
Игорь Пантелеев, Software Developer, DataArt
Для распознавания человеческой речи придумано множество сервисов — достаточно вспомнить Pocketsphinx или Google Speech API. Они способны довольно качественно преобразовать в печатный текст фразы, записанные в виде звукового файла. Но ни одно из этих приложений не может сортировать разные звуки, захваченные микрофоном. Что именно было записано: человеческая речь, крики животных или музыка? Мы столкнулись с необходимостью ответить на этот вопрос. И решили создать пробные проекты для классификации звуков с помощью алгоритмов машинного обучения. В статье описано, какие инструменты мы выбрали, с какими проблемами столкнулись, как обучали модель для TensorFlow, и как запустить наше решение с открытым исходным кодом. Также мы можем загружать результаты распознавания на IoT-платформу DeviceHive, чтобы использовать их в облачных сервисах для сторонних приложений.
Выбор инструментов и модели для классификации
Сначала нам нужно было выбрать ПО для работы с нейронными сетями. Первым решением, которое показалось нам подходящим, была библиотека Python Audio Analysis.
Основная проблема машинного обучения — хороший набор данных. Для распознавания речи и классификации музыки таких наборов очень много. С классификацией случайных звуков дела обстоят не так хорошо, но мы, пусть и не сразу, нашли набор данных с «городскими» звуками.
В ходе тестирования мы столкнулись со следующими проблемами:
- pyAudioAnalysis недостаточно гибкий. Он работает с небольшим спектром параметров, а некоторые из них рассчитываются на лету. Например, количество обучающих циклов основано на количестве сэмплов, и изменить это нельзя.
- Выбранный набор данных содержит только 10 классов, и все они входят в группу звуков города.
Следующим вариантом решения стал набор данных Google AudioSet, который основан на размеченных видео фрагментах YouTube и доступен для загрузки в двух форматах:
- CSV-файлы, в которых содержится следующая информация о каждом фрагменте: ID размещенного на YouTube видео, время начала и окончания фрагмента, одна или несколько присвоенных отрывку меток.
- Извлеченные аудиофичи, которые сохраняются в виде файлов TensorFlow.
Эти аудиофичи совместимы с моделями YouTube-8M. Также это решение предлагает использовать модель TensorFlow VGGish для извлечения фич из аудио потока. Такое решение соответствовало большей части наших требований, и мы решили выбрать его.
Модель обучения
Следующей задачей было выяснить, как работает интерфейс YouTube-8M. Он предназначен для работы с видео, но, к счастью, может работать и с аудио. Эта библиотека довольно гибкая, но имеет фиксированное число классов. Поэтому мы внесли некоторые изменения, чтобы количество классов можно было передавать в качестве параметра. YouTube-8M может работать с данными двух типов: агрегированными фичами и фичами для каждого фрагмента. Google AudioSet предоставляет данные в виде фич для каждого фрагмента. Далее нам нужно было выбрать модель для обучения.
Ресурсы, время и точность
Графические процессоры (GPU) лучше подходят для машинного обучения, чем центральные процессоры (CPU). Вы можете найти больше информации здесь, поэтому мы не будем на этом подробно останавливаться и сразу перейдем к нашей конфигурации. Для экспериментов мы использовали PC с одной видеокартой NVIDIA GTX 970 4GB.
В нашем случае время обучения не имело особого значения. Отметим, что одного–двух часов обучения было достаточно, чтобы принять первоначальное решение о выбранной модели и ее точности.
Конечно, мы хотим получить как можно более высокую точность. Но для обучения более сложной модели (которая должна обеспечить большую точность) потребуется больше оперативной памяти (памяти видеоплаты в случае использования графического процессора).
Выбор модели
Полный список моделей YouTube-8M с описаниями доступен здесь. Поскольку наши данные для обучения представлены в виде фрагментированных фич, необходимо использовать соответствующую модель. Google AudioSet содержит разделенный на три части набор данных: сбалансированное обучение (balanced train), несбалансированное обучение (unbalanced train) и оценка. Подробнее об этом можно прочитать здесь.
Для обучения и оценки использовалась модифицированная версия YouTube-8M. Ее можно найти здесь.
Сбалансированное обучение
В данном случае команда выглядит следующим образом:
python train.py --train_data_pattern=/path_to_data/audioset_v1_embeddings/bal_train/*.tfrecord --num_epochs=100 --learning_rate_decay_examples=400000 --feature_names=audio_embedding --feature_sizes=128 --frame_features --batch_size=512 --num_classes=527 --train_dir=/path_to_logs --model=ModelName
Для LstmModel мы изменили базовую скорость обучения на 0,001 в соответствии с документацией. Также мы изменили значение lstm_cells на 256, так как у нас не хватило оперативной памяти.
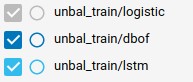
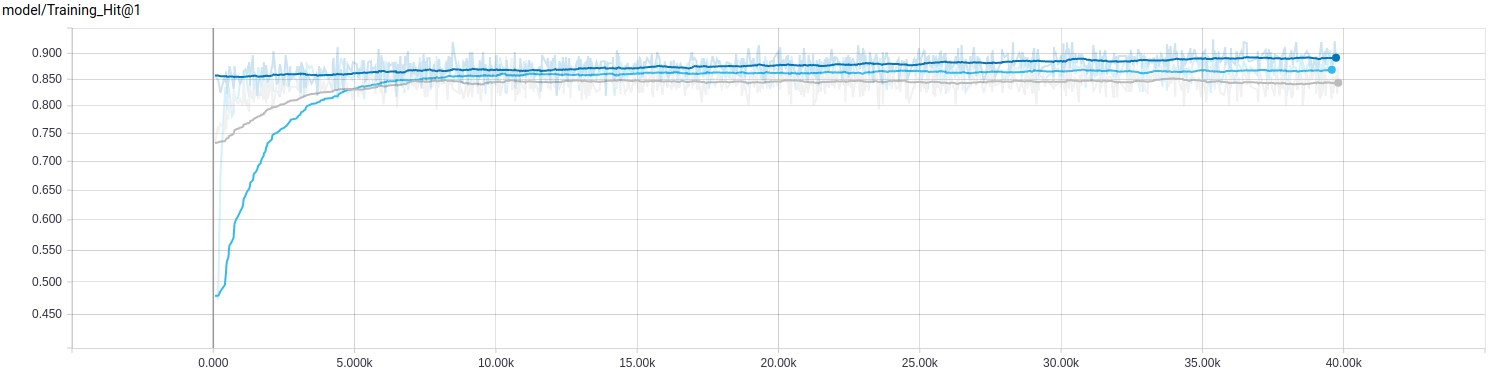
Давайте посмотрим на результаты обучения.

| Название модели | Время обучения | Оценка на последнем шаге | Средняя оценка |
|---|---|---|---|
| Logistic | 14m 3s | 0.5859 | 0.5560 |
| Dbof | 31m 46s | 1.000 | 0.5220 |
| Lstm | 1h 45m 53s | 0.9883 | 0.4581 |
Нам удалось получить хорошие результаты на этапе обучения, однако это не значит, что мы достигнем аналогичных показателей при полной оценке.
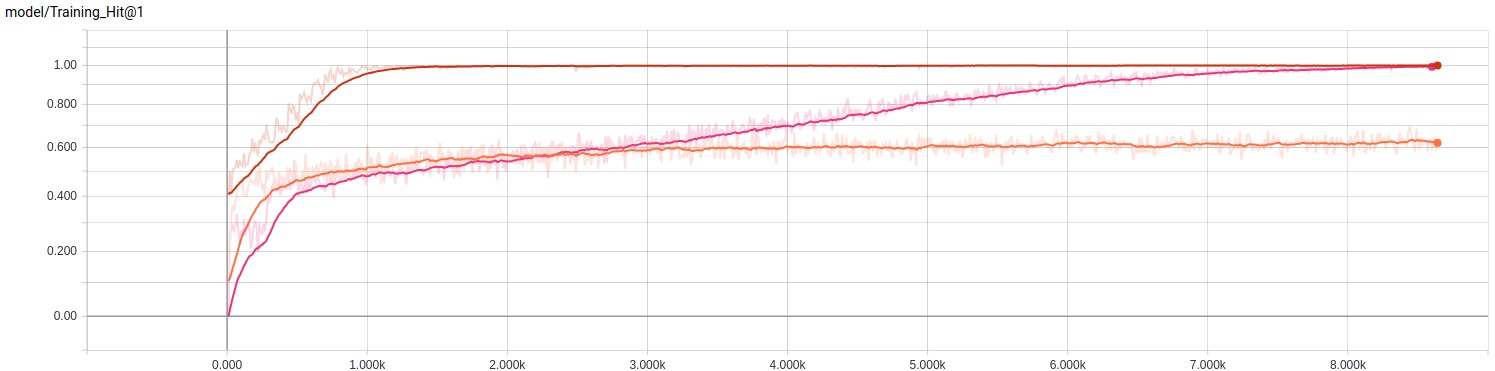
Несбалансированное обучение
В несбалансированном наборе данных намного больше сэмплов, поэтому мы установили значение количества циклов обучения на 10 (следовало выставить пять, потому что на обучение ушло достаточно много времени).
| Название модели | Время обучения | Оценка на последнем шаге | Средняя оценка |
|---|---|---|---|
| Logistic | 2h 4m 14s | 0.8750 | 0.5125 |
| Dbof | 4h 39m 29s | 0.8848 | 0.5605 |
| Lstm | 9h 42m 52s | 0.8691 | 0.5396 |
Журнал обучения
Если вы хотите изучить наши log-файлы, можете скачать и извлечь их, пройдя по этой ссылке. После загрузки запустите tensorboard --logdir /path_to_train_logs/ и перейдите по ссылке.
Подробнее об обучении
YouTube-8M принимает множество параметров, и многие из них влияют на процесс обучения.
Например, можно настроить скорость обучения и количество эпох, что сильно изменит процесс обучения. Также существуют три функции для расчета потерь и другие полезные переменные, которые можно настроить и изменить для улучшения результатов.
Использование обученной модели с устройствами для захвата аудио
Когда у нас есть обученные модели, пора добавить код для взаимодействия с ними.
Захват аудио с помощью микрофона
Нам нужно каким-то образом получить аудиоданные с микрофона. Мы будем использовать библиотеку PyAudio, которая имеет простой интерфейс и может работать на большинстве платформ.
Подготовка звука
Как упоминалось ранее, мы используем модель TensorFlow VGGish в качестве инструмента для извлечения фич. Вот краткое объяснение процесса трансформации:
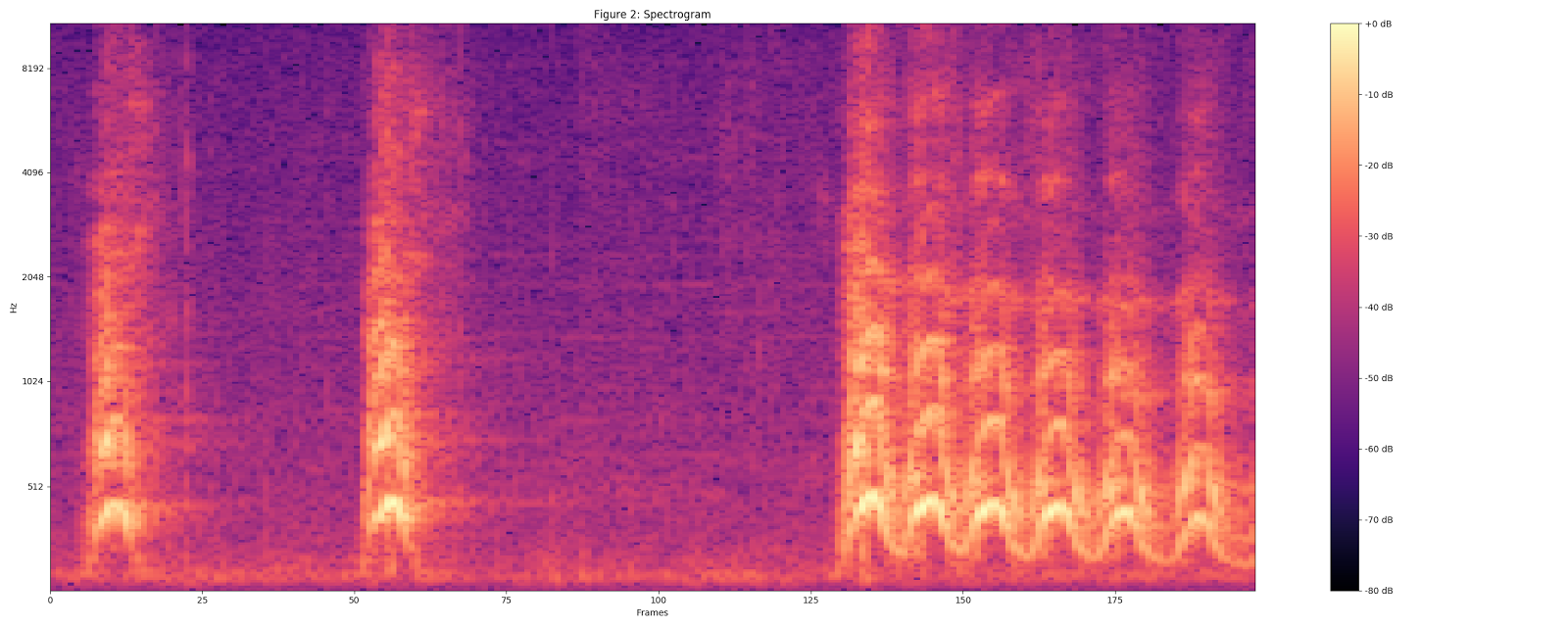
Для визуализации использовался сэмпл Dog bark («Лай собаки») из набора данных UrbanSound.
Преобразуем аудио к формату 16 kHz моно.
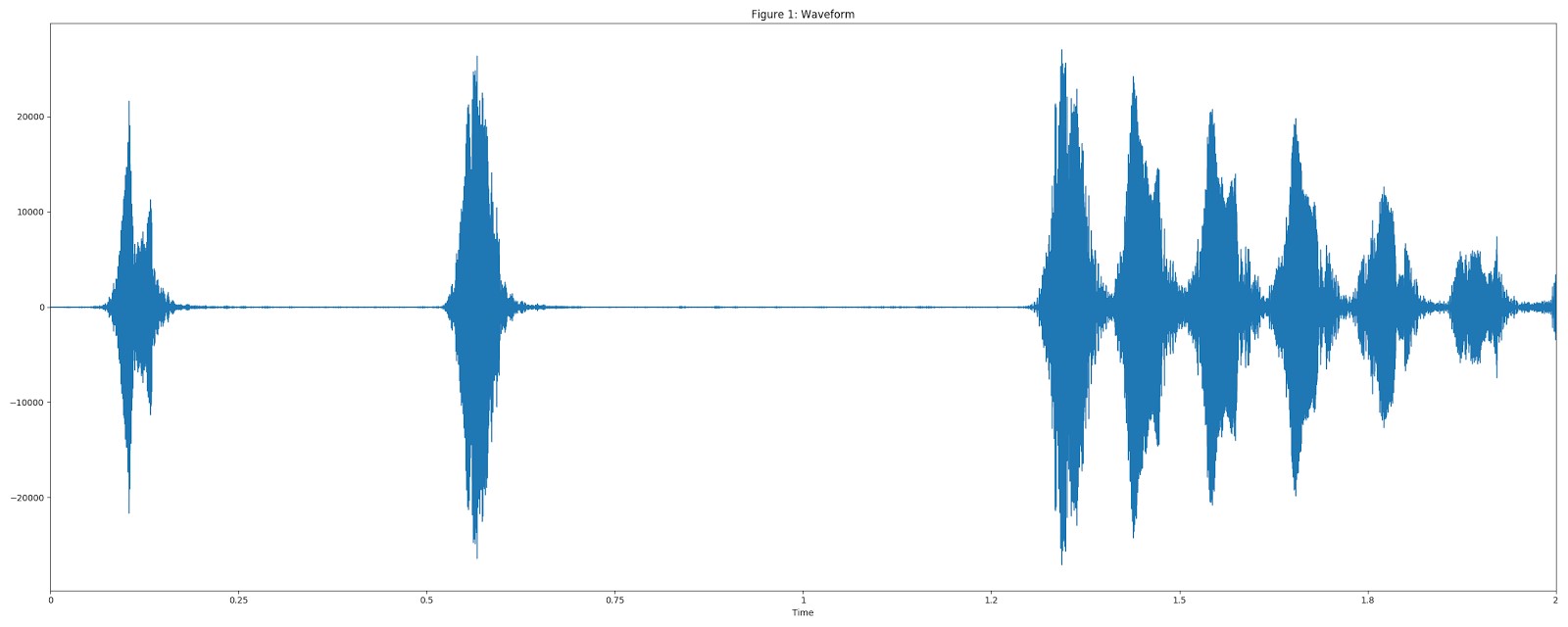
Рассчитываем спектрограмму с помощью величин STFT (преобразование Фурье на малом временном интервале) с размером окна 25 мс, шагом в 10 мс и периодическим окном Ханна.
Рассчитываем мел-спектрограмму, приводя текущую спектрограмму к 64-разрядному мел-диапазону.
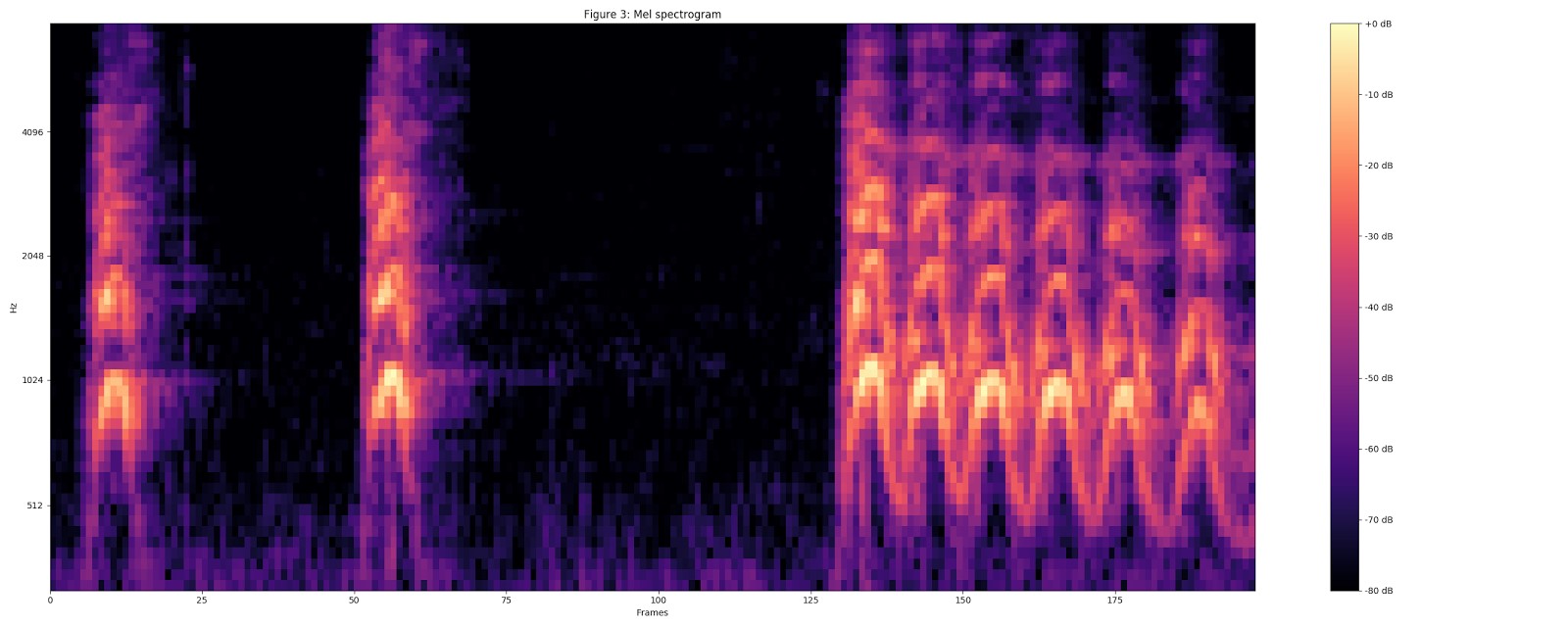
Рассчитываем стабилизированную логарифмическую спектрограмму с помощью log (mel-спектр + 0,01), где используется смещение, чтобы избежать логарифма нуля.

Эти фичи затем преобразуются в непересекающиеся фрагменты в 0,96 секунды, где каждый из них имеет размерность 64 мел-диапазона на 96 фреймов по 10 мс каждый.
Полученные данные затем подаются в модель VGGish для приведения данных в векторный вид.
Классификация
Наконец, нам нужен интерфейс для передачи данных в нейронную сеть и получения результатов.
Возьмем за основу интерфейс YouTube-8M, но изменим его, чтобы удалить этап сериализации/десериализации.
Здесь вы можете ознакомиться с результатами нашей работы. Давайте рассмотрим этот момент подробнее.
Установка
PyAudio использует libportaudio2 и portaudio19-dev, поэтому для работы необходимо установить эти пакеты.
Кроме того, понадобятся некоторые Python-библиотеки. Вы можете установить их с помощью pip: pip install -r requirements.txt
Также вам необходимо загрузить и извлечь в корень проекта архив с сохраненными моделями. Вы можете найти его здесь.
Запуск
Наш проект предлагает возможность использования одного из трех интерфейсов.
Предварительно записанный аудиофайл
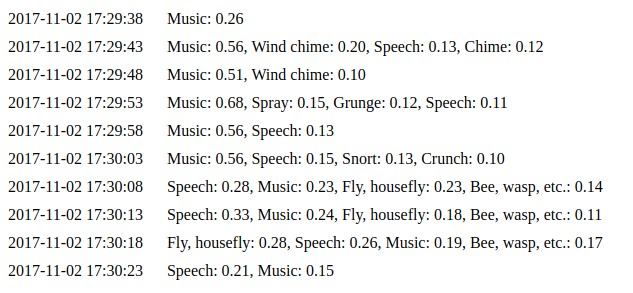
Просто запустите python parse_file.py path_to_your_file.wav, и вы увидите в терминале Speech: 0.75, Music: 0.12, Inside, large room or hall: 0.03
Результат зависит от исходных данных. Эти значения выводятся на основе прогноза нейронной сети. Более высокое значение означает более высокую вероятность того, что входные данные принадлежат этому классу.
Захват и обработка данных с микрофона
python capture.py запускает процесс, который постоянно будет захватывать данные с вашего микрофона. Он будет передавать данные для классификации каждые 5–7 секунд (по умолчанию). Вы увидите результаты так же, как в предыдущем примере. Вы можете запустить его с параметром --save_path=/path_to_samples_dir/, в этом случае все захваченные данные будут сохранены в указанной папке в формате .WAV. Эта функция полезна, если вы хотите попробовать разные модели с теми же образцами. Используйте параметр --help, чтобы получить дополнительную информацию.
Веб-интерфейс
Команда python daemon.py реализует простой веб-интерфейс, который по умолчанию доступен по адресу http://127.0.0.1:8000. Мы используем тот же код, что и в предыдущем примере. Вы можете увидеть последние десять прогнозов на странице событий.
Интеграция с IoT
Последний очень важный момент — интеграция с IoT-инфраструктурой. Если вы запустите веб-интерфейс, который мы упоминали в предыдущем разделе, на главной странице можете найти статус подключения клиента DeviceHive и его настройки. Пока клиент подключен, прогнозы будут отправляться на указанное устройство в виде уведомлений.

Заключение
TensorFlow — очень гибкий инструмент, который может быть полезен во многих приложениях с машинным обучением для распознавания изображений и звуков. Использование такого инструмента в тандеме с IoT-платформой позволяет создать интеллектуальное решение с огромным потенциалом. В «умных городах» его можно применить для обеспечения безопасности — оно, например, способно распознать звуки бьющегося стекла или выстрела. Даже в тропических лесах такое решение можно было бы использовать для отслеживания маршрутов диких животных или птиц, анализируя их голоса. IoT-платформу можно настроить на отправку уведомлений о звуках в радиусе действия микрофона. Такое решение можно установить на локальные устройства (в то же время, его можно развернуть в качестве облачной системы), чтобы минимизировать расходы на трафик и облачные вычисления, кастомизировать его для отправки исключительно уведомлений, без вложений с необработанным аудио. Не забывайте, что это проект с открытым исходным кодом, поэтому вы можете им воспользоваться для создания собственных сервисов.
