
За последний год Яндекс добился значительного прогресса в качестве поиска для запросов, требующих наличия в выдаче актуальных документов. Теперь популярные документы в большинстве своём попадают в результаты поиска по релевантным запросам практически сразу после публикации.

Добиться этого непросто, ведь добавление только что созданных документов в поисковые выдачи, как правило, противоречит другим важным пользовательским метрикам: релевантности, авторитетности и т.д. Сегодня мы решили впервые рассказать о базовых технологиях, позволяющих с пользой подмешивать свежие документы в Поиск.
1. Почему свежесть?
Интерес к любому событию в течение нескольких дней угасает практически до нуля, если, конечно, это событие не получает какого-либо дальнейшего развития. Мы проводили исследование, из которого и родилось это утверждение: оказывается, в среднем 73% пользователей интересуется событием непосредственно в день, когда оно произошло, и только 3% читателей приходит на ресурсы спустя трое суток и более после публикации. С момента проведения этого исследования прошло уже много лет, но в целом ситуация не изменилась. И даже статьи на habrahabr.ru получают наибольшее количество поисковых переходов в первые несколько суток своего существования.
Своевременно продемонстрированная свежесть – важная характеристика не только для веб-поиска. Свежесть нужна также и в поиске по картинкам и видео, поисковых подсказках; разумеется, в новостных агрегаторах и СМИ. Да что уж там: даже в кинотеатр мы в большинстве ситуаций идём на новый фильм, а не на давно вышедший!
Важность освежения поисковой выдачи для поисковой системы сложно переоценить. Для того, чтобы добиться хорошей свежести, нужно решить множество задач: построить контент-систему, которая находит и добавляет в индекс новые документы в реальном времени, научиться предсказывать, каким пользователям по каким запросам необходимо показывать свежие документы, определить лучшие из этих документов. Конечно, все эти задачи решаются с использованием методов машинного обучения.
Данная статья описывает некоторые из наших подходов к решению указанных проблем. А восьмого июня в нашем офисе состоится встреча Яндекс изнутри, на которой в том числе состоится и доклад про свежесть. Мы рассмотрим самую сложную из возникающих задач — задачу ускорения реакции на происходящие события. Записаться на мероприятие можно по этой ссылке.
1.1. Как понять, что свежесть нужна
В той или иной мере свежесть необходима в 10-20% запросов, которые пользователи задают в Яндекс.
Прежде всего, это «событийные» запросы. Когда в мире что-то происходит, пользователи приходят в Поиск, чтобы узнать подробности события. Разные события достаточно сильно отличаются друг от друга как с точки зрения пользовательского интереса, так и с точки зрения необходимой разработки.
Рассмотрим для примера график количества кликов на свежие документы во время проведения выборов в сентябре 2016 года:
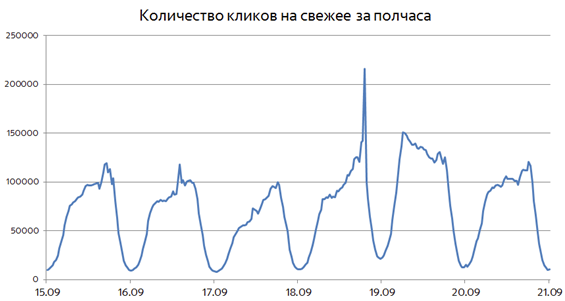
Хорошо видно, как в день выборов потребность в свежем постепенно нарастала, пока не достигла своего пика в 22:00. На следующий день повышенный интерес к свежему сохранялся, но уже через сутки вернулся примерно к обычным значениям. Другими словами, интерес к событию меняется с течением времени. Поэтому первая идея, полезная для определения потребности в свежем – «если какие-то запросы вдруг начинают задавать чаще, наверное, что-то произошло, и пользователям стоит показать свежие документы». Рассмотренная ситуация интересна и ещё по одной причине: интерес к свежему был прогнозируем заранее, т.к. дата выборов была известна задолго до их проведения.
Бывает так, что события сильно растянуты во времени. Примером такого события является Олимпиада 2016 года: в течение всех соревнований пользователи практически в два раза чаще потребляли свежие документы, чем это происходит в обычные дни:
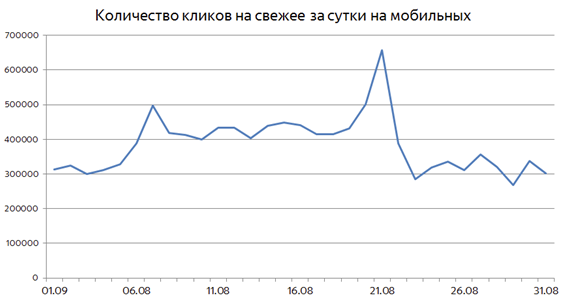
В таких ситуациях уже не получается детектировать интерес к свежести, исходя из резкого всплеска частотности запросов определённой тематики. Здесь на помощь может придти другой метод: если пользователям действительно нужна свежесть по каким-то запросам, возможно, она им понадобится и в ближайшем будущем.
Совсем иначе выглядит ситуация, когда происходит что-то неожиданное. Неожиданные резонансные события обычно не связаны ни с чем хорошим, поэтому просто посмотрим на графики без привязки к датам и конкретным происшествиям:
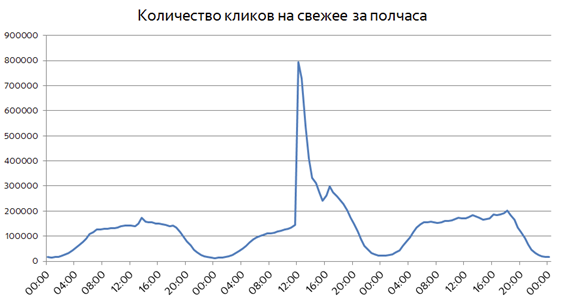
Уже в первые полчаса после произошедшего пользовательский интерес к свежему вырастает почти на порядок. Доля свежих запросов среди всех запросов в Поиск в такие моменты может увеличиваться до 25%. Неожиданные события хорошо детектируются резким всплеском пользовательского интереса, но такие всплески нужно определять в течение считанных минут после возникновения. Мы уже рассказывали о технологии Real Time MapReduce, которая позволяет Яндексу обрабатывать поисковые логи и доставлять результаты вычислений в Поиск в реальном времени.
1.2. Как представлена Свежесть в Поиске Яндекса
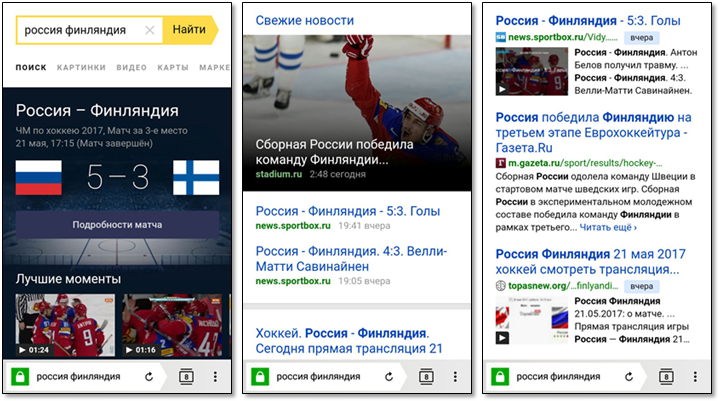
Сейчас мы поговорим о том, как свежие результаты представляются в поисковой выдаче. Рассмотрим запрос «россия финляндия», заданный 22 мая 2017 года. Этот запрос показателен, потому что при ответе на него Поиск демонстрирует практически все функциональные элементы, связанные с отработкой свежих запросов.
Поскольку спортивные запросы составляют значительную долю свежих запросов, мы специальным образом представляем информацию о спортивных матчах. Пользователь может узнать дату и время начала матча, счёт; иногда мы знаем ссылку на прямую трансляцию или видео интересных моментов.
Мы специальным образом группируем результаты из новостных источников, добиваясь большей аттрактивности.
Для остальных случаев мы ограничиваемся стандартными поисковыми сниппетами, к которым добавляем цветную плашки с возрастом документа. Иногда мы знаем, что документ содержит видео, и добавляем в сниппет его превью.
2. Как Свежесть попадает в поисковую выдачу
2.1. Модель Wide pFound
Свежие документы подмешиваются в выдачу по модели wide pFound. Эта модель в своё время была предложена для задачи разнообразия поисковой выдачи, вы можете посмотреть соответствующий доклад yafinder на YaC'2011, посвященный этому: https://events.yandex.ru/lib/talks/12/. Оказалось, что модель подходит для более широкого круга задач, в частности, для подмешивания свежих результатов.
В этой модели мы предполагаем, что пользователь, задавая конкретный поисковый запрос, имеет в виду один из интентов (интересов, тематик,...). Например, задавая запрос «ягуар», пользователь может иметь в виду автомобиль, напиток или животное. Запрос «котики» может предполагать потребность в соответствующих картинках, видео или же просто статьях. Запрос «евровидение» в определённые моменты наверняка требует самых актуальных (свежих!) новостей о ходе конкурса или подготовки к нему, в другие более вероятной потребностью представляется страница Википедии со списком победителей прошлых лет. Среди интентов нужно особо выделить специальный интент, который у нас обозначается  – это интент «всё остальное», который соответствует обычной органической выдаче.
– это интент «всё остальное», который соответствует обычной органической выдаче.
Задача поисковой системы заключается в том, чтобы подобрать для каждого пользователя и его запроса набор подходящих интентов, а затем правильным образом составить из релевантных этим интентам документов выдачу. В модели wide pFound мы считаем, что каждому из интентов соответствует некоторый вес, обозначающий вероятность пользовательского интереса именно к этому интенту, а для каждого документа на выдаче известен вектор его релевантностей для всех рассматриваемых интентов. Тогда для каждого интента можно расчитать метрику pFound – вероятность того, что наша выдача отвечает на запрос пользователя, если он имел в виду именно этот интент. Wide pFound – метрика, равная сумме взвешенных весами интентов pFound'ов по каждому из интентов:

где  — вероятность найти релевантный документ в выдаче, если пользователь имел в виду
— вероятность найти релевантный документ в выдаче, если пользователь имел в виду  -й интент.
-й интент.
Пусть, например, по некоторому запросу вес интента свежести равен 0.9, а релевантности документов соответствуют следующей таблице.
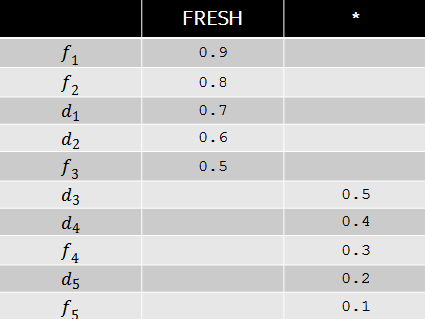
Тогда оптимальной с точки зрения wide pFound будет перестановка документов, изображенная в таблице ниже. Несмотря на то, что релевантности свежих документов в данном случае больше, с точки зрения разнообразия выгодно поставить на третью и четвертую позиции обычные документы, т.к. свежий интент уже в высокой степени удовлетворены первыми двумя результатами. Как мы видим, модель wide pFound представляет некоторый подход к формированию поисковой выдачи из разнородных источников, при этом задача сводится к определению весов интентов и релевантностей документов этим интентам.
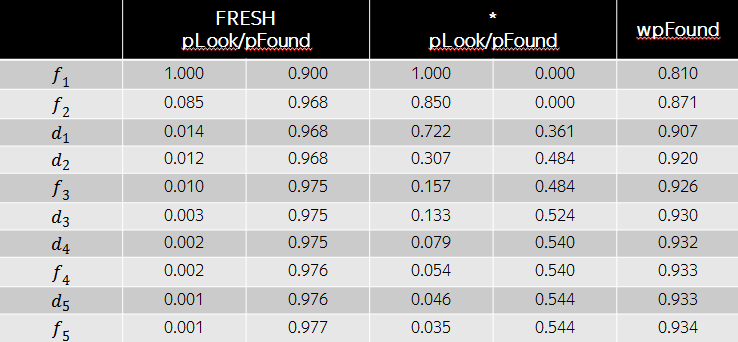
Исторически в Свежести мы называем задачу определения веса свежего интента задачей детекции свежего. Вторая задача – стандартная задача ранжирования документов, в нашем случае – свежих.
2.2. Обучение по кликам
Множество документов, предназначенных для свежего ранжирования, меняется с каждой минутой: появляются новые документы, исчезают старые. Из-за этого возникают сложности с использованием оценок, полученных в прошлом, т.к. и факторы, и оценки документов меняются с течением времени. Например, в 12:00 новость о том, что где-то произошел пожар, может быть релевантной, а в 14:00 уже нет, поскольку пожар к этому времени уже локализован. Поэтому, чтобы оценить релевантность свежей выдачи в 14:00, не удастся обойтись оценкой лишь новых документов: придется пересмотреть релевантности абсолютно всех свежих документов на выдаче.
Из-за этого оказывается сложным иметь большой актуальный оценённый набор размеченных пар «запрос – документ» в свежем ранжировании. Прорыва в качестве свежего ранжирования удалось добиться, когда мы научились использовать для обучения дополнительные источники информации. Главный из них – это пользовательский сигнал, клики на поисковых выдачах.
2.2.1. Обучение по кликам в ранжировании
В большинстве случаев свежие документы не показываются на первой позиции в выдаче, поэтому даже обучить простейший классификатор, предсказывающий кликабельность свежего документа на первой позиции, не так-то просто. Сравнивать между собой соседние свежие документы тоже не получается: между первым и вторым документами из свежести может распологаться произвольно большое количество документов из других источников. Поэтому многие подходы, используемые для обучения по кликам в традиционном ранжировании, совершенно не работают для свежести. Мы используем другие способы.

Представим себе выдачу, содержащую четыре обычных документа и три свежих, причем клики пришлись на первый свежий и последний обычный документы.
Можно предположить, что документ  предпочтительнее, чем документы
предпочтительнее, чем документы  и
и  , а вот сравнить и между собой уже достаточно сложно. Но, например, можно считать, что всё-таки лучше, т.к. текущая формула ранжирования предпочитает именно его.
, а вот сравнить и между собой уже достаточно сложно. Но, например, можно считать, что всё-таки лучше, т.к. текущая формула ранжирования предпочитает именно его.
Поэтому можно сформировать выборку несколькими различными способами:
- Для задачи попарной классификации: будем обучать формулу предпочитать документ документам и .
- Для задачи pointwise-классификации или регрессии: отнесём к положительному классу , а к отрицательному – и .
- Для задачи ранжирования: потребуем от формулы восстановить порядок
 .
.
Конечно, можно придумать и другие способы формирования обучающих выборок. Это творческий и очень увлекательный процесс.
2.2.2. Обучение по кликам в детекции
Рассмотрим две схемы обучения детекции свежего по кликам, которыми мы пользовались в разное время. Каждая из этих схем решает задачу так называемых контекстных многоруких бандитов. Контекстом в данном случае являются факторы, вычисляемые по пользовательскому запросу. Среди относящихся к свежести имело бы смысл упомянуть несколько: «контрастность» запроса (например, отношение частоты запроса за последние сутки к его частоте за последнюю неделю), количество новостей, написанных за последнее время на эту тему, CTR свежести по запросу и так далее.
Кликовую информацию можно собирать несколькими способами. Например, можно использовать клики пользователей по всем свежим документам: если произошел клик по свежему, то необходимо подкрепить предсказание детектора, т.к. срабатывание было уместно. Это весьма привлекательный способ, но при практическом применении он сталкивается с рядом трудностей. Выборка оказывается сильно смещена в сторону срабатываний текущей формулы, а в некоторых случаях очень сложно понять, какой должна быть величина подкрепления. Скажем, если свежесть была показана низко, а кликов не было, то это может быть свидетельством как отсутствия интереса к свежему (и в этом случае необходимо уменьшать вес интента), так и слишком низкой позиции (и в этом случае вес интента необходимо увеличивать).
Можно использовать специальный эксперимент, в котором свежесть показывается на «случайных» позициях. Интент свежести – число от нуля до единицы, которое можно выбирать из небольшого набора — скажем, чисел, кратных 0.05. Тогда задача сводится к выбору одного из 21 различных значений. Это и есть задача о многоруких бандитах. Откликом на наш выбор будет некоторое поведение пользователя на выдаче – например, клик на какой-либо результат, а задача машинного обучения будет формулироваться в терминах выбора величины интента свежести, для которой вероятность этого отлика максимальна. Этот способ дает очень хорошие результаты, но у него есть один значительный недостаток: сама процедура сбора кликового сигнала очень сильно ухудшает выдачу для пользователей, т.к. большинство показов свежего оказываются нерелевантны.
Если же уже имеется некоторая формула  детекции свежести – подобранная по асессорским оценкам или же методом, описанным выше, — то ее значение можно изменять на небольшую случайную величину, а затем предсказывать оптимальное значение изменения её предсказания так же, как это делалось выше. Если говорить точнее, то положим, что на текущем запросе формула предсказывает вес интента
детекции свежести – подобранная по асессорским оценкам или же методом, описанным выше, — то ее значение можно изменять на небольшую случайную величину, а затем предсказывать оптимальное значение изменения её предсказания так же, как это делалось выше. Если говорить точнее, то положим, что на текущем запросе формула предсказывает вес интента  . Прибавим к этому весу небольшую случайную добавку:
. Прибавим к этому весу небольшую случайную добавку:  , где
, где  – величина из небольшого дискретного множества значений. Например,
– величина из небольшого дискретного множества значений. Например,  . Тогда можно обучить формулу
. Тогда можно обучить формулу  , которая будет предсказывать оптимальную величину добавки, а в качестве новой формулы использовать сумму двух:
, которая будет предсказывать оптимальную величину добавки, а в качестве новой формулы использовать сумму двух:  .
.
Этот способ позволяет модифицировать значения текущих формул детекции свежести и постоянно вносить в них улучшения. Он практически не портит выдачу для пользователей, но позволяет за несколько шагов вносить существенные изменения в предсказания наших формул.
3. Когда Свежесть работает хорошо
Наконец, хотелось бы на примере нескольких событий рассказать о показателях, при помощи которых мы понимаем, что Свежесть работает хорошо.
Начать хотелось бы с графика общей актуальности результатов поиска. Этот график строится компанией "Ашманов и партнёры", так что можно не сомневаться в его объективности:
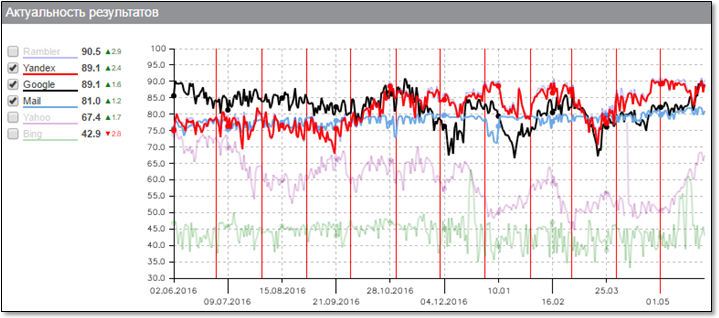
Здесь хорошо виден прогресс Яндекса (красная линия) в скорости индексации документов, который был достигнут в течение последнего года. Наш робот действительно способен за считанные минуты узнать о появлении нового документа и доставить его до поискового индекса Свежести с тем, чтобы он был показан пользователям по релевантным запросам.
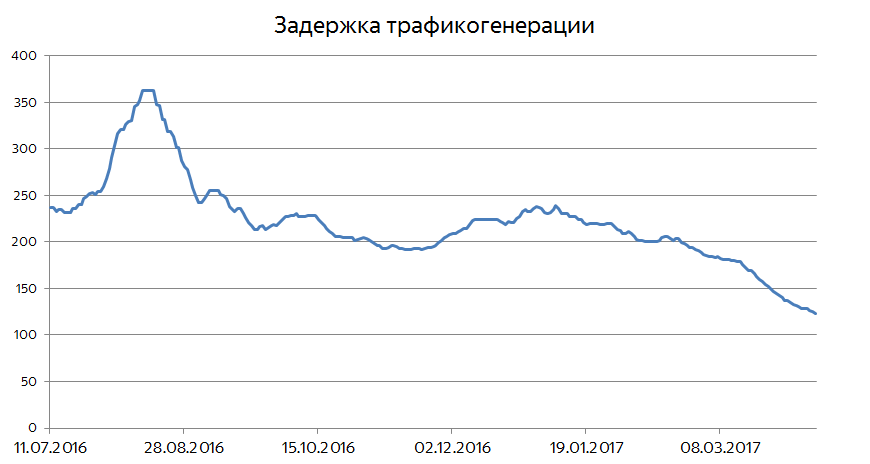
Рассмотрим для примера новость о квалификации сборной Бразилии на ЧМ-2018. Документ появился на сайте издательства в 10:56, и уже в 10:58 мы впервые показали его на выдаче пользователю, а вплоть до 11:00 он был показан еще порядка двадцати раз по релевантным запросам. По этой схеме можно построить и общую метрику, а не только изучать конкретные документы. Возьмём, например, все достаточно популярные документы (которые показывались на выдачах хотя бы 1000 раз в день) и посмотрим на медианное время между их публикацией и первым показом на выдаче.
Если нарисовать этот график за последний год, можно увидеть, что эта величина уменьшилась с четырёх минут до примерно двух. Это и означает, что свежие документы сейчас становятся доступными для пользователей практически моментально.
Когда происходит какое-нибудь достаточно крупное событие, важно сразу начать отвечать пользователям на соответствующие запросы максимально актуальными документами. Иногда это видно на глобальных графиках возраста свежих документов на выдачах. Мы постоянно следим за тем, какая доля показанных документов имеет возраст меньше 10 минут, получаса, часа, двух часов и так далее. За счет того, что интерес к событиям всё-таки растянут во времени, доля такого рода документов редко превышает 50%. Но бывают случаи, когда графики ведут себя так:
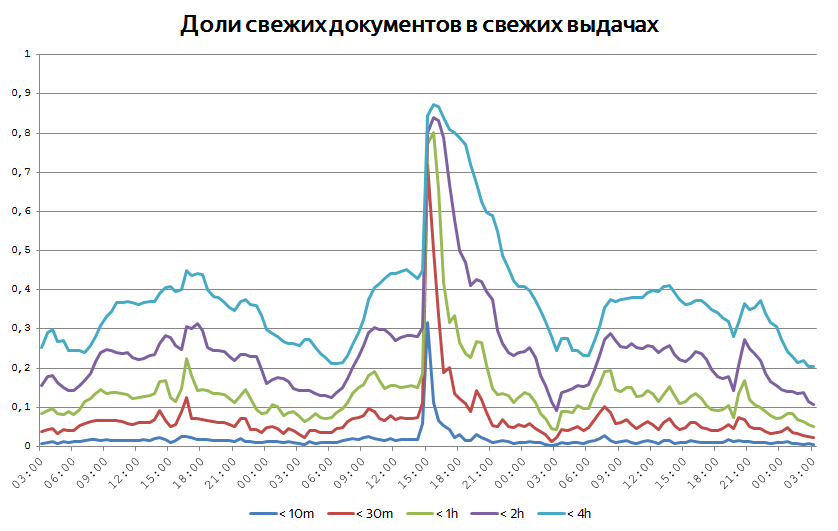
Когда в мире происходит какое-то значительное событие, оно порождает всплеск публикаций и поисковой активности, и тогда чрезвычайно свежие документы начинают превалировать.
4. Заключение
Мы рассмотрели некоторые аспекты формирования поисковой выдачи в ситуациях, когда пользователю необходима максимально актуальная информация по запросу. Конечно, за рамками нашего рассмотрения осталось большое количество вопросов, таких, например, как качество быстрого обхода и робота, антиспам, авторитетность, дизайн и так далее. Мы обсудили лишь свежесть в веб-поиске и оставили за рамками рассмотрения другие сервисы, также испытывающие потребность в свежем: картинки, видео, поисковые подсказки, голосовой поиск и так далее. Часть из этих тем будет затронута на уже анонсированной встрече "Яндекс изнутри", а другие, я надеюсь, мы обсудим в будущих статьях.
Stay tuned!
