
Современные отчеты покрытия в ряде случаев довольно бесполезны, а способы их измерения подходят в основном лишь разработчикам. Всегда можно узнать процент покрытия или просмотреть код, который не был задействован в ходе выполнения тестов, но что делать, если хочется наглядности, простоты и автоматизации?

Под катом — видео и расшифровка доклада Артема Ерошенко из Qameta Software с конференции Heisenbug. Он представил несколько разработанных простых и элегантных решений, которые помогают команде Яндекс.Вертикалей оценивать покрытие тестов, написанных автоматизаторами тестирования. Артем расскажет, как можно быстро узнавать, что покрыто, как покрыто, какие тесты прошли, и мгновенно смотреть наглядные отчеты.
Меня зовут Артем Ерошенко eroshenkoam, я занимаюсь автоматизацией тестирования уже более 10 лет. Я был автоматизатором тестирования, менеджером команды разработки инструментов, разработчиком инструментов.
На данный момент я консультант в области автоматизации тестирования, работаю с несколькими компаниями, с которыми мы выстраиваем процессы.
Я также являюсь разработчиком и негласным менеджером Allure Report. Недавно мы поправили прикольную штуку: теперь в JUnit 5 есть fixtures.
Моя разработка — Atlas Framework. Если кто-то начинал автоматизировать в 2012 году, когда веб-драйверы Java только начинали свой путь, в этот момент я сделал из опенсорса библиотеку, которая называется HTML Elements.
Html Elements имеет свое продолжение и переосмысление в библиотеке Atlas, которая построена на интерфейсах: там нет классов как таковых, нет полей, очень удобная, легковесная и легко расширяемая библиотека. Если у вас есть желание в ней разобраться, можете прочитать статью или посмотреть доклад.
Мой доклад посвящен проблеме автоматизации тестирования и главным образом — покрытиям. В качестве предыстории, я хотел бы обратиться к тому, как процессы тестирования организованы в Яндекс.Вертикалях.
В команде по автоматизации тестирования Яндекс.Вертикалей всего четыре человека, которые автоматизируют четыре сервиса: Яндекс.Авто, Работа, Недвижимость и Запчасти. То есть это небольшая команда автоматизаторов, которые делают очень много. Мы автоматизируем API, веб-интерфейс, мобильные приложения и так далее. Всего у нас где-то около 15,5 тысяч тестов, которые выполняются на разных уровнях.
Стабильность тестов в команде составляет около 97%, хотя некоторые мои коллеги говорят о 99%. Такая высокая стабильность достигается именно благодаря коротким тестам на очень нативных технологиях. Как правило, наши тесты занимают около 15 минут, что очень емко, и мы запускаем их примерно в 800 потоков. То есть у нас 800 браузеров стартуют одновременно — такой стресс-тест нашего testing'а. В качестве железа мы используем Selenoid (Aerokube). Подробнее об автоматизации тестирования в Яндекс.Вертикалях можно узнать, посмотрев мой доклад 2017 года, который до сих пор актуален.
Еще одна особенность нашей команды состоит в том, что у нас автоматизируют все, в том числе ручные тестировщики, которые вносят большой вклад в развитие автоматизации тестирования. Для них мы устраиваем школы, обучаем их тестам, учим, как писать тесты на API, на веб-интерфейс, и зачастую они помогают сопровождать тесты. Таким образом, ребята, которые отвечают за релиз, сами могут сразу же поправить тест, если потребуется.
В Вертикалях тесты пишут разработчики тестов, причем они настолько сильно увлеклись разработкой тестов, что конкурируют с нами. Об этом процессе подробнее можно узнать из доклада «Полный цикл тестирования React-приложений», где Алексей Андросов и Наталья Стусь рассказывают, как они пишут Unit-тесты на Puppeteer параллельно с нашими Java end-to-end тестами.
В нашей команде тесты пишут и инженеры по автоматизации тестирования. Но зачастую мы занимаемся развитием каких-то новых подходов по их оптимизации. Например, мы внедряли скриншотное тестирование, тестирование через моки, сокращение тестирования. В общем, наше направление в основном — software developer in test(SDET), мы больше про то, как надо писать тесты, а тестовая база наполняется отчасти нами и поддерживается ручными тестировщиками.
Проблема, которая возникает внутри этих процессов, заключается в том, что мы не всегда понимаем, что у нас уже покрыто, а что нет. Просматривая 15 тысяч тестов, не всегда ясно, что именно мы проверяем. Это особенно актуально в контексте общения с менеджерами, которые, конечно, не тестируют, но контролируют и задают вопросы. В частности, если возникает вопрос, протестирована ли конкретная кнопка в интерфейсе или flow, то на него сложно ответить, потому что нужно идти в код тестов и смотреть эту информацию.
Если у вас много тестов на разных языках и их пишут люди с разной степенью подготовки, то рано или поздно возникает вопрос, а не пересекаются ли эти тесты вообще? В контексте этой проблемы вопрос покрытия становится особенно актуальным. Обозначу три ключевые темы:
Прежде всего, определимся с тем, что есть два способа покрытия: покрытие требований и покрытие кода продукта.
Рассмотрим покрытие требований на примере auto.ru. На месте тестировщика auto.ru я бы сделал следующее. Во-первых, я бы погуглил и сразу бы нашел специальную таблицу требований. Это и есть основа покрытий требований.
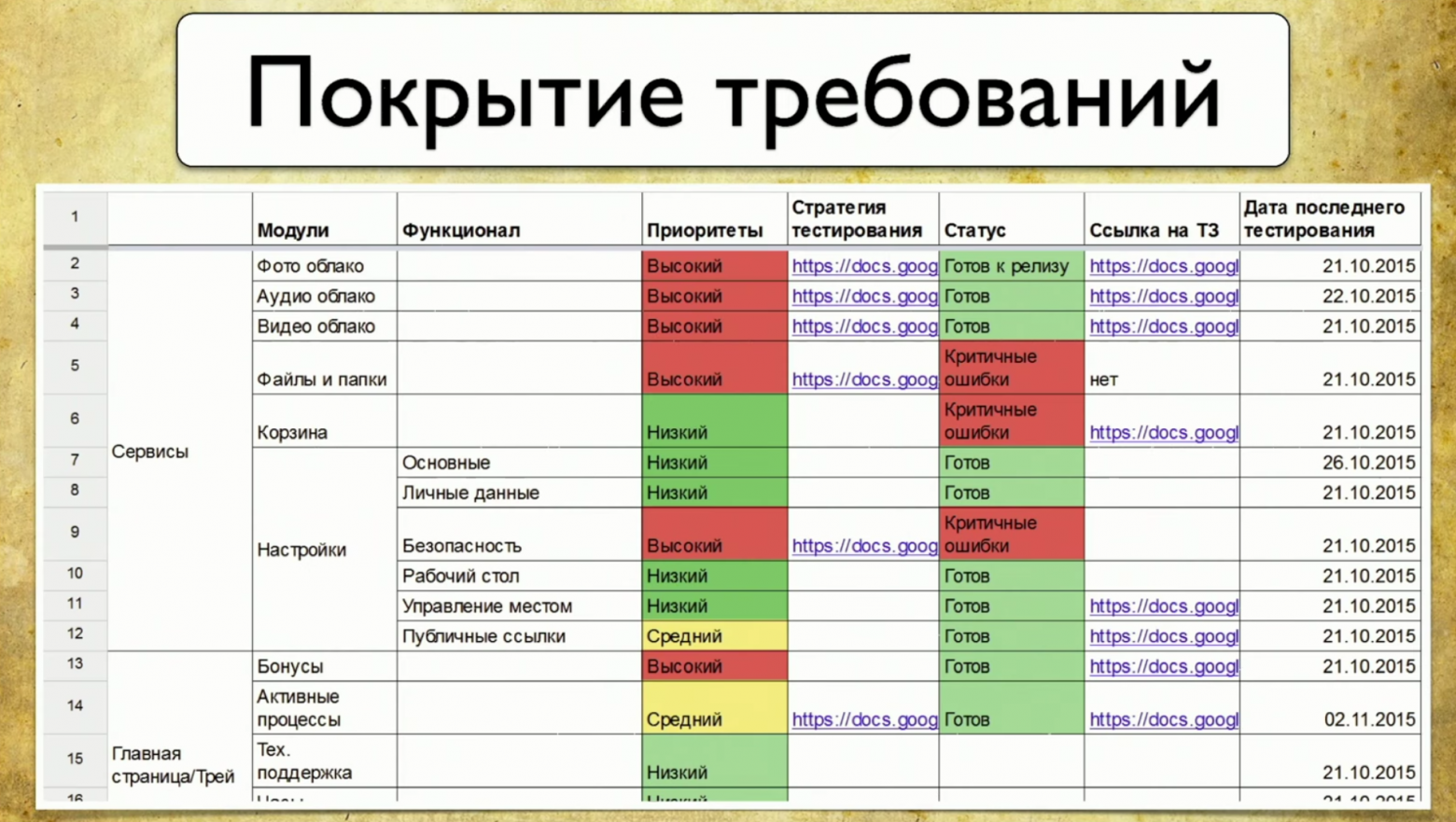
В этой таблице названия требований выписаны слева. В данном случае: аккаунт, объявления, проверка и оплата, то есть проверка объявления. В целом, это и есть покрытие. Детализация левой части зависит от уровня тестировщика. Например, у инженеров из Google есть 49 типов покрытий, которые проверяются на разных уровнях.
Правая часть таблицы — это атрибуты требований. Мы можем использовать что угодно в виде атрибутов, например: приоритет, покрытие и состояние. Тут может быть и дата последнего релиза.

Таким образом, в таблице появляются некие данные. Для ведения таблицы требований можно использовать профессиональные инструменты, например — TestRail.
Справа есть информация о дереве: в папочках расписано, какие требования у нас есть, как их можно покрыть. Там находятся тест-кейсы и так далее.
В Вертикалях этот процесс выглядит так: ручной тестировщик описывает требования и тест-кейсы, затем передает их на автоматизацию тестирования, и автоматизатор пишет по этим тестам код. Причем раньше нам выдавались подробные тест-кейсы, в которых ручной тестировщик описывал всю структуру. Затем кто-нибудь делал коммит на гитхабе, и тест начинал приносить пользу.
Какие у этого подхода есть «плюсы и минусы»? Плюс в том, что этот подход отвечает на наши вопросы. Если менеджер спросит, что у нас покрыто, я открою табличку и покажу, какие фичи покрыты. С другой стороны, эти требования надо всегда держать в актуальном состоянии, а они очень быстро устаревают.
Когда у вас 15 тысяч тестов, то смотреть на TestRail — это все равно, что смотреть на звезду в космосе: она взорвалась уже давно, а свет до вас дошел только сейчас. Вы смотрите на актуальный тест-кейс, а он уже устарел давно и безвозвратно.
Эту проблему сложно решить. Для нас это вообще два разных мира: есть мир автоматизации, который крутится по своим законам, где каждый упавший тест сразу же фиксится, а есть мир ручного тестирования и карт требований. Стена между ними — непробиваемая, если только вы не используете Allure Server. Мы сейчас эту задачу для них как раз и решаем.
Третий пункт «плюсов и минусов» — необходимость ручной работы. Вам в новом проекте нужно заново создавать карту требований, писать все тест-кейсы и так далее. Это всегда требует ручной работы, и это на самом деле очень печально.
Альтернатива этому подходу — покрытие кода. Кажется, это и есть решение нашей задачи. Вот так выглядит покрытие кода продукта:
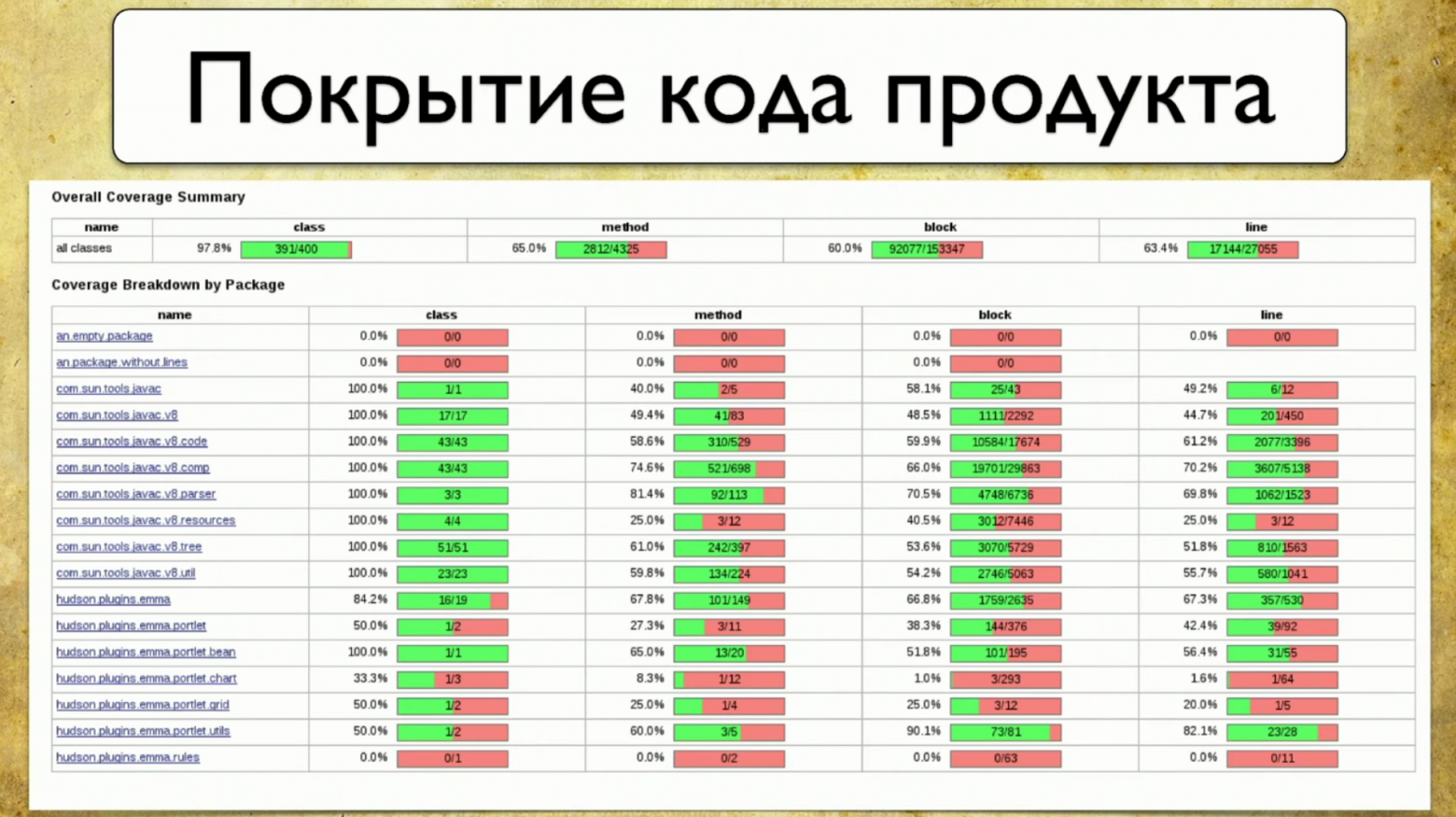
Здесь отражено покрытие по package, точнее маленькая часть того, что на самом деле обычно есть в продукте. Слева написаны package, как раньше были написаны фичи. То есть наше покрытие наконец-то привязывается к каким-то осязаемым штукам, в данном случае — Package. Справа написаны атрибуты: покрытия по классам, покрытия по методам, покрытия по блокам кода и покрытие по строчкам кода.
Процесс сбора покрытия состоит в том, чтобы понять, по какой строчке кода тест проходил, а по какой — нет. Это довольно несложная задача, но в последнее время очень актуальная.
Итак, у нас есть тест, который взаимодействует с системой. Неважно, как он с ней взаимодействует: через фронтенд, API или напрямую лезет в бэкенд — просто будем считать, что он у нас есть.
Затем следует сделать инструментирование. Это некоторый процесс, который позволяет понять, какие строчки кода проверялись, а какие нет. Не надо его подробно изучать, надо просто поискать название вашего фреймворка, на котором вы пишете, скажем, Spring, затем instrumentation, и coverage — по этим трем словам поймете, как это делается.
Когда ваши тесты проверяют, на какую строчку кода попал тест, а на какую не попал, они сохраняют файлы с информацией о том, какие строчки покрыты. На основе этой информации у вас появляются данные.
Покрытие кода я бы сразу назвал минусом. Вы не придете к менеджеру, не покажете вот эту табличку и не скажете, что все автоматизировали, потому что эти данные невозможно читать, он попросит вернуть понятные данные, на которые можно быстро посмотреть и все понять.
Отчет о покрытии кода ближе к разработке. Его нельзя использовать как нормальный подход к предоставлению всех данных команде, если мы хотим, чтобы вся команда могла смотреть.
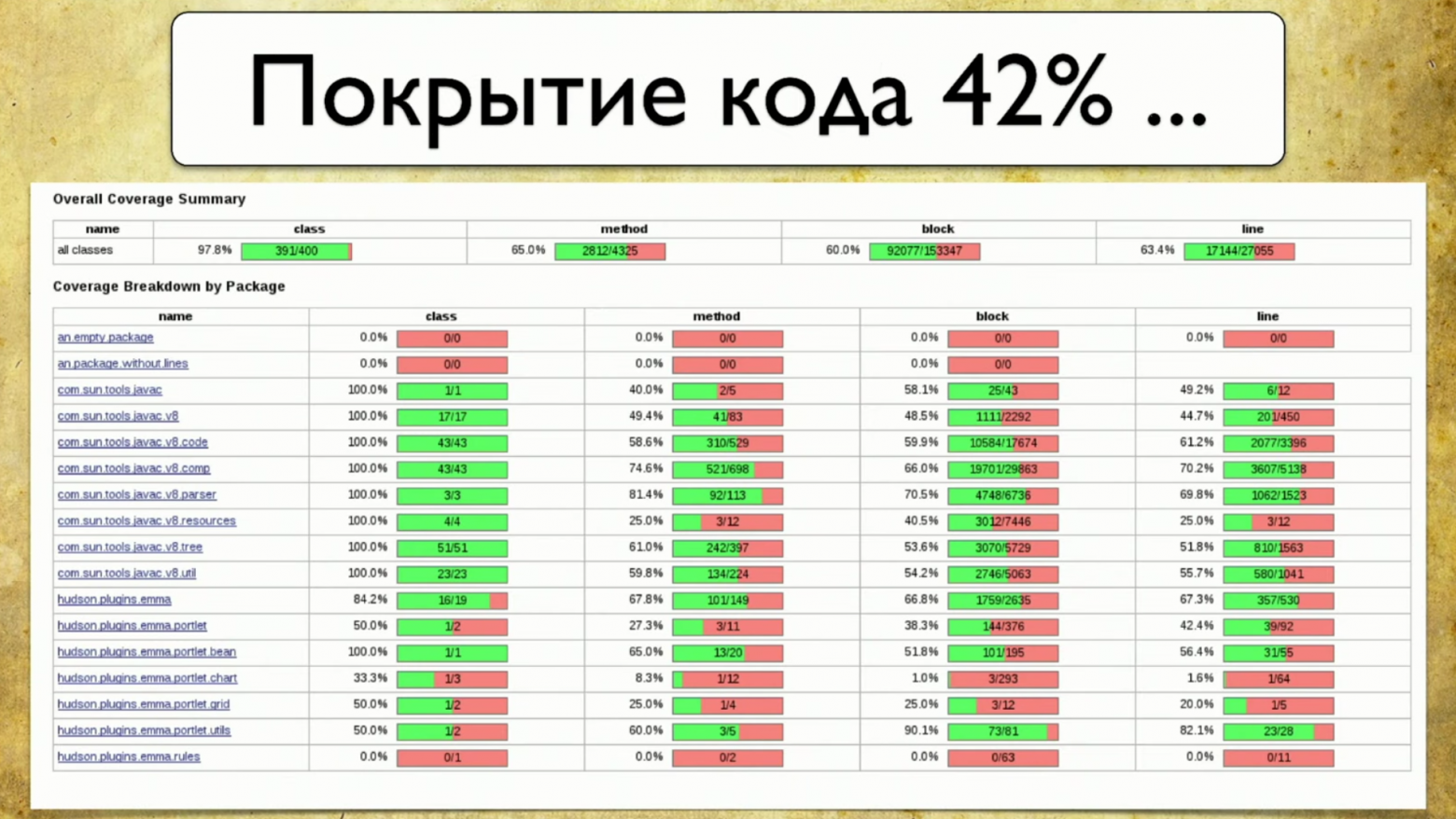
Достоинство этого подхода в том, что он всегда предоставляет актуальные данные. Вам не надо делать много работы, все автоматизировано за вас. Просто подключаете библиотеку, у вас начинают сниматься покрытия — и это реально круто.
Другое достоинство этого подхода в том, что он требует только настройки. Там не надо особо ничего делать — просто приходите с определенной инструкцией, настраиваете покрытие, и оно работает автоматически.
Покрытие требований позволяет выявить нереализованные требования, но не позволяет оценить полноту по отношению к коду. Например, вы начали писать новую фичу «авторизация», просто заносите «фича авторизации», начинаете накидывать на нее тест-кейсы. Вы не можете тут же посмотреть это покрытие в коде, даже если вы напишите какой-то новый класс, все равно не будет информации — происходит разрыв. С другой стороны, это требование авторизации, даже когда оно уже будет имплементировано, когда вы по нему посчитаете покрытие, эта часть не сможет быть актуальной, ее нужно держать актуальной вручную.
Поэтому у нас появилась идея: а что если взять лучшее от каждого? Так, чтобы покрытие отвечало на наши вопросы, всегда было актуально и требовало только настройки. Нам надо просто взглянуть на покрытие под другим углом, то есть взять за основу покрытия другую систему. При этом сделать так, чтобы оно собиралось полностью автоматически и приносило кучу пользы. И для этого мы перейдем в покрытие для API тестов.
Что лежит в основе покрытия? Для этого мы используем Swagger — это API для документации. Сейчас я не представляю свою работу без Swagger, это инструмент, который у меня постоянно используется для тестирования. Если вы не пользуетесь Swagger, я крайне рекомендую зайти на сайт и ознакомиться. Там вы сразу же увидите очень интуитивный и понятный пример использования.
По сути, Swagger представляет из себя документацию, которая генерируется по вашему сервису. Она содержит:
Принцип работы Swagger — это генерация. Неважно, какой фреймворк вы используете. Допустим, Spring либо Go Server, вы используете компонент Swagger Codegen и генерируете swagger.json. Это некоторая спецификация, на основе которой потом рисуется красивый UI.
Для нас важно, что используется именно swagger.json: его поддержка есть для всех широко используемых языков.
У нас есть Open API спецификация swagger.json. Она выглядит так:
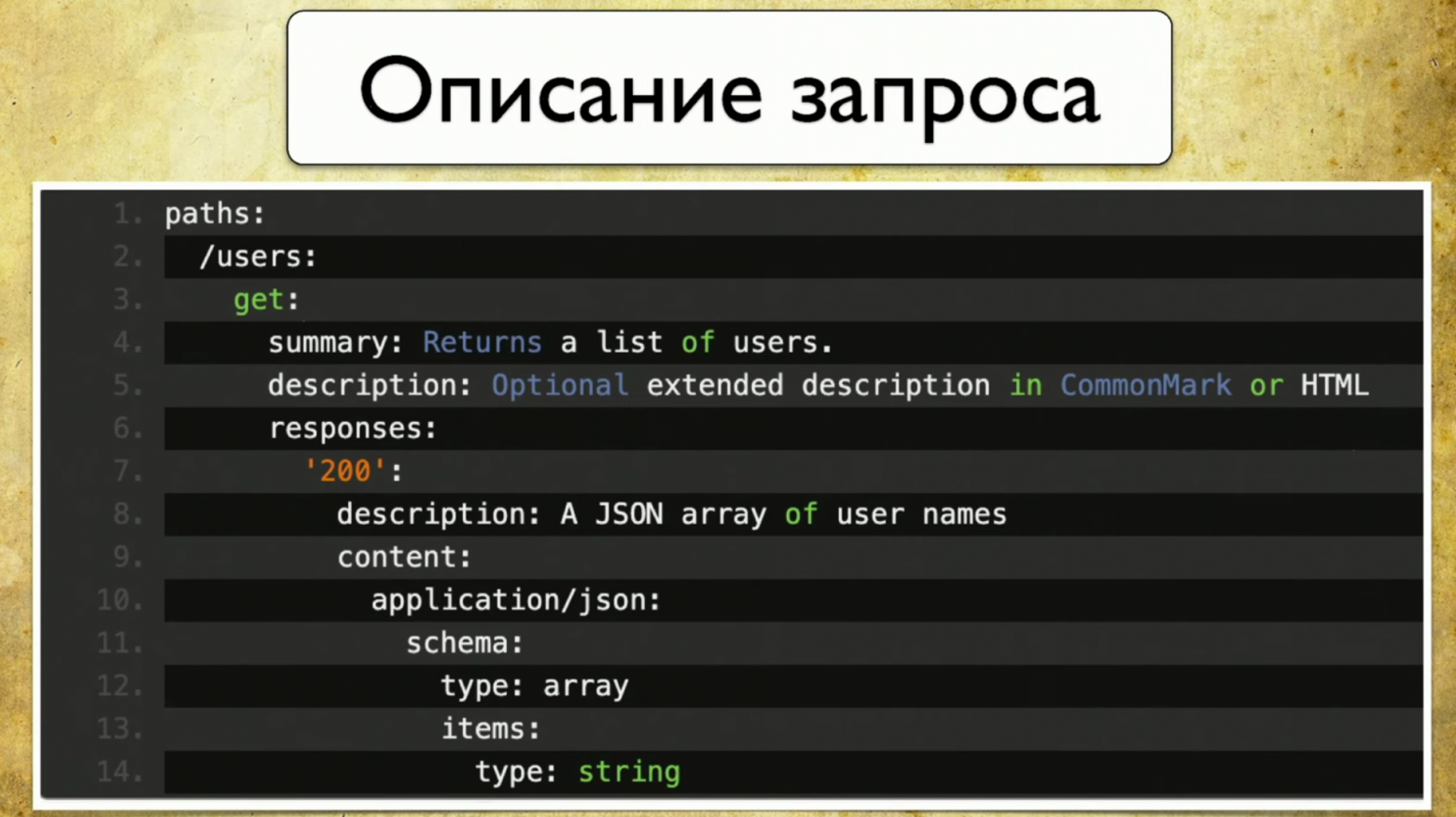
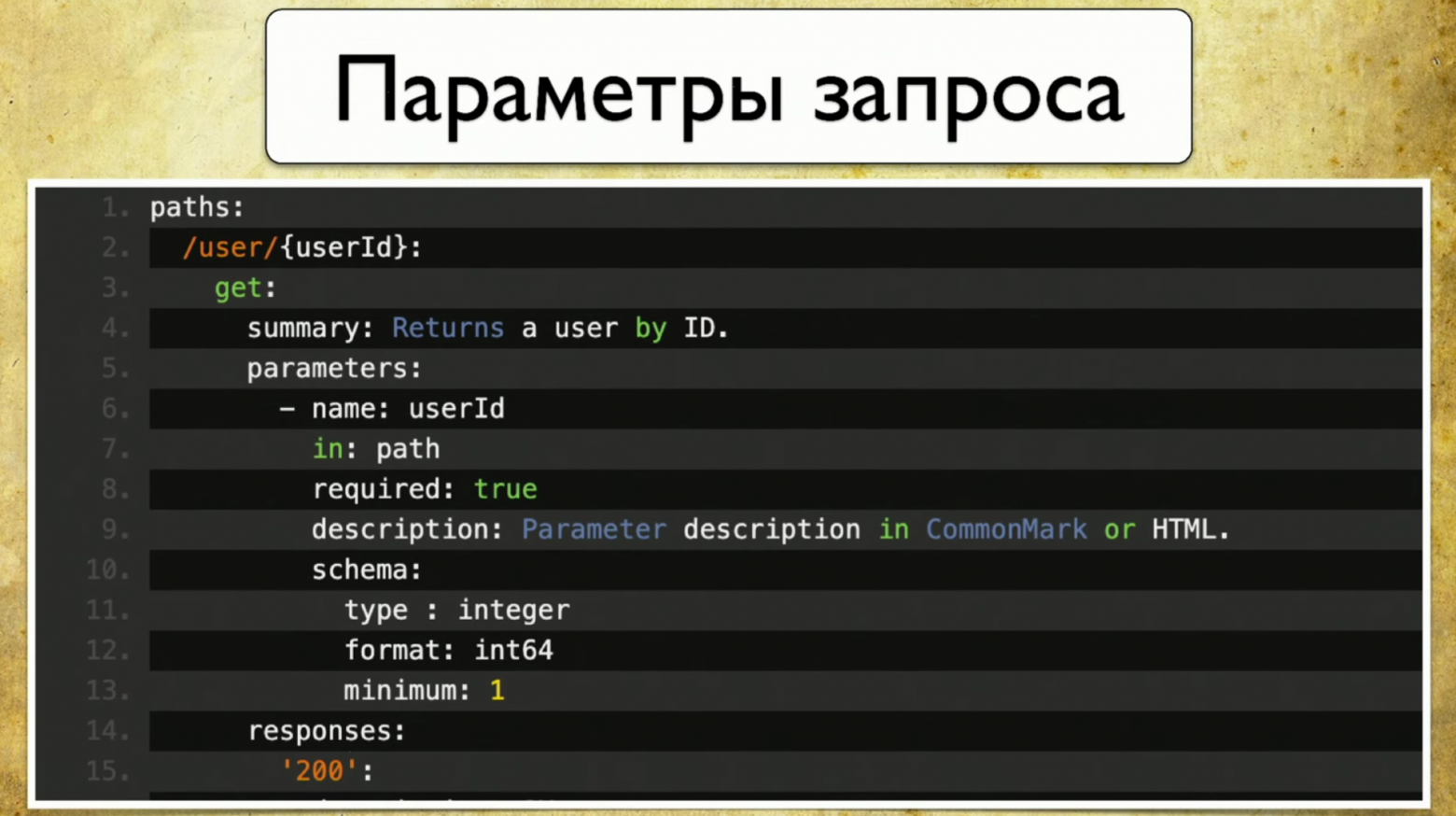
Запросы выглядят примерно таким образом: summary, description, коды ответов и «ручка» (path: /users). Также есть информация о параметре запросов: все структурировано, есть параметр user ID, он находится в пути, где есть required, такой-то description и type — integer.
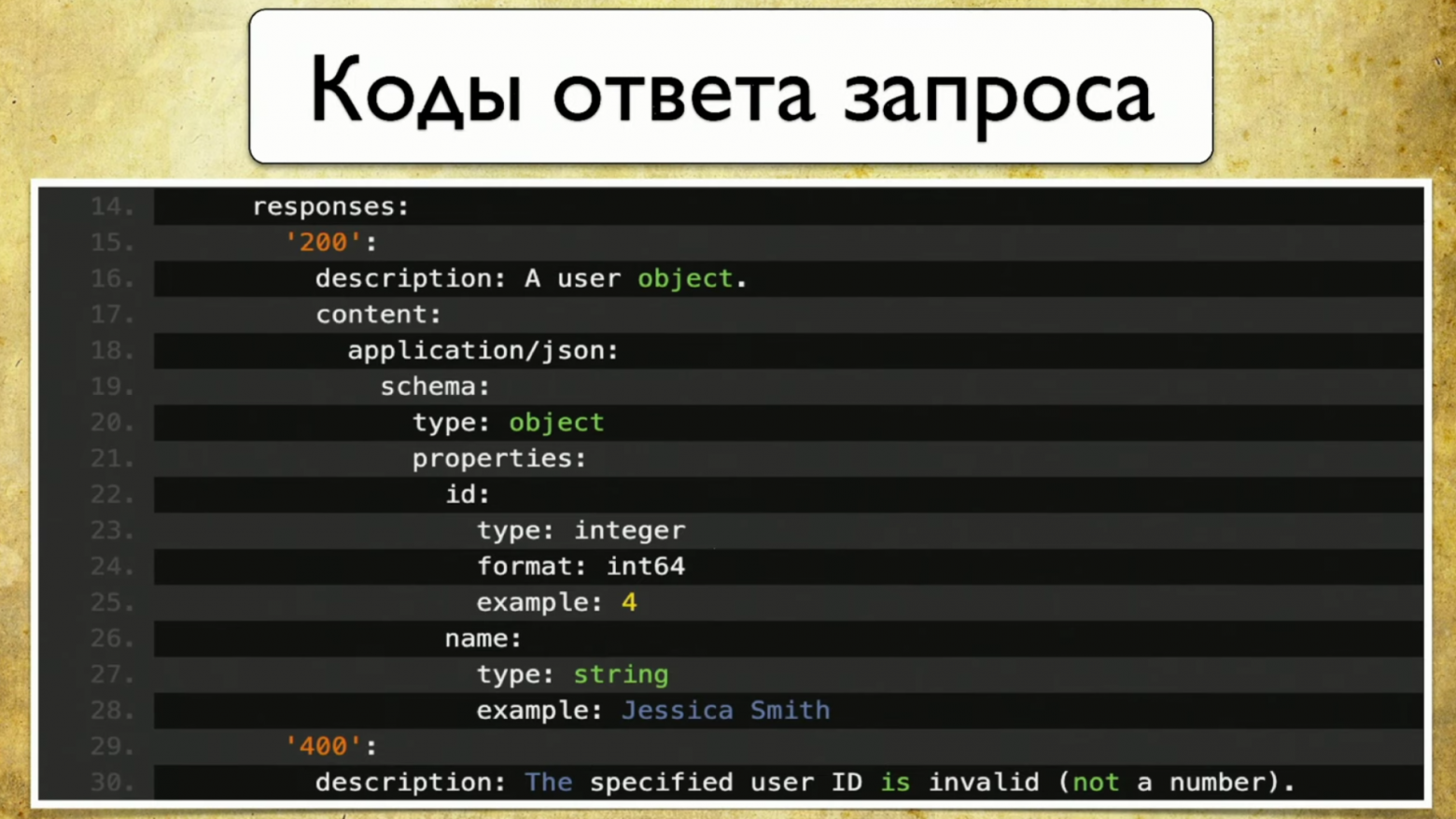
Есть коды ответов, они тоже все задокументированы:
И нам пришла в голову идея: у нас есть сервис, который генерирует Swagger, и мы захотели в тестах сохранять такой же Swagger, чтобы потом их сравнить. Другими словами, когда пробегают тесты, они генерируют ровно такой же Swagger, мы его кидаем на Swagger Diff, понимаем, какие параметры, ручки, статус коды у нас проверены и так далее. Это то же самое инструментирование, тот же самый coverage, только наконец-то в требованиях, которые мы понимаем.
Мы обратились к библиотеке Swagger diff, которая для этого и нужна. Ее принцип работы примерно такой: у вас есть версия 1.0, при V версия API 1.1, они оба генерируют swagger.json, потом вы их кидаете на Swagger diff и смотрите результат.
Результат выглядит примерно таким образом:

У вас есть информация, что появилась, например, новая ручка. У вас также есть информация о том, что удалилось. Это значит, что тесты пора удалять, они уже неактуальны. С появлением информации об изменениях меняются и параметры, таким образом, очевидно, что в этот момент упадут ваши тесты.
Нам понравилась эта идея, и мы начали имплементировать. Как мы решили делать: у нас есть «эталонный» Swagger, который генерирует с кода разработчиков, у нас также есть API тесты, которые будут генерировать свой Swagger, и мы между ними сделаем diff.
Итак, мы запускаем тесты на сервис: у нас есть Rest Assured, который сам обращается к сервисам на API. И мы его инструментируем. Здесь есть подход: можно сделать фильтры, на него уходит запрос — и он сохраняет информацию о запросе в виде swagger.json прямо под себя.
Вот весь код, который нам надо было написать, там было 69-70 строчек — это очень простой код.

Самое смешное, что мы использовали нативный клиент для Swagger, писали прямо там. Нам даже не надо было создавать свои bin-ы, просто наполняли спецификацию Swagger.

У нас получилось очень много .json-файлов, с которыми надо было что-то сделать — написали Swagger-агрегатор. Это очень простая программа, которая работает по следующему принципу:
Таким образом, у нас появляется информация про все ручки, параметры и статус-коды, которые мы задействовали. Кроме того, здесь можно собирать и данные, с которыми эти запросы выполнялись: username, логины и так далее. Мы пока не придумали, как использовать эту информацию, потому что у нас все генерируется, но вы можете понимать, с какими параметрами были вызваны те или иные запросы.
Swagger Diff говорит, что изменилось, а не что покрыто, а мы хотели отображать именно результат покрытия. Там очень много лишних данных, он хранит в себе информацию о description, summary и другую метаинформацию, а у нас этой информации нет. И когда мы делаем Diff, нам пишут, что «у этой ручки отсутствует description», а его и не было.
Мы сделали свою имплементацию, и она работает следующим образом: у нас есть много файлов, которые пришли с автотестов, есть API service Swagger, и мы на основе его генерируем отчет.
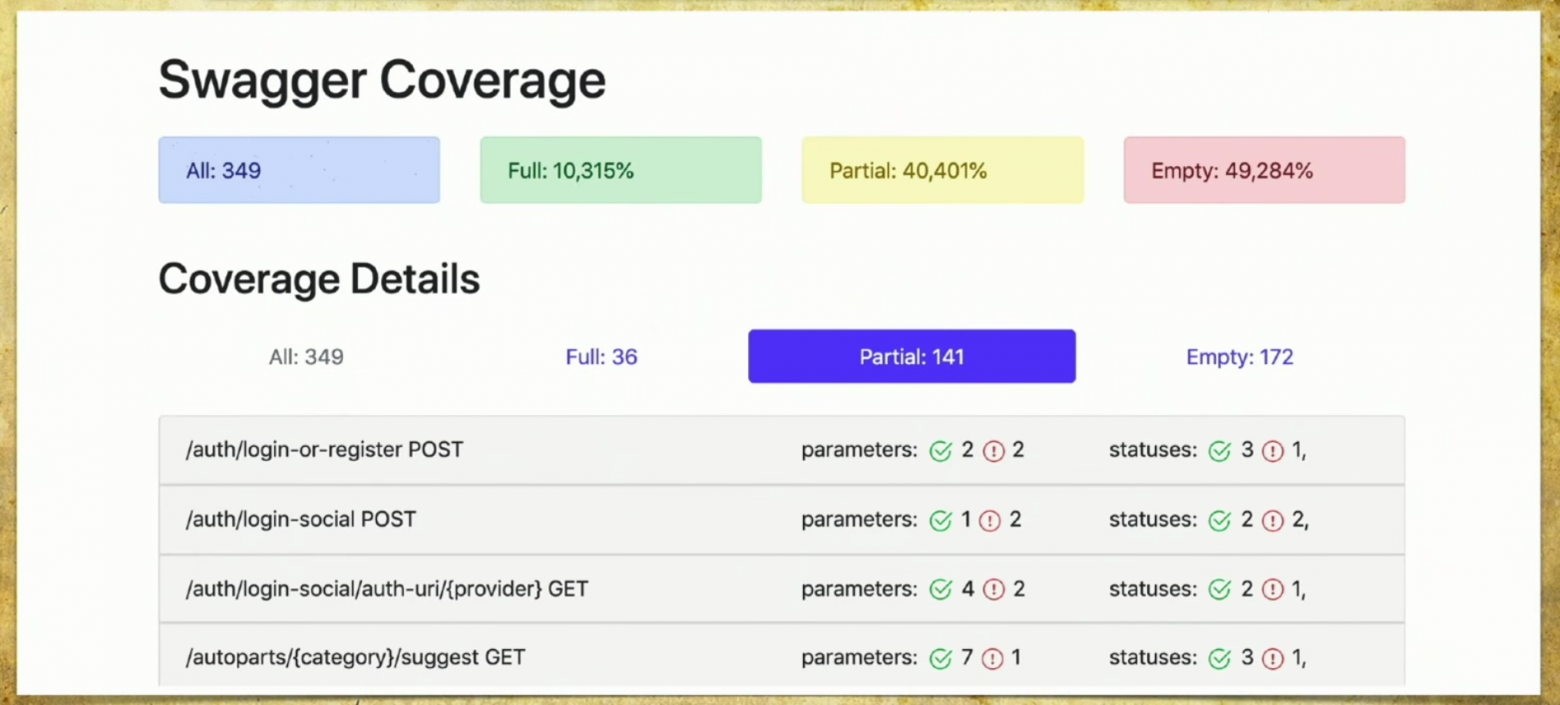
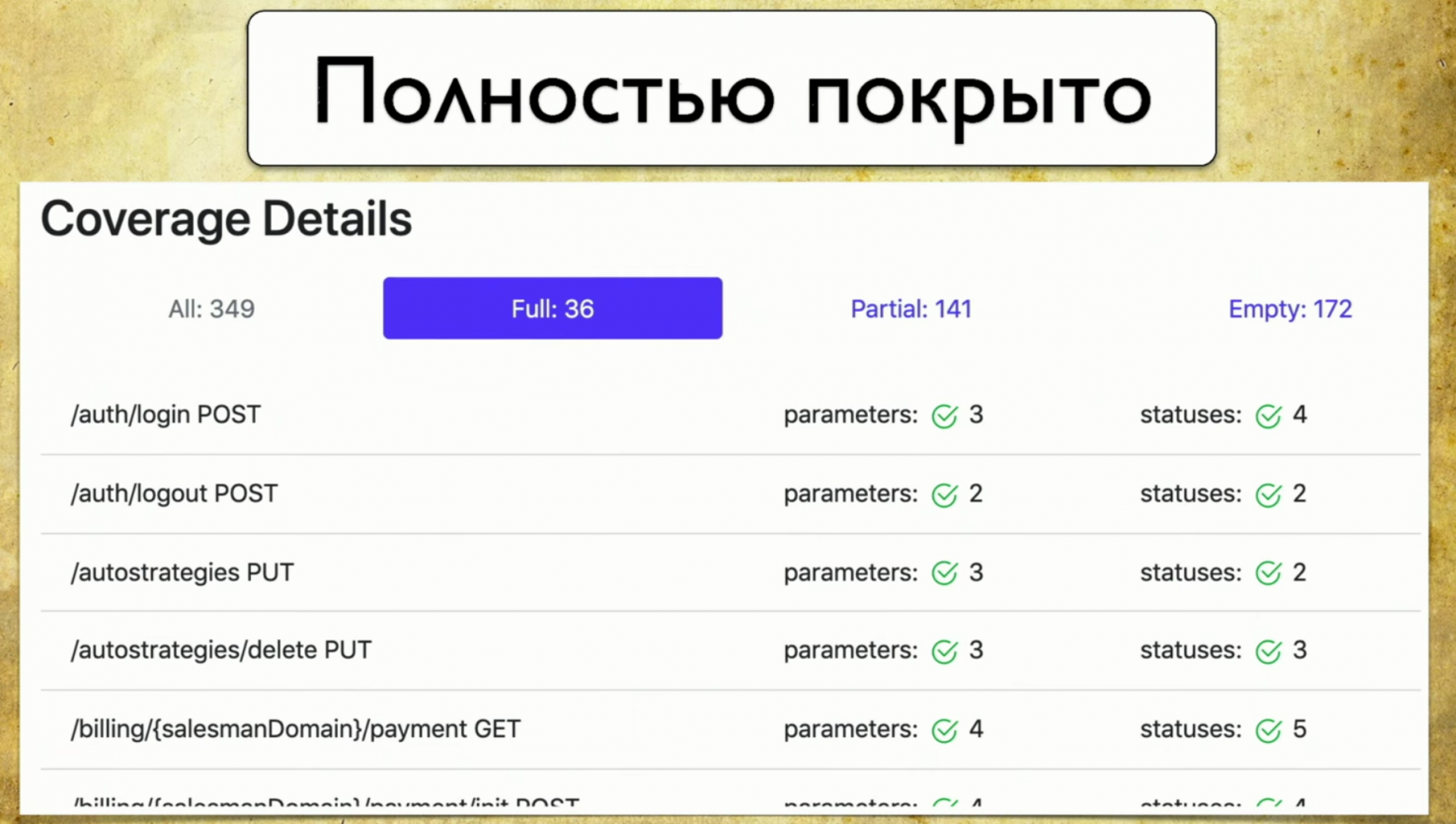
Простой отчет выглядит так: сверху видно информацию, сколько всего ручек (349), информацию о том, которые покрыты полностью (каждый параметр, статус-код и так далее покрыт). Можно выбрать свои критерии, например, покрыть несколько параметров.
Здесь также есть информация, что 40% покрыто частично — это значит, что у нас уже есть тесты на эти ручки, но некоторые вещи еще не покрыты, и нужно туда внимательно посмотреть. Отражено также Empty-покрытие.
Давайте пройдемся по tab-ам. Это full-покрытие, мы видим все параметры, которые у нас есть, которые покрываются, статус-коды и так далее.
Потом у нас есть частичное покрытие. Мы видим, что у нас на ручку login-social один параметр покрыт, а два — нет. Причем мы можем развернуть ее и посмотреть, какие конкретно параметры и статус-коды покрыты. И в этот момент разработчику становится очень удобно: версии приложения у нас катятся очень быстро, и мы зачастую можем забыть какие-то параметры.
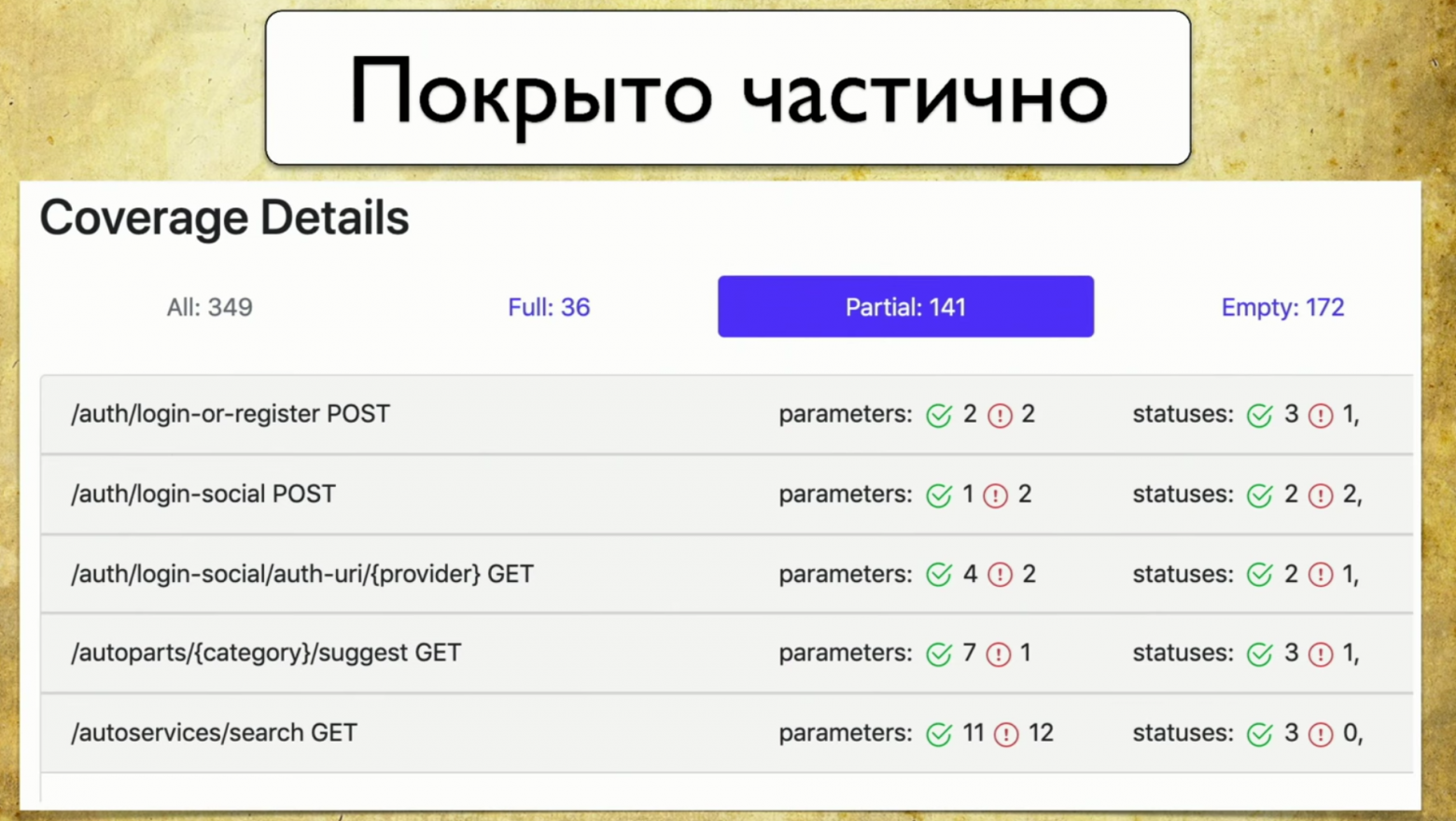
Этот инструмент позволяет всегда быть в тонусе и понимать, что у нас покрыто частично, какой параметр забыли и так далее.
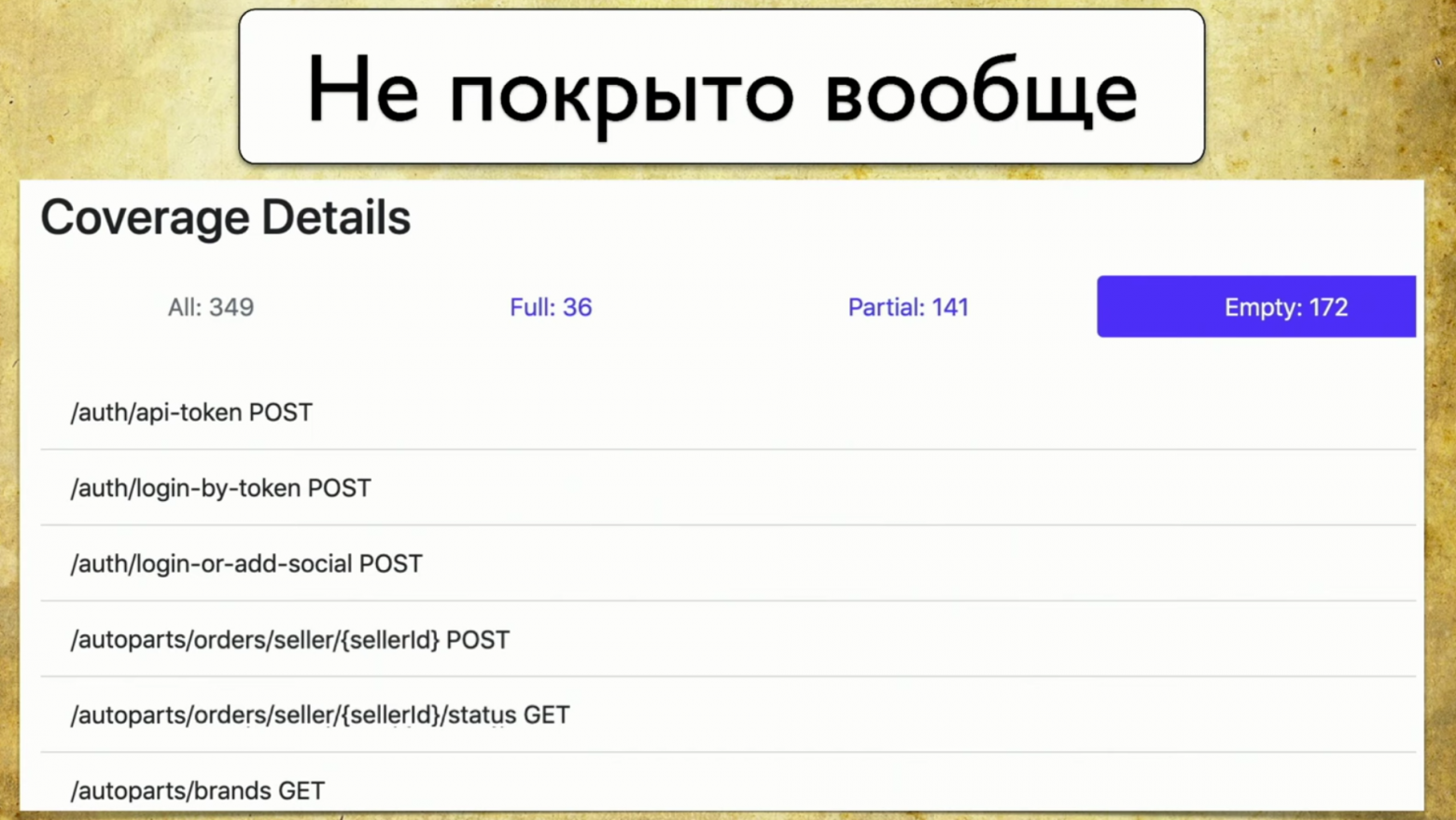
Последнее — Glory of shame, нам еще предстоит это делать. Когда смотришь на эту страничку и видишь там Empty:172 — руки опускаются, и тогда начинаешь обучать ручных тестировщиков писать автотесты, в этом и смысл.
Во-первых, мы стали более осмысленно писать тесты. Мы понимаем, что тестируем, и при этом у нас есть две стратегии. Первая — мы автоматизируем то, чего еще нет, когда приходят ручные тестировщики и говорят, что для определенного сервиса критично, чтобы один запрос был выполнен хотя бы один раз, и мы открываем Empty.
Второй вариант — мы не забываем про хвосты. Как я уже сказал, API релизятся очень быстро, по два-три раза в день могут быть какие-то релизы. Туда постоянно добавляются какие-то параметры: в пяти тысячах тестов невозможно понять, что проверено, а что нет. Поэтому это единственный способ осмысленно выбирать стратегию тестирования и хотя бы что-то делать.
Третий профит — процесс полностью автоматический. Мы позаимствовали подход, и работает автоматика: нам ничего не надо делать, все собирается автоматически.
Во-первых, очень не хочется держать второй отчет, а хочется интегрировать его в Swagger UI. Это мой любимый «Photoshop Edition report»: фишка, которую я разрабатывал в последнее время. Тут сразу же есть информация о параметрах, которые у нас протестированы, а которые нет. И было бы круто отдавать эту информацию сразу вместе со Swagger-ом.

Например, фронтендер может сам посмотреть, какие параметры еще не протестированы, расставить приоритеты и решить, что пока их не нужно брать в разработку, ведь неизвестно, насколько хорошо они работают. Или бэкэндер пишет новую ручку, видит красное и пинает тестировщиков, чтобы все было зеленое. Это сделать довольно несложно, мы идем в этом направлении.
Вторая идея — поддержка других тулов. На самом деле не хочется писать фильтры для конкретных имплементаций: для Java, Python и так далее. Есть идея сделать некую прокси, которая будет пропускать через себя все запросы, и сохранять Swagger-информацию под себя. Таким образом, у нас будет универсальная библиотека, которую можно использовать независимо от того, какой у вас язык.
Третья идея по развитию — это интеграция с Allure Report. Я вижу это вот так:

Как правило, когда параметр «протестирован», это не всегда говорит нам о том, как он протестирован. И хочется навести на этот параметр и увидеть конкретные шаги теста.
Следующий пункт, о котором я хочу поговорить — покрытие для Web-тестов. В основе покрытия — сайт, который вы тестируете, пишете тесты на сайт. Но ведь его можно сделать веб-интерфейсом к вашему покрытию. Например, это будет выглядеть так:
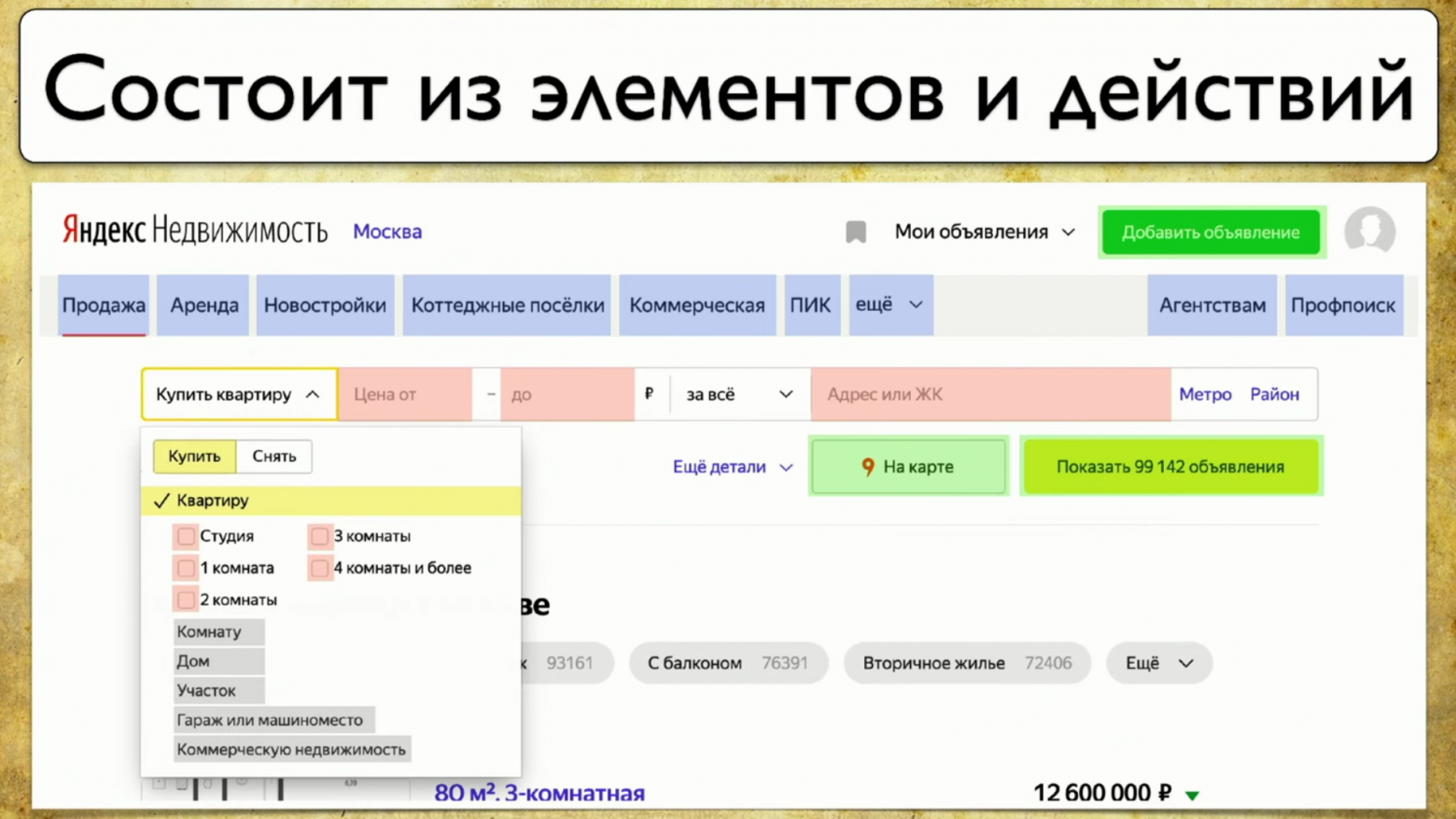
Если посмотреть на ваш сайт — это некоторый набор элементов и способов взаимодействия с ними. Это полное описание: «элемент — способ с ним взаимодействовать». На ссылку можно кликнуть, текст можно скопировать, в input можно что-то вбить. Сайт в целом состоит из элементов и способов их взаимодействия:
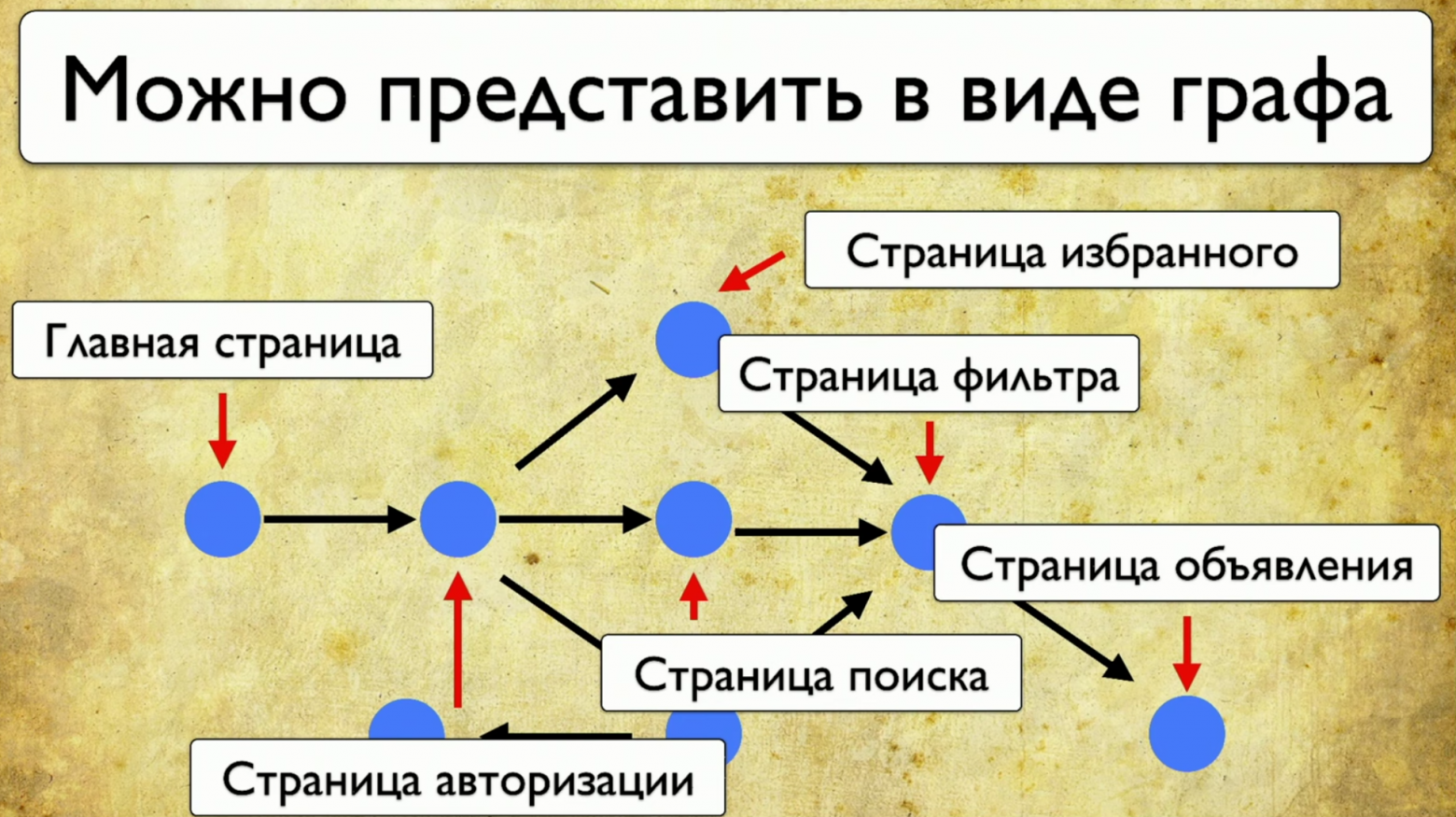
Как бегают тесты: они начинают с какой-то точки, затем, например, заполняют какую-то форму, допустим, форму авторизации, затем разбегаются по другим страничкам, потом еще по другим и заканчиваются.
Если менеджер спрашивает, тестируется ли какая-то конкретная кнопка, а на этот вопрос сложно ответить: нужно код открыть, либо в TestRail зайти, то хочется видеть такое решение проблемы:
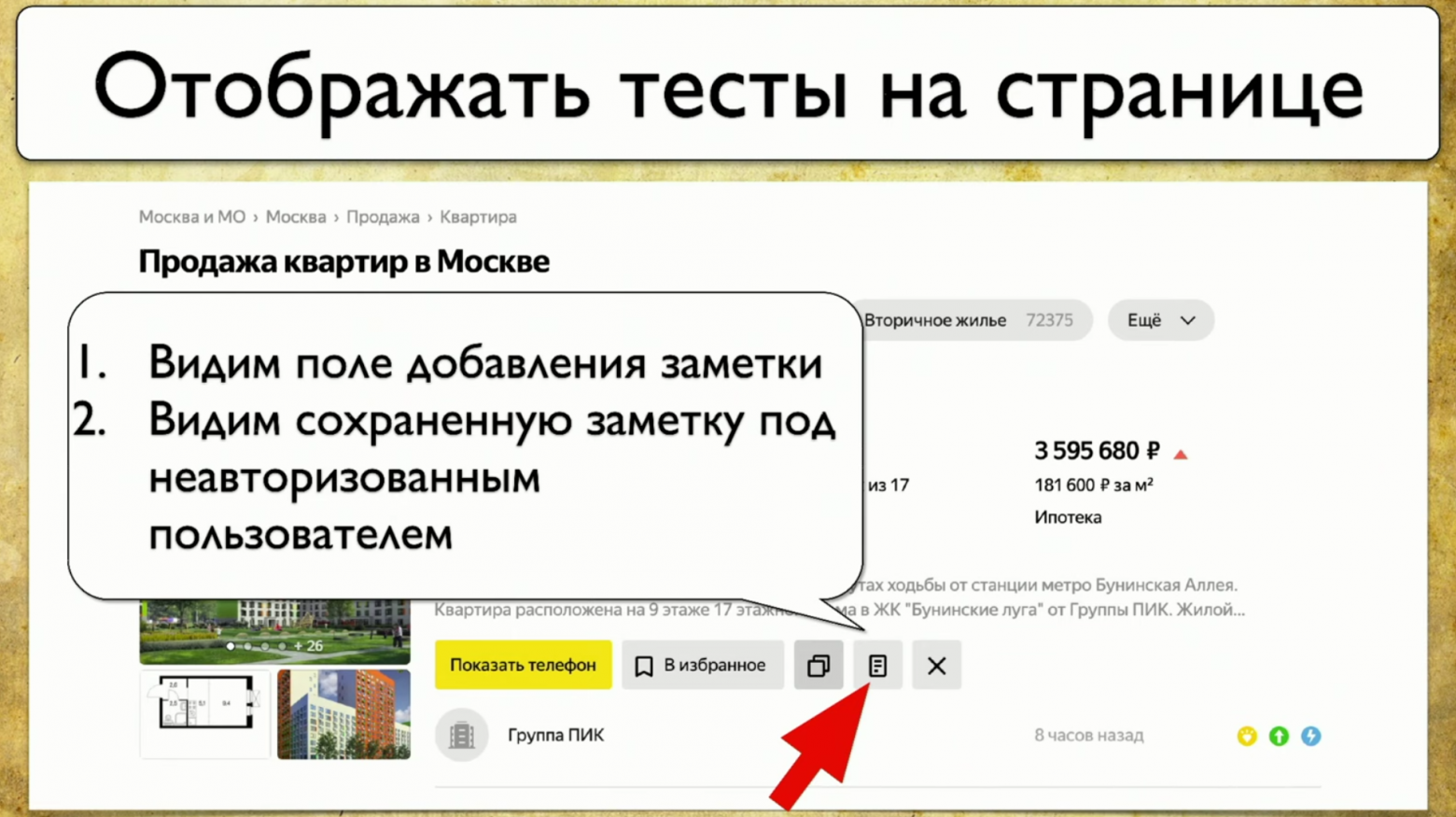
Я хочу навести на этот элемент и увидеть все тесты, которые у нас есть на этот элемент. Если бы такой инструмент был, я был бы счастлив. Когда мы начали думать про эту идею, то, в первую очередь, посмотрели на Яндекс.Метрику. У них на самом деле есть примерно подобная функциональность по карте ссылок. Хорошая идея.
Суть в том, что они подсвечены ровно так, словно уже дают нужную нам информацию. Они говорят: «Вот по этой ссылке проходили 14 раз», что в переводе на язык тестирования значит: «в этой ссылке тестировали 14 тестов» и так или иначе через нее прошли. А вот на эту красную ссылку уходило аж 120 тестов, какие интересные тесты!
Можно рисовать всякие тренды, добавлять метаинформацию, но что будет, если мы это все возьмем и нарисуем с точки зрения тестирования? Итак, у нас задача: навести на какой-то элемент и получить заметку со списком тестов.
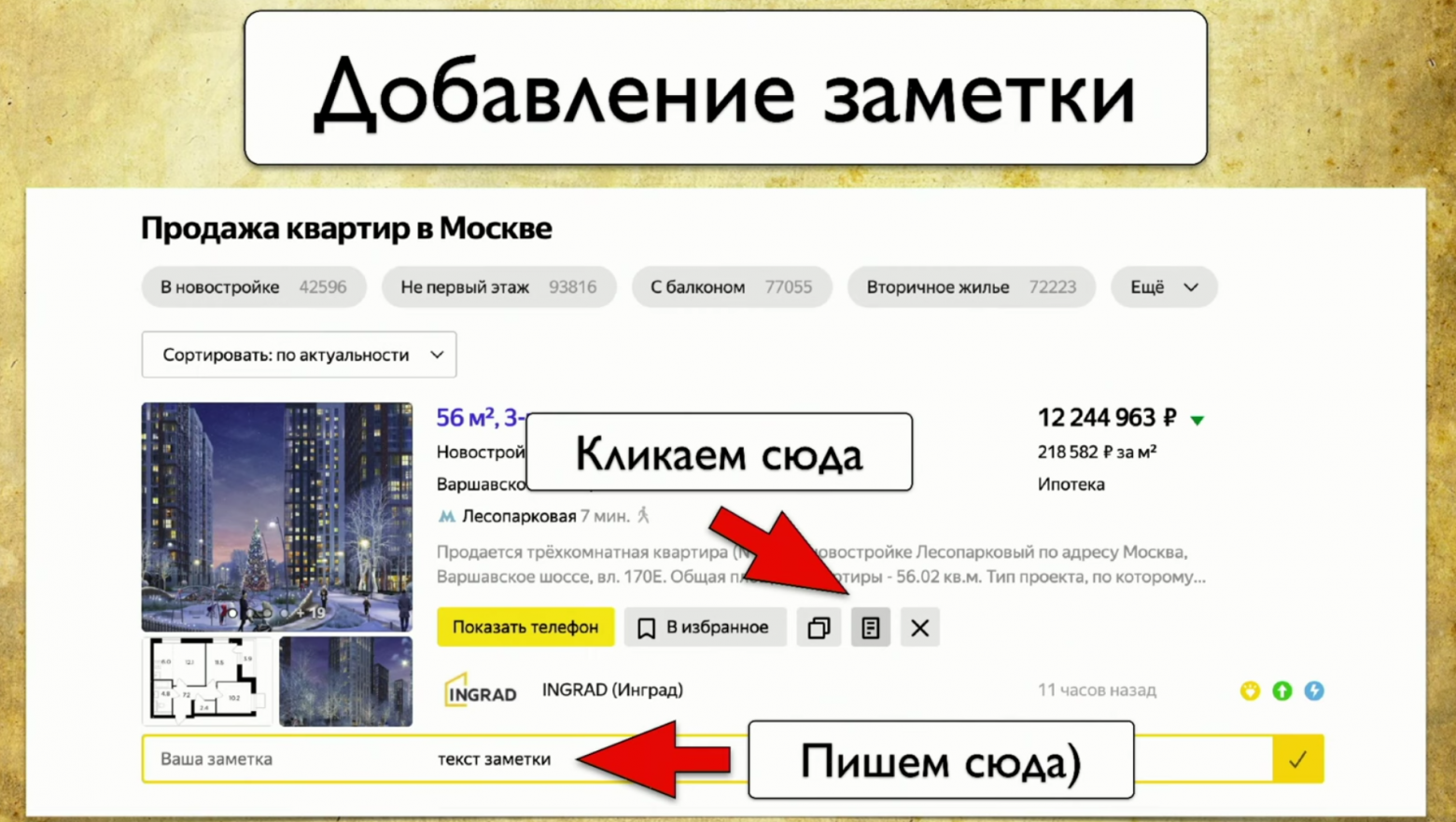
Для того, чтобы это имплементировать, надо кликнуть на иконку, затем написать заметку, и это — весь наш тест. Мы у себя используем Atlas, и интеграция пока есть только с ним.
Atlas выглядит примерно так:
Мы хотим, чтобы хотя бы один результат в выдаче был, иначе нам это не протестировать. Потом мы двигаем курсор на элемент, затем кликаем на него.
Потом сохраняем в input User_Text и сабмиттим ее.
После этого проверяем, что текст ровно тот, который должен был быть.
Тесты запускаются в браузере, Atlas является прокси к этому тесту, применим сюда тот же подход, что все используют при сборе покрытия: сделаем locator с .json. Будем сохранять туда информацию про все открытия страницы, все итерации с элементами, кто сабмиттился, кто делал sendkey, кто click, на какие ID и так далее — будем вести полный лог.
Потом этот лог прикрепляем к Allure в виде каждого теста, и когда у нас появляется много locators.json — мы генерируем meta.json. Схема одна и та же для всех элементов.
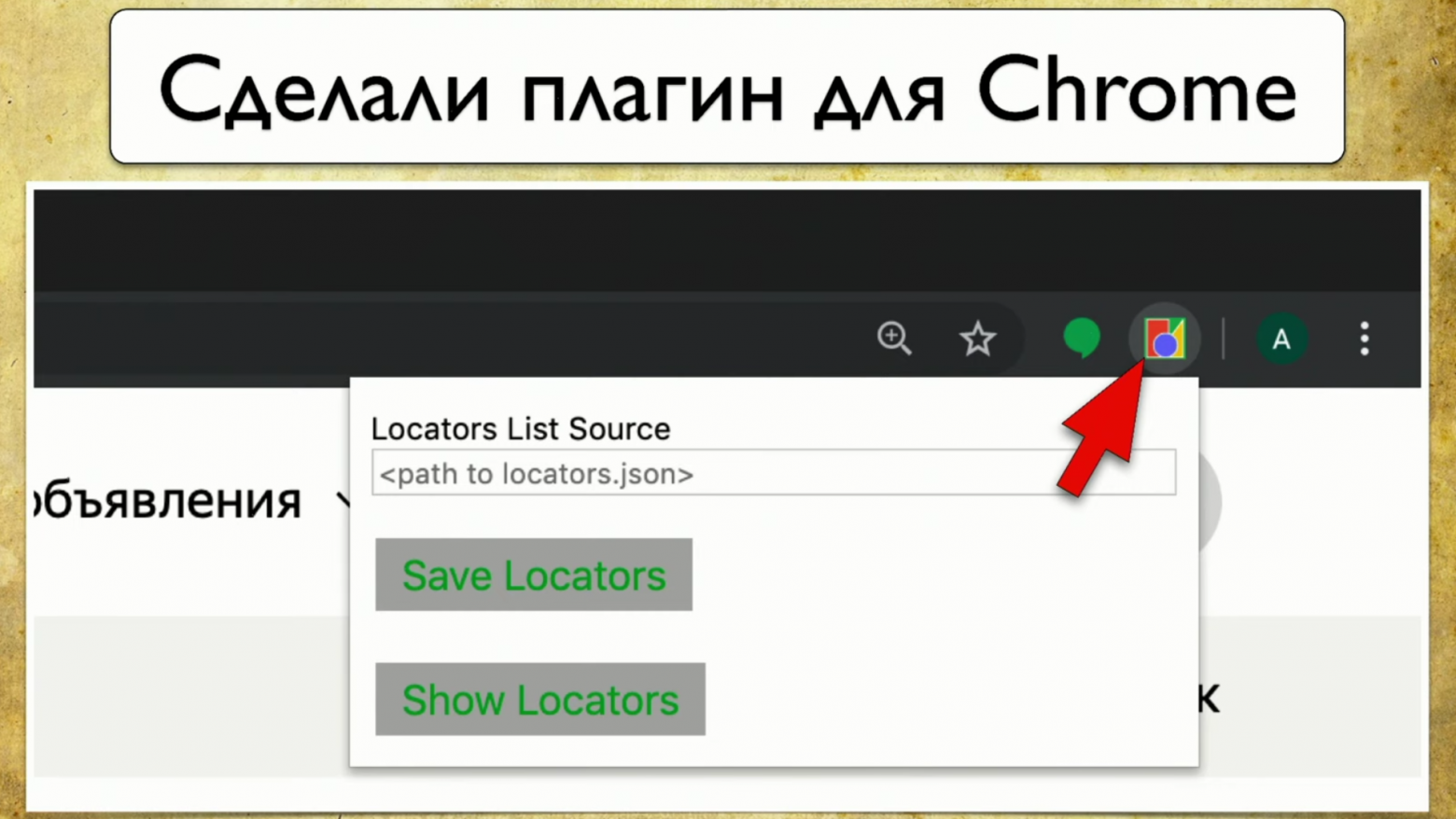
У нас есть плагин для Google Chrome. Мы захотели сделать решение в виде плагина. Я специально сделал кривой скриншот, чтобы на слайде была видна одна важная деталь — path to locators.json.
Если вы сгенерировали отчет сейчас, то там находится карта покрытия на сегодня. Если вы возьмете отчет за предыдущие две недели и вставите сюда, то появится карта покрытия за период две недели назад. У вас появляется машина времени!
Тем не менее, когда вы подключаете этот плагин, он рисует не очень дружелюбный интерфейс.
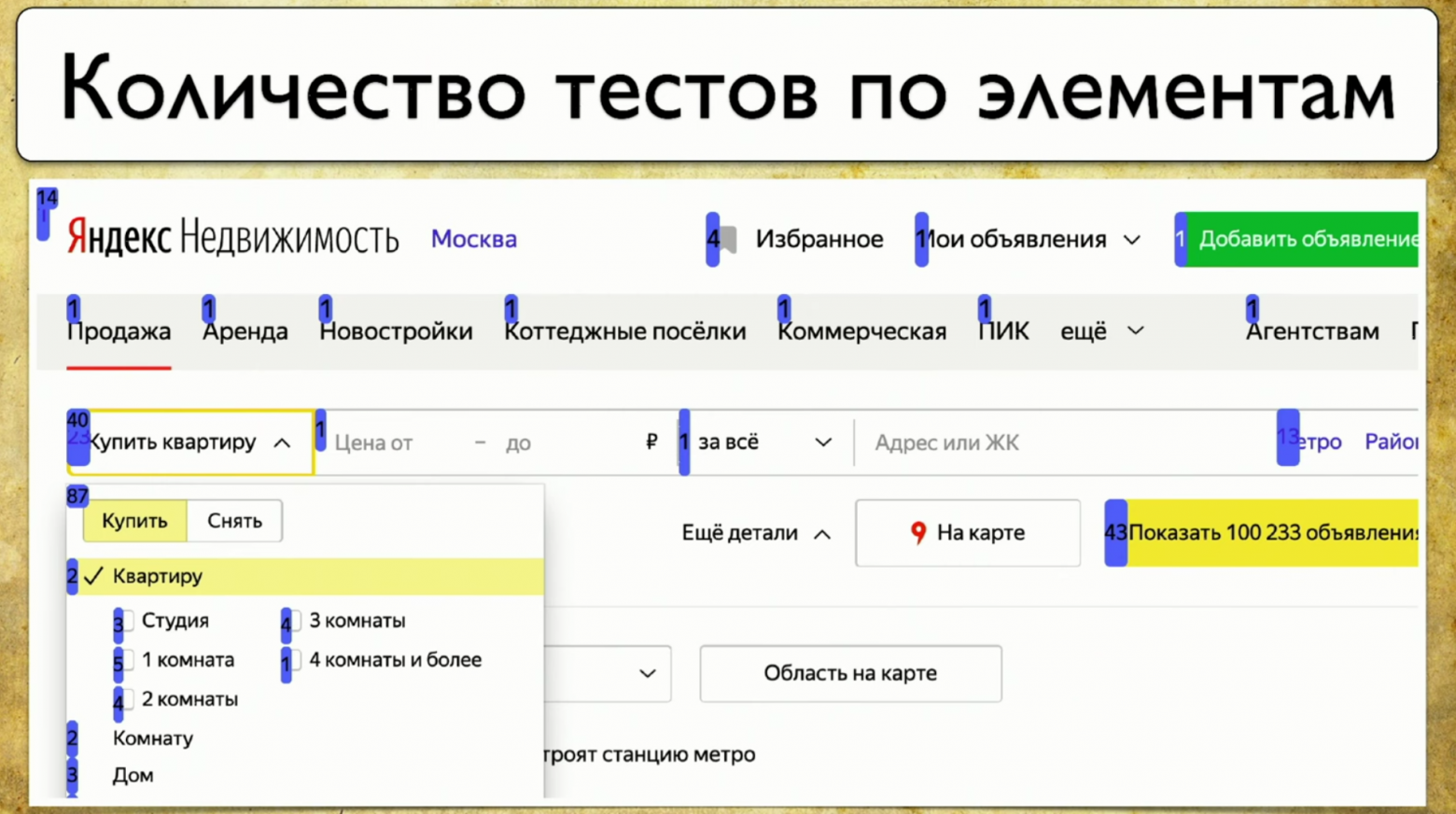
У каждого элемента появляется количество тестов, которые через него проходят: видно, что 40 тестов проходят через «купить квартиру», header тестируется по одному тесту, это прикольно, и опция «квартиру» тоже отображается. У вас получается полная карта покрытия.
Если вы наведете на какой-то элемент, он возьмет данные и отпечатает ваши реальные тесты с вашей tms, Allure Board и так далее. В результате появляется полная информация о том, что тестируется и каким образом.
Учтите, что из каждого теста можно провалиться прямо в Allure-отчет.

Когда вы открываете любую штуку, он подгружает новые селекторы: если у вас есть какие-то тесты, которые проходят через эти селекторы, и вы что-то делали с сайтом, он обработает и покажет всю картину.
Теперь любой может зайти и найти любую «нитку», которая ведет к сценарию. Например, вы предполагаете, что нужно протестировать оплату. Оплата, очевидно, ведет через кнопку оплаты: нажимаете — появляются все тесты, которые проходят через кнопку оплаты. Это чудесно! Вы заходите в любой из них и просматриваете сценарий.
Более того, вы понимаете, что проверялось раньше. У нас генерируется статический файл, вы можете указать к нему путь и указать, какие тесты были две недели назад. Если менеджер, говорит, что в продакшене баг и спрашивает, тестировали ли мы пару недель назад такую-то функциональность, вы берете репорт Allure, говорите, например, что не тестировали.
Еще один профит — ревью после автоматизации тестирования. До этого у нас было ревью до автоматизации тестирования, сейчас же можно делать свои тесты ровно так, как вы их видите. Захотели сделать тест — сделали, отвели какой-то branch, запустили Allure, скинули ссылку на плагин ручному тестировщику и попросили посмотреть тесты. Это именно тот процесс, который позволит вам усилить Agile-стратегию: тимлид делает ревью кода, а ручные тестировщики — ваших тестов (сценариев).
Еще одно достоинство этого подхода заключается в часто используемых элементах. Если мы переверстаем этот блок, в котором 87 тестов, то все они упадут. Вы начинаете понимать, насколько ваши тесты flack-и.
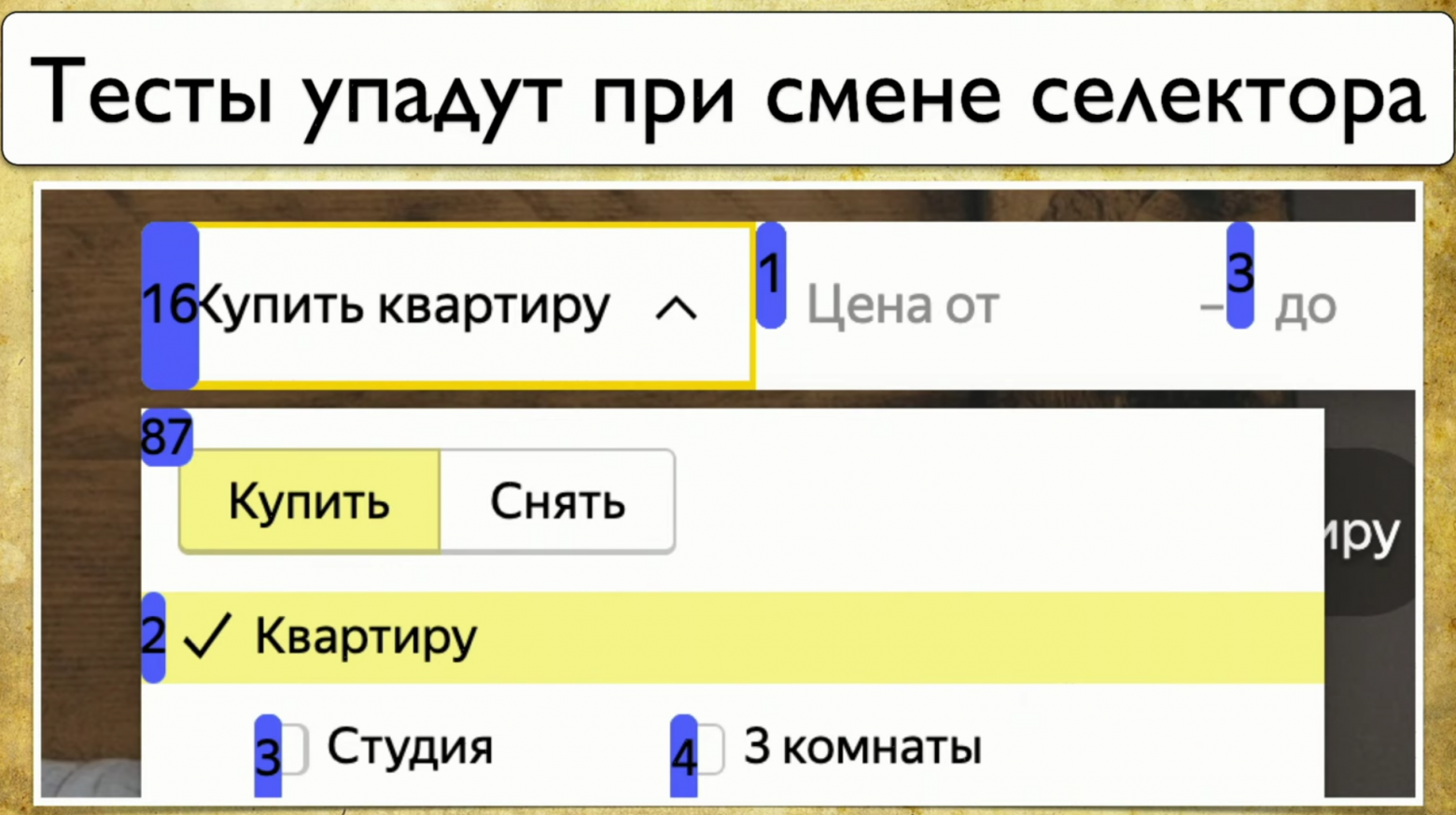
И если у нас переверстается блок «цена от», то ничего страшного, упадет один тест, человек его поправит. Если же изменить блок с 87-ю тестами, то покрытие сильно просядет, потому что 87 тестов не пройдут и не проверят какой-то результат. К этому блоку нужно повышенное внимание. Тогда нужно сообщить разработчику, что этот блок обязательно должен быть с ID, потому что если он уйдет — все развалится.
Например, можно идти по пути развития поддержки для других тулов, например, для Selenide. Хочется даже поддержать не конкретный Selenide, а реализацию драйвера, которая позволит собирать locators, вне зависимости от тулы, которую вы используете. Этот прокси будет дампить информацию и после этого отображать.
Другая идея связана с отображением текущего результата теста. Например, удобно кидать ручному тестировщику сразу такую картину:
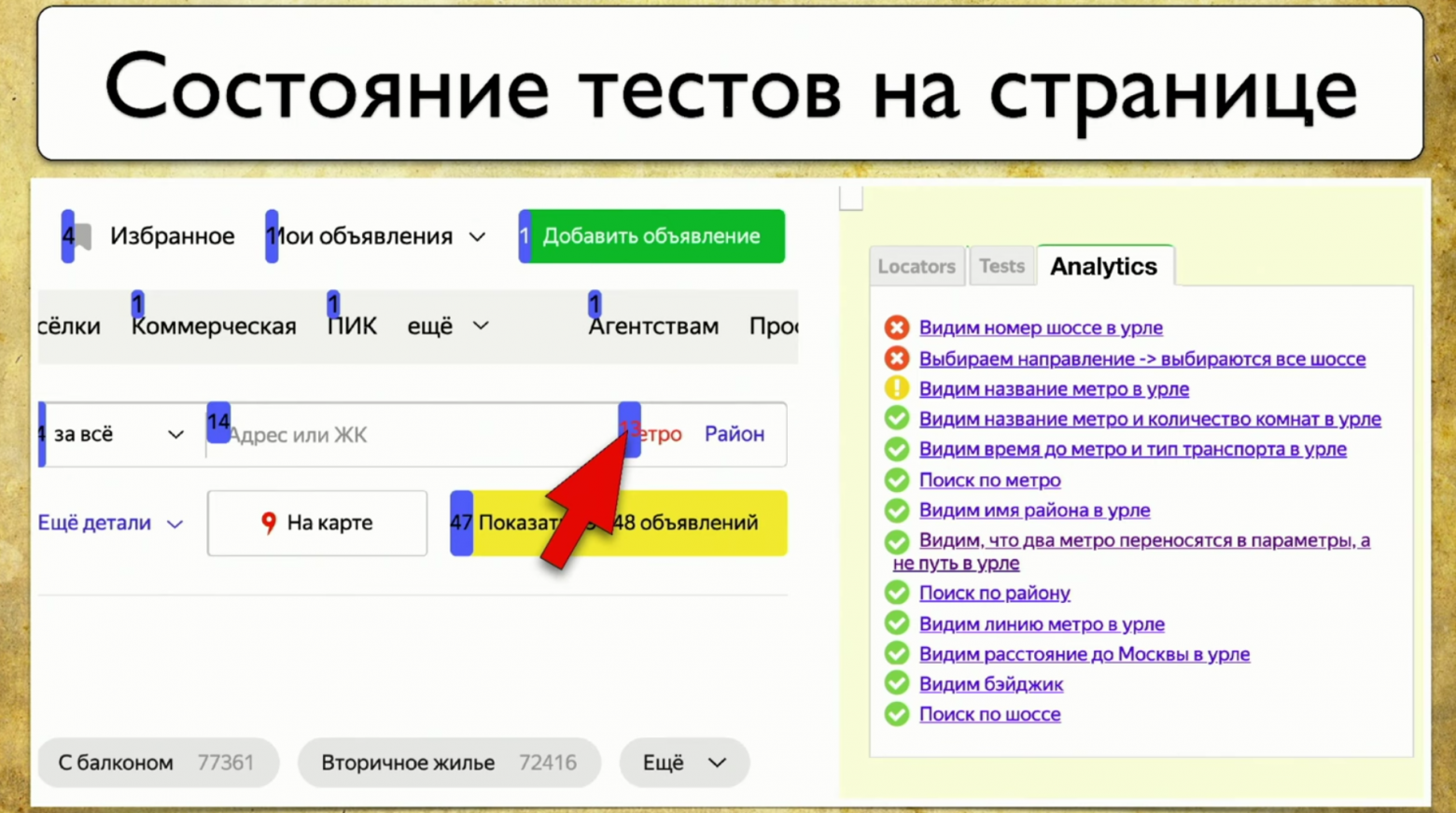
Не надо думать, какие тесты сломались, потому что можно зайти на сайт, кликнуть на тест и пройти его руками без проверок других тестов. Это делается легко, можно забрать эту информацию из Allure и нарисовать прямо здесь.
Можно также добавить Total Score, ведь все любят графики, поскольку хочется разобраться с тестами-дубликатами, которые очень похожи друг на друга, у которых центральная часть одинаковая, а начало и хвост немного поменялись.
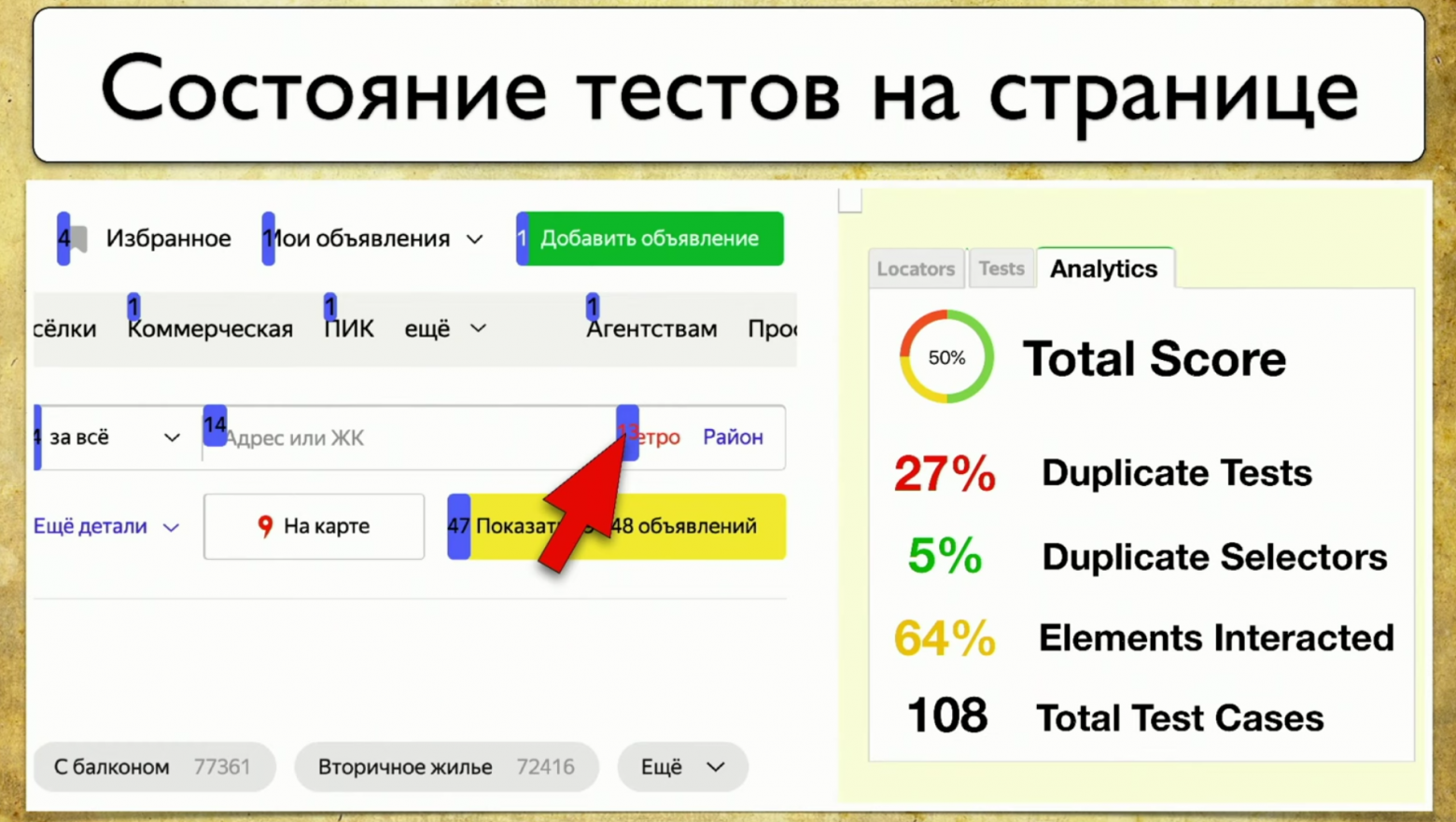
Хочется также сразу видеть цифру дубликатов селекторов. Если она высокая, то на этой странице надо делать рефакторинг и уводить тесты, иначе они будут падать слишком большой пачкой. То же касается и количества элементов, с которыми мы взаимодействовали. Это некоторый общий признак. Однако как только вы будете взаимодействовать со страницей, цифра будет скакать из-за новых элементов и общего количества тест-кейсов, поэтому нужно добавить какую-то аналитику, она будет не лишней.
Можно также добавить распределение тестов по слоям, поскольку хочется видеть не просто, что у нас есть вот эти тесты, а все типы тестов, которые есть на этой странице, возможно, даже ручные тесты.
Таким образом, при наличии Java-тестов и тестов на Puppeteer, которые пишет другая команда, мы можем посмотреть какую-то конкретную страницу и сразу сказать, где у нас тесты пересекаются. То есть мы будем разговаривать с ними на одном языке, и нам не надо будет по крупицам собирать эту информацию. Если у нас есть такой тул, который показывает все в веб-интерфейсе, то задача сравнения тестов на Java и Puppeteer уже не кажется нерешаемой.
Наконец, поговорим про общую стратегию. Мы уже сказали о том, какие есть виды покрытия, назвали два, придумали третий вид покрытия, который мы и использовали в результате. Таким образом, мы просто взяли и посмотрели на эту проблему под другим углом.
Желающие всегда могут присоединяться к нашему комьюнити. Вот два репозитория наших ребят, которые занимаются проблемой покрытия:
Под катом — видео и расшифровка доклада Артема Ерошенко из Qameta Software с конференции Heisenbug. Он представил несколько разработанных простых и элегантных решений, которые помогают команде Яндекс.Вертикалей оценивать покрытие тестов, написанных автоматизаторами тестирования. Артем расскажет, как можно быстро узнавать, что покрыто, как покрыто, какие тесты прошли, и мгновенно смотреть наглядные отчеты.
Меня зовут Артем Ерошенко eroshenkoam, я занимаюсь автоматизацией тестирования уже более 10 лет. Я был автоматизатором тестирования, менеджером команды разработки инструментов, разработчиком инструментов.
На данный момент я консультант в области автоматизации тестирования, работаю с несколькими компаниями, с которыми мы выстраиваем процессы.
Я также являюсь разработчиком и негласным менеджером Allure Report. Недавно мы поправили прикольную штуку: теперь в JUnit 5 есть fixtures.
Atlas Framework
Моя разработка — Atlas Framework. Если кто-то начинал автоматизировать в 2012 году, когда веб-драйверы Java только начинали свой путь, в этот момент я сделал из опенсорса библиотеку, которая называется HTML Elements.
Html Elements имеет свое продолжение и переосмысление в библиотеке Atlas, которая построена на интерфейсах: там нет классов как таковых, нет полей, очень удобная, легковесная и легко расширяемая библиотека. Если у вас есть желание в ней разобраться, можете прочитать статью или посмотреть доклад.
Мой доклад посвящен проблеме автоматизации тестирования и главным образом — покрытиям. В качестве предыстории, я хотел бы обратиться к тому, как процессы тестирования организованы в Яндекс.Вертикалях.
Как устроена автоматизация в Вертикалях?
В команде по автоматизации тестирования Яндекс.Вертикалей всего четыре человека, которые автоматизируют четыре сервиса: Яндекс.Авто, Работа, Недвижимость и Запчасти. То есть это небольшая команда автоматизаторов, которые делают очень много. Мы автоматизируем API, веб-интерфейс, мобильные приложения и так далее. Всего у нас где-то около 15,5 тысяч тестов, которые выполняются на разных уровнях.
Стабильность тестов в команде составляет около 97%, хотя некоторые мои коллеги говорят о 99%. Такая высокая стабильность достигается именно благодаря коротким тестам на очень нативных технологиях. Как правило, наши тесты занимают около 15 минут, что очень емко, и мы запускаем их примерно в 800 потоков. То есть у нас 800 браузеров стартуют одновременно — такой стресс-тест нашего testing'а. В качестве железа мы используем Selenoid (Aerokube). Подробнее об автоматизации тестирования в Яндекс.Вертикалях можно узнать, посмотрев мой доклад 2017 года, который до сих пор актуален.
Еще одна особенность нашей команды состоит в том, что у нас автоматизируют все, в том числе ручные тестировщики, которые вносят большой вклад в развитие автоматизации тестирования. Для них мы устраиваем школы, обучаем их тестам, учим, как писать тесты на API, на веб-интерфейс, и зачастую они помогают сопровождать тесты. Таким образом, ребята, которые отвечают за релиз, сами могут сразу же поправить тест, если потребуется.
В Вертикалях тесты пишут разработчики тестов, причем они настолько сильно увлеклись разработкой тестов, что конкурируют с нами. Об этом процессе подробнее можно узнать из доклада «Полный цикл тестирования React-приложений», где Алексей Андросов и Наталья Стусь рассказывают, как они пишут Unit-тесты на Puppeteer параллельно с нашими Java end-to-end тестами.
В нашей команде тесты пишут и инженеры по автоматизации тестирования. Но зачастую мы занимаемся развитием каких-то новых подходов по их оптимизации. Например, мы внедряли скриншотное тестирование, тестирование через моки, сокращение тестирования. В общем, наше направление в основном — software developer in test(SDET), мы больше про то, как надо писать тесты, а тестовая база наполняется отчасти нами и поддерживается ручными тестировщиками.
Разработчики нам тоже помогают, и это круто.
Проблема, которая возникает внутри этих процессов, заключается в том, что мы не всегда понимаем, что у нас уже покрыто, а что нет. Просматривая 15 тысяч тестов, не всегда ясно, что именно мы проверяем. Это особенно актуально в контексте общения с менеджерами, которые, конечно, не тестируют, но контролируют и задают вопросы. В частности, если возникает вопрос, протестирована ли конкретная кнопка в интерфейсе или flow, то на него сложно ответить, потому что нужно идти в код тестов и смотреть эту информацию.
Что тестируется, а что нет?
Если у вас много тестов на разных языках и их пишут люди с разной степенью подготовки, то рано или поздно возникает вопрос, а не пересекаются ли эти тесты вообще? В контексте этой проблемы вопрос покрытия становится особенно актуальным. Обозначу три ключевые темы:
- Способы эффективного измерения покрытия.
- Покрытие для API тестов.
- Покрытие для web-тестов.
Прежде всего, определимся с тем, что есть два способа покрытия: покрытие требований и покрытие кода продукта.
Как измеряется покрытие требований
Рассмотрим покрытие требований на примере auto.ru. На месте тестировщика auto.ru я бы сделал следующее. Во-первых, я бы погуглил и сразу бы нашел специальную таблицу требований. Это и есть основа покрытий требований.
В этой таблице названия требований выписаны слева. В данном случае: аккаунт, объявления, проверка и оплата, то есть проверка объявления. В целом, это и есть покрытие. Детализация левой части зависит от уровня тестировщика. Например, у инженеров из Google есть 49 типов покрытий, которые проверяются на разных уровнях.
Правая часть таблицы — это атрибуты требований. Мы можем использовать что угодно в виде атрибутов, например: приоритет, покрытие и состояние. Тут может быть и дата последнего релиза.
Таким образом, в таблице появляются некие данные. Для ведения таблицы требований можно использовать профессиональные инструменты, например — TestRail.
Справа есть информация о дереве: в папочках расписано, какие требования у нас есть, как их можно покрыть. Там находятся тест-кейсы и так далее.
В Вертикалях этот процесс выглядит так: ручной тестировщик описывает требования и тест-кейсы, затем передает их на автоматизацию тестирования, и автоматизатор пишет по этим тестам код. Причем раньше нам выдавались подробные тест-кейсы, в которых ручной тестировщик описывал всю структуру. Затем кто-нибудь делал коммит на гитхабе, и тест начинал приносить пользу.
Какие у этого подхода есть «плюсы и минусы»? Плюс в том, что этот подход отвечает на наши вопросы. Если менеджер спросит, что у нас покрыто, я открою табличку и покажу, какие фичи покрыты. С другой стороны, эти требования надо всегда держать в актуальном состоянии, а они очень быстро устаревают.
Когда у вас 15 тысяч тестов, то смотреть на TestRail — это все равно, что смотреть на звезду в космосе: она взорвалась уже давно, а свет до вас дошел только сейчас. Вы смотрите на актуальный тест-кейс, а он уже устарел давно и безвозвратно.
Эту проблему сложно решить. Для нас это вообще два разных мира: есть мир автоматизации, который крутится по своим законам, где каждый упавший тест сразу же фиксится, а есть мир ручного тестирования и карт требований. Стена между ними — непробиваемая, если только вы не используете Allure Server. Мы сейчас эту задачу для них как раз и решаем.
Третий пункт «плюсов и минусов» — необходимость ручной работы. Вам в новом проекте нужно заново создавать карту требований, писать все тест-кейсы и так далее. Это всегда требует ручной работы, и это на самом деле очень печально.
Как измеряется покрытие кода
Альтернатива этому подходу — покрытие кода. Кажется, это и есть решение нашей задачи. Вот так выглядит покрытие кода продукта:
Здесь отражено покрытие по package, точнее маленькая часть того, что на самом деле обычно есть в продукте. Слева написаны package, как раньше были написаны фичи. То есть наше покрытие наконец-то привязывается к каким-то осязаемым штукам, в данном случае — Package. Справа написаны атрибуты: покрытия по классам, покрытия по методам, покрытия по блокам кода и покрытие по строчкам кода.
Процесс сбора покрытия состоит в том, чтобы понять, по какой строчке кода тест проходил, а по какой — нет. Это довольно несложная задача, но в последнее время очень актуальная.
Первые упоминания покрытия кода были еще в 1963 году, но серьезные подвижки в этом направлении появляются только сейчас.
Итак, у нас есть тест, который взаимодействует с системой. Неважно, как он с ней взаимодействует: через фронтенд, API или напрямую лезет в бэкенд — просто будем считать, что он у нас есть.
Затем следует сделать инструментирование. Это некоторый процесс, который позволяет понять, какие строчки кода проверялись, а какие нет. Не надо его подробно изучать, надо просто поискать название вашего фреймворка, на котором вы пишете, скажем, Spring, затем instrumentation, и coverage — по этим трем словам поймете, как это делается.
Когда ваши тесты проверяют, на какую строчку кода попал тест, а на какую не попал, они сохраняют файлы с информацией о том, какие строчки покрыты. На основе этой информации у вас появляются данные.
Какие «плюсы и минусы» у покрытия кода?
Покрытие кода я бы сразу назвал минусом. Вы не придете к менеджеру, не покажете вот эту табличку и не скажете, что все автоматизировали, потому что эти данные невозможно читать, он попросит вернуть понятные данные, на которые можно быстро посмотреть и все понять.
Отчет о покрытии кода ближе к разработке. Его нельзя использовать как нормальный подход к предоставлению всех данных команде, если мы хотим, чтобы вся команда могла смотреть.
Достоинство этого подхода в том, что он всегда предоставляет актуальные данные. Вам не надо делать много работы, все автоматизировано за вас. Просто подключаете библиотеку, у вас начинают сниматься покрытия — и это реально круто.
Другое достоинство этого подхода в том, что он требует только настройки. Там не надо особо ничего делать — просто приходите с определенной инструкцией, настраиваете покрытие, и оно работает автоматически.
Покрытие требований позволяет выявить нереализованные требования, но не позволяет оценить полноту по отношению к коду. Например, вы начали писать новую фичу «авторизация», просто заносите «фича авторизации», начинаете накидывать на нее тест-кейсы. Вы не можете тут же посмотреть это покрытие в коде, даже если вы напишите какой-то новый класс, все равно не будет информации — происходит разрыв. С другой стороны, это требование авторизации, даже когда оно уже будет имплементировано, когда вы по нему посчитаете покрытие, эта часть не сможет быть актуальной, ее нужно держать актуальной вручную.
Поэтому у нас появилась идея: а что если взять лучшее от каждого? Так, чтобы покрытие отвечало на наши вопросы, всегда было актуально и требовало только настройки. Нам надо просто взглянуть на покрытие под другим углом, то есть взять за основу покрытия другую систему. При этом сделать так, чтобы оно собиралось полностью автоматически и приносило кучу пользы. И для этого мы перейдем в покрытие для API тестов.
Покрытие API тестов
Что лежит в основе покрытия? Для этого мы используем Swagger — это API для документации. Сейчас я не представляю свою работу без Swagger, это инструмент, который у меня постоянно используется для тестирования. Если вы не пользуетесь Swagger, я крайне рекомендую зайти на сайт и ознакомиться. Там вы сразу же увидите очень интуитивный и понятный пример использования.
По сути, Swagger представляет из себя документацию, которая генерируется по вашему сервису. Она содержит:
- Список запросов.
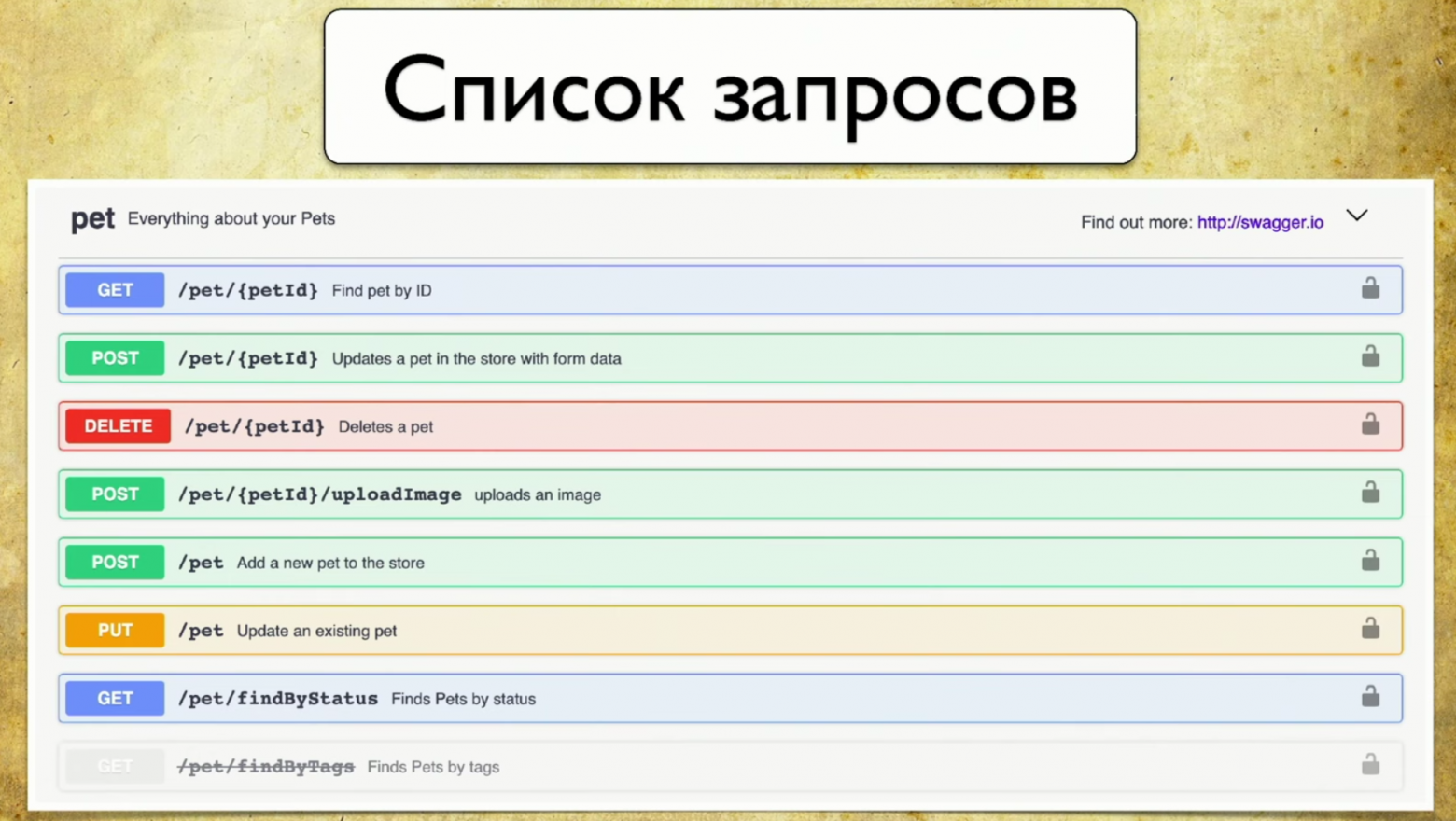
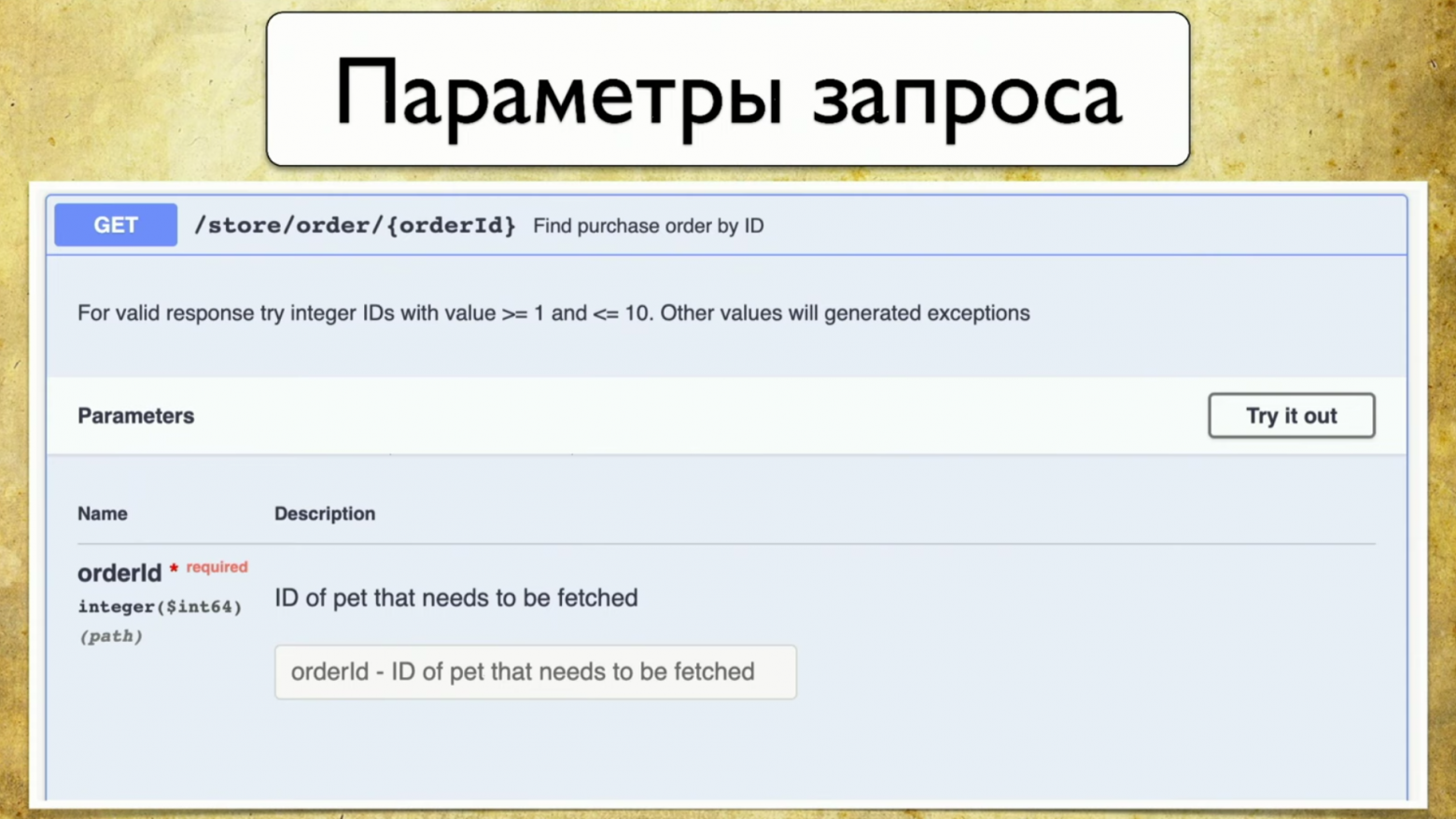
- Параметры запроса: больше нет необходимости дергать разработчика и спрашивать, какие есть параметры.
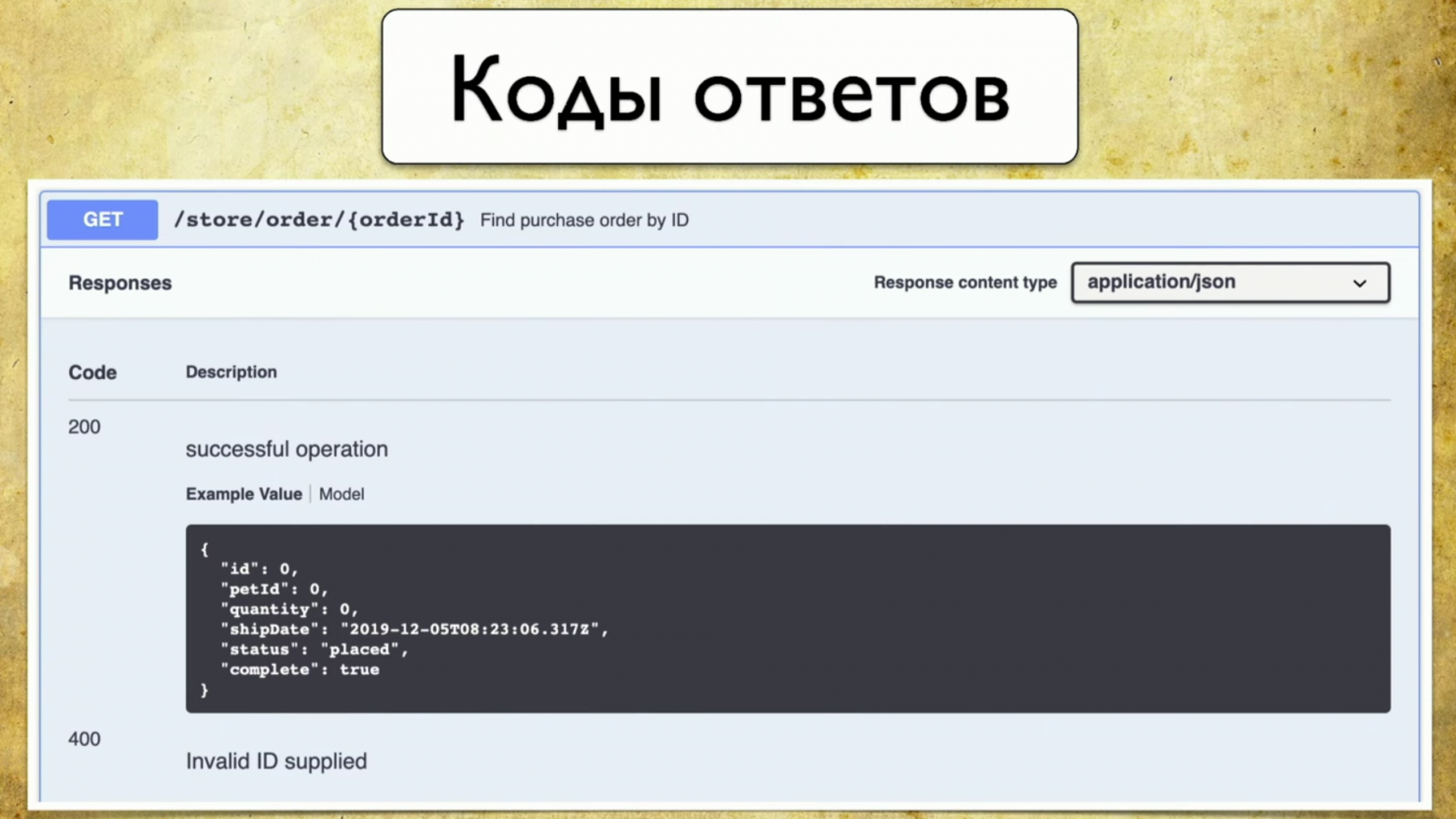
- Коды ответов.
Принцип работы Swagger — это генерация. Неважно, какой фреймворк вы используете. Допустим, Spring либо Go Server, вы используете компонент Swagger Codegen и генерируете swagger.json. Это некоторая спецификация, на основе которой потом рисуется красивый UI.
Для нас важно, что используется именно swagger.json: его поддержка есть для всех широко используемых языков.
У нас есть Open API спецификация swagger.json. Она выглядит так:
Запросы выглядят примерно таким образом: summary, description, коды ответов и «ручка» (path: /users). Также есть информация о параметре запросов: все структурировано, есть параметр user ID, он находится в пути, где есть required, такой-то description и type — integer.
Есть коды ответов, они тоже все задокументированы:
И нам пришла в голову идея: у нас есть сервис, который генерирует Swagger, и мы захотели в тестах сохранять такой же Swagger, чтобы потом их сравнить. Другими словами, когда пробегают тесты, они генерируют ровно такой же Swagger, мы его кидаем на Swagger Diff, понимаем, какие параметры, ручки, статус коды у нас проверены и так далее. Это то же самое инструментирование, тот же самый coverage, только наконец-то в требованиях, которые мы понимаем.
А что если построить дифф?
Мы обратились к библиотеке Swagger diff, которая для этого и нужна. Ее принцип работы примерно такой: у вас есть версия 1.0, при V версия API 1.1, они оба генерируют swagger.json, потом вы их кидаете на Swagger diff и смотрите результат.
Результат выглядит примерно таким образом:
У вас есть информация, что появилась, например, новая ручка. У вас также есть информация о том, что удалилось. Это значит, что тесты пора удалять, они уже неактуальны. С появлением информации об изменениях меняются и параметры, таким образом, очевидно, что в этот момент упадут ваши тесты.
Нам понравилась эта идея, и мы начали имплементировать. Как мы решили делать: у нас есть «эталонный» Swagger, который генерирует с кода разработчиков, у нас также есть API тесты, которые будут генерировать свой Swagger, и мы между ними сделаем diff.
Итак, мы запускаем тесты на сервис: у нас есть Rest Assured, который сам обращается к сервисам на API. И мы его инструментируем. Здесь есть подход: можно сделать фильтры, на него уходит запрос — и он сохраняет информацию о запросе в виде swagger.json прямо под себя.
Вот весь код, который нам надо было написать, там было 69-70 строчек — это очень простой код.
Самое смешное, что мы использовали нативный клиент для Swagger, писали прямо там. Нам даже не надо было создавать свои bin-ы, просто наполняли спецификацию Swagger.
У нас получилось очень много .json-файлов, с которыми надо было что-то сделать — написали Swagger-агрегатор. Это очень простая программа, которая работает по следующему принципу:
- Она встречает новый запрос, если его нет в нашей базе — добавляет.
- Она встречает запрос, у него новый параметр — добавляет.
- То же самое со статус-кодами.
Таким образом, у нас появляется информация про все ручки, параметры и статус-коды, которые мы задействовали. Кроме того, здесь можно собирать и данные, с которыми эти запросы выполнялись: username, логины и так далее. Мы пока не придумали, как использовать эту информацию, потому что у нас все генерируется, но вы можете понимать, с какими параметрами были вызваны те или иные запросы.
Итак, мы были почти в двух шагах от победы, но в результате отказались от Swagger Diff, потому что он работает немного в другой концепции — в концепции дифа.
Swagger Diff говорит, что изменилось, а не что покрыто, а мы хотели отображать именно результат покрытия. Там очень много лишних данных, он хранит в себе информацию о description, summary и другую метаинформацию, а у нас этой информации нет. И когда мы делаем Diff, нам пишут, что «у этой ручки отсутствует description», а его и не было.
Свой отчет
Мы сделали свою имплементацию, и она работает следующим образом: у нас есть много файлов, которые пришли с автотестов, есть API service Swagger, и мы на основе его генерируем отчет.
Простой отчет выглядит так: сверху видно информацию, сколько всего ручек (349), информацию о том, которые покрыты полностью (каждый параметр, статус-код и так далее покрыт). Можно выбрать свои критерии, например, покрыть несколько параметров.
Здесь также есть информация, что 40% покрыто частично — это значит, что у нас уже есть тесты на эти ручки, но некоторые вещи еще не покрыты, и нужно туда внимательно посмотреть. Отражено также Empty-покрытие.
Давайте пройдемся по tab-ам. Это full-покрытие, мы видим все параметры, которые у нас есть, которые покрываются, статус-коды и так далее.
Потом у нас есть частичное покрытие. Мы видим, что у нас на ручку login-social один параметр покрыт, а два — нет. Причем мы можем развернуть ее и посмотреть, какие конкретно параметры и статус-коды покрыты. И в этот момент разработчику становится очень удобно: версии приложения у нас катятся очень быстро, и мы зачастую можем забыть какие-то параметры.
Этот инструмент позволяет всегда быть в тонусе и понимать, что у нас покрыто частично, какой параметр забыли и так далее.
Последнее — Glory of shame, нам еще предстоит это делать. Когда смотришь на эту страничку и видишь там Empty:172 — руки опускаются, и тогда начинаешь обучать ручных тестировщиков писать автотесты, в этом и смысл.
Какую пользу мы получили, когда выкатили свое решение?
Во-первых, мы стали более осмысленно писать тесты. Мы понимаем, что тестируем, и при этом у нас есть две стратегии. Первая — мы автоматизируем то, чего еще нет, когда приходят ручные тестировщики и говорят, что для определенного сервиса критично, чтобы один запрос был выполнен хотя бы один раз, и мы открываем Empty.
Второй вариант — мы не забываем про хвосты. Как я уже сказал, API релизятся очень быстро, по два-три раза в день могут быть какие-то релизы. Туда постоянно добавляются какие-то параметры: в пяти тысячах тестов невозможно понять, что проверено, а что нет. Поэтому это единственный способ осмысленно выбирать стратегию тестирования и хотя бы что-то делать.
Третий профит — процесс полностью автоматический. Мы позаимствовали подход, и работает автоматика: нам ничего не надо делать, все собирается автоматически.
Идеи по развитию
Во-первых, очень не хочется держать второй отчет, а хочется интегрировать его в Swagger UI. Это мой любимый «Photoshop Edition report»: фишка, которую я разрабатывал в последнее время. Тут сразу же есть информация о параметрах, которые у нас протестированы, а которые нет. И было бы круто отдавать эту информацию сразу вместе со Swagger-ом.
Например, фронтендер может сам посмотреть, какие параметры еще не протестированы, расставить приоритеты и решить, что пока их не нужно брать в разработку, ведь неизвестно, насколько хорошо они работают. Или бэкэндер пишет новую ручку, видит красное и пинает тестировщиков, чтобы все было зеленое. Это сделать довольно несложно, мы идем в этом направлении.
Вторая идея — поддержка других тулов. На самом деле не хочется писать фильтры для конкретных имплементаций: для Java, Python и так далее. Есть идея сделать некую прокси, которая будет пропускать через себя все запросы, и сохранять Swagger-информацию под себя. Таким образом, у нас будет универсальная библиотека, которую можно использовать независимо от того, какой у вас язык.
Третья идея по развитию — это интеграция с Allure Report. Я вижу это вот так:
Как правило, когда параметр «протестирован», это не всегда говорит нам о том, как он протестирован. И хочется навести на этот параметр и увидеть конкретные шаги теста.
Покрытие для Web-тестов
Следующий пункт, о котором я хочу поговорить — покрытие для Web-тестов. В основе покрытия — сайт, который вы тестируете, пишете тесты на сайт. Но ведь его можно сделать веб-интерфейсом к вашему покрытию. Например, это будет выглядеть так:
Если посмотреть на ваш сайт — это некоторый набор элементов и способов взаимодействия с ними. Это полное описание: «элемент — способ с ним взаимодействовать». На ссылку можно кликнуть, текст можно скопировать, в input можно что-то вбить. Сайт в целом состоит из элементов и способов их взаимодействия:
Как бегают тесты: они начинают с какой-то точки, затем, например, заполняют какую-то форму, допустим, форму авторизации, затем разбегаются по другим страничкам, потом еще по другим и заканчиваются.
Если менеджер спрашивает, тестируется ли какая-то конкретная кнопка, а на этот вопрос сложно ответить: нужно код открыть, либо в TestRail зайти, то хочется видеть такое решение проблемы:
Я хочу навести на этот элемент и увидеть все тесты, которые у нас есть на этот элемент. Если бы такой инструмент был, я был бы счастлив. Когда мы начали думать про эту идею, то, в первую очередь, посмотрели на Яндекс.Метрику. У них на самом деле есть примерно подобная функциональность по карте ссылок. Хорошая идея.
Суть в том, что они подсвечены ровно так, словно уже дают нужную нам информацию. Они говорят: «Вот по этой ссылке проходили 14 раз», что в переводе на язык тестирования значит: «в этой ссылке тестировали 14 тестов» и так или иначе через нее прошли. А вот на эту красную ссылку уходило аж 120 тестов, какие интересные тесты!
Можно рисовать всякие тренды, добавлять метаинформацию, но что будет, если мы это все возьмем и нарисуем с точки зрения тестирования? Итак, у нас задача: навести на какой-то элемент и получить заметку со списком тестов.
Для того, чтобы это имплементировать, надо кликнуть на иконку, затем написать заметку, и это — весь наш тест. Мы у себя используем Atlas, и интеграция пока есть только с ним.
Atlas выглядит примерно так:
SearchPage.open ();
SearchPage.offersList().should(hasSizeGreaterThan(0));
Мы хотим, чтобы хотя бы один результат в выдаче был, иначе нам это не протестировать. Потом мы двигаем курсор на элемент, затем кликаем на него.
searchPage.offer(FIRST).moveCursor();
searchPage.offer(FIRST).actionBar().note().click();
Потом сохраняем в input User_Text и сабмиттим ее.
searchPage.offer(FIRST).addNoteInput().sendKeys(USER_TEXT);
searchPage.offer(FIRST).saveNote().click();
После этого проверяем, что текст ровно тот, который должен был быть.
searchPage.offer(FIRST).addNoteInput().should(hasValue(USER_TEXT));
Тесты запускаются в браузере, Atlas является прокси к этому тесту, применим сюда тот же подход, что все используют при сборе покрытия: сделаем locator с .json. Будем сохранять туда информацию про все открытия страницы, все итерации с элементами, кто сабмиттился, кто делал sendkey, кто click, на какие ID и так далее — будем вести полный лог.
Потом этот лог прикрепляем к Allure в виде каждого теста, и когда у нас появляется много locators.json — мы генерируем meta.json. Схема одна и та же для всех элементов.
У нас есть плагин для Google Chrome. Мы захотели сделать решение в виде плагина. Я специально сделал кривой скриншот, чтобы на слайде была видна одна важная деталь — path to locators.json.
Если вы сгенерировали отчет сейчас, то там находится карта покрытия на сегодня. Если вы возьмете отчет за предыдущие две недели и вставите сюда, то появится карта покрытия за период две недели назад. У вас появляется машина времени!
Тем не менее, когда вы подключаете этот плагин, он рисует не очень дружелюбный интерфейс.
У каждого элемента появляется количество тестов, которые через него проходят: видно, что 40 тестов проходят через «купить квартиру», header тестируется по одному тесту, это прикольно, и опция «квартиру» тоже отображается. У вас получается полная карта покрытия.
Если вы наведете на какой-то элемент, он возьмет данные и отпечатает ваши реальные тесты с вашей tms, Allure Board и так далее. В результате появляется полная информация о том, что тестируется и каким образом.
Учтите, что из каждого теста можно провалиться прямо в Allure-отчет.
Когда вы открываете любую штуку, он подгружает новые селекторы: если у вас есть какие-то тесты, которые проходят через эти селекторы, и вы что-то делали с сайтом, он обработает и покажет всю картину.
Какой профит?
Как только мы внедрили этот простой подход, то, главным образом, мы начали понимать, что у нас проверяется в тестах.
Теперь любой может зайти и найти любую «нитку», которая ведет к сценарию. Например, вы предполагаете, что нужно протестировать оплату. Оплата, очевидно, ведет через кнопку оплаты: нажимаете — появляются все тесты, которые проходят через кнопку оплаты. Это чудесно! Вы заходите в любой из них и просматриваете сценарий.
Более того, вы понимаете, что проверялось раньше. У нас генерируется статический файл, вы можете указать к нему путь и указать, какие тесты были две недели назад. Если менеджер, говорит, что в продакшене баг и спрашивает, тестировали ли мы пару недель назад такую-то функциональность, вы берете репорт Allure, говорите, например, что не тестировали.
Еще один профит — ревью после автоматизации тестирования. До этого у нас было ревью до автоматизации тестирования, сейчас же можно делать свои тесты ровно так, как вы их видите. Захотели сделать тест — сделали, отвели какой-то branch, запустили Allure, скинули ссылку на плагин ручному тестировщику и попросили посмотреть тесты. Это именно тот процесс, который позволит вам усилить Agile-стратегию: тимлид делает ревью кода, а ручные тестировщики — ваших тестов (сценариев).
Еще одно достоинство этого подхода заключается в часто используемых элементах. Если мы переверстаем этот блок, в котором 87 тестов, то все они упадут. Вы начинаете понимать, насколько ваши тесты flack-и.
И если у нас переверстается блок «цена от», то ничего страшного, упадет один тест, человек его поправит. Если же изменить блок с 87-ю тестами, то покрытие сильно просядет, потому что 87 тестов не пройдут и не проверят какой-то результат. К этому блоку нужно повышенное внимание. Тогда нужно сообщить разработчику, что этот блок обязательно должен быть с ID, потому что если он уйдет — все развалится.
Как можно развиваться дальше?
Например, можно идти по пути развития поддержки для других тулов, например, для Selenide. Хочется даже поддержать не конкретный Selenide, а реализацию драйвера, которая позволит собирать locators, вне зависимости от тулы, которую вы используете. Этот прокси будет дампить информацию и после этого отображать.
Другая идея связана с отображением текущего результата теста. Например, удобно кидать ручному тестировщику сразу такую картину:
Не надо думать, какие тесты сломались, потому что можно зайти на сайт, кликнуть на тест и пройти его руками без проверок других тестов. Это делается легко, можно забрать эту информацию из Allure и нарисовать прямо здесь.
Можно также добавить Total Score, ведь все любят графики, поскольку хочется разобраться с тестами-дубликатами, которые очень похожи друг на друга, у которых центральная часть одинаковая, а начало и хвост немного поменялись.
Хочется также сразу видеть цифру дубликатов селекторов. Если она высокая, то на этой странице надо делать рефакторинг и уводить тесты, иначе они будут падать слишком большой пачкой. То же касается и количества элементов, с которыми мы взаимодействовали. Это некоторый общий признак. Однако как только вы будете взаимодействовать со страницей, цифра будет скакать из-за новых элементов и общего количества тест-кейсов, поэтому нужно добавить какую-то аналитику, она будет не лишней.
Можно также добавить распределение тестов по слоям, поскольку хочется видеть не просто, что у нас есть вот эти тесты, а все типы тестов, которые есть на этой странице, возможно, даже ручные тесты.
Таким образом, при наличии Java-тестов и тестов на Puppeteer, которые пишет другая команда, мы можем посмотреть какую-то конкретную страницу и сразу сказать, где у нас тесты пересекаются. То есть мы будем разговаривать с ними на одном языке, и нам не надо будет по крупицам собирать эту информацию. Если у нас есть такой тул, который показывает все в веб-интерфейсе, то задача сравнения тестов на Java и Puppeteer уже не кажется нерешаемой.
Наконец, поговорим про общую стратегию. Мы уже сказали о том, какие есть виды покрытия, назвали два, придумали третий вид покрытия, который мы и использовали в результате. Таким образом, мы просто взяли и посмотрели на эту проблему под другим углом.
С одной стороны, существует покрытие, которое пинают с 1963 года, с другой стороны, есть ручные тестировщики, которые привыкли жить в более реальном мире, нежели код. Остается только совместить эти два подхода.
Желающие всегда могут присоединяться к нашему комьюнити. Вот два репозитория наших ребят, которые занимаются проблемой покрытия:
