Windows Azure предлагает как NoSQL хранилища, так и SQL-реляционные хранилища. NoSQL хранилища – это, например, Windows Azure Tables (ключ\значение) или BLOB-объекты (двоичные данные такие, как фото, видео, документы и т.п.). К реляционным хранилищам относится SQL Database (ранее SQL Azure).
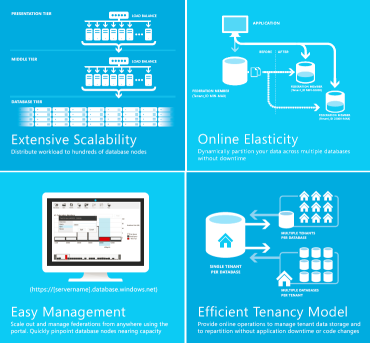
Пост подготовлен на основе статьи Inside Windows Azure SQL Database, которую решила разбить на две части. В первой части приведу информацию об архитектуре SQL Database и о том, как обеспечивается высокая доступность (обнаружение сбоев, реконфигурация). Во второй части расскажу о масштабируемости (регулирование производительности, балансировка нагрузки), а так же приведу рекомендации для разработчиков.
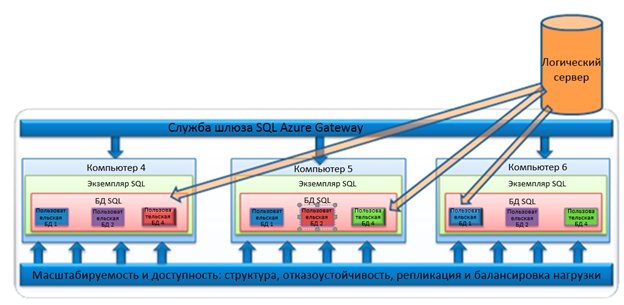
SQL Database – это разделяемая облачная база данных, можно сказать, что это Database as Service (DaaS). В ЦОДах Microsoft установлены серверы SQL Server большой емкости, построенные на основе стандартного оборудования. Каждый SQL Server в ЦОДе содержит несколько различных клиентских баз данных (логические базы), т.е. получается shared режим. Для доступа к данным используется автоматическая балансировка нагрузки и маршрутизация сетевых соединений.
Стоит отметить, что физически или фактически данные сохраняются не в одной базе, а реплицируются. Данные реплицируются в трех базах данных SQL Server, распределенных по трем физическим серверам одного ЦОДа: одна основная и две дополнительные реплики. Все операции чтения и записи выполняются в основной реплике, а любые изменения асинхронно реплицируются на дополнительные реплики. Эти реплики обеспечивают высокую доступность баз данных SQL Database. Большинство ЦОДов Microsoft содержат сотни компьютеров с сотнями экземпляров SQL Server, на которых размещены реплики SQL Database. Крайне низка вероятность того, что основные и дополнительные реплики баз данных SQL Database будут хранится на одних и тех же компьютерах.
Логический сервер – это SQL Database сервер, который вы видите на веб-портале управления Windows Azure. Служба шлюза SQL Database Gateway выполняет функции прокси-сервера, перенаправляя на логический сервер запросы потока табличных данных (Tabular Data Stream, TDS). SQL Database Gateway является границей системы безопасности и обеспечивает проверку учетных данных, соблюдение правил брандмауэра и защиту расположенных за шлюзом экземпляров SQL Server против атак типа «отказ в обслуживании». Шлюз состоит из множества компьютеров, каждый из которых принимает запросы на сетевые подключения от клиентов, проверяет информацию о соединении и передает запрос потока табличных данных соответствующему физическому серверу, в зависимости от имени базы данных, указанного в соединении.
Физическое распределение баз данных, входящих в состав одного и того же логического экземпляра SQL Server, означает, что каждое сетевое соединение привязано к одной базе данных, а не к одному экземпляру SQL Server. Если бы для подключения использовалась команда USE, поток табличных данных пришлось бы перенаправить на совершенно другой физический компьютер в центре обработки данных. По этой причине команда USE не поддерживается для соединений SQL Database.
Приложение использует уровень клиента для прямого обмена данными с SQL Database. Уровень клиента может располагаться в локальном центре обработке данных или размещаться в Windows Azure. Поддерживаются все протоколы, создающие потоки табличных данных для передачи по сети. Можно применять привычные инструменты и библиотеки для создания клиентских приложений, использующих данные в облаке.
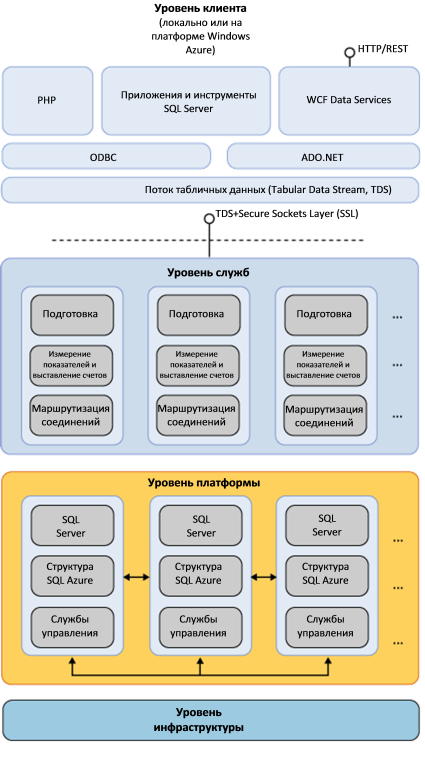
Уровень служб состоит из компьютеров, на которых размещены службы шлюзов, обеспечивающие маршрутизацию, выделение ресурсов, измерение показателей и выставление счетов. Эти службы поддерживаются четырьмя группами компьютеров.
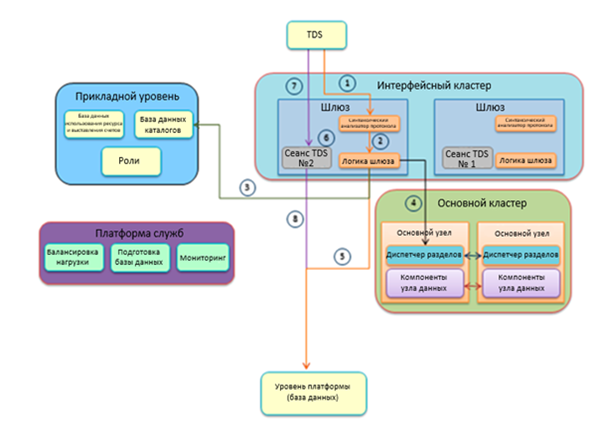
Интерфейсный кластер содержит физические компьютеры шлюза. Компьютеры прикладного уровня авторизуют запросы к серверу и к базе данных, а также управляют выставлением счетов. Компьютеры служебной платформы осуществляют мониторинг работоспособности экземпляров SQL Server в ЦОД и управляют ими. Компьютеры основного кластера отслеживают, какие реплики каких именно баз данных физически существуют в каждом экземпляре SQL Server в ЦОД.
Пронумерованные линии рабочих процессов на рисунке отражают процедуру проверки и создания клиентского соединения:
Уровень платформы состоит из компьютеров, на которых размещены физические базы данных SQL Server в ЦОД. Эти компьютеры называются узлами данных. На рисунке изображена внутренняя организация узлов данных. Каждый узел данных состоит из одного экземпляра сервера SQL Server. Каждый из этих экземпляров имеет одну пользовательскую базу данных, разбитую на разделы. Каждый раздел содержит одну клиентскую базу данных SQL Database, представленную в виде основной или дополнительной реплики.
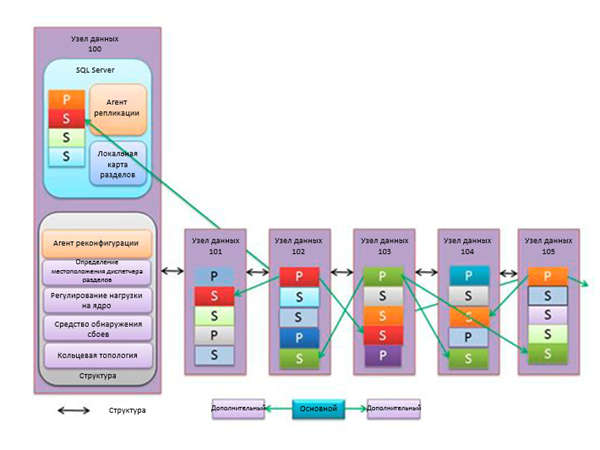
База данных SQL Server типового узла данных может содержать до 650 разделов. Эти базы данных, размещенные в ЦОД, управляются так же, как локальные базы данных SQL Server. Разница лишь в том, что регулярное техническое обслуживание и резервное копирование выполняются специалистами центра обработки данных. Все базы данных, размещенные на узле данных, используют один и тот же файл журнала. Это повышает производительность ведения журнала с помощью последовательных групповых операций ввода-вывода. В отличие от локальных баз данных, журналы баз данных SQL Database хранятся в предварительно выделенном и обнуленном дисковом пространстве. Это позволяет избежать пауз записи при автоматическом увеличении размера файлов журнала.
Еще одним отличием управления журналами в центре обработки данных SQL Database является необходимость кворумной фиксации. Это означает, что основная реплика и как минимум одна из дополнительных реплик должны подтвердить факт записи файлов журнала, прежде чем транзакция будет считаться зафиксированной.
На рисунке показано, что каждый из компьютеров узла данных содержит набор процессов, также называемых структурой. Процессы структуры служат для решения следующих задач:
Платформа Microsoft SQL Database обеспечивает доступность баз данных подписчиков на уровне 99,9%. Это достигается благодаря использованию потребительского оборудования, которое допускает простую и быструю замену в случае отказа компьютера или накопителя, а также за счет управления репликами каждой из баз данных SQL Database (поддерживаются одна основная и две дополнительные реплики).
Необходимо выявлять не только случаи полного отказа компьютеров, но и тенденции медленного снижения производительности компьютеров и нарушения обмена данными с ними. Изложенная выше концепция кворумной фиксации позволяет решать эти проблемы. Во-первых, транзакция не считается зафиксированной, если основная реплика и по крайней мере одна дополнительная реплика не подтверждают запись транзакции в журнал. Во-вторых, если основная и дополнительная реплика подтверждают успешную запись, могут быть обнаружены небольшие сбои, не препятствующие фиксации транзакции, но способные привести к серьезным проблемам.
Процедура замены поврежденных реплик называется реконфигурацией. Реконфигурация может потребоваться при аппаратных сбоях или аварийном завершении работы операционной системы, а также в случае возникновения неполадок экземпляра SQL Server. Реконфигурация также используется при обновлении операционной системы, сервера SQL Server или платформы SQL Database.
Отслеживание работоспособности каждого узла выполняется шестью аналогичными узлами, размещенных в разных стойках. Эти узлы называются соседями. Сбой фиксируется одним из соседей отказавшего узла. Для каждой базы данных, которая хранила реплику на сбойном узле, выполняется процедура реконфигурации. Каждый компьютер содержит реплики сотен баз данных SQL Database, некоторые из которых являются основными, а некоторые — дополнительными. Поэтому в случае отказа узла выполняются сотни операций реконфигурации. При обработке сотен ошибок, вызванных отказом узла, приоритизация не используется. Диспетчер разделов случайным образом выбирает реплику для обработки, после завершения операций над ней выбирает следующую, и так до тех пор, пока не будут обработаны все реплики с отказавшего узла.
Если узел отключается по причине перезагрузки, это считается чистым сбоем, поскольку соседи узла получают сообщение об исключительной ситуации.
Другим возможным вариантом является прекращение обмена данными с компьютером по неизвестной причине, когда фиксируется неопределенная ошибка. В этом случае применяется процедура арбитража, позволяющая достоверно определить факт отказа узла.
Кроме определения отказа отдельной реплики, система выявляет и устраняет последствия отказов целых узлов. Узел состоит из целого экземпляра SQL Server с несколькими разделами, содержащими реплики до 650 различных баз данных. Одни реплики являются основными, другие — дополнительными. В случае отказа узла над каждой из затронутых баз данных выполняется описанная ранее процедура. Для некоторых баз с отказавшими основными репликами процесс арбитража выбирает новую основную реплику из существующих дополнительных реплик, а для других баз данных с отказавшими дополнительными репликами создается новая дополнительная реплика.
Большинство реплик базы данных SQL Database должно подтверждать фиксацию. В настоящее время пользовательские базы данных поддерживают три реплики. Поэтому кворумная фиксация реплики требует подтверждения транзакции двумя другими репликами. Хранилище метаданных, входящее в состав компонентов шлюза ЦОД, поддерживает пять реплик. Ему требуются три подтверждения для проведения кворумной фиксации. Основному кластеру, который поддерживает семь реплик, необходимо подтверждение четырех из них для фиксации транзакции. Информация основного кластера может быть восстановлена даже в случае отказа всех семи реплик. Существуют механизмы автоматизированного восстановления основного кластера при столь масштабных отказах.
Отказ основной реплики
Все операции чтения и записи сначала выполняются в основной реплике. Поэтому отказ основной реплики выявляется незамедлительно и препятствует дальнейшему выполнению работы. При переконфигурации в случае отказа основной реплики диспетчер разделов выбирает одну из дополнительных реплик и назначает ее основной. Как правило, в качестве новой основной реплики выбирается дополнительная реплика на узле с наименьшей рабочей нагрузкой. Процедура присвоения дополнительной реплике статуса основной не вызывает простоя базы данных и не заметна для большинства пользователей. Шлюз передаст клиентскому приложению сообщение об отключении, после чего приложение должно незамедлительно выполнить попытку повторного подключения. Распространение информации о новой основной реплике по всем серверам шлюза может занять до 30 секунд. Поэтому рекомендуется попробовать подключиться повторно несколько раз, делая небольшие паузы после каждой неудачной попытки.
Отказ дополнительной реплики
При отказе дополнительной реплики у базы данных остается только две реплики для кворумной фиксации. Процедура реконфигурации схожа с процедурой, которая выполняется после отказа основной реплики, когда статус одной из дополнительных реплик повышается до основной. В обоих случаях остается только одна дополнительная реплика. После короткого ожидания диспетчер разделов пытается определить, носит ли этот отказ постоянный характер, чтобы создать новую дополнительную реплику.
В некоторых случаях, например при отказе или обновлении операционной системы, отказ дополнительной реплики может иметь кажущийся характер. Неработоспособность дополнительной реплики на отказавшем узле может быть всего лишь временной. Поэтому мгновенного создания новой реплики не происходит. Если дополнительная реплика возвращается в рабочее состояние, выполняются команды проверки данных (checkdisk и т. п.) для подтверждения работоспособности реплики.
Если реплика остается в нерабочем состоянии в течение более двух часов, диспетчер разделов приступает к созданию новой реплики для ее замены. В некоторых случаях такое фиксированное время ожидания не является оптимальным решением, например при отказе компьютера по причине невосстановимого аппаратного сбоя. Новые выпуски платформы SQL Database, возможно, будут содержать функции определения различных типов отказов реплик, а также иметь возможность более оперативного устранения последствий невосстановимых сбоев.
Если произошел невосстановимый сбой узла, то для создания новой дополнительной реплики выбирается один из компьютеров кластера, имеющий достаточное место на диске и запас производительности процессора. Этот компьютер используется для размещения новой дополнительной реплики. База данных копируется из основной реплики, затем эта копия подключается к существующей конфигурации. Время, необходимое для копирования всего содержимого базы данных, служит ограничивающим фактором для максимального размера управляемых баз данных SQL Database.
Все компьютеры в ЦОД представляют собой потребительские вычислительные системы с со средним уровнем производительности и качества комплектующих. На момент написания статьи — 32 ГБ оперативной памяти, восьмиядерным процессор и 12 дисков. Стоимость подобной системы составляла около $3500. Экономичная и доступная конфигурация упрощает быструю замену компьютеров в случае неустранимых сбоев. В среде Windows Azure используется одинаковое потребительское оборудование. Это делает все компьютеры в ЦОДе взаимозаменяемыми, независимо от того, используются они для поддержки SQL Database или Windows Azure.
Итого, распределение реплик баз данных по различным серверам и эффективные алгоритмы присвоения дополнительным репликам статуса основных гарантируют доступность даже при одновременном отказе 15% всех компьютеров ЦОДа. То есть в случае выхода из строя до 15% всех компьютеров уровень поддерживаемой рабочей нагрузки не снизится.
На этом рассказ о SQL Database не заканчивается, будет продолжение (есть продолжение).
PS. Если кому-то понравилась заглавная картинка, то вот ссылка на большой постер.
Пост подготовлен на основе статьи Inside Windows Azure SQL Database, которую решила разбить на две части. В первой части приведу информацию об архитектуре SQL Database и о том, как обеспечивается высокая доступность (обнаружение сбоев, реконфигурация). Во второй части расскажу о масштабируемости (регулирование производительности, балансировка нагрузки), а так же приведу рекомендации для разработчиков.
Обзор архитектуры SQL Database
SQL Database – это разделяемая облачная база данных, можно сказать, что это Database as Service (DaaS). В ЦОДах Microsoft установлены серверы SQL Server большой емкости, построенные на основе стандартного оборудования. Каждый SQL Server в ЦОДе содержит несколько различных клиентских баз данных (логические базы), т.е. получается shared режим. Для доступа к данным используется автоматическая балансировка нагрузки и маршрутизация сетевых соединений.
Стоит отметить, что физически или фактически данные сохраняются не в одной базе, а реплицируются. Данные реплицируются в трех базах данных SQL Server, распределенных по трем физическим серверам одного ЦОДа: одна основная и две дополнительные реплики. Все операции чтения и записи выполняются в основной реплике, а любые изменения асинхронно реплицируются на дополнительные реплики. Эти реплики обеспечивают высокую доступность баз данных SQL Database. Большинство ЦОДов Microsoft содержат сотни компьютеров с сотнями экземпляров SQL Server, на которых размещены реплики SQL Database. Крайне низка вероятность того, что основные и дополнительные реплики баз данных SQL Database будут хранится на одних и тех же компьютерах.
Логический сервер – это SQL Database сервер, который вы видите на веб-портале управления Windows Azure. Служба шлюза SQL Database Gateway выполняет функции прокси-сервера, перенаправляя на логический сервер запросы потока табличных данных (Tabular Data Stream, TDS). SQL Database Gateway является границей системы безопасности и обеспечивает проверку учетных данных, соблюдение правил брандмауэра и защиту расположенных за шлюзом экземпляров SQL Server против атак типа «отказ в обслуживании». Шлюз состоит из множества компьютеров, каждый из которых принимает запросы на сетевые подключения от клиентов, проверяет информацию о соединении и передает запрос потока табличных данных соответствующему физическому серверу, в зависимости от имени базы данных, указанного в соединении.

Физическое распределение баз данных, входящих в состав одного и того же логического экземпляра SQL Server, означает, что каждое сетевое соединение привязано к одной базе данных, а не к одному экземпляру SQL Server. Если бы для подключения использовалась команда USE, поток табличных данных пришлось бы перенаправить на совершенно другой физический компьютер в центре обработки данных. По этой причине команда USE не поддерживается для соединений SQL Database.
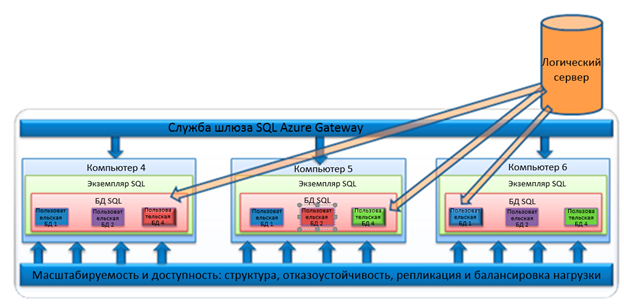
Сетевая топология
Приложение использует уровень клиента для прямого обмена данными с SQL Database. Уровень клиента может располагаться в локальном центре обработке данных или размещаться в Windows Azure. Поддерживаются все протоколы, создающие потоки табличных данных для передачи по сети. Можно применять привычные инструменты и библиотеки для создания клиентских приложений, использующих данные в облаке.
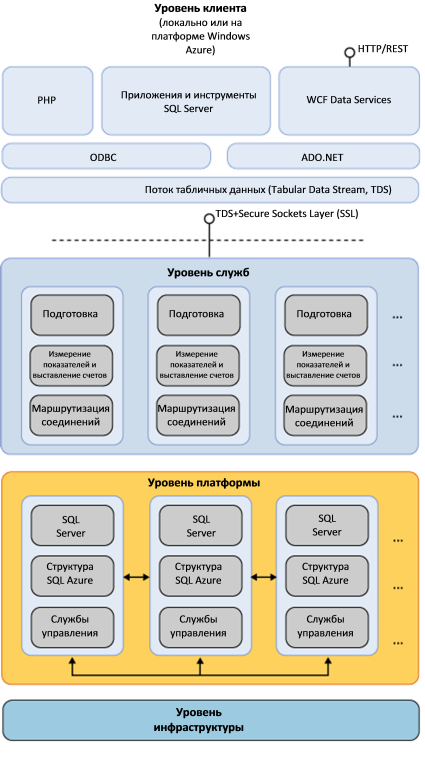
Уровень служб
Уровень служб состоит из компьютеров, на которых размещены службы шлюзов, обеспечивающие маршрутизацию, выделение ресурсов, измерение показателей и выставление счетов. Эти службы поддерживаются четырьмя группами компьютеров.
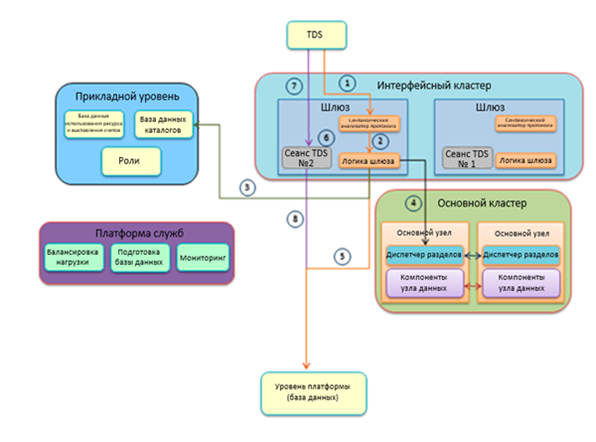
Интерфейсный кластер содержит физические компьютеры шлюза. Компьютеры прикладного уровня авторизуют запросы к серверу и к базе данных, а также управляют выставлением счетов. Компьютеры служебной платформы осуществляют мониторинг работоспособности экземпляров SQL Server в ЦОД и управляют ими. Компьютеры основного кластера отслеживают, какие реплики каких именно баз данных физически существуют в каждом экземпляре SQL Server в ЦОД.
Пронумерованные линии рабочих процессов на рисунке отражают процедуру проверки и создания клиентского соединения:
- Шлюз в интерфейсном кластере, получивший запрос на новое входящее соединение для передачи потока табличных данных (TDS), может установить соединение с клиентом. Синтаксический анализатор с минимальным набором поддерживаемых функций проверяет допустимость полученной команды для передачи базе данных. Команды типа CREATE DATABASE недопустимы, так как должны обрабатываться прикладным уровнем.
- Шлюз выполняет процедуру подтверждения SSL для клиента. Если клиент отказывается использовать протокол SSL, шлюз разрывает соединение. Необходимо обеспечивать полное шифрование трафика. Синтаксический анализатор протокола также содержит средство защиты от атак типа «Отказ в обслуживании», отслеживающее запросы с IP-адресов. Если с IP-адреса или диапазона адресов приходит чрезмерное количество запросов, то последующие попытки соединения с этих адресов будут отклонены.
- Указанные пользователем имя сервера и учетные данные для входа должны быть проверены. Проверка на уровне брандмауэра обеспечивает соединение только с IP-адресами из заданных диапазонов.
- После проверки сервера основной кластер сопоставляет используемое клиентом имя базы данных с внутренним именем базы данных. Основной кластер — это набор компьютеров, обрабатывающих сведения о сопоставлении. При работе в SQL Database понятие раздел имеет совершенно иной смысл, чем при работе с локальными экземплярами SQL Server. В среде SQL Database раздел является частью базы данных SQL Server в ЦОД, которая сопоставляется с одной базой данных SQL Database. Например, на рисунке каждая база данных содержит три раздела, поскольку в каждой из них размещены по три базы данных SQL Database.
- После обнаружения базы данных выполняется проверка подлинности имени пользователя; если проверка завершается ошибкой, соединение разрывается. Шлюз проверяет наличие базы данных, к которой хочет подключиться пользователь.
- Новое подключение может быть выполнено после проверки всех параметров соединения.
- Новое соединение устанавливается непосредственно между компьютером пользователя и внутренним серверным узлом.
- После установления соединения шлюз выступает в качестве прокси-сервера для пакетов, передаваемых между клиентом и платформой обработки данных.
Уровень платформы
Уровень платформы состоит из компьютеров, на которых размещены физические базы данных SQL Server в ЦОД. Эти компьютеры называются узлами данных. На рисунке изображена внутренняя организация узлов данных. Каждый узел данных состоит из одного экземпляра сервера SQL Server. Каждый из этих экземпляров имеет одну пользовательскую базу данных, разбитую на разделы. Каждый раздел содержит одну клиентскую базу данных SQL Database, представленную в виде основной или дополнительной реплики.
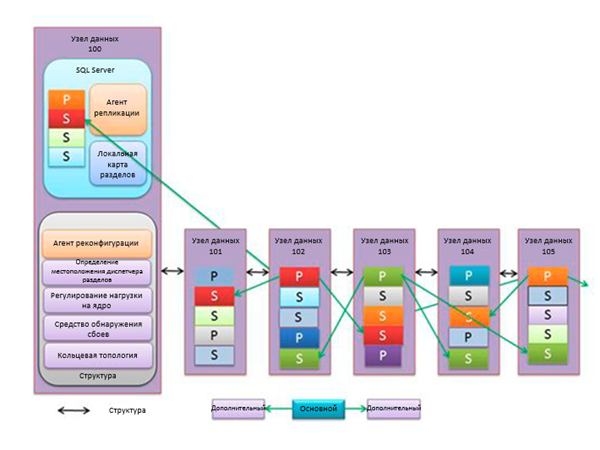
База данных SQL Server типового узла данных может содержать до 650 разделов. Эти базы данных, размещенные в ЦОД, управляются так же, как локальные базы данных SQL Server. Разница лишь в том, что регулярное техническое обслуживание и резервное копирование выполняются специалистами центра обработки данных. Все базы данных, размещенные на узле данных, используют один и тот же файл журнала. Это повышает производительность ведения журнала с помощью последовательных групповых операций ввода-вывода. В отличие от локальных баз данных, журналы баз данных SQL Database хранятся в предварительно выделенном и обнуленном дисковом пространстве. Это позволяет избежать пауз записи при автоматическом увеличении размера файлов журнала.
Еще одним отличием управления журналами в центре обработки данных SQL Database является необходимость кворумной фиксации. Это означает, что основная реплика и как минимум одна из дополнительных реплик должны подтвердить факт записи файлов журнала, прежде чем транзакция будет считаться зафиксированной.
На рисунке показано, что каждый из компьютеров узла данных содержит набор процессов, также называемых структурой. Процессы структуры служат для решения следующих задач:
- Обнаружение сбоев: контроль доступности основных или дополнительных реплик; если они становятся недоступными, может быть запущен агент реконфигурации.
- Агент реконфигурации: управляет повторным созданием основных или дополнительных реплик после сбоя узла.
- Определение местоположения диспетчера разделов: обеспечивает отправку сообщений для диспетчера разделов.
- Регулирование нагрузки на ядро: препятствует монопольному использованию логическим сервером ресурсов узла или превышению его физических ограничений.
- Кольцевая топология: управляет объединенными в логическое кольцо компьютерами кластера; каждый компьютер имеет двух соседей, способных обнаружить его аварийное отключение.
Обеспечение высокой доступности в SQL Database
Платформа Microsoft SQL Database обеспечивает доступность баз данных подписчиков на уровне 99,9%. Это достигается благодаря использованию потребительского оборудования, которое допускает простую и быструю замену в случае отказа компьютера или накопителя, а также за счет управления репликами каждой из баз данных SQL Database (поддерживаются одна основная и две дополнительные реплики).
Обнаружение сбоев
Необходимо выявлять не только случаи полного отказа компьютеров, но и тенденции медленного снижения производительности компьютеров и нарушения обмена данными с ними. Изложенная выше концепция кворумной фиксации позволяет решать эти проблемы. Во-первых, транзакция не считается зафиксированной, если основная реплика и по крайней мере одна дополнительная реплика не подтверждают запись транзакции в журнал. Во-вторых, если основная и дополнительная реплика подтверждают успешную запись, могут быть обнаружены небольшие сбои, не препятствующие фиксации транзакции, но способные привести к серьезным проблемам.
Реконфигурация
Процедура замены поврежденных реплик называется реконфигурацией. Реконфигурация может потребоваться при аппаратных сбоях или аварийном завершении работы операционной системы, а также в случае возникновения неполадок экземпляра SQL Server. Реконфигурация также используется при обновлении операционной системы, сервера SQL Server или платформы SQL Database.
Отслеживание работоспособности каждого узла выполняется шестью аналогичными узлами, размещенных в разных стойках. Эти узлы называются соседями. Сбой фиксируется одним из соседей отказавшего узла. Для каждой базы данных, которая хранила реплику на сбойном узле, выполняется процедура реконфигурации. Каждый компьютер содержит реплики сотен баз данных SQL Database, некоторые из которых являются основными, а некоторые — дополнительными. Поэтому в случае отказа узла выполняются сотни операций реконфигурации. При обработке сотен ошибок, вызванных отказом узла, приоритизация не используется. Диспетчер разделов случайным образом выбирает реплику для обработки, после завершения операций над ней выбирает следующую, и так до тех пор, пока не будут обработаны все реплики с отказавшего узла.
Если узел отключается по причине перезагрузки, это считается чистым сбоем, поскольку соседи узла получают сообщение об исключительной ситуации.
Другим возможным вариантом является прекращение обмена данными с компьютером по неизвестной причине, когда фиксируется неопределенная ошибка. В этом случае применяется процедура арбитража, позволяющая достоверно определить факт отказа узла.
Кроме определения отказа отдельной реплики, система выявляет и устраняет последствия отказов целых узлов. Узел состоит из целого экземпляра SQL Server с несколькими разделами, содержащими реплики до 650 различных баз данных. Одни реплики являются основными, другие — дополнительными. В случае отказа узла над каждой из затронутых баз данных выполняется описанная ранее процедура. Для некоторых баз с отказавшими основными репликами процесс арбитража выбирает новую основную реплику из существующих дополнительных реплик, а для других баз данных с отказавшими дополнительными репликами создается новая дополнительная реплика.
Большинство реплик базы данных SQL Database должно подтверждать фиксацию. В настоящее время пользовательские базы данных поддерживают три реплики. Поэтому кворумная фиксация реплики требует подтверждения транзакции двумя другими репликами. Хранилище метаданных, входящее в состав компонентов шлюза ЦОД, поддерживает пять реплик. Ему требуются три подтверждения для проведения кворумной фиксации. Основному кластеру, который поддерживает семь реплик, необходимо подтверждение четырех из них для фиксации транзакции. Информация основного кластера может быть восстановлена даже в случае отказа всех семи реплик. Существуют механизмы автоматизированного восстановления основного кластера при столь масштабных отказах.
Отказ основной реплики
Все операции чтения и записи сначала выполняются в основной реплике. Поэтому отказ основной реплики выявляется незамедлительно и препятствует дальнейшему выполнению работы. При переконфигурации в случае отказа основной реплики диспетчер разделов выбирает одну из дополнительных реплик и назначает ее основной. Как правило, в качестве новой основной реплики выбирается дополнительная реплика на узле с наименьшей рабочей нагрузкой. Процедура присвоения дополнительной реплике статуса основной не вызывает простоя базы данных и не заметна для большинства пользователей. Шлюз передаст клиентскому приложению сообщение об отключении, после чего приложение должно незамедлительно выполнить попытку повторного подключения. Распространение информации о новой основной реплике по всем серверам шлюза может занять до 30 секунд. Поэтому рекомендуется попробовать подключиться повторно несколько раз, делая небольшие паузы после каждой неудачной попытки.
Отказ дополнительной реплики
При отказе дополнительной реплики у базы данных остается только две реплики для кворумной фиксации. Процедура реконфигурации схожа с процедурой, которая выполняется после отказа основной реплики, когда статус одной из дополнительных реплик повышается до основной. В обоих случаях остается только одна дополнительная реплика. После короткого ожидания диспетчер разделов пытается определить, носит ли этот отказ постоянный характер, чтобы создать новую дополнительную реплику.
В некоторых случаях, например при отказе или обновлении операционной системы, отказ дополнительной реплики может иметь кажущийся характер. Неработоспособность дополнительной реплики на отказавшем узле может быть всего лишь временной. Поэтому мгновенного создания новой реплики не происходит. Если дополнительная реплика возвращается в рабочее состояние, выполняются команды проверки данных (checkdisk и т. п.) для подтверждения работоспособности реплики.
Если реплика остается в нерабочем состоянии в течение более двух часов, диспетчер разделов приступает к созданию новой реплики для ее замены. В некоторых случаях такое фиксированное время ожидания не является оптимальным решением, например при отказе компьютера по причине невосстановимого аппаратного сбоя. Новые выпуски платформы SQL Database, возможно, будут содержать функции определения различных типов отказов реплик, а также иметь возможность более оперативного устранения последствий невосстановимых сбоев.
Если произошел невосстановимый сбой узла, то для создания новой дополнительной реплики выбирается один из компьютеров кластера, имеющий достаточное место на диске и запас производительности процессора. Этот компьютер используется для размещения новой дополнительной реплики. База данных копируется из основной реплики, затем эта копия подключается к существующей конфигурации. Время, необходимое для копирования всего содержимого базы данных, служит ограничивающим фактором для максимального размера управляемых баз данных SQL Database.
Все компьютеры в ЦОД представляют собой потребительские вычислительные системы с со средним уровнем производительности и качества комплектующих. На момент написания статьи — 32 ГБ оперативной памяти, восьмиядерным процессор и 12 дисков. Стоимость подобной системы составляла около $3500. Экономичная и доступная конфигурация упрощает быструю замену компьютеров в случае неустранимых сбоев. В среде Windows Azure используется одинаковое потребительское оборудование. Это делает все компьютеры в ЦОДе взаимозаменяемыми, независимо от того, используются они для поддержки SQL Database или Windows Azure.
Итого, распределение реплик баз данных по различным серверам и эффективные алгоритмы присвоения дополнительным репликам статуса основных гарантируют доступность даже при одновременном отказе 15% всех компьютеров ЦОДа. То есть в случае выхода из строя до 15% всех компьютеров уровень поддерживаемой рабочей нагрузки не снизится.
На этом рассказ о SQL Database не заканчивается, будет продолжение (есть продолжение).
PS. Если кому-то понравилась заглавная картинка, то вот ссылка на большой постер.
