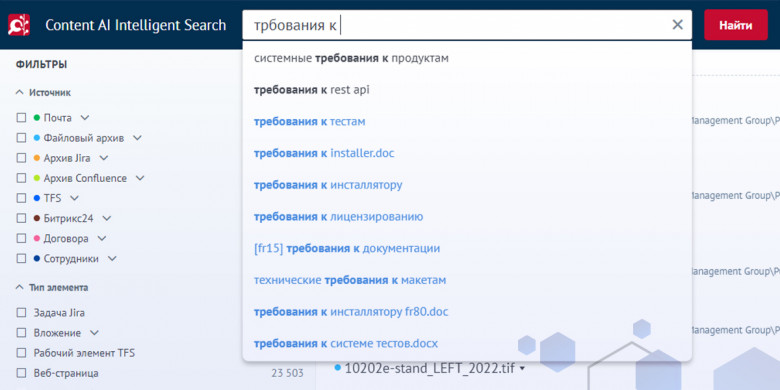
Привет, Хабр!
Меня зовут Елена Понаскова, я HR-директор в Content AI.
В IT-индустрии борьба за таланты давно вышла за рамки зарплатных вилок и стандартных бонусов. Да, деньги важны, но что на самом деле удерживает людей в компании? Не просто интересные проекты или карьерные перспективы, а чувство принадлежности. Когда команда — это не просто коллеги, а единомышленники, когда ценности компании созвучны твоим, а атмосфера дарит не только мотивацию, но и ощущение надежности — именно тогда возникает искренняя вовлеченность.
Сегодня хочу рассказать о том, как мы создаем среду, где люди не просто работают, а хотят остаться.