

PostgreSQL и Redis — распространенные СУБД, которые «обросли» аудиторией. Их популярность варьируется от задачи к задаче, а сами они имеют свои сильные и слабые стороны.
Нашим клиентам бесплатно на тест доступны PostgreSQL и Redis по модели DBaaS, поэтому мы решили подробнее рассмотреть эти инструменты с точки зрения надежности, производительности и простоты настройки, а также обсудить тематические кейсы.
Левый угол: Redis

Производительность
Redis (REmote DIctionary Server) хранит данные в памяти, поэтому не обращается к жестким дискам или твердотельным накопителям, как традиционные СУБД. На скорость работы также влияет поддержка асинхронной репликации. Так, запросы к данным обрабатывают сразу несколько серверов, что ускоряет чтение.
В целом производительность Redis неоспоримо выше, по сравнению с той же PostgreSQL. Особенно ярко это проявляется при обработке больших объёмов данных JSON (их еще называют blobs).
На практике можно встретить кейсы, когда скорость чтения и записи Redis превышает возможности PostgreSQL в 16–20 раз.
Разберем на следующем примере.
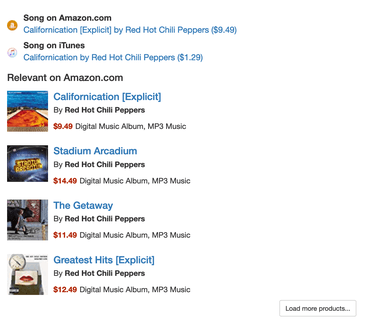
В сервисе поиска песен Song Search после каждой найденной композиции загружаются партнерские ссылки на Amazon.com. Чтобы не перегружать Amazon Affiliate Product API, результаты поиска сохраняются вместе с некоторыми метаданными в локальной базе данных. Когда кто-то в следующий раз просматривает страницу с песней, он может прочитать ее из этой базы.
Однако хранить эти данные локально слишком долго нельзя, поскольку цены и другая информация меняются. Поэтому через несколько сотен дней данные удаляются и обновляются. Модель (PostgreSQL через Django ORM) выглядит следующим образом:
class AmazonAffiliateLookup(models.Model, TotalCountMixin):
song = models.ForeignKey(Song, on_delete=models.CASCADE)
matches = JSONField(null=True)
search_index = models.CharField(max_length=100, null=True)
lookup_seconds = models.FloatField(null=True)
created = models.DateTimeField(auto_now_add=True, db_index=True)
modified = models.DateTimeField(auto_now=True)
А что будет, если использовать для этих целей Redis? Тогда возможно установить время истечения срока действия при хранении и не беспокоиться об очистке старой информации.
Настроим Redis следующим образом:
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": REDIS_URL,
"TIMEOUT": config("CACHE_TIMEOUT", 500),
"KEY_PREFIX": config("CACHE_KEY_PREFIX", ""),
"OPTIONS": {
"COMPRESSOR": "django_redis.compressors.zlib.ZlibCompressor",
"SERIALIZER": "django_redis.serializers.msgpack.MSGPackSerializer",
},
}
}
Сравнивая скорость чтения (Postgres 11.4 и Redis 3.2.1), автор установил, что Redis в 16 раз быстрее, чем PostgreSQL, при чтении больших двоичных объектов JSON.
В то же время Redis поддерживает широкий свод типов данных. Это — списки, наборы, строки, упорядоченные множества, а также хэши. Последние позволяют СУБД хранить и обрабатывать миллионы объектов даже в небольшом инстансе. Собственно, многие веб-приложения вычисляют хэши для полей в пользовательских профилях и используют их в качестве идентификатора.
Надежность
В целом Redis обеспечивает высокий уровень сохранности данных. Но поскольку СУБД держит все данные в памяти, есть риск потерять их при аварийном отключении сервера.
Redis не ориентирована на ACID-транзакции, так как приносит устойчивость в жертву скорости. Однако при желании она все же может удовлетворять всем требованиям стандарта для высоконадёжных систем. По умолчанию fsync() задан параметр everysec, и СУБД сохраняет данные на диск ежесекундно. Но если применить команду appendfsync always, то система будет синхронизировать данные после каждой записи. Но, очевидно, это отразится на общей производительности.
Настройка
Сам по себе процесс развертки Redis довольно прост. Однако Redis — это однопоточная система, поэтому на задачах с многопоточностью настройка порой оборачивается головной болью. Если вам нужна высокая степень параллелизма, Redis создаст некоторые проблемы.
Когда лучше использовать Redis
СУБД хорошо подходит для работы с интенсивно меняющимися данными (или данными, к которым часто обращается приложение). Но эксперты не рекомендуют применять её для обработки критически значимых данных. Для этих целей лучше использовать PostgreSQL.
Правый угол: PostgreSQL

Надежность
PostgreSQL заточена под работу с критическими данными, которые записываются прямо на диск. Так они защищены от случайных сбоев на сервере или потери питания. В то же время эта СУБД умеет работать со сложными составными запросами, даже если они подразумевают чтение, запись и валидацию одновременно.
Производительность
Цена высокой надежности — относительно низкая скорость работы. PostgreSQL действительно медленнее аналогов, однако все же способна справляться с высокой нагрузкой:
- имеет специальный тип данных (tsvector) для быстрого поиска по тексту;
- может масштабироваться для больших нагрузок;
- можно включить кэширование в памяти, текстовый поиск, специализированное индексирование и хранение ключевых значений.
Параметр конфигурации shared_buffer в конфигурационном файле Postgres определяет, сколько памяти будет использоваться для кэширования данных. Обычно он должен быть установлен на уровне 25-40% от общего объема памяти. Это связано с тем, что Postgres также использует кэш операционной системы. При большем объеме памяти большинству повторяющихся запросов, обращающихся к одному и тому же набору данных, не потребуется обращаться к диску. Вот как можно установить этот параметр в Postgres CLI:
ALTER SYSTEM SET shared_buffer TO = <value>
Более подробно о настройках производительности можно прочитать тут.
Не существует «серебряной пули» или волшебной кнопки, нажатие на которую решает все проблемы производительности SQL. Но их можно минимизировать за счет умных подходов к составлению запросов.
К слову, некоторые из таких подходов мы обсуждали в одном из прошлых материалов. Например, CLUSTER упрощает работу с «холодным» чтением буферов с диска, а LEFT JOIN вместо INNER JOIN помогает планировщику делать более точные прогнозы количества строк. В сумме эти и другие решения ускоряют выполнение запросов PostgreSQL в десятки раз.
Настройка
Процесс может быть запутанным, особенно для начинающих системных администраторов. Однако это обусловлено обширным набором дополнительных инструментов. Экосистема развивается с 1988 года. За прошедшее время появились самые разные расширения — например, PostGIS, добавляющий поддержку географических объектов, или модули для полнотекстового поиска.
Когда лучше использовать PostgreSQL
Один из ключевых юзкейсов — управление очень большими базами данных, для работы с которыми важна точность и надежность, но не скорость. Например, компания Adjust применяет PostgreSQL для работы с БД в десятки петабайт. Большую её часть составляют логи приложений, а также информация о транзакциях и аналитика мобильных приложений.
Post GIS позволяет быстро и легко создавать пространственные базы данных, что сделало Postgres особенно популярным среди грузоотправителей и логистических компаний.
Государственные учреждения, финансовые компании и медицинские организации выбирают PostgreSQL из-за безопасности.
Еще одна сфера, где PostgreSQL находит широкое применение, — это космос. Космонавты предъявляют особые требования к вычислительным системам, а отказоустойчивость на орбите имеет первостепенное значение. По этой причине PostgreSQL используют на МКС. Система управления базами данных является частью комплекса для мониторинга компьютеров космической станции. Состояние вычислительных узлов контролирует система мониторинга Nagios, которая передает информацию PostgreSQL. Содержимое базы данных затем реплицируют на сервер в командном центре.
Redis feat. PostgreSQL
Различия в производительности и масштабируемости не означают, что бизнес должен выбирать что-то одно. Redis и PostgreSQL могут работать в паре для решения бизнес-задач.
Рассмотрим на примере. Антивирусный бэкенд компании Wultra (из сферы информационной безопасности) должен был обрабатывать множество одновременных запросов к базе данных пакетов Android, чтобы определить, является ли пакет безопасным или нет.
Серверу необходимо обрабатывать до 100 млн пакетов каждый день (примерно 1200 пакетов в секунду). Эти запросы отправляются с мобильных устройств, которые проверяют состояние установленных пакетов на устройстве. Ответ должен быть получен в течение 100 мс.
Изначально инженеры использовали PostgreSQL для хранения данных и опроса базы, но SQL-движок не справлялся с нагрузкой. При 1000 пакетах, вставляемых в секунду, некоторые запросы занимают более 20 секунд, и производительность продолжает снижаться.
Теперь каждый запрос сперва попадает в Redis (с помощью MSET вставляют сразу несколько строк в базу), а затем отдельный поток постепенно переносит их в SQL-хранилище.
В Spring процесс выглядит следующим образом:
// Этот фрагмент кода добавляет новые пакеты с префиксом packageInsert:: используя команду MSET.
Map<String, PackageInfoEntity> packageDetails = new HashMap<>();
for (Map.Entry<PackageInfoKey, PackageInfoEntity> entry : entityMap.entrySet()) {
String insertKey = "packageInsert::" + entry.getKey();
packageDetails.put(insertKey, entry.getValue());
}
redisTemplate.opsForValue().multiSet(packageDetails);
Так Redis используется для обработки вставок во время высокой нагрузки, а новые записи вставляются в PostgreSQL с небольшой задержкой.
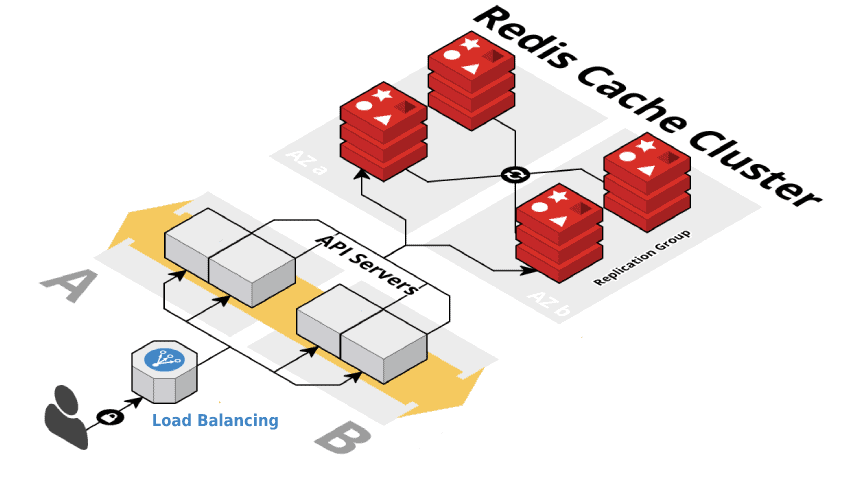
Упростить работу с обеими СУБД можно, если развернуть их в облаке — кластеры PostgreSQL и Redis предлагаем мы. Облачный провайдер отвечает за обновления, безопасность данных, резервное копирование, что положительно сказывается на стабильности сервиса.
Больше о базах данных в нашем блоге:
- Зачем компаниям и разработчикам базы данных в облаке
- Бессерверные платформы для работы с PostgreSQL
- Как ускорить выполнение запросов PostgreSQL в 100 раз

