
Раньше для вызова такси приходилось звонить на разные номера диспетчерских служб и ждать подачу машины полчаса или даже больше. Теперь сервисы такси хорошо автоматизированы, а среднее время подачи автомобиля Яндекс.Такси в Москве около 3-4 минут. Но стоит пойти дождю или закончиться массовому мероприятию, и мы вновь можем столкнуться с дефицитом свободных машин.
Меня зовут Скогорев Антон, я руковожу группой разработки эффективности платформы в Яндекс.Такси. Сегодня я расскажу читателям Хабра, как мы научились прогнозировать высокий спрос и дополнительно привлекать водителей, чтобы пользователи могли найти свободную машину в любое время. Вы узнаете, как формируется коэффициент, влияющий на стоимость заказа. Там всё далеко не так просто, как может показаться на первый взгляд.
Задача динамического ценообразования
Самая главная задача динамического ценообразования – предоставлять возможность заказать такси всегда. Достигается она с помощью коэффициента surge pricing coefficient, на который умножается рассчитанная цена. Мы называем его просто «сурдж». Важно сказать, что сурдж не только регулирует спрос на такси, но и помогает привлечь новых водителей, чтобы повысить предложение.
Если выставить сурдж слишком большим – мы снизим спрос слишком сильно, будет избыток свободных машин. Если выставить слишком низким – пользователи будут видеть «нет свободных машин». Нужно уметь выбирать такой коэффициент, при котором мы будем ходить по тонкому льду между отсутствием свободных машин и низким спросом.
От чего этот коэффициент должен зависеть? Сходу на ум приходит зависимость от количества машин и заказов вокруг пользователя. Теперь можно просто поделить количество заказов на количество водителей, получить коэффициент и какой-то формулой (возможно, линейной) превратить его в наш сурдж.
Но в этой задачке есть небольшая проблема – считать заказы вокруг пользователя может быть уже слишком поздно. Ведь заказ – это почти всегда уже занятая машина, а значит, повышение нашего коэффициента всегда будет запаздывать. Поэтому мы считаем не созданные заказы, а намерения заказать машину – пины. Пин – это метка «А» на карте, которую ставит пользователь, запуская наше приложение.

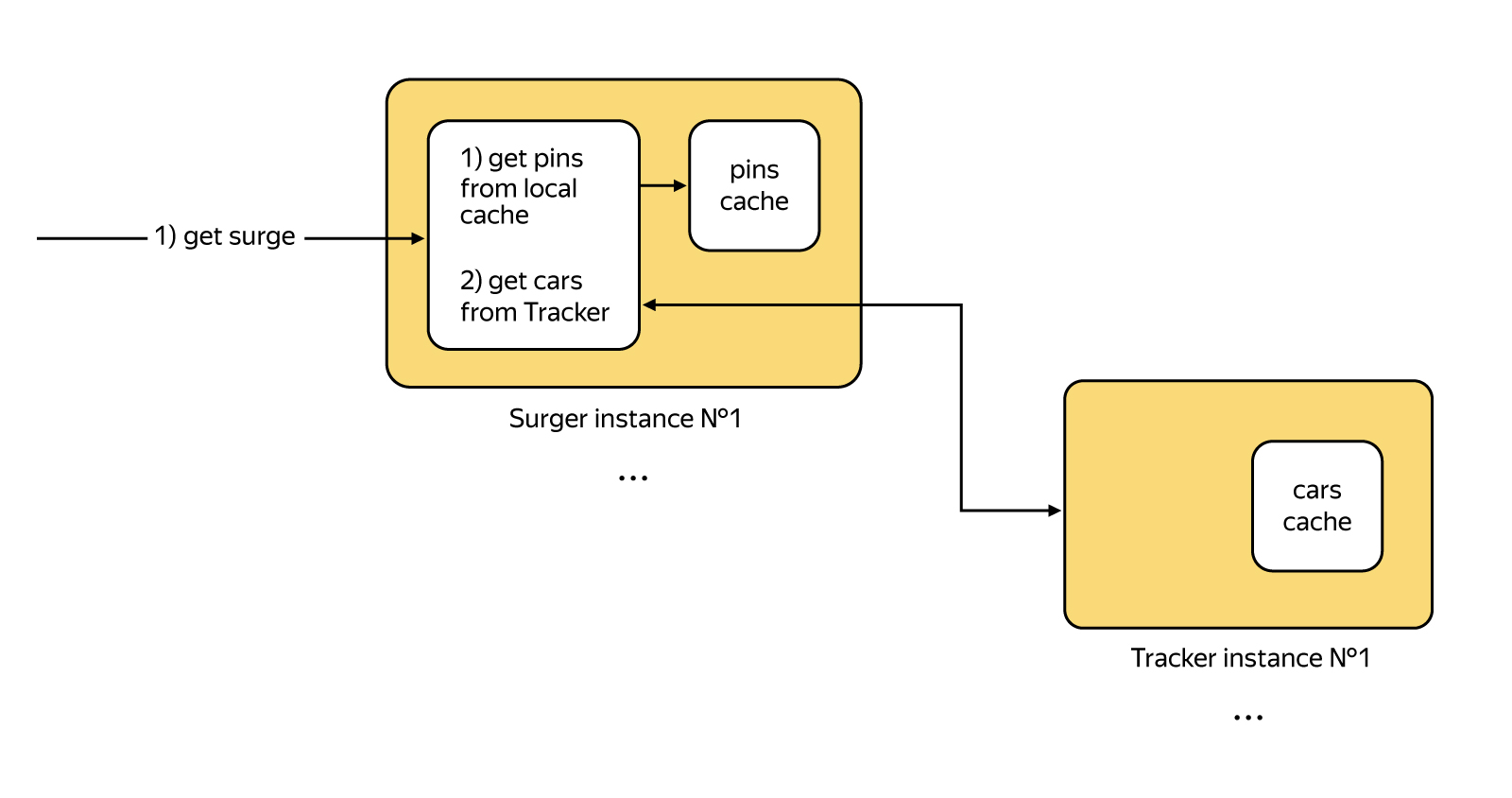
Сформулируем задачу: нам нужно считать мгновенные значения машин и пинов в какой-то точке пользователя.
Считаем количество пинов и машин вокруг
Когда положение пина меняется (пользовать выбирает точку «А»), приложение пользователя присылает в бекенд новые координаты и небольшую простыню дополнительной информации, которая помогает оценивать пин более точно (например, выбранный тариф).
Мы стараемся придерживаться микросервисной архитектуры, где каждый микросервис занимается обособленными задачами. Подсчетом сурджа занимается микросервис Surger. Он регистрирует пины, сохраняет их в базу данных, а также обновляет слепок пинов в оперативной памяти, в которую они достаточно неплохо умещаются. Отставание кэша при такой работе всего несколько секунд, что приемлемо в нашем случае.
Несколько слов про базу данных
При регистрации каждый пин асинхронно складывается в MongoDb с TTL Index, где TTL – «время жизни» пина, при котором мы считаем его активным для подсчета повышающего коэффициента. Пользователь не ждет, пока мы совершаем эти действия. Даже если что-то пойдет не так, потерять пин не такая большая трагедия.


Горячий кэш строится с индексом по геохэшу. Мы группируем все пины по геохэшу, а затем собираем пины для нужного радиуса вокруг точки заказа.
С машинами мы поступаем также, но в другом сервисе под названием Tracker, в который Surger просто ходит с вопросом «а сколько водителей находятся в этом радиусе».
Так мы считаем мгновенные значения коэффициента.
Кэширование
Кейс: вы стоите в Москве на Садовом кольце и хотите заказать машину. При этом цена прыгает достаточно часто и это раздражает.
Уже зная механику, можно понять, что такое может быть из-за того, что на условном светофоре скапливаются водители в момент запроса сурджа и также быстро оттуда уезжают. Из-за этого сурдж и цена могут заметно «прыгать».
Чтобы избежать подобного, мы кэшируем значение сурджа по пользователям. Когда пользователь приходит за сурджом, мы смотрим – есть ли для этого пользователя сохраненное значение сурджа в допустимом радиусе (линейный обход по всем сохраненным сурджам пользователя). Если есть – отдаем его, иначе рассчитываем новый и также сохраняем.
Работало это неплохо, но бывают и другие ситуации.
Кейс: 2 пользователя запрашивают сурдж. Один заказывает на 30 секунд позже другого, когда машины со светофора из прошлого кейса уже уехали. Получаем картину, где 2 пользователя, заказывающие почти одновременно, могут иметь заметно отличающийся сурдж.
И тут мы переходим от кэша по пользователю на кэш по позиции. Теперь, вместо того чтобы кэшировать значение сурджа только по пользователю, мы начинаем кэшировать его по уже знакомому нам геохэшу. Так мы почти чиним проблему. Почему почти? Потому что могут быть отличия на границах геохэшей. Но проблема не такая существенная, потому что у нас есть сглаживание.
Сглаживание
Возможно, читая кейс про светофор, вам пришла в голову мысль, что это как-то нечестно – считать мгновенный сурдж, зависящий от светофора. Мы тоже так считаем, поэтому придумали, как исправить ситуацию.
Мы решили позаимствовать у машинного обучения метод ближайших соседей для задачи регрессии для того, чтобы определить, как сильно значение мгновенного сурджа отличается от того, что сейчас происходит вокруг.
Этап обучения, как и в формальном описании метода, состоит в запоминании всех объектов – в нашем случае рассчитанных значений сурджа в пине, мы всё это и так уже делаем на момент загрузки всех пинов в кэш. Дело за малым – посчитать мгновенное значение, сравнить его со значением в зоне и договориться, что мы не можем отклоняться от значения в зоне слишком сильно.
Так мы получаем систему с быстрым откликом на происходящие события и позволяющую быстро считать значение повышающего коэффициента.
Водительская карта сурджа
Для коммуникации с водителем нам нужно уметь отображать карту сурджа в приложении водителя – таксометре. Это дает водителю обратную связь о том, есть ли спрос в зоне, где он находится сейчас, и куда ему стоит двигаться, чтобы получить наиболее дорогие заказы. Для нас же это значит, что больше водителей приедут в зону с повышенным спросом и урегулируют его.
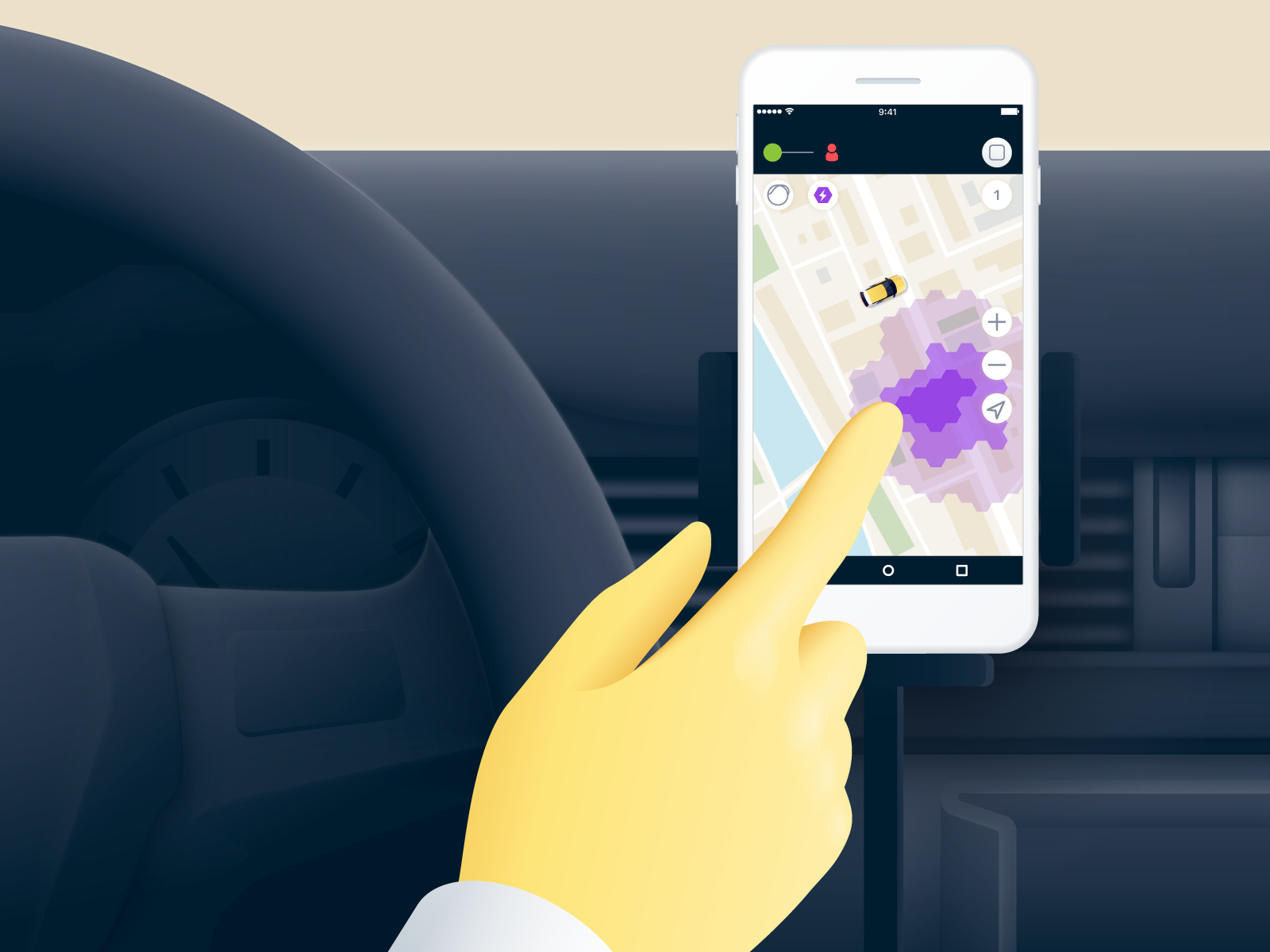
Мы живем с парадигмой, что устройство водителя – это достаточно слабое устройство. Поэтому рендеринг гексагональной сетки сурджа лежит на стороне бекенда. Клиент приходит в бекенд за тайлами. Это порезанные растровые картинки для непосредственного отображения на карте.
У нас есть отдельный сервис, который периодически забирает слепки пинов из микросервиса Surger и рассчитывает всю метаинформацию, необходимую для рендеринга гексагональной сетки: где какой гексагон и какой сурдж в каждом.
Заключение
Динамическое ценообразование – это постоянный поиск баланса между спросом и предложением, чтобы пользователям всегда были доступны свободные машины, в том числе за счет механизма привлечения дополнительных водителей в районы с высоким спросом. Например, мы сейчас работаем над более глубоким применением машинного обучения для расчета сурджа. В рамках одной из задач этого направления учимся определять вероятность конвертации пина в заказ и учитывать эту информацию. Работы здесь хватает, поэтому мы всегда рады новым специалистам в команде.
Если вам интересно узнать о какой-то части этой большой темы более детально, то пишите в комментариях. Отзывы и идеи тоже приветствуются!
P.S. В следующей публикации мой коллега расскажет о применении машинного обучения для прогнозирования ожидаемого времени прибытия такси.
