
Привет, меня зовут Даниил Гинсбург, я работаю в Яндексе сетевым архитектором.
В своем докладе я попытался дать свое определение понятия Software-defined Network, которое сегодня понимается в индустрии как чрезмерно широко, так и чрезмерно узко. Мой рассказ также затронул исторические корни SDN, его будущее и вопросы практического развертывания.
Видеозапись доклада

Для начала попытаемся ответить на вопрос, все ли у нас хорошо в сетях? Может быть, нам и переделывать ничего не надо? Я уверен, что это не так, и сейчас попытаюсь обосновать свою точку зрения.
Что же сейчас не так в сетевом мире? Первое, что нас убивает – это сложность. Наши сетевые решения, наши сети сложны. Сложность нам мешает масштабироваться, управлять сетями, делает их хрупкими. Сложность – наш враг. Передача полезного трафика (data-plane устроена сложно. Data-plane наших железок умеет кучу всего: форвардить миллионы инкапсуляций, делать миллион разных тоннелей (причем, мы продолжаем изобретать новые). Есть люди, которые строят из этого абсолютно ужасные конструкции.
Например, гоняют multicast через IRB, который торчит в VPLS, под которым лежат link aggregation groups. Такую штуку невозможно масштабировать, невозможно отлаживать. И стоит это дорого, дорого и в плане железа, и в плане рабочего времени.
Всем этим богатством возможностей data-plane нужно как-то управлять. А раз все это хозяйство такое сложное, то и управлять им сложно.
Мы строим дикие бутерброды из протоколов, и наши протоколы управления развиваются сиюминутно.
Мой любимый (хоть и не самый вопиющий) пример сиюминутности – это Multiprotocol BGP. Для того чтобы анонсировать маршрут по нему, next hop в этом анонсе должен иметь ту же самую address family (v4, v6 или что-то еще). Когда мы хотим v4-маршрут c v6 next hop, мы начинаем придумывать новые RFC. Соответственно, у нас есть n NLRI, то потенциально появляется n2 RFC. Это ужасная, ущербная и невыразительная абстракция.
Когда я придумываю сеть, я в первую очередь представляю себе, как должен течь трафик. Отсюда я сразу же представляю, как должны быть наполнены мои таблицы форвардинга. А потом я начинаю думать, как же мне с помощью существующих протоколов наполнить эти таблицы тем самым образом, как я хочу. И это получается не всегда. Именно из-за невыразительных абстракций.
Все это обходится очень дорого. Сетевой элемент, который имеет огромную сложность в data-plane и control-plane, в конкретном случае использует, скажем, 5% возможностей, а оплачивается на все 100. И оплачивается не только ценой железки, но и сложностью ПО, которое на ней используется, багами в нем, хрупкостью сети.
Когда мне нужна новая фича в оборудовании, я прихожу к вендору. Если мне повезет, получу я эту фичу через год, причем преломленную через сознание вендора, который знает «как лучше».
В числе прочего, из-за этого мы имеем крайне затрудненную автоматизацию. Каждый вендор изобретает свой способ автоматической конфигурации. Если у меня появляется новый вендор, мне нужно модифицировать всю систему управления и автоматизации. Не с нуля, конечно, но значительно.
Очевидно, что нужно с этим всем что-то делать. Например, переделать вообще все и назвать это SDN.
Точного определения этому термину я дать не могу, никто не может. Некоторые связывают его с инициативой OpenFlow, некоторые употребляют его просто как прилагательное в синонимическом ряду «хороший», «модный», «современный».
Так что же такое SDN? Это нечто, которое даст нам удобные абстракции. Они будут простыми, понятными естественными, выразительными и полными. Это позволит реализовывать необходимые функции сети самостоятельно, а не ждать, когда вендор сделает это. Естественно, упростится и автоматизация.
Во-первых, разделить прохождение трафика (data-plane) и сигнализацию/управление (control plane). Во-вторых, сделать элементы data-plane максимально простыми и, в-третьих, централизовать control-plane. Это все позволит быстро и просто реализовывать удобные абстракции в control-plane независимо от data-plane.
Теперь разберем все эти идеи по порядку.
Первый вопрос, который возникает в связи с разделением data-plane и control-plane – насколько их нужно разделить?
Это далеко не новая идея, это делали или пытались делать уже много раз. Так, например, устроен любой современный маршрутизатор. Есть элементы data-plane: форвардинговые движки, которые принимают пакеты и решают, куда их форвардить, есть соединяющая их матрица коммутации. Модуль управления существует отдельно. Пользовательский трафик течет насквозь, трафик управления поступает в control engine, который программирует forwarding engine.

Такой подход позволяет масштабировать отдельный сетевой элемент. С другой стороны такой подход крайне усложняет модель отказов. Такая составная конструкция ломается по частям. Более того, даже data-plane может сломаться частично. Например, если у вас сломалась матрица коммутации, а control engine этого не заметил, весь пользовательский трафик будет просто дропаться. Управленческий трафик будет продолжать ходить, и все будут думать, что наш сетевой элемент жив.
На схеме этого нет, но синий трафик идет через отдельную внутреннюю cеть out-of-band-управления. И эта сеть также может отказать. Если мы возьмем и разделим data-plane и control-plane не в рамках одного сетевого элемента, а в рамках всей сети, то cеть out-of-band-управления станет столь же сложной, что и наш data-plane. Соответственно, ломаться она станет так же часто и плохо, как и основная сеть.
Возникает также вопрос, а как же управлять управляющей сетью, если она столь же сложна, что и сеть, передающая полезный трафик?
Перейдем к идее упрощения элементов data-plane. Мы должны придумать достаточно простую и общую абстракцию для управления сетевым элементом. Простую, понятную, достаточно гибкую и выразительную.
Насколько простой должна быть эта абстракция? Если не вдаваться глубоко в детали, data-plane выглядит следующим образом: к нам приходит пакет, мы берем поля из заголовка делаем lookup в таблице форвардинга, модифицируем заголовки пакета и отправляем в следующий интерфейс.
Реальность несколько сложнее. Вот так выглядит сильно упрощенная схема того, что происходит в одном чипе сетевого элемента:
Какую абстракцию элементов data-plane нам предлагает OpenFlow? У нас есть поля, есть таблица лукапов, мы делаем поиск, определяем, что нужно сделать и воплощаем это. Все предельно просто.
Одна из проблем с абстракцией в OpenFlow 1.0 – это комбинаторный взрыв. Для примера возьмем простую искуственную задачу. Нам нужно пропускать трафик на N хостов на одни и те же M TCP-портов, а остальной трафик сбрасывать. В OpenFlow 1.0 для этого нам потребуется NxM записей, придется перечислить все комбинации хост-порт. Масштабировать это не получится.
В OpenFlow 1.1 и всех последующих версиях появляется идея множественных таблиц. Это избавляет от комбинаторного взрыва. Идея сравнительно элегантная, но у нее есть проблема, она плохо отражается на железе. Дело в том, что железо, которое стоит разумных денег, не умеет делать лукапы в произвольном порядке.
В современном железе есть возможность делать многостадийную обработку. Находим в таблице соответствующую запись, а дальше проводим несколько стадий обработки: добавляем метку, перезаписываем заголовок, потом еще что-нибудь и т.д. Называется это indirect next hops: один next hop в этом случае ссылается на другой по индексу таблицы. Т.е. находить следующий просто. Однако, в конструкции с множественными таблицами у нас нет непосредственных ссылок, и мы вынужденны будем делать multifield lookup несколько раз, а это достаточно затратно. Однако от комбинаторного взрыва мы избавляемся и та же задача с N хостов и M портов решается гораздо проще: у на будет две таблицы: N записей в одной и M записей в другой.
В рамках организации Open Networking Foundation, которая разрабатывает и стандартизирует OpenFlow, работает Forwarding Abstractions working group (FAWG). Разрабатываемая этой группой идея заключается в том, чтобы опрашивать сетевые элементы о том, какую последовательность лукапов они могут сделать. Т.е. когда контроллер делает запрос, сетевой элемент предоставляет ему информацию обо всем том чудовищном пайплайне, который представлен на предыдущей картинке.
Но куда же делась абстракция?
Если мы ввели абстракцию, и для того, чтобы ее эффективно использовать и реализовывать, приходится рассказывать контроллеру обо всех деталях реализации, значит, мы либо что-то не то абстрагируем, либо абстрагируем не там.
Попробуем определить, насколько централизованным должен быть control-plane. Тут есть пространство для маневра. Централизация и децентрализация – процесс колебательный.
Те, кто достаточно давно работают в индустрии, скорее всего, со мной согласятся. Один из примеров, d котором мы уже прошли несколько циклов. Мы покупаем BRAS и ставим его в середине. Понимаем, что у нас ничего не масштабируется, растащим его по краям. Теперь теряется управление, снова возвращаемся к централизации, покупаем BRAS побольше и ставим его в середину. И так далее.
Это естественный процесс, от которого никуда не деться. Он диктуется не только модой и маркетингом, но и вполне объективными факторами, техническим прогрессом. С централизацией и децентрализацией в control-plane все будет происходить точно так же.
Что нам в этом плане предлагают радикалы от OpenFlow-подхода? Предполагается, что сам сетевой элемент крайне туп и неспособен ни как каким самостоятельным действиям, что ему контроллер говорит, то он и делает.
Соответственно, контроллер должен будет реагировать на все события в сети. Если элемент неспособен перекинуть трафик с одного пути на другой путь самостоятельно, то контроллер должен увидеть этот отказ и прореагировать на него. Такая конструкция очень опасна в плане масштабирования. Придется снова брать большой контроллер, делить его на несколько, распределять, чтобы он справлялся с нагрузкой. Т.е. мы снова входим в виток централизации/децентрализации.
Главное – это умерить революционный пыл и подойти к SDN с эволюционной точки зрения.
Все то, что нам обещает SDN, все то, о чем мы говорили в начале – действительно хорошо. Это то, к чему нам нужно стремиться. Мы должны приложить все усилия, чтобы эти обещания сбылись.
Так что же нам для этого нужно сделать?
Во-первых, стандартизировать один механизм data-plane. Для управления всем разнообразием протоколов, конструкций и механизмов, которые есть в сегодняшнем data-plane, нет никакого разумного способа.
Во-вторых, нужно выбрать правильную абстракцию элемента, которая была бы простой и в тоже время гибкой. Кроме того, нужно обеспечить возможность реализовывать сетевые функции как централизованно, так и децентрализованно. Также нужно найти способ комбинирования по-разному реализованных функций.
Оба стиля управления – централизованный и децентрализованный – важны. Есть естественно централизованные функции, например, высокоуровневые политики.
И в то же время существуют децентрализованные по своей природе функции, например, перемаршрутизация при сбоях. Кроме того, есть функции, которые можно реализовывать так, как это выгодно здесь и сейчас. К таким функциям можно отнести вычисление пути. Например, внутри дата-центра у меня нет никакой потребности делать traffic-engineering, там просто нет необходимости экономить полосу. А вот в WAN уже может потребоваться traffic-engineering, и его можно и иногда нужно делать централизованно.
Сеть может иметь доменную структуру: например, DC и WAN, access и core, RAN и blcackhaul. Разные части сети выполняют различные функции, они устроены по-разному, и подходят им разные типы управления. Соответственно, чтобы сеть была единой, разные части сети нужно «сшивать» и «накладывать» друг на друга. Поверх доменов мы можем сделать транспорты, а поверх этих транспортов – «сервисы».
Правильная абстракция элемента действительно должна прятать его сложность. Та дикая схема, которую мы рассматривали в начале, на самом деле отображает только то, что происходит внутри одного чипа. Когда мы говорим о какой-то мультислотовой распределенной коробке, все усложняется еще сильнее. И это нужно прятать, мы не хотим знать, что там происходит.
Эта абстракция должна позволять комбинировать разные стили управления. Если какая-то функция реализована классическим способом в виде распределенного сигналинга, а другая – в виде централизованного управления, они должны уметь друг с другом взаимодействовать.
Один из многообещающих подходов – это i2rs от IETF. Это несколько более высокоуровневая модель, чем предлагаемый OpenFlow. Например, i2rs оперирует не записями в таблице форвардинга, а понятием маршрута.
Что технический прогресс позволяет нам сделать сегодня и в самое ближайшее время?
На сегодня есть два самых актуальных применения SDN: сетевая виртуализация и сцепление сервисов. Мы должны понимать, что у нас есть уровень виртуализации и уровень транспорта, задача которого заключается в том, чтобы перетаскивать пакеты.
В качестве транспорта у нас есть IP/MPLS. Мы умеем делать простую MPLS-сеть, делать транспорт.
95% сложности MPLS control-plane сосредоточена в организации сервисов. Именно здесь должны быть сосредоточены усилия.
Виртуализация должна начинаться от хоста. Современные процессоры позволяют нам делать это достаточно дешево. Мы делаем виртуальный свитч на хосте, и с него начинается виртуализация.
Такая сеть должна управляться гибридно: централизованные элементы управления должны быть распределены. Это даст нам возможность брать политики разделения сети и компилировать их в определенные правила гибридных контроллеров, управляющих наложенной сетью.
При этом, каковы бы ни были наши политики, мы не трогаем транспорт. В нем ничего не меняется, он не знает ни про наши политики, ни про наложенную сеть.
Подводя итоги, хочется повторить идею о том, что SDN, что бы под ним ни подразумевалось, действительно обещает нам хорошие вещи, их нужно претворять в жизнь. Однако, это нужно делать правильными инструментами, а не приравнивать SDN и OpenFlow.
В своем докладе я попытался дать свое определение понятия Software-defined Network, которое сегодня понимается в индустрии как чрезмерно широко, так и чрезмерно узко. Мой рассказ также затронул исторические корни SDN, его будущее и вопросы практического развертывания.
Видеозапись доклада
Для начала попытаемся ответить на вопрос, все ли у нас хорошо в сетях? Может быть, нам и переделывать ничего не надо? Я уверен, что это не так, и сейчас попытаюсь обосновать свою точку зрения.
Сложность
Что же сейчас не так в сетевом мире? Первое, что нас убивает – это сложность. Наши сетевые решения, наши сети сложны. Сложность нам мешает масштабироваться, управлять сетями, делает их хрупкими. Сложность – наш враг. Передача полезного трафика (data-plane устроена сложно. Data-plane наших железок умеет кучу всего: форвардить миллионы инкапсуляций, делать миллион разных тоннелей (причем, мы продолжаем изобретать новые). Есть люди, которые строят из этого абсолютно ужасные конструкции.
Например, гоняют multicast через IRB, который торчит в VPLS, под которым лежат link aggregation groups. Такую штуку невозможно масштабировать, невозможно отлаживать. И стоит это дорого, дорого и в плане железа, и в плане рабочего времени.
Всем этим богатством возможностей data-plane нужно как-то управлять. А раз все это хозяйство такое сложное, то и управлять им сложно.
Мы строим дикие бутерброды из протоколов, и наши протоколы управления развиваются сиюминутно.
Мой любимый (хоть и не самый вопиющий) пример сиюминутности – это Multiprotocol BGP. Для того чтобы анонсировать маршрут по нему, next hop в этом анонсе должен иметь ту же самую address family (v4, v6 или что-то еще). Когда мы хотим v4-маршрут c v6 next hop, мы начинаем придумывать новые RFC. Соответственно, у нас есть n NLRI, то потенциально появляется n2 RFC. Это ужасная, ущербная и невыразительная абстракция.
Когда я придумываю сеть, я в первую очередь представляю себе, как должен течь трафик. Отсюда я сразу же представляю, как должны быть наполнены мои таблицы форвардинга. А потом я начинаю думать, как же мне с помощью существующих протоколов наполнить эти таблицы тем самым образом, как я хочу. И это получается не всегда. Именно из-за невыразительных абстракций.
Все это обходится очень дорого. Сетевой элемент, который имеет огромную сложность в data-plane и control-plane, в конкретном случае использует, скажем, 5% возможностей, а оплачивается на все 100. И оплачивается не только ценой железки, но и сложностью ПО, которое на ней используется, багами в нем, хрупкостью сети.
Feature velocity
Когда мне нужна новая фича в оборудовании, я прихожу к вендору. Если мне повезет, получу я эту фичу через год, причем преломленную через сознание вендора, который знает «как лучше».
В числе прочего, из-за этого мы имеем крайне затрудненную автоматизацию. Каждый вендор изобретает свой способ автоматической конфигурации. Если у меня появляется новый вендор, мне нужно модифицировать всю систему управления и автоматизации. Не с нуля, конечно, но значительно.
Что с этим делать
Очевидно, что нужно с этим всем что-то делать. Например, переделать вообще все и назвать это SDN.
Точного определения этому термину я дать не могу, никто не может. Некоторые связывают его с инициативой OpenFlow, некоторые употребляют его просто как прилагательное в синонимическом ряду «хороший», «модный», «современный».
Так что же такое SDN? Это нечто, которое даст нам удобные абстракции. Они будут простыми, понятными естественными, выразительными и полными. Это позволит реализовывать необходимые функции сети самостоятельно, а не ждать, когда вендор сделает это. Естественно, упростится и автоматизация.
Во-первых, разделить прохождение трафика (data-plane) и сигнализацию/управление (control plane). Во-вторых, сделать элементы data-plane максимально простыми и, в-третьих, централизовать control-plane. Это все позволит быстро и просто реализовывать удобные абстракции в control-plane независимо от data-plane.
Теперь разберем все эти идеи по порядку.
Разделение data-plane и control-plane
Первый вопрос, который возникает в связи с разделением data-plane и control-plane – насколько их нужно разделить?
Это далеко не новая идея, это делали или пытались делать уже много раз. Так, например, устроен любой современный маршрутизатор. Есть элементы data-plane: форвардинговые движки, которые принимают пакеты и решают, куда их форвардить, есть соединяющая их матрица коммутации. Модуль управления существует отдельно. Пользовательский трафик течет насквозь, трафик управления поступает в control engine, который программирует forwarding engine.

Такой подход позволяет масштабировать отдельный сетевой элемент. С другой стороны такой подход крайне усложняет модель отказов. Такая составная конструкция ломается по частям. Более того, даже data-plane может сломаться частично. Например, если у вас сломалась матрица коммутации, а control engine этого не заметил, весь пользовательский трафик будет просто дропаться. Управленческий трафик будет продолжать ходить, и все будут думать, что наш сетевой элемент жив.
На схеме этого нет, но синий трафик идет через отдельную внутреннюю cеть out-of-band-управления. И эта сеть также может отказать. Если мы возьмем и разделим data-plane и control-plane не в рамках одного сетевого элемента, а в рамках всей сети, то cеть out-of-band-управления станет столь же сложной, что и наш data-plane. Соответственно, ломаться она станет так же часто и плохо, как и основная сеть.
Возникает также вопрос, а как же управлять управляющей сетью, если она столь же сложна, что и сеть, передающая полезный трафик?
Упрощение элементов сети
Перейдем к идее упрощения элементов data-plane. Мы должны придумать достаточно простую и общую абстракцию для управления сетевым элементом. Простую, понятную, достаточно гибкую и выразительную.
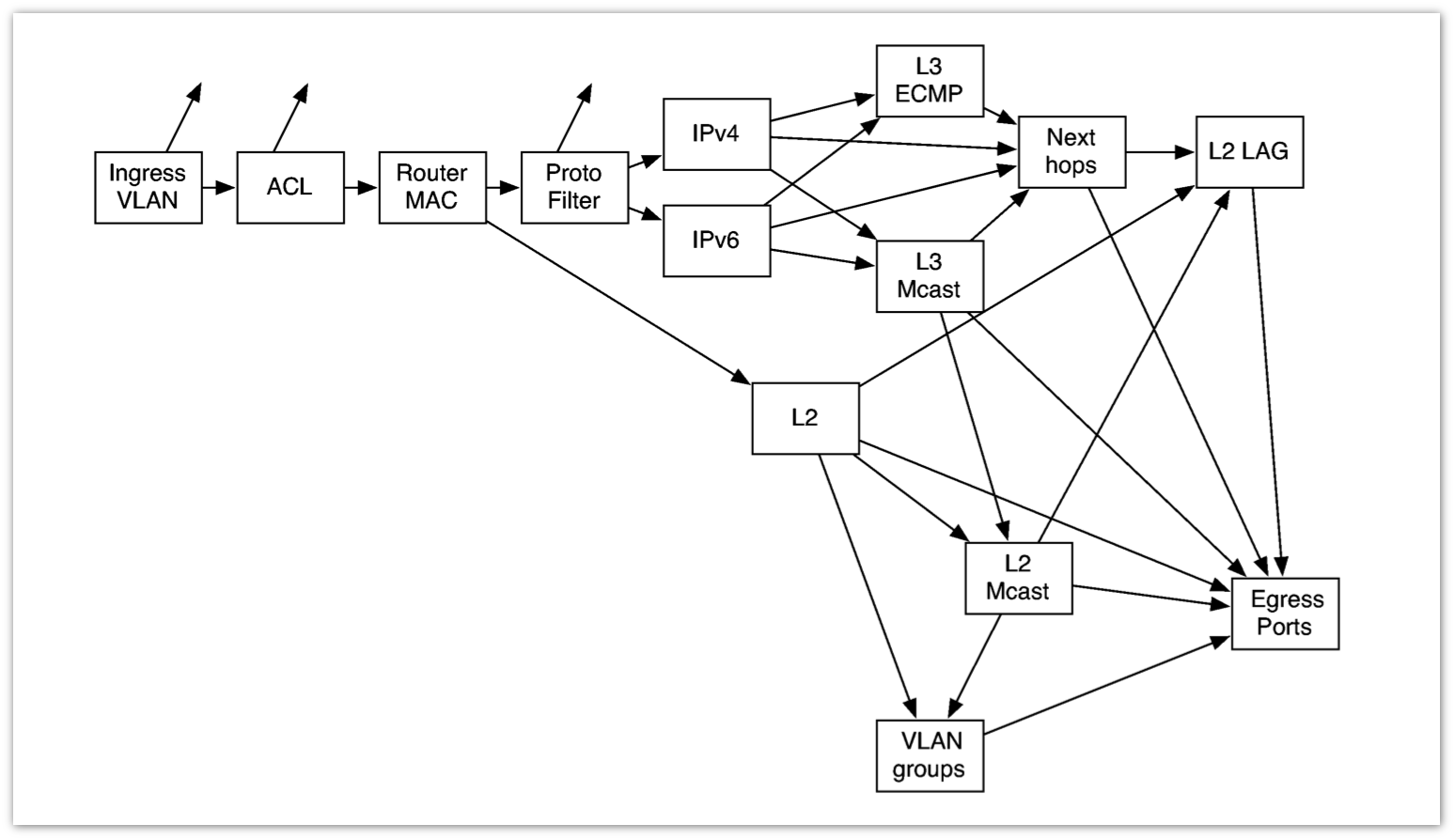
Насколько простой должна быть эта абстракция? Если не вдаваться глубоко в детали, data-plane выглядит следующим образом: к нам приходит пакет, мы берем поля из заголовка делаем lookup в таблице форвардинга, модифицируем заголовки пакета и отправляем в следующий интерфейс.
Реальность несколько сложнее. Вот так выглядит сильно упрощенная схема того, что происходит в одном чипе сетевого элемента:
Какую абстракцию элементов data-plane нам предлагает OpenFlow? У нас есть поля, есть таблица лукапов, мы делаем поиск, определяем, что нужно сделать и воплощаем это. Все предельно просто.
Одна из проблем с абстракцией в OpenFlow 1.0 – это комбинаторный взрыв. Для примера возьмем простую искуственную задачу. Нам нужно пропускать трафик на N хостов на одни и те же M TCP-портов, а остальной трафик сбрасывать. В OpenFlow 1.0 для этого нам потребуется NxM записей, придется перечислить все комбинации хост-порт. Масштабировать это не получится.
В OpenFlow 1.1 и всех последующих версиях появляется идея множественных таблиц. Это избавляет от комбинаторного взрыва. Идея сравнительно элегантная, но у нее есть проблема, она плохо отражается на железе. Дело в том, что железо, которое стоит разумных денег, не умеет делать лукапы в произвольном порядке.
В современном железе есть возможность делать многостадийную обработку. Находим в таблице соответствующую запись, а дальше проводим несколько стадий обработки: добавляем метку, перезаписываем заголовок, потом еще что-нибудь и т.д. Называется это indirect next hops: один next hop в этом случае ссылается на другой по индексу таблицы. Т.е. находить следующий просто. Однако, в конструкции с множественными таблицами у нас нет непосредственных ссылок, и мы вынужденны будем делать multifield lookup несколько раз, а это достаточно затратно. Однако от комбинаторного взрыва мы избавляемся и та же задача с N хостов и M портов решается гораздо проще: у на будет две таблицы: N записей в одной и M записей в другой.
В рамках организации Open Networking Foundation, которая разрабатывает и стандартизирует OpenFlow, работает Forwarding Abstractions working group (FAWG). Разрабатываемая этой группой идея заключается в том, чтобы опрашивать сетевые элементы о том, какую последовательность лукапов они могут сделать. Т.е. когда контроллер делает запрос, сетевой элемент предоставляет ему информацию обо всем том чудовищном пайплайне, который представлен на предыдущей картинке.
Но куда же делась абстракция?
Если мы ввели абстракцию, и для того, чтобы ее эффективно использовать и реализовывать, приходится рассказывать контроллеру обо всех деталях реализации, значит, мы либо что-то не то абстрагируем, либо абстрагируем не там.
Централизация и децентрализация
Попробуем определить, насколько централизованным должен быть control-plane. Тут есть пространство для маневра. Централизация и децентрализация – процесс колебательный.
Те, кто достаточно давно работают в индустрии, скорее всего, со мной согласятся. Один из примеров, d котором мы уже прошли несколько циклов. Мы покупаем BRAS и ставим его в середине. Понимаем, что у нас ничего не масштабируется, растащим его по краям. Теперь теряется управление, снова возвращаемся к централизации, покупаем BRAS побольше и ставим его в середину. И так далее.
Это естественный процесс, от которого никуда не деться. Он диктуется не только модой и маркетингом, но и вполне объективными факторами, техническим прогрессом. С централизацией и децентрализацией в control-plane все будет происходить точно так же.
Что нам в этом плане предлагают радикалы от OpenFlow-подхода? Предполагается, что сам сетевой элемент крайне туп и неспособен ни как каким самостоятельным действиям, что ему контроллер говорит, то он и делает.
Соответственно, контроллер должен будет реагировать на все события в сети. Если элемент неспособен перекинуть трафик с одного пути на другой путь самостоятельно, то контроллер должен увидеть этот отказ и прореагировать на него. Такая конструкция очень опасна в плане масштабирования. Придется снова брать большой контроллер, делить его на несколько, распределять, чтобы он справлялся с нагрузкой. Т.е. мы снова входим в виток централизации/децентрализации.
Так что же делать на самом деле?
Главное – это умерить революционный пыл и подойти к SDN с эволюционной точки зрения.
Все то, что нам обещает SDN, все то, о чем мы говорили в начале – действительно хорошо. Это то, к чему нам нужно стремиться. Мы должны приложить все усилия, чтобы эти обещания сбылись.
Так что же нам для этого нужно сделать?
Во-первых, стандартизировать один механизм data-plane. Для управления всем разнообразием протоколов, конструкций и механизмов, которые есть в сегодняшнем data-plane, нет никакого разумного способа.
Во-вторых, нужно выбрать правильную абстракцию элемента, которая была бы простой и в тоже время гибкой. Кроме того, нужно обеспечить возможность реализовывать сетевые функции как централизованно, так и децентрализованно. Также нужно найти способ комбинирования по-разному реализованных функций.
Оба стиля управления – централизованный и децентрализованный – важны. Есть естественно централизованные функции, например, высокоуровневые политики.
И в то же время существуют децентрализованные по своей природе функции, например, перемаршрутизация при сбоях. Кроме того, есть функции, которые можно реализовывать так, как это выгодно здесь и сейчас. К таким функциям можно отнести вычисление пути. Например, внутри дата-центра у меня нет никакой потребности делать traffic-engineering, там просто нет необходимости экономить полосу. А вот в WAN уже может потребоваться traffic-engineering, и его можно и иногда нужно делать централизованно.
Сеть может иметь доменную структуру: например, DC и WAN, access и core, RAN и blcackhaul. Разные части сети выполняют различные функции, они устроены по-разному, и подходят им разные типы управления. Соответственно, чтобы сеть была единой, разные части сети нужно «сшивать» и «накладывать» друг на друга. Поверх доменов мы можем сделать транспорты, а поверх этих транспортов – «сервисы».
Правильная абстракция элемента действительно должна прятать его сложность. Та дикая схема, которую мы рассматривали в начале, на самом деле отображает только то, что происходит внутри одного чипа. Когда мы говорим о какой-то мультислотовой распределенной коробке, все усложняется еще сильнее. И это нужно прятать, мы не хотим знать, что там происходит.
Эта абстракция должна позволять комбинировать разные стили управления. Если какая-то функция реализована классическим способом в виде распределенного сигналинга, а другая – в виде централизованного управления, они должны уметь друг с другом взаимодействовать.
Один из многообещающих подходов – это i2rs от IETF. Это несколько более высокоуровневая модель, чем предлагаемый OpenFlow. Например, i2rs оперирует не записями в таблице форвардинга, а понятием маршрута.
Где мы сейчас
Что технический прогресс позволяет нам сделать сегодня и в самое ближайшее время?
На сегодня есть два самых актуальных применения SDN: сетевая виртуализация и сцепление сервисов. Мы должны понимать, что у нас есть уровень виртуализации и уровень транспорта, задача которого заключается в том, чтобы перетаскивать пакеты.
В качестве транспорта у нас есть IP/MPLS. Мы умеем делать простую MPLS-сеть, делать транспорт.
95% сложности MPLS control-plane сосредоточена в организации сервисов. Именно здесь должны быть сосредоточены усилия.
Виртуализация должна начинаться от хоста. Современные процессоры позволяют нам делать это достаточно дешево. Мы делаем виртуальный свитч на хосте, и с него начинается виртуализация.
Такая сеть должна управляться гибридно: централизованные элементы управления должны быть распределены. Это даст нам возможность брать политики разделения сети и компилировать их в определенные правила гибридных контроллеров, управляющих наложенной сетью.
При этом, каковы бы ни были наши политики, мы не трогаем транспорт. В нем ничего не меняется, он не знает ни про наши политики, ни про наложенную сеть.
Заключение
Подводя итоги, хочется повторить идею о том, что SDN, что бы под ним ни подразумевалось, действительно обещает нам хорошие вещи, их нужно претворять в жизнь. Однако, это нужно делать правильными инструментами, а не приравнивать SDN и OpenFlow.
