Привет, Хабр!
Меня зовут Виталий Котов, я работаю в компании Badoo и бо́льшую часть времени занимаюсь вопросами автоматизации тестирования. Решением одного такого вопроса я и хочу поделиться в этой статье.
Речь пойдёт о том, как мы организовали процесс работы UI-тестов с A/B-тестами, коих у нас немало. Я расскажу о том, с какими проблемами мы столкнулись и к какому флоу пришли в итоге. Добро пожаловать под кат!

В этой статье очень часто встречается слово «тест». Всё потому, что мы говорим одновременно и про UI-тесты, и про A/B-тесты. Я старался всегда разделять эти два понятия и формулировать мысли так, чтобы текст читался легко. Если где-то я всё же упустил первую часть слова и написал просто «тест», я имел в виду UI-тест.
Приятного чтения!
Итак, давайте прежде всего определимся с понятием A/B-теста. Вот цитата из Википедии:
«A/B-тестирование (англ. A/B testing, Split testing) — метод маркетингового исследования, суть которого заключается в том, что контрольная группа элементов сравнивается с набором тестовых групп, в которых один или несколько показателей были изменены, для того, чтобы выяснить, какие из изменений улучшают целевой показатель» Ссылка.
В терминах нашего проекта наличие A/B-теста подразумевает, что какой-то функционал различен для разных пользователей. Я бы выделил несколько вариантов:
Чтобы вся эта логика работала, у нас в компании есть инструмент, который называется UserSplit Tool, и о нём подробно рассказывал наш разработчик Ринат Ахмадеев в этой статье.
Мы же сейчас поговорим о том, что значит наличие A/B-тестов для отдела тестирования и для автоматизаторов в частности.
Когда мы говорим о покрытии UI-тестами, мы не говорим о количестве строк кода, которые мы протестировали. Это и понятно, ведь даже просто открытие страницы может задействовать много компонентов, в то время как мы ещё ничего не протестировали.
За много лет работы в сфере автоматизации тестирования я видел немало способов измерять покрытие UI-тестов. Не буду перечислять их все, лишь скажу, что мы предпочитаем оценивать этот показатель по количеству фич, которые покрыты UI-тестами. Это не идеальный способ (а идеального лично я и не знаю), но в нашем случае он работает.
И вот тут мы возвращаемся непосредственно к теме статьи. Как измерять и удерживать хороший уровень покрытия UI-тестов, когда каждая фича может вести себя по-разному в зависимости от пользователя, который её использует?
Ещё до того как в компании появился инструмент UserSplit Tool и A/B-тестов стало по-настоящему много, мы придерживались следующей стратегии покрытия фич UI-тестами: покрытие только тех фич, которые уже какое-то время находятся на продакшене и устоялись.
А всё потому, что раньше, когда фича только попадала на продакшен, она какое-то время ещё «тюнилась» — могли измениться её поведение, внешний вид. А ещё она и вовсе могла не зарекомендовать себя и довольно быстро пропасть с глаз пользователей. Писать UI-тесты для нестабильных фич — дело затратное и у нас не практиковалось.
С внедрением в процесс разработки A/B-тестов поначалу ничего не изменилось. У каждого A/B-теста была так называемая «контрольная группа», то есть группа, которая видела какое-то дефолтное поведение фичи. Именно на него и писались UI-тесты. Всё, что надо было сделать при написании UI-тестов для такой фичи, — не забыть включить пользователю именно дефолтное поведение. Мы этот процесс называем форсом A/B-группы (от англ. force).
На описании форса остановлюсь подробнее, так как он ещё сыграет роль в моём повествовании.
Мы уже не раз в своих статьях и в докладах рассказывали про QaAPI. Тем не менее, как ни странно, до сих пор мы не написали полноценную статью про этот инструмент. Вероятно, однажды этот пробел будет заполнен. А пока можно посмотреть видео выступления моего коллеги Дмитрия Марущенко: «4. Концепция QaAPI: взгляд на тестирование с другой стороны баррикад».
Если в двух словах, то QaAPI позволяет через специальный бэкдор делать запросы из теста на сервер приложения с целью манипуляции какими-либо данными. При помощи этого инструмента мы, например, подготавливаем пользователей к конкретным тест-кейсам, отправляем им сообщения, загружаем фото и так далее.
При помощи того же QaAPI мы умеем форсить группу A/B-теста; достаточно только указать название теста и название желаемой группы. Вызов в тесте выглядит примерно так:
Последним параметром мы указываем user_id или device_id, для которого этот форс должен начать работать. Параметр device_id мы указываем в случае неавторизованного пользователя, так как параметра user_id тогда ещё нет. Всё верно, для неавторизованных страниц у нас тоже бывают A/B-тесты.
После вызова этого QaAPI-метода авторизованный пользователь или владелец девайса гарантированно будет видеть тот вариант фичи, который мы зафорсили. Именно такие вызовы мы писали в UI-тестах, которые покрывали фичи, находящиеся под A/B-тестированием.
И так мы жили довольно долго. UI-тесты покрывали только контрольные группы A/B-тестов. Тогда их было не очень много, и это работало. Но время шло; количество A/B-тестов стало увеличиваться, и почти все новые фичи стали запускаться под A/B-тестами. Подход с покрытием только контрольных версий фичей нас перестал устраивать. И вот почему…
Проблема первая — покрытие
Как я написал выше, со временем почти все новые фичи стали выходить под A/B-тестами. Помимо контрольного, у каждой фичи есть ещё один, два или три других варианта. Выходит, для такой фичи покрытие в лучшем случае не превысит 50%, а в худшем — будет примерно 25%. Раньше, когда таких фич было мало, это не оказывало существенного влияния на суммарный показатель покрытия. Теперь — стало оказывать.
Проблема вторая — долгие A/B-тесты
Некоторые A/B-тесты сейчас занимают довольно длительное время. А мы продолжаем релизиться два раза в день (об этом можно почитать в статье нашего QA-инженера Ильи Кудинова «Как мы уже 4 года выживаем в условиях двух релизов в день»).
Таким образом, вероятность сломать какую-то из версий A/B-теста за это время невероятно большая. А это обязательно скажется на user experience и сведёт на нет весь смысл A/B-тестирования фичи: ведь фича может показывать плохие результаты на какой-то из версий не потому, что она не нравится пользователям, а потому, что не работает как положено.
Если мы хотим быть уверены в результате A/B-тестирования, нельзя допускать, чтобы какая-то из версий фичи работала иначе, чем от неё ожидается.
Проблема третья — актуальность UI-тестов
Есть такое понятие, как релиз A/B-теста. Это означает, что A/B-тест собрал достаточное количество статистики и продакт-менеджер готов открыть победивший вариант для всех пользователей. Релиз A/B-теста происходит асинхронно с релизом кода, так как зависит от настройки конфига, а не от кода.
Предположим, победил и зарелизился не контрольный вариант. Что будет с UI-тестами, которые покрывали только его? Правильно: они сломаются. А что, если они сломаются за час до релиза билда? Сможем ли мы провести регрессионное тестирование этого самого билда? Нет. Как известно, со сломанными тестами далеко не уедешь.
Значит, нужно быть готовым к закрытию любого A/B-теста заранее, чтобы оно не помешало работоспособности UI-тестов и, как следствие, очередному релизу билда.
Вывод
Вывод из вышесказанного напрашивается очевидный: надо покрывать A/B-тесты UI-тестами целиком, все варианты. Логично? Да! Всем спасибо, расходимся!
… Шутка! Не всё так просто.
Первое, что показалось неудобным, — контроль над тем, какие A/B-тесты и варианты фич уже покрыты, а какие — ещё нет. Исторически сложилось так, что мы называем UI-тесты по следующему принципу:
Например, ChatBlockedUserTest, RegistrationViaFacebookTest и так далее. Пихать сюда ещё и название сплит-теста показалось неудобным. Во-первых, названия стали бы невероятно длинными. Во-вторых, тесты пришлось бы переименовывать по завершении A/B-теста, а это плохо сказалось бы на сборе статистики, которая учитывает название UI-теста.
Грепать же всё время код на вызов QaAPI-метода — то ещё удовольствие.
Так что мы решили убрать все вызовы QaApi::forceSplitTest() из кода UI-тестов и перенести данные о том, где какие форсы нужны, в MySQL-табличку. Для неё мы сделали UI-представление на Selenium Manager (о нём я рассказывал тут).
Выглядит это примерно так:

В таблице можно указать, для какого UI-теста форс какого A/B-теста и в какой группе мы хотим применить. Можно указать название самого UI-теста, класса тестов или All.
Помимо этого, мы можем указать, распространяется этот форс на авторизованных или на неавторизованных пользователей.
Далее мы научили UI-тесты при запуске получать данные из этой таблицы и форсить те, которые имеют отношение непосредственно к запущенному тесту или ко всем (all) тестам.
Таким образом нам удалось собрать все манипуляции A/B-тестами в одном месте. Теперь список покрытых A/B-тестов удобен для просмотра.
Там же мы создали форму для добавления новых A/B-тестов:
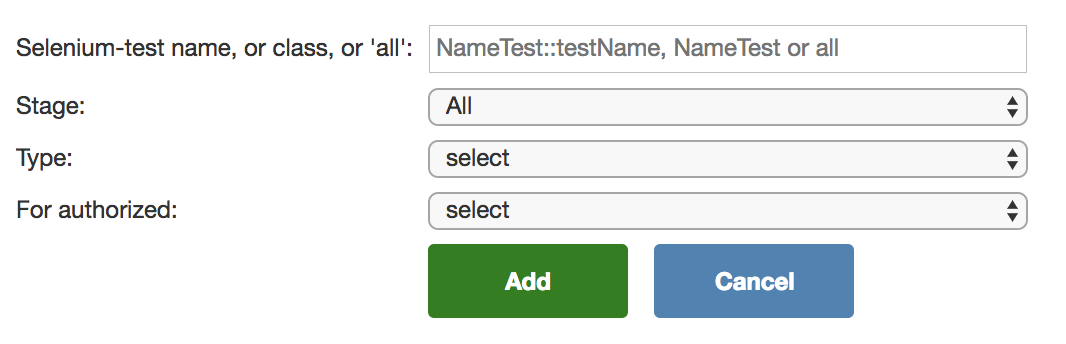
Всё это позволяет легко и быстро добавлять и убирать необходимые форсы без создания коммита, ожидания, когда он разложится по всем клаудам, где запускаются UI-тесты, и т. д.
Второе, чему мы решили уделить внимание, — пересмотр подхода к написанию UI-тестов для A/B-тестов.
В двух словах расскажу, как мы пишем обычные UI-тесты. Архитектура довольно простая и привычная:
В целом эта архитектура нас полностью устраивает. Мы знаем, что, если изменился UI, надо менять только PageObject-классы (при этом сами тесты не должны быть затронуты). Если же поменялась бизнес-логика фичи, меняем сценарий.
Как я писал в одной из предыдущих статей, с UI-тестами у нас работают все: и ребята из отдела ручного тестирования, и разработчики. Чем этот процесс проще и понятнее, тем чаще тесты будут запускать люди, не имеющие к ним непосредственного отношения.
Но, как я писал выше, в отличие от устоявшихся фич, A/B-тесты то приходят, то уходят. Если мы будем писать их в том же формате, что и обычные UI-тесты, придётся постоянно удалять код из множества разных мест после завершения A/B-тестов. Сами понимаете, на рефакторинг, особенно когда и без него всё работает, не всегда удаётся выделить время.
Тем не менее позволить нашим классам зарастать неиспользуемыми методами и локаторами не хочется, это сделает те же PageObject’ы сложными для использования. Как бы облегчить себе жизнь?
Тут нам на выручку пришёл PhpStorm (спасибо ребятам из JetBrains за удобную IDE), а именно вот эта фича.
Если коротко, она позволяет при помощи специальных тегов разделять код на так называемые регионы. Мы попробовали — и нам понравилось. Мы начали писать временные UI-тесты на активные A/B-тесты в одном файле, разделяя зоны кода на регионы, указывающие на класс, в который в будущем следует положить данный код.
В итоге код теста выглядел примерно так:

В каждом регионе находится код, который относится к тому или иному классу. Наверняка и в других IDE есть нечто подобное.
Таким образом, мы одним классом-тестом покрывали все варианты A/B-теста, помещая туда же и PageObject-методы, и локаторы. А после его завершения мы сначала удаляли из класса проигравшие варианты, а затем довольно легко разносили оставшийся код по нужным классам в соответствии с тем, что указано в регионе.
Нельзя просто так взять и разом покрыть все A/B-тесты UI-тестами. С другой стороны, и задачи такой нет. Задача с точки зрения автоматизации состоит в том, чтобы быстро покрывать только важные и долгоиграющие тесты.
Тем не менее до релиза любого, даже самого крошечного, A/B-теста хочется иметь возможность запустить все UI-тесты на победившем варианте и убедиться, что всё работает как надо и мы на 100% пользователей тиражируем качественный работающий функционал.
Упомянутое выше решение с MySQL-таблицей для этой цели не подходит. Дело в том, что, если добавить туда форс, он сразу начнёт включаться для всех UI-тестов. Помимо стейджинга (нашего предпродакшен-окружения, где мы запускаем полный набор тестов), это повлияет ещё и на UI-тесты, запущенные против веток отдельных задач. С результатами тех запусков будут работать коллеги из отдела ручного тестирования. И если зафоршенный A/B-тест имеет баг, тесты для их задач тоже упадут и ребята могут решить, что проблема в их задаче, а не в A/B-тесте. Из-за этого на тестирование и разбирательство может уйти много времени (никто не будет доволен).
Мы пока обошлись минимальными изменениями, добавив в таблицу возможность указывать целевое окружение:

Это окружение можно на лету изменить в уже существующей записи. Таким образом, мы можем добавить форс только для стейджинга, никак не влияя на результаты прохождения тестов на отдельных задачах.
Итак, до начала всей этой истории наши UI-тесты покрывали только основные (контрольные) группы A/B-тестов. Но мы поняли, что хотим большего, и пришли к выводу, что покрывать другие варианты A/B-тестов тоже необходимо.
В итоге:
Всё это позволило адаптировать автоматизацию тестирования под постоянно меняющиеся фичи, легко контролировать и увеличивать уровень покрытия и не зарастать легаси-кодом.
А у вас есть опыт приведения на первый взгляд хаотичной ситуации к какому-то контролируемому порядку и упрощения жизни себе и коллегам? Делитесь им в комментариях. :)
Спасибо за внимание! И с наступающим Новым годом!
Меня зовут Виталий Котов, я работаю в компании Badoo и бо́льшую часть времени занимаюсь вопросами автоматизации тестирования. Решением одного такого вопроса я и хочу поделиться в этой статье.
Речь пойдёт о том, как мы организовали процесс работы UI-тестов с A/B-тестами, коих у нас немало. Я расскажу о том, с какими проблемами мы столкнулись и к какому флоу пришли в итоге. Добро пожаловать под кат!
Пока не начали...
В этой статье очень часто встречается слово «тест». Всё потому, что мы говорим одновременно и про UI-тесты, и про A/B-тесты. Я старался всегда разделять эти два понятия и формулировать мысли так, чтобы текст читался легко. Если где-то я всё же упустил первую часть слова и написал просто «тест», я имел в виду UI-тест.
Приятного чтения!
Что такое A/B-тесты
Итак, давайте прежде всего определимся с понятием A/B-теста. Вот цитата из Википедии:
«A/B-тестирование (англ. A/B testing, Split testing) — метод маркетингового исследования, суть которого заключается в том, что контрольная группа элементов сравнивается с набором тестовых групп, в которых один или несколько показателей были изменены, для того, чтобы выяснить, какие из изменений улучшают целевой показатель» Ссылка.
В терминах нашего проекта наличие A/B-теста подразумевает, что какой-то функционал различен для разных пользователей. Я бы выделил несколько вариантов:
- фича доступна для одной группы пользователей, но недоступна для другой;
- фича доступна для всех пользователей, но работает по-разному;
- фича доступна для всех пользователей, работает одинаково, но выглядит по-разному;
- любая комбинация предыдущих трёх вариантов.
Чтобы вся эта логика работала, у нас в компании есть инструмент, который называется UserSplit Tool, и о нём подробно рассказывал наш разработчик Ринат Ахмадеев в этой статье.
Мы же сейчас поговорим о том, что значит наличие A/B-тестов для отдела тестирования и для автоматизаторов в частности.
Покрытие UI-тестами
Когда мы говорим о покрытии UI-тестами, мы не говорим о количестве строк кода, которые мы протестировали. Это и понятно, ведь даже просто открытие страницы может задействовать много компонентов, в то время как мы ещё ничего не протестировали.
За много лет работы в сфере автоматизации тестирования я видел немало способов измерять покрытие UI-тестов. Не буду перечислять их все, лишь скажу, что мы предпочитаем оценивать этот показатель по количеству фич, которые покрыты UI-тестами. Это не идеальный способ (а идеального лично я и не знаю), но в нашем случае он работает.
И вот тут мы возвращаемся непосредственно к теме статьи. Как измерять и удерживать хороший уровень покрытия UI-тестов, когда каждая фича может вести себя по-разному в зависимости от пользователя, который её использует?
Как фичи покрывались UI-тестами изначально
Ещё до того как в компании появился инструмент UserSplit Tool и A/B-тестов стало по-настоящему много, мы придерживались следующей стратегии покрытия фич UI-тестами: покрытие только тех фич, которые уже какое-то время находятся на продакшене и устоялись.
А всё потому, что раньше, когда фича только попадала на продакшен, она какое-то время ещё «тюнилась» — могли измениться её поведение, внешний вид. А ещё она и вовсе могла не зарекомендовать себя и довольно быстро пропасть с глаз пользователей. Писать UI-тесты для нестабильных фич — дело затратное и у нас не практиковалось.
С внедрением в процесс разработки A/B-тестов поначалу ничего не изменилось. У каждого A/B-теста была так называемая «контрольная группа», то есть группа, которая видела какое-то дефолтное поведение фичи. Именно на него и писались UI-тесты. Всё, что надо было сделать при написании UI-тестов для такой фичи, — не забыть включить пользователю именно дефолтное поведение. Мы этот процесс называем форсом A/B-группы (от англ. force).
На описании форса остановлюсь подробнее, так как он ещё сыграет роль в моём повествовании.
Force для A/B-тестов и QaAPI
Мы уже не раз в своих статьях и в докладах рассказывали про QaAPI. Тем не менее, как ни странно, до сих пор мы не написали полноценную статью про этот инструмент. Вероятно, однажды этот пробел будет заполнен. А пока можно посмотреть видео выступления моего коллеги Дмитрия Марущенко: «4. Концепция QaAPI: взгляд на тестирование с другой стороны баррикад».
Если в двух словах, то QaAPI позволяет через специальный бэкдор делать запросы из теста на сервер приложения с целью манипуляции какими-либо данными. При помощи этого инструмента мы, например, подготавливаем пользователей к конкретным тест-кейсам, отправляем им сообщения, загружаем фото и так далее.
При помощи того же QaAPI мы умеем форсить группу A/B-теста; достаточно только указать название теста и название желаемой группы. Вызов в тесте выглядит примерно так:
QaApi::forceSpliTest(“Test name”, “Test group name”, {USER_ID or DEVICE_ID});Последним параметром мы указываем user_id или device_id, для которого этот форс должен начать работать. Параметр device_id мы указываем в случае неавторизованного пользователя, так как параметра user_id тогда ещё нет. Всё верно, для неавторизованных страниц у нас тоже бывают A/B-тесты.
После вызова этого QaAPI-метода авторизованный пользователь или владелец девайса гарантированно будет видеть тот вариант фичи, который мы зафорсили. Именно такие вызовы мы писали в UI-тестах, которые покрывали фичи, находящиеся под A/B-тестированием.
И так мы жили довольно долго. UI-тесты покрывали только контрольные группы A/B-тестов. Тогда их было не очень много, и это работало. Но время шло; количество A/B-тестов стало увеличиваться, и почти все новые фичи стали запускаться под A/B-тестами. Подход с покрытием только контрольных версий фичей нас перестал устраивать. И вот почему…
Зачем покрывать A/B-тесты
Проблема первая — покрытие
Как я написал выше, со временем почти все новые фичи стали выходить под A/B-тестами. Помимо контрольного, у каждой фичи есть ещё один, два или три других варианта. Выходит, для такой фичи покрытие в лучшем случае не превысит 50%, а в худшем — будет примерно 25%. Раньше, когда таких фич было мало, это не оказывало существенного влияния на суммарный показатель покрытия. Теперь — стало оказывать.
Проблема вторая — долгие A/B-тесты
Некоторые A/B-тесты сейчас занимают довольно длительное время. А мы продолжаем релизиться два раза в день (об этом можно почитать в статье нашего QA-инженера Ильи Кудинова «Как мы уже 4 года выживаем в условиях двух релизов в день»).
Таким образом, вероятность сломать какую-то из версий A/B-теста за это время невероятно большая. А это обязательно скажется на user experience и сведёт на нет весь смысл A/B-тестирования фичи: ведь фича может показывать плохие результаты на какой-то из версий не потому, что она не нравится пользователям, а потому, что не работает как положено.
Если мы хотим быть уверены в результате A/B-тестирования, нельзя допускать, чтобы какая-то из версий фичи работала иначе, чем от неё ожидается.
Проблема третья — актуальность UI-тестов
Есть такое понятие, как релиз A/B-теста. Это означает, что A/B-тест собрал достаточное количество статистики и продакт-менеджер готов открыть победивший вариант для всех пользователей. Релиз A/B-теста происходит асинхронно с релизом кода, так как зависит от настройки конфига, а не от кода.
Предположим, победил и зарелизился не контрольный вариант. Что будет с UI-тестами, которые покрывали только его? Правильно: они сломаются. А что, если они сломаются за час до релиза билда? Сможем ли мы провести регрессионное тестирование этого самого билда? Нет. Как известно, со сломанными тестами далеко не уедешь.
Значит, нужно быть готовым к закрытию любого A/B-теста заранее, чтобы оно не помешало работоспособности UI-тестов и, как следствие, очередному релизу билда.
Вывод
Вывод из вышесказанного напрашивается очевидный: надо покрывать A/B-тесты UI-тестами целиком, все варианты. Логично? Да! Всем спасибо, расходимся!
… Шутка! Не всё так просто.
Интерфейс для A/B-тестов
Первое, что показалось неудобным, — контроль над тем, какие A/B-тесты и варианты фич уже покрыты, а какие — ещё нет. Исторически сложилось так, что мы называем UI-тесты по следующему принципу:
- название фичи или страницы;
- описание кейса;
- Test.
Например, ChatBlockedUserTest, RegistrationViaFacebookTest и так далее. Пихать сюда ещё и название сплит-теста показалось неудобным. Во-первых, названия стали бы невероятно длинными. Во-вторых, тесты пришлось бы переименовывать по завершении A/B-теста, а это плохо сказалось бы на сборе статистики, которая учитывает название UI-теста.
Грепать же всё время код на вызов QaAPI-метода — то ещё удовольствие.
Так что мы решили убрать все вызовы QaApi::forceSplitTest() из кода UI-тестов и перенести данные о том, где какие форсы нужны, в MySQL-табличку. Для неё мы сделали UI-представление на Selenium Manager (о нём я рассказывал тут).
Выглядит это примерно так:
В таблице можно указать, для какого UI-теста форс какого A/B-теста и в какой группе мы хотим применить. Можно указать название самого UI-теста, класса тестов или All.
Помимо этого, мы можем указать, распространяется этот форс на авторизованных или на неавторизованных пользователей.
Далее мы научили UI-тесты при запуске получать данные из этой таблицы и форсить те, которые имеют отношение непосредственно к запущенному тесту или ко всем (all) тестам.
Таким образом нам удалось собрать все манипуляции A/B-тестами в одном месте. Теперь список покрытых A/B-тестов удобен для просмотра.
Там же мы создали форму для добавления новых A/B-тестов:
Всё это позволяет легко и быстро добавлять и убирать необходимые форсы без создания коммита, ожидания, когда он разложится по всем клаудам, где запускаются UI-тесты, и т. д.
Архитектура UI-тестов
Второе, чему мы решили уделить внимание, — пересмотр подхода к написанию UI-тестов для A/B-тестов.
В двух словах расскажу, как мы пишем обычные UI-тесты. Архитектура довольно простая и привычная:
- классы-тесты — там описана бизнес-логика покрываемой фичи (по сути, это сценарии наших тестов: сделал то-то, увидел то-то);
- PageObject-классы — там описаны все взаимодействия с UI и локаторы;
- TestCase-классы — там находятся общие методы, которые не касаются непосредственно UI, но могут пригодиться в нескольких классах-тестах (например, взаимодействия с QaAPI);
- core-классы — там находятся логика поднятия сессии, логирование и другие вещи, которые при написании обычного теста трогать не надо.
В целом эта архитектура нас полностью устраивает. Мы знаем, что, если изменился UI, надо менять только PageObject-классы (при этом сами тесты не должны быть затронуты). Если же поменялась бизнес-логика фичи, меняем сценарий.
Как я писал в одной из предыдущих статей, с UI-тестами у нас работают все: и ребята из отдела ручного тестирования, и разработчики. Чем этот процесс проще и понятнее, тем чаще тесты будут запускать люди, не имеющие к ним непосредственного отношения.
Но, как я писал выше, в отличие от устоявшихся фич, A/B-тесты то приходят, то уходят. Если мы будем писать их в том же формате, что и обычные UI-тесты, придётся постоянно удалять код из множества разных мест после завершения A/B-тестов. Сами понимаете, на рефакторинг, особенно когда и без него всё работает, не всегда удаётся выделить время.
Тем не менее позволить нашим классам зарастать неиспользуемыми методами и локаторами не хочется, это сделает те же PageObject’ы сложными для использования. Как бы облегчить себе жизнь?
Тут нам на выручку пришёл PhpStorm (спасибо ребятам из JetBrains за удобную IDE), а именно вот эта фича.
Если коротко, она позволяет при помощи специальных тегов разделять код на так называемые регионы. Мы попробовали — и нам понравилось. Мы начали писать временные UI-тесты на активные A/B-тесты в одном файле, разделяя зоны кода на регионы, указывающие на класс, в который в будущем следует положить данный код.
В итоге код теста выглядел примерно так:
В каждом регионе находится код, который относится к тому или иному классу. Наверняка и в других IDE есть нечто подобное.
Таким образом, мы одним классом-тестом покрывали все варианты A/B-теста, помещая туда же и PageObject-методы, и локаторы. А после его завершения мы сначала удаляли из класса проигравшие варианты, а затем довольно легко разносили оставшийся код по нужным классам в соответствии с тем, что указано в регионе.
Как мы теперь закрываем A/B-тесты
Нельзя просто так взять и разом покрыть все A/B-тесты UI-тестами. С другой стороны, и задачи такой нет. Задача с точки зрения автоматизации состоит в том, чтобы быстро покрывать только важные и долгоиграющие тесты.
Тем не менее до релиза любого, даже самого крошечного, A/B-теста хочется иметь возможность запустить все UI-тесты на победившем варианте и убедиться, что всё работает как надо и мы на 100% пользователей тиражируем качественный работающий функционал.
Упомянутое выше решение с MySQL-таблицей для этой цели не подходит. Дело в том, что, если добавить туда форс, он сразу начнёт включаться для всех UI-тестов. Помимо стейджинга (нашего предпродакшен-окружения, где мы запускаем полный набор тестов), это повлияет ещё и на UI-тесты, запущенные против веток отдельных задач. С результатами тех запусков будут работать коллеги из отдела ручного тестирования. И если зафоршенный A/B-тест имеет баг, тесты для их задач тоже упадут и ребята могут решить, что проблема в их задаче, а не в A/B-тесте. Из-за этого на тестирование и разбирательство может уйти много времени (никто не будет доволен).
Мы пока обошлись минимальными изменениями, добавив в таблицу возможность указывать целевое окружение:
Это окружение можно на лету изменить в уже существующей записи. Таким образом, мы можем добавить форс только для стейджинга, никак не влияя на результаты прохождения тестов на отдельных задачах.
Подводим итоги
Итак, до начала всей этой истории наши UI-тесты покрывали только основные (контрольные) группы A/B-тестов. Но мы поняли, что хотим большего, и пришли к выводу, что покрывать другие варианты A/B-тестов тоже необходимо.
В итоге:
- мы создали интерфейс для удобного контроля над покрытием A/B-тестов; в результате теперь у нас есть вся информация о работе UI-тестов с A/B-тестами;
- мы выработали для себя способ написания временных UI-тестов с простым и эффективным флоу их дальнейшего удаления или перевода в ряды постоянных;
- мы научились легко и безболезненно тестировать релизы A/B-тестов, не мешая другим запущенным UI-тестам, и без излишних коммитов в Git.
Всё это позволило адаптировать автоматизацию тестирования под постоянно меняющиеся фичи, легко контролировать и увеличивать уровень покрытия и не зарастать легаси-кодом.
А у вас есть опыт приведения на первый взгляд хаотичной ситуации к какому-то контролируемому порядку и упрощения жизни себе и коллегам? Делитесь им в комментариях. :)
Спасибо за внимание! И с наступающим Новым годом!
