
Прим. перев.: Это продолжение цикла статей от технологического евангелиста из AWS (Adrian Hornsby) про довольно новую ИТ-дисциплину — chaos engineering, — в рамках которой инженеры проводят эксперименты, призванные смягчить последствия сбоев в системах. Первый материал этого цикла рассказывал про концепцию chaos engineering в целом, второй — о том, как эта деятельность способствует позитивным культурным изменениям внутри организаций.

Последний материал посвящён практике хаос-инжиниринга: методам экспериментирования и инструментам для их непосредственной реализации. Несмотря на то, что его перевод уже публиковался на днях на хабре, у нас готова своя версия, которая кажется нам качественной и по-прежнему уместной для размещения. Так весь цикл перевода этих статей был представлен в едином стиле и наши подписчики — читатели прошлых частей — увидят его полностью.
Прим. автора: Хочу выразить искреннюю признательность своему другу Ricardo Sueiras за его вклад в подготовку этой публикации и за то, что он помог мне сдвинуться с мертвой точки. Рикардо, ты крут!
«Мы становимся тем, что лицезреем. Сначала мы формируем свои инструменты, а затем они формируют нас». — Маршалл Маклюэн (канадский философ, прославившийся своими исследованиями в области коммуникаций; первое предложение этой цитаты, впрочем, заимствовано у британского поэта Уильяма Блейка — прим. перев.)
Важно помнить, что смысл хаос-инжиниринга вовсе НЕ в том, чтобы выпустить «обезьянок» на свободу и позволить им внедрять сбои случайным образом и бесцельно. Наоборот, это четко определенный, формализованный научный метод экспериментирования.
Хаос-инжиниринг начинается с понимания устойчивого состояния системы. За этим следует формулировка гипотезы и, наконец, проверка и анализ результатов экспериментов ради повышения отказоустойчивости системы.

Этапы хаос-инжиниринга
В первой части данной серии статей я изложил концепцию хаос-инжиниринга и рассмотрел каждый шаг процесса, изображенного выше.
Во второй части — рассказал о направлениях, с которых следует начинать разработку экспериментов, и о том, как выбрать правильную гипотезу.
В этой, третьей, части речь пойдет о самих экспериментах. Будет представлена коллекция инструментов и методов, покрывающих широкий спектр возможностей по «внесению неисправностей» (fault injection или failure injection), необходимый для проведения экспериментов хаос-инжиниринга.
Список нельзя назвать исчерпывающим, однако его вполне достаточно для начала и того, чтобы заложить основу для дальнейших размышлений.
Внедрение неисправностей в систему позволяет понять и проверить, соответствует ли спецификациям её реакция на стрессовые условия. Впервые эта методика использовалась для провоцирования неисправностей на аппаратном уровне — в частности, на уровне контактов — путём изменения электрических сигналов на устройствах.
В разработке программного обеспечения внесение неисправностей помогает повысить отказоустойчивость системы и устранить потенциально слабые места. Этот процесс получил название «устранение неисправностей» (fault removal). Также он помогает прикинуть потенциальные последствия сбоя — то есть его радиус поражения — ещё до того, как нечто подобное случится в production. Это называется «прогнозированием неисправностей» (failure forecasting).
У внесения неисправностей есть несколько важных плюсов. Оно помогает:
Внедрение неисправностей подразделяется на пять категорий:
Далее я рассмотрю каждую категорию и приведу пример внесения неисправности для каждой из них. Кроме того, расскажу о некоторых комплексных инструментах для внесения сбоев и управления ими.
* Примечание: в этой статье не будет рассматриваться внесение неисправностей на уровне персонала. Эту тему затрону в отдельной публикации.
Хотя облачные услуги приучили нас к тому, что ресурсы практически безграничны, вынужден вас разочаровать: это не так. Экземпляр, контейнер, функция и т.д. — независимо от уровня абстракции, ресурсы рано или поздно закончатся. Проверкой устойчивости системы, поставленной в условия жесткой нехватки ресурсов, и занимается подход с названием «исчерпание ресурсов» (resource exhaustion).

Исчерпание ресурсов обычно выглядит как DoS-атака (правда, не совсем привычная), стремящаяся помешать работе целевого хоста. Это довольно популярный способ внесения неисправностей — возможно, по той причине, что его легко реализовать.
Один из моих любимых инструментов — stress-ng, реинкарнация оригинальной утилиты, которую разработал Amos Waterland.
С помощью stress-ng можно внедрить неисправности в различные физические подсистемы компьютера, а также в интерфейсы ядра ОС, используя «стрессоры» (stressors). Они доступны для: CPU, кэша CPU, устройств, ввода/вывода, прерываний, файловой системы, памяти, сети, операционной системы, конвейеров, планировщиков, виртуальных машин. Страницы руководства включают полное описание всех доступных стресс-тестов, коих насчитывается целых 220 штук!
Вот несколько полезных примером применения stress-ng:
Используйте dd чрезвычайно осторожно! Ошибка в команде может стереть, уничтожить или перезаписать данные на жёстком диске!
Производительность, отказоустойчивость и масштабируемость API имеют большое значение. В самом деле, API позволяют компаниям совершенствовать свои приложения и развивать бизнес.
Нагрузочное тестирование (load testing) — отличная возможность испытать приложение, прежде чем оно попадёт в production. Также это превосходный метод стресс-тестирования, позволяющий выявить проблемы и ограничения, которые в противном случае могли бы проявиться только при реальной нагрузке.
Вот отличная отправная точка:
Эта команда запускает 12 потоков и держит открытыми 400 HTTP-подключений в течение 20 секунд.
Eight Fallacies of Distributed Computing от Peter'а Deutsch'а — это набор из предположений, которыми руководствуются разработчики при проектировании распределённых систем. Однако они часто оборачиваются против них, вызывая перебои в работе системы и заставляя менять её архитектуру. Вот эти предположения:
Этот список, по сути, представляет собой готовый перечень направлений для внесения неисправностей и проверки способности распределенной системы противостоять сетевым сбоям.
tc можно использовать для имитации задержки и потери пакетов для UDP- или TCP-приложений, а также для ограничения пропускной способности сети для конкретного сервиса с целью имитировать реальное перемещение трафика в интернете.
— Внедряем задержку в 100 мс:
— Внедряем задержку в 100 мс с дельтой в 50 мс:
— Имитируем повреждение 5 % сетевых пакетов:
— Имитируем потерю 7 % пакетов с корреляцией в 25 %:
Примечание: 7 % позволяют сохранить работоспособность TCP.
Файл hosts — один из нескольких способов, с помощью которых компьютер сопоставляет сетевые узлы в компьютерной сети и переводит понятные для человека домены в IP-адреса. Как вы уже догадались, он отлично подходит и для запутывания компьютеров. Вот несколько примеров:
— Блокируем доступ к API DynamoDB из экземпляра EC2:
— Блокируем доступ экземпляра EC2 к API EC2:
Вот пример работы с этим файлом. Изначально API EC2 доступен, и команда
Но как только я добавляю строку

Конечно, этот метод работает для всех endpoint'ов AWS.

Идёт обновление кэша DNS…
… только вам потребуется 24 часа, чтобы его понять.
21 октября 2016 году DDoS-атака на Dyn привела к тому, что значительное число интернет-платформ и сервисов оказались недоступны в Европе и Северной Америке. Согласно отчёту ThousandEyes Global DNS Performance за 2018 год, 60 % компаний и SaaS-провайдеров по-прежнему полагаются на один источник DNS и, следовательно, уязвимы перед сбоями DNS. Поскольку без DNS нет и интернета, разумно имитировать падение этой службы, чтобы проверить устойчивость системы к возможному отказу DNS.
Традиционно для борьбы с DDoS-атаками используется така называемый blackholing — метод, в котором «плохой» сетевой трафик отправляется прямиком в «чёрную дыру» и выбрасывается в пустоту (этакая сетевая версия
С этой работой прекрасно справится iptables. Эта утилита используется для настройки, обслуживания и анализа таблиц с правилами фильтрации IP-пакетов в ядре Linux.
Чтобы отправить DNS-трафик в «чёрную дыру», попробуйте сделать следующее:
Один из главных недостатков инструментов под Linux, таких как
Toxiproxy — это TCP-прокси с открытым исходным кодом, разработанный инженерной командой Shopify. Он помогает имитировать хаотические сетевые и системные условия из реальной жизни. Для этого достаточно поместить Toxiproxy между компонентами инфраструктуры, как показано на иллюстрации ниже:
Слайд из выступления Simon'а Eskildsen'а, главы команды production-разработки, Shopify
Этот инструмент специально разработан для окружений с тестами, CI и разработкой, он поддерживает детерминированный или рандомизированный хаос, а также кастомизацию. Toxiproxy манипулирует соединением между клиентом и upstream'ом с помощью так называемых «токсиков» (toxics) и поддерживает настройку через HTTP API. Кроме того, инструмент поставляется с набором предустановленных токсиков.
В примере ниже показывается, как Toxiproxy с помощью downstream-токсика увеличивает задержку на 1000 мс между клиентом Redis, redis-cli и самой Redis:

Начиная с октября 2014 года Toxiproxy с успехом используется во всех development- и test-средах в Shopify. Подробности о Toxiproxy можно узнать из этой записи в блоге.
Программы падают. Это общеизвестный факт. Что делать, если произошел сбой? Следует ли зайти на сервер по SSH и перезапустить упавший процесс? Системы контроля процессов позволяют следить за состоянием процесса или изменять его с помощью таких директив, как start, stop, restart. Эти системы обычно реализуются для постоянного контроля за процессом. Одним из таких инструментов является
Эти инструменты следует использовать при деплое приложений. Конечно, прежде всего надо изучить последствия от падений критических процессов. Убедитесь, что получаете соответствующие уведомления, а процессы перезапускаются в автоматическом режиме:
— «Убийство» Java-процессов:
— «Убийство» процессов Python:
Конечно, с помощью
Если и есть сбои, жалобы на которые терпеть не может поддержка, так это те, которые имеют отношение к базам данных. Данные ценятся на вес золота, и всякий раз, когда происходит сбой в БД, возрастает риск потери данных клиентов.

В некоторых случаях способность как можно быстрее восстановить данные и вернуть систему в работоспособное состояние может определить судьбу компании. К сожалению, подготовиться ко всему разнообразию сбоев баз данных непросто, и многие из них проявляются только в production.
Впрочем, если вы используете Amazon Aurora, то можете проверить отказоустойчивость кластера баз данных Amazon Aurora путем специальных запросов с внедрением ошибок.
Запросы со сбоями в виде SQL-команд направляются экземпляру Amazon Aurora и позволяют запланировать «возникновение» одного из следующих событий:
Отправляя запрос со сбоем, вы также указываете желаемую продолжительность имитации неисправности.
— Падение экземпляра Amazon Aurora:
— Имитация отказа реплики Aurora:
— Имитация выхода из строя диска в кластере с БД Aurora:
— Имитация повышенной загрузки диска в кластере с БД Aurora:
Внедрять сбои может быть непросто, если вы используете serverless-компоненты, поскольку управляемые serverless-сервисы вроде AWS Lambda изначально не поддерживают внесение неисправностей.
Чтобы решить эту проблему, я написал небольшую библиотеку на Python и лямбда-слой для внедрения сбоев в AWS Lambda. Оба в настоящее время поддерживают задержки, ошибки, исключения и внедрение кодов ошибок HTTP.
Само внесение неисправностей осуществляется путём задания следующих параметров в AWS SSM Parameter Store:
Можно добавить декоратор Python в функцию-обработчик для внедрения неисправности.
— Вызываем исключение:
— Внедряем неправильный код ошибки HTTP:
— Внедряем задержку:
Чтобы узнать больше об этой Python-библиотеке, перейдите по ссылке.
Lambda по умолчанию использует механизм безопасности для параллельной (concurrent) работы всех функций в определённом регионе для каждой учётной записи. Под параллельной работой подразумевается число выполнений кода функции в любой момент времени. Оно используется для масштабирования вызовов функции в ответ на входящие запросы. Однако его же можно использовать для обратной цели: замедления работы Lambda.
Эта команда установит
Этот инструмент для наблюдения за serverless-архитектурой обладает встроенной возможностью внедрять неисправности в serverless-приложения. Thundra использует так называемые span listeners для внедрения сбоев, таких как отсутствие обработчика ошибок для DynamoDB, отсутствие резервного источника данных или отсутствие таймаута для исходящих HTTP-запросов. Я сам не пользовался этим инструментом, однако эта публикация от Yan Cui и это замечательное видео от Marcia Villalba прекрасно описывают процесс работы. Исходя из них, Thundra выглядит многообещающе.
Подводя черту под serverless-разделом, хочу порекомендовать всем отличную статью о сложностях хаос-инжиниринга в serverless-приложениях, которую написал уже упомянутый Yan Cui.
Хаос-инжиниринг начинался в инъекции сбоев на уровне инфраструктуры — как в случае Amazon, так и в случае Netflix. Пожалуй, инфраструктурные сбои: от отключения целого ЦОД и до случайной остановки экземпляров — реализовать проще всего.
И, естественно, первым на ум приходит пример с chaos monkey.
На заре своего существования Netflix озаботился разработкой и внедрением правильного подхода к архитектурным решениям. Chaos monkey стала одним из первых приложений, развернутых в AWS, которое следило на состоянием автомасштабируемых stateless-микросервисов. Другими словами, любой экземпляр мог быть остановлен и автоматически заменен без потери состояния. Chaos monkey следила за тем, чтобы никто не нарушал это правило.
Следующий скрипт — по аналогии с хаос-обезьянкой — случайным образом выбирает и останавливает экземпляр в определенной зоне доступности внутри региона:
Обратите внимание на

— «Да, было бы классно, если бы вы перезапустили базу…» — Упс, не тот экземпляр...
Высока вероятность, что вы ошеломлены всем разнообразием инструментов, о которых шла речь до настоящего момента. К счастью, есть несколько готовых пакетов по оркестрации и внедрению неисправностей, которые объединяют функциональность вышеперечисленных инструментов, делая это в простой и удобной форме.
Chaos Toolkit — один из моих любимейших инструментов подобного рода. Это целая Open Source-платформа для хаос-инжиниринга, поддерживаемая (на коммерческой основе) прекрасной командой ChaosIQ, включающей в числе прочих Russ Miles, Sylvain Hellegouarch и Marc Perrien.
Chaos Toolkit предлагает декларативный и расширяемый открытый API для экспериментов по организации хаоса. Он включает в себя драйверы для AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humio, Prometheus и Gremlin.
Расширения — это набор тестов и последовательностей действий для организации различных экспериментов — например, для случайной остановки экземпляров в определенной зоне доступности, если значение
Запустить этот эксперимент просто:
Преимущество Chaos Toolkit, во-первых, в открытых исходниках (поэтому его легко приспособить для конкретных потребностей). Во-вторых, он прекрасно интегрируется в CI/CD-пайплайн и поддерживает непрерывное хаос-тестирование.
Недостатком Chaos Toolkit'а является его сложность: чтобы начать работать, необходимо разобраться в его особенностях и принципах. Более того, в Toolkit'е нет готовых экспериментов: придётся написать свои собственные. Впрочем, команда ChaosIQ активно работает над устранением этого недостатка.
Другой мой любимый инструмент — Gremlin — включает в себя полный набор режимов внесения неисправностей в простой и удобной для использования форме с интуитивно понятным пользовательским интерфейсом — этакий вариант Chaos-as-a-Service.
Gremlin обеспечивает внедрение ошибок в ресурсы, состояния, сеть и запросы, позволяя экспериментировать с различными частями системы. Он поддерживает bare metal, различных поставщиков облачных услуг, контейнерные среды (включая Kubernetes*), приложения и (в некоторой степени) serverless-вычисления.
* Прим. перев.: Подробнее об использовании Gremlin в контексте Kubernetes (и не только) можно прочитать, например, в этой статье.
Бонусом идет отличный контент в блоге проекта. Кроме того, ребята из Gremlin по-настоящему круты и всегда готовы прийти на выручку! Прежде всего это Matthew, Kolton, Tammy, Rich, Ana и HML.
Работать с Gremlin'ом весьма просто.
Войдите в приложение и выберите Create Attack:
Выберите целевой экземпляр:
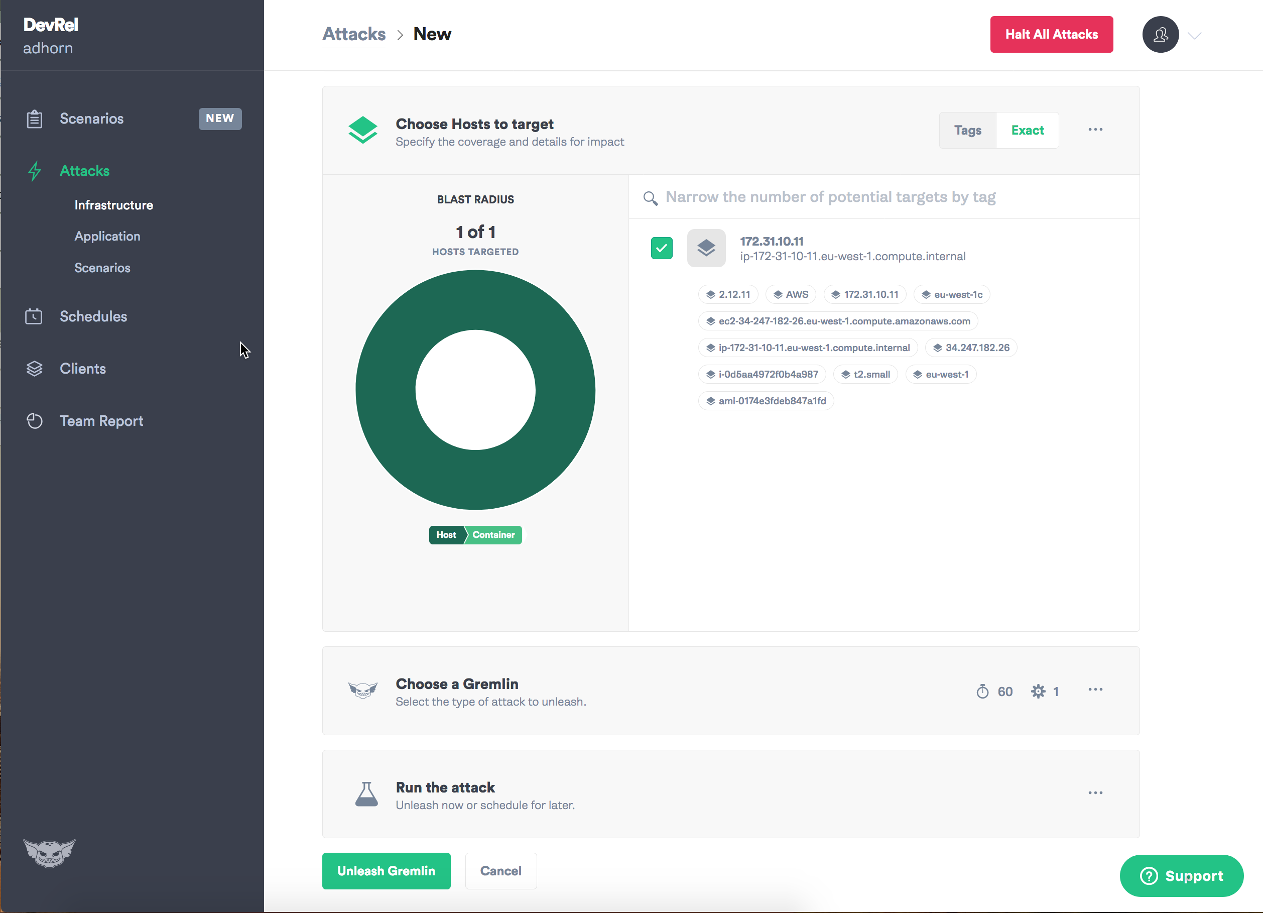
Выберите тип неисправности, которую хотите внедрить, и выпустите (unleash) маленького гремлина на свободу!
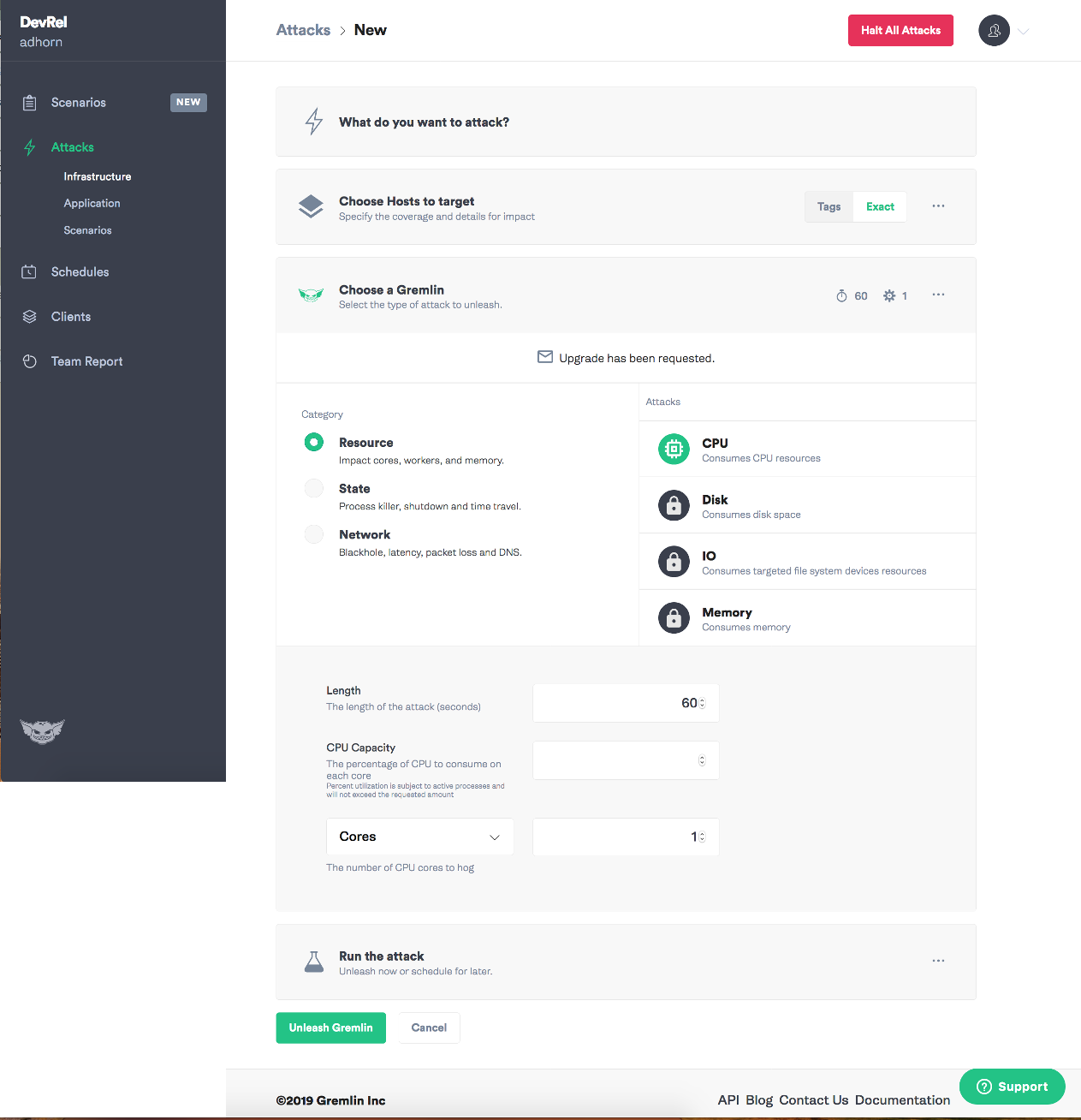
Должен признать, что всегда любил Gremlin, поскольку он делает хаос-экспериментирование простым и понятным.
Недостатком, на мой взгляд, является ценообразование. Оно не слишком подходит новичкам или для эпизодического (on-demand) использования из-за своей лицензии. Впрочем, недавно появилась бесплатная версия. Другим минусом Gremlin'а является необходимость устанавливать клиента и демона в экземпляры, которые станут целями атаки, что по душе далеко не всем.
Сервис EC2 Run Command, представленный в 2015 году, был создан для безопасного и простого администрирования экземпляров EC2. Сегодня он позволяет удаленно и безопасно управлять конфигурацией экземпляров не только типа EC2, но и из гибридных окружений. К ним относятся on-premises-серверы, виртуальные машины и даже ВМ в других облачных окружениях, используемых с Systems Manager.
Run Command позволяет автоматизировать DevOps-задачи или проводить обновления конфигурации независимо от размера вашего парка.
Run Command преимущественно используется для таких задач, как установка и bootstrapping приложений, захват логов или присоединение экземпляров к домену Windows, однако он также хорошо подходит для проведения хаос-экспериментов.
У меня есть запись в блоге, посвященная внедрению хаоса с помощью AWS System Manager, а также готовые исходники для экспериментов. Попробуйте — уверен, вам понравится!
Прежде чем закончить эту статью, хочу подчеркнуть несколько важных моментов, касающихся внедрения сбоев.
На этом всё. Спасибо, что дочитали до конца! Надеюсь, вам понравилась третья часть. Жду от вас мнений, комментариев и, конечно, хлопков в ладоши (на Medium — прим. перев.)!
Читайте также в нашем блоге:
Последний материал посвящён практике хаос-инжиниринга: методам экспериментирования и инструментам для их непосредственной реализации. Несмотря на то, что его перевод уже публиковался на днях на хабре, у нас готова своя версия, которая кажется нам качественной и по-прежнему уместной для размещения. Так весь цикл перевода этих статей был представлен в едином стиле и наши подписчики — читатели прошлых частей — увидят его полностью.
Прим. автора: Хочу выразить искреннюю признательность своему другу Ricardo Sueiras за его вклад в подготовку этой публикации и за то, что он помог мне сдвинуться с мертвой точки. Рикардо, ты крут!
«Мы становимся тем, что лицезреем. Сначала мы формируем свои инструменты, а затем они формируют нас». — Маршалл Маклюэн (канадский философ, прославившийся своими исследованиями в области коммуникаций; первое предложение этой цитаты, впрочем, заимствовано у британского поэта Уильяма Блейка — прим. перев.)
Важно помнить, что смысл хаос-инжиниринга вовсе НЕ в том, чтобы выпустить «обезьянок» на свободу и позволить им внедрять сбои случайным образом и бесцельно. Наоборот, это четко определенный, формализованный научный метод экспериментирования.
«Метод включает в себя внимательное наблюдение, применение строгого скептицизма к предмету наблюдения, учитывая, что сознательные предположения могут исказить интерпретацию наблюдений. Он включает в себя формулировку гипотез при помощи индукции, основанных на этих наблюдениях; экспериментальную и измеримую проверку выводов, следующих из гипотез; а также уточнение (или отказ от) гипотезы в зависимости от результатов экспериментов». — Wikipedia
Хаос-инжиниринг начинается с понимания устойчивого состояния системы. За этим следует формулировка гипотезы и, наконец, проверка и анализ результатов экспериментов ради повышения отказоустойчивости системы.
Этапы хаос-инжиниринга
В первой части данной серии статей я изложил концепцию хаос-инжиниринга и рассмотрел каждый шаг процесса, изображенного выше.
Во второй части — рассказал о направлениях, с которых следует начинать разработку экспериментов, и о том, как выбрать правильную гипотезу.
В этой, третьей, части речь пойдет о самих экспериментах. Будет представлена коллекция инструментов и методов, покрывающих широкий спектр возможностей по «внесению неисправностей» (fault injection или failure injection), необходимый для проведения экспериментов хаос-инжиниринга.
Список нельзя назвать исчерпывающим, однако его вполне достаточно для начала и того, чтобы заложить основу для дальнейших размышлений.
Внесение неисправностей: что это и зачем?
Внедрение неисправностей в систему позволяет понять и проверить, соответствует ли спецификациям её реакция на стрессовые условия. Впервые эта методика использовалась для провоцирования неисправностей на аппаратном уровне — в частности, на уровне контактов — путём изменения электрических сигналов на устройствах.
В разработке программного обеспечения внесение неисправностей помогает повысить отказоустойчивость системы и устранить потенциально слабые места. Этот процесс получил название «устранение неисправностей» (fault removal). Также он помогает прикинуть потенциальные последствия сбоя — то есть его радиус поражения — ещё до того, как нечто подобное случится в production. Это называется «прогнозированием неисправностей» (failure forecasting).
У внесения неисправностей есть несколько важных плюсов. Оно помогает:
- постичь и попрактиковаться в реакции на инциденты и непредвиденные обстоятельства;
- оценить масштаб последствий реальных сбоев;
- оценить эффективность и пределы возможностей механизмов обеспечения отказоустойчивости;
- устранить недостатки проектирования и найти слабые места;
- оценить и повысить наблюдаемость системы;
- узнать радиус поражения от сбоев и помочь уменьшить его;
- осмыслить распространение последствий сбоя между компонентами системы.
Категории неисправностей
Внедрение неисправностей подразделяется на пять категорий:
- сбои на уровне ресурсов;
- на уровне сети и зависимостей;
- на уровне приложений, процессов и сервисов;
- на уровне инфраструктуры;
- на уровне персонала*.
Далее я рассмотрю каждую категорию и приведу пример внесения неисправности для каждой из них. Кроме того, расскажу о некоторых комплексных инструментах для внесения сбоев и управления ими.
* Примечание: в этой статье не будет рассматриваться внесение неисправностей на уровне персонала. Эту тему затрону в отдельной публикации.
1. Сбои на уровне ресурсов или «исчерпание ресурсов»
Хотя облачные услуги приучили нас к тому, что ресурсы практически безграничны, вынужден вас разочаровать: это не так. Экземпляр, контейнер, функция и т.д. — независимо от уровня абстракции, ресурсы рано или поздно закончатся. Проверкой устойчивости системы, поставленной в условия жесткой нехватки ресурсов, и занимается подход с названием «исчерпание ресурсов» (resource exhaustion).
Исчерпание ресурсов обычно выглядит как DoS-атака (правда, не совсем привычная), стремящаяся помешать работе целевого хоста. Это довольно популярный способ внесения неисправностей — возможно, по той причине, что его легко реализовать.
Исчерпание ресурсов CPU, памяти и ввода/вывода
Один из моих любимых инструментов — stress-ng, реинкарнация оригинальной утилиты, которую разработал Amos Waterland.
С помощью stress-ng можно внедрить неисправности в различные физические подсистемы компьютера, а также в интерфейсы ядра ОС, используя «стрессоры» (stressors). Они доступны для: CPU, кэша CPU, устройств, ввода/вывода, прерываний, файловой системы, памяти, сети, операционной системы, конвейеров, планировщиков, виртуальных машин. Страницы руководства включают полное описание всех доступных стресс-тестов, коих насчитывается целых 220 штук!
Вот несколько полезных примером применения stress-ng:
- Стресс-тест CPU —
matrixprod— предлагает отличное сочетание операций с памятью, кэшем и с плавающей запятой. Пожалуй, является лучшим способом «поджарить» CPU.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s - Стресс-тест
iomix-bytesпишет N байтов для каждого процесса-worker'а iomix. Значение N по умолчанию равно 1 Гб и идеально подходит для стресс-теста ввода/вывода. В этом примере я указываю 80 % свободного пространства в файловой системе:
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s -
vm-bytesидеально подходит для проведения стресс-тестов памяти. В данном примере stress-ng запускает 9 стрессоров виртуальной памяти. Вместе они «съедают» 90 % доступной памяти на один час (каждый стрессор использует 10 % доступной памяти):
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
Исчерпание места на жестких дисках
dd — это утилита для командной строки, созданная для преобразования и копирования файлов. При этом dd может читать (или писать) из специальных файлов устройств, таких как /dev/zero и /dev/random, для задач вроде резервного копирования загрузочного сектора жёсткого диска или получения определенного количества случайной информации. Таким образом, её также можно использовать для внесения неисправности в хост и имитации заполнения диска. Помните, как ваши логи съели всё свободное пространство на сервере и привели к падению приложения? Эта утилита способна помочь, но также и навредить. Используйте dd чрезвычайно осторожно! Ошибка в команде может стереть, уничтожить или перезаписать данные на жёстком диске!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &Исчерпание ресурсов API приложения
Производительность, отказоустойчивость и масштабируемость API имеют большое значение. В самом деле, API позволяют компаниям совершенствовать свои приложения и развивать бизнес.
Нагрузочное тестирование (load testing) — отличная возможность испытать приложение, прежде чем оно попадёт в production. Также это превосходный метод стресс-тестирования, позволяющий выявить проблемы и ограничения, которые в противном случае могли бы проявиться только при реальной нагрузке.
wrk — инструмент для бенчмаркинга HTTP, способный генерировать значительную нагрузку на системы. Мне очень нравится нагружать API для health-check'ов — особенно, если это глубокие проверки, поскольку они позволяют многое узнать об архитектурных решениях в проекте: как настроен кэш? Как работает ограничение по частоте? Уделяет ли система приоритетное внимание health-check'ам от балансировщиков нагрузки?Вот отличная отправная точка:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/healthЭта команда запускает 12 потоков и держит открытыми 400 HTTP-подключений в течение 20 секунд.
2. Внедрение неисправностей на уровне сети и зависимостей
Eight Fallacies of Distributed Computing от Peter'а Deutsch'а — это набор из предположений, которыми руководствуются разработчики при проектировании распределённых систем. Однако они часто оборачиваются против них, вызывая перебои в работе системы и заставляя менять её архитектуру. Вот эти предположения:
- Сеть надёжна.
- Задержка равна нулю.
- Пропускная способность безгранична.
- Сеть безопасна.
- Топология не меняется.
- Есть только один администратор.
- Транспортировка всегда происходит без проблем.
- Сеть гомогенна.
Этот список, по сути, представляет собой готовый перечень направлений для внесения неисправностей и проверки способности распределенной системы противостоять сетевым сбоям.
Внедрение задержек, потерь и повреждений сети
tc (traffic control) — это инструмент командной строки для конфигурации планировщика пакетов ядра Linux. Он определяет, как пакеты попадают в очередь для передачи и приёма по сетевому интерфейсу. Возможности включают постановку в очередь, применение политик, классификацию, планирование, шейпинг и отбрасывание.tc можно использовать для имитации задержки и потери пакетов для UDP- или TCP-приложений, а также для ограничения пропускной способности сети для конкретного сервиса с целью имитировать реальное перемещение трафика в интернете.
— Внедряем задержку в 100 мс:
# Запуск
❯ tc qdisc add dev eth0 root netem delay 100ms
# Остановка
❯ tc qdisc del dev eth0 root netem delay 100ms— Внедряем задержку в 100 мс с дельтой в 50 мс:
# Запуск
❯ tc qdisc add dev eth0 root netem delay 100ms 50ms
# Остановка
❯ tc qdisc del dev eth0 root netem delay 100ms 50ms— Имитируем повреждение 5 % сетевых пакетов:
# Запуск
❯ tc qdisc add dev eth0 root netem corrupt 5%
# Остановка
❯ tc qdisc del dev eth0 root netem corrupt 5%— Имитируем потерю 7 % пакетов с корреляцией в 25 %:
# Запуск
❯ tc qdisc add dev eth0 root netem loss 7% 25%
# Остановка
❯ tc qdisc del dev eth0 root netem loss 7% 25%Примечание: 7 % позволяют сохранить работоспособность TCP.
Манипуляции с /etc/hosts
/etc/hosts — это простой текстовый файл, сопоставляющий IP-адреса с доменными именами (одна строка на адрес). Для каждого хоста должна быть своя строка со следующей информацией:IP_адрес каноническое_доменное_имя [алиасы...]Файл hosts — один из нескольких способов, с помощью которых компьютер сопоставляет сетевые узлы в компьютерной сети и переводит понятные для человека домены в IP-адреса. Как вы уже догадались, он отлично подходит и для запутывания компьютеров. Вот несколько примеров:
— Блокируем доступ к API DynamoDB из экземпляра EC2:
# Запуск
# Копируем /etc/hosts в /etc/host.back
❯ cp /etc/hosts /etc/hosts.back
❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts
# Остановка
# Возвращаем изначальную версию /etc/hosts
❯ cp /etc/hosts.back /etc/hosts— Блокируем доступ экземпляра EC2 к API EC2:
# Запуск
# Копируем /etc/hosts в /etc/host.back
❯ cp /etc/hosts /etc/hosts.back
❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts
# Остановка
# Возвращаем /etc/hosts
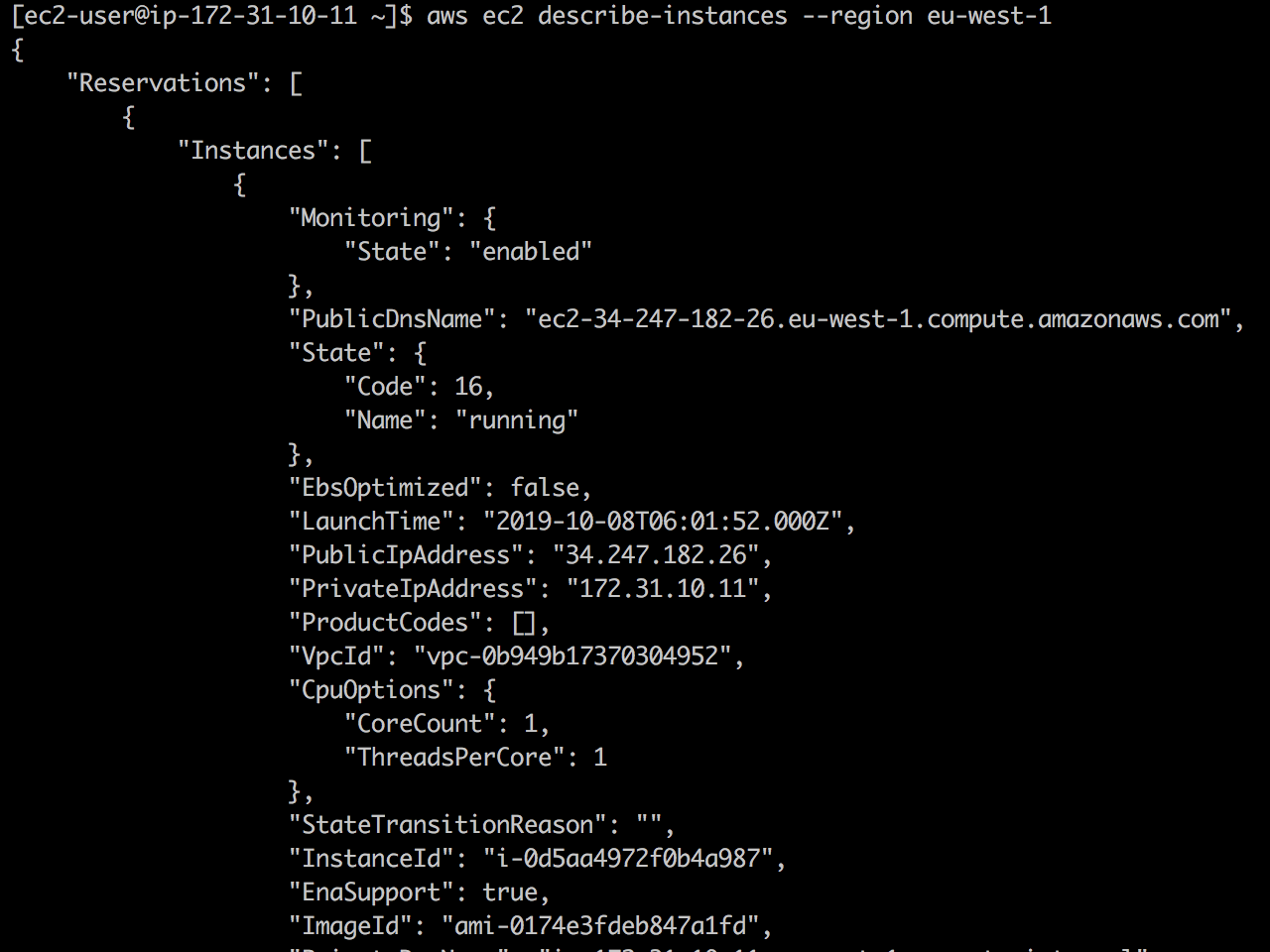
❯ cp /etc/hosts.back /etc/hostsВот пример работы с этим файлом. Изначально API EC2 доступен, и команда
ec2 describe-instances завершается успешно:Но как только я добавляю строку
127.0.0.1 ec2.eu-west-1.amazonaws.com в /etc/hosts, вызовы перестают доходить до API EC2:Конечно, этот метод работает для всех endpoint'ов AWS.
Я мог бы рассказать анекдот про DNS...
Идёт обновление кэша DNS…
… только вам потребуется 24 часа, чтобы его понять.
21 октября 2016 году DDoS-атака на Dyn привела к тому, что значительное число интернет-платформ и сервисов оказались недоступны в Европе и Северной Америке. Согласно отчёту ThousandEyes Global DNS Performance за 2018 год, 60 % компаний и SaaS-провайдеров по-прежнему полагаются на один источник DNS и, следовательно, уязвимы перед сбоями DNS. Поскольку без DNS нет и интернета, разумно имитировать падение этой службы, чтобы проверить устойчивость системы к возможному отказу DNS.
Традиционно для борьбы с DDoS-атаками используется така называемый blackholing — метод, в котором «плохой» сетевой трафик отправляется прямиком в «чёрную дыру» и выбрасывается в пустоту (этакая сетевая версия
/dev/null). Можно воспользоваться им для имитации потери сетевого трафика или отказа протокола, например, службы DNS.С этой работой прекрасно справится iptables. Эта утилита используется для настройки, обслуживания и анализа таблиц с правилами фильтрации IP-пакетов в ядре Linux.
Чтобы отправить DNS-трафик в «чёрную дыру», попробуйте сделать следующее:
# Запуск
❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP
❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP
# Остановка
❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP
❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROPВнесение неисправностей с помощью Toxiproxy
Один из главных недостатков инструментов под Linux, таких как
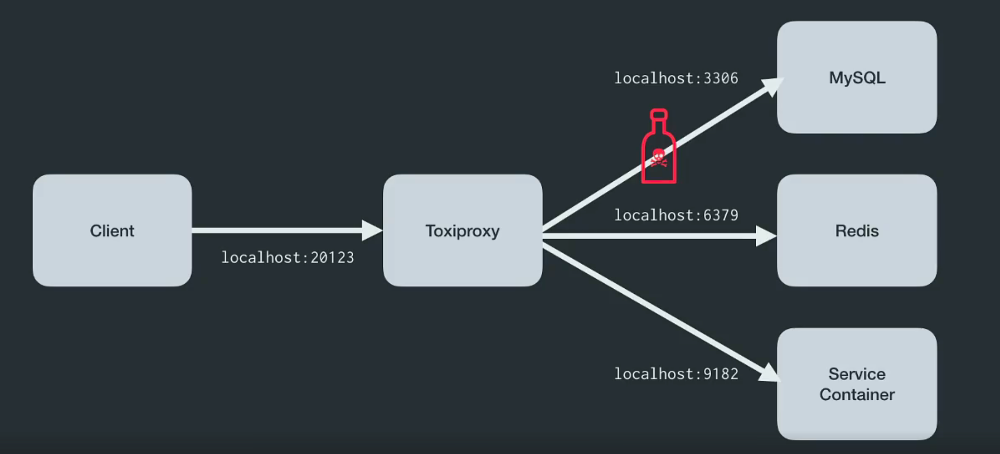
tc и iptables, состоит в том, что они требуют root-привилегий для своей работы, что может быть проблематично для некоторых организаций и ситуаций. В этом случае на выручку придет Toxiproxy!Toxiproxy — это TCP-прокси с открытым исходным кодом, разработанный инженерной командой Shopify. Он помогает имитировать хаотические сетевые и системные условия из реальной жизни. Для этого достаточно поместить Toxiproxy между компонентами инфраструктуры, как показано на иллюстрации ниже:
Слайд из выступления Simon'а Eskildsen'а, главы команды production-разработки, Shopify
Этот инструмент специально разработан для окружений с тестами, CI и разработкой, он поддерживает детерминированный или рандомизированный хаос, а также кастомизацию. Toxiproxy манипулирует соединением между клиентом и upstream'ом с помощью так называемых «токсиков» (toxics) и поддерживает настройку через HTTP API. Кроме того, инструмент поставляется с набором предустановленных токсиков.
В примере ниже показывается, как Toxiproxy с помощью downstream-токсика увеличивает задержку на 1000 мс между клиентом Redis, redis-cli и самой Redis:
Начиная с октября 2014 года Toxiproxy с успехом используется во всех development- и test-средах в Shopify. Подробности о Toxiproxy можно узнать из этой записи в блоге.
3. Внедрение сбоев на уровне приложения, процесса и сервиса
Программы падают. Это общеизвестный факт. Что делать, если произошел сбой? Следует ли зайти на сервер по SSH и перезапустить упавший процесс? Системы контроля процессов позволяют следить за состоянием процесса или изменять его с помощью таких директив, как start, stop, restart. Эти системы обычно реализуются для постоянного контроля за процессом. Одним из таких инструментов является
systemd. Он обеспечивает базовый набор методов для управления процессами в Linux. Supervisord предлагает аналогичный функционал для UNIX-подобных операционных систем.Эти инструменты следует использовать при деплое приложений. Конечно, прежде всего надо изучить последствия от падений критических процессов. Убедитесь, что получаете соответствующие уведомления, а процессы перезапускаются в автоматическом режиме:
— «Убийство» Java-процессов:
❯ pkill -KILL -f java
# Альтернативный способ
❯ pkill -f 'java -jar'— «Убийство» процессов Python:
❯ pkill -KILL -f pythonКонечно, с помощью
pkill можно убить практически любой процесс в системе.Внесение сбоев в базы данных
Если и есть сбои, жалобы на которые терпеть не может поддержка, так это те, которые имеют отношение к базам данных. Данные ценятся на вес золота, и всякий раз, когда происходит сбой в БД, возрастает риск потери данных клиентов.
В некоторых случаях способность как можно быстрее восстановить данные и вернуть систему в работоспособное состояние может определить судьбу компании. К сожалению, подготовиться ко всему разнообразию сбоев баз данных непросто, и многие из них проявляются только в production.
Впрочем, если вы используете Amazon Aurora, то можете проверить отказоустойчивость кластера баз данных Amazon Aurora путем специальных запросов с внедрением ошибок.
Внедрение сбоев в Amazon Aurora
Запросы со сбоями в виде SQL-команд направляются экземпляру Amazon Aurora и позволяют запланировать «возникновение» одного из следующих событий:
- падение читающего (reader) или пишущего (writer) экземпляра БД;
- сбой реплики Aurora;
- выход диска из строя;
- сбой диска с пометкой случайных сегментов как переполненных (congested).
Отправляя запрос со сбоем, вы также указываете желаемую продолжительность имитации неисправности.
— Падение экземпляра Amazon Aurora:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];— Имитация отказа реплики Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE
[ TO ALL | TO "replica name" ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };— Имитация выхода из строя диска в кластере с БД Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE
[ IN DISK index | NODE index ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };— Имитация повышенной загрузки диска в кластере с БД Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION
BETWEEN minimum AND maximum MILLISECONDS
[ IN DISK index | NODE index ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };Сбои в serverless-мире
Внедрять сбои может быть непросто, если вы используете serverless-компоненты, поскольку управляемые serverless-сервисы вроде AWS Lambda изначально не поддерживают внесение неисправностей.
Внедряем сбои в функции Lambda
Чтобы решить эту проблему, я написал небольшую библиотеку на Python и лямбда-слой для внедрения сбоев в AWS Lambda. Оба в настоящее время поддерживают задержки, ошибки, исключения и внедрение кодов ошибок HTTP.
Само внесение неисправностей осуществляется путём задания следующих параметров в AWS SSM Parameter Store:
{
"isEnabled": true,
"delay": 400,
"error_code": 404,
"exception_msg": "I really failed seriously",
"rate": 1
}Можно добавить декоратор Python в функцию-обработчик для внедрения неисправности.
— Вызываем исключение:
@inject_exception
def handler_with_exception(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_exception('foo', 'bar')
Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1
corrupting now
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../chaos_lambda.py", line 316, in wrapper
raise _exception_type(_exception_msg)
Exception: I really failed seriously— Внедряем неправильный код ошибки HTTP:
@inject_statuscode
def handler_with_statuscode(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_statuscode('foo', 'bar')
Injecting Error 404 at a rate of 1
corrupting now
{'statusCode': 404, 'body': 'Hello from Lambda!'}— Внедряем задержку:
@inject_delay
def handler_with_delay(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}>>> handler_with_delay('foo', 'bar')
Injecting 400 of delay with a rate of 1
Added 402.20ms to handler_with_delay
{'statusCode': 200, 'body': 'Hello from Lambda!'}Чтобы узнать больше об этой Python-библиотеке, перейдите по ссылке.
Вмешиваемся в работу Lambda, устанавливая лимит concurrency
Lambda по умолчанию использует механизм безопасности для параллельной (concurrent) работы всех функций в определённом регионе для каждой учётной записи. Под параллельной работой подразумевается число выполнений кода функции в любой момент времени. Оно используется для масштабирования вызовов функции в ответ на входящие запросы. Однако его же можно использовать для обратной цели: замедления работы Lambda.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0Эта команда установит
concurrency на нуль, вынуждая запросы завершаться с ошибкой 429 («слишком много запросов»).Thundra — отслеживаем serverless-транзакции
Этот инструмент для наблюдения за serverless-архитектурой обладает встроенной возможностью внедрять неисправности в serverless-приложения. Thundra использует так называемые span listeners для внедрения сбоев, таких как отсутствие обработчика ошибок для DynamoDB, отсутствие резервного источника данных или отсутствие таймаута для исходящих HTTP-запросов. Я сам не пользовался этим инструментом, однако эта публикация от Yan Cui и это замечательное видео от Marcia Villalba прекрасно описывают процесс работы. Исходя из них, Thundra выглядит многообещающе.
Подводя черту под serverless-разделом, хочу порекомендовать всем отличную статью о сложностях хаос-инжиниринга в serverless-приложениях, которую написал уже упомянутый Yan Cui.
4. Внесение неисправностей на уровне инфраструктуры
Хаос-инжиниринг начинался в инъекции сбоев на уровне инфраструктуры — как в случае Amazon, так и в случае Netflix. Пожалуй, инфраструктурные сбои: от отключения целого ЦОД и до случайной остановки экземпляров — реализовать проще всего.
И, естественно, первым на ум приходит пример с chaos monkey.
Случайная остановка экземпляра EC2 в зоне доступности
На заре своего существования Netflix озаботился разработкой и внедрением правильного подхода к архитектурным решениям. Chaos monkey стала одним из первых приложений, развернутых в AWS, которое следило на состоянием автомасштабируемых stateless-микросервисов. Другими словами, любой экземпляр мог быть остановлен и автоматически заменен без потери состояния. Chaos monkey следила за тем, чтобы никто не нарушал это правило.
Следующий скрипт — по аналогии с хаос-обезьянкой — случайным образом выбирает и останавливает экземпляр в определенной зоне доступности внутри региона:
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")stop-random-instance.py
(gist для stop-random-instance.py)
import boto3
import random
REGION = 'eu-west-1'
def stop_random_instance(az, tag_name, tag_value, region=REGION):
'''
>>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1')
['i-0ddce3c81bc836560']
'''
ec2 = boto3.client("ec2", region_name=region)
paginator = ec2.get_paginator('describe_instances')
pages = paginator.paginate(
Filters=[
{
"Name": "availability-zone",
"Values": [
az
]
},
{
"Name": "tag:" + tag_name,
"Values": [
tag_value
]
}
]
)
instance_list = []
for page in pages:
for reservation in page['Reservations']:
for instance in reservation['Instances']:
instance_list.append(instance['InstanceId'])
print("Going to stop any of these instances", instance_list)
selected_instance = random.choice(instance_list)
print("Randomly selected", selected_instance)
response = ec2.stop_instances(InstanceIds=[selected_instance])
return response(gist для stop-random-instance.py)
Обратите внимание на
tag_name и tag_value. Подобные маленькие хитрости помогают предотвратить отключение «не того» экземпляра. #lessonlearned— «Да, было бы классно, если бы вы перезапустили базу…» — Упс, не тот экземпляр...
5. Комплексные инструменты для оркестрации и внесения неисправностей
Высока вероятность, что вы ошеломлены всем разнообразием инструментов, о которых шла речь до настоящего момента. К счастью, есть несколько готовых пакетов по оркестрации и внедрению неисправностей, которые объединяют функциональность вышеперечисленных инструментов, делая это в простой и удобной форме.
Chaos Toolkit
Chaos Toolkit — один из моих любимейших инструментов подобного рода. Это целая Open Source-платформа для хаос-инжиниринга, поддерживаемая (на коммерческой основе) прекрасной командой ChaosIQ, включающей в числе прочих Russ Miles, Sylvain Hellegouarch и Marc Perrien.
Chaos Toolkit предлагает декларативный и расширяемый открытый API для экспериментов по организации хаоса. Он включает в себя драйверы для AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humio, Prometheus и Gremlin.
Расширения — это набор тестов и последовательностей действий для организации различных экспериментов — например, для случайной остановки экземпляров в определенной зоне доступности, если значение
tag-key равно chaos-ready.stop-random-instance-exp.json
(gist для stop-random-instance-exp.json)
{
"version": "1.0.0",
"title": "What is the impact of randomly terminating an instance in an AZ",
"description": "terminating EC2 instance at random should not impact my app from running",
"tags": ["ec2"],
"configuration": {
"aws_region": "eu-west-1"
},
"steady-state-hypothesis": {
"title": "more than 0 instance in region",
"probes": [
{
"provider": {
"module": "chaosaws.ec2.probes",
"type": "python",
"func": "count_instances",
"arguments": {
"filters": [
{
"Name": "availability-zone",
"Values": ["eu-west-1c"]
}
]
}
},
"type": "probe",
"name": "count-instances",
"tolerance": [0, 1]
}
]
},
"method": [
{
"type": "action",
"name": "stop-random-instance",
"provider": {
"type": "python",
"module": "chaosaws.ec2.actions",
"func": "stop_instance",
"arguments": {
"az": "eu-west-1c"
},
"filters": [
{
"Name": "tag-key",
"Values": ["chaos-ready"]
}
]
},
"pauses": {
"after": 60
}
}
],
"rollbacks": [
{
"type": "action",
"name": "start-all-instances",
"provider": {
"type": "python",
"module": "chaosaws.ec2.actions",
"func": "start_instances",
"arguments": {
"az": "eu-west-1c"
},
"filters": [
{
"Name": "tag-key",
"Values": ["chaos-ready"]
}
]
}
}
]
}(gist для stop-random-instance-exp.json)
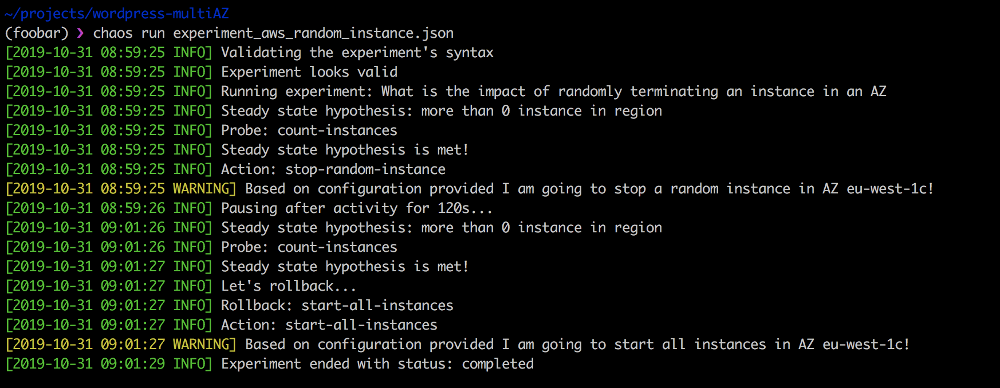
Запустить этот эксперимент просто:
❯ chaos run experiment_aws_random_instance.jsonПреимущество Chaos Toolkit, во-первых, в открытых исходниках (поэтому его легко приспособить для конкретных потребностей). Во-вторых, он прекрасно интегрируется в CI/CD-пайплайн и поддерживает непрерывное хаос-тестирование.
Недостатком Chaos Toolkit'а является его сложность: чтобы начать работать, необходимо разобраться в его особенностях и принципах. Более того, в Toolkit'е нет готовых экспериментов: придётся написать свои собственные. Впрочем, команда ChaosIQ активно работает над устранением этого недостатка.
Gremlin
Другой мой любимый инструмент — Gremlin — включает в себя полный набор режимов внесения неисправностей в простой и удобной для использования форме с интуитивно понятным пользовательским интерфейсом — этакий вариант Chaos-as-a-Service.
Gremlin обеспечивает внедрение ошибок в ресурсы, состояния, сеть и запросы, позволяя экспериментировать с различными частями системы. Он поддерживает bare metal, различных поставщиков облачных услуг, контейнерные среды (включая Kubernetes*), приложения и (в некоторой степени) serverless-вычисления.
* Прим. перев.: Подробнее об использовании Gremlin в контексте Kubernetes (и не только) можно прочитать, например, в этой статье.
Бонусом идет отличный контент в блоге проекта. Кроме того, ребята из Gremlin по-настоящему круты и всегда готовы прийти на выручку! Прежде всего это Matthew, Kolton, Tammy, Rich, Ana и HML.
Работать с Gremlin'ом весьма просто.
Войдите в приложение и выберите Create Attack:
Выберите целевой экземпляр:
Выберите тип неисправности, которую хотите внедрить, и выпустите (unleash) маленького гремлина на свободу!
Должен признать, что всегда любил Gremlin, поскольку он делает хаос-экспериментирование простым и понятным.
Недостатком, на мой взгляд, является ценообразование. Оно не слишком подходит новичкам или для эпизодического (on-demand) использования из-за своей лицензии. Впрочем, недавно появилась бесплатная версия. Другим минусом Gremlin'а является необходимость устанавливать клиента и демона в экземпляры, которые станут целями атаки, что по душе далеко не всем.
Run Command в AWS System Manager
Сервис EC2 Run Command, представленный в 2015 году, был создан для безопасного и простого администрирования экземпляров EC2. Сегодня он позволяет удаленно и безопасно управлять конфигурацией экземпляров не только типа EC2, но и из гибридных окружений. К ним относятся on-premises-серверы, виртуальные машины и даже ВМ в других облачных окружениях, используемых с Systems Manager.
Run Command позволяет автоматизировать DevOps-задачи или проводить обновления конфигурации независимо от размера вашего парка.
Run Command преимущественно используется для таких задач, как установка и bootstrapping приложений, захват логов или присоединение экземпляров к домену Windows, однако он также хорошо подходит для проведения хаос-экспериментов.
У меня есть запись в блоге, посвященная внедрению хаоса с помощью AWS System Manager, а также готовые исходники для экспериментов. Попробуйте — уверен, вам понравится!
Закругляюсь!
Прежде чем закончить эту статью, хочу подчеркнуть несколько важных моментов, касающихся внедрения сбоев.
- Смысл хаос-инжиниринга не в том, чтобы ломать что-то в production. Это целое путешествие. Путешествие к знанию, получаемому путем проведения экспериментов в контролируемой среде — любой среде, будь то локальное окружение для разработки, beta, staging или production. Это путешествие может начаться где угодно! Об этом прекрасно сказала Olga Hall:
«Цените хаос независимо от обстоятельств. Найдите для него место в своём путешествии». — Olga Hall, старший менеджер команды Resilience Engineering в Amazon Prime Video.
- Прежде чем внести неисправность, помните, что необходимо иметь наготове соответствующие мониторинг и алерты. Без них вы не сможете оценить влияние экспериментов с хаосом или измерить радиус поражения — два критически важных компонента в практике хаос-инжиниринга.
- Некоторые из описанных методов могут нанести серьёзный урон, поэтому соблюдайте осторожность и проводите начальные испытания на тестовых экземплярах, от падения которых не пострадают реальные клиенты.
- Наконец, тестируйте, пробуйте, испытывайте, а затем повторяйте всё снова. Помните, что цель хаос-инжиниринга — выработать уверенность в способности вашего приложения (и инструментов) пережить турбулентные условия эксплуатации.
На этом всё. Спасибо, что дочитали до конца! Надеюсь, вам понравилась третья часть. Жду от вас мнений, комментариев и, конечно, хлопков в ладоши (на Medium — прим. перев.)!
P.S. от переводчика
Читайте также в нашем блоге:
- «Chaos Engineering: искусство умышленного разрушения. Часть 1» (про концепцию chaos engineering и как он помогает находить/исправлять проблемы до того, как они приведут к сбоям production);
- «Chaos Engineering: искусство умышленного разрушения. Часть 2» (как chaos engineering способствует позитивным культурным изменениям внутри организаций);
- «Мониторинг и Kubernetes (обзор и видео доклада)».
