Привет, Хабр! Каждый SRE в нашей команде когда-то мечтал спокойно спать по ночам. Мечты имеют свойство сбываться. В этой статье я расскажу про это и про то, как мы достигаем производительности и устойчивости своей системы Dodo IS.

Перед тем, как подобраться к asynс, необходимо ввести термин Concurrency.
В компьютерах не так уж много вещей происходят параллельно. Одна из таких вещей – вычисления на нескольких процессорах. Степень параллелизма ограничена количеством потоков CPU.
На самом деле Threads – это часть концепции Preemptive Multitasking, один из способов моделировать Concurrency в программе, когда мы полагаемся на операционную систему в вопросе Concurrency. Эта модель остается полезной до тех пор, пока мы понимаем, что имеем дело именно с моделью Concurrency, а не с параллелизмом.
Async/await – это синтаксический сахар для State Machine, другая полезная модель Concurrency, которая может работать в однопоточной среде. По сути это Cooperative Multitasking – модель сама по себе вообще не учитывает параллелизм. В сочетании с Multithreading, мы получаем одну модель поверх другой, и жизнь сильно усложняется.
Допустим, у нас 20 Threads и 20 запросов в обработке в секунду. На картинке видно пик – 200 запросов в системе одновременно. Как такое могло произойти:
Есть масса причин, по которым запросы за короткий интервал времени накопились и пришли единой пачкой. В любом случае, ничего страшного не произошло, они встали в очередь Thread Pool и потихоньку выполнились. Пиков больше нет, всё идет дальше, как ни в чем не бывало.
Предположим, что умный алгоритм Thread Pool (а там есть элементы машинного обучения) решил, что пока нет резона увеличивать количество Threads. Connection Pool в MySql тоже 20, потому что Threads=20. Соответственно, нам нужно только 20 соединений к SQL.
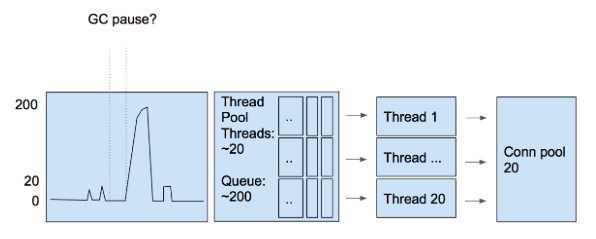
В этом случае, уровень Concurrency сервера с точки зрения внешней системы = 200. Сервер уже получил эти запросы, но еще не выполнил. Однако для приложения, работающего в парадигме Multithreading, количество одновременных запросов ограничено текущим размером Thread Pool = 20. Итак, мы имеем дело со степенью Concurrency = 20.

Посмотрим, что произойдет в приложении, работающем с async/await при той же нагрузке и распределении запросов. Здесь нет никакой очереди перед тем, как создать Task, и запрос поступает в обработку сразу. Конечно, на короткое время используется Thread из ThreadPool, и первая часть запроса, до обращения в базу данных, выполняется сразу. Поскольку Thread быстро возвращается в Thread Pool, нам не нужно большого количества Threads для обработки. На этой диаграмме мы не отображаем Thread Pool вообще, он прозрачен.
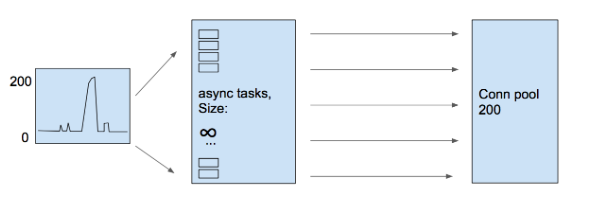
Что это будет означать для нашего приложения? Внешняя картина такая же – уровень Concurrency = 200. При этом ситуация внутри поменялась. Раньше запросы «толпились» в очереди ThreadPool, теперь степень Concurrency приложения тоже равна 200, потому как у нас нет никаких ограничений со стороны TaskScheduler. Ура! Мы достигли цели async – приложение «справляется» практически с любой степенью Concurrency!
Приложение стало прозрачным с точки зрения Concurrency, поэтому теперь Concurrency проецируется на базу данных. Теперь нам нужен пул соединений такого же размера = 200. База данных – это CPU, память, сеть, хранилище. Это такой же сервис со своими проблемами, как и любой другой. Чем больше запросов одновременно пытаемся выполнить, тем медленнее они выполняются.
При полной нагрузке на базу данных, в лучшем случае, Response Time деградирует линейно: вы дали запросов в два раза больше, стало работать в два раза медленнее. На практике из-за конкуренции запросов обязательно возникнет overhead, и, может оказаться, что система будет деградировать нелинейно.
Причины второго порядка:
Причина первого порядка:
В итоге async борется против ограниченных ресурсов и … побеждает! База данных не выдерживает и начинает замедляться. От этого сервер дополнительно наращивает Concurrency, и система уже не может выйти с честью из этой ситуации.
Иногда происходит интересная ситуация. У нас есть сервер. Он работает себе такой, все в порядке. Ресурсов хватает, даже с запасом. Потом мы вдруг получаем сообщение от клиентов, что сервер тормозит. Смотрим в график и видим, что был какой-то всплеск активности клиентов, но теперь все в норме. Думаем на DOS атаку или совпадение. Сейчас вроде всё нормально. Только вот сервер продолжает тупить, причем все жестче, пока не начинают сыпаться таймауты. Через некоторое время другой сервер, который использует ту же базу данных тоже начинает загибаться. Знакомая ситуация?
Можно попробовать объяснить это тем, что в какой-то момент сервер получил пиковое количество запросов и «сломался». Но мы ведь знаем, что нагрузка была снижена, а серверу после этого очень долго не становилось лучше, вплоть до полного исчезновения нагрузки.
Риторический вопрос: а сервер вообще должен был сломаться от чрезмерной нагрузки? Они так делают?
Здесь мы не будем анализировать графики с реальной производственной системы. В момент падения сервера мы зачастую не можем получить такой график. Сервер исчерпывает ресурс CPU, и как следствие не может записывать логи, отдавать метрики. На диаграммах в момент катастрофы зачастую наблюдается разрыв всех графиков.
SRE должны уметь изготавливать системы мониторинга мало подверженные такому эффекту. Системы, которые в любой ситуации предоставляют хоть какую-то информацию, и, вместе с тем, умеют анализировать post-mortem системы по отрывочным сведениям. Для учебных целей мы в рамках данной статьи используем несколько другой подход.
Попробуем создать модель, которая математически работает так же, как сервер под нагрузкой. Далее будем изучать характеристики сервера. Отбросим нелинейность реальных серверов и смоделируем ситуацию, где при возрастающей сверх номинала нагрузке происходит линейное замедление. В два раза больше, чем нужно запросов – в два раза медленнее обслуживаем.
Такой подход позволит:
Навигация по графику:
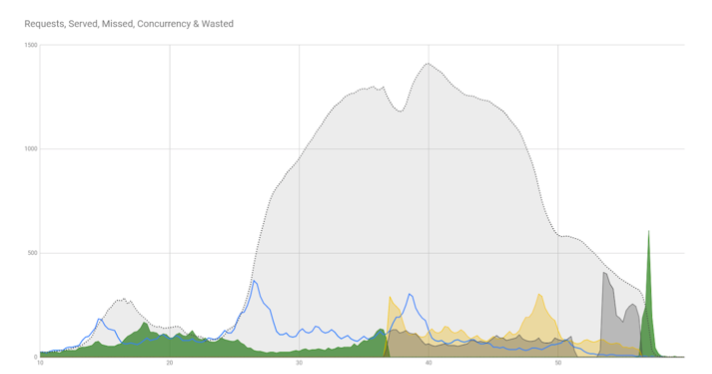
Почему график запросов клиента (синий на диаграмме) получился именно таким? Обычно график заказов в наших пиццериях плавненько растет утром и убывает вечером. Но мы наблюдаем три пика на фоне обычной равномерной кривой. Эта форма графика выбрана для модели не случайно, а по поводу. Модель родилась при расследовании реального инцидента с сервером контакт-центра пиццерий в России во время чемпионата мира по футболу.
Мы сидели и ждали, что у нас будет больше заказов. К Чемпионату подготовились, теперь серверы смогут пройти проверку на прочность.
Первый пик – любители футбола идут смотреть чемпионат, они голодны и покупают пиццу. Во время первого тайма они заняты и не могут заказывать. Но равнодушные к футболу люди могут, поэтому на графике дальше все идет как обычно.
И вот кончается первый тайм, и наступает второй пик. Болельщики перенервничали, проголодались и сделали в три раза больше заказов, чем в первый пик. Пицца покупается со страшной скоростью. Потом начинается второй тайм, и снова не до пиццы.
Тем временем, сервер контакт-центра начинает потихоньку загибаться и обслуживать запросы все медленнее и медленнее. Компонент системы, в данном случае – веб-сервер Колл-центра, дестабилизирован.
Третий пик наступит, когда матч закончится. Болельщиков и систему ждет пенальти.
Что произошло? Сервер мог удерживать 100 условных запросов. Мы понимаем, что он рассчитан на эту мощность и больше не выдержит. Приходит пик, который сам по себе не такой большой. Зато серая область Concurrency гораздо выше.
Модель рассчитана так, что Concurrency численно равна количеству заказов в секунду, поэтому визуально на графике оно должно быть такого же масштаба. Однако оно гораздо выше, потому что накапливается.
Мы видим здесь тень от графика – это запросы стали возвращаться к клиенту, выполняться (показано первой красной стрелкой). Масштаб времени здесь условный, чтобы увидеть смещение во времени. Второй пик уже выбил наш сервер. Он упал и стал обрабатывать вчетверо меньше запросов, чем в обычное время.
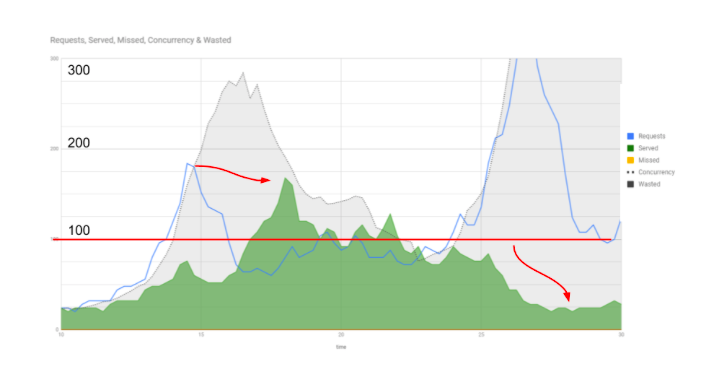
На второй половине графика видно, что какие-то запросы все-же сначала выполнялись, но потом появились желтые пятна – запросы перестали выполняться совсем.
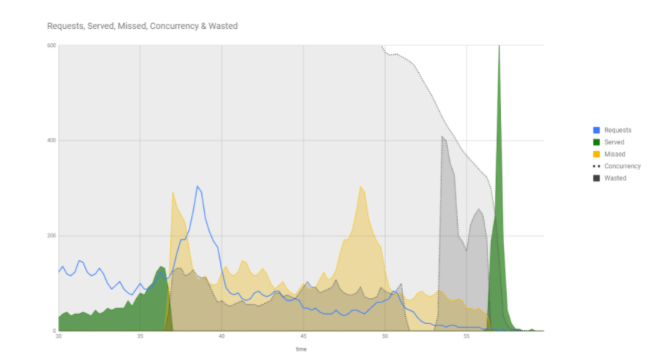
Еще раз весь график. Видно, что Concurrency зашкаливает. Появляется огромная гора.
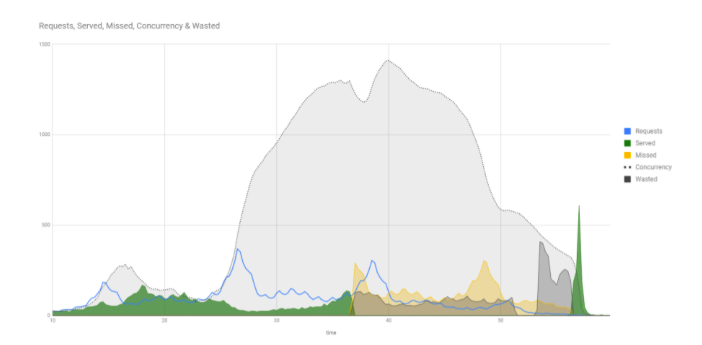
Обычно мы анализировали совсем другие метрики: насколько медленно запрос выполнялся, сколько запросов в секунду. А на Concurrency вообще не смотрим, даже не думали про эту метрику. А зря, потому что именно эта величина лучше всего показывает момент отказа сервера.
Но откуда взялась такая огромная гора? Самый большой пик нагрузки-то давно уже прошёл!
Закон Литтла регулирует Concurrency.
L (количество клиентов внутри системы) = λ (скорость их пребывания) ∗ W (время, которое они проводят внутри системы)
Это в среднем. Однако у нас ситуация развивается драматически, нас среднее не устраивает. Мы это уравнение будем дифференцировать, потом интегрировать. Для этого посмотрим в книгу Джона Литтла, который эту формулу придумал, и увидим там интеграл.
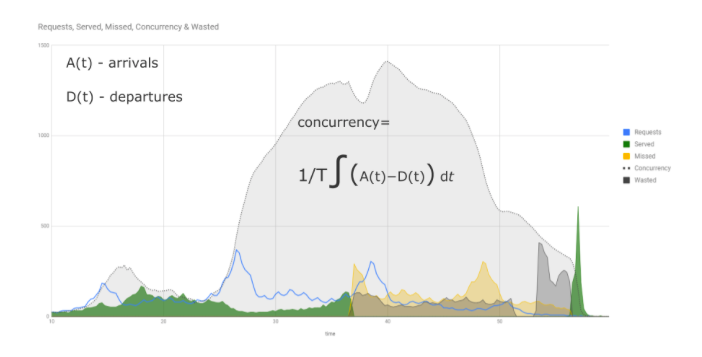
У нас есть количество поступлений в систему и количество тех, кто уходит из системы. Запрос поступает и уходит, когда все выполнено. Ниже изображен регион графика роста, соответствующий линейному росту Concurrency.
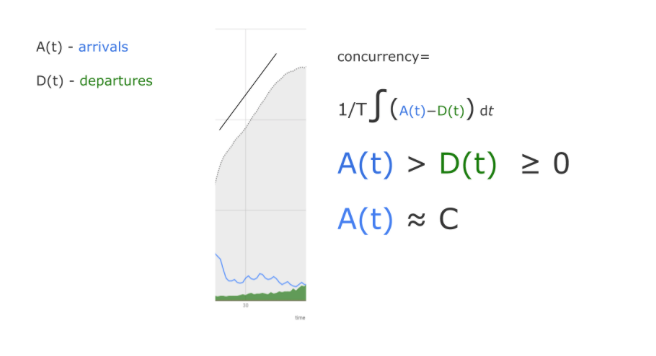
Зеленых запросов мало. Это те, которые реально выполняются. Синие – те, которые поступают. Между таймами у нас обычное количество запросов, ситуация стабильная. Но Concurrency все равно растет. Сервер уже не справится с этой ситуацией сам. Это значит, что скоро он упадет.
Но почему Concurrency растет? Смотрим на интеграл константы. У нас ничего не меняется в системе, но интеграл выглядит как линейная функция, которая растет только вверх.
Объяснение с интегралами сложновато, если не помнить математики. Тут предлагаю размяться и сыграть в игру.
Предусловия: На сервер поступают запросы, каждый требует три периода обработки на CPU. Ресурс CPU делится равномерно между всеми задачами. Это похоже на то, как расходуется ресурс CPU при Preemptive Multitasking. Число в клетке означает количество работы, оставшейся после данного такта. За каждый условный такт поступает новый запрос.
Представьте, что поступил запрос. Всего 3 единицы работы, по завершении первого периода обработки осталось 2 единицы.
Во втором периоде наслаивается еще один запрос, теперь оба CPU заняты. Они сделали по единице работы по первым двум запросам. Осталось доделать 1 и 2 единицы для первого и второго запроса соответственно.
Теперь пришел третий запрос, и начинается самое интересное. Казалось бы, первый запрос должен был быть завершен, но в этом периоде уже три запроса делят между собой ресурс CPU, поэтому степени завершенности для всех трех запросов теперь дробные по завершении третьего периода обработки:
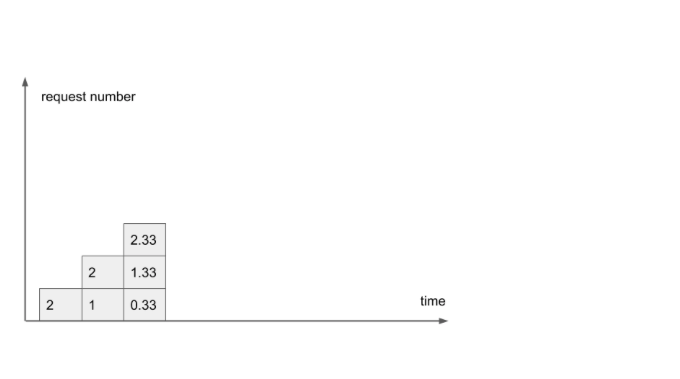
Дальше еще интереснее! Добавляется четвертый запрос, и теперь степень Concurrency уже 4, так как всем четырем запросам потребовался ресурс в этом периоде. Тем временем, первый запрос к концу четвертого периода уже выполнился, в следующий период он не переходит, и ему осталось 0 работы для CPU.
Так как первый запрос уже выполнился, подведем итог для него: он выполнялся на треть дольше, чем мы ожидали. Предполагалось, что длина каждой задачи по горизонтали в идеале = 3, по количеству работы. Помечаем его оранжевым, в знак того, что мы не совсем довольны результатом.
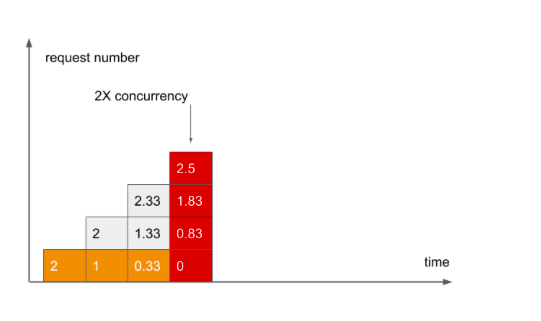
Поступает пятый запрос. Степень Concurrency по прежнему 4, но мы видим, что в пятом столбике оставшейся работы в сумме больше. Это происходит, потому что в четвертом столбике оставалось больше несделанной работы, чем в третьем.
Продолжаем еще три периода. Ждем ответов.
– Сервер, алё!
–…

– Ваш звонок очень важен для нас…
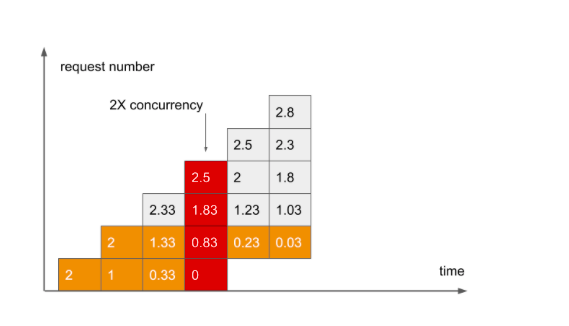
Ну вот, наконец-то пришел ответ на второй запрос. Время ответа вдвое дольше, чем ожидалось.
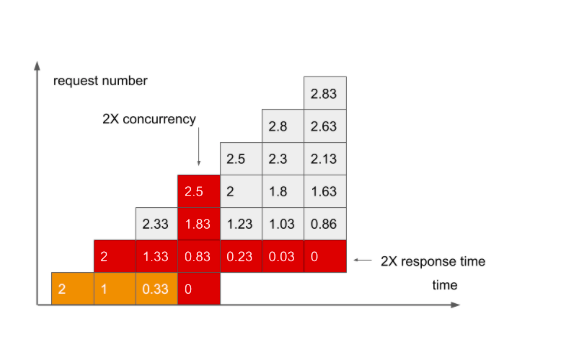
Степень Concurrency выросла уже втрое, и ничто не предвещает, что ситуация изменится к лучшему. Я не рисовал дальше, потому что время ответа на третий запрос уже не влезет в картинку.
Запросы накапливаются в памяти неограниченно. Рано или поздно попросту закончится память. Кроме этого, при увеличении масштаба возрастают накладные затраты на CPU на обслуживание различных структур данных. Например, пул соединений теперь должен отслеживать таймауты большего количества соединений, сборщик мусора теперь должен перепроверять большее количество объектов на хипе, и так далее.
Исследовать все возможные последствия накопления активных объектов не является целью этой статьи, но даже простого накопления данных в оперативной памяти уже достаточно, чтобы завалить сервер. Кроме того, мы уже рассмотрели, что сервер-клиент проецирует свои проблемы Concurrency на сервер базы данных, и другие сервера, которые он использует как клиент.
Самое интересное: теперь даже если подать на сервер меньшую нагрузку, он все равно не восстановится. Все запросы будут заканчиваться таймаутом, а сервер будет расходовать все доступные ресурсы.
А чего мы, собственно, ожидали?! Ведь мы заведомо дали серверу количество работы, с которым он не справится.
Когда занимаешься архитектурой распределенной системы, полезно подумать, как обычные люди решают такие проблемы. Возьмем, например, ночной клуб. Он перестанет функционировать, если туда зайдет слишком много людей. Вышибала справляется с проблемой просто: смотрит, сколько человек внутри. Один вышел – другого запускает. Новый гость придет и оценит размер очереди. Если очередь большая, уйдет домой. Что если применить этот алгоритм для сервера?

Давайте поиграем еще раз.
Предусловия: Опять у нас два CPU, такие же задачи по 3 единицы, поступающие каждый период, но теперь мы поставим вышибалу, и задачи будут умные — если они видят, что длина очереди 2, то сразу идут домой.


Пришел третий запрос. В этом периоде он стоит в очереди. У него число 3 по окончании периода. Дробных чисел в остатках нет, потому что два CPU выполняют две задачи, по единице за период.
Хотя у нас три запроса наслаиваются, степень Concurrency внутри системы = 2. Третий стоит в очереди и не считается.
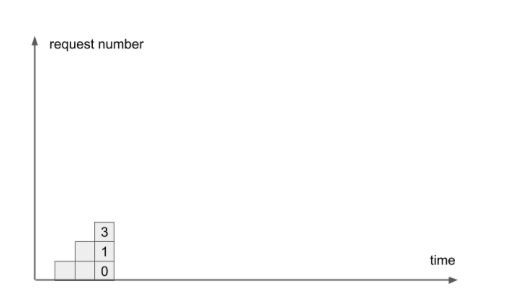
Пришел четвертый – та же картина, хотя уже накопилось больше оставшейся работы.

…
…
В шестом периоде третий запрос выполнился с отставанием на треть, и степень Concurrency уже = 4.
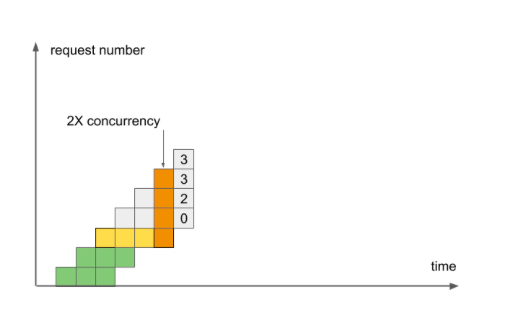
Степень Concurrency возросла в два раза. Больше она не может вырасти, ведь мы установили на это явный запрет. С максимальной скоростью выполнились только два первых запроса – те, кто пришел в клуб первыми, пока для всех хватало места.
Жёлтые запросы находились в системе дольше, но они стояли в очереди и не оттягивали на себя ресурс CPU. Поэтому те, кто был внутри спокойно развлекались. Это могло продолжаться и дальше, пока не пришел мужик и не сказал, что в очереди стоять не будет, а лучше отправится домой. Это невыполненный запрос:
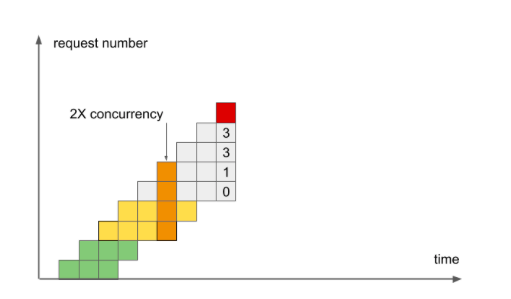
Ситуация может повторяться бесконечно, при этом время выполнения запросов остается на одном уровне – ровно вдвое дольше, чем хотелось бы.
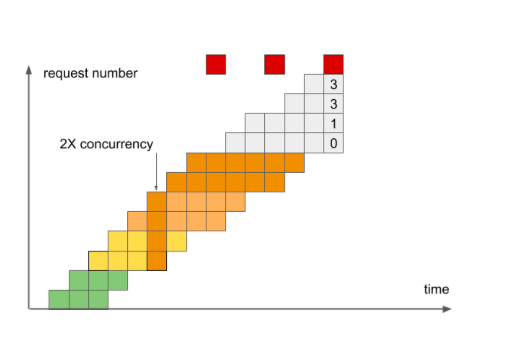
Мы видим, что простое ограничение уровня Concurrency устраняет проблему жизнеспособности сервера.
Простейшего «вышибалу» можно написать самому. Ниже привожу код с использованием семафора. Тут нет ограничения длины очереди снаружи. Код только для иллюстрации, не нужно его копировать.
Чтобы создать ограниченную очередь, нужно два семафора. Для этого подходит библиотека Polly, которую рекомендует Microsoft. Обратите внимание на паттерн Bulkhead. Дословно переводится как «переборка» – элемент конструкции, позволяющий судну не тонуть. Если честно, я считаю, что лучше подходит термин «вышибала». Важно то, что этот паттерн позволяет серверу выживать в безнадежных ситуациях.
Сначала мы на нагрузочном стенде выдавливаем из сервера все, что можно, пока не определяем, сколько запросов он может держать. Например, мы определили, что это 100. Ставим bulkhead.
Дальше сервер пропустит только нужное количество запросов, остальные будут стоять в очереди. Разумно будет выбрать несколько меньшее число, чтобы был запас. Готовой рекомендации на этот счет у меня нет, потому что есть сильная зависимость от контекста и конкретной ситуации.
Взгляните на этот постмортем напоследок, больше мы такого не увидим.
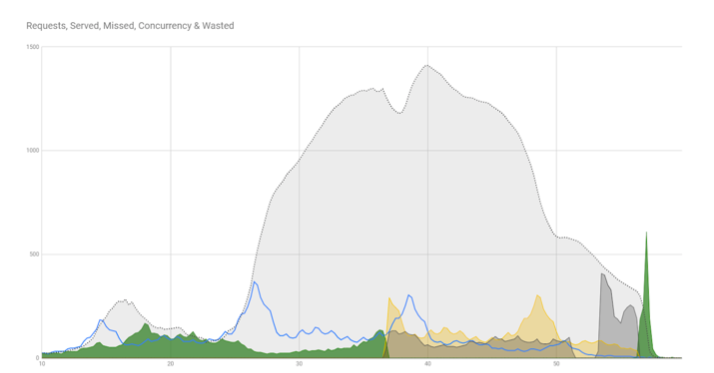
Вся эта серая куча однозначно коррелирует с падением сервера. Серое – смерть для сервера. Попробуем просто срезать это и посмотреть, что произойдет. Кажется, что какое-то количество запросов пойдет домой, просто не выполнится. Но сколько?
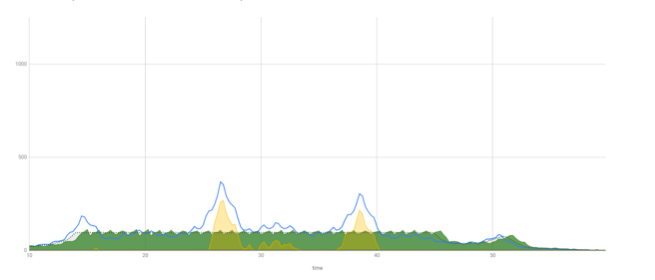
Оказалось, нашему серверу стало жить очень хорошо и весело. Он постоянно пашет на максимальной мощности. Конечно, когда происходит пик, его вышибает, но совсем ненадолго.
Окрыленные успехом попробуем сделать так, чтобы его совсем не вышибало. Попробуем увеличить длину очереди.
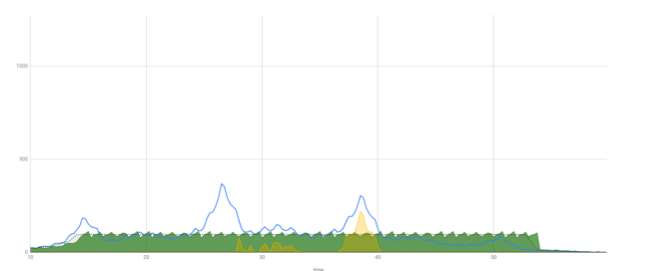
Стало получше, но вырос хвост. Это те запросы, которые еще долго потом выполняются.
Раз уж что-то стало лучше, попробуем довести до абсурда. Разрешим длину очереди в 10 раз больше, чем можем обслуживать одновременно:
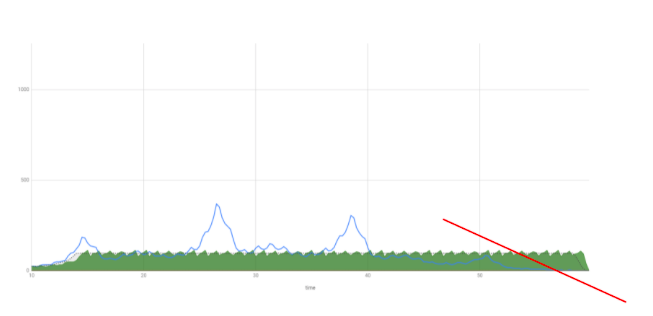
Если говорить о метафоре клуба и вышибалы, такая ситуация вряд ли возможна – никто не захочет ждать на входе дольше, чем проведет времени в клубе. Мы также не будем делать вид, что это нормальная ситуация для нашей системы.
Лучше вообще не обслуживать клиента, чем томить его на сайте или в мобильном приложении загрузкой каждого экрана по 30 секунд и портить репутацию компании. Лучше сразу честно сказать малой части клиентов, что сейчас мы не можем их обслужить. В противном случае, мы будем в несколько раз медленнее обслуживать всех клиентов, ведь график показывает, что ситуация сохраняется довольно долго.
Есть и еще один риск – другие компоненты системы могут быть не рассчитаны на такое поведение сервера, и, как мы уже знаем, Concurrency проецируется на клиентов.
Поэтому возвращаемся к первому варианту «100 на 100» и думаем, как масштабировать наши мощности.
¯\_(ツ)_/¯
При таких параметрах самая большая деградация по времени выполнения – ровно в 2 раза от «номинала». В то же время – это 100% деградация по времени выполнения запроса.
Если ваш клиент чувствителен ко времени выполнения (а это, как правило, справедливо, как с клиентами-людьми, так и с клиентами-серверами), то можно подумать о дальнейшем снижении длины очереди. В этом случае, мы можем брать какой-то процент от внутренней Concurrency, и будем точно знать, что сервис деградирует по времени ответа не больше, чем на этот процент в среднем.
По сути мы не пытаемся создать очередь, мы пытаемся защититься от флуктуаций нагрузки. Здесь так же, как и в случае определения первого параметра переборки (количество внутри), полезно определить, какие флуктуации нагрузки может накинуть клиент. Так мы будем знать, в каких случаях мы, грубо говоря, упустим прибыль от потенциального обслуживания.
Еще важнее определить, какие флуктуации Latency могут выдержать взаимодействующие с сервером другие компоненты системы. Так мы будем знать, что действительно выжимаем из существующей системы максимум без опасности потерять обслуживание полностью.
Проблему Uncontrolled Concurrency мы лечим с помощью Bulkhead Isolation.
Этот метод, как и другие, рассматриваемые в этой серии статей, удобно реализовывать библиотекой Polly.
Преимущество метода в том, что отдельную компоненту системы будет крайне трудно дестабилизировать как таковую. Система приобретает очень предсказуемое поведение по части времени на выполнение успешных запросов и гораздо более высокие шансы на успешное выполнение запросов вцелом.
Однако мы не решаем всех проблем. Например, проблему недостаточной мощности сервера. В данной ситуации нужно заведомо решиться на «сбрасывание балласта» в случае скачка нагрузки, которую мы оценили как чрезмерную.
Дальнейшие меры, которые наше исследование не затрагивает, могут включать, например, динамическое масштабирование.

Цикл статей про крушение системы Dodo IS*:В прошлой статье мы рассмотрели проблемы блокирующего кода в парадигме Preemptive Multitasking. Предполагалось, что необходимо переписать блокирующий код на async/await. Так мы и сделали. Теперь поговорим о том, какие проблемы возникли, когда мы сделали это.
1. День, когда Dodo IS остановилась. Синхронный сценарий.
2. День, когда Dodo IS остановилась. Асинхронный сценарий.
* Материалы написаны на основе моего выступления на DotNext 2018 в Москве.
Вводим термин Concurrency
Перед тем, как подобраться к asynс, необходимо ввести термин Concurrency.
В теории массового обслуживания Concurrency – это количество клиентов, которые в данный момент находятся внутри системы. Иногда Concurrency путают с Parallelism, но на самом деле это разные вещи.Тем, кто столкнулся с термином Concurrency впервые, я рекомендую видео Роба Пайка. Concurrency – это когда мы имеем дело со многими вещами одновременно, а Parallelism – когда делаем много вещей одновременно.
В компьютерах не так уж много вещей происходят параллельно. Одна из таких вещей – вычисления на нескольких процессорах. Степень параллелизма ограничена количеством потоков CPU.
На самом деле Threads – это часть концепции Preemptive Multitasking, один из способов моделировать Concurrency в программе, когда мы полагаемся на операционную систему в вопросе Concurrency. Эта модель остается полезной до тех пор, пока мы понимаем, что имеем дело именно с моделью Concurrency, а не с параллелизмом.
Async/await – это синтаксический сахар для State Machine, другая полезная модель Concurrency, которая может работать в однопоточной среде. По сути это Cooperative Multitasking – модель сама по себе вообще не учитывает параллелизм. В сочетании с Multithreading, мы получаем одну модель поверх другой, и жизнь сильно усложняется.
Сравнение работы двух моделей
Как всё работало в модели Preemptive Multitasking
Допустим, у нас 20 Threads и 20 запросов в обработке в секунду. На картинке видно пик – 200 запросов в системе одновременно. Как такое могло произойти:
- запросы могли сгруппироваться, если 200 клиентов нажали кнопку в один и тот же момент;
- сборщик мусора мог остановить запросы на несколько десятков миллисекунд;
- запросы могли задержаться в какой-либо очереди, если прокси поддерживает очередь.
Есть масса причин, по которым запросы за короткий интервал времени накопились и пришли единой пачкой. В любом случае, ничего страшного не произошло, они встали в очередь Thread Pool и потихоньку выполнились. Пиков больше нет, всё идет дальше, как ни в чем не бывало.
Предположим, что умный алгоритм Thread Pool (а там есть элементы машинного обучения) решил, что пока нет резона увеличивать количество Threads. Connection Pool в MySql тоже 20, потому что Threads=20. Соответственно, нам нужно только 20 соединений к SQL.

В этом случае, уровень Concurrency сервера с точки зрения внешней системы = 200. Сервер уже получил эти запросы, но еще не выполнил. Однако для приложения, работающего в парадигме Multithreading, количество одновременных запросов ограничено текущим размером Thread Pool = 20. Итак, мы имеем дело со степенью Concurrency = 20.
Как всё теперь работает в модели async

Посмотрим, что произойдет в приложении, работающем с async/await при той же нагрузке и распределении запросов. Здесь нет никакой очереди перед тем, как создать Task, и запрос поступает в обработку сразу. Конечно, на короткое время используется Thread из ThreadPool, и первая часть запроса, до обращения в базу данных, выполняется сразу. Поскольку Thread быстро возвращается в Thread Pool, нам не нужно большого количества Threads для обработки. На этой диаграмме мы не отображаем Thread Pool вообще, он прозрачен.

Что это будет означать для нашего приложения? Внешняя картина такая же – уровень Concurrency = 200. При этом ситуация внутри поменялась. Раньше запросы «толпились» в очереди ThreadPool, теперь степень Concurrency приложения тоже равна 200, потому как у нас нет никаких ограничений со стороны TaskScheduler. Ура! Мы достигли цели async – приложение «справляется» практически с любой степенью Concurrency!
Последствия: нелинейная деградация системы
Приложение стало прозрачным с точки зрения Concurrency, поэтому теперь Concurrency проецируется на базу данных. Теперь нам нужен пул соединений такого же размера = 200. База данных – это CPU, память, сеть, хранилище. Это такой же сервис со своими проблемами, как и любой другой. Чем больше запросов одновременно пытаемся выполнить, тем медленнее они выполняются.
При полной нагрузке на базу данных, в лучшем случае, Response Time деградирует линейно: вы дали запросов в два раза больше, стало работать в два раза медленнее. На практике из-за конкуренции запросов обязательно возникнет overhead, и, может оказаться, что система будет деградировать нелинейно.
Почему так происходит?
Причины второго порядка:
- теперь базе данных нужно одновременно держать в памяти структуры данных для обслуживания большего количества запросов;
- теперь базе данных нужно обслуживать коллекции большего размера (а это алгоритмически невыгодно).
Причина первого порядка:
- contention, о которой уже немного говорилось в предыдущей статье.
В итоге async борется против ограниченных ресурсов и … побеждает! База данных не выдерживает и начинает замедляться. От этого сервер дополнительно наращивает Concurrency, и система уже не может выйти с честью из этой ситуации.
Синдром внезапной смерти сервера
Иногда происходит интересная ситуация. У нас есть сервер. Он работает себе такой, все в порядке. Ресурсов хватает, даже с запасом. Потом мы вдруг получаем сообщение от клиентов, что сервер тормозит. Смотрим в график и видим, что был какой-то всплеск активности клиентов, но теперь все в норме. Думаем на DOS атаку или совпадение. Сейчас вроде всё нормально. Только вот сервер продолжает тупить, причем все жестче, пока не начинают сыпаться таймауты. Через некоторое время другой сервер, который использует ту же базу данных тоже начинает загибаться. Знакомая ситуация?
Почему умерла система?
Можно попробовать объяснить это тем, что в какой-то момент сервер получил пиковое количество запросов и «сломался». Но мы ведь знаем, что нагрузка была снижена, а серверу после этого очень долго не становилось лучше, вплоть до полного исчезновения нагрузки.
Риторический вопрос: а сервер вообще должен был сломаться от чрезмерной нагрузки? Они так делают?
Моделируем ситуацию падения сервера
Здесь мы не будем анализировать графики с реальной производственной системы. В момент падения сервера мы зачастую не можем получить такой график. Сервер исчерпывает ресурс CPU, и как следствие не может записывать логи, отдавать метрики. На диаграммах в момент катастрофы зачастую наблюдается разрыв всех графиков.
SRE должны уметь изготавливать системы мониторинга мало подверженные такому эффекту. Системы, которые в любой ситуации предоставляют хоть какую-то информацию, и, вместе с тем, умеют анализировать post-mortem системы по отрывочным сведениям. Для учебных целей мы в рамках данной статьи используем несколько другой подход.
Попробуем создать модель, которая математически работает так же, как сервер под нагрузкой. Далее будем изучать характеристики сервера. Отбросим нелинейность реальных серверов и смоделируем ситуацию, где при возрастающей сверх номинала нагрузке происходит линейное замедление. В два раза больше, чем нужно запросов – в два раза медленнее обслуживаем.
Такой подход позволит:
- рассмотреть то, что произойдет в лучшем случае;
- снять точные метрики.
Навигация по графику:
- синий – количество запросов к серверу;
- зеленый – ответы сервера;
- желтый – таймауты;
- темно-серый – запросы, которые зря тратили ресурсы сервера, так как клиент не дождался ответа по таймауту. Иногда клиент может сообщить об этом серверу обрывом соединения, но в общем случае такая роскошь может быть технически неосуществима, например, если сервер делает CPU-bound работу, без кооперации с клиентом.

Почему график запросов клиента (синий на диаграмме) получился именно таким? Обычно график заказов в наших пиццериях плавненько растет утром и убывает вечером. Но мы наблюдаем три пика на фоне обычной равномерной кривой. Эта форма графика выбрана для модели не случайно, а по поводу. Модель родилась при расследовании реального инцидента с сервером контакт-центра пиццерий в России во время чемпионата мира по футболу.
Кейс «Чемпионат мира по футболу»
Мы сидели и ждали, что у нас будет больше заказов. К Чемпионату подготовились, теперь серверы смогут пройти проверку на прочность.
Первый пик – любители футбола идут смотреть чемпионат, они голодны и покупают пиццу. Во время первого тайма они заняты и не могут заказывать. Но равнодушные к футболу люди могут, поэтому на графике дальше все идет как обычно.
И вот кончается первый тайм, и наступает второй пик. Болельщики перенервничали, проголодались и сделали в три раза больше заказов, чем в первый пик. Пицца покупается со страшной скоростью. Потом начинается второй тайм, и снова не до пиццы.
Тем временем, сервер контакт-центра начинает потихоньку загибаться и обслуживать запросы все медленнее и медленнее. Компонент системы, в данном случае – веб-сервер Колл-центра, дестабилизирован.
Третий пик наступит, когда матч закончится. Болельщиков и систему ждет пенальти.
Разбираем причины падения сервера
Что произошло? Сервер мог удерживать 100 условных запросов. Мы понимаем, что он рассчитан на эту мощность и больше не выдержит. Приходит пик, который сам по себе не такой большой. Зато серая область Concurrency гораздо выше.
Модель рассчитана так, что Concurrency численно равна количеству заказов в секунду, поэтому визуально на графике оно должно быть такого же масштаба. Однако оно гораздо выше, потому что накапливается.
Мы видим здесь тень от графика – это запросы стали возвращаться к клиенту, выполняться (показано первой красной стрелкой). Масштаб времени здесь условный, чтобы увидеть смещение во времени. Второй пик уже выбил наш сервер. Он упал и стал обрабатывать вчетверо меньше запросов, чем в обычное время.

На второй половине графика видно, что какие-то запросы все-же сначала выполнялись, но потом появились желтые пятна – запросы перестали выполняться совсем.

Еще раз весь график. Видно, что Concurrency зашкаливает. Появляется огромная гора.

Обычно мы анализировали совсем другие метрики: насколько медленно запрос выполнялся, сколько запросов в секунду. А на Concurrency вообще не смотрим, даже не думали про эту метрику. А зря, потому что именно эта величина лучше всего показывает момент отказа сервера.
Но откуда взялась такая огромная гора? Самый большой пик нагрузки-то давно уже прошёл!
Закон Литтла
Закон Литтла регулирует Concurrency.
L (количество клиентов внутри системы) = λ (скорость их пребывания) ∗ W (время, которое они проводят внутри системы)
Это в среднем. Однако у нас ситуация развивается драматически, нас среднее не устраивает. Мы это уравнение будем дифференцировать, потом интегрировать. Для этого посмотрим в книгу Джона Литтла, который эту формулу придумал, и увидим там интеграл.

У нас есть количество поступлений в систему и количество тех, кто уходит из системы. Запрос поступает и уходит, когда все выполнено. Ниже изображен регион графика роста, соответствующий линейному росту Concurrency.

Зеленых запросов мало. Это те, которые реально выполняются. Синие – те, которые поступают. Между таймами у нас обычное количество запросов, ситуация стабильная. Но Concurrency все равно растет. Сервер уже не справится с этой ситуацией сам. Это значит, что скоро он упадет.
Но почему Concurrency растет? Смотрим на интеграл константы. У нас ничего не меняется в системе, но интеграл выглядит как линейная функция, которая растет только вверх.
Поиграем?
Объяснение с интегралами сложновато, если не помнить математики. Тут предлагаю размяться и сыграть в игру.
Игра № 1
Предусловия: На сервер поступают запросы, каждый требует три периода обработки на CPU. Ресурс CPU делится равномерно между всеми задачами. Это похоже на то, как расходуется ресурс CPU при Preemptive Multitasking. Число в клетке означает количество работы, оставшейся после данного такта. За каждый условный такт поступает новый запрос.
Представьте, что поступил запрос. Всего 3 единицы работы, по завершении первого периода обработки осталось 2 единицы.
Во втором периоде наслаивается еще один запрос, теперь оба CPU заняты. Они сделали по единице работы по первым двум запросам. Осталось доделать 1 и 2 единицы для первого и второго запроса соответственно.
Теперь пришел третий запрос, и начинается самое интересное. Казалось бы, первый запрос должен был быть завершен, но в этом периоде уже три запроса делят между собой ресурс CPU, поэтому степени завершенности для всех трех запросов теперь дробные по завершении третьего периода обработки:

Дальше еще интереснее! Добавляется четвертый запрос, и теперь степень Concurrency уже 4, так как всем четырем запросам потребовался ресурс в этом периоде. Тем временем, первый запрос к концу четвертого периода уже выполнился, в следующий период он не переходит, и ему осталось 0 работы для CPU.
Так как первый запрос уже выполнился, подведем итог для него: он выполнялся на треть дольше, чем мы ожидали. Предполагалось, что длина каждой задачи по горизонтали в идеале = 3, по количеству работы. Помечаем его оранжевым, в знак того, что мы не совсем довольны результатом.

Поступает пятый запрос. Степень Concurrency по прежнему 4, но мы видим, что в пятом столбике оставшейся работы в сумме больше. Это происходит, потому что в четвертом столбике оставалось больше несделанной работы, чем в третьем.
Продолжаем еще три периода. Ждем ответов.
– Сервер, алё!
–…

– Ваш звонок очень важен для нас…

Ну вот, наконец-то пришел ответ на второй запрос. Время ответа вдвое дольше, чем ожидалось.

Степень Concurrency выросла уже втрое, и ничто не предвещает, что ситуация изменится к лучшему. Я не рисовал дальше, потому что время ответа на третий запрос уже не влезет в картинку.
Наш сервер вошел в нежелательное состояние, из которого он никогда не выйдет самостоятельно. Game over.
Чем характеризуется GameOver-состояние сервера?
Запросы накапливаются в памяти неограниченно. Рано или поздно попросту закончится память. Кроме этого, при увеличении масштаба возрастают накладные затраты на CPU на обслуживание различных структур данных. Например, пул соединений теперь должен отслеживать таймауты большего количества соединений, сборщик мусора теперь должен перепроверять большее количество объектов на хипе, и так далее.
Исследовать все возможные последствия накопления активных объектов не является целью этой статьи, но даже простого накопления данных в оперативной памяти уже достаточно, чтобы завалить сервер. Кроме того, мы уже рассмотрели, что сервер-клиент проецирует свои проблемы Concurrency на сервер базы данных, и другие сервера, которые он использует как клиент.
Самое интересное: теперь даже если подать на сервер меньшую нагрузку, он все равно не восстановится. Все запросы будут заканчиваться таймаутом, а сервер будет расходовать все доступные ресурсы.
А чего мы, собственно, ожидали?! Ведь мы заведомо дали серверу количество работы, с которым он не справится.
Когда занимаешься архитектурой распределенной системы, полезно подумать, как обычные люди решают такие проблемы. Возьмем, например, ночной клуб. Он перестанет функционировать, если туда зайдет слишком много людей. Вышибала справляется с проблемой просто: смотрит, сколько человек внутри. Один вышел – другого запускает. Новый гость придет и оценит размер очереди. Если очередь большая, уйдет домой. Что если применить этот алгоритм для сервера?

Давайте поиграем еще раз.
Игра № 2
Предусловия: Опять у нас два CPU, такие же задачи по 3 единицы, поступающие каждый период, но теперь мы поставим вышибалу, и задачи будут умные — если они видят, что длина очереди 2, то сразу идут домой.


Пришел третий запрос. В этом периоде он стоит в очереди. У него число 3 по окончании периода. Дробных чисел в остатках нет, потому что два CPU выполняют две задачи, по единице за период.
Хотя у нас три запроса наслаиваются, степень Concurrency внутри системы = 2. Третий стоит в очереди и не считается.

Пришел четвертый – та же картина, хотя уже накопилось больше оставшейся работы.

…
…
В шестом периоде третий запрос выполнился с отставанием на треть, и степень Concurrency уже = 4.

Степень Concurrency возросла в два раза. Больше она не может вырасти, ведь мы установили на это явный запрет. С максимальной скоростью выполнились только два первых запроса – те, кто пришел в клуб первыми, пока для всех хватало места.
Жёлтые запросы находились в системе дольше, но они стояли в очереди и не оттягивали на себя ресурс CPU. Поэтому те, кто был внутри спокойно развлекались. Это могло продолжаться и дальше, пока не пришел мужик и не сказал, что в очереди стоять не будет, а лучше отправится домой. Это невыполненный запрос:

Ситуация может повторяться бесконечно, при этом время выполнения запросов остается на одном уровне – ровно вдвое дольше, чем хотелось бы.

Мы видим, что простое ограничение уровня Concurrency устраняет проблему жизнеспособности сервера.
Как увеличить жизнеспособность сервера через ограничение уровня Concurrency
Простейшего «вышибалу» можно написать самому. Ниже привожу код с использованием семафора. Тут нет ограничения длины очереди снаружи. Код только для иллюстрации, не нужно его копировать.
const int MaxConcurrency = 100;
SemaphoreSlim bulkhead = new SemaphoreSlim(MaxConcurrency, MaxConcurrency);
public async Task ProcessRequest()
{
if (!await bulkhead.WaitAsync())
{
throw new OperationCanceledException();
}
try { await ProcessRequestInternal(); return; }
finally { bulkhead.Release(); }
}Чтобы создать ограниченную очередь, нужно два семафора. Для этого подходит библиотека Polly, которую рекомендует Microsoft. Обратите внимание на паттерн Bulkhead. Дословно переводится как «переборка» – элемент конструкции, позволяющий судну не тонуть. Если честно, я считаю, что лучше подходит термин «вышибала». Важно то, что этот паттерн позволяет серверу выживать в безнадежных ситуациях.
Сначала мы на нагрузочном стенде выдавливаем из сервера все, что можно, пока не определяем, сколько запросов он может держать. Например, мы определили, что это 100. Ставим bulkhead.
Дальше сервер пропустит только нужное количество запросов, остальные будут стоять в очереди. Разумно будет выбрать несколько меньшее число, чтобы был запас. Готовой рекомендации на этот счет у меня нет, потому что есть сильная зависимость от контекста и конкретной ситуации.
- Если поведение сервера стабильно зависит от нагрузки с точки зрения ресурсов, то это число может приближаться к пределу.
- Если среда подвержена флуктуациям нагрузки, следует выбрать более консервативное число, с учетом размера этих флуктуаций. Такие флуктуации могут возникать по разным причинам, например, для среды исполнения с GC характерны небольшие пики нагрузки на CPU.
- Если сервер выполняет периодические задачи по расписанию, это также следует учесть. Можно даже разработать адаптивную переборку, которая будет вычислять, сколько можно давать одновременно запросов без деградации сервера (но это уже выходит за рамки данного исследования).
Эксперименты с запросами
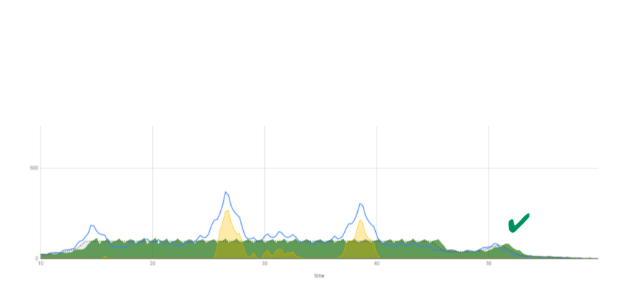
Взгляните на этот постмортем напоследок, больше мы такого не увидим.

Вся эта серая куча однозначно коррелирует с падением сервера. Серое – смерть для сервера. Попробуем просто срезать это и посмотреть, что произойдет. Кажется, что какое-то количество запросов пойдет домой, просто не выполнится. Но сколько?
100 внутри, 100 снаружи

Оказалось, нашему серверу стало жить очень хорошо и весело. Он постоянно пашет на максимальной мощности. Конечно, когда происходит пик, его вышибает, но совсем ненадолго.
Окрыленные успехом попробуем сделать так, чтобы его совсем не вышибало. Попробуем увеличить длину очереди.
100 внутри, 500 снаружи

Стало получше, но вырос хвост. Это те запросы, которые еще долго потом выполняются.
100 внутри, 1000 снаружи
Раз уж что-то стало лучше, попробуем довести до абсурда. Разрешим длину очереди в 10 раз больше, чем можем обслуживать одновременно:

Если говорить о метафоре клуба и вышибалы, такая ситуация вряд ли возможна – никто не захочет ждать на входе дольше, чем проведет времени в клубе. Мы также не будем делать вид, что это нормальная ситуация для нашей системы.
Лучше вообще не обслуживать клиента, чем томить его на сайте или в мобильном приложении загрузкой каждого экрана по 30 секунд и портить репутацию компании. Лучше сразу честно сказать малой части клиентов, что сейчас мы не можем их обслужить. В противном случае, мы будем в несколько раз медленнее обслуживать всех клиентов, ведь график показывает, что ситуация сохраняется довольно долго.
Есть и еще один риск – другие компоненты системы могут быть не рассчитаны на такое поведение сервера, и, как мы уже знаем, Concurrency проецируется на клиентов.
Поэтому возвращаемся к первому варианту «100 на 100» и думаем, как масштабировать наши мощности.
Победитель – 100 внутри, 100 снаружи

¯\_(ツ)_/¯
При таких параметрах самая большая деградация по времени выполнения – ровно в 2 раза от «номинала». В то же время – это 100% деградация по времени выполнения запроса.
Если ваш клиент чувствителен ко времени выполнения (а это, как правило, справедливо, как с клиентами-людьми, так и с клиентами-серверами), то можно подумать о дальнейшем снижении длины очереди. В этом случае, мы можем брать какой-то процент от внутренней Concurrency, и будем точно знать, что сервис деградирует по времени ответа не больше, чем на этот процент в среднем.
По сути мы не пытаемся создать очередь, мы пытаемся защититься от флуктуаций нагрузки. Здесь так же, как и в случае определения первого параметра переборки (количество внутри), полезно определить, какие флуктуации нагрузки может накинуть клиент. Так мы будем знать, в каких случаях мы, грубо говоря, упустим прибыль от потенциального обслуживания.
Еще важнее определить, какие флуктуации Latency могут выдержать взаимодействующие с сервером другие компоненты системы. Так мы будем знать, что действительно выжимаем из существующей системы максимум без опасности потерять обслуживание полностью.
Диагноз и лечение
Проблему Uncontrolled Concurrency мы лечим с помощью Bulkhead Isolation.
Этот метод, как и другие, рассматриваемые в этой серии статей, удобно реализовывать библиотекой Polly.
Преимущество метода в том, что отдельную компоненту системы будет крайне трудно дестабилизировать как таковую. Система приобретает очень предсказуемое поведение по части времени на выполнение успешных запросов и гораздо более высокие шансы на успешное выполнение запросов вцелом.
Однако мы не решаем всех проблем. Например, проблему недостаточной мощности сервера. В данной ситуации нужно заведомо решиться на «сбрасывание балласта» в случае скачка нагрузки, которую мы оценили как чрезмерную.
Дальнейшие меры, которые наше исследование не затрагивает, могут включать, например, динамическое масштабирование.
