
Ежедневно Яндекс обрабатывает входящий поток из миллионов писем и файлов. Их количество постоянно и непрерывно увеличивается. При этом уровень входящей нагрузки неравномерный, он сильно зависит от времени суток и дня недели. Кроме того, периодически случаются ботнет-атаки.
Задача усложняется тем, что каждое письмо и каждый файл требуют дополнительной обработки: мы классифицируем их, сохраняем, извлекаем текст, распознаем образы, создаем индексы. Благодаря этому в дальнейшем пользователю гораздо проще найти нужные письма или файлы.

Обработка может занимать разное время: от миллисекунд, требуемых для сохранения письма, до нескольких десятков секунд, затрачиваемых, например, на извлечение текста из фотографий.
Как бы мы не рассчитывали мощность системы приема и обработки писем и файлов, мы никогда не застрахованы от ситуаций, когда входной поток значительно превышает наши ожидания.
В этих случаях нам помогают очереди. Они позволяют сгладить всплески входной нагрузки: выиграть время и дождаться, когда кластер обработки писем станет доступен.
Очередь на обработку документов мало чем отличается от живой очереди в магазине или на почте. Там они тоже возникают по той же причине: обслуживать клиентов мгновенно невозможно. Однако важное преимущество очереди на обработку документов в Персональных сервисах Яндекса заключается в том, что стоят в ней только письма и файлы, пользователю ждать ничего не надо. По сути это буфер, в который можно быстро записать файлы и письма, а когда нагрузка на систему обработки спадет, быстро все это прочитать.
Как правило с очередью работают две программы: одна записывает в нее данные, другая вычитывает их и отправляет потребителю.
Программа записи в очередь должна быть максимально простой, чтобы не вносить никаких дополнительных задержек на приеме задачи, мы же не хотим делать еще одну очередь на помещение в основную. И программа чтения из очереди уже взаимодействует с различными функциональными элементами сервисов: Почты/Диска или других продуктов.
Программ чтения данных может быть несколько, каждая из которых служит для специализированной обработки данных. Программа чтения может работать существенно дольше, чем программа записи, поскольку на нее возложена дополнительная функциональность. Поэтому очередь должна уметь хранить данные за промежуток времени, достаточный для обработки писем/файлов своими источниками.
В основном очереди используются там, где есть неравномерная входная нагрузка и требуется выполнять операции над данными. В частности, на приеме писем в почту и файлов в диск.
При использовании очередей важно учитывать такие правила:
Письма влетают в почту и попадают в кластер Mx-Front, программы которого обрабатывают письма и сохраняют их в почтовые хранилища.
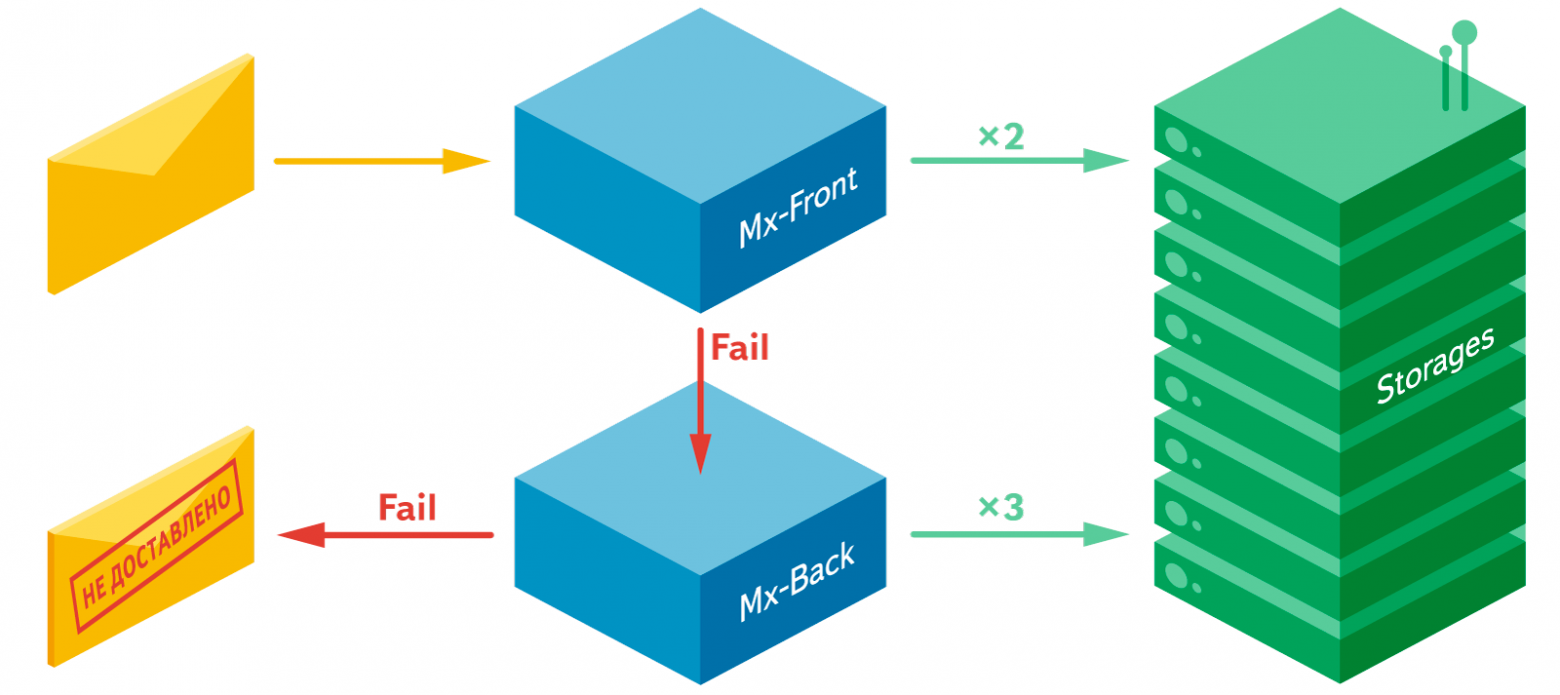
Если покладка письма прошла неудачно, письмо попадает на кластер Mx-Back, который состоит из очереди на PostFix и ряда программ покладки и анализа писем. Программы кластера Mx-Back делают много попыток положить письмо в хранилища в течение длительного времени, но если и здесь неудача, то письмо считается недоставленным. Если покладка письма удалась, то письмо отправляется на кластер Services, из которого оно уже доставляется в поиск.
Поскольку сервис Почтовый офис является частью почты, то и система покладки встроена в почтовую. Отличие состоит лишь в том, что сам сервис не должен хранить сами письма. Сервису требуется лишь мета-информация из писем. А еще Постофис позволяет посмотреть на почту со стороны отправителя, а не со стороны получателя. Поэтому в качестве очереди мы решили попробовать другие решения, отличные от PostFix.
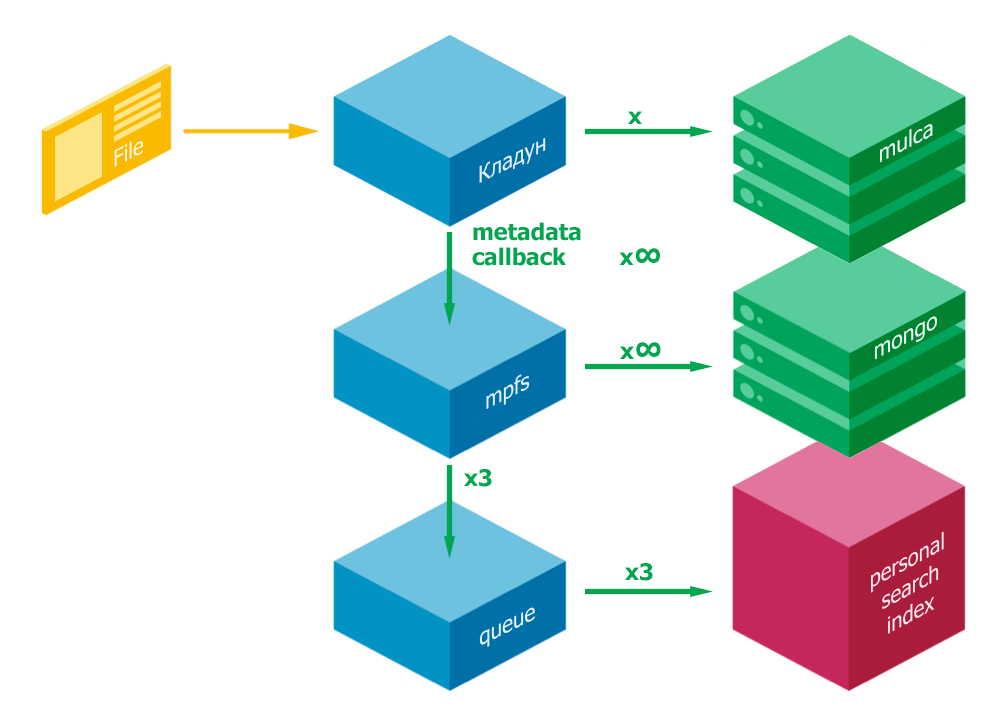
Файлы влетают в кладун, который складывает файлы в хранилище (mulca) и отправляет в кластер mpfs. MPFS сохраняет метаинформацию о файлах в хранилище метаданных (mongo DB) и кладет в очередь для доставки файлов в поиск. Далее файлы из очереди попадают в поиск.
PostFix – очередь на входе в Почту в трех местах: mxfront, mxback, services
Достоинство у этой очереди всего одно, она очень проста в использовании.
Недостатков гораздо больше:
RabbitMQ – используется для информирования Поиска в почте об удалении писем из почтового ящика. Основное достоинство этой очереди – возможность произвольного чтения данных. К недостаткам можно отнести все недостатки несетевой очереди, перечисленные выше.
Очередь в Mongo DB – используется в Диске для всех операций с метаданными: копирование, перемещение файлов на Диске и индексация файлов для поиска.
Достоинства – очередь сетевая. Если выпадает один сервер, данные сохраняются.
К основным недостаткам относится то, что очередь разгребается разными обработчиками, которые не синхронизированы друг с другом, поэтому не выполняется очередность постановки задач.
Существующие решения ограничены по решаемым задачам или не дают гарантии доставки получателю. Поэтому мы решили потестировать Apache ZooKeeper – очередь с гарантией доставки. Помимо гарантированной доставки, у него есть еще два важных преимущества:
Конечно, есть и недостатки, но они не столь существенны:
Три сервера, необходимых в минимальной конфигурации мы разместили в разных дата-центрах, чтобы быть застрахованными от отключения одного из них целиком. Более того, недоступность одного из дата-центров для компании является типовым режимом работы. Еженедельно проходят так называемые учения, чтобы быть уверенными, что сервисы Яндекса будут продолжать работать, если один из дата-центров вышел из строя.
Учитывая богатый опыт использования очередей в персональных сервисах Яндекса, заявленные технические характеристики выше перечисленных очередей, а также наши внутренние требования по надежности доставки данных, мы решили рискнуть и попробовать Zookeeper в новом персональном сервисе Яндекса Почтовый офис.
Мы провели множество экспериментов, вот некоторые из них:
То, что у нас получилось, обязательно нужно было протестировать функционально и нагрузочно. Вот как мы это делали…
Для того, чтобы качественно провести функциональное и нагрузочное тестирование системы доставки, мы сначала описали кейсы, в которых очередь должна “доставлять”. Все возможные ситуации вытекают из продуктовых требований к надежности системы доставки и архитектурных особенностей построения систем в нашей компании.
Во-первых, протокол гарантированной доставки требует наличия нечетного количества работающих инстансов системы гарантированной доставки – это минимум три одновременно работающих программы, а лучше пять.
Во-вторых, в Яндексе является стандартом одновременное размещение любых систем в разных дата-центрах – это позволяет сохранить работоспособность сервиса в случае отключения питания в ДЦ или других аномальных явлениях в данном ДЦ.
В третьих, мы умышленно усложнили себе жизнь и решили совместить требование системы доставки и требования Яндекса, в результате мы разместили программу системы доставки на трех разных серверах, расположенных в трех разных дата-центрах.
С одной стороны, выбранное нами решение усложняет общую архитектуру и приводит к различным нежелательным эффектам в виде долгих междатацентровых пингов, с другой стороны, мы получаем систему, защищенную от атомной войны.
Получилась такая архитектура: прокси, получающий данные, очередь, хранилище.
Прокси размещены в пяти дата-центрах на десяти серверах. Очередь размещена в трех дата-центрах на трех серверах. В качестве хранилища может быть выбран любой SQL и noSQL storage, а самих хранилищ может быть любое количество. В нашем случае в качестве хранилища мы выбрали noSQL storage на базе Lucene, и разместили его на двух серверах в 2-х разных дата-центрах.
Перед вводом в эксплуатацию мы провели функциональное и нагрузочное тестирование системы гарантированной доставки.
Тестирование проводилось последовательно в четырех режимах:
По результатам тестирования мы зажмурили глаза и, взяв ответственность на свою голову, решили запускать всю эту систему в продакшен. Как и ожидали, тестирование тестированием, а реальная жизнь создает такие ситуации, которые никогда не предскажешь заранее. Иногда у нас заканчивается пул соединений, иногда мы долго доставляем данные на один из бэкэндов, причем один из бэкэндов почему-то актуальный, а второй отстает.
Одним словом, в ходе эксплуатации возникают все новые и новые ситуации, которые мы успешно фиксим, и наша очередь, запущенная еще в ноябре, из экспериментальной технологии постепенно превращается в хороший автономный продукт.
Задача усложняется тем, что каждое письмо и каждый файл требуют дополнительной обработки: мы классифицируем их, сохраняем, извлекаем текст, распознаем образы, создаем индексы. Благодаря этому в дальнейшем пользователю гораздо проще найти нужные письма или файлы.
Обработка может занимать разное время: от миллисекунд, требуемых для сохранения письма, до нескольких десятков секунд, затрачиваемых, например, на извлечение текста из фотографий.
Как бы мы не рассчитывали мощность системы приема и обработки писем и файлов, мы никогда не застрахованы от ситуаций, когда входной поток значительно превышает наши ожидания.
В этих случаях нам помогают очереди. Они позволяют сгладить всплески входной нагрузки: выиграть время и дождаться, когда кластер обработки писем станет доступен.
Что такое очередь
Очередь на обработку документов мало чем отличается от живой очереди в магазине или на почте. Там они тоже возникают по той же причине: обслуживать клиентов мгновенно невозможно. Однако важное преимущество очереди на обработку документов в Персональных сервисах Яндекса заключается в том, что стоят в ней только письма и файлы, пользователю ждать ничего не надо. По сути это буфер, в который можно быстро записать файлы и письма, а когда нагрузка на систему обработки спадет, быстро все это прочитать.
Как правило с очередью работают две программы: одна записывает в нее данные, другая вычитывает их и отправляет потребителю.
Программа записи в очередь должна быть максимально простой, чтобы не вносить никаких дополнительных задержек на приеме задачи, мы же не хотим делать еще одну очередь на помещение в основную. И программа чтения из очереди уже взаимодействует с различными функциональными элементами сервисов: Почты/Диска или других продуктов.
Программ чтения данных может быть несколько, каждая из которых служит для специализированной обработки данных. Программа чтения может работать существенно дольше, чем программа записи, поскольку на нее возложена дополнительная функциональность. Поэтому очередь должна уметь хранить данные за промежуток времени, достаточный для обработки писем/файлов своими источниками.
В основном очереди используются там, где есть неравномерная входная нагрузка и требуется выполнять операции над данными. В частности, на приеме писем в почту и файлов в диск.
При использовании очередей важно учитывать такие правила:
- Очередь нужна там, где есть неравномерная нагрузка на систему обработки.
- Очередь помогает сгладить неравномерность и служит некоторым буфером между входом и системой обработки.
- Сиcтема обработки должна справляться со всей входной нагрузкой на каком-то определенном ограниченном временном интервале, иначе никакие очереди не помогут.
Архитектура системы приема писем в Почту:
Письма влетают в почту и попадают в кластер Mx-Front, программы которого обрабатывают письма и сохраняют их в почтовые хранилища.
Если покладка письма прошла неудачно, письмо попадает на кластер Mx-Back, который состоит из очереди на PostFix и ряда программ покладки и анализа писем. Программы кластера Mx-Back делают много попыток положить письмо в хранилища в течение длительного времени, но если и здесь неудача, то письмо считается недоставленным. Если покладка письма удалась, то письмо отправляется на кластер Services, из которого оно уже доставляется в поиск.
Архитектура системы приема данных в Почтовый офис:
Поскольку сервис Почтовый офис является частью почты, то и система покладки встроена в почтовую. Отличие состоит лишь в том, что сам сервис не должен хранить сами письма. Сервису требуется лишь мета-информация из писем. А еще Постофис позволяет посмотреть на почту со стороны отправителя, а не со стороны получателя. Поэтому в качестве очереди мы решили попробовать другие решения, отличные от PostFix.
Архитектура системы приема файлов в Диск:
Файлы влетают в кладун, который складывает файлы в хранилище (mulca) и отправляет в кластер mpfs. MPFS сохраняет метаинформацию о файлах в хранилище метаданных (mongo DB) и кладет в очередь для доставки файлов в поиск. Далее файлы из очереди попадают в поиск.
Какие бывают очереди
PostFix – очередь на входе в Почту в трех местах: mxfront, mxback, services
Достоинство у этой очереди всего одно, она очень проста в использовании.
Недостатков гораздо больше:
- рассчитан только для почтовых задач и работает по протоколу smtp;
- работает только в пределах одного сервера, значит в случае поломки сервера все данные пропадают и нет синхронизации последовательности между разными серверам;
- нельзя читать из произвольного места в очереди, возможно только последовательное чтение;
- возврат задачи в очередь возможен только через начало.
RabbitMQ – используется для информирования Поиска в почте об удалении писем из почтового ящика. Основное достоинство этой очереди – возможность произвольного чтения данных. К недостаткам можно отнести все недостатки несетевой очереди, перечисленные выше.
Очередь в Mongo DB – используется в Диске для всех операций с метаданными: копирование, перемещение файлов на Диске и индексация файлов для поиска.
Достоинства – очередь сетевая. Если выпадает один сервер, данные сохраняются.
К основным недостаткам относится то, что очередь разгребается разными обработчиками, которые не синхронизированы друг с другом, поэтому не выполняется очередность постановки задач.
ZooKeeper
Существующие решения ограничены по решаемым задачам или не дают гарантии доставки получателю. Поэтому мы решили потестировать Apache ZooKeeper – очередь с гарантией доставки. Помимо гарантированной доставки, у него есть еще два важных преимущества:
- сохранность данных и работоспособность, когда один из серверов очереди недоступен;
- возможность распределения голов очереди по разным дата-центрам.
Конечно, есть и недостатки, но они не столь существенны:
- требуется избыточное количество серверов – минимум три, а лучше пять;
- требуется время на синхронизацию данных во всех головах очереди.
Три сервера, необходимых в минимальной конфигурации мы разместили в разных дата-центрах, чтобы быть застрахованными от отключения одного из них целиком. Более того, недоступность одного из дата-центров для компании является типовым режимом работы. Еженедельно проходят так называемые учения, чтобы быть уверенными, что сервисы Яндекса будут продолжать работать, если один из дата-центров вышел из строя.
Учитывая богатый опыт использования очередей в персональных сервисах Яндекса, заявленные технические характеристики выше перечисленных очередей, а также наши внутренние требования по надежности доставки данных, мы решили рискнуть и попробовать Zookeeper в новом персональном сервисе Яндекса Почтовый офис.
Zookeeper заводится не с первого раза
Мы провели множество экспериментов, вот некоторые из них:
- Попробовали через ZooKeeper передавать данные в количестве равном числу хранилищ. По умолчанию это два бэкэнда. Получили 8 тысяч RPS (requests per second) на передачу данных в одном экземпляре. И 2,5 тысячи RPS на передачу данных в двух экземплярах.
Поняли, что нам нужно иметь минимум три бэкэнда – два поиска + логстор, в итоге передавали данные три раза через ZooKeeper и получили 500 RPS – это очень низкая производительность, поскольку сервисов, желающих получить одни и те же данные может быть гораздо больше трех, а значит мы с каждым разом будем терять производительность на копирование данных и протоколы согласования между серверами очереди. - Тщательно рассмотрев все проблемы из первого этапа экспериментов, мы решили использовать ZooKeeper как кольцевой буфер. В этом случае в ZooKeeper данные всегда складываются только один раз, а каждый бэкэнд содержит свою позицию в очереди, до которой он вычитал данные из очереди. В этом случае, если бэкэнд падает, он поднимается и вычитывает из очереди данные начиная с позиции, которая у него сохранена. Такое решение имеет два важных преимущества: во-первых, высокая производительность (8 тысяч RPS) благодаря тому, что данные хранятся всего в одном экземпляре. Во-вторых, неограниченное число бэкэндов, которые пользуются одними и теми же данными. Таким образом были решены проблемы с производительностью очереди.
- Но тут мы узнали, что это еще не все. Поскольку ZooKeeper может работать только с данными в памяти, а недоступность одного из серверов хранилища (бэкэнда) может достигать нескольких суток, то для самого ZooKeeper-а требуется хранилище. В качестве этого хранилища стали использовать Apache Lucene.
То, что у нас получилось, обязательно нужно было протестировать функционально и нагрузочно. Вот как мы это делали…
Архитектура тестового стенда
Для того, чтобы качественно провести функциональное и нагрузочное тестирование системы доставки, мы сначала описали кейсы, в которых очередь должна “доставлять”. Все возможные ситуации вытекают из продуктовых требований к надежности системы доставки и архитектурных особенностей построения систем в нашей компании.
Во-первых, протокол гарантированной доставки требует наличия нечетного количества работающих инстансов системы гарантированной доставки – это минимум три одновременно работающих программы, а лучше пять.
Во-вторых, в Яндексе является стандартом одновременное размещение любых систем в разных дата-центрах – это позволяет сохранить работоспособность сервиса в случае отключения питания в ДЦ или других аномальных явлениях в данном ДЦ.
В третьих, мы умышленно усложнили себе жизнь и решили совместить требование системы доставки и требования Яндекса, в результате мы разместили программу системы доставки на трех разных серверах, расположенных в трех разных дата-центрах.
С одной стороны, выбранное нами решение усложняет общую архитектуру и приводит к различным нежелательным эффектам в виде долгих междатацентровых пингов, с другой стороны, мы получаем систему, защищенную от атомной войны.
Получилась такая архитектура: прокси, получающий данные, очередь, хранилище.
Прокси размещены в пяти дата-центрах на десяти серверах. Очередь размещена в трех дата-центрах на трех серверах. В качестве хранилища может быть выбран любой SQL и noSQL storage, а самих хранилищ может быть любое количество. В нашем случае в качестве хранилища мы выбрали noSQL storage на базе Lucene, и разместили его на двух серверах в 2-х разных дата-центрах.
Функциональное и нагрузочное тестирование
Перед вводом в эксплуатацию мы провели функциональное и нагрузочное тестирование системы гарантированной доставки.
Тестирование проводилось последовательно в четырех режимах:
- Нормальный режим работы: все сервера доступны. Отправляем данные через очередь с нагрузкой 500 RPS в течение суток, проверяем, что все данные доставляются до бэкэнда.
- Недоступен один из серверов очереди. Начинаем отправку данных через очередь. Отключаем одну из голов очереди на час. Продолжаем отправку писем и проверяем, что данные доставляются до бэкэндов.
- Недоступен один из серверов бэкэнда. Начинаем отправку данных через очередь. Отключаем один из бэкэндов на час, затем включаем и спустя определенный промежуток времени проверяем, что данные добежали до бэкэнда.
- Недоступен один из серверов очереди и один из серверов бэкэнда. Начинаем отправку данных через очередь. Отключаем одну из голов очереди и одну из голов бэкэнда на один час. Отправку данных не останавливаем. Проверяем, что данные доставляются в рабочий бэкэнд. Через час включаем отключенные головы очереди и бэкэнда. Проверяем что после включения данные попадают в оба бэкэнда и что данные в каждом из них одинаковые.
Внедрение
По результатам тестирования мы зажмурили глаза и, взяв ответственность на свою голову, решили запускать всю эту систему в продакшен. Как и ожидали, тестирование тестированием, а реальная жизнь создает такие ситуации, которые никогда не предскажешь заранее. Иногда у нас заканчивается пул соединений, иногда мы долго доставляем данные на один из бэкэндов, причем один из бэкэндов почему-то актуальный, а второй отстает.
Одним словом, в ходе эксплуатации возникают все новые и новые ситуации, которые мы успешно фиксим, и наша очередь, запущенная еще в ноябре, из экспериментальной технологии постепенно превращается в хороший автономный продукт.
