Когда я только пришла в Naumen, не знала, что такое файловые хранилища и как с ними работать. Однако первые мои задачи были связаны именно с этим, поэтому пришлось разобраться, что это такое, и как файлы хранятся в системе.
Благодаря осознанной эволюции хранения файлов, у нас есть решение, где мы не потеряем файлы и не упадем под нагрузками. Поделюсь базой, чтобы вы разобрались с файлами, и могли использовать файловые хранилища в работе или своих проектах.

Мария Аменд
Разработчик в Naumen
Когда дело касается файлов, первое, что приходит в голову — это сохранять их в базе данных. При маленьких размерах файлов и небольшом количестве — это хорошее решение. Однако когда файлы начинают расти, а их количество увеличивается, наша БД начинает разбухать. Возникает три основные проблемы:
Занимаем много места на сервере, где находится БД;
БД долго обрабатывает запросы;
Время создания бэкапа уходит в бесконечность.
На помощь приходят файловые хранилища. В компании мы называем их ФХ, далее буду указывать сокращенно.
ФХ — это директория на локальном или сетевом диске, где мы храним и получаем файлы.
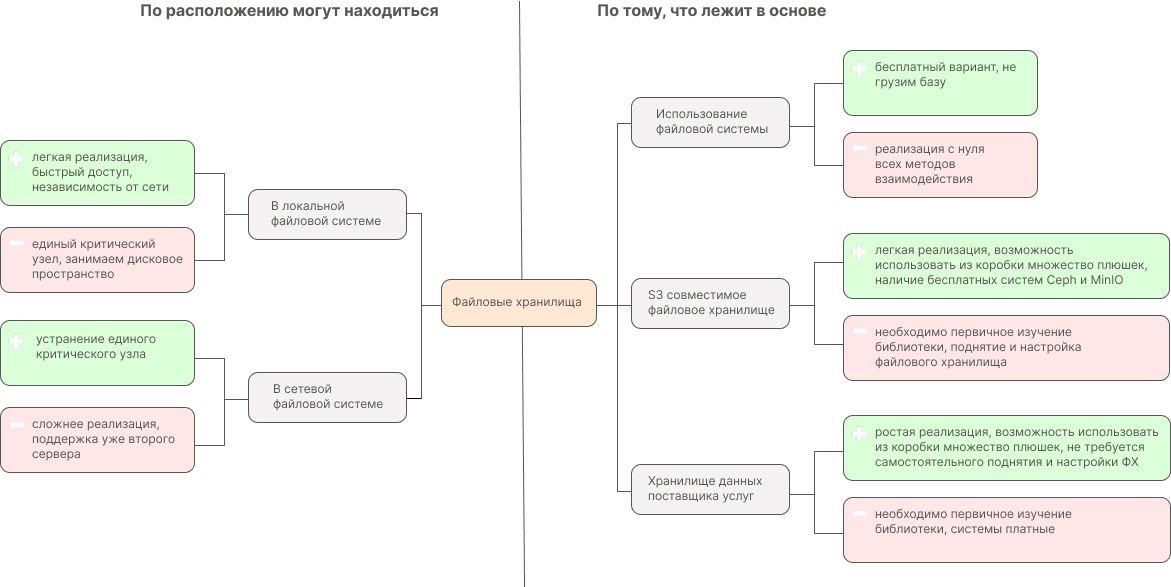
Варианты реализации взаимодействия с файловым хранилищем
Первый вариант
Для примера возьмем ФХ S3 совместимого типа, чтобы не реализовывать все методы взаимодействия и больше внимания уделить реализации.
@Component
public class FileController
{
private final FXOperations fxOperations;
private final FileDao fileDao;
@Inject
public FileController(FXOperations fxOperations, FileDao fileDao)
{
this.fxOperations = fxOperations;
this.fileDao = fileDao;
}
public void save(java.io.File fileForSave) throws FileNotFoundExceptions
{
File file = new File(fileForSave.getName());
fxOperation.save(fileForSave.getName(), new FileInputStream(fileForSave), fileForSave.length());(fileForSave.getName(), new FileInputStream(FileForSave), fileForSave.length());
fileDao.save(file);
}
// get delete
}У нас есть класс FileController, через который мы сохраняем файл, к которому также может обращаться наш фронт. У нас есть сущность File, метод сохранения файлов. Потом мы сохраняем в базу саму сущность файла.
public class File
{
private long id;
private String name;
public File(String Name) { this.name = name; }
//region getter-setter
public long getId() { return id; }
public void setId(long id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
// endregion getter-setter
}File — это указатель на файл в ФХ. По сути, в поле name мы храним полное имя файла, чтобы легко его найти. Эта сущность нужна только для этого.
Также есть FileDao, который сохраняет файл в БД.
@Component
public class FileDao
{
public void save(File obj) { return; }
}Последний важный класс — это FXOperations.
@Component
public class FXOperations
{
private Finall AmazonS3 amazonS3 = AmazonS3ClientBuilder
.standard()
.withCredentials(new AWSStaticCredentialsProvider(
new BasicAWSCredentials("access_key", "secret_key")))
.build();
public void save(String filePath, InputStream content, long size)
{
String bucketName = "default";
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(size);
amazonS3.putObject(bucketName, filePath, content, metadata);
}
//get delete
}У нас ФХ S3 совместимого типа, поэтому я использую уже готовую библиотеку и создаю объект, через который будем обращаться к ФХ, указываю базовые параметры из разряда accessKey, secretKey — как подключиться к ФХ.
Сохранение простое, главное указать все необходимые параметры для ФХ. Это bucketName, путь до файла filePath, content и metadata. Metadata — это небольшая информация в файле, например, там можно сохранить размер файла (size), добавить разрешение и так далее.
Соединим все вместе. Мы создаем объект File, в котором будет храниться, как мы можем получить к нему доступ. Сохраняем файл в ФХ и сохраняем файл в саму БД.
File file = new File(fileForSave.getName());
fxOperation.save(fileForSave.getName(), new FileInputStream(fileForSave), fileForSave.lenght());
fileDao.save(file);Решение рабочее, но возникает проблема — мы можем потерять данные. То есть мы сильно зависим от ФХ: если ФХ недоступно, или у него плохое соединение — мы можем потерять данные. Если мы хотим отдать пользователю информацию, что файл сохранен в хранилище, пользователь будет долго находиться в окне сохранения. Это следует исправить.
Второй вариант реализации
Пользователь сохраняет файл → сначала сохраняем файл в БД → потом в отдельном потоке произведем перемещение из БД в ФХ.
Главное — мы можем отпустить пользователя: файл надежно сохранен в БД. Затем в отдельной задаче мы переместим файл из БД в файловое хранилище и скажем, что теперь все хранится в ФХ, приложение будет обращаться туда.
Так это выглядит в коде.
@Component
public class FileController
{
private final FXOperations fxOperations;
private final FileDao fileDao;
@Inject
public FileController(FXOperations fxOperations, FileDao fileDao)
{
this.fxOperations = fxOperations;
this.fileDao = fileDao;
}
public void save(java.io.File fileForSave) throws FileNotFoundException
{
File file = new File(
fileForSave.getName(),
new FileInputStream(fileForSave),
fileForSave.length(),
false);
fileDao.save(file);
new Thread(() ->
{
fxOperations.save(file);
file.setInputStream(null);
fileDao.save(file);
}).start();
}
}
}У нас есть FileController, он немного видоизменился. В нашу сущность File мы теперь сохраняем не только сам путь до файла и полное имя, но сохраняем content, размер и обозначаем, где сейчас хранится файл — в хранилище или еще в БД. Ну и сохраняем нашу сущность.
В отдельный поток выкидываем саму логику перемещения файла из БД в ФХ. Мы просто вызываем метод сохранения, передавая наш файл. А затем, после успешного перемещения, мы говорим, что файл хранится в ФХ, и у нас в базе нет его контента. И обновляем нашу сущность в БД.
Сам файл немного видоизменился, мы добавили несколько новых полей, которые помогут временно хранить файл в БД. Сама сущность FileDao не изменилась. Изменилась немного FXOperations — теперь мы все данные не принимаем в методе, а получаем из ранее сохраненного файла, все остальное осталось прежним.
public class File
{
private long id;
private String name;
private InputStream inputStream;
private long size;
private boolean isFX;
public File(String name, InputStream inputStream, long size, boolean isFX)
{
this.name = name;
this.InputStream = inputStream;
this.size = size;
this.isFX = isFX;
}
//region getter-setter
public long getId() { return id; }
public String getName() { return name; }
public InputStream getInputStream() { return inputStream; }
}Сама сущность FileDao не изменилась. Изменилась немного FXOperations — теперь мы все данные не принимаем в методе, а получаем из ранее сохраненного файла, все остальное осталось прежним.
@Component
public class FXOperations
{
private final AmazonS3 amazonS3 = AmazonS3ClientBuilder
.standard()
.withCredentials(new AWSStaticCredentialsProvider(
new basicAWSCredentials("access_key", "secret_key")));
.build();
public void save(File file)
{
String filePath = file.getName();
InputStream content = file.getInputStream();
long size = file.getSize();
String bucketName = "default"
final ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(size);
amazonS3.putObject(bucketName, filePath, content, metadata);
}
//get delete
}Мы реализовали логику, но может возникнуть проблема пиковых нагрузок. Если пользователи решат разом сохранить файлы, упадет либо ФХ, либо приложение сильно затормозится, либо все это вместе. Нужно это исправить.
Третий вариант реализации
Пользователь сохраняет файл → мы перемещаем файл в БД и отпускаем пользователя → потом отдельной задачей переместим файл из БД в ФХ. Мы сделаем это в удобное для нас время удобными пачками.
В коде это выглядит так.
@Component
public class FileController
{
private final FileDao fileDao;
@Inject
public FileController(FileDao fileDao) { this.fileDao = fileDao: }
public void save(java.io.File fileForSave) throws FileNotFoundExceptions
{
File file = new File(
fileForSave.getName(),
new FileInputStream(fileForSave),
fileForSave.length(),
false);
fileDao.save(file);
}
// get delete
} У нас есть FileController, оставляем в нем логику по сохранению файла. Здесь ничего не изменилось, наша сущность File имеет такие же поля. Единственное — у нас появился новый класс MoveJob. В данном классе есть задача, которая запускается в этом примере раз в 30 секунд.
@Component
public class MoveJob
{
private final FileDao fileDao;
private final FXOperations fxOperations;
@Inject
public MoveJob(FileDao fileDao, FXOperations fxOperations)
{
this.fileDao = fileDao;
this.fxOperations = dxOperations;
}
@Scheduled(fixedDelay = 30000)
public void move()
{
List<File> files = fileDao.getFiles(10);
for (File file : files)
{
fxOperations.save(file);
file.setFX(true);
file.setInputStream(null);
fileDao.save(file);
}
}
}В FileDao появился новый метод: метод извлечения 10 файлов. Логику опустим, но здесь все достаточно просто — обычный select с параметрами. Получаем 10 файлов, которые перемещаем в ФХ.
Бывают очень важные файлы, к которым нужно всегда иметь доступ. Например, попросить пользователя запросить свой файл чуть позже, если есть проблемы с ФХ, не очень хорошо, но не сильно критично. Другое дело, когда нет доступа к файлам, которые жизненно необходимы системе: файлы для интерфейса, файлы с логикой, конфигурационные файлы. Это желательно держать поближе.
Что мы можем сделать?
Сделать фильтрацию и не перемещать некоторые файлы в хранилище.
Учесть важные файлы при поднятии нашего приложения и скачивать эти файлы рядом.
Хранить все файлы на диске.
В качестве примера приведу, когда мы делаем фильтрацию при переносе. Пользователь скачивает файл → мы размещаем его в БД → переносим в ФХ, но с уточнением, что перенесется не каждый файл. Мы сначала проверим, можно его перенести или нет.
В коде это выглядит так
@Component
public class FileController
{
private final FileDao fileDao;
@Inject
public FileController(FileDao fileDao) { this.fileDao = fileDao; }
public void save(java.io.File fileForSave) throws FileNotFoundException
{
saveFile(fileForSave, false);
}
public void saveSystem(java.io.File fileForSave) throws FileNotFoundException
{
saveFile(fileForSave, true);
}
public void saveFile(java.io.File fileForSave, boolean isSystem) throws FileNotFound
{
File file = new File(
fileForsave.getName(),
new FileInputStream(fileForSave),
fileForSave.length(),
false,
isSystem);
fileDao.save(file);
}
}У нас есть некоторый FileController и есть два метода — save и saveSystem. Если метод save, значит, сохраняем не системный файл, а во втором варианте — системный. Я вынесла логику в отдельный метод, она не изменилась, кроме сохранения дополнительно признака системности файла.
@Component
public class MoveJob implements Runnable
{
private final FileDao fileDao;
private final FXOperations fxOperations;
@Inject
public MoveJob(FileDao fileDao, FXOperations fxOperations)
{
this.fileDao = fileDao;
this.fxOperations = fxOperations;
}
@Override
public void run()
{
List<File> files = fileDao.getFiles(10, false);
for (File file : files)
{
fxOperations.save(file);
file.setFX(true);
file.setInputStream(null);
fileDao.save(file);
}
}
}Сама работа по перемещению также не изменилась. В выборке добавим условия: включай все несистемные файлы. Потом мы пробежимся по ним и перенесем в ФХ.
Есть много возможностей улучшить и дополнить решение, однако в рамках базовой реализации четвертое решение нам подойдет.
Плюшки
Обработка тайм-аута
Если нашему ФХ плохо, не нужно продолжать долбить его, можно взять перерыв и потом продолжить обращаться к нему.
Поддержка нескольких ФХ
Если ФХ хранит очень много файлов, мы переключаемся на дополнительное и продолжаем работать. А из первого получаем файлы, которые уже сохранены. Либо если одному ФХ стало плохо, мы переключаемся на резервное ФХ и работаем с ним, пока разбираемся с основным.
ФХ — полезный инструмент, если у нас в системе много файлов. Мы пришли к варианту, что сохраняем файл сначала в БД, отпускаем пользователя, а в отдельной задаче переносим файл из БД в ФХ, учитывая то, что не все файлы нужно переносить.
