Data Scientists узнают, что интересует людей и на что они тратят деньги
В ходе исследований различных аудиторий Data Scientists наблюдают как закономерные, так и удивительные факты, которые ярко характеризуют социум вокруг нас. В этой статье я расскажу о тех курьёзах и необычных случаях, которые заметила при выполнении задач, связанных с аудиторным анализом, исследованием интересов пользователей Интернета и покупательского поведения различных социальных групп.
Какие социологические особенности удалось выяснить благодаря применению моделей машинного обучения? Что мы знаем о покупателях?

Профиль клиента по его чеку? Легко!
Я работаю аналитиком данных в CleverDATA и, как правило, встречаюсь со следующими задачами: классификацией сырых данных, аудиторным анализом и построением look alike моделей (LaL), когда у заказчика есть собственная аудитория и он хотел бы найти похожую. Это очень востребовано для различных рекламных кампаний в Интернете.
У нас есть биржа данных 1DMC DATA Exchange, участники которой могут обогащать и монетизировать свои данные. В ней содержатся деперсонализированные данные двух видов, агрегированные в атрибуты нашей таксономии, – это онлайн-покупки и clickstream, то есть последовательность посещений страниц, которую нам удалось отследить. Формат данных отвечает европейскому стандарту защиты персональных данных GDPR.
Атрибутами нашей таксономии являютсям факты владения вещью или наличие определенного интереса у человека. Это бинарная информация — либо есть, либо нет.
Вот примеры атрибутов нашей таксономии:

Одной из самых значимых задач является агрегация сырых данных поставщиков в атрибуты таксономии, то есть задача классификации.
Мне необходимо по покупкам людей сделать выводы об их образе жизни и наличии у них тех или иных вещей (условно, чек на фирменный фонарь модели Street Rod наверняка свидетельствует о том, что покупатель является владельцем мотоцикла Harley-Davidson) или выявить потенциальный интерес к покупкам с помощью Интернет-страниц, которые они посещают. Потом эта информация будет использоваться для таргетинговой рекламы.

В процессе моей работы появляются такие цепочки:
- чек – мои AI-модели – профиль покупателя;
- click stream – мои AI-модели — профиль посетителя сайта.
Инструмент, который мы используем в CleverDATA, автоматически строит бинарный классификатор для любого атрибута нашей таксономии. Из самого названия атрибута таксономии (владелец атрибута мотоцикла-чоппера) мы в итоге получаем уже автоматически оцененный бинарный классификатор (хорошая ли модель или аналитику ее необходимо доработать), который способен по чеку определить наличие или отсутствие такого предмета у человека. Подробнее об этом вы можете почитать в нашей статье на Хабре.

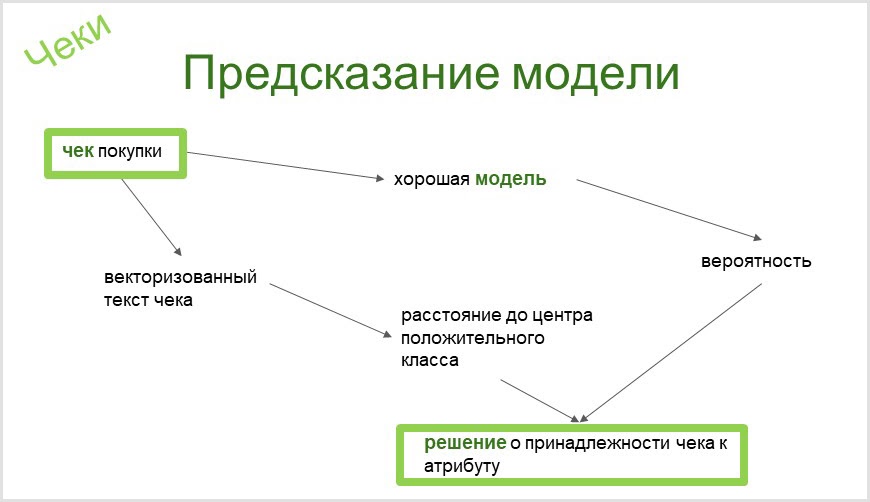
При классификации чеков необходим инструмент, который позволит отделять чеки, похожие по словам, от похожих по смыслу. Так, я как-то строила модель для фиксации интереса к курсам профессиональной переподготовки. И она определила чек на покупку детской книги Паоло Косси «Курс уроков волшебства для обычного кота» как интерес к данной теме. Это, конечно, забавная ошибка. Кстати, о существовании книги я узнала именно из этого чека.

Чтобы избежать подобных курьёзов, мы применяли языковые модели для оценки получившихся бинарных классификаторов и отсечения тех примеров, которые похожи по словам, но не по смыслу.
Чеки мне приходится время от времени просматривать глазами, чтобы находить какие-то ложные соответствия и впоследствии автоматизировать поиск подобных ошибочно выстроенных связей. Бывает полезно докопаться до сути, потому что, возможно, один-единственный непонятный случай позволит мне улучшить весь процесс.
За всю практику у меня скопился целый набор чеков-загадок, которые я не смогла не только классифицировать, но даже расшифровать, что именно приобрел покупатель. Этими забавными случаями я регулярно делюсь с коллегам и даже завела рубрику «AI шутит».
Самая частая разгадка – указание в чеке названия книги без наименования товара. Именно это мы видим в случае с «волшебством для обычного кота». А какие покупки зафиксированы в чеке «Забор Новосибирск 1029 руб.» и «Договор-коробка 5000 руб.», я до сих пор не поняла. Ваши версии принимаю в комментариях к этой статье.
Далее перейдем к классификации click stream.
Профиль клиента по его перемещениям на web-сайте
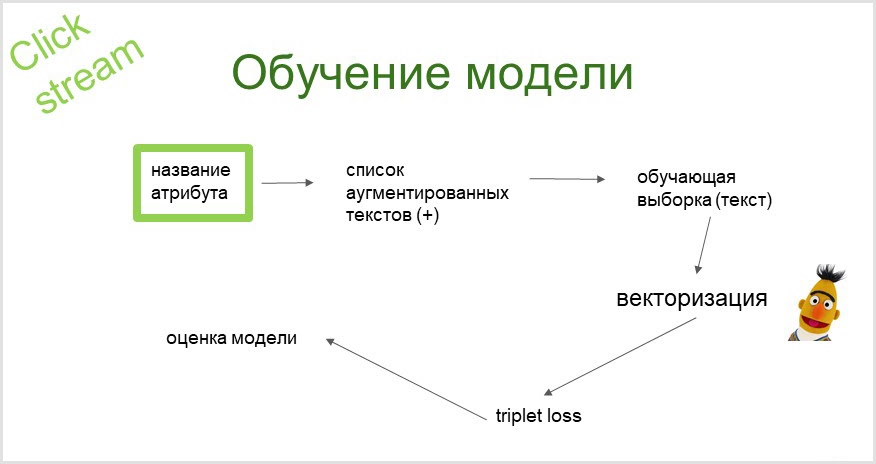
Система классификации кликстрима была введена нами в 2019 году, который был богат на прорывы в области NLP (Natural Language Processing). Одним из самых громких и успешных изобретений в данной области является сеть BERT (Bidirectional Encoder Representations from Transformers). Так что впереди будет немного Бертологии.

Из названия атрибута мы с помощью вероятностной языковой модели получаем аугментированный (расширенный синонимами) список запросов, которые мы краулим (отправляем в поисковик и собираем поисковую выдачу), отсюда получается наша обучающая выборка. Векторизуем её при помощи предобученной языковой модели BERT. На полученных эмбеддингах (векторах) обучаем классификатор (с функцией потерь triplet loss).
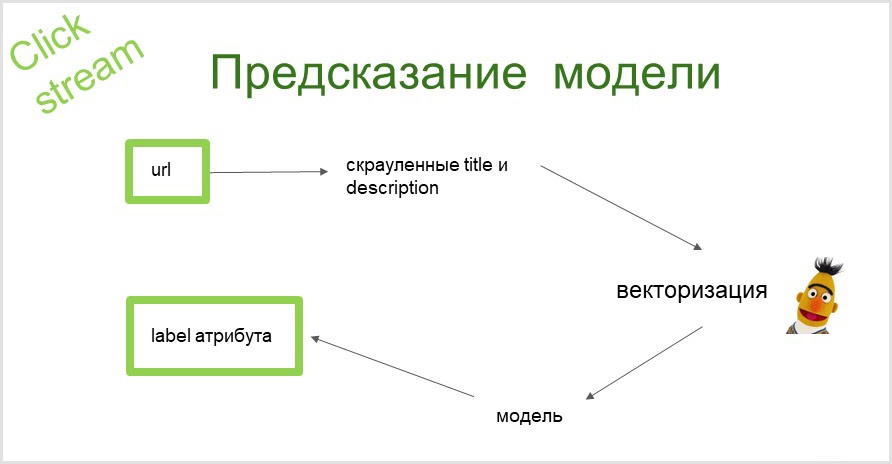
Как происходит предсказание?
Мы берем url страницы, собираем текстовую информацию (title и description страницы). При помощи BERT получаем векторное представление данных текстов. Затем эти векторы подаем в модель и на выходе получаем атрибут, к которому мы можем отнести страницу.
В целом данная система весьма успешна, все забавные случаи, которые мне попались, скорее исключения, чем правило. Но я стараюсь уделять им большое внимание, потому что малая ошибка может привести к большим неприятным последствиям, поскольку через систему проходит огромное количество данных.
Онлайн-данные, которые я исследовала, показали, что люди чаще всего читают в Интернете. Выяснилось, что это одна из очень популярных тематик – это астрология, гадания и т.п.

Вот эти конкретные страницы (url-адреса, не домены) за день посещало свыше 5000 тысяч человек (уникальных идентификаторов). Особенно поразил сайт, посвященный астрологии кошки и раскрывающий связь характера животного с его знаком зодиака.

Все знают про стоп-слова и обычно подключают словари или фильтруют по частотам, не погружаясь глубоко в специфику текстов. На первых порах я тоже подключила свои словарики. Результат не порадовал: сайт рецептов без использования выпечки классифицировался в атрибут интереса к выпечке (домашнему выпеканию). А связано это с тем, что все отрицательные частицы присутствовали в моем словаре стоп-слов.

На своем примере я призываю своих коллег внимательно читать те словари, которыми вы фильтруете свои данные.
Еще одна распространенная проблема: люди часто используют саркастичные высказывания, что на этапе краулинга приводит к забавным фразочкам в title и description страниц, относящихся к определенным запросам в Интернете. Например, модель может связывать чебуреки и интерес к вегетарианской диете. Мне кажется, это объяснимо обилием комментариев к статьям на тему вегетарианства в духе «А как ты живешь без чебуреков?».

А теперь минутка черного юмора в нашей рубрике «AI шутит»: обсуждение легализации эвтаназии модель связала с интересом к покупке жилья, а рэпера Тимати – с цирком. Мне приходилось залезать в данные и вручную переотмечать класс.
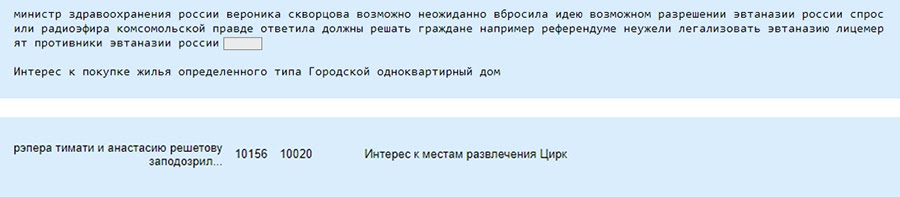
Есть сетапы, которые мы не можем контролировать, они зависят от социума, в котором мы живем. И тогда криминал получается вперемешку с комедиями и семейными отношениями.

А есть и неоднозначные случаи, когда даже не знаешь, стоит ли ругать модель и что-то переразмечать, борясь с ошибками, или оставить всё как есть.
Возможно получение посылок действительно несет предпринимательский риск.
А на доске объявлений может обнаружиться всё что угодно.

Поиск похожей аудитории
Следующий блок задач, который мне как аналитику приходится решать, – это Audienсe Research/Look-alike modeling. Заказчик, как правило, хочет некого нового знания об аудитории, которое должно ему помочь наладить с ней коммуникации. Но даже если его запрос нечетко сформулирован, мы всегда стараемся ему помочь, и в большинстве случаев нам это удается.
Здесь есть выбор, делать ли упор на Audience Research, то есть на внутренние инсайты (разведывательный анализ аудитории) или же на Look-alike модель, которая потом позволит проскорить аудиторию нашей биржи и обнаружить потенциальных клиентов, опираясь на внутренние данные заказчика о целевой аудитории. Под аудиторией понимается множество закодированных идентификаторов (телефонов, адресов электронной почты или онлайн id). Напоминаю, мы не работаем с данными в открытом виде, соблюдаем все правила законодательства.
Итак, мы можем множество закодированных идентификаторов пересечь с биржей и посмотреть покупательское поведение или их click stream. Для любой целевой аудитории и любых задач мы в любом случае делаем кластеризацию. После того как модель сгруппировала людей по их покупательскому поведению, я как-то увидела кластер, состоящий только из людей, которые делают ставки на спорт и больше ничего не покупают в Интернете. Хотя, возможно, у них какие-то отдельные аккаунты для букмекерских целей.
Вот скрин этого кластера.

Кейс «Счастливое материнство»
Для рекламной кампании известного бренда подгузников надо было провести исследование аудитории и найти женщин на третьем триместре беременности – заказчик предположил, что именно с третьего триместра надо рекламировать товар, чтобы большая часть аудитории его купила.
В начале анализа описание обстоятельств жизни беременных напоминало идиллическую картинку: молодая семья с домашними животными накануне появления ребенка обустраивает жилье.

Женщины из разных кластеров являются владелицами гаджетов разных брендов, предпочитают разные марки гигиенических товаров, и в целом всё благополучно. Смотрите сами.
25,5% идентификаторов
Покупатели Huggies Elite Soft, в три раза реже покупают Pampers и в 7 раз реже продукцию Lovular. Пользуются продукцией марки «Пелигрин». С высокой вероятностью (0,6) являются родителями девочек. Склонны оплачивать ЖКХ через Интернет.
25,5% идентификаторов
Склонны оплачивать через Интернет услуги связи и страховые услуги. С высокой вероятностью (0,6) являются владельцами собак. Покупают продукцию Helen Harper. Среди потребительской электроники выражен бренд Xiaomi.
17,5% идентификаторов
Пользователи Ozon Premium. Покупают технику по уходу за ребенком Philips Avent, интересуются техникой и установками для глажки.
Внимание, совет на будущее: следите за акциями/брендами, которые в общем объеме данных создают «шум».
Статус Ozon Premium во многих наших кластерах оказался одним из определяющих атрибутов. Но таргетироваться на аудиторию потенциальных покупателей подгузников лишь по Ozon Premium – за гранью здравого смысла. Поэтому мне пришлось вырезать статус из всех данных. Да, я таким образом понизила метрики, но при этом повысила адекватность модели. На первое место вышли товары для новорожденных, а не раскрученный, популярный статус. Это было опыт, который научил отсекать товары, имеющие слишком большую значимость для модели.
Для look-alike моделирования на поверхности лежит идея построения нескольких простых классификаторов целевой аудитории (класс 1) и обобщенной (класс 0) для того, чтобы выделить ЦА.
Например, берем покупки целевой аудитории и десятикратного объема случайных профилей. Приводим эту информацию в последовательность, покупок. Затем мы работаем с полученными текстами (препроцессинг): удаляем все высокочастотные, неинформативные слова, а оставшиеся приводим к начальной форме. Дальше мы строим простые классификаторы нескольких разных семейств – линейные (Linear SVC, Logistic Regression), «деревянные» (RandomForest) и т. д. – и меряем feature importance, то есть важность каких-либо слов по мнению моделей. Я находила пороговые значения, выше которых важность этих признаков неадекватна, то есть признак слишком шумит. Прежде чем построить что-то автоматическое, приходится много раз применить здравый смысл и метод внимательного взгляда, чтобы собрать внутреннюю статистику и понимать, какие методы работают, какие — нет.
Кластеры с идиллической картиной накануне появления ребенка мы рассмотрели, но прослеживались и другие жизненные истории. Например, в одном из кластеров потенциальные покупатели подгузников для новорожденных с высокой вероятностью (0,65) имеют аккаунт на сайте знакомств. Это не голословное утверждение, они оплачивают услуги на таких сайтах.
Чтобы инсайты «работали», всегда приходится интерпретировать новые знания, но в этот раз мне совсем не хочется искать подноготную – о социальном неблагополучии и бытовой неустроенности жизни в нашей стране и так всем известно.

Напомню, что в рамках этого кейса мы исследовали всю аудиторию, которая была заинтересована в покупке подгузников для новорожденных. И это оказались не только женщины на третьем триместре беременности.
Отдельный кластер я назвала «Воскресными папами» – его представители являются футбольными фанатами, заядлыми автолюбителями, приобретают комплектующие для автомобилей Sparco и время от времени покупают товары Chupa Chups.
А теперь внимание, вопрос: стоит ли удалять «воскресных пап», если они не относятся к первоначально обозначенной целевой аудитории? Подобный вопрос я часто задаю своим менеджерам проекта, и происходит переосмысление задачи. Быть может, нам на самом деле нужна не определенная целевая аудитория, а все, кто может стать покупателями товара. В нашем случае это и папы, и бабушки-дедушки, и братья-сестры, и подруги роженицы, готовые позаботиться о малыше. Ответ, какую аудиторию считать целевой, – за представителями бизнеса.
Кейс «Индивидуальные предприниматели»

Следующий кейс, о котором я расскажу, – Audience Research для целевой аудитории «Индивидуальные предприниматели», открывшие расчетный счет в известном банке.
Основные отличия этих людей от аудитории биржи отлично прослеживаются по их покупкам. Самое очевидное – оплата роялти (10-15% профилей), услуг охраны и жилищно-коммунальные платежи за нежилые помещения. Среди косвенных признаков, указывающих на предпринимателей, – покупка дополнительного места багажа при перелетах (в 15-20% случаев). Во всем объеме чеков значительную часть составляют книги по психологии, самопознанию и саморазвитию, практикумы по общению с подчиненными и коучинговая литература.
С помощью LaL feature importance мы получили косвенные признаки ЦА: авиаперевозки, покупка робота-пылесоса, кофемашины, смартфона Honor, доставка цветов, оплата страховых премий. Этот кейс один из тех прекрасных случаев, когда машины нам дают легко интерпретируемый результат.
Роботы-пылесосы домой покупают занятые люди. Без кофемашин не обходится ни один офис. Доставку цветов и частые перелеты тоже можно связать =).
Кейс «Автовладельцы»
Известный автобренд в ценовом сегменте «выше среднего» был абсолютно убежден, что его клиенты совершенно исключительные люди и хотел узнать их привычки и предпочтения.
Данная целевая аудитория существенно пересекается с предыдущим кейсом (»Индивидуальные предприниматели»). Но не все ИП покупают эту марку машины.

Оказалось, что представления заказчика об уникальности клиентов сильно преувеличены. Да, аудитория не совпадает со средней, но только в каких-то деталях, например, автолюбители предпочитают покупать элитный чай (дороже на 300 руб.) и вообще больше тратят на красивое и эстетичное, чем на функциональное и практичное.
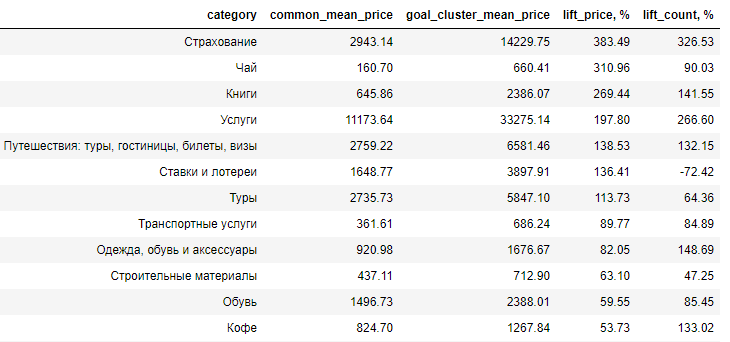
Здесь представлено различие целевой аудитории и средней аудитории покупателей в терминах lift, то есть на сколько процентов средняя цена на товар в изучаемой аудитории превосходит ту же величину в средней аудитории (lift_price). Как видно, основные траты приходятся на удовольствия.
Мы всегда честно и беспристрастно проверяем гипотезы. Вполне ожидаемо, что иногда гипотеза заказчика об исключительности его аудитории не подтверждается полученными данными. В этом нет ничего страшного, просто нужна новая гипотеза и новое исследование.

В заключение скажу, что в своей работе я руководствуюсь принципом «Рутина успокаивает». И вам советую.
При таких разнообразных данных обязательно нужно быть очень аккуратным и внимательным к мелочам, так как любое на первый взгляд исключение может впоследствии оказаться правилом и мы можем получить много ошибочных результатов.
Так, если бы я не увидела, что моя модель «без выпечки» относит к «выпечке», в продакшн ушла бы «дырявая» система. Так что не пренебрегайте рутиной: если потратить полчаса на проверку глазами, можно спать спокойно – модель не будет ошибаться.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}