
Cегодня браузеры играют жизненно важную роль в современных организациях, поскольку всё больше программных приложений доставляется пользователям через веб-браузер в виде веб-приложений. Практически всё, что вы делаете в Интернете, включает в себя применение веб-браузера, а потому он является одним из самых используемых потребительских программных продуктов на планете.
Работая дверями в Интернет, браузеры в то же время создают существенные угрозы целостности персональных вычислительных устройств. Почти ежедневно мы слышим новости наподобие "баг Google Chrome активно используется как Zero-Day" или "Google подтвердила четвёртый эксплойт Zero-Day Chrome за 2022 год". На самом деле, эксплойты браузеров не представляют собой ничего нового, их находят уже долгие годы, начиная с первого эксплойта для удалённого исполнения кода, задокументированного как CVE-1999-0280. Первым потенциально публичным раскрытием браузерного эксплойта, используемого в реальных условиях, стал эксплойт Aurora браузера Internet Explorer, который атаковал Google в декабре 2010 года.
У меня интерес к веб-браузерам возник в 2018 году, когда мой приятель Майкл Вебер познакомил меня с разработкой агрессивных браузерных расширений, открывшей мне глаза на поверхность потенциальных атак. После этого я начал глубже исследовать внутреннее устройство Chrome и крайне заинтересовался эксплойтами веб-браузеров. Потому что будем откровенны — какая Red Team не захочет иметь эксплойт веб-браузера, работающий «в один клик» или даже «без клика»?
В мире исследований безопасности браузеры считаются одними из самых впечатляющих целей для поиска уязвимостей. К сожалению, они же являются и одними из самых сложных для изучения, поскольку объём знаний, необходимых для того, чтобы хотя бы приступить к изучению внутренностей браузера, многим исследователям кажется неподъёмным.
Несмотря на это, я решил начать изучение, взявшись за потрясающий обучающий курс maxpl0it’s под названием "Introduction to Hard Target Internals". Крайне рекомендую тоже пройти его! Этот курс дал мне много информации о внутренней работе и устройстве браузеров наподобие Chrome и Firefox. После этого я начал сосредоточенно читать всё, что мог найти, от блогов по Chromium до постов разработчиков v8.
Так как в изучении я использую стиль «изучи сам, обучи других, пойми», то выпускаю эту серию постов «Эксплойтинг браузера Chrome», чтобы познакомить читателей с внутренностями браузеров и более глубоко изучить экслойтинг браузера Chrome в Windows, параллельно учась самостоятельно.
Вы можете задаться вопросом: почему Chrome и почему Windows? На то есть две причины:
- Chrome занял примерно 73% рынка, то есть является самым широко используемым браузером в мире.
- Windows имеет долю рынка примерно в 90%, то есть тоже является самой широко используемой операционной системой в мире.
Взявшись за исследование самого используемого ПО в мире, Red Team сильно увеличивает свои шансы находить баги, писать эксплойты и успешно их использовать.
ПРЕДУПРЕЖДЕНИЕ. Из-за огромной сложности браузеров, движков JavaScript и JIT-компиляторов эти посты будут очень сложны в освоении.
На текущий момент запланирована серия из трёх постов. Но в зависимости от сложности и объёма информации я могу разделить материал на несколько дополнительных постов.
Учтите, что я пишу эти посты в процессе изучения. Так что наберитесь терпения, возможно, для выпуска последующих постов потребуется какое-то время.
Кроме того, если вы заметите, что я допустил ошибку в постах или ввожу читателя в заблуждение, то свяжитесь со мной! Также приветствуются любые рекомендации, конструктивная критика, критические отзывы и так далее!
В целом, к концу этой серии постов мы раскроем всё, что необходимо знать для начала исследования и эксплойтинга потенциальных багов Chrome. В последнем посте серии мы попытаемся выполнить эксплойтинг CVE-2018-17463 — уязвимости JIT-компилятора в оптимизаторе Chrome v8 (TurboFan), обнаруженной Сэмюелом Гроссом.
Итак, давайте без лишних предисловий приступим к изучению сложного мира эксплойтинга браузеров!
В сегодняшнем посте мы раскроем базовые обязательные концепции, которые необходимо понимать, прежде чем мы двинемся глубже. Мы обсудим следующие темы:
- Поток исполнения движков JavaScript
- Конвейер компиляторов движков JavaScript
- Стековые и регистровые машины
- JavaScript и внутренности V8
- Описание объектов
- HiddenClass (Map)
- Переходы Shape (Map)
- Свойства
- Элементы и массивы
- Просмотр объектов Chrome в памяти
- Маркировка указателей
- Сжатие указателей
Но прежде чем приступить к изучению, вам нужно скомпилировать
v8 и d8 под Windows. Подробные инструкции о том, как это сделать, можно прочитать в моём gist "Building Chrome V8 on Windows".Поток исполнения движков JavaScript
Своё изучение внутренностей браузеров мы начнём с понимания того, что такое движки JavaScript и как они работают. Движки JavaScript — неотъемлемая часть выполнения JavaScript-кода. Раньше они были простыми интерпретаторами, но современные движки — это сложные программы, включающие в себя множество повышающих производительность компонентов, например, оптимизирующих компиляторов и компиляцию Just-In-Time (JIT).
На самом деле, сегодня используется множество различных движков JS, например:
- V8 — опенсорсный высокопроизводительный движок JavaScript и WebAssembly компании Google, используемый в Chrome.
- SpiderMonkey — движок JavaScript и WebAssembly Mozilla, используемый в Firefox.
- Chakra — проприетарный движок JScript, разработанный Microsoft для применения в IE и Edge.
- JavaScriptCore — встроенный движок JavaScript Apple для использования WebKit в Safari.
Так зачем же нам нужно использовать эти движки JavaScript и все их тонкости?
Как мы знаем, JavaScript — это легковесный интерпретируемый объектно-ориентированный скриптовый язык. В интерпретируемых языках код выполняется построчно, а результат выполнения кода мгновенно возвращается, чтобы нам не приходилось компилировать код в другой вид, прежде чем его выполнит браузер. Из-за такого подхода подобные языки имеют довольно низкую производительность. Именно поэтому используется компиляция наподобие компиляции Just-In-Time: код JavaScript парсится на байт-код (абстракцию машинного кода), а затем оптимизируется JIT, чтобы сделать код гораздо эффективнее и в той или иной мере «быстрее».
Хотя каждый из вышеупомянутых движков JavaScript имеет свои компиляторы и оптимизаторы, все они спроектированы и реализованы схожим образом на основе стандарта EcmaScript (который используется взаимозаменяемо с JavaScript). В спецификации EcmaScript подробно описано, как JavaScript должен быть реализован в браузере, чтобы программа на JavaScript выполнялась совершенно одинаково во всех браузерах.
Что же происходит после того, как мы исполним код на JavaScript? Чтобы подробно описать это, я начертил схему, в которой показано высокоуровневое описание общего «потока исполнения», также известного как конвейер компиляции движков JavaScript.
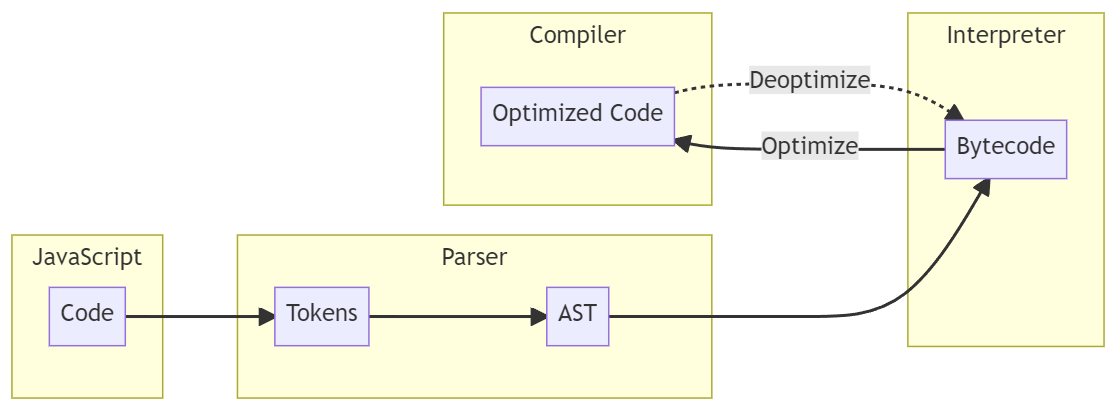
Поначалу схема может показаться непонятной, но не волнуйтесь, на самом деле, разобраться в ней не так сложно. Давайте пошагово разберём поток исполнения и объясним, что делает каждый из компонентов.
- Парсер: после исполнения JavaScript-кода, он передаётся в движок JavaScript и мы переходим на первый этап — парсинг кода. Парсер превращает код в следующие элементы:
- Токены: сначала код разбивается на «токены»: идентификаторы, числа, строки, операторы и так далее. Это называется «лексическим анализом» или «токенизацией».
- Пример:
var num = 42разбивается наvar,num,=,42, после чего каждый «токен» (элемент) маркируется своим типом, то есть в данном случае это будутKeyword,Identifier,Operator,Number.
- Пример:
- Абстрактное синтаксическое дерево (Abstract Syntax Tree, AST): после парсинга кода на токены парсер превращает эти токены в AST. Эта часть называется «анализом синтаксиса» и она оправдывает своё название: проверяет отсутствие синтаксических ошибок в коде.
- Для приведённого выше примера кода AST будет выглядеть так:
{ "type": "VariableDeclaration", "start": 0, "end": 13, "declarations": [ { "type": "VariableDeclarator", "start": 4, "end": 12, "id": { "type": "Identifier", "start": 4, "end": 7, "name": "num" }, "init": { "type": "Literal", "start": 10, "end": 12, "value": 42, "raw": "42" } } ], "kind": "var" }
- Для приведённого выше примера кода AST будет выглядеть так:
- Токены: сначала код разбивается на «токены»: идентификаторы, числа, строки, операторы и так далее. Это называется «лексическим анализом» или «токенизацией».
- Интерпретатор: после генерации дерева AST оно передаётся интерпретатору, который обходит AST и генерирует байт-код. После генерации байт-кода он исполняется, а AST удаляется.
- Список байт-кодов для V8 можно найти здесь.
- Пример байт-кода для
var num = 42;показан ниже:
LdaConstant [0] Star1 Mov <closure>, r2 CallRuntime [DeclareGlobals], r1-r2 LdaSmi [42] StaGlobal [1], [0] LdaUndefined Return
- Компилятор: компилятор действует заранее благодаря использованию профайлера, контролирующего и отслеживающего код, который должен быть оптимизирован. Если в коде есть «горячая функция», то компилятор берёт эту функцию и генерирует оптимизированный машинный код для исполнения. И наоборот, если он видит, что оптимизированная «горячая функция» больше не используется, он «деоптимизирует» её обратно в байт-код.
В JavaScript-движке от компании Google, который назвается V8, конвейер компиляции очень похож на данную схему. Однако в V8 есть дополнительный «неоптимизирующий» компилятор, который был добавлен только в 2021 году. Каждый компонент V8 имеет собственное имя:
- Ignition: быстрый низкоуровневый интерпретатор V8 на основе регистров, генерирующий байт-код.
- SparkPlug: новый неоптимизирующий компилятор JavaScript движка V8, выполняющий компиляцию из байт-кода итеративным обходом байт-кода и созданием машинного кода для каждого посещённого байт-кода.
- TurboFan: оптимизирующий компилятор V8, транслирующий байт-код в машинный код с дополнительными, более сложными оптимизациями кода. Также включает в себя компиляцию JIT (Just-In-Time).
В целом, конвейер компиляции V8 высокоуровнево выглядит так:

Не беспокойтесь, если часть этих понятий или функций наподобие «компиляторов» и «оптимизаций» вам пока непонятна. В рамках этого поста понимание всего конвейера компиляции не требуется, но нам нужно общее представление о том, как в целом работает движок. Подробнее конвейер V8 и его компоненты рассмотрим во втором посте.
Если вы хотите подробнее узнать о конвейере, рекомендую посмотреть видео "JavaScript Engines: The Good Parts".
Единственное, что вы должны понять на данном этапе: интерпретатор — это "стековая машина" или, по сути, VM (Virtual Machine, виртуальная машина), в которой выполняется байт-код. Что касается Ignition (интерпретатора V8), то на самом деле он является «регистровой машиной» с накопительным регистром. Ignition тоже использует стек, но для ускорения работы хранит всё в регистрах.
Чтобы лучше разобраться в этих понятиях, рекомендую прочитать "Understanding V8’s Bytecode" и "Firing up the Ignition Interpreter".
JavaScript и внутренности V8
Теперь, когда у нас есть базовое представление о структуре движка JavaScript и его конвейере компиляции, настало время углубиться во внутренности самого JavaScript и разобраться, как V8 хранит и описывает объекты JavaScript в памяти вместе с их значениями и свойствами.
Этот раздел — самый важный для понимания, если вы хотите использовать баги в V8 и других движках JavaScript, поскольку все популярные движки реализуют модель объектов JavaScript схожим образом.
Как мы знаем, JavaScript — это язык с динамической типизацией. Это значит, что информация о типах связана со значениями среды исполнения, а не с переменными этапа компиляции, как в C++. То есть свойства любого объекта JavaScript можно с лёгкостью изменять в среде исполнения. Система типов JavaScript определяет типы данных как Undefined, Null, Boolean, String, Symbol, Number и Object (в том числе массивы и функции).
Что же это значит, если не углубляться в подробности? В целом, это означает, что объект или примитив наподобие
var в JavaScript, в отличие от типов в C++, может менять свой тип данных во время исполнения. Например, зададим на JavaScript новую переменную с именем item и присвоим ей значение 42.var item = 42;Использовав оператор typeof для переменной
item, мы увидим, что он возвращает её тип, то есть Number.typeof item
'number'Что же произойдёт, если мы попробуем присвоить
item строке, а затем проверим её тип данных?item = "Hello!";
typeof item
'string'Посмотрите, теперь переменной
item задан тип данных String, а не Number. Именно это делает JavaScript «динамическим» по своей природе. Если бы мы создали на C++ int, или целочисленную переменную, а позже попытались присвоить ей значение string, этого не удалось бы сделать:int item = 3;
item = "Hello!"; // error: invalid conversion from 'const char*' to 'int'
// ^~~~~~~~Однако это удобство JavaScript создает для нас проблему. V8 и Ignition написаны на C++, поэтому интерпретатору и компилятору нужно разобраться, как JavaScript намеревается использовать свои данные. Это критически важно для эффективной компиляции кода, особенно потому что в C++ есть различия в размере памяти под такие типы данных, как
int или char.Наряду с эффективностью, это также критически важно для безопасности, поскольку если интерпретатор и компилятор «интерпретируют» код на JavaScript неверно, и мы получим объект-словарь вместо объекта-массива, то возникнет уязвимость Type Confusion.
Как же V8 хранит всю эту информацию с каждым значением среды исполнения, и как движок обеспечивает свою эффективность?
В V8 это достигается благодаря использованию специального объекта информационного типа под названием Map (не путать с Map Objects), также известного под именем "Hidden Class". Иногда Map ещё называют "Shape", особенно в движке JavaScript Mozilla под названием SpiderMonkey. V8 тоже использует нечто подобное под названием «сжатие указателей» (pointer compression) или «маркировка указателей» в памяти (подробнее о которой мы поговорим ниже), это позволяет V8 снизить потребление памяти и представить любое значение в памяти в виде указателя на объект.
Но прежде чем углубляться в то, как всё это функционирует, сначала нужно понять, что такое объекты JavaScript, и как они заданы внутри V8.
Описание объектов
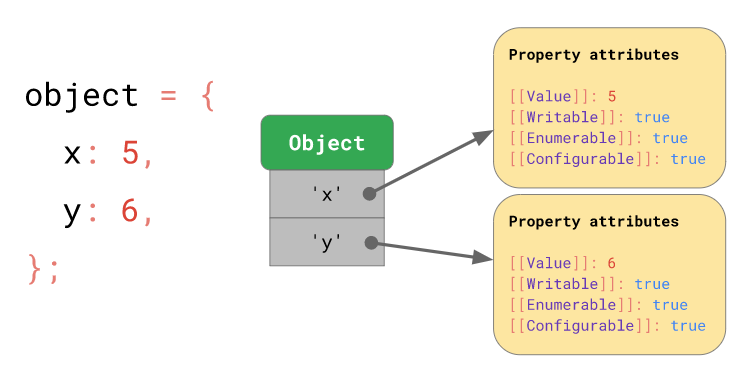
В JavaScript объекты, по сути, являются коллекцией свойств, хранящихся в виде пар «ключ-значение». Это значит, что объекты ведут себя подобно словарям. Объекты могут быть Array, Function, Boolean, RegExp и так далее.
С каждым объектом в JavaScript связаны свойства, которые можно описать как переменную, определяющую характеристику объекта. Например, новый объект
car может иметь такие свойства, как make, model и year, помогающие описать, чем является объект car. К свойствам объекта можно получить доступ при помощи простого оператора-точки наподобие objectName.propertyName или при помощи прямых скобок, например, objectName['propertyName'].Дополнительно свойство каждого объекта сопоставляется с атрибутами свойств, которые используются для описания и объяснения состояния свойств объектов. Пример того, как эти атрибуты свойств выглядят в объекте JavaScript, можно увидеть ниже.
Теперь, когда мы немного разобрались с тем, что же такое объект, нужно понять, как объект структурирован в памяти, и где он хранится.
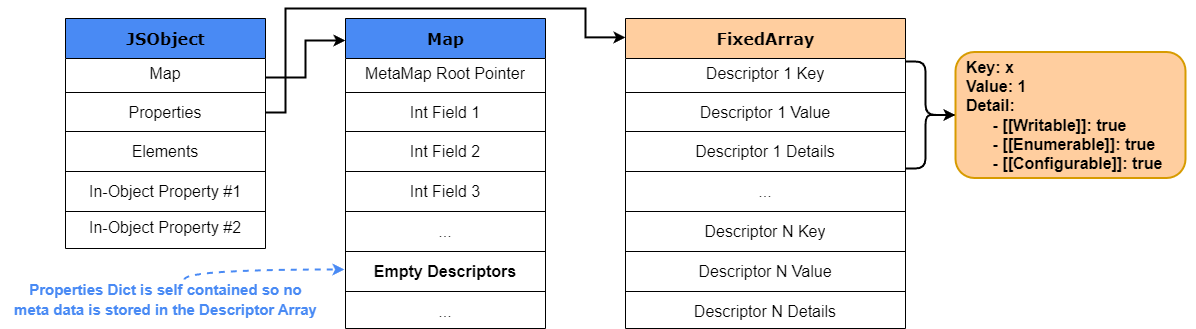
При создании объекта V8 создаёт новый JSObject и выделяет в куче память под него. Значение объекта является указателем на
JSObject, который содержит в своей структуре следующее:- Map: указатель на объект HiddenClass, в котором подробно описывается "shape", или структура объекта.
- Properties: указатель на объект, содержащий именованные свойства.
- Elements: указатель на объект, содержащий пронумерованные свойства.
- In-Object Properties: указатели на именованные свойства, определённые при инициализации объекта.
На изображении ниже показано, как структурирован в памяти базовый объект JSObject V8.

Взглянув на структуру JSObject, можно увидеть, что Properties и Elements хранятся в двух отдельных структурах данных
FixedArray, что повышает эффективность добавления свойств и доступа к ним. Структура элементов преимущественно хранит неотрицательные целые числа или свойства array-indexed properties (keys), более известные как элементы. Что касается структуры свойств, то если ключ-свойство это не неотрицательное целое число, а например, строка, то свойство будет храниться или как Inline-Object Property (объясняется ниже), или в структуре свойств, иногда также называемой objects properties backing store.Здесь стоит заметить, что хотя именованные свойства хранятся примерно так же как элементы в массиве, они неодинаковы с точки зрения доступа к свойствам. В отличие от ситуации с элементами, мы не можем просто использовать ключ для поиска позиции именованных свойств в массиве свойств; нам нужны дополнительные метаданные. Как говорилось выше, V8 использует специальный объект под названием
HiddenClass, или Map, связанный с каждым JSObject. Эта Map хранит всю информацию об объектах JavaScript, что, в свою очередь, позволяет V8 быть «динамическим».То есть, прежде чем углубляться в понимание структуры и свойств JSObject, нам нужно сначала понять, как этот HiddenClass работает в V8.
HiddenClass (Map) и переходы Shape
Как говорилось выше, мы знаем, что JavaScript — это язык с динамической типизацией. В частности, из-за этого в JavaScript отсутствует концепция классов. Если вы создаёте объект или класс в C++, то, в отличие от JavaScript, не можете добавлять или удалять методы и свойства на лету. В C++ и других объектно-ориентированных языках можно хранить свойства объектов в фиксированных смещениях памяти, поскольку структура объекта для экземпляра конкретного класса никогда не меняется, однако в JavaScript она может динамически меняться во время исполнения. Чтобы справляться с этим, JavaScript использует концепцию под названием "prototype-based-inheritance", в которой каждый объект имеет ссылку на прототип, или «shape», свойства которого он в себе содержит.
Как V8 хранит структуру объекта?
Здесь в дело вступает
HiddenClass, или Map. Hidden Class работают схоже с фиксированной структурой объекта, где значения свойств (или указатели на эти свойства) могут храниться в специфической структуре памяти, и доступ к ним может осуществляться благодаря фиксированному смещению между этими значениями/указателями. Эти смещения генерируются Torque и находятся внутри папки /torque-generated/src/objects/*.tq.inc в V8. Это фактически служит идентификатором «shape» объекта, что, в свою очередь, позволяет V8 лучше оптимизировать JavaScript-код и снизить время доступа к свойствам.Как было показано в примере с
JSObject, Map — это ещё одна структура данных внутри объекта. Эта структура Map содержит следующую информацию:- Динамический тип объекта, например, String, JSArray, HeapNumber и так далее.
- Типы объектов в V8 перечислены в
/src/objects/objects.h
- Типы объектов в V8 перечислены в
- Размер объекта (свойства внутри объекта и так далее)
- Свойства объекта и место их хранения
- Тип элементов массивов
- Прототип, или Shape объекта (если он существует)
Чтобы показать, как объект Map выглядит в памяти, я создал довольно подробную структуру Map движка V8. Дополнительную информацию о структурах можно найти в исходном коде V8, она находится в исходныхй файлах
/src/objects/map.h и /src/objects/descriptor-array.h.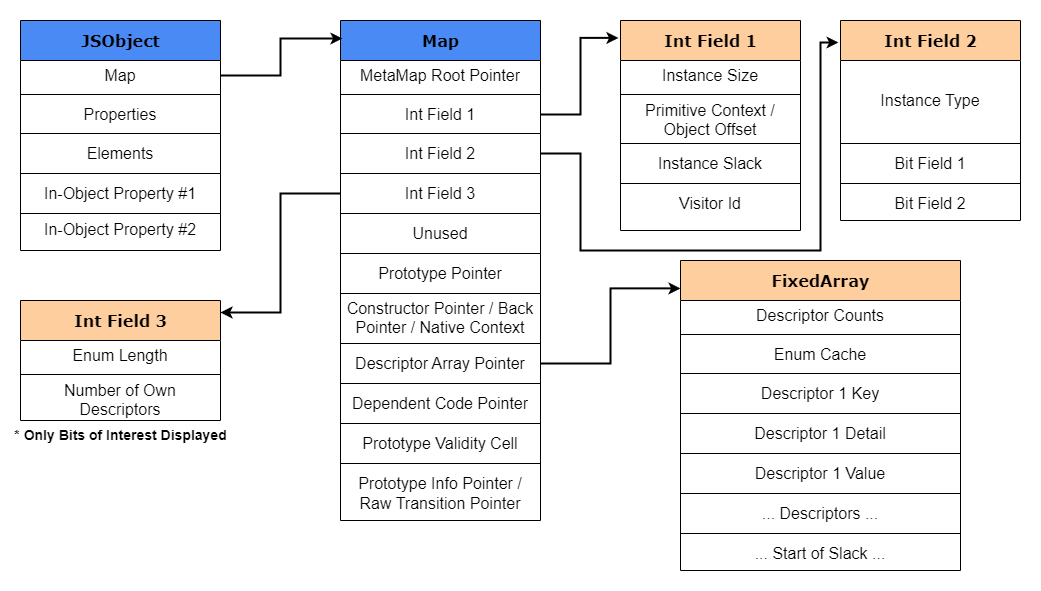
Теперь, когда мы знаем, как выглядит структура Map, давайте объясним, что такое «shape», о котором постоянно упоминаем. Как вы знаете, каждый только что созданный
JSObject будет иметь собственный HiddenClass, содержащий смещение в памяти для каждого из его свойств. И вот что интересно: при каждом динамическом создании, удалении или изменении свойства этого объекта создаётся новый HiddenClass. Этот новый HiddenClass хранит информацию о существующих свойствах, включая смещение в памяти для нового свойства. Следует учесть, что новый HiddenClass создаётся только при добавлении нового свойства, добавление индексированного свойства не создаёт новые HiddenClass.Как же это выглядит на практике? Для примера возьмём следующий код:
var obj1 = {};
obj1.x = 1;
obj1.y = 2;В начале мы создаём новый объект
obj1, создаваемый и сохраняемый в куче V8. Так как этот объект только что создан, мы должны создать HiddenClass, даже несмотря на то, что для этого объекта не задано никаких свойств. Этот HiddenClass тоже создаётся и хранится в куче V8. В нашем примере мы назовём этот исходный HiddenClass «C0».
После перехода к следующей строке кода и исполнения
obj1.x = 1 V8 создаёт второй HiddenClass с именем «C1», имеющий в своей основе C0. C1 будет первым HiddenClass, описывающим местоположение свойства x в памяти. Но вместо хранения указателя на значение для x он на самом деле будет хранить смещение для x, которое будет являться смещением 0.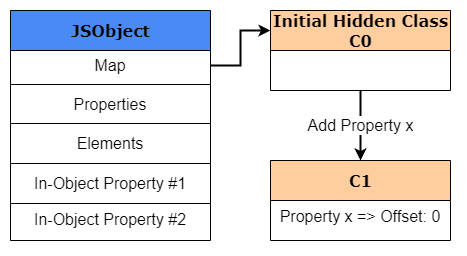
Я знаю, что теперь кто-то из вас просит: «почему смещение свойства, а не его значение?»
В V8 это трюк для оптимизации. Map — это довольно затратные объекты с точки зрения использования памяти. Если мы будем хранить пары свойств «ключ-значение» в формате словаря для каждого создаваемого
JSObject, то это приведёт к большим дополнительным вычислительным затратам, поскольку парсинг словарей выполняется медленно. Во-вторых, что произойдёт, если создать новый объект, например, obj2, который имеет общие с obj1 свойства x и y? Даже если значения могут быть одинаковыми, на самом деле два объекта получат одинаковые именованные свойства в одном порядке, в одной «форме» ("shape"). В таком случае было бы слишком затратно хранить одно имя свойства в двух разных местах.Именно это позволяет V8 быть быстрым: он оптимизирован так, чтобы Map была как можно более общей для схожих по «форме» объектов. Поскольку все имена свойств повторяются для всех объектов одного shape и поскольку они находятся в одном порядке, можно иметь множество объектов, указывающих на один HiddenClass в памяти со смещением для свойств вместо указателей на значения. Также это упрощает сборку мусора, поскольку Map являются распределениями
HeapObject, как и JSObject.Чтобы лучше объяснить эту концепцию, давайте на минуту отойдём от примера выше и рассмотрим важные части HiddenClass. Двумя самыми важными частями HiddenClass, позволяющими Map иметь свой «shape», являются DescriptorArray и третье битовое поле. Если вернуться к изображению структуры Map, можно заметить, что третье битовое поле (bit field) хранит количество свойств, а descriptor array содержит информацию об именованных свойствах: имя, позицию, где хранится значение (смещение) и атрибуты свойств.
Допустим, мы создаём новый объект, например
var obj {x: 1}. Свойство x будет храниться внутри свойств In-Object или в Properties store объекта JavaScript. Так как создан новый объект, также будет создан новый HiddenClass. В этом HiddenClass будут заполнены descriptor array и третье битовое поле. В третьем битовом поле numberOfOwnDescriptors присваивается значение 1, поскольку у нас есть только одно свойство. После этого descriptor array заполнит части массива key, details и value информацией, относящейся к свойству x. Этому дескриптору будет присвоено значение 0. Почему 0? Свойства In-Object и Properties store — это просто массив. Поэтому присвоив дескриптору значение 0, V8 будет знать, что значение ключей находится в смещении 0 этого массива для любого объекта с таким же shape.Визуальное объяснение этого показано ниже.
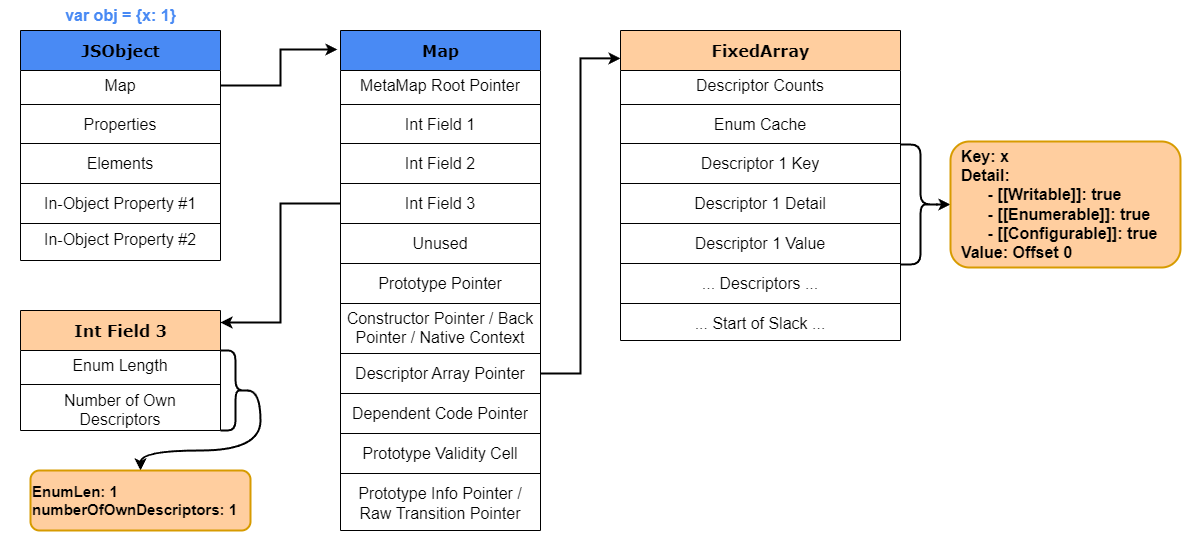
Давайте посмотрим, как это выглядит внутри V8. Для начала запустим
d8 с параметром --allow-natives-syntax и исполним следующий код на JavaScript:d8> var obj1 = {a: 1, b: 2, c: 3}Затем воспользуемся командой
%DebugPrint() для нашего объекта, чтобы отобразить его свойства, map и другую информацию, например, дескриптор экземпляра. После исполнения обратите внимание на следующее: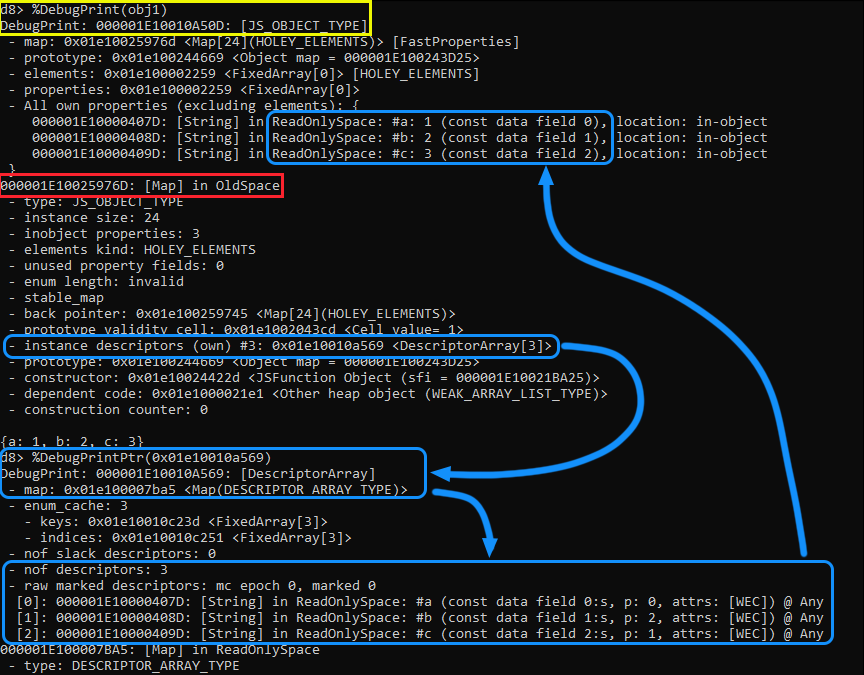
Жёлтым выделен объект
obj1. Красным выделен указатель на наш HiddenClass или Map. В этом HiddenClass мы видим дескриптор экземпляра, указывающий на DescriptorArray. Применив функцию %DebugPrintPtr() к указателю на этот массив, мы можем увидеть больше подробностей о том, как этот массив выглядит в памяти. Они выделены голубым.Обратите внимание, у нас есть три свойства, соответствующих количеству дескрипторов в разделе дескрипторов экземпляра map. Ниже мы видим, что массив дескрипторов (descriptor array) содержит ключи свойств, а
const data field содержит смещения к их соответствующим значениям в property store. Если мы пройдём по стрелке обратно от смещений к объектам, то заметим, что смещения совпадают, а каждому свойству назначено своё верное значение.Также обратите внимание, что справа от этих свойств указано местоположение каждого из этих свойств; как говорилось выше, они in-object. Это доказывает, что смещения используются для свойств в In-Object и Properties store.
Итак, мы разобрались, зачем используются смещения. Теперь вернёмся к ранее приведённому примеру с HiddenClass. Как говорилось ранее, при добавлении свойства
x к obj1 создаётся новый HiddenClass с именем «C1» и смещением для x. Так как мы создаём новый HiddenClass, V8 обновит C0 при помощи «перехода класса» (class transition), заявляющего, что если создаётся новый объект со свойством x, то HiddenClass должен переключаться непосредственно на C1.Затем, когда мы выполняем
obj1.y = 2, процесс повторяется. Создаётся новый HiddenClass с именем C2, и к C1 добавляется переход класса, заявляющий, что для любого объекта со свойством x, если добавляется свойство y, то HiddenClass должен выполнять переход к C2. В конечном итоге, все эти переходы классов формируют структуру под названием «дерево переходов» (transition tree).
Стоит заметить, что переходы классов зависят от порядка, в котором к объекту добавляются свойства. То есть в случае, когда после y добавляется z, «shape» больше не будет таким же и не будет следовать по тому же пути переходов от C1 к C2. Вместо этого будет создан новый HiddenClass и для учёта этого нового свойства от C1 будет добавлен новый путь перехода, ещё больше расширяющий дерево переходов.
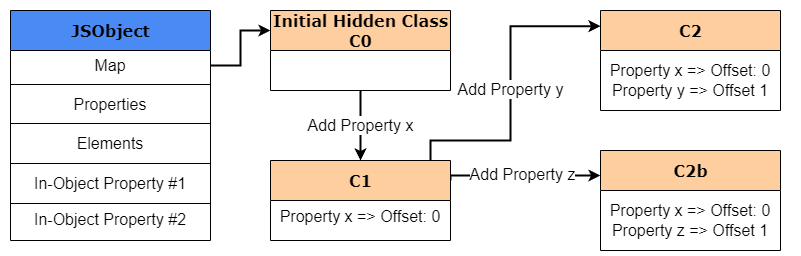
Разобравшись с этим, давайте посмотрим, как объекты выглядят в памяти, когда Map является общей для двух объектов с одинаковым shape.
Для начала снова запустим
d8 с параметром --allow-natives-syntax, а затем введём две следующие строки кода на JavaScript:d8> var obj1 = {x: 1, y: 2};
d8> var obj2 = {x: 2, y: 3};После завершения снова воспользуемся командой
%DebugPrint() для обоих объектов, чтобы посмотреть их свойства, map и другую информацию. После выполнения обратите внимание на следующее: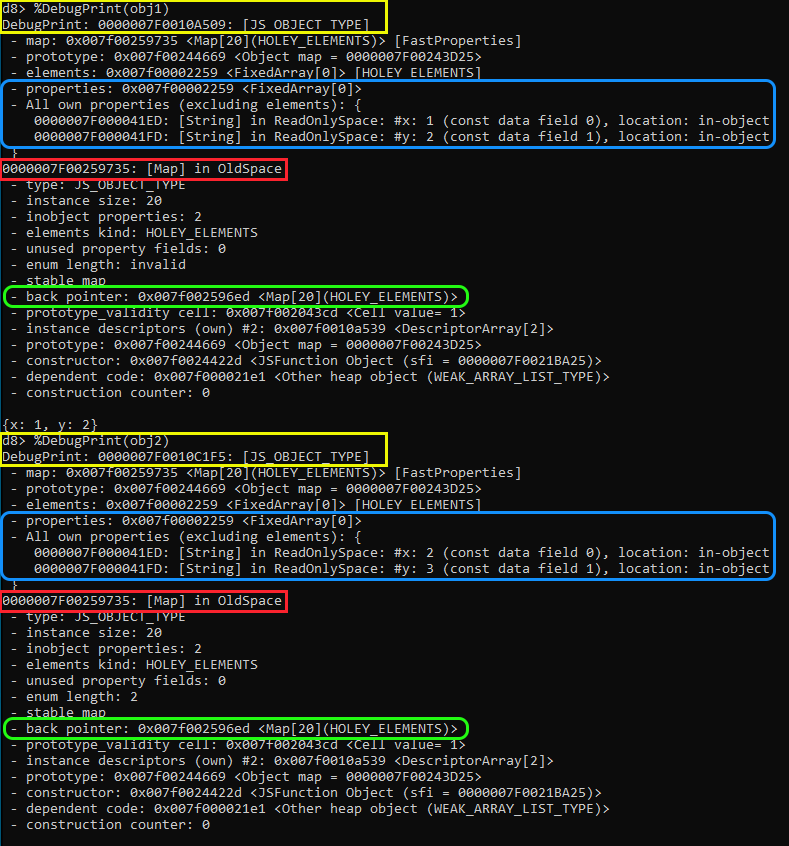
Жёлтым выделены оба объекта,
obj1 и obj2. Обратите внимание, что каждый является JS_OBJECT_TYPE со своим адресом памяти в куче. поскольку, очевидно, это отдельные объекты с потенциально разными свойствами.Как мы знаем, оба этих объекта имеют одинаковый shape, поскольку оба содержат x и y в одинаковом порядке. В данном случае синим показано то, что свойства находятся в одном
FixedArray, а смещения для x и y имеют значения 0 и 1. Так получилось, поскольку, как мы уже знаем, объекты с одинаковым shape имеют общий HiddenClass (выделенный красным), который имеет один descriptor array.Как видите, большинство свойств объекта и адресов Map будут одинаковыми, потому что оба этих объекта имеют общую Map.
Теперь взглянем на
back_pointer, выделенный зелёным цветом. Если посмотреть на пример перехода Map от C0 к C2, то можно заметить, что мы упоминали нечто под названием «дерево переходов». Это дерево переходов создаётся V8 в фоновом режиме при каждом создании нового HiddenClass; оно позволяет V8 связывать старые и новые HiddenClass. Этот back_pointer является частью дерева переходов и указывает на родительскую map, от которой был выполнен переход. Это позволяет V8 проходить по цепочке обратных указателей (back pointer), пока он не найдёт map, содержащую свойства объектов, то есть их shape.Давайте воспользуемся
d8, чтобы глубже изучить, как это происходит. Мы снова применим команду %DebugPrintPtr() для вывода подробностей об указателе адреса в V8. В данном случае мы используем адрес back_pointer, чтобы узнать подробности о нём. После выполнения команды результат у вас должен оказаться схожим с моим.
Зелёным выделено то, что
back_pointer резолвится в памяти в JS_OBJECT_TYPE, который на самом деле оказывается Map! Это та map C1, о которой мы говорили ранее. Мы знаем, что Map находит свою предыдущую Map, но как она знает, к какой Map переходить при добавлении свойства? Если внимательно изучить информацию внутри Map, то можно заметить, что под указателем дескриптора экземпляра есть раздел «transitions», выделенный красным цветом. В этом разделе переходов содержится информация, на которую указывает Raw Transition Pointer в структуре Map.В V8 переходы Map используют концепцию под названием TransitionsAccessor. Это вспомогательный класс, инкапсулирующий доступ к различным способам, которыми Map может хранить переходы к другим map в своём соответствующем поле
Map::kTransitionsOrPrototypeInfo, также известном как вышеупомянутый Raw Transition Pointer. Этот указатель указывает на нечто под названием TransitionArray, который опять-таки является FixedArray, содержащим переходы map для изменений свойств.Взглянув на выделенный красным раздел, мы видим, что в этом массиве переходов только один переход. В этом массиве мы видим, что переход 1 описывает переход для того момента, когда к объекту добавляется свойство y. При добавлении y он приказывает map обновиться при помощи map, хранящейся в
0x007f00259735, что соответствует нашей текущей map! Если бы существовал другой переход, например вместо y к x добавлялась z, то в этом массиве переходов было бы два элемента, каждый из которых указывал бы на соответствующую map для shape этого объекта.ПРИМЕЧАНИЕ: если вы хотите поэкспериментировать с Map и посмотреть другие визуальные описания переходов Map, то рекомендую использовать инструмент Indicium движка V8. Этот инструмент представляет собой унифицированный веб-интерфейс, позволяющий трассировать, отлаживать и анализировать паттерны создания и изменения Map в реальных приложениях.
Что же произойдёт с деревом переходов, если мы удалим свойство? При каждом удалении свойства движок V8 создаёт новую map особым образом. Как мы знаем, map довольно затратны с точки зрения использования памяти, поэтому на определённом этапе затраты на наследование и содержание дерева переходов становятся всё больше, а система начинает работать всё медленнее. В случае удаления последнего свойства объекта Map просто изменяет обратный указатель так, чтобы он возвращал к своей предыдущей map, а не создавал новую. Но что произойдёт, если мы удалим среднее свойство объекта?
Если мы добавляем слишком много атрибутов или удаляем не последние элементы, V8 перестанет поддерживать дерево переходов и переключается на более медленный режим, называющийся словарным режимом (dictionary mode).
Что же такое словарный режим? Теперь, когда мы знаем, что для отслеживания shape объектов V8 использует HiddenClass, мы можем совершить полный круг и углубиться в понимание того, как эти свойства и элементы хранятся и обрабатываются в V8.
Свойства
Как объяснялось ранее, объекты JavaScript имеют два фундаментальных вида свойств: именованные свойства и индексированные элементы. Мы начнём с описания именованных свойств.
При обсуждении Map и Descriptor Array мы упоминали, что именованные свойства хранятся или In-Object, или внутри массива свойств. Что это за In-Object Property, о котором мы говорим?
В V8 это режим хранения свойств непосредственно в объекте. Поскольку доступ к ним возможен без всяких обходных путей, режим очень быстрый. Впрочем, он все еще ограничен исходным размером объекта. Если добавляется больше свойств, чем есть места в объекте, то новые свойства сохраняются внутри properties store.
В целом, движки JavaScript используют для хранения свойств два «режима»:
- Fast Properties: обычно применяется для определения свойств, хранящихся в линейном properties store. Доступ к этим свойствам выполняется просто по индексу в properties store с отсылкой к массиву Descriptor Array в HiddenClass.
- Slow Properties: этот режим, также известный как «словарный», применяется, когда добавляется или удаляется слишком много свойств, что приводит к чрезмерным тратам памяти. В результате этого объект со slow properties («медленными свойствами») получит в качестве properties store автономный словарь. Метаинформация всех свойств далее хранится не внутри Descriptor Array в HiddenClass, а непосредственно в словаре свойств. Для доступа к этим свойствам в дальнейшем V8 использует хэш-таблицу.
Пример того, как выглядит Map при переходе к slow properties с автономным словарём, показан ниже.
Здесь стоит упомянуть один аспект. Переходы shape работают только для fast properties, но не для slow properties, ведь словарные shape используются только одним объектом, поэтому они не могут быть общими для нескольких объектов, а следовательно, не имеют и переходов.
Элементы
Итак, мы уже практически разобрались с именованными свойствами. Теперь давайте взглянем на индексированные свойства, или элементы. Можно подумать, что работа с индексированными свойствами будет проще… однако это заблуждение. Обработка элементов не менее сложна, чем именованных свойств. Даже несмотря на то, что все индексированные свойства хранятся в elements store, V8 очень чётко различает, какие типы элементов могут храниться в каждом из массивов. На самом деле в этом хранилище может отслеживаться примерно 21 тип элементов! Это позволяет V8 оптимизировать операции с массивом под конкретный тип элемента.
Как это понимать? Давайте для примера рассмотрим следующую строку кода:
const array = [1,2,3];Если мы выполним в JavaScript операцию typeof для этого элемента, то она сообщит, что массив содержит
number, поскольку JavaScript не делает разницы между integer, float и double. Однако V8 учитывает гораздо более тонкие различия и классифицирует этот массив как PACKED_SMI_ELEMENTS, где SMI расшифровывается как Small Integers.Что же такое SMI? V8 отслеживает то, какой тип элементов содержится в каждом массиве. Он использует эту информацию для оптимизации операций с массивом под этот тип элемента. В V8 есть три типа элементов, о которых нам нужно знать:
SMI_ELEMENTS— используется для описания массива, содержащего маленькие целые числа, например, 1,2,3 и так далее.DOUBLE_ELEMENTS— используется для описания массива, содержащего числа с плавающей запятой, например, 4.5, 5.5 и так далее.ELEMENTS— используется для описания массива, содержащего строковые литеральные элементы или значения, которые нельзя представить в виде SMI или Double, например, «x».
Как V8 использует эти типы элементов для массива? Они задаются для массива или для каждого элемента? Ответ: тип элементов задаётся для массива. Здесь важно запомнить, что эти типы элементов имеют «переход», идущий только в одном направлении. Это дерево переходов «сверху вниз» можно рассматривать так:
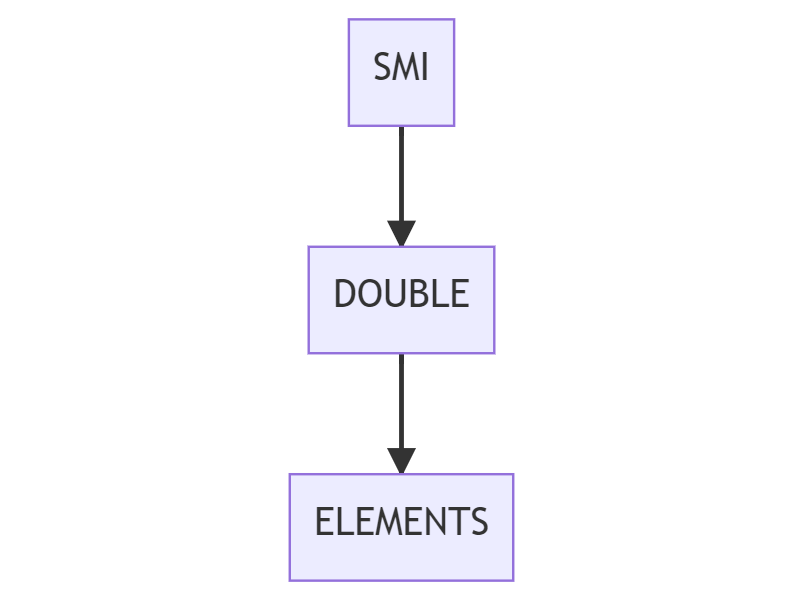
Давайте вернёмся к рассмотренному ранее примеру массива:
const array = [1,2,3];
// Тип элементов: PACKED_SMI_ELEMENTSКак видите, V8 отслеживает тип элементов этого массива как упакованные SMI (подробнее об упаковке мы поговорим ниже). Если бы мы добавили число с плавающей запятой, то тип элементов массива «перешёл» в тип элементов Double.
const array = [1,2,3];
// Тип элементов: PACKED_SMI_ELEMENTS
array.push(3.337)
// Тип элементов: PACKED_DOUBLE_ELEMENTSПричина перехода проста: оптимизация операций. Так как у нас есть целые числа и числа с плавающей запятой, движку V8 необходимо иметь возможность выполнять оптимизации с этими значениями, поэтому он выполняет переход к
DOUBLE. Ведь множество чисел, которое можно представить как SMI — это подмножество чисел, которые можно представить как double.Так как переход типов элементов выполняется в одном направлении, после того, как массив будет помечен более низким типом элементов, например,
PACKED_DOUBLE_ELEMENTS, он больше не сможет вернуться «наверх» к PACKED_SMI_ELEMENTS, даже если мы заменим или удалим это число с плавающей запятой. В общем случае, чем более конкретен тип элементов, создаваемых в массиве, тем более гибкие оптимизации доступны. Чем ниже мы спускаемся по типам элементов, тем медленнее становятся манипуляции с этим объектом.Далее нам нужно понять первую особенность, V8 проявляющуюся, когда он отслеживает вспомогательные хранилища элементов, когда индекс удаляется или пуст. Она заключается в следующем:
PACKED— используется для обозначения сплошных массивов, то есть таких, где заполнены все доступные элементы массива.HOLEY— используется для обозначения массивов, имеющих «дырки», например, когда индексированный элемент удаляется или не определён. Также это называется превращением массива в «разреженный».
Например, возьмём два таких массива:
const packed_array = [1,2,3,5.5,'x'];
// Тип элементов: PACKED_ELEMENTS
const holey_array = [1,2,,5,'x'];
// Тип элементов: HOLEY_ELEMENTSКак видите,
holey_array содержит «дырки», поскольку мы забыли добавить в индекс 3 и оставили его пустым или неопределённым. V8 учитывает это различие потому, что операции с упакованными массивами можно оптимизировать агрессивнее, чем операции с разреженными. Если вы хотите узнать об этом подробнее, рекомендую посмотреть доклад Матиаса Биненса "V8 internals for JavaScript Developers", в которой эта тема раскрывается очень хорошо.Кроме того, V8 реализует вышеупомянутые переходы типов элементов с массивами
PACKED и HOLEY, образуя «сетку». Ниже показана простая визуализация таких переходов из блога V8.
Мы опять-таки должны помнить о том, что типы элементов выполняют через эту сетку односторонние переходы вниз. При добавлении числа с плавающей запятой к массиву SMI он будет помечен как double. Аналогично, при создании в массиве «дырки» он навечно помечается как разреженный, даже если в дальнейшем его заполнить.
V8 также имеет вторую особенность, важное различие между элементами, которое нужно понять. Во вспомогательных хранилищах элементов, как и в properties store, элементы тоже могут быть в быстром или словарном (медленном) режиме. Быстрые элементы — это просто массив, в котором индекс свойства сопоставляется со смещением элемента в хранилище элементов. Медленные элементы появляются только при наличии больших разреженных массивов, в которых занято только несколько элементов. В таком случае вспомогательное хранилище массива использует словарное описание, которое мы видели в properties store, чтобы экономить память ценой производительности. Этот словарь хранит в словарных триплет-значениях ключ, значение и атрибуты элемента.
Просмотр объектов Chrome в памяти
Мы уже рассмотрели множество сложных тем о внутреннем устройстве JavaScript и V8. Надеюсь, на этом этапе у вас уже есть достаточное понимание того, как работает V8. Теперь, когда у нас есть эти знания, настало время понаблюдать, как V8 и его объекты выглядят в памяти при изучении через WinDBG, и какие виды оптимизаций используются.
Мы используем WinDBG потому, что будем писать эксплойты, отлаживать свой POC и так далее, и при этом в основном будем пользоваться WinDBG в сочетании с d8. Поэтому нам нужно понимать нюансы структуры памяти V8. Если вы незнакомы с WinDBG, то рекомендую вам прочитать и усвоить пост "Getting Started with WinDbg (User-Mode)" компании Microsoft, а также "команды GDB для пользователей WinDbg", если вы ранее пользовались GDB.
Мы уже изучали структуры памяти объектов и map, а также экспериментировали с d8, поэтому у вас должно быть общее представление о том, что куда указывает и где находится в памяти. Но не обольщайтесь, всё будет не так просто. Оптимизации играют важную роль в обеспечении скорости и эффективности V8; то же самое относится и к обработке и хранению значений в памяти.
Что это значит? Давайте при помощи d8 и WinDBG вкратце рассмотрим структуру простого объекта V8. Для начала снова инициируем d8 с опцией
--allow-natives-syntax и создадим простой объект:d8> var obj = {x:1, y:2}После этого давайте воспользуемся функцией
%DebugPrint() для вывода информации об объекте.d8> var obj = {x:1, y:2};
d8> %DebugPrint(obj)
DebugPrint: 000002530010A509: [JS_OBJECT_TYPE]
- map: 0x025300259735 <Map[20](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x025300244669 <Object map = 0000025300243D25>
- elements: 0x025300002259 <FixedArray[0]> [HOLEY_ELEMENTS]
- properties: 0x025300002259 <FixedArray[0]>
- All own properties (excluding elements): {
00000253000041ED: [String] in ReadOnlySpace: #x: 1 (const data field 0), location: in-object
00000253000041FD: [String] in ReadOnlySpace: #y: 2 (const data field 1), location: in-object
}
0000025300259735: [Map] in OldSpace
- type: JS_OBJECT_TYPE
- instance size: 20
- inobject properties: 2
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x0253002596ed <Map[20](HOLEY_ELEMENTS)>
- prototype_validity cell: 0x0253002043cd <Cell value= 1>
- instance descriptors (own) #2: 0x02530010a539 <DescriptorArray[2]>
- prototype: 0x025300244669 <Object map = 0000025300243D25>
- constructor: 0x02530024422d <JSFunction Object (sfi = 000002530021BA25)>
- dependent code: 0x0253000021e1 <Other heap object (WEAK_ARRAY_LIST_TYPE)>
- construction counter: 0Далее запустим WinDBG и прикрепим его к процессу d8. После подключения отладчика мы исполним команду dq, за которой следует адрес в памяти нашего объекта (
0x0000020C0010A509) для отображения содержимого его памяти. Ваши результаты должны быть очень похожи на мои.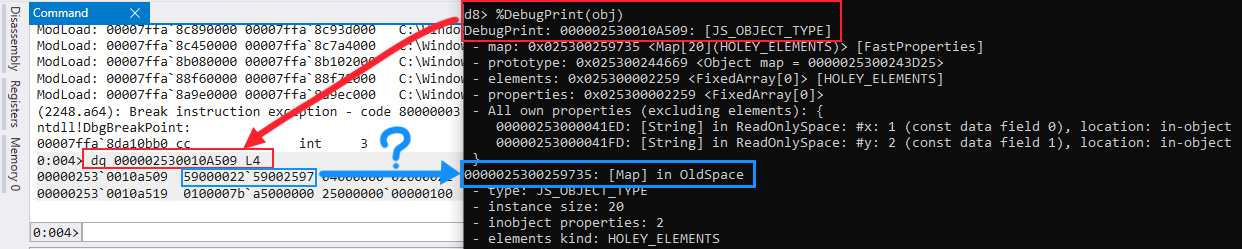
Изучив вывод WinDBG, мы увидим, что используем правильный адрес памяти для объекта. Но когда мы взглянем на содержимое памяти, то первый адрес (который должен быть указателем на map — вспомните структуру JSObject) покажется повреждённым. Точнее, кто-то может подумать, что он повреждён, однако более опытные реверс-инженеры или создатели эксплойтов могут даже подумать, что это проблема смещения/выравнивания, что с технической точки зрения близко, но неверно.
Это снова работа оптимизаций V8. Вы уже понимаете, почему нам нужно обсудить эти оптимизации: неопытный глаз серьёзно запутается из-за того, что происходит в памяти. На самом, деле мы видим два явления — сжатие указателей (Pointer Compression) и маркировку указателей (Pointer Tagging).
Начнём с того, что разберёмся в маркировке указателей или значений в V8.
Маркировка указателей
Что же такое маркировка указателей и почему мы её используем? Как известно, в V8 значения представлены как объекты и распределяются в куче, вне зависимости от того, являются ли они объектом, массивом, числом или строкой. Многие программы на JavaScript на самом деле выполняют вычисления с целочисленными значениями. Если бы нам постоянно нужно было создавать в JavaScript новый объект
Number() каждый раз, когда мы выполняем инкремент или изменение значения, то мы бы тратили лишнее время на создание объекта и отслеживание кучи; к тому же это увеличивает используемое пространство в памяти, поэтому этот подход очень неэффективен.В таком случае V8 поступает так: вместо создания постоянного создания новых объектов он на самом деле хранит некоторые значения, встраивая их. Это работает, однако создаёт вторую проблему: как отличить указатель на объект от встроенного значения? Именно здесь на помощь приходит маркировка указателей.
Техника маркировки указателей основана на том факте, что в системах x32 и x64 распределённые данные должны быть выровнены в границах слова (4 байтов). Так как данные выровнены таким образом, младшие биты (least significant bits, LSB) всегда будут равны нулю. Маркировка использует два нижних, или младших бита, чтобы различать указатель на объект в куче и integer или SMI.
В архитектуре x64 используется следующая схема маркировки:
|----- 32 bits -----|----- 32 bits -------|
Pointer: |________________address______________(w1)|
Smi: |____int32_value____|000000000000000000(0)|Как видно из примера, 0 используется для обозначения SMI, а 1 — для обозначения указателя. При изучении памяти SMI стоит также заметить, что при встроенном хранении они на самом деле удваиваются, чтобы избежать маркировки указателя. То есть если исходное значение равно 1, в памяти оно будет храниться как 2.
Внутри указателя также есть w во втором LSB, обозначающий бит, используемый для различения ссылки на сильный и слабый указатель. Если вы не знаете, что такое сильные и слабые указатели, то я объясню. Сильный указатель — это указатель, обозначающий, что объект, на который указывают, должен оставаться в памяти (он представляет объект), а слабый указатель — это указатель, просто указывающий на данные, которые могут быть удалены. Когда сборщик мусора (GC) удаляет объект, он должен удалить и сильный указатель, поскольку он содержит счётчик ссылок.
При такой схеме маркировки указателей арифметические и двоичные операции с целыми числами могут игнорировать маркировку, поскольку нижние 32 бита будут одними нулями. Однако при разыменовании HeapObject движок V8 сначала должен маскировать самый младший бит. Для этого используется специальный метод доступа, занимающийся очисткой LSB.
Зная об этом, давайте теперь вернёмся к нашему примеру в WinDBG и сбросим этот LSB вычитанием 1 из адреса. Таким образом мы должны получить действительный адрес в памяти. После этого результат должен выглядеть так:

Как видите, после сброса LSB мы получаем действительные адреса указателей в памяти! В частности, у нас есть map, свойства, элементы и встроенные объекты. Снова обратите внимание на то, что SMI удвоены, то есть x, содержащий 1, на самом деле в памяти имеет значение 2, то же справедливо для значения 2, которое теперь равно 4.
Внимательные читатели могли заметить, что на объект в памяти на самом деле указывает только половина указателя. Почему так получилось? Если вы скажете «ещё одна оптимизация», то не ошибётесь. Эта концепция называется сжатием указателей (Pointer Compression), о ней мы сейчас и поговорим.
Сжатие указателей
Сжатие указателей в Chrome и V8 использует интересное свойство объектов в куче: объекты кучи обычно находятся близко друг к другу, поэтому самые старшие биты указателя, скорее всего, будут одинаковыми. В таком случае V8 сохраняет в память только половину указателя (самые младшие биты) и помещает старшие биты (32 верхних бита) кучи V8 (известные как isolate root) в корневой регистр (R13). Когда нам нужно выполнить доступ к указателю, регистр и значение в памяти просто складываются и мы получаем полный адрес. Эта схема сжатия реализована в файле исходников
/src/common/ptr-compr-inl.h движка V8.По сути, команда разработчиков V8 стремилась засунуть оба типа маркированных значений в 32 бита на 64-битной архитектуре, специально для того, чтобы уменьшить трату ресурсов в V8, пытаясь вернуть как можно больше впустую тратящихся 4 байтов в архитектуре x64.
В заключение
И на этом наше глубокое изучение внутренностей JavaScript и V8 завершается! Надеюсь, вам понравился этот пост, и он помог разобраться в тонкостях V8.
Я знаю, что мы рассмотрели множество разных тем, и поначалу они кажутся очень сложными, поэтому уделите время внимательному прочтению и выработайте понимание базовых концепций, ведь прежде чем мы научимся всё это эксплойтить, вам понадобится понимать, как это работает изнутри. Помните: чтобы знать, как что-то сломать, нужно сначала понять, как это работает.
Во второй части серии постов мы вернёмся к более глубокому пониманию конвейера компиляции и объясним, что происходит внутри Ignition, Spark-Plug и TurboFan. Также мы подробнее рассмотрим JIT-компилятор, speculative guards, оптимизации, допущения и многое другое, что позволит нам лучше понимать распространённые уязвимости движков JavaScript наподобие type confusion.
Благодарности
Хочу от всего сердца поблагодарить maxpl0it и Fletcher за вычитку поста, критические отзывы и добавление нескольких важных деталей перед публикацией. Ребята, спасибо за то, что потратили своё время на проверку точности и читаемости этого поста!
Ссылки
- Attacking JavaScript Engines — A Case Study of JavaScriptCore and CVE-2016-4622
- A Tale of Types, Classes, and Maps by Benedikt Meurer
- A tour of V8: Object Representation
- Exploiting Logic Bugs in JavaScript JIT Engines
- Fast properties in V8
- How is Data Stored in V8 JS Engine Memory
- JavaScript Engine fundamentals: Shapes and Inline Caches
- JavaScript Engines Hidden Classes
- Javascript Hidden Classes and Inline Caching in V8
- Juicing V8: A Primary Account for the Memory Forensics of the V8 JavaScript Engine
- Learning V8
- Mathias Bynens — V8 Internals for JavaScript Developers
- Pointer Compression in V8
- SMIs and Doubles
- V8 / Chrome Architecture Reading List — For Vulnerability Researchers
- V8 Dev Blog
- V8 Engine JSObject Structure Analysis and Memory Optimization Ideas
- V8 Hidden Class
