
Есть множество подходов к созданию кода приложений, направленных на то, чтобы сложность проекта не росла со временем. Например, объектно-ориентированный подход и множество прилагаемых паттернов, позволяют если не удерживать сложность проекта на одном уровне, то хотя бы держать ее под контролем в ходе разработки, и делать код доступным для нового программиста в команде.
Как можно управлять сложностью проекта по разработке ETL-трансформаций на Spark?
Тут все не так просто.
Как это выглядит в жизни? Заказчик предлагает создать приложение, собирающее витрину. Вроде бы надо выполнить через Spark SQL код и сохранить результат. В ходе разработки выясняется, что для сборки этой витрины требуется 20 источников данных, из которых 15 похожи, остальные нет. Эти источники надо объединить. Далее выясняется, что для половины из них надо писать собственные процедуры сборки, очистки, нормализации.
И простая витрина после детального описания начинает выглядеть примерно так:
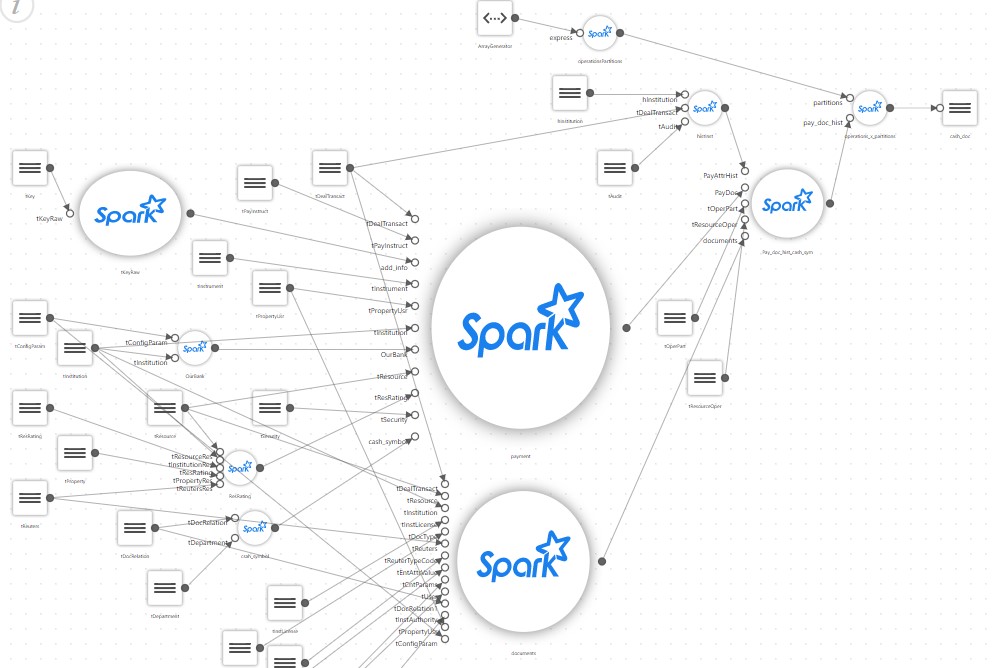
В результате простой проект, который должен был всего лишь запустить на Spark скрипт SQL собирающий витрину, обрастает собственным конфигуратором, блоком чтения большого числа настроечных файлов, собственным ответвлением маппинга, трансляторами каких-нибудь специальных правил и т.д.
К середине проекта оказывается, что получившийся код способен поддерживать только автор. Да и тот основное время проводит в задумчивости. А заказчик тем временем просит собрать еще пару витрин и опять на основе сотни источников. При этом, надо помнить, что Spark вообще не очень подходит для создания собственных фреймворков.
Например, Spark предназначен, чтобы код выглядел как-то так (псевдокод):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)Вместо этого приходится делать что-то такое:
var Source1 = readSourceProps(“source1”)
var sql = readSQL(“destTable”)
writeSparkData(source1, sql)То есть выносить блоки кода в отдельные процедуры и пытаться писать что-то свое, универсальное, что может быть кастомизировано настройками.
При этом сложность проекта остается на одном уровне, конечно же, но только для автора проекта, и только короткое время. Любой приглашенный программист будет долго осваиваться, и главное, что не получится к проекту привлекать людей, знающих только SQL.
А это печально, так как Spark сам по себе прекрасно позволяет разрабатывать ETL-приложения тем, кто знает только SQL.
И в ходе развития проекта получилось так, что из простой вещи сделали сложную.
А теперь представьте реальный проект, где таких витрин, как на картинке, десятки, а то и сотни, и используют они разные технологии, например, часть могут быть основаны на парсинге XML данных, а часть на потоковых данных.
Очень хочется как-то удержать сложность проекта на приемлемом уровне. Как же это сделать?
Решением может стать использование инструмента и подхода low-code, когда за тебя решает среда разработки, которая берет на себя всю сложность, предлагая какой-нибудь удобный подход, как, например, описано в этой статье.
В статье описываются подходы и преимущества применения инструмента для решения такого рода проблем. В частности, «Неофлекс» предлагает собственное решение Neoflex Datagram, который с успехом применяется у разных заказчиков.
Но не всегда можно такое приложение использовать.
Что же делать?
В таком случае мы используем подход, который условно называется Orc – Object Spark, или Orka, кому как нравится.
Исходные данные такие:
Есть заказчик, который предоставляет рабочее место, где есть стандартный набор инструментов, а именно: Hue для разработки Python или Scala-кода, Hue редакторы для отладки SQL через Hive или Impala, а также Oozie workflow Editor. Этого немного, но вполне достаточно для решения задач. Добавить что-то к среде нельзя, никакие новые инструменты поставить невозможно, в силу разных причин.
Так как же разрабатывать ETL-приложения, которые, как обычно, перерастут в большой проект, в котором будут участвовать сотни таблиц источников данных и десятки целевых витрин, и при этом не утонуть в сложности, и не написать лишнего?
Для решения проблемы используется ряд положений. Они не являются собственным изобретением, а целиком основаны на архитектуре самого Spark.
- Все сложные объединения, вычисления и трансформации делаются через Spark SQL. Spark SQL оптимизатор улучшается с каждой версией и работает очень хорошо. Поэтому отдаем всю работу по вычислению Spark SQL оптимизатору. То есть наш код опирается на цепочку SQL, где шаг 1 готовит данные, шаг 2 джойнит, шаг 3 вычисляет и так далее.
- Все промежуточные вычисления сохраняются как временные таблицы в каталоге Spark, в результате чего они становятся доступны в Spark SQL. Любой промежуточный источник данных (DataFrame) можно сохранять в текущей сессии и дальше обращаться к нему через Spark SQL.
- Поскольку Spark приложение выполняется как Directed Acicled Graph, то есть выполнение идет сверху вниз без всяких циклов, то любой датасет, сохраненный как временная таблица, допустим, на шаге 2, доступен на любом этапе после шага 2.
- Все операции в Spark это lazy, то есть данные подгружаются только тогда, когда они нужны, поэтому регистрация датасетов как временных таблиц на производительность не влияет.
В результате всё приложение можно сделать очень простым.
Достаточно сделать файл конфигурации, в котором определить одноуровневый список источников данных. Этот последовательный список источников данных и есть object, описывающий логику всего приложения.
Каждый источник данных содержит ссылку на SQL. В SQL для текущего источника можно использовать источник, отсутствующий в Hive, но описанный в файле конфигурации выше текущего.
Например, источник 2, если переложить его в код на Spark, выглядит примерно так (псевдокод):
var df = spark.sql(“select * from t1”);
df.saveAsTempTable(“source2”);А источник 3 уже может выглядеть так:
var df = spark.sql(“select count(*) from source2”)
df.saveAsTempTable(“source3”);То есть источник 3 видит все, что было вычислено до него.
А для тех источников, что являются целевыми витринами, надо указать параметры сохранения этой целевой витрины.
В результате примерно так выглядит файл конфигурации приложения:
[{name: “source1”, sql: “select * from t1”},
{name: “source2”, sql: “select count(*) from source1”},
...
{name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]А код приложения выглядит примерно так:
List = readCfg(...)
For each source in List:
df = spark.sql(source.sql).saveAsTempTable(source.name)
If(source.target == true) {
df.write(“format”, source.format).save(source.path)
}Это, собственно, и всё приложение. Больше ничего не требуется, кроме одного момента.
А как это все отлаживать?
Ведь сам код в данном случае очень простой, что там отлаживать, а вот логику того, что делается, неплохо бы проверить. Отладка очень простая — надо пройти все приложения до проверяемого источника. Для этого в Oozie workflow надо добавить параметр, который позволяет остановить приложение на требуемом источнике данных, распечатав в лог его схему и содержимое.
Мы назвали этот подход Object Spark, в том смысле, что вся логика приложения отвязана от Spark кода и сохранена в одном, довольно простом файле конфигурации, который и является объектом-описанием приложения.
Код остается простым, и после его создания можно разрабатывать даже сложные витрины, привлекая программистов всего лишь знающих SQL.
Процесс разработки получается очень простой. В начале привлекается опытный Spark программист, создающий универсальный код, а потом правится файл конфигурации приложения путем добавления туда новых источников.
Что дает такой подход:
- Можно привлекать к разработке SQL-программистов;
- С учетом параметра в Oozie отлаживать такое приложение становится легко и просто. Это отладка любого промежуточного шага. Приложение отработает все до нужного источника, вычислит его и остановится;
- По мере добавления требований заказчика код самого приложения меняется мало (ну конечно… ну ладно), а вот все его требования, вся логика сборки витрин, остаются не в коде, а в файле конфигурации, который управляет работой приложения. Этот файл и есть объектное описание сборки витрины, тот самый Object Spark;
- Такой подход обладает всей гибкостью доступной в языке программирования, что исключено при использовании инструмента. В случае необходимости простой и универсальный код можно дописывать. Например, можно добавить поддержку стриминга, вызова моделей, поддержку парсинга XML или JSON, вложенного в поля таблиц-источников. При том, что такое приложение может быть быстро написано с нуля в зависимости от требований заказчика;
- Главное следствие такого подхода. По мере усложнения проекта вся логика сборки витрин не размазывается по коду приложения, откуда ее довольно трудно извлечь, а сохраняется в файле конфигурации, отдельно от кода, где доступна для анализа.
