Если у вас есть Grafana и несколько систем мониторинга, то почему бы не визуализировать все имеющиеся данные и статусы в едином интерфейсе?
Покажем на примере нашего тестового стенда как скрестить Zabbix и SCOM в единой Grafana и сделать сервисный мониторинг (с точки зрения здоровья сервисов). Подробности и скриншоты под катом.
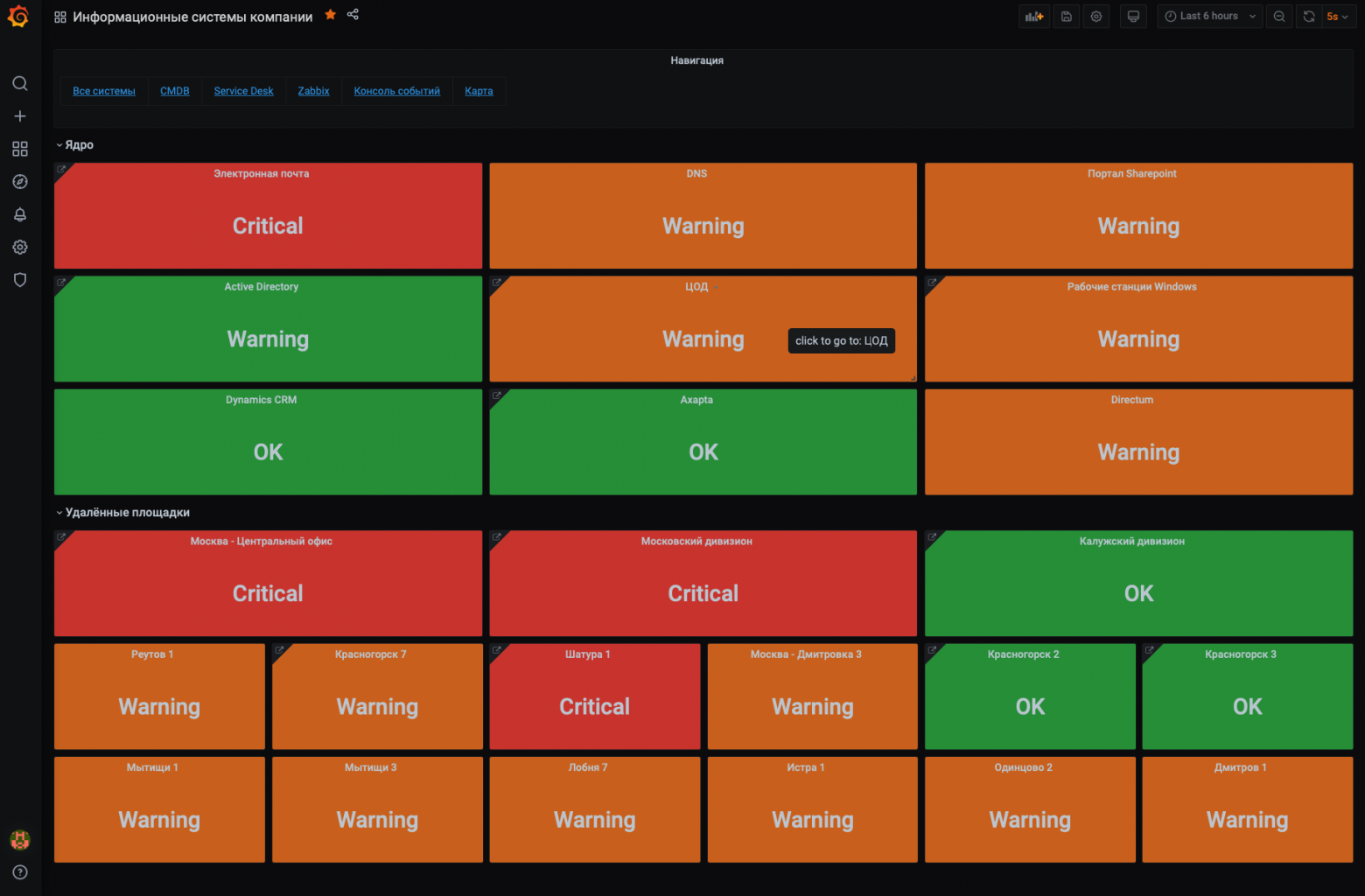
На скриншоте ниже информационные системы компании. Здесь электронная почта, DNS, Active Directory, Sharepoint и другие. Каждый квадрат — это агрегированный статус информационной системы. Ниже мы покажем за счет чего так получается. Обращаем внимание, что различные системы могут быт охвачены различными системами мониторинга. В нашем случае — это Zabbix и SCOM.

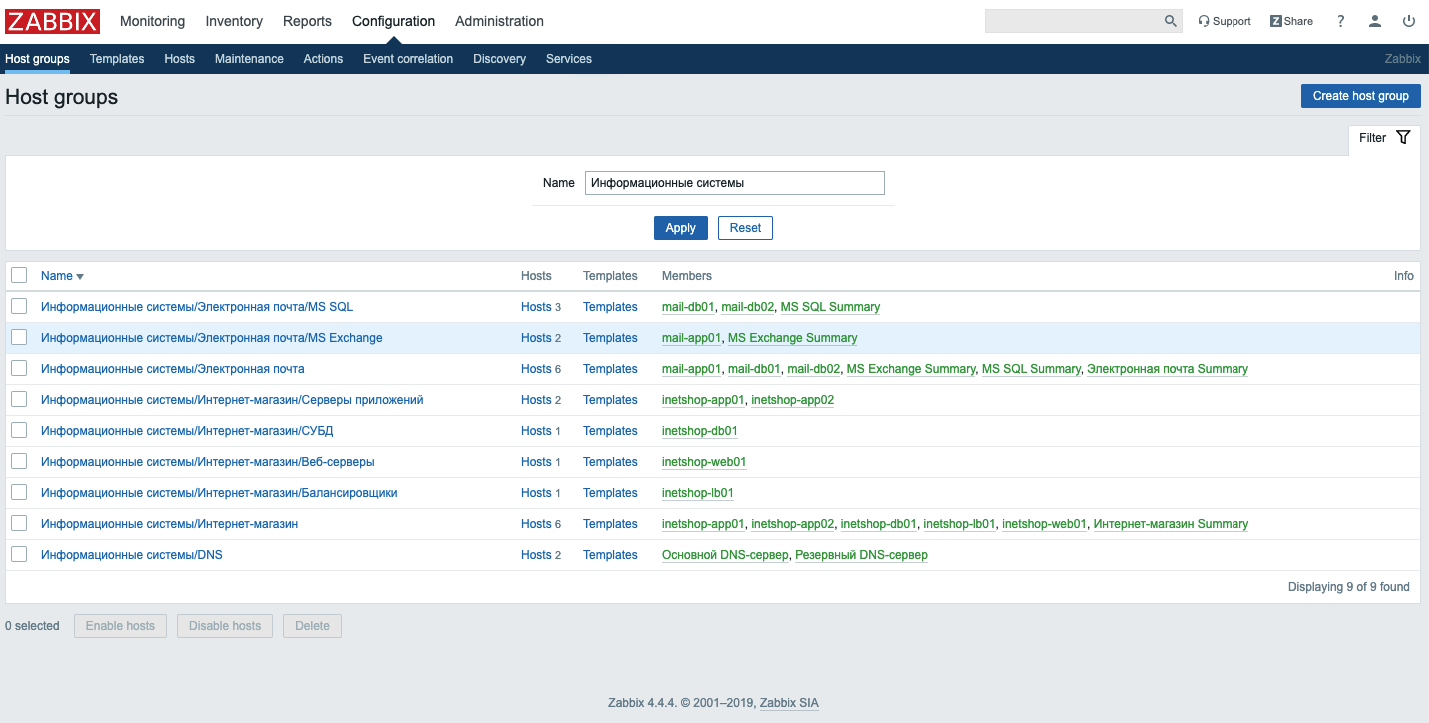
Начнём c Zabbix. Там есть возможность создавать группы узлов. Каждому узлу соответствует набор триггеров. Что мы делаем дальше? Ищем наихудший статус триггера на узле и отдаём его значение в специальный элемент данных. Следом проводим аналогичное действие по агрегированию наихудшего статуса триггера для группы узлов и получаем агрегированный статус здоровья группы.
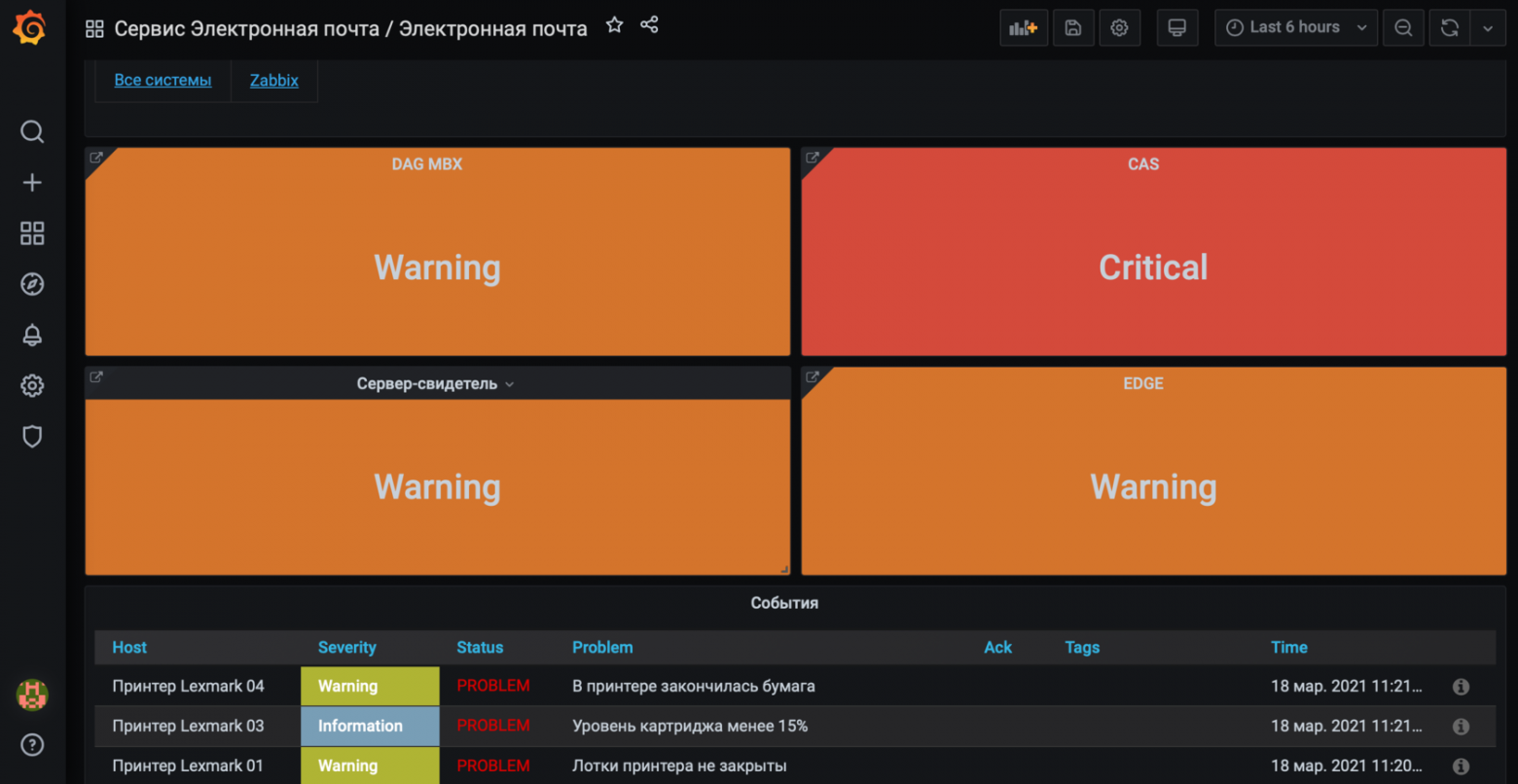
Уже после этого можно привязывать статусные элементы данных к плиткам в Grafana. На скриншоте ниже компоненты информационной системы Электронная почта. Каждая плитка — это агрегированный статус здоровья сервисов системы. Каждая плитка — это ссылка, можно провалиться и увидеть на каком узле проблема. Обратите внимание, что такая агрегация позволяет выводить вложенные события на каждом уровне (они под плитками).
Если проваливаться дальше, то можно дойти до уровня узла, где будут его метрики производительности. При желании, там можно сделать плитку с агрегированным статусов виртуализации, а дальше и сетевых устройств. Подход зависит от задач. С Zabbix разобрались, переходим к SCOM.
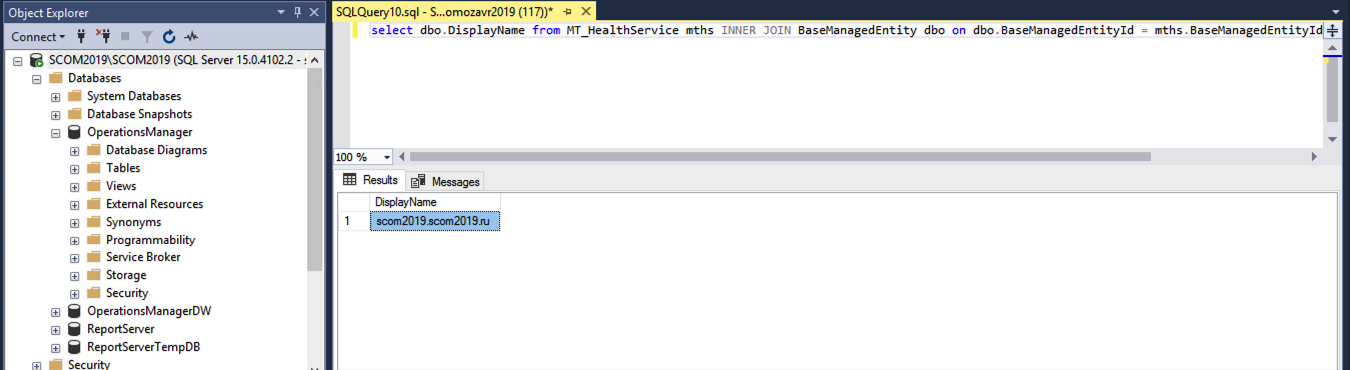
Интеграция Grafana со SCOM реализована при помощи SQL-запросов в базы OperationsManager и OperationsManagerDW. Первая для кратковременного хранения, вторая для долговременного. При помощи SQL-запроса получим список узлов, которые находятся на мониторинге в SCOM.
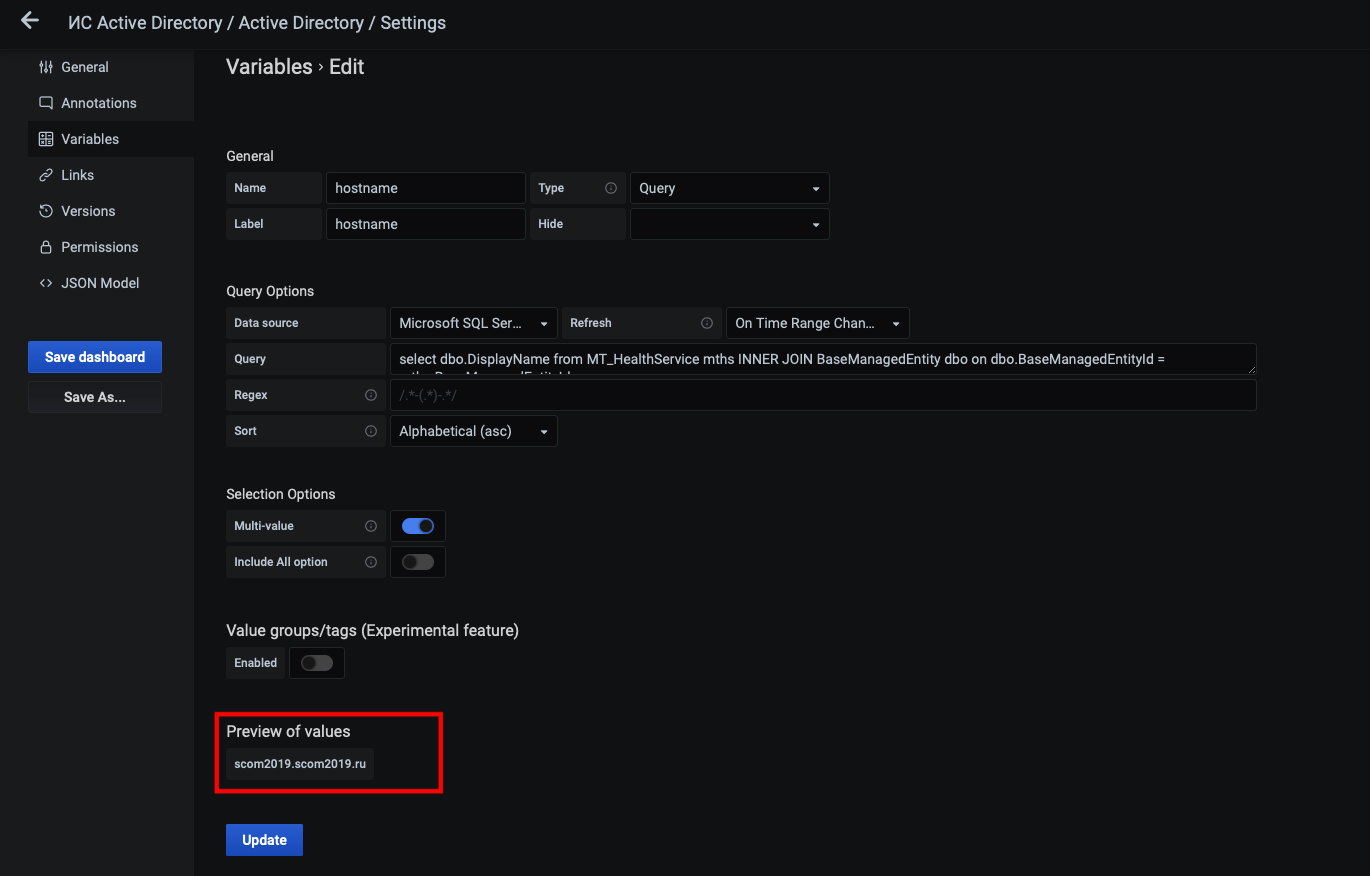
Настроим переменные, которые будут определять фильтры в Grafana и помогут в дальнейшем автоматизировать появление здесь новых узлов.
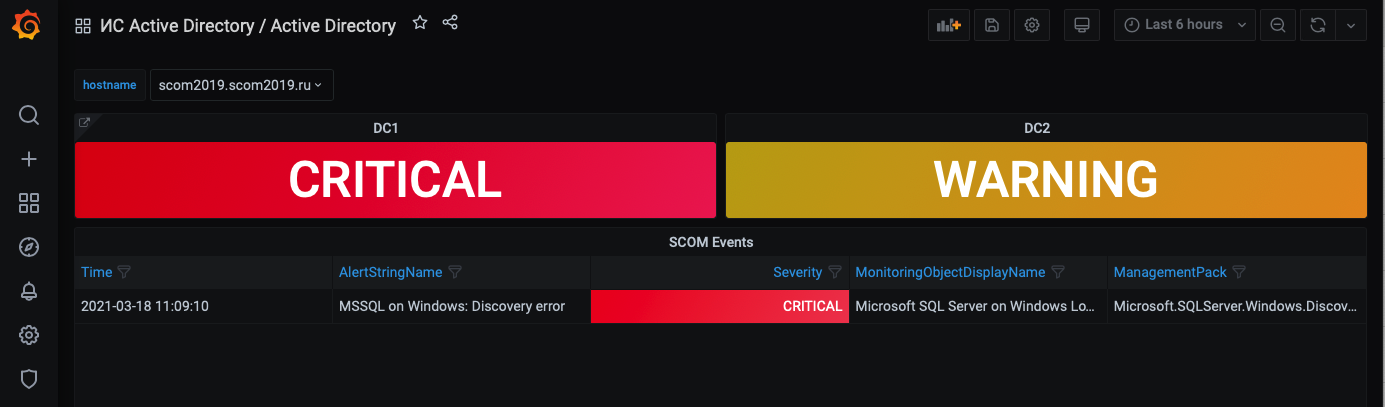
Другими SQL-запросами в SCOM можно получить статусы узлов (аналогично Zabbix) и список событий. Таким образом, нажав на плитку Active Directory на уровне информационных систем, можно перейти на представление с доменнных контроллеров и соответствующими событиями по ним.
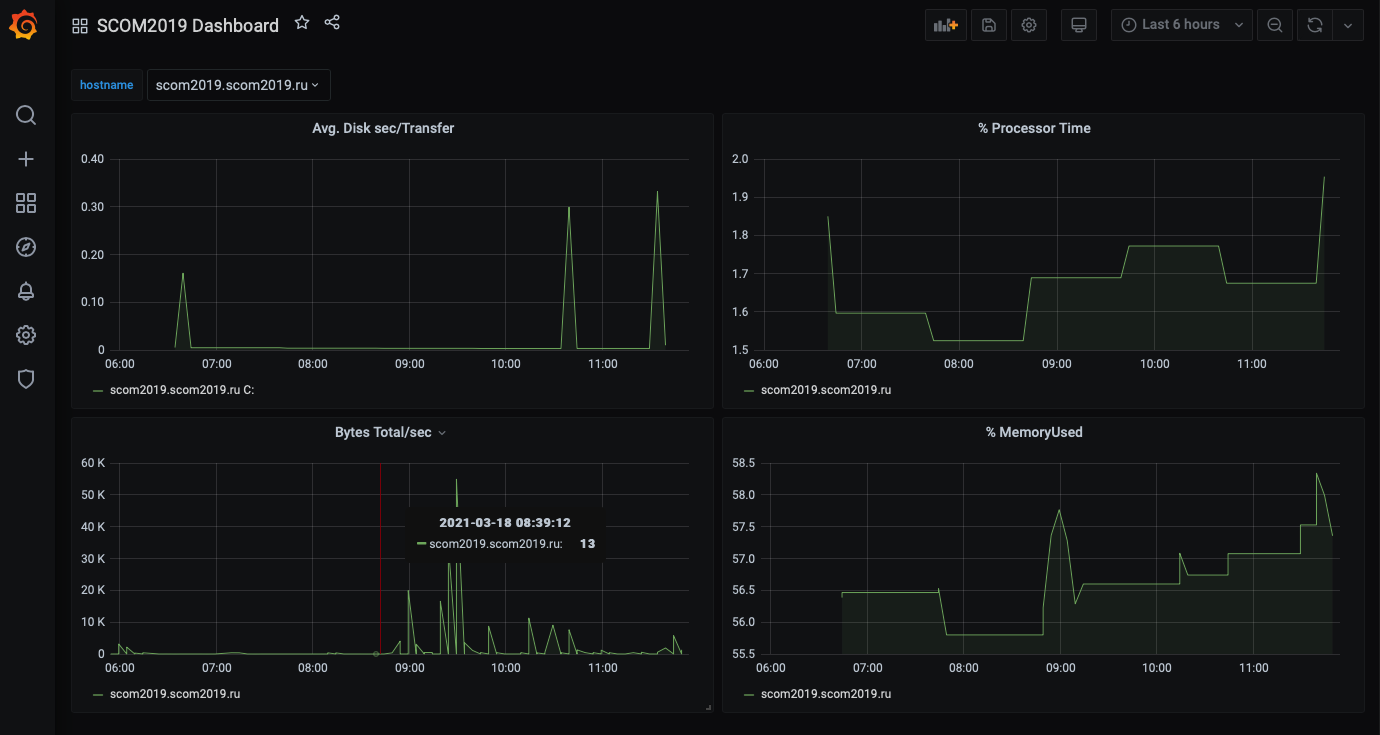
Ну, а дальше посмотреть на значения отдельных метрик узла.
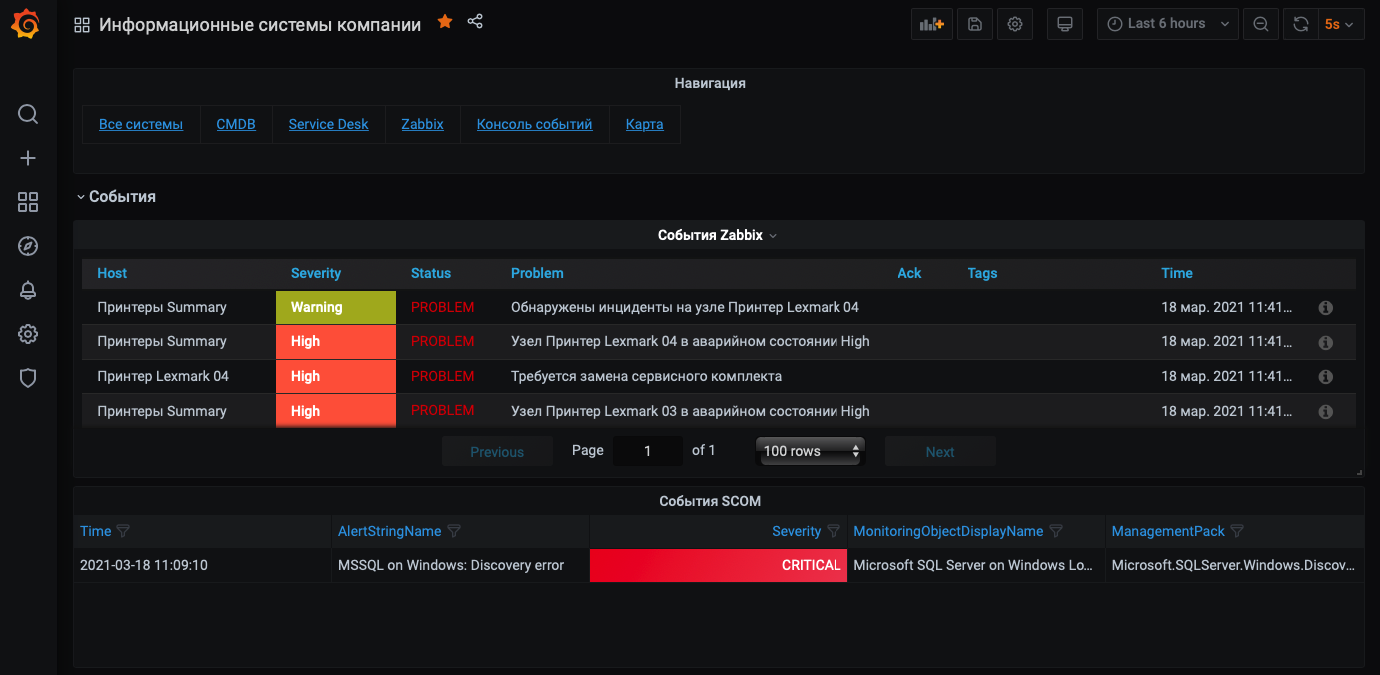
Ещё можно использовать вот такое представление с событиями одновременно для Zabbix и Microsoft SCOM.
Спасибо за внимание! Надеюсь, было интересно.
А ещё у нас есть:
Описание комплексного решения по мониторингу на открытых системах
Zabbix под замком: включаем опции безопасности компонентов Zabbix для доступа изнутри и снаружи
Добавляем CMDB и географическую карту к Zabbix
Если вас интересуют услуги внедрения, администрирования и поддержки Zabbix, вы можете оставить заявку в форме обратной связи на нашем сайте.
Покажем на примере нашего тестового стенда как скрестить Zabbix и SCOM в единой Grafana и сделать сервисный мониторинг (с точки зрения здоровья сервисов). Подробности и скриншоты под катом.
На скриншоте ниже информационные системы компании. Здесь электронная почта, DNS, Active Directory, Sharepoint и другие. Каждый квадрат — это агрегированный статус информационной системы. Ниже мы покажем за счет чего так получается. Обращаем внимание, что различные системы могут быт охвачены различными системами мониторинга. В нашем случае — это Zabbix и SCOM.
Начнём c Zabbix. Там есть возможность создавать группы узлов. Каждому узлу соответствует набор триггеров. Что мы делаем дальше? Ищем наихудший статус триггера на узле и отдаём его значение в специальный элемент данных. Следом проводим аналогичное действие по агрегированию наихудшего статуса триггера для группы узлов и получаем агрегированный статус здоровья группы.
Уже после этого можно привязывать статусные элементы данных к плиткам в Grafana. На скриншоте ниже компоненты информационной системы Электронная почта. Каждая плитка — это агрегированный статус здоровья сервисов системы. Каждая плитка — это ссылка, можно провалиться и увидеть на каком узле проблема. Обратите внимание, что такая агрегация позволяет выводить вложенные события на каждом уровне (они под плитками).
Если проваливаться дальше, то можно дойти до уровня узла, где будут его метрики производительности. При желании, там можно сделать плитку с агрегированным статусов виртуализации, а дальше и сетевых устройств. Подход зависит от задач. С Zabbix разобрались, переходим к SCOM.
Интеграция Grafana со SCOM реализована при помощи SQL-запросов в базы OperationsManager и OperationsManagerDW. Первая для кратковременного хранения, вторая для долговременного. При помощи SQL-запроса получим список узлов, которые находятся на мониторинге в SCOM.
Настроим переменные, которые будут определять фильтры в Grafana и помогут в дальнейшем автоматизировать появление здесь новых узлов.
Другими SQL-запросами в SCOM можно получить статусы узлов (аналогично Zabbix) и список событий. Таким образом, нажав на плитку Active Directory на уровне информационных систем, можно перейти на представление с доменнных контроллеров и соответствующими событиями по ним.
Ну, а дальше посмотреть на значения отдельных метрик узла.
Ещё можно использовать вот такое представление с событиями одновременно для Zabbix и Microsoft SCOM.
Спасибо за внимание! Надеюсь, было интересно.
А ещё у нас есть:
Описание комплексного решения по мониторингу на открытых системах
Zabbix под замком: включаем опции безопасности компонентов Zabbix для доступа изнутри и снаружи
Добавляем CMDB и географическую карту к Zabbix
Если вас интересуют услуги внедрения, администрирования и поддержки Zabbix, вы можете оставить заявку в форме обратной связи на нашем сайте.
