
Сегодня мы начинаем публиковать серию постов о машинном обучении и его месте в Яндексе, а также инструментах, которые избавили разработчиков поисковой системы от рутинных действий и помогли сфокусироваться на главном — изобретении новых подходов к улучшению поиска. Основное внимание мы уделим применению этих средств для улучшения формулы релевантности, и более широко — для качества ранжирования.

Наша отрасль устроена так, что качеством поиска нужно заниматься постоянно. Во-первых, поисковые компании конкурируют между собой, а любое улучшение быстро приводит к изменению доли рынка каждой. Во-вторых, поисковые оптимизаторы стараются найти слабые места в алгоритмах, чтобы поднимать в результатах поиска даже те сайты, которые менее релевантны запросам людей. В-третьих, привычки пользователей меняются. Например, за последние несколько лет длина среднего поискового запроса выросла с 1,5 до 3 слов.
Качество поиска — это комплексное понятие. Оно состоит из множества взаимосвязанных элементов: ранжирования, сниппетов, полноты поисковой базы, безопасности и многих других. В этой серии статей мы рассмотрим только один аспект качества — ранжирование. Как многим уже известно, оно отвечает за порядок предоставления найденной информации пользователю.
Даже самая простая идея, которая может его улучшить, должна проделать сложный многошаговый путь от обсуждения в кругу коллег до запуска готового решения. И чем более автоматизированным (а значит быстрым и простым для разработчика) будет этот путь, тем быстрее пользователи смогут воспользоваться этим улучшением и тем чаще Яндекс сможет запускать такие нововведения.
Возможно, вы уже читали о платформе распределённых вычислений Yet Another MapReduce (YAMR), библиотеке машинного обучения Матрикснет и основном алгоритме обучения формулы ранжирования. Теперь мы решили рассказать и о фреймворке FML (friendly machine learning — «машинное обучение с человеческим лицом»). Он стал следующим шагом в автоматизации и упрощении работы наших коллег — поставил работу с машинным обучением на поток. Вместе FML и Матрикснет являются частями одного решения — технологии машинного обучения Яндекса.
Рассказывать о FML достаточно сложно, а сделать это мы хотим обстоятельно. Поэтому разобьём наш рассказ на несколько постов:
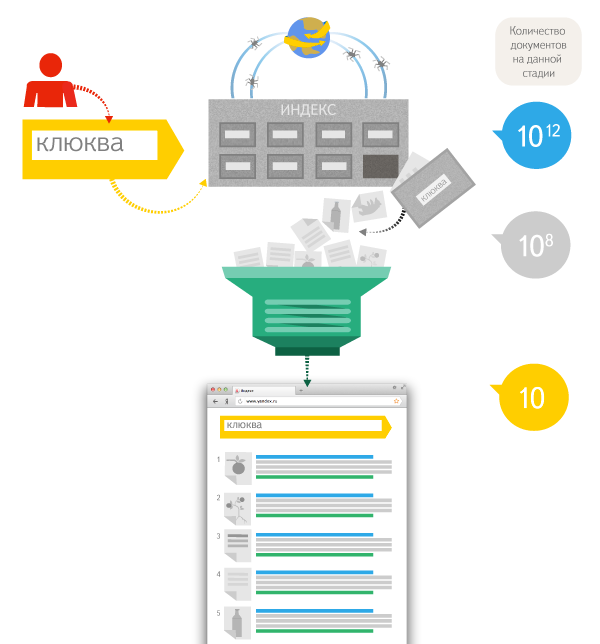
После того как поисковая система приняла запрос пользователя и нашла все подходящие страницы, она должна упорядочить их по принципу наибольшего соответствия запросу. Алгоритм, выполняющий эту работу, и называется функцией ранжирования (в СМИ её иногда называют формулой релевантности). Именно в том, чтобы выделить наиболее важные из найденных страниц и определить «правильный» порядок их выдачи, и заключается задача ранжирования. Его улучшение — первое и главное место, где используются FML и Матрикснет.
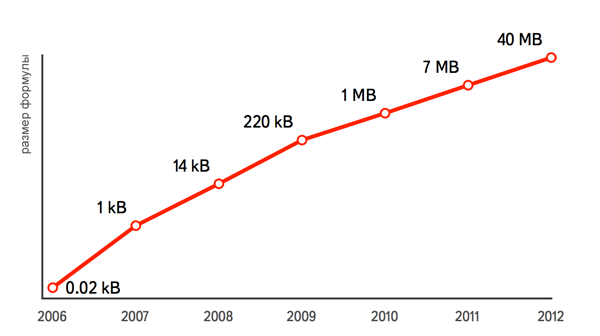
Когда-то давно в Яндексе функция ранжирования выражалась одной единственной формулой, подобранной вручную. Её размер растёт экспоненциально (на графике шкала Y — логарифмическая).
Помимо того, что со временем формула грозила достичь неуправляемых размеров, появились и другие причины перехода от ручного подбора к машинному обучению. Например, в какой-то момент нам потребовалось иметь одновременно несколько формул, чтобы одинаковые запросы обрабатывались по-разному в зависимости от региона пользователя.
Формально в ранжировании, как и в любой задаче машинного обучения с учителем, нам нужно построить функцию, которая наилучшим образом соответствует экспертным данным. В ранжировании эксперты определяют порядок, в котором нужно показывать документы по конкретным запросам. Таких запросов десятки тысяч. И чем лучше, с точки зрения экспертных оценок, оказался порядок документов, сформированный формулой, тем лучшее ранжирование мы получили. Эти данные называются оценками и, как многие знают, готовятся отдельными специалистами — асессорами. Для каждого запроса они оценивают, насколько хорошо тот или иной документ отвечает на него.
Входными данными для обучаемой функции, по которым она должна определить порядок документов для любого другого запроса, выступают так называемые факторы — различные признаки страниц. Эти признаки могут как зависеть от запроса (например, учитывать, сколько его слов содержится в тексте страницы), так и нет (например, отличать стартовую страницу сайта от внутренних). Среди факторов, используемых для обучения, есть также признаки самого запроса, которые едины для всех страниц — к примеру, на каком языке задан запрос, сколько в нём слов, насколько часто его задают пользователи.
Машинное обучение использует обучающую выборку, чтобы установить зависимость между порядком страниц для запроса, полученным исходя из их оценки людьми, и признаками этих страниц. Полученная функция используется для ранжирования по всем запросам, независимо от наличия по ним экспертных оценок.
Для построения хорошей формулы ранжирования важно не только получить оценки релевантности, но и правильным образом отобрать запросы, по которым их делать. Поэтому мы берём такое их подмножество, которое бы наилучшим образом представляло интересы пользователей.
Существует несколько технологий получения асессорских оценок, и каждая из них даёт свой вид суждений. В данный момент в Яндексе асессоры оценивают релевантность документа запросу по пятибалльной шкале. Этот метод основан на методологии Cranfield II. В других задачах мы используем и иные виды экспертных данных — например, в классификаторах могут применяться бинарные оценки.
Итак, функция ранжирования строится по набору факторов и по обучающим данным, подготовленным экспертами. Её построением и занимается машинное обучение — в случае Яндекса библиотека Матрикснет. В следующих постах мы расскажем о том, откуда берутся поисковые факторы, и как всё это связано с FML.
Наша отрасль устроена так, что качеством поиска нужно заниматься постоянно. Во-первых, поисковые компании конкурируют между собой, а любое улучшение быстро приводит к изменению доли рынка каждой. Во-вторых, поисковые оптимизаторы стараются найти слабые места в алгоритмах, чтобы поднимать в результатах поиска даже те сайты, которые менее релевантны запросам людей. В-третьих, привычки пользователей меняются. Например, за последние несколько лет длина среднего поискового запроса выросла с 1,5 до 3 слов.
Качество поиска — это комплексное понятие. Оно состоит из множества взаимосвязанных элементов: ранжирования, сниппетов, полноты поисковой базы, безопасности и многих других. В этой серии статей мы рассмотрим только один аспект качества — ранжирование. Как многим уже известно, оно отвечает за порядок предоставления найденной информации пользователю.
Даже самая простая идея, которая может его улучшить, должна проделать сложный многошаговый путь от обсуждения в кругу коллег до запуска готового решения. И чем более автоматизированным (а значит быстрым и простым для разработчика) будет этот путь, тем быстрее пользователи смогут воспользоваться этим улучшением и тем чаще Яндекс сможет запускать такие нововведения.
Возможно, вы уже читали о платформе распределённых вычислений Yet Another MapReduce (YAMR), библиотеке машинного обучения Матрикснет и основном алгоритме обучения формулы ранжирования. Теперь мы решили рассказать и о фреймворке FML (friendly machine learning — «машинное обучение с человеческим лицом»). Он стал следующим шагом в автоматизации и упрощении работы наших коллег — поставил работу с машинным обучением на поток. Вместе FML и Матрикснет являются частями одного решения — технологии машинного обучения Яндекса.
Рассказывать о FML достаточно сложно, а сделать это мы хотим обстоятельно. Поэтому разобьём наш рассказ на несколько постов:
- Что такое ранжирование и какие задачи оно решает. Здесь мы расскажем о проблематике ранжирования и основных сложностях, возникающих в этой области. Даже если вы никогда не занимались этой темой, этого введения будет достаточно для понимания всего последующего материала. А уже знакомые с ранжированием смогут свериться с нами в используемой терминологии.
- Подбор формулы ранжирования. Вы узнаете о том, как FML стал конвейером по подбору формул (да-да, их много!), чтобы оперативно учитывать большой объём асессорских оценок и новых факторов при минимальном участии человека. А также о созданном в Яндексе кластере на GPU-процессорах, который вполне может войти в сотню самых мощных суперкомпьютеров в мире.
Разработка новых факторов и оценка их эффективности. Как правило, публикации в сфере машинного обучения уделяют основное внимание самому процессу подбора формул, а разработку новых факторов обходят стороной. Однако сколько бы замечательной ни была технология машинного обучения, без хороших факторов ничего не получится. В Яндексе существует даже отдельная группа разработчиков, занятая исключительно их созданием. Здесь речь пойдёт о том, из чего состоит технологический цикл, в результате которого появляются новые факторы, и каким образом FML помогает оценить пользу от внедрения и себестоимость каждого из них.
- Мониторинг качества уже внедрённых факторов. Интернет постоянно меняется. И вполне возможно, что факторы, которые ещё несколько лет назад очень помогли поднять качество, на сегодняшний день утратили свою ценность и впустую расходуют вычислительные ресурсы. Поэтому мы расскажем о том, как FML поддерживает постоянную эволюцию, в которой слабые факторы погибают и уступают место сильным.
Конвейер распределённых вычислений. Машинное обучение — лишь одна из задач, которые хорошо решает FML. Более широко его применяют для того, чтобы упростить работу с распределёными вычислениями на кластере в несколько тысяч серверов над большим массивом данных, меняющимся во времени. На сегодняшний день около 70% вычислений в разработке Яндекс.Поиска находится под управлением FML.
Области применения и сравнение с аналогами. FML используется в Яндексе для машинного обучения целым рядом команд и для решения далёких от поиска задач. Мы полагаем, что наша разработка может пригодиться и коллегам по отрасли, имеющим дело с задачами машинного обучения, да и просто с расчётами на больших объёмах данных. Мы обозначим круг задач, для решения которых FML может оказаться полезным и за пределами Яндекса, и сравним его с аналогами, доступными на рынке. Мы также расскажем, как применение FML в CERN может открыть дорогу Нобелевской премии.
Что такое ранжирование и какую задачу оно решает
После того как поисковая система приняла запрос пользователя и нашла все подходящие страницы, она должна упорядочить их по принципу наибольшего соответствия запросу. Алгоритм, выполняющий эту работу, и называется функцией ранжирования (в СМИ её иногда называют формулой релевантности). Именно в том, чтобы выделить наиболее важные из найденных страниц и определить «правильный» порядок их выдачи, и заключается задача ранжирования. Его улучшение — первое и главное место, где используются FML и Матрикснет.
Когда-то давно в Яндексе функция ранжирования выражалась одной единственной формулой, подобранной вручную. Её размер растёт экспоненциально (на графике шкала Y — логарифмическая).
Помимо того, что со временем формула грозила достичь неуправляемых размеров, появились и другие причины перехода от ручного подбора к машинному обучению. Например, в какой-то момент нам потребовалось иметь одновременно несколько формул, чтобы одинаковые запросы обрабатывались по-разному в зависимости от региона пользователя.
Формально в ранжировании, как и в любой задаче машинного обучения с учителем, нам нужно построить функцию, которая наилучшим образом соответствует экспертным данным. В ранжировании эксперты определяют порядок, в котором нужно показывать документы по конкретным запросам. Таких запросов десятки тысяч. И чем лучше, с точки зрения экспертных оценок, оказался порядок документов, сформированный формулой, тем лучшее ранжирование мы получили. Эти данные называются оценками и, как многие знают, готовятся отдельными специалистами — асессорами. Для каждого запроса они оценивают, насколько хорошо тот или иной документ отвечает на него.
Входными данными для обучаемой функции, по которым она должна определить порядок документов для любого другого запроса, выступают так называемые факторы — различные признаки страниц. Эти признаки могут как зависеть от запроса (например, учитывать, сколько его слов содержится в тексте страницы), так и нет (например, отличать стартовую страницу сайта от внутренних). Среди факторов, используемых для обучения, есть также признаки самого запроса, которые едины для всех страниц — к примеру, на каком языке задан запрос, сколько в нём слов, насколько часто его задают пользователи.
Машинное обучение использует обучающую выборку, чтобы установить зависимость между порядком страниц для запроса, полученным исходя из их оценки людьми, и признаками этих страниц. Полученная функция используется для ранжирования по всем запросам, независимо от наличия по ним экспертных оценок.
Для построения хорошей формулы ранжирования важно не только получить оценки релевантности, но и правильным образом отобрать запросы, по которым их делать. Поэтому мы берём такое их подмножество, которое бы наилучшим образом представляло интересы пользователей.
Существует несколько технологий получения асессорских оценок, и каждая из них даёт свой вид суждений. В данный момент в Яндексе асессоры оценивают релевантность документа запросу по пятибалльной шкале. Этот метод основан на методологии Cranfield II. В других задачах мы используем и иные виды экспертных данных — например, в классификаторах могут применяться бинарные оценки.
Почему стандартные методики неприменимы в ранжировании
Однако, даже собрав достаточное число оценок и рассчитав для каждой пары (запрос + документ) набор факторов, построить ранжирующую функцию стандартными методами оптимизации не так просто. Основная сложность возникает из-за кусочно-постоянной природы целевых метрик ранжирования (nDCG, pFound и т.п.). Это свойство не позволяет использовать здесь, например, известные градиентные методы, которые требуют дифференцируемости функции, которую мы оптимизируем.
Существует отдельная научная область, посвященная метрикам ранжирования и их оптимизации — Learning to Rank (обучение ранжированию). А в Яндексе есть специальная группа, которая занимается реализацией и совершенствованием различных методов решения этого достаточно узкого, но очень важного для поиска класса оптимизационных задач.
Существует отдельная научная область, посвященная метрикам ранжирования и их оптимизации — Learning to Rank (обучение ранжированию). А в Яндексе есть специальная группа, которая занимается реализацией и совершенствованием различных методов решения этого достаточно узкого, но очень важного для поиска класса оптимизационных задач.
Итак, функция ранжирования строится по набору факторов и по обучающим данным, подготовленным экспертами. Её построением и занимается машинное обучение — в случае Яндекса библиотека Матрикснет. В следующих постах мы расскажем о том, откуда берутся поисковые факторы, и как всё это связано с FML.
