
Наверное, все слышали про крутой фаззер AFL.
Многие используют его как основной фаззер для поиска уязвимостей и ошибок.
Недавно появился форк AFL, AFLSmart, который имеет интересное развитие идеи. Если верить документации, он может мутировать данные по заранее подготовленной модели, в то время как AFL применяет рандомные низкоуровневые операции. Однако, есть несколько подводных камней. Рассказываем об AFLSmart и разбираемся, что у него под капотом.
На самом деле этот форк появился несколько лет назад, но более-менее понятное описание было опубликовано только в августе 2019 года в статье Smart Greybox Fuzzing. Опубликованные данные показывают, что этот фаззер может увеличить скорость поиска багов. Например, авторы нашли 9 багов в FFmpeg за неделю. Мы решили опробовать AFLSmart в одном из своих проектов.
К сожалению, в индустрии информационной безопасности до сих пор нет четко устоявшего определения, что такое Grey-Box Fuzzing. Некоторые понимают под ним тот фаззинг, который имеет обратную связь от таргета для подготовки тестовых данных для улучшения покрытия (это honggfuzz, AFL и все его модификации). Другие понимают подход, при котором фаззер на старте уже имеет какую-то информацию о структуре входных данных и в процессе своей работы соблюдает это описание (не рассчитывая на случайность рандомных преобразований), чтобы не застревать и лучше продвигаться вглубь кода (наш сегодняшний пациент AFLSmart). Мы относимся ко второй категории. AFLSmart не единственный представитель Grey-Box подхода и, если вам интересна данная тема, советуем также обратить внимание на Superion и Nautilus.
Вернемся к нашему проекту. Объектом исследования стала не очень известная сетевая библиотека. Сейчас уже и не вспомнить, на что ушло больше времени — на исследование библиотеки или на понимание AFLSmart. Нам хотелось получить результат не хуже, чем у авторов вышеупомянутой статьи, поэтому мы уделили фаззеру пристальное внимание.
Проблема заключалась в том, что фаззер не вел себя предсказуемым образом и генерировал не те данные, которые мы от него ждали. Немного забегая вперед, отметим, что в AFLSmart есть недоработка, с которой можно столкнуться при создании более требовательной модели данных, чем в примерах у авторов статьи. Удивительно, что спустя год после публичного релиза никто не столкнулся с этим до нас.
Немного о наших ожиданиях. После прочтения white paper о AFLSmart сложилось впечатление, что он может и структуру данных соблюсти и сами данные промутировать так, чтобы значительно увеличить покрытие. То есть может учесть, что где находится, а также что и как можно и нельзя мутировать. Это очень важно, ведь многие форматы файлов и сетевых пакетов содержат различные magic words, контрольные суммы и т.д., при неверном значении которых дальнейшая обработка файла или пакета вообще не происходит, то есть нет никакого продвижения по покрытию нового кода. Мы рассчитывали, что как раз с помощью AFLSmart сможем решить эму проблему, описав ему известный нам формат.
T-Fuzz: fuzzing by program transformation
Идея в том, чтобы при фаззинге трансформировать не только входные данные, но и саму программу, чтобы увеличить покрытие путем удаления "hard" проверок.
Если кратко:
1) We show that fuzzing can more effectively find bugs by transforming the target program,
instead of resorting to heavy weight program analysis techniques.
2) We present a set of techniques that enable fuzzing to mutate both inputs and the programs, including techniques for
(i) automatic detection of sanity checks in the target program,
(ii) program transformation to remove the detected sanity checks,
(iii) reproducing bugs in the original program by filtering false positives that only crash in the transformed program.
Итак, AFLSmart — это связка двух фаззеров: AFL и Peach. Если вы сталкивались с Peach, то знаете, что для работы он требует модель, по которой будут генерироваться данные (т.к. это генерационный фаззер). Можно просто описать формат данных в выбранном приложении, но можно также и дать указания относительно того, что можно мутировать и что нельзя. Например, нельзя трогать magic words, если вы уверены, что они точно нужны.
Как выяснилось, Peach здесь нужен, только чтобы по модели разбивать входные тест-кейсы на части (чанки). Это просто парсер, а генерацией занимаются добавленные в AFL мутаторы, и ошибка была в них. Вы увидите, что, хотя пофиксить ее было легко, нам пришлось попутно разобраться во всех нюансах, чтобы быть уверенными, что это единственное проблемное место.
Для наглядности возьмем pcap файл, он имеет следующий формат:
PcapHeader
| bytes | type | Name | Description |
|---|---|---|---|
| 4 | uint32 | magic | 'A1B2C3D4' means the endianness is correct |
| 2 | uint16 | vmajor | major number of the file format |
| 2 | uint16 | vminor | minor number of the file format |
| 4 | int32 | thiszone | correction time in seconds from UTC to local time (0) |
| 4 | uint32 | sigfigs | accuracy of time stamps in the capture (0) |
| 4 | uint32 | snaplen | max length of captured packed (65535) |
| 4 | uint32 | network | type of data link (1 = ethernet) |
Frame
| bytes | type | Name | Description |
|---|---|---|---|
| 4 | uint32 | ts_sec | timestamp seconds |
| 4 | uint32 | ts_usec | timestamp microseconds |
| 4 | uint32 | incl_len | number of octets of packet saved in file |
| 4 | uint32 | orig_len | actual length of packet |
| incl_len | uint32 | data | data |
pcap файлы, конечно, имеют и другие поля в Frame(Ethernet Header, IPv4, UDP), но мы не будем их детально описывать и, чтобы облегчить задачу, спрячем в поле data.
Соответствующая модель для Peach будет выглядеть так:
<Defaults>
<Number signed="false" valueType="hex" endian="little"/>
</Defaults>
<DataModel name="PcapHeader">
<Number name="magic" size="32" mutable="false"/>
<Number name="vmajor" size="16"/>
<Number name="vminor" size="16"/>
<Number name="thiszone" size="32"/>
<Number name="sigfigs" size="32"/>
<Number name="snaplen" size="32"/>
<Number name="network" size="32"/>
</DataModel>
<DataModel name="Frame">
<Number name="ts_sec" size="32"/>
<Number name="ts_usec" size="32"/>
<Number name="incl_len" size="32">
<Relation type="size" of="data"/>
</Number>
<Number name="orig_len" size="32"/>
<Blob name="data"/>
</DataModel>
<DataModel name="Pcap">
<Block name="PHeader" ref="PcapHeader"/>
<Block name="PFrame" ref="Frame" maxOccurs="100000"/>
</DataModel>Теперь посмотрим, какие новые мутаторы, работающие с этой моделью, добавили в оригинальный AFL и в чем, собственно, была проблема.
Высокоуровневые мутаторы
На самом деле, мутации производятся тремя несложными способами.
Удаление чанка
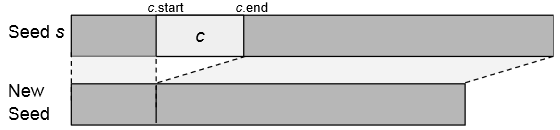
Seed s — это валидный файл, у которого мутатор удалит чанк c с координатами c.start, c.end. Координаты — это смещения от начала файла. Например, у pcap файлов сначала идет константа A1B2C3D4, следовательно, c.start=0, c.end=3.
Добавление чанка
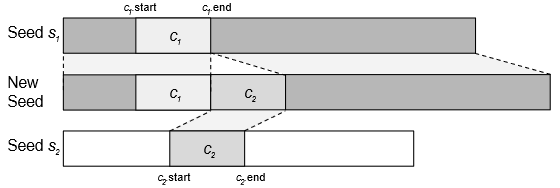
Фаззер выбирает произвольный чанк c2 из одного файла и вставляет его сразу за c1 в другом файле. Здесь важно, чтобы у обоих чанков были родители одного типа. Этот мутатор не добавит чанк timestamp к константе A1B2C3D4 в случае с pcap файлом. Но он может добавить version_major, потому что и константа и version_major относятся к PCAP Packet Header.
Замена чанка
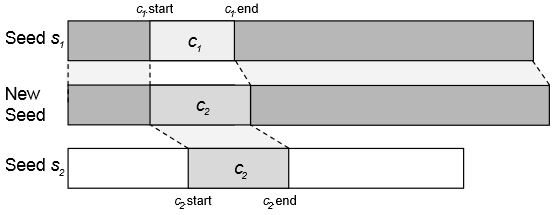
Этот мутатор просто меняет произвольный чанк c1 на c2. Учитывается, что у чанков может быть разный размер.
Также стоит разобраться, откуда берутся эти координаты.
Как уже было сказано, Peach выполняет роль парсера — он разбивает тест-кейс на чанки.
Можно увидеть, как это работает:
peach -1 -inputFilePath=valid_file -outputFilePath=valid_file.chunks model.xmlСгенерированный valid_file.chunks будет содержать смещения всех чанков.
Вот как это выглядит в случае с pcap и этим файлом:
0,95,Pcap,Enabled
0,23,Pcap~PHeader,Enabled
0,3,Pcap~PHeader~magic,Disabled
4,5,Pcap~PHeader~vmajor,Enabled
6,7,Pcap~PHeader~vminor,Enabled
8,11,Pcap~PHeader~thiszone,Enabled
12,15,Pcap~PHeader~sigfigs,Enabled
16,19,Pcap~PHeader~snaplen,Enabled
20,23,Pcap~PHeader~network,Enabled
24,95,Pcap~PFrame,Enabled
24,95,Pcap~PFrame~PFrame,Enabled
24,27,Pcap~PFrame~PFrame~ts_sec,Enabled
28,31,Pcap~PFrame~PFrame~ts_usec,Enabled
32,35,Pcap~PFrame~PFrame~incl_len,Enabled
36,39,Pcap~PFrame~PFrame~orig_len,Enabled
40,95,Pcap~PFrame~PFrame~data,EnabledПросто смещения, имена и значение атрибута mutable.
Вот с этим атрибутом и была проблема.
Проблема
Каждый чанк в модели может иметь атрибут mutable=false, который укажет фаззеру не трогать его содержимое. Это может потребоваться, если есть magic word, как у pcap файлов, например, — A1B2C3D4.
Однако, AFLSmart упрямо игнорировал это. Он верно парсил значение, но данные все равно подвергал мутациям. В AFLSmart есть опция запуска дебага -l, она включает логирование результатов высокоуровневых мутаций, логи можно потом смотреть в папке {out}/log.
Пришлось лезть внутрь и разбираться, в чем дело. Все оказалось проще некуда.
Представление чанка в памяти имеет следующий вид:
struct chunk {
unsigned long
id; /* The id of the chunk, which either equals its pointer value or, when
loaded from chunks file, equals to the hashcode of its chunk
identifer string casted to unsigned long. */
int type; /* The hashcode of the chunk type. */
int start_byte; /* The start byte, negative if unknown. */
int end_byte; /* The last byte, negative if unknown. */
char modifiable; /* The modifiable flag. */
struct chunk *next; /* The next sibling child. */
struct chunk *children; /* The children chunks linked list. */
};Мы видим поле modifiable. Оно принимает значение 0, если чанк нельзя модифицировать, и 1 — если можно.
Логично предположить, что это поле должно где-то проверяться.
Быстрый поиск по исходникам привел нас к выводу, что он не проверяется нигде. Хотя есть две функции, где это можно сделать.
Функция get_chunk_to_delete выдает рандомный чанк на удаление, но проверяет лишь его координаты:
struct chunk *get_chunk_to_delete(struct chunk **chunks_array, u32 total_chunks,
u32 *del_from, u32 *del_len) {
struct chunk *chunk_to_delete = NULL;
u8 i;
*del_from = 0;
*del_len = 0;
for (i = 0; i < 3; ++i) {
int start_byte;
u32 chunk_id = UR(total_chunks);
chunk_to_delete = chunks_array[chunk_id];
start_byte = chunk_to_delete->start_byte;
if (start_byte >= 0 &&
chunk_to_delete->end_byte >= start_byte) {
*del_from = start_byte;
*del_len = chunk_to_delete->end_byte - start_byte + 1;
break;
}
}То же самое и с функцией get_target_to_splice, которая выдает чанк, который будет заменен:
struct chunk *get_target_to_splice(struct chunk **chunks_array,
u32 total_chunks, int *target_start_byte,
u32 *target_len, u32 *type) {
struct chunk *target_chunk = NULL;
u8 i;
*target_start_byte = 0;
*target_len = 0;
*type = 0;
for (i = 0; i < 3; ++i) {
u32 chunk_id = UR(total_chunks);
target_chunk = chunks_array[chunk_id];
*target_start_byte = target_chunk->start_byte;
if (*target_start_byte >= 0 &&
target_chunk->end_byte >= *target_start_byte) {
*target_len = target_chunk->end_byte - *target_start_byte + 1;
*type = target_chunk->type;
break;
}
}
return target_chunk;
}В общем, дело решилось добавлением проверок поля modifiable в этих функциях и пулл-реквестом в репозиторий AFLSmart. Авторы внесли изменения.
Итак, теперь можно рассмотреть, как именно работает AFLSmart и какие у него есть режимы.
Режимы работы AFLSmart
Режимов работы у AFLSmart два, и выбор режима зависит от того, насколько вам нужны родные мутаторы AFL(низкоуровневые).
В режиме по умолчанию сначала работают высокоуровневые операторы. При этом, если результат их работы не приведет к увеличению покрытия, будет применен низкоуровневый мутатор splicing. Он берет исходный кейс и случайный кейс, затем меняет часть содержимого исходного (второй кейс выступает источником). Фаззер далее смотрит, насколько это улучшит ситуацию с покрытием.
Во втором режиме фаззер сначала меняет кейс через высокоуровневые мутаторы, а затем результат прокручивается через рандомные низкоуровневые. Как вы понимаете, низкоуровневые мутаторы уже не учитывают формат и с легкостью могут попортить поля, которые трогать нельзя. Нужно это понимать и учитывать. Этот режим называется stacking и включается опцией -h.
Появилась, кстати, классная опция -e <ext>: она подставит расширение <ext> в текущий кейс. Оригинальный AFL пишет очередной тест-кейс в файл {out}/.cur_input, но бывают приложения, которые проверяют расширение и ожидают на вход, например, {out}/.cur_input.png|wav|avi и т.д. Если нет правильного расширения, файл будет просто отброшен. Поэтому разработчики добавили такую функцию.
Итог
После устранения недоработки фаззинг с AFLSmart у нас все равно не взлетел. Исследуемая нами библиотека запускает несколько потоков, и AFLSmart начинает сходить с ума, потому что один и тот же тест-кейс может обнаружить разные пути, а стандартные рекомендации для нас не сработали. Таков механизм оригинального AFL, он изначально создавался под парсеры файлов, а не для работы с сетевыми пакетами асинхронного сервера.
Смотрите сами, авторы демонстрируют, что нашли 42 zero-day уязвимостей в нескольких популярных приложениях. Это все парсеры, с которыми может справиться AFLSmart из коробки.
Это ограничение можно преодолеть, если допилить clang модуль afl-llvm-pass.so и заставить его инструментировать только код, ответственный за парсинг пакетов. Также в AFL и AFLSmart можно загрузить свой bitmap и заставить игнорировать пути в других потоках. Но об этом в следующий раз.
