

В мире данных происходит революция. Сегодня волна Open-Source-форматов данных, поднявшаяся благодаря развитию технологий, меняет привычное положение дел для всех участников экосистемы, от поставщиков до предприятий. Вы наверняка слышали о таких форматах, как Parquet, ORC, Avro, Arrow, Protobuf, Thrift и MessagePack. Команда VK Cloud перевела статью о том, что они собой представляют и какой из них лучше выбрать.
Трудности с большими данными
Чтобы вовремя генерировать аналитику, необходимую для информированных решений и оптимизации бизнеса, нужно правильно организовать и анализировать данные. Работа с неструктурированными данными — изображениями, PDG, аудио, видео и т. п. — сопряжена с различными трудностями. Структурированные и полуструктурированные данные, такие как файлы CSV, XML, JSON и другие, плохо поддаются сжатию, оптимизации и долговременному хранению.
Бизнес-данные, которые накапливают компании, становятся все сложнее. Раньше для каждого Data Event создавалось по 20 полей, но их количество уже давно перевалило за сотню. Эти данные легко хранить в озере, но в строковых форматах для выполнения запроса нужно просканировать значительный объем данных.
Способность формулировать запросы и манипулировать данными становится критически важной в области обработки данных, искусственного интеллекта, машинного обучения, бизнес-аналитики и отчетности. Эти задачи требуют находить малые диапазоны в огромных дата-сетах — и отсюда возникает потребность в разных форматах данных.
Форматы данных для микросервисов
Сначала давайте посмотрим на структуры, достаточно далекие от озера данных. Форматы Protobuf, Thrift и MessagePack больше подходят для взаимодействия между микросервисами.
Protocol Buffers
Protocol Buffers от Google (также известный как Protobuf) — это формат сериализации данных без привязки к языку и платформе. Он позволяет эффективно кодировать структурированную информацию для передачи по сети или хранения в файле. Это расширяемый формат, так что пользователи могут определять собственные типы и структуры данных. Protobuf обеспечивает компактное бинарное представление, которое можно эффективно передавать и хранить.
Protocol Buffers используется в разных API Google и поддерживается многими языками программирования, в том числе C++, Python и Java. Его часто используют в ситуациях, когда данные нужно передать по сети или хранить в компактном формате, как в случае с протоколами передачи данных, хранилищами и интеграцией.
Обзор реализации
gRPC — это современный, высокопроизводительный Open-Source-фреймворк RPC (удаленного вызова процедур), который можно запустить в любой среде. Он обеспечивает непосредственное взаимодействие между методами клиентских и серверных приложений подобно вызову метода в объектно-ориентированном программировании. gRPC построен на основе HTTP/2 как транспортного протокола и фреймворка ProtoBuf для кодирования запросов и ответных сообщений. Эффективность gRPC, способного работать в любой среде, обеспечивается поддержкой двунаправленной потоковой передачи и обменом сообщениями с небольшой задержкой. gRPC используется в разных API Google и поддерживается множеством языков программирования, в том числе C++, Python и Java.
Формат применяется в контекстах и приложениях, для которых важны низкий уровень задержки, высокая производительность и эффективность обмена сообщениями. Его часто используют для связи между собой полиглотных систем, например мобильных устройств, веб-клиентов и бэкенд-сервисов. Кроме того, он подходит для подключения сервисов и создания масштабируемых распределенных систем в микросервисных архитектурах. gRPC также применяется в IoT-приложениях, для потоковой передачи и обмена сообщениями в реальном времени и для подключения облачных сервисов.
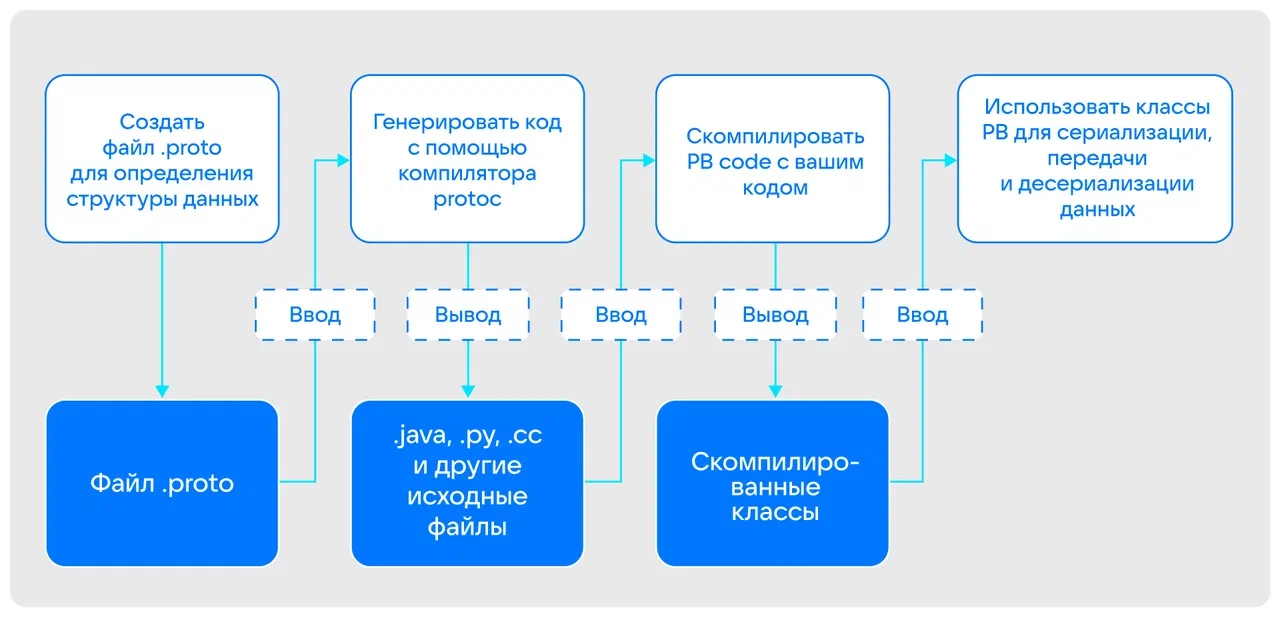
Источник: developers.google.com/protocol-buffers
Thrift
Thrift — это язык описания интерфейсов (IDL) и протокол связи, который обеспечивает разработку масштабируемых сервисов, работающих с несколькими языками программирования. Он похож на другие языки IDL, например на CORBA и Google Protocol Buffers, но меньше весит и проще в использовании. В Thrift используется механизм генерации кода для необходимого языка программирования на основе определений IDL. Таким образом, разработчики могут легко создавать клиентские и серверные приложения, способные взаимодействовать друг с другом посредством двоичного протокола связи Thrift. Сфера применения Thrift охватывает распределенные системы, микросервисы и Message-oriented middleware.
Поддерживаемые языки
Apache Thrift поддерживает множество языков программирования, в том числе функциональные языки, например Erlang и Haskell. С Thrift можно определить сервис на одном языке, а потом сгенерировать необходимый код для реализации на другом. Также можно сгенерировать клиентские библиотеки, которые обеспечат вызов сервиса из другого языка. Таким образом, можно создавать взаимосвязанные системы, в которых используются разные языки программирования.
Обзор реализации
Код, сгенерированный компилятором IDL, создает клиент-серверные заглушки. Под капотом они взаимодействуют между этими двумя нативными протоколами и транспортным уровнем, тем самым обеспечивая RPC между процессорами.

Источник: https://thrift.apache.org/
MessagePack
MessagePack — это формат сериализации, который обеспечивает компактное бинарное представление структурированных данных. Он эффективнее и быстрее других форматов сериализации, таких как JSON, благодаря представлению в двоичном, а не в текстовом формате. MessagePack применяют в распределенных системах, микросервисах и хранилищах данных. Он поддерживается множеством языков программирования, в том числе C++, Python и Java. Его часто используют, чтобы передавать данные по сети или хранить их в компактном формате. Кроме того, MessagePack — это расширяемый формат, так что пользователи могут определять собственные типы и структуры.
Обзор реализации
Мы в MinIO решили использовать MessagePack в качестве формата сериализации. Благодаря возможности добавлять и удалять ключи обеспечивается расширяемость с JSON. Его изначальная реализация — это заголовок, за которым следует объект MessagePack со структурой:
{
"Versions": [
{
"Type": 0, // Type of version, object with data or delete marker.
"V1Obj": { /* object data converted from previous versions */ },
"V2Obj": {
"VersionID": "", // Version ID for delete marker
"ModTime": "", // Object delete marker modified time
"PartNumbers": 0, // Part Numbers
"PartETags": [], // Part ETags
"MetaSys": {} // Custom metadata fields.
// More metadata
},
"DelObj": {
"VersionID": "", // Version ID for delete marker
"ModTime": "", // Object delete marker modified time
"MetaSys": {} // Delete marker metadata
}
}
]
}
Преобразования метаданных унаследованы от предыдущих версий, а новые версии включают
V2Obj или DelObj в зависимости от активной операции при получении запросов на обновление. В сущности, когда нам нужно просто прочитать метаданные, можно остановить чтение файла, дочитав до их конца. Для получения обновлений нужно максимум два непрерывных чтения. Для этого меняется и представление на диске. Раньше все метаданные хранились как большой объект, содержащий все версии. Теперь мы пишем это следующим образом:- сигнатура с версией;
- версия данных заголовка (целое число);
- версия метаданных (целое число);
- счетчик версий (целое число).
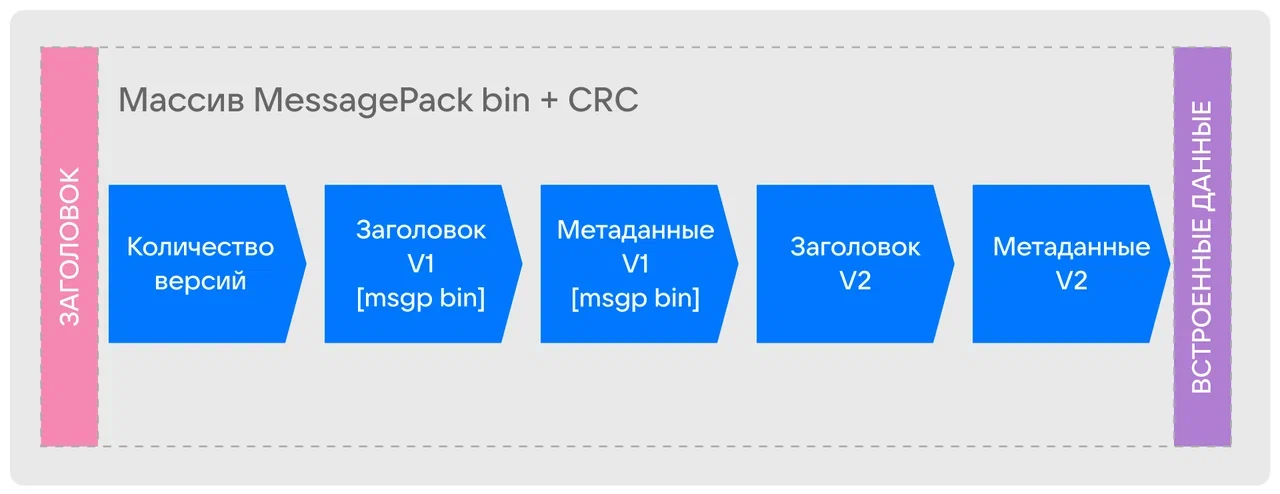
Общая структура xl.meta
Форматы данных для потоковой передачи
Avro
Apache Avro — это система сериализации, позволяющая быстро создавать компактные двоичные представления структур данных. Поскольку это расширяемый формат, пользователи могут самостоятельно определять типы и структуры. Он также поддерживает динамически и статически типизированные языки. Avro часто используют в экосистеме Hadoop: его области применения охватывают хранение, обмен данными и их интеграцию.
В Avro для сериализации и десериализации данных определяется схема, поэтому он поддерживает разнообразные структуры данных и их изменение с течением времени. А еще Avro работает с файлами контейнеров для хранения Persistent Data, RPC и интеграции с разными языками.
Формат основан на схемах, которые сохраняются в файле при записи данных. Схема представляет собой JSON-документ, определяющий структуру, которая хранится в файле или передается в сообщении Avro. Она определяет тип для полей данных, а также имена и порядок следования этих полей. Кроме того, структура может содержать информацию о кодировании и сжатии данных, а также о любых метаданных.
Схемы Avro обеспечивают хранение и передачу информации в единообразном и предсказуемом формате. Данные, которые записываются в файл Avro или передаются в сообщении Avro, хранятся вместе со схемой, так что получатель знает, как их интерпретировать.
Основанный на схемах подход обеспечивает компактность и высокую скорость сериализации, поддерживая при этом динамические скриптовые языки. Файлы можно обработать позже в любой программе. А если программе, считывающей данные, нужна другая схема, нет проблем, ведь обе схемы доступны.
Поддерживаемые языки
Apache Avro — наиболее популярный формат сериализации для записи данных; его чаще всего выбирают для пайплайнов потоковой передачи. В нем есть надежная поддержка эволюции схемы, а также реализации для JVM (Java, Kotlin, Scala, …), Python, C/C++/C#, PHP, Ruby, Rust, JavaScript и даже Perl.
У нас в документации есть полезные материалы по сравнению Avro с другими системами. Apache Kafka и платформа Confluent разработали специальные коннекторы для него, но они работают с любым форматом данных.
Форматы файлов Big Data для озера данных
Parquet
Apache Parquet — это столбчатый формат хранения для обработки больших данных. Он активно используется в экосистеме Hadoop. Несмотря на снижение ее популярности, этот формат остается весьма распространенным — отчасти потому, что он все еще поддерживается ключевыми системами обработки данных, в том числе Apache Spark, Apache Flink и Apache Drill.
Реализованный в Parquet способ организации данных оптимизирует их для столбчатых операций, таких как фильтрация и агрегирование. Чтобы хранить данные с высокой эффективностью, в Parquet используется сочетание приемов сжатия и кодирования. Формат позволяет создавать схемы, поддерживающие применение ограничений по типам данных и обработку с высокой скоростью. Parquet — популярное решение для хранения больших наборов и запросов к ним, поскольку в этом формате запросы выполняются быстро, а хранение и обработка — эффективно.
Обзор реализации
Эта схема позволяет эффективно фиксировать метаданные, поддерживает эволюцию файлового формата и упрощает хранение. Алгоритмы сжатия Parquet снижают требования к объемам хранилища, позволяют быстрее извлекать данные и поддерживаются множеством фреймворков. Есть три типа метаданных: файла, столбца (фрагмента) и заголовка страницы. Для сериализации и десериализации структур метаданных в Parquet используется Thrift TCompactProtocol.
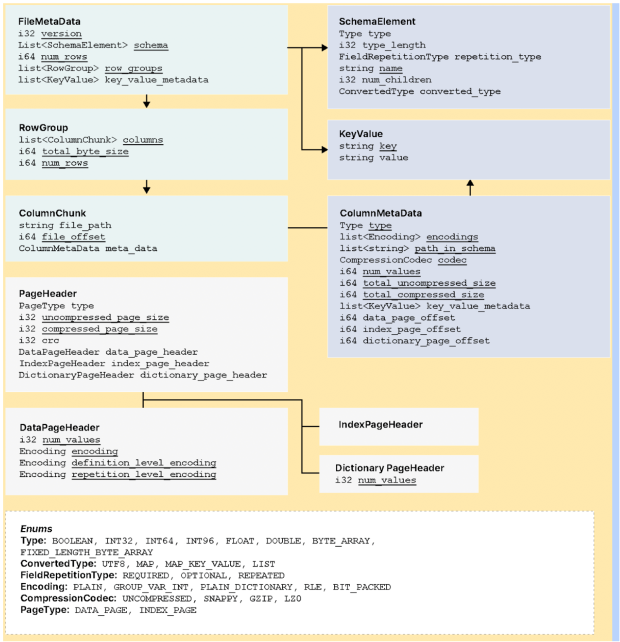
Источник: parquet.apache.org
ORC
ORC, или Optimized Row Columnar — это формат хранения, предназначенный для повышения производительности систем обработки данных. ORC хранит информацию в столбчатом виде. Это позволяет быстрее выполнять запросы и анализ, поскольку доступ осуществляется только к нужным столбцам без чтения всех строк. Функции ORC также включают сжатие, Predicate Pushdown, улучшенный параллелизм при использовании отдельных RecordReader для одних и тех же файлов и вывод типов для дальнейшего повышения производительности.
Еще одно преимущество ORC по сравнению с RCFile, особенно в деплойментах Hadoop, — значительное сокращение нагрузки на NameNodes. Следует отметить, что формат ORC ориентирован на архитектуру и рабочие нагрузки Hadoop. Учитывая, что самые современные стеки данных отходят от Hadoop, возможности применения ORC в облачной среде довольно ограничены.
Обзор реализации
Строковые данные в файле ORC организованы в группы, так называемые Stripe, и содержат последовательности строк и метаданных об этих строках. Каждый Stripe содержит последовательность строк, а каждая строка делится на последовательность столбцов. Данные из каждого столбца хранятся отдельно, что позволяет ORC эффективно читать не всю строку, а только те столбцы, которые нужны для конкретного запроса. ORC также включает метаданные о данных, например о типах, и сведения о сжатии, что помогает повысить скорость чтения. ORC поддерживает множество форматов сжатия, в том числе zlib, LZO и Snappy. Благодаря этому сокращается размер данных на диске и повышается производительность чтения и записи. Формат также поддерживает разные типы индексов, такие как индексы строки и фильтры Блума: это дополнительно повышает скорость чтения.
Источник: orc.apache.org
Результат
orcfiledump содержит сводную информацию по метаданным файла: количество строк, столбцов и Stripe в файле, типы данных столбцов и информацию о любых индексах, которая хранится в файле.В дополнение к метаданным
orcfiledump также выводит на печать фактические данные в файле ORC. К ним относятся значения каждого столбца в каждой строке, а также любые имеющиеся значения NULL. Каждая строка представляет собой запись, состоящую из каждого столбца, который определяется как поле. Сочетания строк представляют собой табличную структуру.Arrow
Apache Arrow — это столбчатый Open-Source-формат хранения данных в памяти, повышающий скорость работы при выполнении задач по обработке и аналитике. Он стандартизирован и используется для представления и манипулирования данными в разных системах, фреймворках обработки и библиотеках машинного обучения.
Одно из ключевых преимуществ Apache Arrow — способность эффективно передавать данные между разными системами и процессами. Он обеспечивает обмен без сериализации и десериализации, которые периодически требуют много времени и ресурсов. Благодаря этому формат хорошо подходит для использования в распределенных и параллельных вычислительных средах, где нужно быстро обрабатывать и анализировать большие объемы данных.
Преимущества Apache Arrow не ограничиваются высокой производительностью. В этом формате реализована поддержка большого спектра типов данных, поддержка вложенных и иерархических структур, а также интеграция со множеством языков программирования. Формат Arrow часто используется в приложениях для Big Data и аналитики, где он позволяет эффективно передавать данные между системами и выполнять обработку в памяти. Он также используется в разработке распределенных систем и аналитических пайплайнов, работающих в реальном времени.
Обзор реализации
Большинство команд по работе с данными сталкиваются с низкой эффективностью и проблемами производительности, которые возникают из-за сериализации и десериализации внутреннего формата каждой БД и каждого языка без стандартного столбчатого формата данных. Другая серьезная проблема — дублирование и увеличение размеров таблицы из-за бесполезных данных, вызванных необходимостью писать стандартные алгоритмы для каждого формата.
Источник: arrow.apache.org
Столбчатый формат хранения в памяти Arrow значительно улучшает аналитику данных с помощью сокращения числа операций чтения и записи на диск и повышения скорости выполнения запросов. Он использует двоичное представление данных фиксированной ширины, которое позволяет быстро читать и писать в память. Кроме повышения скорости операций с помощью вычислений в памяти, фреймворк позволяет добавлять пользовательские коннекторы, чтобы упростить агрегирование данных разных форматов.

Источник: arrow.apache.org
Dremio — это инструмент ускорения запросов на основе фреймворка Arrow. Dremio обеспечивает высокую скорость обращения к разным источникам данных: БД, озера и облачные хранилища. Он использует столбчатый формат Arrow для хранения и обработки данных, что позволяет воспользоваться такими его преимуществами, как производительность и эффективность. Подробнее об этом можно прочитать в статье «Apache Arrow, и как этот формат вписывается в сегодняшний ландшафт данных».
Каждому свое: как выбрать лучший формат
Компании вкладывают деньги в микросервисную архитектуру, чтобы улучшить управление программным обеспечением и отказаться от монолитных решений. Переход на контейнеры и большие кластеры Kubernetes — естественный ход вещей. Эти микросервисы встроены в гетерогенные языки и основываются на парадигме «полиглотного плюрализма». Для этих сценариев подходят Protocol Buffers, Thrift или MessagePack. Они упрощают взаимодействие между микросервисами и повышают скорость обработки событий. Другое преимущество, которое помогает улучшить поддержку приложений, — это способность выполнять деплойменты часто и автономно.
С появлением потоковых архитектур и архитектур на основе сообщений возросла потребность в новых форматах и сжатии данных, и на первый план вышел формат Avro. Как мы упоминали выше, Arvo — очень гибкий формат, который можно применять для микросервисов, потоковых приложений и архитектур на основе сообщений. Он активно используется в архитектурах озера данных и Lake House. Открытые табличные форматы (Iceberg и Hudi) используют Avro со схемами, поддерживающими изоляцию моментальных снимков.
Parquet — наиболее популярный формат для архитектуры озера данных и Lake House, который остается стандартом в этой области. Благодаря способности ORC поддерживать большие размеры Stripe этот формат приобрел популярность в мире Hadoop Distributed File System (HDFS), но, как мы знаем, мир этот становится все меньше и меньше. Все же он хорошо подходит для таких сценариев использования, как резервное копирование. Новый формат Arrow отлично подходит для In-memory и может применяться для объектных хранилищ, в которых потребность в Object Persistence не столь длительна.
Современный стек данных — это выбор, и хороших вариантов для выбора форматов данных и файлов становится все больше. MinIO поддерживает все из них, оставляя выбор решения за вами и вашим архитектором облачных решений.
Вы прямо сейчас можете воспользоваться инструментами для работы с данными от VK Cloud. Для тестирования мы начисляем новым пользователям 3000 бонусных рублей и будем рады вашей обратной связи.
Stay tuned
Присоединяйтесь к телеграм-каналу «Данные на стероидах». В нем вы найдете все об инструментах и подходах для извлечения максимальной пользы из работы с данными: регулярные дайджесты, полезные статьи, а также анонсы конференций и вебинаров.
