
Практика показала, что хардкорные расшифровки с наших докладов хорошо заходят, так что мы решили продолжать. Сегодня у нас в меню смесь из подходов к поиску и анализу ошибок и крэшей, приправленная щепоткой полезных инструментов, подготовленная на основе доклада Андрея Паньгина aka apangin из Одноклассников на одном из JUG'ов (это была допиленная версия его доклада с JPoint 2016). В без семи минут двухчасовом докладе Андрей подробно рассказывает о стек-трейсах и хип-дампах.
Пост получился просто огромный, так что мы разбили его на две части. Сейчас вы читаете первую часть, вторая часть лежит здесь.
Сегодня я буду рассказывать про стек-трейсы и хип-дампы — тему, с одной стороны, известную каждому, с другой — позволяющую постоянно открывать что-то новое (я даже багу нашел в JVM, пока готовил эту тему).
Когда я делал тренировочный прогон этого доклада у нас в офисе, один из коллег спросил: «Все это очень интересно, но на практике это кому-нибудь вообще полезно?» После этого разговора первым слайдом в свою презентацию я добавил страницу с вопросами по теме на StackOverflow. Так что это актуально.
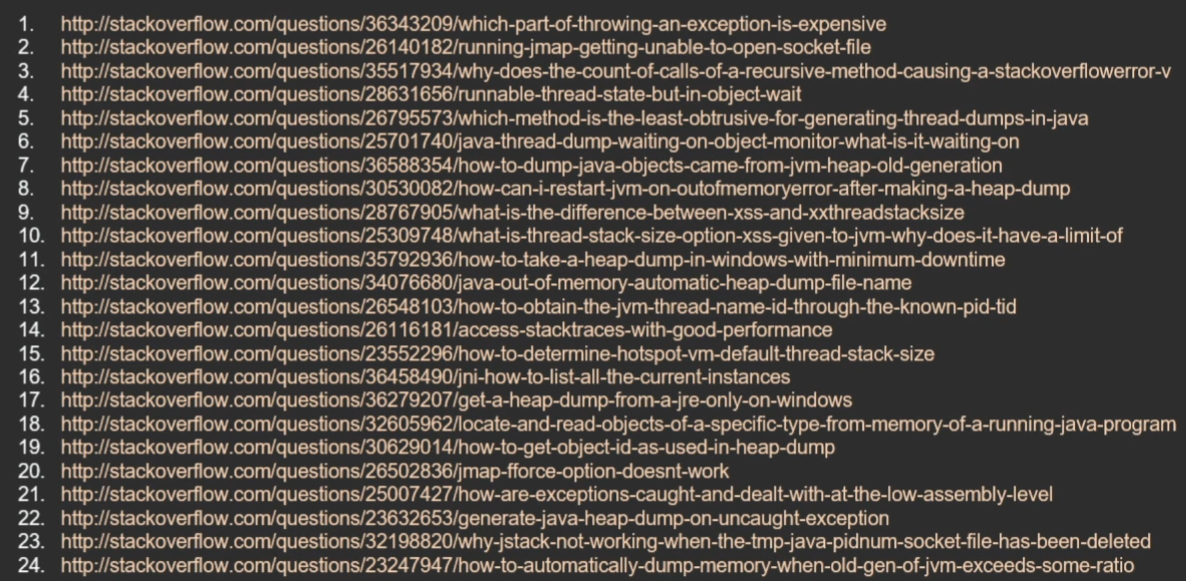
Сам я работаю ведущим программистом в Одноклассниках. И так сложилось, что зачастую мне приходится работать с внутренностями Java — тюнить ее, искать баги, дергать что-то через системные классы (порой не совсем легальными способами). Оттуда я и почерпнул большую часть информации, которую сегодня хотел вам представить. Конечно, в этом мне очень помог мой предыдущий опыт: я 6 лет работал в Sun Microsystems, занимался непосредственно разработкой виртуальной Java-машины. Так что теперь я знаю эту тему как изнутри JVM, так и со стороны пользователя-разработчика.

Когда начинающий разработчик пишет свой «Hello world!», у него выскакивает эксепшн и ему демонстрируется стек-трейс, где произошла эта ошибка. Так что какие-то представления о стек-трейсах есть у большинства.
Перейдем сразу к примерам.
Я написал небольшую программку, которая в цикле 100 миллионов раз производит такой эксперимент: создает массив из 10 случайных элементов типа long и проверяет, сортированный он получился или нет.
По сути он считает вероятность получения сортированного массива, которая приблизительно равна
Что произойдет? Эксепшн, выход за пределы массива.
Давайте разбираться, в чем дело. У нас в консоль выводится:
но стек-трейсов никаких нет. Куда делись?
В HotSpot JVM есть такая оптимизация: у эксепшенов, которые кидает сама JVM из горячего кода, а в данном случае код у нас горячий — 100 миллионов раз дергается, стек-трейсы не генерируются.
Это можно исправить с помощью специального ключика:
Теперь попробуем запустить пример. Получаем все то же самое, только все стек-трейсы на месте.
Подобная оптимизация работает для всех неявных эксепшенов, которые бросает JVM: выход за границы массива, разыменование нулевого указателя и т.д.

Раз оптимизацию придумали, значит она зачем-то нужна? Понятно, что программисту удобнее, когда стек-трейсы есть.
Давайте измерим, сколько «стоит» у нас создание эксепшена (сравним с каким-нибудь простым Java-объектом, вроде Date).
С помощью JMH напишем простенькую бенчмарку и измерим, сколько наносекунд занимают обе операции.

Оказывается, создать эксепшн в 150 раз дороже, чем обычный объект.
И тут не все так просто. Для виртуальной машины эксепшн не отличается от любого другого объекта, но разгадка кроется в том, что практически все конструкторы эксепшн так или иначе сводятся к вызову метода fillInStackTrace, который заполняет стек-трейс этого эксепшена. Именно заполнение стек-трейса отнимает время.
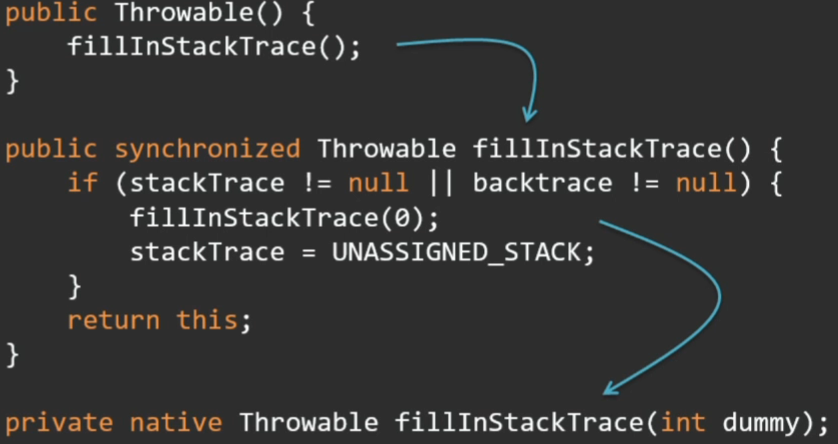
Этот метод в свою очередь нативный, падает в VM рантайм и там гуляет по стеку, собирает все фреймы.
Метод fillInStackTrace публичный, не final. Давайте его просто переопределим:
Теперь создание обычного объекта и эксепшена без стек-трейса отнимают одинаковое время.

Есть и другой способ создать эксепшн без стек-трейса. Начиная с Java 7, у Throwable и у Exception есть protected-конструктор с дополнительным параметром writableStackTrace:
Если туда передать false, то стек-трейс генерироваться не будет, и создание эксепшена будет очень быстрым.
Зачем нужны эксепшены без стек-трейсов? К примеру, если эксепшн используется в коде в качестве способа быстро выбраться из цикла. Конечно, лучше так не делать, но бывают случаи, когда это действительно дает прирост производительности.
А сколько стоит бросить эксепшн?
Рассмотрим разные случаи: когда он бросается и ловится в одном методе, а также ситуации с разной глубиной стека.
Вот, что дают измерения:

Т.е. если у нас глубина небольшая (эксепшн ловится в том же фрейме или фреймом выше — глубина 0 или 1), эксепшн ничего не стоит. Но как только глубина стека становится большой, затраты совсем другого порядка. При этом наблюдается четкая линейная зависимость: «стоимость» исключения почти линейно зависит от глубины стека.
Дорого стоит не только получение стек-трейса, но и дальнейшие манипуляции — распечатка, отправка по сети, запись, — все, для чего используется метод getStackTrace, который переводит сохраненный стек-трейс в объекты Java.
Видно, что преобразование стек-трейса в 10 раз «дороже» его получения:

Почему это происходит?
Вот метод getStackTrace в исходниках JDK:
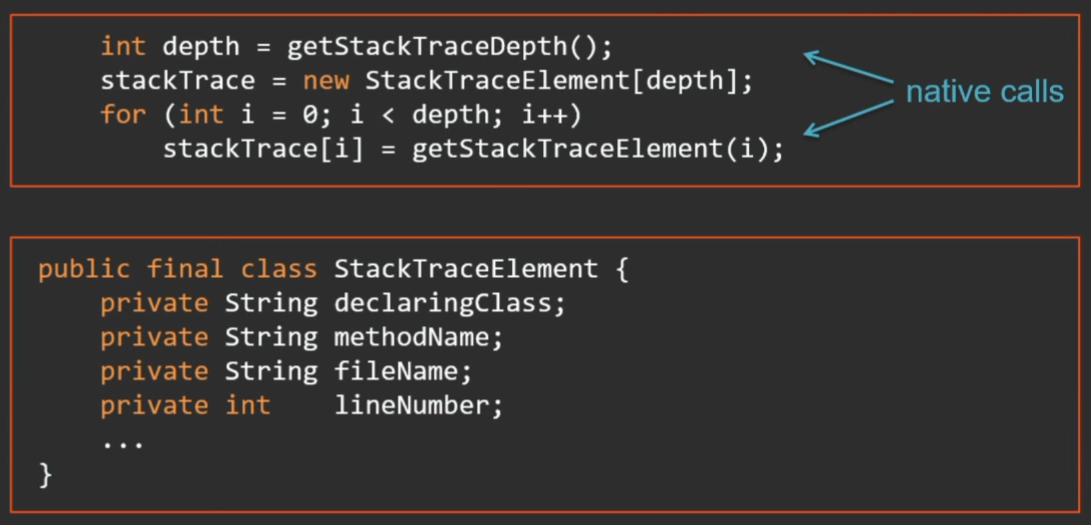
Сначала через вызов нативного метода мы узнаем глубину стека, потом в цикле до этой глубины вызываем нативный метод, чтобы получить очередной фрейм и сконвертировать его в объект StackTraceElement (это нормальный объект Java с кучей полей). Мало того, что это долго, процедура отнимает много памяти.
Более того, в Java 9 этот объект дополнен новыми полями (в связи с известным проектом модуляризации) — теперь каждому фрейму приписывается отметка о том, из какого он модуля.
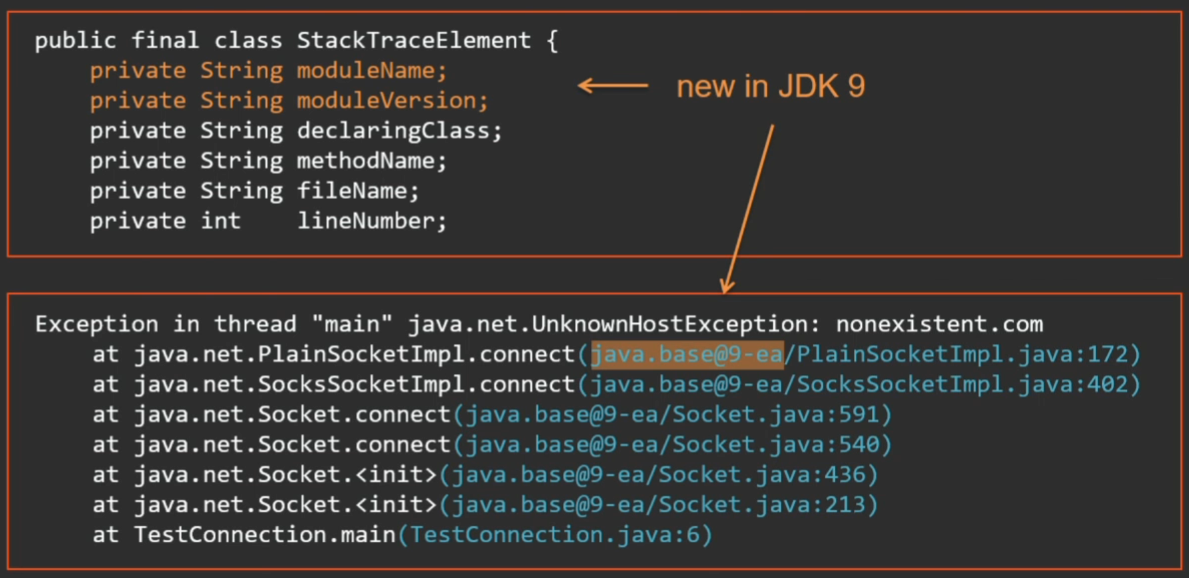
Привет тем, кто парсит эксепшены с помощью регулярных выражений. Готовьтесь к сюрпризам в Java 9 — появятся еще и модули.
Чтобы узнать, что же делает программа, проще всего взять тред дамп, например, утилитой jstack.
Фрагменты вывода этой утилиты:
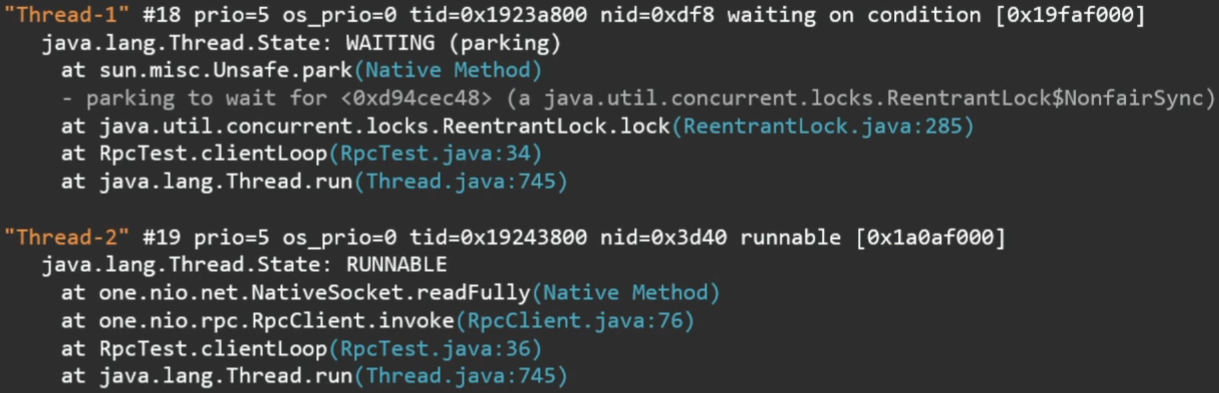
Что здесь видно? Какие есть потоки, в каком они состоянии и их текущий стек.
Более того, если потоки захватили какие-то локи, ожидают входа в synchronized-секцию или взятия ReentrantLock, это также будет отражено в стек-трейсе.
Порой полезным оказывается малоизвестный идентификатор:
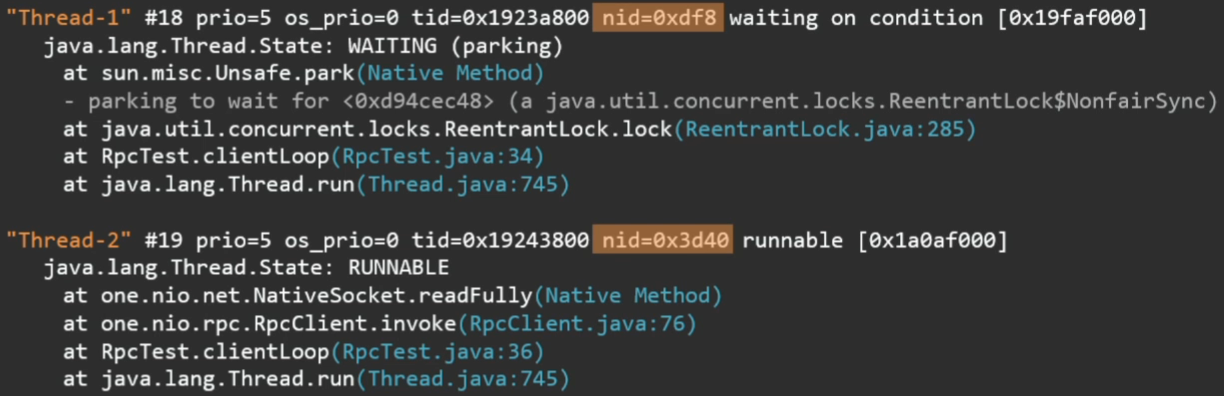
Он напрямую связан с ID потока в операционной системе. Например, если вы смотрите программой top в Linux, какие треды у вас больше всего едят CPU, pid потока — это и есть тот самый nid, который демонстрируется в тред дампе. Можно тут же найти, какому Java-потоку он соответствует.
В случае с мониторами (с synchronized-объектами) прямо в тред дампе будет написано, какой тред и какие мониторы держит, кто пытается их захватить.
В случае с ReentrantLock это, к сожалению, не так. Здесь видно, как Thread 1 пытается захватить некий ReentrantLock, но при этом не видно, кто этот лок держит. На этот случай в VM есть опция:
Если мы запустим то же самое с PrintConcurrentLocks, в тред дампе увидим и ReentrantLock.
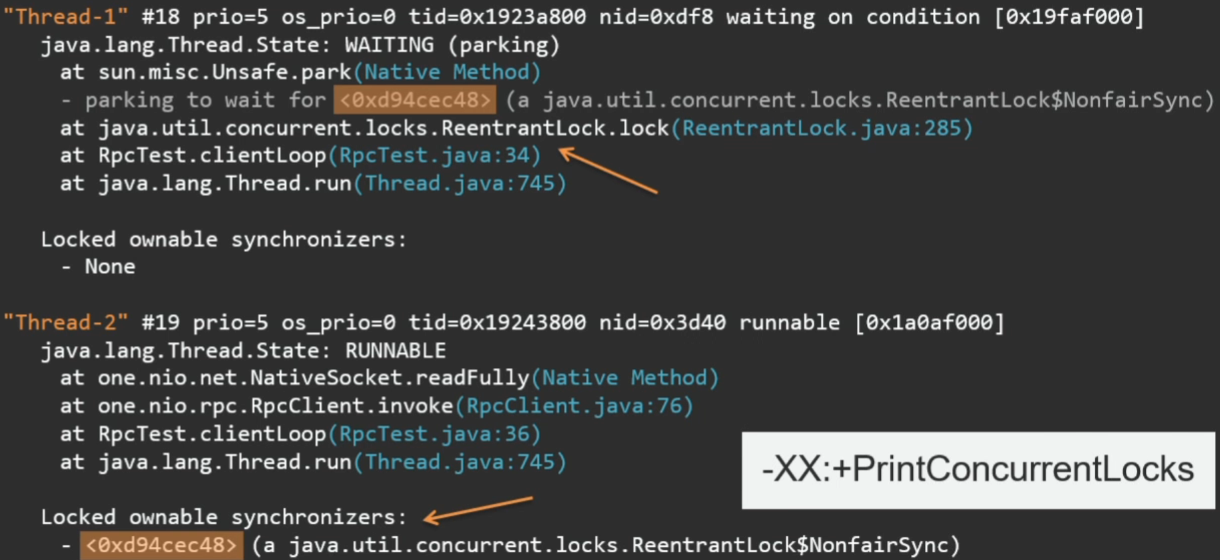
Здесь указан тот самый id лока. Видно, что его захватил Thread 2.
Если опция такая хорошая, почему бы ее не сделать «по умолчанию»?
Она тоже чего-то стоит. Чтобы напечатать информацию о том, какой поток какие ReentrantLock’и держит, JVM пробегает весь Java heap, ищет там все ReentrantLock’и, сопоставляет их с тредами и только потом выводит эту информацию (у треда нет информации о том, какие локи он захватил; информация есть только в обратную сторону — какой лок связан с каким тредом).
В указанном примере по названиям потоков (Thread 1 / Thread 2) непонятно, к чему они относятся. Мой совет из практики: если у вас происходит какая-то длинная операция, например, сервер обрабатывает клиентские запросы или, наоборот, клиент ходит к нескольким серверам, выставляйте треду понятное имя (как в случае ниже — прямо IP того сервера, к которому клиент сейчас идет). И тогда в дампе потока сразу будет видно, ответа от какого сервера он сейчас ждет.

Хватит теории. Давайте опять к практике. Этот пример я уже не раз приводил.
Запускаем программку 3 раза подряд. 2 раза она выводит сумму чисел от 0 до 100 (не включая 100), третий — не хочет. Давайте смотреть тред дампы:

Первый поток оказывается RUNNABLE, выполняет наш reduce. Но смотрите, какой интересный момент: Thread.State вроде как RUNNABLE, но при этом написано, что поток in Object.wait().
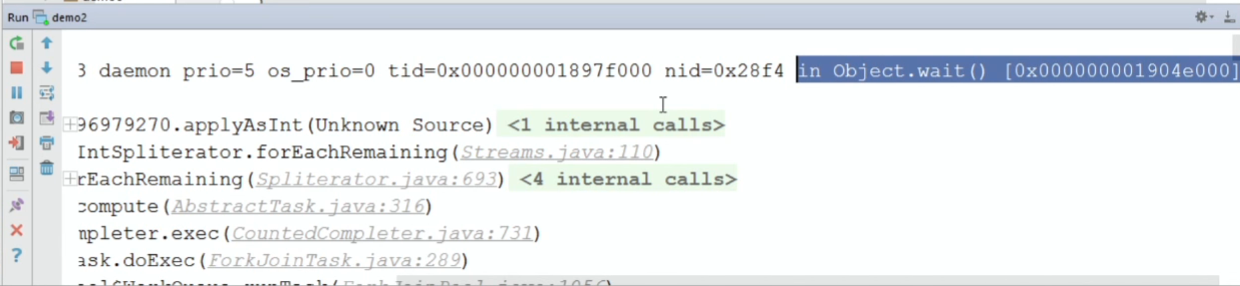
Мне тоже это было не понятно. Я даже хотел сообщить о баге, но оказывается, такая бага заведена много лет назад и закрыта с формулировкой: «not an issue, will not fix».
В этой программке действительно есть дедлок. Его причина — инициализация классов.
Выражение выполняется в статическом инициализаторе класса ParallelSum:
Но поскольку стрим параллельный, исполнение происходит в отдельных потоках ForkJoinPool, из которых вызывается тело лямбды:
Код лямбды записан Java-компилятором прямо в классе ParallelSum в виде приватного метода. Получается, что из ForkJoinPool мы пытаемся обратиться к классу ParallelSum, который в данный момент находится на этапе инициализации. Поэтому потоки начинают ждать, когда же закончится инициализация класса, а она не может закончиться, поскольку ожидает вычисления этой самой свертки. Дедлок.
Почему вначале сумма считалась? Просто повезло. У нас небольшое количество элементов суммируется, и иногда все исполняется в одном потоке (другой поток просто не успевает).
Но почему же тогда поток в стек-трейсе RUNNABLE? Если почитать документацию к Thread.State, станет понятно, что никакого другого состояния здесь быть не может. Не может быть состояния BLOCKED, поскольку поток не заблокирован на Java-мониторе, нет никакой synchronized-секции, и не может быть состояния WAITING, потому что здесь нет никаких вызовов Object.wait(). Синхронизация происходит на внутреннем объекте виртуальной машины, который, вообще говоря, даже не обязан быть Java-объектом.
Представьте себе ситуацию: в куче мест в нашем приложении что-то логируется. Было бы полезно узнать, из какого места появилась та или иная строчка.

В Java нет препроцессора, поэтому нет возможности использовать макросы __FILE__, __LINE__, как в С (эти макросы еще на этапе компиляции преобразуются в текущее имя файла и строку). Поэтому других способов дополнить вывод именем файла и номером строки кода, откуда это было напечатано, кроме как через стек-трейсы, нет.
Генерим эксепшн, у него получаем стек-трейс, берем в данном случае второй фрейм (нулевой — это метод getLocation, а первый — вызывает метод warning).
Как мы знаем, получение стек-трейса и, тем более, преобразование его в стек-трейс элементы очень дорого. А нам нужен один фрейм. Можно ли как-то проще сделать (без эксепшн)?
Помимо getStackTrace у исключения есть метод getStackTrace объекта Thread.
Будет ли так быстрее?
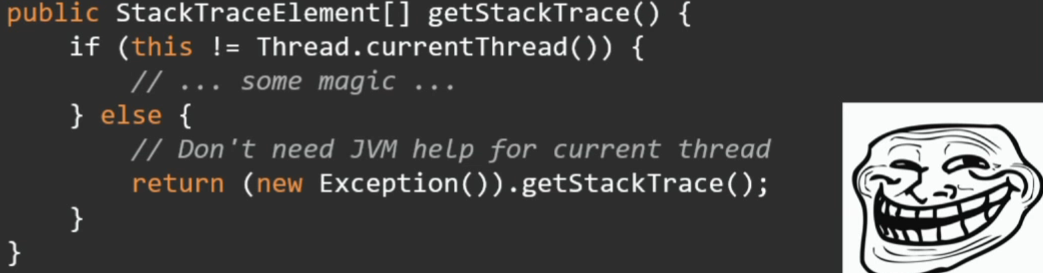
Нет. JVM никакой магии не делает, здесь все будет работать через тот же эксепшн с точно таким же стек-трейсом.
Но хитрый способ все-таки есть:
Я люблю всякие приватные штуки: Unsafe, SharedSecrets и т.д.
Есть аксессор, который позволяет получить StackTraceElement конкретного фрейма (без необходимости преобразовывать весь стек-трейс в Java-объекты). Это будет работать быстрее. Но есть плохая новость: в Java 9 это работать не будет. Там проделана большая работа по рефакторингу всего, что связано со стек-трейсами, и таких методов там теперь просто нет.
Конструкция, позволяющая получить какой-то один фрейм, может быть полезна в так называемых Caller-sensitive методах — методах, чей результат может зависеть от того, кто их вызывает. В прикладных программах с такими методами приходится сталкиваться нечасто, но в самой JDK подобных примеров немало:
В зависимости от того, кто вызывает Class.forName, поиск класса будет осуществляться в соответствующем класс-лоадере (того класса, который вызвал этот метод); аналогично — с получением ResourceBundle и загрузкой библиотеки System.loadLibrary. Также информация о том, кто вызывает, полезна при использовании различных методов, которые проверяют пермиссии (а имеет ли данный код право вызывать этот метод). На этот случай в «секретном» API предусмотрен метод getCallerClass, который на самом деле является JVM-интринсиком и вообще почти ничего не стоит.
Как уже много раз говорилось, приватный API — это зло, использовать которое крайне не рекомендуется (сами рискуете нарваться на проблемы, подобные тем, что ранее вызвал Unsafe). Поэтому разработчики JDK задумались над тем, что раз этим пользуются, нужна легальная альтернатива — новый API для обхода потоков. Основные требования к этому API:
Известно, что в публичном релизе Java 9 будет java.lang.StackWalker.
Получить его экземпляр очень просто — методом getInstance. У него есть несколько вариантов — дефолтный StackWalker или незначительно конфигурируемый опциями:

Также для оптимизации можно задавать примерную глубину, которая необходима (чтобы JVM могла оптимизировать получение стек-фреймов в batch).
Простейший пример, как этим пользоваться:
Берем StackWalker и вызываем метод forEach, чтобы он обошел все фреймы. В результате получим такой простой стек-трейс:

То же самое с опцией SHOW_REFLECT_FRAMES:
В этом случае добавятся методы, относящиеся к вызову через рефлекшн:

Если добавить опцию SHOW_HIDDEN_FRAMES (она, кстати, включает в себя SHOW_REFLECT_FRAMES, т.е. рефлекшн-фреймы тоже будут показаны):
В стек-трейсе появятся методы динамически-сгенерированных классов лямбд:
А теперь самый главный метод, который есть в StackWalker API — метод walk с такой хитрой непонятной сигнатурой с кучей дженериков:
Метод walk принимает функцию от стек-фрейма.
Его работу проще показать на примере.
Несмотря на то, что все это выглядит страшно, как этим пользоваться — очевидно. В функцию передается стрим, а уже над стримом можно проводить все привычные операции. К примеру, вот так выглядел бы метод getCallerFrame, который достает только второй фрейм: пропускаются первые 2, потом вызывается findFirst:
Метод walk возвращает тот результат, который возвращает эта функция стрима. Все просто.
Для данного конкретного случая (когда нужно получить просто Caller класс) есть специальный shortcut метод:
Еще один пример посложнее.
Обходим все фреймы, оставляем только те, которые относятся к пакету org.apache, и выводим первые 10 в список.
Интересный вопрос: зачем такая длинная сигнатура с кучей дженериков? Почему бы просто не сделать у StackWalker метод, который возвращает стрим?
Если дать API, который возвращает стрим, у JDK теряется контроль над тем, что дальше над этим стримом делают. Можно дальше этот стрим положить куда-то, отдать в другой поток, попробовать его использовать через 2 часа после получения (тот стек, который мы пытались обойти, давно потерян, а тред может быть давно убит). Таким образом будет невозможно обеспечить «ленивость» Stack Walker API.
Основной поинт Stack Walker API: пока вы находитесь внутри walk, у вас зафиксировано состояние стека, поэтому все операции на этом стеке можно делать lazy.
На десерт еще немного интересного.
Как всегда, разработчики JDK прячут от нас кучу сокровищ. И помимо обычных стек-фреймов они для каких-то своих нужд сделали живые стек-фреймы, которые отличаются от обычных тем, что имеют дополнительные методы, позволяющие не только получить информацию о методе и классе, но еще и о локальных переменных, захваченных мониторах и значениях экспрешн-стека данного стек-фрейма.
Защита здесь не ахти какая: класс просто сделали непубличным. Но кто же нам мешает взять рефлекшн и попробовать его? (Примечание: в актуальных сборках JDK 9 доступ к непубличному API через рефлекшн запрещён. Чтобы его разрешить, необходимо добавить опцию JVM
Пробуем на таком примере. Есть программа, которая рекурсивным методом ищет выход из лабиринта. У нас есть квадратное поле size x size. Есть метод visit с текущими координатами. Мы пытаемся из текущей клетки пойти влево / вправо / вверх / вниз (если они не заняты). Если дошли из правой-нижней клетки в левую-верхнюю, считаем, что нашли выход и распечатываем стек.
Запускаем:
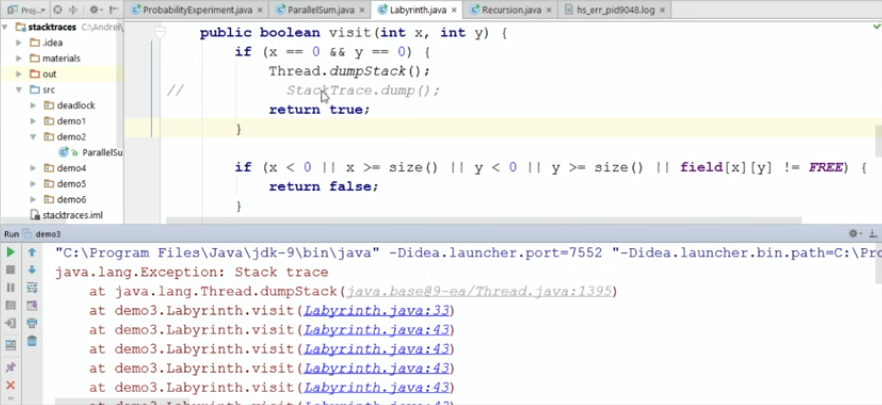
Если я делаю обычный dumpStack, который был еще в Java 8, получаем обычный стек-трейс, из которого ничего не понятно. Очевидно — рекурсивный метод сам себя вызывает, но интересно, на каком шаге (и с какими значениями координат) вызывается каждый метод.
Заменим стандартный dumpStack на наш StackTrace.dump, который через рефлекшн использует live стек-фреймы:
В первую очередь надо получить соответствующий StackWalker, вызвав метод getStackWalker. Все фреймы, которые будут передаваться в getStackWalker, на самом деле будут экземплярами лайв стек-фрейма, у которого есть дополнительные методы, в частности, getLocals для получения локальных переменных.
Запускаем. Получаем то же самое, но у нас отображается весь путь из лабиринта в виде значений локальных переменных:

На этом мы заканчиваем первую часть поста. Вторая часть здесь.
Лично встретиться с Андреем в Москве можно будет уже совсем скоро — 7-8 апреля на JPoint 2017. В этот раз он выступит с докладом «JVM-профайлер с чувством такта», в котором расскажет, как можно получить честные замеры производительности приложения, комбинируя несколько подходов к профилированию. Доклад будет «всего» часовой, зато в дискуссионной зоне никто не будет ограничивать вас от вопросов и горячих споров!
Кроме этого, на JPoint есть целая куча крутых докладов практически обо всем из мира Java — обзор планируемых докладов мы давали в другом посте, а просто программу конференции вы найдете на сайте мероприятия.
Пост получился просто огромный, так что мы разбили его на две части. Сейчас вы читаете первую часть, вторая часть лежит здесь.
Сегодня я буду рассказывать про стек-трейсы и хип-дампы — тему, с одной стороны, известную каждому, с другой — позволяющую постоянно открывать что-то новое (я даже багу нашел в JVM, пока готовил эту тему).
Когда я делал тренировочный прогон этого доклада у нас в офисе, один из коллег спросил: «Все это очень интересно, но на практике это кому-нибудь вообще полезно?» После этого разговора первым слайдом в свою презентацию я добавил страницу с вопросами по теме на StackOverflow. Так что это актуально.

Сам я работаю ведущим программистом в Одноклассниках. И так сложилось, что зачастую мне приходится работать с внутренностями Java — тюнить ее, искать баги, дергать что-то через системные классы (порой не совсем легальными способами). Оттуда я и почерпнул большую часть информации, которую сегодня хотел вам представить. Конечно, в этом мне очень помог мой предыдущий опыт: я 6 лет работал в Sun Microsystems, занимался непосредственно разработкой виртуальной Java-машины. Так что теперь я знаю эту тему как изнутри JVM, так и со стороны пользователя-разработчика.
Стек-трейсы
Стек-трейсы exception
Когда начинающий разработчик пишет свой «Hello world!», у него выскакивает эксепшн и ему демонстрируется стек-трейс, где произошла эта ошибка. Так что какие-то представления о стек-трейсах есть у большинства.
Перейдем сразу к примерам.
Я написал небольшую программку, которая в цикле 100 миллионов раз производит такой эксперимент: создает массив из 10 случайных элементов типа long и проверяет, сортированный он получился или нет.
package demo1;
import java.util.concurrent.ThreadLocalRandom;
public class ProbabilityExperiment {
private static boolean isSorted(long[] array) {
for (int i = 0; i < array.length; i++) {
if (array[i] > array[i + 1]) {
return false;
}
}
return true;
}
public void run(int experiments, int length) {
int sorted = 0;
for (int i = 0; i < experiments; i++) {
try {
long[] array = ThreadLocalRandom.current().longs(length).toArray();
if (isSorted(array)) {
sorted++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.printf("%d of %d arrays are sorted\n", sorted, experiments);
}
public static void main(String[] args) {
new ProbabilityExperiment().run(100_000_000, 10);
}
}По сути он считает вероятность получения сортированного массива, которая приблизительно равна
1/n!. Как это часто бывает, в программке ошиблись на единичку:for (int i = 0; i < array.length; i++)Что произойдет? Эксепшн, выход за пределы массива.
Давайте разбираться, в чем дело. У нас в консоль выводится:
java.lang.ArrayIndexOutOfBoundsExceptionно стек-трейсов никаких нет. Куда делись?
В HotSpot JVM есть такая оптимизация: у эксепшенов, которые кидает сама JVM из горячего кода, а в данном случае код у нас горячий — 100 миллионов раз дергается, стек-трейсы не генерируются.
Это можно исправить с помощью специального ключика:
-XX:-OmitStackTraceInFastThrowТеперь попробуем запустить пример. Получаем все то же самое, только все стек-трейсы на месте.
Подобная оптимизация работает для всех неявных эксепшенов, которые бросает JVM: выход за границы массива, разыменование нулевого указателя и т.д.
Раз оптимизацию придумали, значит она зачем-то нужна? Понятно, что программисту удобнее, когда стек-трейсы есть.
Давайте измерим, сколько «стоит» у нас создание эксепшена (сравним с каким-нибудь простым Java-объектом, вроде Date).
@Benchmark
public Object date() {
return new Date();
}
@Benchmark
public Object exception() {
return new Exception();
}
С помощью JMH напишем простенькую бенчмарку и измерим, сколько наносекунд занимают обе операции.
Оказывается, создать эксепшн в 150 раз дороже, чем обычный объект.
И тут не все так просто. Для виртуальной машины эксепшн не отличается от любого другого объекта, но разгадка кроется в том, что практически все конструкторы эксепшн так или иначе сводятся к вызову метода fillInStackTrace, который заполняет стек-трейс этого эксепшена. Именно заполнение стек-трейса отнимает время.
Этот метод в свою очередь нативный, падает в VM рантайм и там гуляет по стеку, собирает все фреймы.
Метод fillInStackTrace публичный, не final. Давайте его просто переопределим:
@Benchmark
public Object exceptionNoStackTrace() {
return new Exception() {
@Override
public Throwable fillInStackTrace() {
return this;
}
};
}Теперь создание обычного объекта и эксепшена без стек-трейса отнимают одинаковое время.
Есть и другой способ создать эксепшн без стек-трейса. Начиная с Java 7, у Throwable и у Exception есть protected-конструктор с дополнительным параметром writableStackTrace:
protected Exception(String message, Throwable cause,
boolean enableSuppression,
boolean writableStackTrace);Если туда передать false, то стек-трейс генерироваться не будет, и создание эксепшена будет очень быстрым.
Зачем нужны эксепшены без стек-трейсов? К примеру, если эксепшн используется в коде в качестве способа быстро выбраться из цикла. Конечно, лучше так не делать, но бывают случаи, когда это действительно дает прирост производительности.
А сколько стоит бросить эксепшн?
Рассмотрим разные случаи: когда он бросается и ловится в одном методе, а также ситуации с разной глубиной стека.
@Param("1", "2", "10", "100", "1000"})
int depth;
@Benchmark
public Object throwCatch() {
try {
return recursive(depth);
} catch (Exception e) {
return e;
}
}
Вот, что дают измерения:
Т.е. если у нас глубина небольшая (эксепшн ловится в том же фрейме или фреймом выше — глубина 0 или 1), эксепшн ничего не стоит. Но как только глубина стека становится большой, затраты совсем другого порядка. При этом наблюдается четкая линейная зависимость: «стоимость» исключения почти линейно зависит от глубины стека.
Дорого стоит не только получение стек-трейса, но и дальнейшие манипуляции — распечатка, отправка по сети, запись, — все, для чего используется метод getStackTrace, который переводит сохраненный стек-трейс в объекты Java.
@Benchmark
public Object fillInStackTrace() {
return new Exception();
}
@Benchmark
public Object getStackTrace() {
return new Exception().getStackTrace();
}
Видно, что преобразование стек-трейса в 10 раз «дороже» его получения:
Почему это происходит?
Вот метод getStackTrace в исходниках JDK:
Сначала через вызов нативного метода мы узнаем глубину стека, потом в цикле до этой глубины вызываем нативный метод, чтобы получить очередной фрейм и сконвертировать его в объект StackTraceElement (это нормальный объект Java с кучей полей). Мало того, что это долго, процедура отнимает много памяти.
Более того, в Java 9 этот объект дополнен новыми полями (в связи с известным проектом модуляризации) — теперь каждому фрейму приписывается отметка о том, из какого он модуля.
Привет тем, кто парсит эксепшены с помощью регулярных выражений. Готовьтесь к сюрпризам в Java 9 — появятся еще и модули.
Давайте подведем итоги
- создание самого объекта эксепшн — дешевое;
- занимает время получение его стек-трейса;
- еще дороже — преобразование этого внутреннего стек-трейса в Java-объект в StackTraceElement. Сложность этого дела прямо пропорциональна глубине стека.
- бросание эксепшн — быстрое, оно почти ничего не стоит (почти как безусловный переход),
- но только если эксепшн ловится в том же фрейме. Тут надо дополнить еще, что JIT у нас умеет инлайнить методы, поэтому один скомпилированный фрейм может в себя включать несколько Java-методов, заинлайниных друг в друга. Но если эксепшн ловится где-то глубже по стеку, его дороговизна пропорциональна глубине стека.
Пара советов:
- отключайте на продакшене оптимизацию, возможно, это сэкономит много времени на отладке:
-XX:-OmitStackTraceInFastThrow
- не используйте эксепшены для управления потоком программы; это считается не очень хорошей практикой;
- но если вы все-таки прибегаете к этому способу, позаботьтесь о том, чтобы эксепшены были быстрыми и лишний раз не создавали стек-трейсы.
Стек-трейсы в тред дампах
Чтобы узнать, что же делает программа, проще всего взять тред дамп, например, утилитой jstack.
Фрагменты вывода этой утилиты:
Что здесь видно? Какие есть потоки, в каком они состоянии и их текущий стек.
Более того, если потоки захватили какие-то локи, ожидают входа в synchronized-секцию или взятия ReentrantLock, это также будет отражено в стек-трейсе.
Порой полезным оказывается малоизвестный идентификатор:
Он напрямую связан с ID потока в операционной системе. Например, если вы смотрите программой top в Linux, какие треды у вас больше всего едят CPU, pid потока — это и есть тот самый nid, который демонстрируется в тред дампе. Можно тут же найти, какому Java-потоку он соответствует.
В случае с мониторами (с synchronized-объектами) прямо в тред дампе будет написано, какой тред и какие мониторы держит, кто пытается их захватить.
В случае с ReentrantLock это, к сожалению, не так. Здесь видно, как Thread 1 пытается захватить некий ReentrantLock, но при этом не видно, кто этот лок держит. На этот случай в VM есть опция:
-XX:+PrintConcurrentLocksЕсли мы запустим то же самое с PrintConcurrentLocks, в тред дампе увидим и ReentrantLock.
Здесь указан тот самый id лока. Видно, что его захватил Thread 2.
Если опция такая хорошая, почему бы ее не сделать «по умолчанию»?
Она тоже чего-то стоит. Чтобы напечатать информацию о том, какой поток какие ReentrantLock’и держит, JVM пробегает весь Java heap, ищет там все ReentrantLock’и, сопоставляет их с тредами и только потом выводит эту информацию (у треда нет информации о том, какие локи он захватил; информация есть только в обратную сторону — какой лок связан с каким тредом).
В указанном примере по названиям потоков (Thread 1 / Thread 2) непонятно, к чему они относятся. Мой совет из практики: если у вас происходит какая-то длинная операция, например, сервер обрабатывает клиентские запросы или, наоборот, клиент ходит к нескольким серверам, выставляйте треду понятное имя (как в случае ниже — прямо IP того сервера, к которому клиент сейчас идет). И тогда в дампе потока сразу будет видно, ответа от какого сервера он сейчас ждет.
Хватит теории. Давайте опять к практике. Этот пример я уже не раз приводил.
package demo2;
import java.util.stream.IntStream;
public class ParallelSum {
static int SUM = IntStream.range(0, 100).parallel().reduce(0, (x, y) -> x + y);
public static void main(String[] args) {
System.out.println(SUM);
}
}Запускаем программку 3 раза подряд. 2 раза она выводит сумму чисел от 0 до 100 (не включая 100), третий — не хочет. Давайте смотреть тред дампы:
Первый поток оказывается RUNNABLE, выполняет наш reduce. Но смотрите, какой интересный момент: Thread.State вроде как RUNNABLE, но при этом написано, что поток in Object.wait().
Мне тоже это было не понятно. Я даже хотел сообщить о баге, но оказывается, такая бага заведена много лет назад и закрыта с формулировкой: «not an issue, will not fix».
В этой программке действительно есть дедлок. Его причина — инициализация классов.
Выражение выполняется в статическом инициализаторе класса ParallelSum:
static int SUM = IntStream.range(0, 100).parallel().reduce(0, (x, y) -> x + y);Но поскольку стрим параллельный, исполнение происходит в отдельных потоках ForkJoinPool, из которых вызывается тело лямбды:
(x, y) -> x + yКод лямбды записан Java-компилятором прямо в классе ParallelSum в виде приватного метода. Получается, что из ForkJoinPool мы пытаемся обратиться к классу ParallelSum, который в данный момент находится на этапе инициализации. Поэтому потоки начинают ждать, когда же закончится инициализация класса, а она не может закончиться, поскольку ожидает вычисления этой самой свертки. Дедлок.
Почему вначале сумма считалась? Просто повезло. У нас небольшое количество элементов суммируется, и иногда все исполняется в одном потоке (другой поток просто не успевает).
Но почему же тогда поток в стек-трейсе RUNNABLE? Если почитать документацию к Thread.State, станет понятно, что никакого другого состояния здесь быть не может. Не может быть состояния BLOCKED, поскольку поток не заблокирован на Java-мониторе, нет никакой synchronized-секции, и не может быть состояния WAITING, потому что здесь нет никаких вызовов Object.wait(). Синхронизация происходит на внутреннем объекте виртуальной машины, который, вообще говоря, даже не обязан быть Java-объектом.
Стек-трейс при логировании
Представьте себе ситуацию: в куче мест в нашем приложении что-то логируется. Было бы полезно узнать, из какого места появилась та или иная строчка.
В Java нет препроцессора, поэтому нет возможности использовать макросы __FILE__, __LINE__, как в С (эти макросы еще на этапе компиляции преобразуются в текущее имя файла и строку). Поэтому других способов дополнить вывод именем файла и номером строки кода, откуда это было напечатано, кроме как через стек-трейсы, нет.
public static String getLocation() {
StackTraceElement s = new Exception().getStackTrace()[2];
return s.getFileName() + ':' + s.getLineNumber();
}
Генерим эксепшн, у него получаем стек-трейс, берем в данном случае второй фрейм (нулевой — это метод getLocation, а первый — вызывает метод warning).
Как мы знаем, получение стек-трейса и, тем более, преобразование его в стек-трейс элементы очень дорого. А нам нужен один фрейм. Можно ли как-то проще сделать (без эксепшн)?
Помимо getStackTrace у исключения есть метод getStackTrace объекта Thread.
Thread.current().getStackTrace()Будет ли так быстрее?
Нет. JVM никакой магии не делает, здесь все будет работать через тот же эксепшн с точно таким же стек-трейсом.
Но хитрый способ все-таки есть:
public static String getLocation() {
StackTraceElement s = sun.misc.SharedSecrets.getJavaLangAccess()
.getStackTraceElement(new Exception(), 2);
return s.getFileName() + ':' + s.getLineNumber();
}
Я люблю всякие приватные штуки: Unsafe, SharedSecrets и т.д.
Есть аксессор, который позволяет получить StackTraceElement конкретного фрейма (без необходимости преобразовывать весь стек-трейс в Java-объекты). Это будет работать быстрее. Но есть плохая новость: в Java 9 это работать не будет. Там проделана большая работа по рефакторингу всего, что связано со стек-трейсами, и таких методов там теперь просто нет.
Конструкция, позволяющая получить какой-то один фрейм, может быть полезна в так называемых Caller-sensitive методах — методах, чей результат может зависеть от того, кто их вызывает. В прикладных программах с такими методами приходится сталкиваться нечасто, но в самой JDK подобных примеров немало:
В зависимости от того, кто вызывает Class.forName, поиск класса будет осуществляться в соответствующем класс-лоадере (того класса, который вызвал этот метод); аналогично — с получением ResourceBundle и загрузкой библиотеки System.loadLibrary. Также информация о том, кто вызывает, полезна при использовании различных методов, которые проверяют пермиссии (а имеет ли данный код право вызывать этот метод). На этот случай в «секретном» API предусмотрен метод getCallerClass, который на самом деле является JVM-интринсиком и вообще почти ничего не стоит.
sun.reflect.Reflection.getCallerClassКак уже много раз говорилось, приватный API — это зло, использовать которое крайне не рекомендуется (сами рискуете нарваться на проблемы, подобные тем, что ранее вызвал Unsafe). Поэтому разработчики JDK задумались над тем, что раз этим пользуются, нужна легальная альтернатива — новый API для обхода потоков. Основные требования к этому API:
- чтобы можно было обойти только часть фреймов (если нам нужно буквально несколько верхних фреймов);
- возможность фильтровать фреймы (не показывать ненужные фреймы, относящиеся к фреймворку или системным классам);
- чтобы эти фреймы конструировались ленивым образом (lazy) — если нам не нужно получать информацию о том, с каким файлом он связан, эта информация преждевременно не извлекается;
- как в случае с getCallerClass — нам нужно не имя класса, а сам инстанс java.lang.Class.
Известно, что в публичном релизе Java 9 будет java.lang.StackWalker.
Получить его экземпляр очень просто — методом getInstance. У него есть несколько вариантов — дефолтный StackWalker или незначительно конфигурируемый опциями:
- опция RETAIN_CLASS_REFERENCE означает, что вам нужны не имена классов, а именно инстансы;
- прочие опции позволяют показать в стек-трейсе фреймы, относящиеся к системным классам и классам рефлекшн (по умолчанию они не будут показаны в стек-трейсе).
Также для оптимизации можно задавать примерную глубину, которая необходима (чтобы JVM могла оптимизировать получение стек-фреймов в batch).
Простейший пример, как этим пользоваться:
StackWalker sw = StackWalker.getInstance();
sw.forEach(System.out::println);Берем StackWalker и вызываем метод forEach, чтобы он обошел все фреймы. В результате получим такой простой стек-трейс:
То же самое с опцией SHOW_REFLECT_FRAMES:
StackWalker sw = StackWalker.getInstance(StackWalker.Option.SHOW_REFLECT_FRAMES);
sw.forEach(System.out::println);В этом случае добавятся методы, относящиеся к вызову через рефлекшн:
Если добавить опцию SHOW_HIDDEN_FRAMES (она, кстати, включает в себя SHOW_REFLECT_FRAMES, т.е. рефлекшн-фреймы тоже будут показаны):
StackWalker sw = StackWalker.getInstance(StackWalker.Option.SHOW_HIDDEN_FRAMES);
sw.forEach(System.out::println);В стек-трейсе появятся методы динамически-сгенерированных классов лямбд:
А теперь самый главный метод, который есть в StackWalker API — метод walk с такой хитрой непонятной сигнатурой с кучей дженериков:
public <T> T walk(Function<? super Stream<StackFrame>, ? extends T> function)Метод walk принимает функцию от стек-фрейма.
Его работу проще показать на примере.
Несмотря на то, что все это выглядит страшно, как этим пользоваться — очевидно. В функцию передается стрим, а уже над стримом можно проводить все привычные операции. К примеру, вот так выглядел бы метод getCallerFrame, который достает только второй фрейм: пропускаются первые 2, потом вызывается findFirst:
public static StackFrame getCallerFrame() {
return StackWalker.getInstance()
.walk(stream -> stream.skip(2).findFirst())
.orElseThrow(NoSuchElementException::new);
}
Метод walk возвращает тот результат, который возвращает эта функция стрима. Все просто.
Для данного конкретного случая (когда нужно получить просто Caller класс) есть специальный shortcut метод:
return StackWalker.getInstance(RETAIN_CLASS_REFERENCE).getCallerClass();Еще один пример посложнее.
Обходим все фреймы, оставляем только те, которые относятся к пакету org.apache, и выводим первые 10 в список.
StackWalker sw = StackWalker.getInstance();
List<StackFrame> frames = sw.walk(stream ->
stream.filter(sf -> sf.getClassName().startsWith("org.apache."))
.limit(10)
.collect(Collectors.toList()));
Интересный вопрос: зачем такая длинная сигнатура с кучей дженериков? Почему бы просто не сделать у StackWalker метод, который возвращает стрим?
public Stream<StackFrame> stream();Если дать API, который возвращает стрим, у JDK теряется контроль над тем, что дальше над этим стримом делают. Можно дальше этот стрим положить куда-то, отдать в другой поток, попробовать его использовать через 2 часа после получения (тот стек, который мы пытались обойти, давно потерян, а тред может быть давно убит). Таким образом будет невозможно обеспечить «ленивость» Stack Walker API.
Основной поинт Stack Walker API: пока вы находитесь внутри walk, у вас зафиксировано состояние стека, поэтому все операции на этом стеке можно делать lazy.
На десерт еще немного интересного.
Как всегда, разработчики JDK прячут от нас кучу сокровищ. И помимо обычных стек-фреймов они для каких-то своих нужд сделали живые стек-фреймы, которые отличаются от обычных тем, что имеют дополнительные методы, позволяющие не только получить информацию о методе и классе, но еще и о локальных переменных, захваченных мониторах и значениях экспрешн-стека данного стек-фрейма.
/* package-private */
interface LiveStackFrame extends StackFrame {
public Object[] getMonitors();
public Object[] getLocals();
public Object[] getStack();
public static StackWalker getStackWalker();
}
Защита здесь не ахти какая: класс просто сделали непубличным. Но кто же нам мешает взять рефлекшн и попробовать его? (Примечание: в актуальных сборках JDK 9 доступ к непубличному API через рефлекшн запрещён. Чтобы его разрешить, необходимо добавить опцию JVM
--add-opens=java.base/java.lang=ALL-UNNAMED) Пробуем на таком примере. Есть программа, которая рекурсивным методом ищет выход из лабиринта. У нас есть квадратное поле size x size. Есть метод visit с текущими координатами. Мы пытаемся из текущей клетки пойти влево / вправо / вверх / вниз (если они не заняты). Если дошли из правой-нижней клетки в левую-верхнюю, считаем, что нашли выход и распечатываем стек.
package demo3;
import java.util.Random;
public class Labyrinth {
static final byte FREE = 0;
static final byte OCCUPIED = 1;
static final byte VISITED = 2;
private final byte[][] field;
public Labyrinth(int size) {
Random random = new Random(0);
field = new byte[size][size];
for (int x = 0; x < size; x++) {
for (int y = 0; y < size; y++) {
if (random.nextInt(10) > 7) {
field[x][y] = OCCUPIED;
}
}
}
field[0][0] = field[size - 1][size - 1] = FREE;
}
public int size() {
return field.length;
}
public boolean visit(int x, int y) {
if (x == 0 && y == 0) {
StackTrace.dump();
return true;
}
if (x < 0 || x >= size() || y < 0 || y >= size() || field[x][y] != FREE) {
return false;
}
field[x][y] = VISITED;
return visit(x - 1, y) || visit(x, y - 1) || visit(x + 1, y) || visit(x, y + 1);
}
public String toString() {
return "Labyrinth";
}
public static void main(String[] args) {
Labyrinth lab = new Labyrinth(10);
boolean exitFound = lab.visit(9, 9);
System.out.println(exitFound);
}
}Запускаем:
Если я делаю обычный dumpStack, который был еще в Java 8, получаем обычный стек-трейс, из которого ничего не понятно. Очевидно — рекурсивный метод сам себя вызывает, но интересно, на каком шаге (и с какими значениями координат) вызывается каждый метод.
Заменим стандартный dumpStack на наш StackTrace.dump, который через рефлекшн использует live стек-фреймы:
package demo3;
import java.lang.reflect.Method;
import java.util.Arrays;
public class StackTrace {
private static Object invoke(String methodName, Object instance) {
try {
Class<?> liveStackFrame = Class.forName("java.lang.LiveStackFrame");
Method m = liveStackFrame.getMethod(methodName);
m.setAccessible(true);
return m.invoke(instance);
} catch (ReflectiveOperationException e) {
throw new AssertionError("Should not happen", e);
}
}
public static void dump() {
StackWalker sw = (StackWalker) invoke("getStackWalker", null);
sw.forEach(frame -> {
Object[] locals = (Object[]) invoke("getLocals", frame);
System.out.println(" at " + frame + " " + Arrays.toString(locals));
});
}
}В первую очередь надо получить соответствующий StackWalker, вызвав метод getStackWalker. Все фреймы, которые будут передаваться в getStackWalker, на самом деле будут экземплярами лайв стек-фрейма, у которого есть дополнительные методы, в частности, getLocals для получения локальных переменных.
Запускаем. Получаем то же самое, но у нас отображается весь путь из лабиринта в виде значений локальных переменных:
На этом мы заканчиваем первую часть поста. Вторая часть здесь.
Лично встретиться с Андреем в Москве можно будет уже совсем скоро — 7-8 апреля на JPoint 2017. В этот раз он выступит с докладом «JVM-профайлер с чувством такта», в котором расскажет, как можно получить честные замеры производительности приложения, комбинируя несколько подходов к профилированию. Доклад будет «всего» часовой, зато в дискуссионной зоне никто не будет ограничивать вас от вопросов и горячих споров!
Кроме этого, на JPoint есть целая куча крутых докладов практически обо всем из мира Java — обзор планируемых докладов мы давали в другом посте, а просто программу конференции вы найдете на сайте мероприятия.
