

Когда у масштабного проекта происходит масштабное обновление, всё никогда не бывает просто: неизбежно возникают неочевидные нюансы (проще говоря, грабли). И тогда, как бы хороша ни была документация, с чем-то поможет только опыт — свой или чужой.
На конференции Joker 2018 я рассказал, с какими проблемами столкнулся сам при переходе к Spring Boot 2 и как они решаются. А теперь специально для Хабра — текстовая версия этого доклада. Для удобства в посте есть и видеозапись, и оглавление: можно не читать всё целиком, а перейти непосредственно к волнующей вас проблеме.
Оглавление
- Видеозапись
- Вступление
- Грабли compile time
Примеры проблем
Как быть - Content-Type. Определение типа HTTP-ответа
Проблема
Как быть - Scheduling. Запуск по расписанию
Проблема
Как быть - Spring Cloud & Co. Совместимость библиотек
Проблема
Бонус: сложий случай
Как быть - Relax Binding. Нечёткая привязка параметров
Проблема
Как быть - Unit Testing. Выполнение тестов в Mockito 2
Проблема
Как быть - Gradle Plugin. Сборка Spring Boot проектов
Проблема
Как быть - Прочее
- Заключение. Резюме и выводы
День добрый! Хочу рассказать вам о некоторых особенностях (назовём их граблями), с которыми вы можете столкнуться при обновлении фреймворка Spring Boot на вторую версию и при последующей его эксплуатации.
Меня зовут Владимир Плизгá (GitHub), я работаю в компании «ЦФТ», одном из крупнейших и старейших разработчиков ПО в России. Последние несколько лет занимаюсь там бэкенд-разработкой, отвечая за техническое развитие интернет-банка предоплаченных карт. Как раз на этом проекте я стал инициатором и исполнителем перехода от монолитной архитектуры к микросервисной (который ещё длится). Ну и коль скоро большинство тех знаний, которыми я решил с вами поделиться, накоплено на примере именно этого проекта, расскажу о нём чуть-чуть поподробнее.
Коротко о подопытном продукте
Это интернет-банк, который в одиночку обслуживает порядка двух с лишним десятков компаний-партнёров по всей России: предоставляет конечным клиентам возможность управлять их денежными средствами с помощью дистанционного банковского обслуживания (мобильные приложения, сайты). Один из партнеров — компания Билайн и её платёжная карта. Интернет-банк для нее получился неплохим, судя по рейтингу Markswebb Mobile Banking Rank, где наш продукт занял неплохие позиции для новичков.
«Кишочки» всё ещё в переходном процессе, поэтому у нас есть один монолит, так называемое ядро, вокруг которого возведены 23 микросервиса. Внутри у микросервисов Spring Cloud Netflix, Spring Integration и кое-что ещё. А на Spring Boot 2 всё это дело летает примерно с июля месяца. И вот как раз на этом месте остановимся поподробнее. Переводя этот проект на вторую версию, я столкнулся с некоторыми особенностями, о которых и хочу вам рассказать.
План доклада

Областей, где появились особенности Spring Boot 2, довольно много, постараемся пробежаться по всем. Чтобы сделать это быстро, нам понадобится опытный сыщик или следователь — кто-то, кто всё это раскопает как будто бы за нас. Поскольку Холмс с Ватсоном уже выступили с докладом на Joker, нам будет помогать другой специалист — лейтенант Коломбо. Вперёд!
Spring Boot / 2
Для начала пару слов о Spring Boot в целом и второй версии в частности. Во-первых, вышла эта версия, мягко говоря, не вчера: 1 марта 2018 она уже была в General Availability. Одна из главных целей, которую преследовали разработчики, — это полноценная поддержка Java 8 на уровне исходников. То есть скомпилировать на меньшей версии не удастся, хотя runtime совместим. В качестве основы взят Spring Framework пятой версии, который вышел чуть-чуть раньше Spring Boot 2. И это не единственная зависимость. Ещё у него есть такое понятие, как BOM (Bill Of Materials) — это огромный XML, в котором перечислены все (транзитивные для нас) зависимости от всевозможных сторонних библиотек, дополнительных фреймворков, инструментов и прочего.
Соответственно, не все те спецэффекты, которые привносит второй Spring Boot, произрастают из него самого или из экосистемы Spring. На всё это хозяйство написано два отличных документа: Release Notes и Migration Guide. Документы классные, Spring в этом смысле вообще молодцы. Но, по понятным причинам, там возможно охватить далеко не всё: есть какие-то частности, отклонения и прочее, что либо нельзя, либо не стоит туда включать. О таких особенностях и поговорим.
Compile time. Примеры изменений в API
Начнём с более-менее простых и очевидных граблей: это те, что возникают в compile time. То есть то, что не даст вам даже скомпилировать проект, если вы просто поменяете у Spring Boot в скрипте сборки цифру 1 на цифру 2.
Основной источник изменений, который стал основанием для таких правок в Spring Boot, — это, конечно, переход Spring на Java 8. Кроме того, веб-стек Spring 5 и Spring Boot 2 разделился, условно говоря, на два. Теперь он сервлетный, традиционный для нас, и реактивный. Кроме того, потребовалось учесть ряд недочётов из прошлых версий. Ещё сторонние библиотеки поднакинули (извне Spring). Если посмотреть в Release Notes, то никаких подводных камней с ходу не видно и, честно говоря, когда я впервые читал Release Notes, мне показалось, там вообще всё нормально. И выглядело для меня это примерно вот так:
Но, как вы наверняка догадываетесь, всё не так хорошо.
На чем сломается компиляция (пример 1):
- Почему: класса
WebMvcConfigurerAdapterбольше нет; - Зачем: для поддержки фишек Java 8 (default-методы в интерфейсах);
- Что делать: использовать интерфейс
WebMvcConfigurer.
Проект может не скомпилироваться как минимум из-за того, что некоторых классов просто больше нет. Почему? Да потому что в Java 8 они не нужны. Если это были адаптеры с примитивной имплементацией методов, то пояснять особо нечего, default-методы всё это отлично решают. Вот на примере этого класса понятно, что достаточно использовать сам интерфейс, и никакие адаптеры уже не понадобятся.
На чем сломается компиляция (пример 2):
- Почему: метод
PropertySourceLoader#loadстал возвращать список источников вместо одного; - Зачем: для поддержки мульти-документных ресурсов, например, YAML;
- Что делать: оборачивать ответ в
singletonList()(при переопределении).
Пример из совсем другой области. Некоторые методы изменили даже сигнатуры. Если вам доводилось использовать метод load PropertySourceLoader, то он теперь возвращает коллекцию. Соответственно, это позволило поддержать мульти-документные ресурсы. Например, в YAML через три чёрточки можно указать кучу документов в одном файле. Если теперь вам понадобилось с ним работать из Java, имейте в виду, что это нужно делать через коллекцию.
На чем сломается компиляция (пример 3):
- Почему: некоторые классы из пакета
org.springframework.boot.autoconfigure.webразъехались по пакетамorg.springframework.boot.autoconfigure.web—.servletи.reactive; - Зачем: чтобы поддержать реактивный стек наравне с традиционным;
- Что делать: обновить импорты.
Ещё больше изменений было привнесено тем самым разделением стеков. Например, то, что раньше лежало в одном пакете web, теперь разъехалась по двум пакетам с кучей классов. Это
.servlet и .reactive. Зачем сделано? Потому что реактивный стек не должен был стать огромным костылём поверх сервлетного. Нужно было сделать это так, чтобы они могли поддерживать свой собственный жизненный цикл, развиваться в своих направлениях и не мешать друг другу. Что с этим делать? Достаточно поменять импорты: большинство из этих классов остались совместимыми на уровне API. Большинство, но не все.На чем сломается компиляция (пример 4):
- Почему: поменялась сигнатура методов класса
ErrorAttributes: вместоRequestAttributesстали использоватьсяWebRequest(servlet)иServerRequest(reactive); - Зачем: чтобы поддержать реактивный стек наравне с традиционным;
- Что делать: заменить имена классов в сигнатурах.
Например, в классе ErrorAttributes отныне вместо RequestAttributes в методах стали использоваться два других класса: это WebRequest и ServerRequest. Причина всё та же самая. А что с этим делать? Если вы именно переходите с первого на второй Spring Boot, то надо поменять RequestAttributes на WebRequest. Ну а если вы уже на втором, то использовать ServerRequest. Очевидно, не правда ли?..
Как быть?
Таких примеров довольно много, мы не будем разбирать по полочкам их все. Что с этим делать? Прежде всего, стоит поглядывать в Spring Boot 2.0 Migration Guide для того, чтобы вовремя заметить касающееся вас изменение. Например, в нём упоминаются переименования совершенно неочевидных классов. Ещё, если уж всё-таки что-то разъехалось и поломалось, стоит учитывать, что понятие «web» разделилось на 2: «servlet» и «reactive». При ориентации во всяких классах и пакетах это может помогать. Кроме того, надо иметь в виду, что переименовались не только сами классы и пакеты, но и целые зависимости и артефакты. Как это, например, произошло со Spring Cloud.
Content-Type. Определение типа HTTP-ответа
Хватит об этих простых вещах из compile time, там всё понятно и просто. Поговорим о том, что может твориться во время исполнения и, соответственно, может выстрелить, даже если Spring Boot 2 у вас уже давно работает. Поговорим об определении content-type.

Ни для кого не секрет, что на Spring можно писать веб-приложения, причём как страничные, так и REST API, и они могут отдавать контент с самыми разными типами, будь то XML, JSON или что-то ещё. И одна из прелестей, за которые Spring так любят, — это то, что можно вообще не заморачиваться с определением отдаваемого типа у себя в коде. Можно надеяться на магию. Эта магия работает, условно говоря, тремя разными способами: либо полагается на заголовок Accept, пришедший от клиента, либо на расширение запрошенного файла, либо на специальный параметр в URL, которым, естественно, тоже можно рулить.
Рассмотрим простенький примерчик (полный исходный код). Здесь и далее я буду использовать нотацию от Gradle, но даже если вы поклонник Maven, вам не составит труда понять, что здесь написано: мы собираем малюсенькое приложение на первом Spring Boot и используем всего один starter web.
Пример (v1.x):
dependencies {
ext {
springBootVersion = '1.5.14.RELEASE'
}
compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion")
}
В качестве исполняемого кода у нас один-единственный класс, в котором сразу объявлен метод контроллера.
@GetMapping(value = "/download/{fileName: .+}",
produces = {TEXT_HTML_VALUE, APPLICATION_JSON_VALUE, TEXT_PLAIN_VALUE})
public ResponseEntity<Resource> download(@PathVariable String fileName) {
//формируем только тело ответа, без Content-Type
}
Он принимает на вход некое имя файла, которое якобы сформирует и отдаст. Он действительно формирует его контент в одном из трёх указанных типов (определяя это по имени файла), но никак не задает content-type — у нас же Spring, он сам всё сделает.

В общем-то, можно даже попробовать так сделать. Действительно, если мы будем запрашивать один и тот же документ с разными расширениями, он будет отдаваться с правильным content-type в зависимости от того, что мы возвращаем: хочешь — json, хочешь — txt, хочешь — html. Работает как в сказке.
Обновляем до v2.x
dependencies {
ext {
springBootVersion = '2.0.4.RELEASE'
}
compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion")
}
Приходит время обновляться на второй Spring Boot. Мы просто меняем цифру 1 на 2.

Spring MVC Path Matching Default Behavior Change
Но мы же инженеры, мы ещё заглянем в Migration Guide, а вдруг там что-нибудь про это сказано. Но там упоминается какой-то «suffix path matching». Речь о том, как правильно маппить методы в Java с URL. Но это не наш случай, хотя немножко похоже.

Поэтому забиваем, проверяем и бах! — внезапно не работает. Почему-то везде начинает отдаваться просто text/html, а если покопать, то не именно text/html, а просто первый из типов, указанных вами в атрибуте produces на аннотации @GetMapping. Почему так? Выглядит, мягко говоря, непонятно.

И здесь уже никакие Release Notes не помогут, придётся почитать исходники.
ContentNegotiationManagerFactoryBean
public ContentNegotiationManagerFactoryBean build() {
List<ContentNegotiationStrategy> strategies = new ArrayList<>();
if (this.strategies != null) {
strategies.addAll(this.strategies);
}
else {
if (this.favorPathExtension) {
PathExtensionContentNegotiationStrategy strategy;
// …
Там можно будет найти классик с очень понятным лаконичным коротким именем, в котором упоминается некий флажок под названием «учитывай расширение в пути» (favorPathExtension). Значение этого флажка «истина» соответствует применению некой стратегии с другим понятным коротким лаконичным именем, из которого понятно, что она как раз отвечает за определение content-type по расширению файла. Как видите, если флажок будет равен «ложь», то стратегия не применится.

Да, наверное, многие замечали, что в Spring, видимо, есть какой-то гайдлайн, чтобы имя обязательно было ну хотя бы из двадцати символов.

Если покопаться ещё чуть глубже, то можно нарыть вот такой фрагмент. В самом Spring-фреймворке, причём не в пятой версии, как можно бы было ожидать, а испокон веков этот флажок по умолчанию равен «истина». В то время как в Spring Boot и именно во второй версии он был перекрыт ещё другим, который теперь доступен для управления из настроек. То есть теперь мы можем рулить им из энвайронмента, и это только во второй версии. Чуете? Там он уже принял значение «ложь». То есть хотели, вроде как, сделать как лучше, вынесли этот флажок в настройки (и это здорово), но значение по умолчанию переключили на другое (это уже не очень).
Разработчики фреймворка тоже люди, им тоже свойственно ошибаться. Что с этим делать? Понятно, надо переключить параметр у себя в проекте, и всё будет хорошо.
Единственное, что стоит сделать на всякий случай, для очистки совести, — это заглянуть в документацию на Spring Boot просто на предмет какого-нибудь упоминания этого флажка. И там он действительно упоминается, но только в каком-то странном контексте:
If you understand the caveats and would still like your application to use suffix pattern matching, the following configuration is required:Написано, дескать, если вы понимаете все заковырки и всё ещё хотите использовать suffix path matching, то ставьте этот флажок. Чувствуете расхождение? Вроде как мы говорим-то об определении content-type в контексте этого флажка, а здесь речь о матчинге Java-методов и URL. Выглядит как-то непонятно.
spring.mvc.contentnegotiation.favor-path-extension=true
…
Приходится закапываться дальше. На GitHub есть вот такой pull request:

В рамках данного пулл-реквеста были сделаны эти изменения — переключение значения по умолчанию — и там один из авторов фреймворка говорит, что у этой проблемы есть два аспекта: один — это как раз-таки path matching, а второй — это определение content-type. То есть, другими словами, флажок относится и к тому, и к другому, и они неразрывно связаны.
Можно бы было, конечно, найти это сразу на GitHub, если б знать только, где искать.

Suffix match
Более того, в документации на сам Spring Framework ещё говорится, что использование расширений файлов было необходимо раньше, однако теперь более не считается необходимостью. Более того, оно показало себя проблематичным в ряде случаев.
Резюмируем
Изменение значения флажка по умолчанию — это вовсе не баг, а фича. Она неразрывно связана с определением path matching и призвана делать три вещи:
- снизить риски по безопасности (какие именно, я уточню);
- выровнять поведение WebFlux и WebMvc, они отличались в этом аспекте;
- выровнять заявление в документации с кодом фреймворка.
Как быть?
Во-первых, по возможности нужно не полагаться на определение content-type по расширению. Тот пример, который я показал, — это контрпример, так делать не надо! Равно как и не надо полагаться на то, что запросы вида «GET что-нибудь.json», например, смапятся просто на «GET что-нибудь». Так было в Spring Framework 4 и в Spring Boot 1. Больше так не работает. Если нужно смапиться на файл с расширением, это нужно делать в явном виде. Вместо этого лучше полагаться на заголовок Accept либо на URL-параметр, именем которого вы можете рулить. Ну если это никак не сделать, допустим, у вас какие-то старые мобильные клиенты, которые перестали обновляться в прошлом веке, то придётся вернуть этот флажок, выставить его в «true», и всё будет работать как раньше.
Кроме того, для общего понимания можно почитать главу «Suffix match» в документации на Spring Framework, она самими разработчиками считается своеобразным сборником best practices в этой области, и ознакомиться с тем, что такое атака Reflected File Download, как раз реализуемая с помощью манипуляций с расширением файлов.
Scheduling. Выполнение задач по расписанию или периодически
Давайте немного сменим область рассмотрения и поговорим о выполнении задач по расписанию или периодически.
Пример задачи. Выводить сообщение в лог каждые 3 секунды
О чём идёт речь, я думаю, понятно. У нас есть какие-то бизнес-потребности, делать что-либо с каким-то повтором, поэтому мы сразу перейдём к примеру. Допустим, у нас стоит мегасложная задача: выводить в лог какую-нибудь гадость каждые 3 секунды.

Сделать это можно, очевидно, самыми разными способами, под них по-любому уже что-нибудь есть в Spring. И найти это — способов уйма.
Вариант 1: поиск примера в своём проекте
/**
*A very helpful service
*/
@Service
public class ReallyBusinessService {
// … a bunch of methods …
@Scheduled(fixedDelay = 3000L)
public void runRepeatedlyWithFixedDelay() {
assert Runtime.getRuntime().availableProcessors() >= 4;
}
// … another bunch of methods …
}
Мы можем посмотреть в нашем же проекте и наверняка найдём что-нибудь вот такое. На публичном методе будет висеть одна аннотация, и из неё будет понятно, что как только её вешаешь, всё работает прям как в сказке.
Вариант 2: поиск нужной аннотации

Можно саму аннотацию поискать прямо по названию, и наверняка тоже будет понятно из документации, что её вешаешь — и всё работает.
Вариант 3: Googling
Если себе веры нет, то можно загуглить, и по найденному тоже будет понятно, что с одной аннотации всё заведётся.
@Component
public class EventCreator {
private static final Logger LOG = LoggerFactory.getLogger(EventCreator.class);
private final EventRepository eventRepository;
public EventCreator(final EventRepository eventRepository) {
this.eventRepository = eventRepository;
}
@Scheduled(fixedRate = 1000)
public void create() {
final LocalDateTime start = LocalDateTime.now();
eventRepository.save(
new Event(new EventKey("An event type", start, UUID.randomUUID()), Math.random() * 1000));
LOG.debug("Event created!");
}
}
Кто видит в этом подвох? Мы же инженеры всё-таки, давайте проверим, как это работает в реальности.
Show me the code!
Рассмотрим конкретную задачу (сама задача и код есть в моем репозитории).
Кто не хочет читать, можете посмотреть вот этот фрагмент видео с демонстрацией (до 22-й минуты):
В качестве зависимости будем использовать первый Spring Boot с двумя стартерами. Один — для веба, мы же вроде как веб-сервер разрабатываем, а второй — spring starter actuator, чтобы у нас были production-ready фичи, чтобы мы были хотя бы немножко похожи на что-то настоящее.
dependencies {
ext {
springBootVersion = '1.5.14.RELEASE'
// springBootVersion = '2.0.4.RELEASE'
}
compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion")
compile("org.springframework.boot:spring-boot-starter-actuator:$springBootVersion")
// +100500 зависимостей в случае настоящего приложения
}А исполняемый код у нас будет ещё проще.
package tech.toparvion.sample.joker18.schedule;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.Scheduled;
@SpringBootApplication
public class EnableSchedulingDemoApplication {
private static final Logger log = LoggerFactory.getLogger(EnableSchedulingDemoApplication.class);
public static void main(String[] args) {
SpringApplication.run(EnableSchedulingDemoApplication.class, args);
}
@Scheduled(fixedRate = 3000L)
public void doOnSchedule() {
log.info(“Еще 3 секунды доклада потрачено без дела…”);
}
}
Вообще практически ничего примечательного, кроме одного-единственного метода, на который мы навешали аннотацию. Мы её где-то скопипастили и ожидаем, что она будет работать.
Давайте проверим, мы же инженеры. Запускаем. Мы предполагаем, что каждые три секунды в лог будет выводиться такое сообщение. Всё должно работать из коробки, мы убеждаемся, что у нас всё запущено именно на первом Spring Boot, и ожидаем вывода нужной строчки. Проходит три секунды — строчка выводится, проходит шесть — строчка выводится. Оптимисты победили, всё работает.
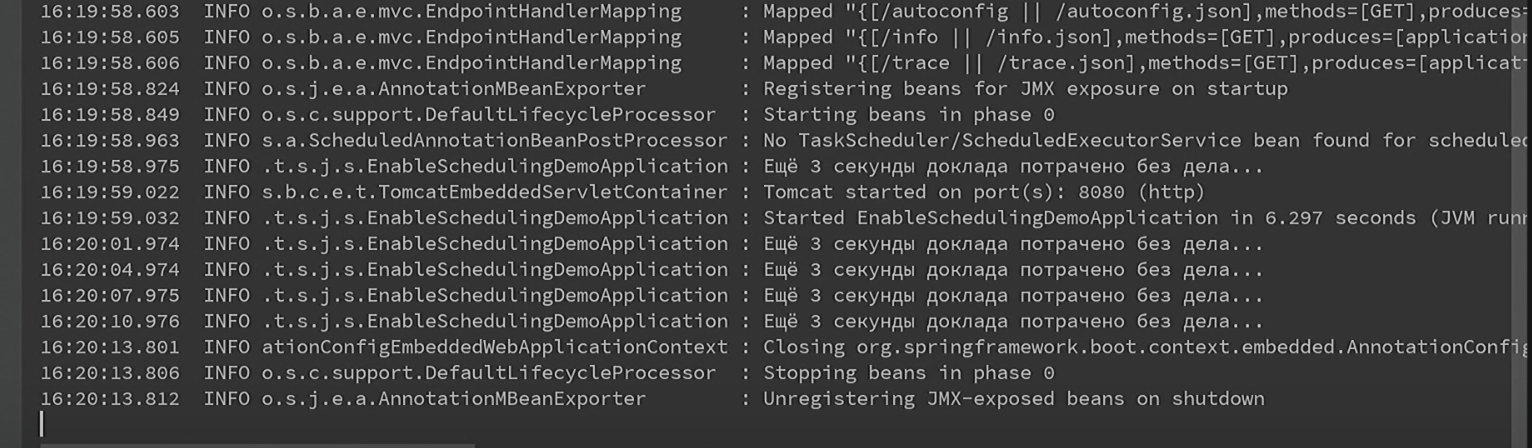
Только приходит время обновляться на второй Spring Boot. Не будем заморачиваться, просто переключимся с одного на другой:
dependencies {
ext {
// springBootVersion = '1.5.14.RELEASE'
springBootVersion = '2.0.4.RELEASE'
}
По идее, Migration Guide нас ни о чём не предупреждал, и мы ожидаем, что всё будет работать без отклонений. С точки зрения исполняемого кода, никакие из других граблей, о которых я упоминал раньше (несовместимость на уровне API или что-то ещё) здесь у нас нет, поскольку приложение максимально простое.
Запускаем. Первым делом убеждаемся, что мы работаем на втором Spring Boot, в остальном никаких, вроде бы, отклонений нет.
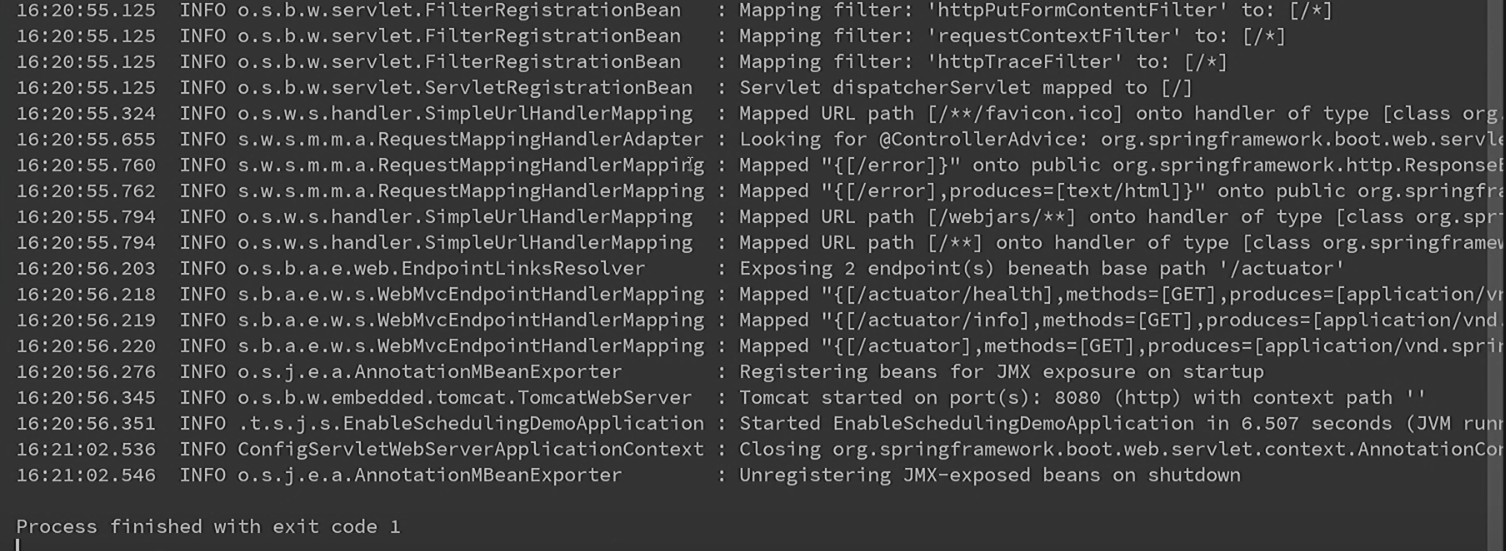
Однако проходит 3 секунды, 6, 9, а Германа всё нет — никакого вывода, ничего не работает.
Как это часто бывает, ожидание расходится с реальностью. Нам часто пишут в документации, что на самом деле в Spring Boot всё работает из коробки, что мы вообще можем с минимальными заморочками просто запуститься как есть, и никакой конфигурации не потребуется. Но как только дело доходит до реальности, часто выясняется, что надо бы всё-таки почитать документацию. В частности, если хорошенько покопаться, там можно найти вот такие строчки:
7.3.1. Enable Scheduling AnnotationsДля того, чтобы заработала аннотация Scheduled, надо повесить ещё одну аннотацию на класс с ещё одной аннотацией. Ну, как обычно в Spring. Но почему оно раньше-то работало? Мы же вроде ничего такого не делали. Очевидно, эта аннотация где-то висела раньше в первом Spring Boot, а сейчас во втором её почему-то нет.
To enable support for @Scheduled and Async annotations, you can add @EnableScheduling and @EnableAsync to one of your @Configuration classes.

Начинаем рыться в исходниках первого Spring Boot. Находим, что есть какой-то класс, на котором она якобы висит. Смотрим ближе, он называется «MetricExportAutoConfiguration» и, судя по всему, отвечает за поставку этих метрик производительности вовне, в какие-нибудь централизованные агрегаторы, и на нём действительно есть эта аннотация.

Причём она работает так, что включает своё поведение на всё приложение сразу, её не надо вешать на отдельные классы. Именно этот класс был поставщиком этого поведения, а потом почему-то не стал. Почему?

Всё тот же GitHub наталкивает нас на такую археологическую раскопку: в рамках перехода на вторую версию Spring Boot этот класс был выкошен вместе с аннотацией. Почему? Да потому что движок поставки метрик тоже изменился: они больше не стали использовать свой самописный, а перешли на Micrometer — действительно осмысленное решение. Вот только вместе с ним удалилось кое-что лишнее. Может быть, это даже правильно.
Кто не хочет читать, смотрите коротенькое демо на 30 секунд:
Из этого следует, что если мы сейчас возьмём и в нашем исходном классе вручную повесим недостающую аннотацию, то, по идее, поведение должно стать корректным.
package tech.toparvion.sample.joker18.schedule;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
@SpringBootApplication
@EnableScheduling
public class EnableSchedulingDemoApplication {
private static final Logger log = LoggerFactory.getLogger(EnableSchedulingDemoApplication.class);
public static void main(String[] args) {
SpringApplication.run(EnableSchedulingDemoApplication.class, args);
}
@Scheduled(fixedRate = 3000L)
public void doOnSchedule() {
log.info(“Еще 3 секунды доклада потрачено без дела…”);
}
}
Как думаете, заработает? Давайте проверять. Запускаем.
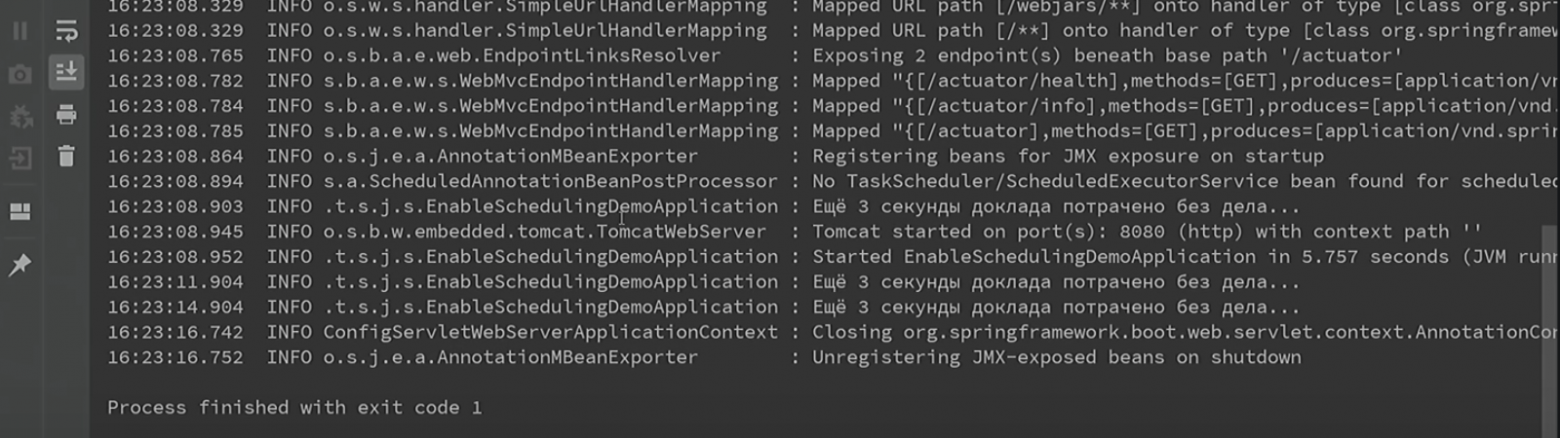
Видно, что через 3 секунды, через 6 и через 9 сообщение, ожидаемое нами, в лог всё-таки выводится.
Как быть?
Что с этим делать в этом конкретном и в более общем случае? Как бы нравоучительно это ни звучало, во-первых, стоит читать не только копируемые фрагменты документации, но и чуть шире, как раз чтобы охватывать вот такие аспекты.
Во-вторых, помнить, что в Spring Boot хоть многие фичи есть из коробки (scheduling, async, caching, …), они не всегда включены, их нужно явно включать.
В-третьих, не мешает перестраховаться: добавлять аннотации Enable* (а их целое семейство) в свой код, не надеясь на фреймворк. Но тогда возникает вопрос: а что будет, если случайно я и мои коллеги добавим несколько аннотаций, как они себя поведут? Сам фреймворк утверждает, что дублирование аннотаций никогда не приводит к ошибкам. А на самом деле: почти никогда. Дело в том, что некоторые из этих аннотаций имеют атрибуты.
Например, @EnableAsync и EnableCaching имеют атрибуты, которые, в частности, управляют тем, в каком режиме будут проксироваться бины для того, чтобы реализовать соответствующую функциональность. Следовательно, вы можете случайно задать эти аннотации в двух местах с разным значением атрибутов. Что в этом случае будет? Частично на этот вопрос отвечает javadoc на один из классов, как раз причастных к этой функциональности. Он говорит, что этот регистратор работает путём поиска ближайшей аннотации. Он знает о том, что есть несколько возможных Enable*, но по большому счёту ему всё равно, какой именно он выберет. К чему это может привести? А вот об этом мы как раз и поговорим в следующем кейсе.
Spring Cloud & Co. Совместимость библиотек

Возьмём за основу маленький микросервис на Spring Boot 2 в качестве базы, навернём на него Spring Cloud — нам понадобится только его фича Service Discovery (обнаружение сервисов по имени). Ещё в качестве мониторинга прикрутим JavaMelody. И ещё нам понадобится какая-нибудь традиционная база. Не важно, какая, лишь бы поддерживала JDBC, поэтому возьмём простейшую H2.

Не в качестве рекламы, а просто для общего понимания скажу, что JavaMelody — это встроенный мониторинг, к которому можно обратиться прямо из приложения и посмотреть всякие графики, метрики и прочее. Удобно в dev-окружении, в test, а в бою она умеет экспортировать метрики для потребления каким-нибудь централизованным инструментом, типа Prometheus.
Наш замес будет выглядеть на Gradle вот таким образом:
dependencies {
ext {
springBootVersion = '2.0.4.RELEASE'
springCloudVersion = '2.0.1.RELEASE'
}
compile("org.springframework.boot:spring-boot-starter-web:$springBootVersion")
runtime("org.springframework.boot:spring-boot-starter-jdbc:$springBootVersion")
runtime group: "org.springframework.cloud",
name: "spring-clooud-starter-netflix-eureka-client",
version: springCloudVersion
runtime("net.bull.javamelody:javamelody-spring-boot-starter:1.72.0")
//…
}
(полный исходный код)
Мы берём две зависимости от Spring Boot — это web и jdbc, от Spring Cloud берём его клиента к eureka (это, если кто не знает, как раз фишка Service Discovery), и сам JavaMelody. Исполняемого кода у нас вообще практически не будет.
@SpringBootApplication
public class HikariJavamelodyDemoApplication {
public static void main(String[] args) {
SpringApplication.run(HikariJavamelodyDemoApplication.class, args);
}
}
Запускаем.

Такое приложение развалится прямо при старте. Выглядеть это будет не очень приятно, а в самом конце лога ошибок будет сказано, что якобы не удалось скастить какой-то там com.sun.proxy к Hikari, HikariDataSource. На всякий случай поясню, что Hikari — это пул коннектов к базе данных, такой же как Tomcat, C3P0 или прочее.

Почему так произошло? Тут нам как раз понадобится помощь следователя.
Материалы дела
Spring Cloud оборачивает dataSource в прокси
Следователь накопал, что Spring Cloud здесь причастен тем, что он оборачивает dataSource (единственный в этом приложении), в прокси. Делает он это для того, чтобы поддержать фичу AutoRefresh или RefreshScope — это когда конфигурацию микросервиса можно подтягивать из другого централизованного микросервисного конфига и на лету её применять. Как раз за счёт прокси он это обновление и проворачивает. Для этого он использует только CGLIB.
Как вы, наверное, знаете в Spring Boot и в принципе в Spring поддерживаются два механизма проксирования: на основе встроенного в JDK механизма (тогда проксируется не сам бин, а его интерфейс) и с помощью библиотеки CGLIB (тогда проектируется сам бин). Обёртывание производится раньше всех BeanPostProcessor’ов за счёт подмены BeanDefinition и задания так называемого фабричного бина, который выпускает целевой бин сразу обернутым в прокси.
JavaMelody оборачивает dataSource в прокси
Второй участник — это JavaMelody. Он тоже оборачивает DataSource в прокси, но делает это для снятия метрик, чтобы перехватывать вызовы и записывать их в своё хранилище. JavaMelody использует только JDK-проксирование, потому что больше никак не умеет, просто не предусмотрели. Но работает он более традиционным способом — при помощи BeanPostProcessor.
Если посмотреть на всё это через призму дебаггера, то будет видно, что непосредственно перед падением DataSource выглядел как обертка в JDK-прокси, внутри которой обёртка CGLIB-прокси. Получилась вот такая матрешка:
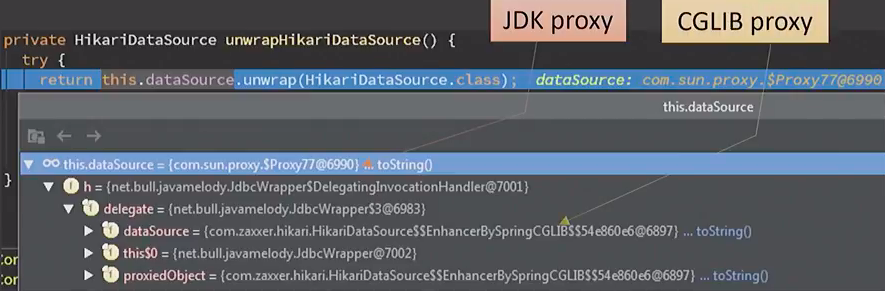
Само по себе это неплохо. Если только не учитывать тот факт, что не все обёртки друг с другом хорошо работают.
Spring Boot вызывает dataSource.unwrap()
Масло в огонь подливает Spring Boot, он делает на этом DataSource#unwrap(), чтобы провалидировать этот бин перед выставлением по JMX. В этом случае JDK-прокси свободно пропускает через себя этот вызов (поскольку ей нечего с ним делать), а CGLIB-прокси, которую добавил Spring Cloud, снова запрашивает бин у Spring Context. Естественно, получает полноценную матрёшку, у которой на внешнем уровне JDK-обёртка, применяет к ней CGLIB API и на этом ломается.
Если показать то же самое в картинках, то выглядит это примерно так:

https://jira.spring.io/browse/SPR-17381
Внешний вызов проходит через внешнюю же оболочку, но вместо того, чтобы делегироваться к целевому бину, ещё раз запрашивает у контекста этот же самый бин. Под это дело заведён баг, он пока ещё не разрешён, но, надеюсь, когда-нибудь это будет поправлено.

Но это не вся картина. При чём тут на самом деле Hikari?
Если понаблюдать, то при замене пула Hikari на какой-нибудь другой пул проблема исчезает, потому что Spring Cloud просто его не оборачивает. Ещё одно наблюдение: Hikari стал пулом по умолчанию именно в Spring Boot 2. Чувствуете? Что-то тут уже попахивает какими-то новшествами. Но казалось бы, где Spring Cloud? Из названия предполагается, что он витает где-то в облаках, а где пул коннектов к базе данных? Тоже не близко. По идее, они не должны друг о друге знать.
А на самом деле…
org.springframework.cloud.autoconfigure.RefreshAutoConfiguration
.RefreshScopeBeanDefinitionEnhancer:
/**
* Class names for beans to post process into refresh scope. Useful when you
* don’t control the bean definition (e.g. it came from auto-configuration).
*/
private Set<String> refreshables = new HashSet<>(
Arrays.asList("com.zaxxer.hikari.HikariDataSource"));
А на самом деле в Spring Cloud есть такой волшебный autoconfiguration, в котором есть ещё более волшебный Enhancer BeanDefinition’ов, в котором пусть не в явном виде, но прямо захардкожена зависимость от Hikari. То есть разработчики Spring Cloud сразу предусмотрели возможность работы именно с этим пулом. И именно поэтому оборачивают его в прокси.
Какие выводы из этого можно сделать? Автообновление бинов в Spring Cloud достаётся не бесплатно, все бины сразу из коробки выходят в CGLIB-обёртках. Это нужно учитывать, например, для того, чтобы знать, что не все прокси-обёртки одинаково хорошо работают друг с другом. Этот пример как раз нам это доказывает (jira.spring.io/browse/SPR-17381). Оборачивать в прокси могут не только BeanPostProcessor, если вы вдруг так думали. Выдавать обёртки можно через подмену BeanDefinition и переопределение фабричного бина ещё до того, как применились все BeanPostProcessor’ы. И ещё Stack Overflow часто учит нас тому, что если вы сталкиваетесь с какой-то такой ересью, то просто порулите флажками, proxyTargetClass переключите с true на false или наоборот, и всё пройдёт. Но не всё проходит, и в некоторых случаях этого флажка просто нет. Мы увидели сразу два таких примера.
По сути дела это просто частный случай такой вот индивидуальной совместимости компонентов, которую приходится учитывать путём вытеснения какого-то одного из них, чтобы вся сбойная комбинация разрушилась.
Вытеснять можно тремя способами:
- Переключиться на другой пул коннектов (например, Tomcat JDBC Pool)
spring.datasource.type=org.apache.tomcat.jdbc.pool.DataSource
Не забыв добавить зависимость
runtime 'org.apache.tomcat:tomcat-jdbc:8.5.29'
Hikari берёт, вроде как, производительностью, но не факт, что вы уже упёрлись в неё, можно вернуться на старый пул Tomcat, который использовался в первом Spring Boot. - Можно потеснить JavaMelody, либо отключив JDBC-мониторинг, либо вытеснив её полностью.
javamelody.excluded-datasources=scopedTarget.dataSource - Отключить автообновление на лету в Spring Cloud.
spring.cloud.refresh.enabled=false
Мы, если помните, втащили эту фичу ради того, чтобы работать с Service Discovery, обновлять бины нам не нужно было вовсе.
Таким образом можно избежать этой проблемы. Она кажется одним вырожденным случаем и можно бы было о нём и не упоминать, но на самом деле проявлений у такой проблемы гораздо больше.
Бонус (схожий случай*)
*но без Spring Cloud (и можно без JavaMelody)
@Component
@ManagedResource
@EnableAsync
public class MyJmxResource {
@ManagedOperation
@Async
public void launchLongLastingJob() {
// какой-то долгоиграющий код
}
}
Полный исходный код: github.com/toparvion/joker-2018-samples/tree/master/jmx-resource.
Возьмём схожий случай. То же самое приложение, только мы выкинем из него Spring Cloud. Можно и JavaMelody выкинуть, оставив лишь один Spring-бин, создаваемый этим мониторингом. А чтобы придать этому проекту больше полезности, мы предположим, что в нём есть класс, который выставляет по JMX один публичный метод. И этот метод якобы выполняет какую-то долгую работу, поэтому мы его пометили как Async, чтобы не заставлять JMX-консоль долго ждать. Чтобы он был виден по JMX, мы вешаем на него аннотацию @ManagedOperation, а чтобы всё это заработало, добавляем ещё два рубильника (как мы любим в Spring — надо накидать больше аннотаций, и тогда всё будет OK).
Так вот если такое приложение запустить, то оно действительно успешно стартанет, не будет никаких ошибок в логах, но, увы, бин myJMXResource не будет доступен по JMX, его даже не будет видно. И если посмотреть через дебаггер, то снова будет видна всё та же самая матрёшка — бин обернут в две прокси, CGLIB и JDK.

Снова JDK и CGLIB-прокси. И сразу становится понятно, что где-то здесь замешан BeanPostProcessor.
И действительно, есть два причастных BeanPostProcessor’а:
AsyncAnnotationBeanPostProcessor
- Должность: директор по работе с аннотацией Async
- Прописка: org.springframework.scheduling
- Место рождения: аннотация @EnableAsync (через Import)
2. DefaultAdvisorAutoProxyCreator
- Должность: помощник по работе с AOP-прокси, отвечает за перехват вызовов для навешивания аспектов
- Прописка: org.springframework.aop.framework.autoproxy
- Место рождения: @Configuration-класс PointcutAdvisorConfig (библиотечный или самописный)
DefaultAdvisorAutoProxyCreator происходит из @Configuration-класса. В моём случае, когда я это дело проходил впервые, это был JavaMelody, но на самом деле он мог быть добавлен и любым другим прикладным configuration-классом. И кстати, если он называется PointcutAdvisorConfig, то с ним будет ещё одно интересное наблюдение.

Стоит его переименовать, как внезапно проблема уходит. Он назывался PointcutAdvisorConfig, стал просто AdvisorConfig, причём это не обычный бин, а configuration-класс, который поставляет бины, то есть, вроде как, ничего не должно сломаться, но поведение реально меняется с ошибочного на корректное или наоборот.
Казалось бы, переименование тут ни при чём, но важно помнить, что где переименование, там и порядок чего-либо.

И в данном случае это порядок BeanPostProcessor’ов. Если посмотреть на их список в двух режимах, когда всё хорошо и когда всё плохо, то будет видно, что эти два BeanPostProcessor следуют в обратном по отношению друг к другу порядке. Если зарыться в кишочки, первый из них клюёт на искусственно добавленный интерфейс Advised (вставленный предыдущим BeanPostProcessor’ом), видит этот интерфейс, думает, что он прикладной, а раз есть прикладной интерфейс, значит, лучше применить JDK-проксирование, оно как раз позволяет это сделать более естественным образом. Он делает и этим всё ломает.
Но на самом деле это не вся картина. Если посмотреть всю цепочку влияния, то она выглядит примерно так:

На обнаружение бина для выставления по JMX повлиял как раз порядок прокси. Тот в свою очередь определился порядком применения BeanPostProcessor. Он неразрывно связан с порядком регистрации BeanPostProcessor’ов, который происходит от порядка имен бинов в контексте, который, в свою очередь, как ни странно, определяется порядком загрузки или сортировки ресурсов с файловой системы или из JAR, в зависимости от того, откуда вы запускаетесь.
Как быть?
Во-первых, по возможности стоит использовать более высокоуровневые абстракции, предоставляемые фреймворком Spring AOP, в частности, аспекты. Почему «по возможности»? Потому что зачастую вы можете даже не знать, что откуда-то у вас существуют бины вот этих Advice и Advisor, они могут быть привнесены сторонними библиотеками, как это было в случае с мониторингом.
Во-вторых, не забывать о best practices. Элементарно, если бы мы взяли и спрятали этот прикладной бин JMX-ресурс под интерфейсом, то проблемы могло бы и не быть. Если всё-таки сломалось, можно посмотреть на состав прокси через отладчик, увидеть, из каких слоёв он состоит. Если вдруг этого не сделано раньше, можно попробовать autowire’ить (заинжектить) этот бин в любой другой. Это позволит вскрыть проблему раньше. Скорее всего, вы увидите по исключению, что там есть какое-то наслоение. В качестве обхода можно попытаться порулить порядком бинов через аннотации Order, чтобы не заниматься случайным переименованием. И там, где это применимо, можно попробовать порулить режимом проксирования, т.е. всё тем же флажком proxyTargetClass, если он применим.
Резюме: что делать в общих случаях, связанных с прокси. Во-первых, «Keep calm and YAGNI». Не стоит думать, что такая жесть ждёт вас за каждым углом и надо прямо сейчас обязательно от неё защищаться. Пробуйте «в лоб», в крайнем случае всегда можно где-то откатиться, где-то попробовать обойти иначе, но не стоит думать, что надо решать эту проблему до того, как она появилась. Если вы привносите новые библиотеки, стоит поинтересоваться, как они работают именно в отношении прокси: создают ли они прокси-объекты, в каком порядке, можно ли повлиять на режимы проксирования — как видите, это не всегда так. И ещё не стоит включать всё подряд на всякий случай. Да, Spring приучает нас к тому, что там ничего не надо делать, всё работает из коробки. И вот доклады того же Кирилла Толкачёва tolkkv, где он показывает, что простенькое приложение состоит из 436-ти бинов, это ярко доказывают. И на этом примере было видно, что не все фичи одинаково полезны.
Relax Binding. Работа со свойствами (параметрами) приложения
О прокси поговорили, переключаемся на другую тему.

https://docs.spring.io/spring-boot/docs/2.0.5.RELEASE/reference/htmlsingle/#boot-features-external-config-relaxed-binding
Есть такой замечательный механизм, как Relax Binding в Spring Boot. Это возможность чтения свойств для приложения откуда-то извне без чёткого их совпадения с именем внутри приложения. Например, если у вас есть в каком-то бине поле firstName и вы хотите, чтобы оно смапилось извне с префиксом acme.my-project.person, то Spring Boot может это обеспечить достаточно лояльным способом. Как бы ни были заданы эти свойства снаружи: через camel case, через дефисы, как принято в переменных окружениях, или как-то ещё — всё это корректно смапится просто на firstName. Как раз это и называется Relax Binding.
Так вот во второй версии Spring Boot’а эти правила немного ужесточились, а ещё утверждается, что с ними стало проще работать из кода приложения — унифицирован способ задания имен свойств в коде приложения. Я, честно говоря, этого не почувствовал, но так написано в документации:
- github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.0-Migration-Guide#relaxed-binding (примерно 1 страница)
- docs.spring.io/spring-boot/docs/2.0.5.RELEASE/reference/htmlsingle/#boot-features-external-config-relaxed-binding (примерно 3 страницы)
- github.com/spring-projects/spring-boot/wiki/Relaxed-Binding-2.0 (примерно 4 страницы)
Чтиво очень увлекательное, советую ознакомиться, много интересного. Но грабли-то остались. Понятно, что всех кейсов там не учтёшь.
Например:
dependencies {
ext {
springBootVersion = '1.5.4.RELEASE'
}
compile("org.springframework.boot:spring-boot-starter:$springBootVersion")
}
(полный исходный код)
У нас есть малюсенькое приложение с одним-единственным стартером, даже не web, на первом Spring Boot, и у него в исполняемом коде теперь уже чуть-чуть побольше всего.
@SpringBootApplication
public class RelaxBindingApplication implements ApplicationRunner {
private static final Logger log =
LoggerFactory.getLogger(RelaxBindingDemoApplication.class);
@Autowired
private SecurityProperties securityProperties;
public static void main(String[] args) {
SpringApplication.run(RelaxBindingDemoApplication.class, args);
}
@Override
public void main run(ApplicationArguments args) {
log.info("KEYSTORE TYPE IS: {}", securityProperties.getKeyStoreType());
}
}
В частности, мы инжектим некий POJO-объект (носитель свойств) и выводим в лог одно из этих свойств, в данном случае KEYSTORE TYPE. Этот POJO представляет из себя два поля с двумя геттерами и сеттерами, значения для которых берутся из applications.properties или application.yaml, не важно.
Если говорить конкретно о поле keystoreType, то оно выглядит как private String keystoreType, а значение задаётся ему в applications.properties: security.keystoreType=jks.
@Component
@ConfigurationProperties(prefix = "security")
public class SecurityProperties {
private String keystorePath;
private String keystoreType;
public String getKeystorePath() {
return keystorePath;
}
public void setKeystorePath(String keystorePath) {
this.keystorePath = keystorePath;
}
public String getKeyStoreType() {
return keystoreType;
}
public void setKeystoreType(String keystoreType) {
this.keystoreType = keystoreType;
}
}
Запустим это на первом Spring Boot и всё будет работать отлично.

Всё выводится, всё работает, поют птицы, играет арфа. Стоит нам обновиться на вторую версию, как приложение внезапно даже не запустится.

Не то что свойство не определится, даже не запустится. И сообщение будет, на первый взгляд, несколько неадекватным, якобы не найден какой-то сеттер для свойства, которого у нас вообще нет в проекте, какой-то key-store-type. То есть стоило нам в первый раз попробовать, всё работало прям огонь, а второй раз делаем фактически то же самое, и уже проходит не очень.
Тут нас может спасти только режим паранойи. Включаем его и проверяем, нет ли у нас такого свойства.

Такого свойства у нас нет. Мы проверяем проект не из 2 миллионов строк, поэтому легко убедиться, что свойство отсутствует. Сопоставляем прямо вот побуквенно и с учётом регистра код в Java и в properties — всё одинаковое, нигде ничего не разъехалось. Но мы же знаем, что, наверное, там не сразу рефлексия применяется, должен ещё быть сеттер, и он тоже должен быть корректным. Проверяем его — сеттер тоже удовлетворяет конвенции для Java bean и полностью соответствует остальным буквам в регистре. На всякий случай, раз уж включили паранойю, проверим геттеры. А вот с геттером есть одна особенность, у него «keystore» написано так, будто это два слова: «Key» и «Store». Внезапненько…

Казалось бы, при чём тут геттер, если не смогли засеттить? Разбираемся.
Оказывается, что первоисточником списка бинов, при вот этом Relax Binding стали внезапно геттеры (в том числе getStoreType()). Не только они, но они в первую очередь. Соответственно, под каждый геттер должен быть найден и свой сеттер. Но под такое свойство, как keyStoreType, никакого сеттера нет. Собственно, об это как раз и ломается Relax Binding, пытаясь найти возможность связывания, и выводит об этом сообщение таким неочевидным образом, как мы видели выше.
Может показаться, что это какой-то вырожденный кейс, там кто-то один раз накосячил, и из этого раздули проблему. Но она может воспроизводиться достаточно легко, если принять поправку на реальность. В действительности класс конфигурации может выглядеть примерно вот так:

А проблема может воспроизводиться не только на том, что кто-то ошибся в одном методе, но и на том, что в результате, например, кривого мёржа или ещё чего-нибудь, в классе оказалось два метода с почти одинаковым именем. Проявление проблемы в этом случае будет таким же.
Как быть?
В первую очередь режим паранойи придётся оставить включенным: сверять регистры букв в именах свойств всё-таки надо. Во-вторых, если вы предполагаете, что у вас в dev-окружении свойства будут браться, например, из YAML и properties, а на боевом — из переменных окружения в операционной системе, то проверьте это заранее, может и не смапиться. В-третьих, было бы здорово ознакомиться c тем самым гайдом, который написали именно по второй версии Relax Binding, достаточно один раз прочитать. Ну и, наконец, надеяться, что в третьей версии Spring Boot всё будет хорошо.
Unit Testing. Выполнение тестов в Mockito 2
Поговорим немного о тестировании, только не о каком-то там высокоуровневом интеграционном и функциональном, а об обычном модульном тестировании при помощи Mockito.
Mockito оказался при делах потому, что если вы подтяните себе в зависимости Spring Boot Starter, ну или вообще тестовую оснастку Spring, то автоматически получите зависимость ещё и от Mockito.
$gradle -q dependencyInsight --configuration testCompile --dependency mockito
org.mockito:mockito-core:2.15.0
variant "runtime"
/--- org.springframework.boot:spring-boot-starter-test:2.0.2.RELEASE
/---testCompile
Но какую версию этой зависимости? Вот тут есть один неочевидный момент. В первой версии Spring Boot использовал Mockito также первой версии, однако с версией 1.5.2 Spring Boot стал допускать ручное включение Mockito 2, то есть стал с ним совместим. Однако по умолчанию это по-прежнему не изменилось. И только со второй версии он стал использовать Mockito 2.
Сам Mockito обновился достаточно давно, ещё в конце 2016-го года вышли Mockito 2.0 и Mockito.2.1— две серьёзные версии с кучей изменений: поддержали Java 8 с её выведением типов, обошли пересечение с библиотекой Hamcrest и учли много набитых давным-давно шишек. И эти версии, как предполагает изменение мажорной цифры, обратно не совместимы с первой.
Всё это приводит к тому, что вы не только сталкиваетесь с кучей проблем в основном коде, но и получаете провальные (хоть и компилируемые) тесты.

Например, у вас был вот такой простенький тест, в котором вы замокали JButton из Swing, выставили ему имя null, а потом проверяете, действительно ли вы выставили какую-то любую строчку. С одной стороны, string’у можно присвоить null, с другой стороны, null не проходит instanceof на string. В общем, в Mockito 1 это всё проходило без проблем, но Mockito 2 уже научился вникать в это дело более основательно и говорит, что anyString на null больше не проходит, он в явном виде выдаст ошибку о том, что такой тест более не является корректным. И заставляет проверять в явном виде: если вы ожидаете там увидеть null, будьте добры так и пропишите. По утверждению разработчиков, они почувствовали, что такое изменение сделает тестовую оснастку чуть более безопасной, чем она была в Mockito 1.
Возьмем похожий, на первый взгляд, пример.
public class MyService {
public void setTarget(Object target) {
//…
}
}
<hr/>
@Test
public void testAnyStringMatcher() {
MyService myServiceMock = mock(MyService.class);
myServiceMock.setTarget(new JButton());
verify(myServiceMock).setTarget(anyString());
}
Допустим, у нас есть прикладной класс с единственным методом, принимающим любой объект. И теперь мы его замокировали и в качестве этого любого объекта задали ему всё тот же JButton. А потом внезапно проверяем его на anyString. Казалось бы, это полная ересь: мы передали кнопку, а проверяем на строчку — вообще не связанные вещи. Но это здесь, в вырожденном одном классе такое кажется безумным. Когда вы проверяете какое-либо поведение приложения под разными углами в 10-ти аспектах с сотней тестов, написать такое на самом деле легко и просто. И Mockito 1 никак не скажет, что вы проверяете полную фигню:
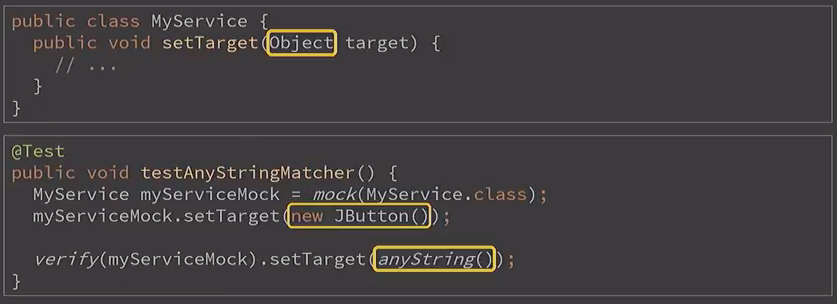
Mockito 2 уже об этом предупредит, хотя, на первый взгляд, anyString ведёт себя точно так же:

Поговорим немножко о другой области. Ещё один пример, только теперь касающийся исключений. Допустим, у нас есть всё тот же прикладной класс, теперь с ещё более простым методом, который вообще ничего не принимает и ничего не делает, и мы хотим сэмулировать в нём падение по SocketTimeoutException, то есть как будто бы там какой-то сетевой сбой внутри. При этом сам метод изначально никаких проверяемых исключений не декларировал, а SocketTimeoutException проверяемый, если помните. Так вот такой тест без проблем проходил в Mockito 1.
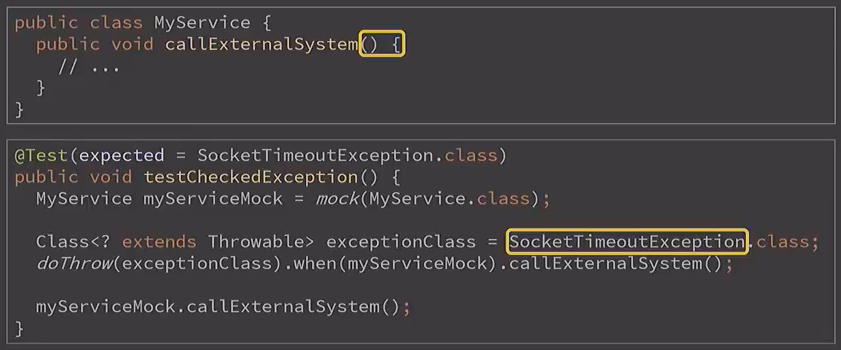
А вот Mockito 2 уже научился в это дело вникать и говорить, что проверяемое исключение для данного случая не валидно:

Фишка в том, что Mockito 1 тоже умел так делать, но только в том случае, если исключение было создано именно как экземпляр класса. То есть если вы создали new SocketTimeoutException прямо через new, через constructor, то Mockito 1 бы тоже заругался.
Что с этим делать? Придётся оборачивать такие исключения, например, в RuntimeException, а потом уже вышвыривать их из класса, так как теперь Mockito стал более чётким в проверках.
Таких кейсов достаточно много. Я привёл парочку примеров, а остальное обозначу лишь в общих чертах. В первую очередь это несовместимость в compile-time. Кое-какие классы переехали в другие пакеты, чтобы не пересекаться с Hamcrest. Касательно Spring Boot, в Mockito 1 больше не поддерживаются классы @MockBean и @SpyBean. И ещё отдельного внимания заслуживает полноценный тестовый фреймворк, который запилили в Spring Integration, мне довелось приложить к нему руку в части review.
(Почитать: https://docs.spring.io/spring-integration/docs/5.0.0.RELEASE/reference/htmlsingle/#testing)
Как быть?
Как бы нравоучительно ни звучало, но те практики, которые рекомендовались для использования с Mockito 1, зачастую позволяют обходить проблем с Mockito 2 (dzone.com/refcardz/mockito).
Во-вторых, если вам ещё предстоит такой переход, вы можете сделать его заранее, начав с версии Spring Boot 1.5.2 использовать Mockito 2.
В-третьих, конечно, можно учитывать те гайды, которые приведены для Mockito 2, и на них уже собрано уже довольно много интересного опыта: раз, два.
Gradle Plugin. Сборка Spring Boot проектов
Последнее, о чем хотелось бы поговорить, — это Spring Boot-плагин для Gradle.
В самом Migration Guide сказано, что Spring Boot плагин для Gradle был изрядненько переписан. Что есть, то есть. Из основного: ему теперь нужен Gradle 4 версии (соответственно, хотя бы пустой settings.gradle в корне проекта). Он больше по умолчанию не подключает dependency management plugin, чтобы было поменьше магии. И ещё задача bootRepackage, самая магическая, распалась на две: на bootWar и bootJar. Вот как раз на bootJar мы чуть поподробнее и остановимся.
Задача bootJar:
- Активируется автоматически, если применены плагины org.springframework.boot и java;
- Отключает задачу jar;
- Умеет находить mainClassName (главное имя класса для запуска) разными способами (и валит сборку, если все-таки не нашла).
Казалось бы, такие понятные очевидные выводы, но что из них следует — отнюдь не очевидно, пока не попробуешь, ибо это Gradle, да ещё и со Spring Boot.
О чём конкретно идёт речь? Мы возьмём какое-нибудь простенькое приложение на Spring Boot 2, сборочку, естественно, на Gradle 4 и с использованием вот этого Spring Boot-плагина. И чтобы добавить ему реалистичности, мы сделаем его не обычным, а составным: у нас будет и прикладной код, и библиотека, как это часто делается (общий код выделяется в библиотеку, все остальные от него зависят).

Если на картинках, то вот так. Цифра в имени app1 предполагает, что может быть app2, app3 и т. д. Этот app1 зависит от библиотеки lib.
«Show me the code!»
Корневой проект
subprojects {
repositories {
mavenCentral()
}
apply plugin: 'java'
apply plugin: 'org.springframework.boot'
}
В корневом проекте у нас всё очень просто — применяется два плагина: java и сам Spring Boot ко всем подпроектам.
Кстати, я не упомянул, что это не единственный способ это сделать, можно разными способами. Можно либо в корневом проекте указать, что мы будем применять плагин к каждому подпроекту, либо в каждом подпроекте указать, с чем он будет работать. Ради лаконичности нашего примера выберем первый способ.
app1: скрипт сборки
dependencies {
ext {
springBootVersion = '2.0.4.RELEASE'
}
compile("org.springframework.boot:spring-boot-starter:$springBootVersion")
compile project(':lib')
}
В прикладном коде у нас указана только зависимость от lib и то, что это Spring Boot-приложение.
app1: исполняемый код
@SpringBootApplication
public class GradlePluginDemoApplication implements ApplicationRunner {
//…
@Override
public void run(ApplicationArguments args) {
String appVersion = Util.getAppVersion(getClass());
log.info("Current application version: {}", appVersion);
}
}
В исполняемом коде мы только обратимся к классу Util, лежащему у нас в либе.
lib: исполняемый код
public abstract class Util {
public static String getAppVersion(Class<?> appClass) {
return appClass.getPackage().getImplementationVersion();
}
}
Этот класс Util своим методом getAppVersion просто обратится к пакету, возьмёт у него манифест, запросит ImplementationVersion и вернёт её. А скрипт сборки у этого подпроекта вообще пустой.

Если запускать такое приложение из IDE, всё будет нормально, она разрешит все зависимости, и всё будет работать идеально. Но стоит выполнить gradle build извне IDE вручную, как сборка сломается. И причиной станет внезапно невозможность разрешения зависимости от Util. То есть, казалось бы, библиотека лежит совсем рядышком, но найти её компилятор не может, потому что якобы не видит такого пакета.
Результаты расследования
Причины:
- bootJar глушит собою jar;
- Gradle поставляет зависимости подпроектам на основе выхлопа от jar.
Следствия:
- Компилятор не может разрешить зависимость от библиотеки;
- Все атрибуты манифеста, выставленные на задаче jar (тот же ImplementationVersion), игнорируются.
Как можно это исправить? Один из вариантов: сделать в самом корневом скрипте вот такое исключение.

То есть как бы оторвать применение Spring Boot-плагина от остальных проектов, сказав, что для lib его применять не нужно. Однако есть и другой способ.
Вариант 2: применять SB Gradle Plugin только к Spring Boot-подпроектам
bootJar {
enabled = false
}
Если мы не хотим, чтобы корневой проект знал о каких-то отдельной вычурной библиотеке, можно в ней самой, точнее, в её скрипте сборки, прописать, что конкретно для этого подпроекта bootJar должен быть выключен. Соответственно, обычная стандартная задача jar останется включенной, и всё будет работать как и прежде.
Прочее
Мы поговорили, наверное, лишь о небольшой доле всех граблей, которые могут встретиться при обновлении Spring Boot. Некоторые из оставшихся я упомяну лишь вкратце.

В Spring Boot за скобками нашего рассмотрения остались многочисленные переименования параметров: они связаны и с переходом на web-стек, на разбивку его на сервлетный и реактивный, и с другими правками. Чтобы с этим как-то работать, со второй версией поставляется такая классная штука, как Spring Boot properties migrator, очень рекомендую задействовать её для того, чтобы понять, какие у вас параметры используются с устаревшими именами. Она прям в лог вам выпишет, что вот этот параметр устарел, его нужно заменить на такой-то, а вот этот отныне бесполезен и так далее.
Ещё много изменений произошло в Actuator. В частности, теперь придётся совсем иначе рулить безопасностью (доступностью) его методов, отныне это больше похоже на Spring Security. Больше нет никаких специальных флажков для этого.

В Spring Cloud произошло много переименований. Это важно потому, что его версия тоже транзитивно будет подтянута вами. Это переименование артефактов, касающихся Netflix и Feign.

В Spring Integration, который тоже достиг пятой версии, как и Spring Framework, произошёл ряд изменений. Одно из самых крупных — это то, что некогда экспериментальный Java DSL въехал в ядро самого проекта и, соответственно, его больше не нужно подключать как отдельную зависимость. Ещё те адаптеры, которые служат для связи с внешним миром, входные и выходные, теперь заполучили свои собственные статические методы, которые могут использоваться в конвейерах на методе handle без специального метода handleWithAdapter.
Заключение. Резюме и выводы
Резюмируя, я обозначу четыре области, от которых стоит ждать подвохов:

При обновлении это, в первую очередь, конечно, Web, поскольку разделение стеков не могло пройти незамеченным.
Второе (Properties Binding), связывание внешних параметров, тоже изрядно доставляет удовольствие за счёт того, что изменился механизм Relax Binding.
Третье — всё, что связано с механизмами проксирования: это всякое кэширование, AOP и прочее, тоже может стать источником изменений за счёт того, что в Spring Boot 2 по умолчанию изменился режим проксирования.
И, наконец, четвёртое, тесты — как раз потому, что произошло обновление с Mockito 1 на Mockito 2. Но это всё какие-то общие слова, а как с этим быть?
- Пробовать «с нахрапа» (YAGNI)
- Сверяться с образцами;
- Проверять обновления в Migration Guide;
- Смотреть другие грабледайджесты: раз, два
Во-первых, не надо думать, что такие грабли будут ждать вас на каждом шагу, стоит пробовать запускаться как есть, помнить о принципе YAGNI. До тех пор, пока у вас что-то не сломалось, не надо пытаться это чинить. Такой подход, как минимум, позволит вам оценить масштаб проблем.
Во-вторых, если с чем-то всё-таки столкнулись, можете свериться с некоторыми образцами, которые я насобирал, пока готовился к этому докладу. Там нет никакой лишней логики, они исключительно занимаются воспроизведением конкретных ситуаций, которые документированы, описаны, как что делать и откуда что брать. Плюс к тому не мешало бы периодически заглядывать в сам Migration Guide. Благодаря тому, что этот документ постоянно пополняется и развивается самими разработчиками, велика вероятность того, что как только вы в него загляните, вдруг выяснится, что ваш кейс разрешён и там об этом уже написано.
Есть и другие такие грабледайджесты, которые собирали опыт и обобщали всевозможные грабли при обновлении и дальнейшей эксплуатации Spring Boot. Надеюсь, что все эти советы и знания помогут вам обновиться без проблем и в дальнейшем успешно использовать Spring Boot, поставить его себе на службу, чтобы он служил вам верой и правдой… вплоть до третьей версии.
Если вам понравился доклад, обратите внимание: 5-6 апреля в Москве пройдёт JPoint, и там я выступлю с новым докладом о Spring Boot: в этот раз о переводе Spring Boot-микросервисов с Java 8 на Java 11. Подробности о конференции — на сайте.
