У меня тут term три, а эта хочет четыре — ну, давай, вперёд!» Теперь лидер стал третьим, первый снял с себя полномочия и через таймаут на выборы говорит: «Погодите, а где лидер? У меня term 5!» — и пошло-поехало. Кластер всё время пытается выбрать себе лидера.
Как хочется видеть ситуацию?
Как только нода, которая не видит лидера, предлагает голосовать, тот, кому она прислала запрос, говорит: «Погоди, лидер у нас есть, всё нормально», и нода принимает ответ.
Как в жизни — мы хотим, чтобы действующего лидера зря никто не прерывал. Когда есть возможность продолжать лидерство, пусть так и будет.
Pre-Vote: варианты решения
Для этих проблем мы нашли три способа решения: предварительные выборы, игнорирование выборов голосующими, которые видят лидера, и Pre-Vote на основе метаинформации.
Предварительные выборы
Этот вариант подробно описан в статье Диего Онгаро про Raft:
- Перед началом выборов спрашиваем, проголосуют ли за нас.
- Ответ положительный, если голосующий сам не видит лидера, и если проголосовал бы за кандидата в обычных выборах.
- После получения кворума положительных ответов начинаем выборы.
Например, перед началом выборов можно запускать предварительное голосование. То есть рассылать сообщение о желании избраться, не повышая term. На такое сообщение могут ответить отказом: «Не надо, у нас есть лидер». Если же большинство ответило положительно, то можно начать нормальное голосование и после получения кворума стать лидером.
Проверим работает это или нет. На схеме ниже третья оторванная нода в ожидании кворума запускает предварительное голосование. Ей никто не отвечает и она не может набрать необходимый кворум, поэтому остаётся в term 3. Если связность восстановить, никаких выборов не произойдёт.
Во втором примере мы тоже не видим лидера, и точно также спрашиваем у второй ноды: «Может, проголосуем?». Она отвечает, что лидер есть, поэтому не надо.
У этого решения есть недостаток: требуется новый тип сообщений, который сломает обратную совместимость с существующими инсталляциями. Это не уведомление второй ноды о начале выборов, а предложение об их проведении, требующее от неё согласия. Предыдущая версия Tarantool о таком сообщении не знает и не сможет дальше работать, поэтому мы решили, что такой способ нам подходит только как запасной.
Игнорирование выборов
Можно было бы игнорировать выборы голосующими, которые видят лидера. То есть, сервер, видящий лидера напрямую, игнорирует любые запросы на голос от соседей. К примеру, если я follower в term 3, и мне кто-то присылает term 4, то я его игнорирую и отвечаю, что лидер есть. Однако, если этот term 4 пришлют самому лидеру, он снимет с себя полномочия.
Недостаток решения в том, что оно неполноценное: не работает со временно оторванным сервером. При восстановлении подключения к лидеру он пришлёт ему более высокий term и спровоцирует ненужные выборы, вызвав тем самым простой кластера.
Pre-Vote на основе метаинформации
Мы пошли в сторону «секретного кармана», про который писали выше: каждый сервер знает состояние Raft у соседей благодаря широковещательной рассылке сообщений, которые идут для поддержания текущей репликации.
Мы регулярно либо рассылаем данные, либо присылаем друг другу пинги, и в пинг можно положить информацию о term лидера и о сложившейся в кластере политической ситуации:
- Добавляем в сообщение о состоянии информацию о том, видно ли лидера.
- Если кто-то видит лидера в текущем term, то выборы не начинаем.
Действительно, если кто-то прислал информацию, что лидер жив, зачем выбирать нового? Лидер где-то есть, и главное, что данные к нам попадут.
Проверим, поможет или нет. В одном случае, как только у третьей ноды восстанавливается связность с данными, которые реплицируются, она узнаёт, что первая нода до сих пор является лидером.
Во втором случае, который был у Cloudflare, эта информация будет постоянно приходить в третью ноду, независимо от того, виден ли лидер напрямую.
Мы сошлись на том, что третий способ эквивалентен решению с предварительными выборами, но зато мы сохраняем обратную совместимость. Это решение будем использовать в грядущей версии Tarantool.
Определение Split-Vote
Вторая надстройка, о которой хотим рассказать — выборы по Raft могут длиться со счастливым окончанием, но без гарантии по длительности. Время, необходимое для выборов, вообще неизвестно. Как результат, мы можем получить долгую недоступность кластера на запись после потери лидера. Это произойдёт потому, что каждый раунд выборов, в котором ни одна нода-кандидат не набрала большинства, заканчивается запуском нового раунда. Но прежде, чем новый раунд будет запущен, мы выжидаем полностью весь таймаут на случай, если прилетит решающий голос. Нам такое долгое ожидание не подходит.
В случае успешных выборов, если кто-то сразу набрал большинство, лидер появляется в самом начале раунда, потому что время пинга очень маленькое по сравнению с длительностью раунда. Выжидать весь таймаут нет нужды.
Split-Vote: решение
Итак, у нас есть рассылка отданных голосов. Осталось только научить ноды их считать. Как только в кластере из 6 нод мы видим у одной ноды три голоса и другой три голоса, а всего для победы требуется четыре, то сразу же понимаем, что дальше ждать голосования нет смысла.
Каждая нода может считать голоса, отданные за всех кандидатов. Допустим, у вас три кандидата и большинство голосов разделилось между двумя нодами. Тогда очевидно, что большинство уже никто не наберёт. Можно тут же начинать новые выборы. Мы это реализовали и получили экономию до 90 % времени на каждый раунд с разделившимися голосами.
Fencing
Третья надстройка, которую мы сделали — это Fencing. Сразу предвосхищаю вопросы: под Fencing мы подразумеваем не защиту от старых записей, а стремление избежать появления двух лидеров в один момент времени.
Fencing: проблема №1
Ситуация, когда один лидер уже есть, не исключает возможность существования нескольких нод, считающих себя лидерами в разных term одновременно. Этого хотелось бы избежать, потому что только один лидер может выполнять синхронную запись.
Допустим, один лидер в term 15, другой в term 16, и очень нехорошо, если наши пользователи по-прежнему ходят к обоим, в зависимости от конфигурации клиента. В таком случае, если у нас синхронная репликация, то на одном из двух лидеров запись не сработает, а если асинхронная — может случиться конфликт данных при записи на обоих нодах.
Fencing: проблема №2
Кроме того, упомянутая Pre-Vote, которая информирует о состоянии текущего лидера, может привести нас в состояние заблокированного на запись кластера.
Допустим, в нашей конфигурации было пять нод, одна из которых вышла из строя. Но это только начало проблемы, потому что дальше у четвёртой ноды отвалился кворум связей. Остались лишь связи, достаточные, чтобы распространить информацию на кластер. Это лидер, но если мы попытаемся на него что-то записать, то записи либо не получат кворумного подтверждения и вы будете отваливаться по таймаутам, либо этому лидеру придётся снять полномочия. При этом никто из первых трёх нод не может запустить выборы, потому что лидер известен.
Fencing: способы решения
Теперь о том, как можно решить проблему с Fencing:
1. Для определения текущего лидера клиент может запрашивать у всех нод кластера текущий term и состояние ноды.
Когда мы спрашиваем всех подряд, лидер он или нет, это не решает проблему заблокированного кластера из примера 2, потому что лидер останется один, но писать он не сможет. Для примера 1 продолжительность недоступности на запись увеличивается: все клиенты, которые придут в кластер, должны будут сперва опросить, кто текущий лидер и в каком он term: «Лидера с самым большим term нашёл, я в него буду ходить!». Реализация этого во всех клиентах потребует много усилий.
2. Переложить определение лидера на внешнюю систему, гарантирующую его единственность, и довериться ей.
Это не хорошо, потому что у нас в инсталляции появится ещё одна система. Это будет сторонняя точка отказа, про которую мы ничего не знаем. К тому же потребуется дополнительная экспертиза по работе с такой системой, кластер будет сложнее администрировать.
3. Доработать RAFT в Tarantool.
Как бы нам хотелось это сделать в Tarantool? Во-первых, хотелось бы оповещать клиента. Проще всего сделать это, если он к кому-то обратился, а тот скажет, что больше не лидер и, может быть, сообщит, кто лидер.
Нода-лидер следит за обрывом соединений между репликами и может сказать: «У меня нет кворума, я больше не могу ничего подтверждать, поэтому я не буду лидером», снимет с себя полномочия и начнёт отвечать клиентам: «Я больше не лидер, ко мне больше не ходите».
Рассмотрим простой вариант:
Есть три ноды, лидер что-то пишет. Проходит некоторое время, пока запись доходит до Follower 1 и Follower 2, и те отправляют ответы-подтверждения.
Зелёным цветом выделены таймауты на репликацию. Допустим, Leader получил ответ как раз под самое окончание этого таймаута (t1), но Follower 1 начал свой таймаут на запуск выборов раньше — при отправке ответа. Допустим, после этого случился разрыв сети, и по прошествии таймаута Follower 1 запустит выборы. Сети нет, Follower 2 с Follower 1 могут очень быстро договориться к моменту t2 (стрелки синего цвета обозначают взаимодействие), тем более, что мы постарались ускорить выборы. И между t2 и t3, когда на Leader истечёт таймаут на репликацию, в кластере существует два лидера одновременно — неприятно!
Рассмотрим крайний случай. Сообщение от лидера до Follower летит очень быстро, а назад летит ровно столько, сколько длится таймаут. Это значит, что лидер получит весточку как раз под конец периода его легитимности. Поэтому нам, чтобы не начинать новые выборы, пока лидер может считать себя легитимным, надо иметь удвоенный таймаут, что мы и реализовали. Если на Followers поставить таймаут в два раза больше, то перевыборы запустятся после того, как лидер уже снимет с себя полномочия. При этом мы решили сохранить обратную совместимость даже с тем решением, которое у нас было до сих пор. Назвали это отдельным конфигурационным параметром Fencing.
Три варианта применения Fencing:
- Выключен.
- Слабый Fencing — более быстрый Follower, но можно увидеть двух лидеров, если таймауты равны.
- Сильный Fencing — точно не будет двух лидеров.
Более сильный Fencing приведёт к увеличенному периоду перевыборов, то есть Follower замедлится, но зато будет гарантия, что двух лидеров, хоть и в разных term, не окажется.
Выводы
Мы ожидали от Raft:
- Один лидер на term == один лидер в данный момент времени.
- Лидер постоянен.
- Быстрая смена лидера.
Получили буквально то же самое:
- Fencing: один лидер на term == один лидер в данный момент времени.
- Pre-Vote, Fencing: лидер постоянен.
- Определение Split-Vote: возможна быстрая смена лидера, ускорили выборы примерно в 10 раз.
Надеемся, что наше решение будет иметь большую практическую значимость, и что Tarantool станет вашим инструментом.
