
Часть 1: Вводно-теоретическая (лирическая)
Привет! Сегодня мы поговорим и попробуем на практике реализацию паттерна Change Data Capture (далее – CDC) в Apache Flink.
Статья разделена на несколько частей: в первой мы рассмотрим теоретические основы Change Data Capture, варианты реализации и сферы применения. Во второй – обратимся к особенностям CDC-коннекторов экосистемы Apache Flink, а также выделим самые интересные фичи (а заодно и немного расскажем об Apache Flink для тех, кто раньше с ним не сталкивался). В третьей части – перейдем к практике, закатаем рукава и реализуем несложный сценарий захвата изменений из WAL PostgreSQL, приправленный объединениями, агрегацией, стеком ELK и целым кластером Flink, правда в миниатюре.
Итак, CDC. Википедия сообщает, что Change Data Capture в базах данных есть ничто иное, как набор паттернов проектирования, которые позволяют выявлять и отслеживать изменения в данных, что, в свою очередь, позволяет некоторым образом реагировать на эти самые изменения. “Изменения данных”, “события”, “реагировать” – эти слова-детекторы вызывают у меня бурю эмоций и неминуемо уводят в сторону потоковой обработки и событийно-ориентированной архитектуры. CDC – это не только event-driven подходы, хотя именно эта область применения представляет наибольший интерес в рамках нашей статьи. Мы в Neoflex активно используем реактивные подходы к архитектуре распределенных систем, строим аналитические платформы потоковой обработки и нам не чужд event-driven дизайн (приходите работать – будет интересно!).
Почему event-driven? Позволю себе вольно процитировать книгу “Event Streams in Action” (изд. Manning, 2019 г.):
“Хотите верьте – хотите нет, но ваша компания уже работает с потоками цифровых (и не только) событий. Наверняка, большинство ваших коллег не размышляет в подобном ключе и в своих рассуждениях о работе в основном опирается на:
Людей или активности, с которыми им приходится взаимодействовать на ежедневной основе: заказчики, маркетологи, коммиты, релизы и прочее;
Софт и железо, на котором работают те или иные решения;
Задачи, которые нужно выполнить сегодня, завтра или до конца недели.
Люди живут в этой парадигме потому, что они совсем не похожи на машины и привыкли к другой модели общения и взаимодействия. Те, кто осмелится взглянуть на свою работу, как на последовательность непрерывных публикаций и чтений событий из информационного потока, рискуют временно потерять рассудок, по крайней мере, им наверняка потребуется пара дней отгула, чтобы прийти в себя.
Суровые машины лишены этих проблем. Они спокойно принимают такое определение бизнеса:
“Компания – это система, которая генерирует изменения, реагируя на непрерывный поток событий.”
Пожалуй, на этой ноте мы и закончим наше лирическое вступление.
Где можно применить CDC?
Представим абстрактный банк, который хранит сведения о счетах своих клиентов в некоторой базе данных. Эти сведения интересны множеству сторонних систем, начиная от интернет-банка, заканчивая фрод-мониторингом. Прямое обращение к базе данных со стороны внешних систем может время от времени вызывать взрывной рост нагрузки и последующее радикальное падение производительности. Например, если сотрудники банка получают зарплату 15-го числа каждого месяца, примерно в районе обеда, то немалая их часть захочет поинтересоваться остатками на зарплатном счете в один и тот же момент. Пиковая нагрузка в этот период легко приведет наш интернет-банкинг в состояние временной нетрудоспособности. Схема этого мифического процесса отражена на рисунке 1:

Разумеется, увидеть подобную архитектуру в реальных системах не так-то просто (тем не менее, более чем реально). Она плохо масштабируется, в большинстве случаев требует распределенных транзакций, обладает низкой отказоустойчивостью и рядом других недостатков.
Как выйти из этой ситуации? Один из способов – применить CDC, захватывать изменения в интересующих нас таблицах и передавать их системам-потребителям в виде событий, применяя на их стороне подходы в духе “переноса состояния” (другими словами – event-carried state transfer или event sourcing).

Довольно тонкий и спорный момент, о который можно сломать не одну сотню копий – обеспечение целостности данных между мастер-источником (в нашем случае это база данных счетов) и потребителями. Принимая во внимание тот факт, что какой бы стремительной (а с немецкого Flink переводится не иначе как “шустрый”) не была реализация CDC, она не способна работать бесконечно быстро и непременно вносит свою лепту в процесс публикации изменений.
Кроме того, важно соблюдать семантику гарантированной, а еще лучше гарантированной однократной (exactly-once) доставки событий потребителям (или заставить их быть идемпотентными). В сухом остатке мы видим классическую теорему CAP, в которой жертвуем буквой “C” (читай – consistency), сознательно уходя в сторону событийной целостности. Но, как говорят на исторической родине Apache Flink: “Der Teufel ist nicht so schwarz wie man ihn malt”, то есть черт вовсе не так уж и страшен. Зато взамен получаем гибкое масштабирование и возможность использования быстрых локальных кэшей для хранения проекций данных (здесь речь о классической stateful-обработке в потоке), и, как следствие, приобретаем общее увеличение производительности и отзывчивости на фоне отказов. Действительно, теперь при временной недоступности базы данных счетов мы не прекратим обслуживать запросы интернет-банка, а с точки зрения клиента сбой и вовсе не будет заметен, потому что по сути, глядя на счет, мы видим только его локальную проекцию (но держим в уме немецкого чертика с его обвинениями в событийной природе консистентности данных нашей архитектуры).
И все же, снова ненадолго вернемся к концепциям change data capture. Можно выделить два главенствующих подхода к отслеживанию изменений в базах данных. Первый основан на периодическом full scan’е таблиц и выявлении изменений между соседними итерациями. На этом принципе работают, например, Kafka JDBC Source и Sqoop. Итерации выполняются последовательно, поэтому можно запросто упустить ряд обновлений, которые произошли между соседними сканированиями, захватив только итоговое состояние. События удаления с большой вероятностью также останутся незамеченными. Кроме того, пакетная обработка в виде последовательных full scan’ов вносит ощутимый вклад в увеличение общей задержки (читай – latency). Тем не менее, этот подход вполне применим, если речь идет, например, о работе с так называемым slow-change dimension в терминах DWH.
Учитывая особенности реализации некоторых СУБД, включаем смекалку и понимаем, что можно использовать транзакционные логи в качестве источника изменений! Например, постоянно отслеживать binlog’и MySQL или WAL PostgreSQL. Оба содержат сведения об успешно завершенных транзакциях. На этом принципе работает небезызвестный Debezium. Теперь можно смело говорить о потоковой обработке изменений по мере их появления в логе и гарантировать, что всякое изменение будет взято в оборот без потерь. Никаких table scan, как следствие – минимальная нагрузка на узлы базы данных. На фоне потоковой обработки также ожидаем снижение задержек и, соответственно, меньшие огрехи в событийной целостности. Выглядит как успех!
В сухом остатке потоковый CDC можно представить в виде ETL-процесса, где “E” отвечает за анализ лога базы данных, “T” – по обыкновению занимается преобразованиями и агрегациями событий, а “L” – транслирует полученные агрегаты или сырые события потребителю. На рисунке ниже представлен возможный вариант реализации ETL, примерно о таком технологическом стеке мы поговорим в следующей части статьи:

Часть 2: Условно-практическая (рассудительная)
В этой части, как и обещали, мы рассмотрим некоторые особенности Apache Flink и его CDC-коннекторов. Если Apache Flink для вас в новинку, рекомендую посмотреть небольшой доклад об архитектуре и основах этого фреймворка от компании Neoflex на YouTube.
В версии 1.11 разработчики Apache Flink впервые представили CDC, который опирался на слегка измененную (по сравнению с прежними версиями) реализацию TableSource API. Новый API содержал четыре типа сущностей, отражающих изменения в отслеживаемых таблицах:
INSERT;
UPDATE_BEFORE;
UPDATE_AFTER;
DELETE.
Все они, фактически, напрямую соотносились с содержимым транзакционных логов СУБД.
Flink на тот момент уже умел интегрироваться с Debezium в части сбора изменений БД в JSON и их конвертации в формат, понятный для табличного API Apache Flink. Пример такого JSON можно увидеть ниже:
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}
Как видно из структуры, событие изменения в полной мере отражает предыдущее и новое состояния сущности. Это позволяет реализовать полноценный event-carried state transfer на принимающей стороне.
Давайте заглянем чуть глубже в шаги “Extract” и “Transform” нашего процесса: Debezium захватывает изменения из лога базы данных и записывает их в топик Apache Kafka. Джоб Apache Flink подписывается на топик и читает JSON события изменений в формате Debezium, налету преобразуя их в представление Kafka Table. Пара трансформаций на стороне Flink и вуаля – поток изменений готов к записи во внешние системы.
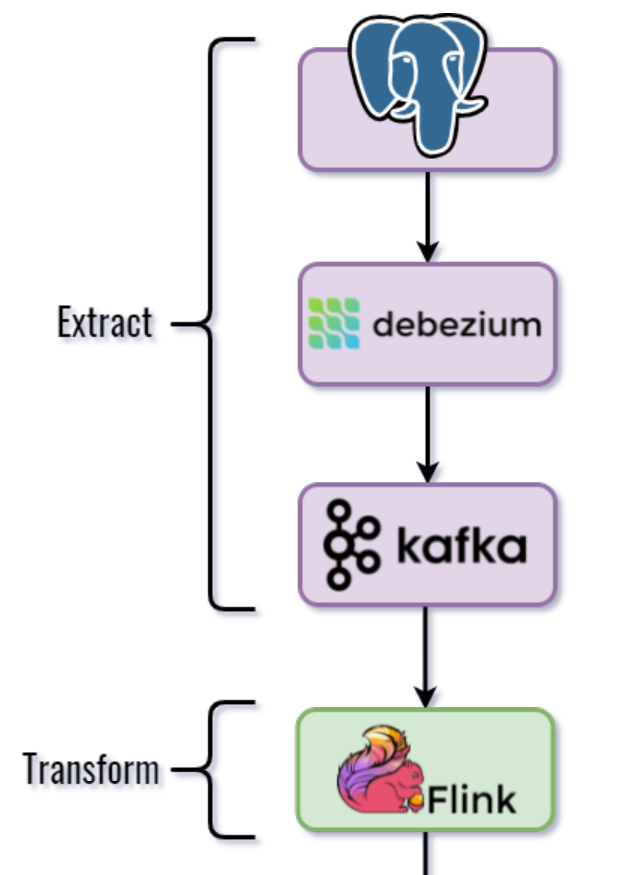
Тем не менее, подход не лишен своих недостатков. Чем больше участников в процессе, тем сложнее система и тем ниже ее стабильность, а сложность поддержки – выше. Положа руку на сердце, соглашаемся, что участников в нашем ETL-процессе немало.
Было бы неплохо заставить джоб Apache Flink напрямую потреблять изменения из логов базы данных, исключив из процесса других участников. Сжимаем ETL-процесс до одного супер-шага:

И получаем Flink CDC Connectors! Это набор коннекторов для MySQL и PostgreSQL, разработанный Alibaba и Ververica, который позволяет подключаться к логам БД прямо из Flink-джоба, заменив тем самым связку Debezium + Apache Kafka. Использование коннектора смотрится куда выгоднее прежнего варианта и позволяет снизить общие задержки процесса, затраты на поддержку инфраструктуры, к тому же гарантирует семантику однократной доставки событий (только для шагов “E” и “T”, семантика для “L” во многом зависит от конечных систем).
Фактически, коннекторы CDC не исключают использования Debezium, напротив, он интегрирован и используется в качестве основного движка захвата изменений.
Коннекторы также умеют читать снэпшоты баз данных и потреблять изменения сразу нескольких БД внутри одного джоба.
Многогранность сценариев использования таких ETL-процессов восхищает своей изысканностью, например:
Join’ы данных DWH и их запись в другие БД;
Потоковые ETL с агрегациями;
Публикация событий изменений в топики Apache Kafka;
Join’ы таблиц нескольких БД на базе потоковой stateful-обработки.
Не хочу более томить читателя мучительным ожиданием, поэтому перехожу к практической части.
Часть 3: Безусловно-практическая
Условный бизнес-сценарий
Все это время мы оставались в стороне от конкретного бизнес-сценария практической части. Пришло время это исправить.
Чтобы не уходить далеко от финтех-тематики (при этом не погружаться в ее дебри) давайте представим некоторую базу данных (пусть это будет PostgreSQL), которая содержит три таблицы, каждая из которых описывает ту или иную часть профиля клиента:

Таблица Clients содержит базовую информацию о клиенте: уникальный id, имя, фамилию, пол и т. д. Сведения о клиентах можно смело отнести к разряду slow-change dimension. Flink CDC полностью подходит для работы с медленно изменяющимися данными: в момент запуска приложения сначала считываются записи снэпшота и только затем – потоковые обновления из WAL.
Таблица ClientTransactions содержит сведения о транзакциях по различным счетам в контексте идентификатора клиента. Для каждой транзакции определяется сумма прихода/расхода и время проведения.
Третья таблица – ClientLocation, содержит сведения о геолокации пользователя, полученные, например, из мобильного приложения.
Итак, задача: отслеживать изменения Clients и материализовывать их в виде таблицы Flink Table API, фактически применяя паттерн event-driven state transfer. События с изменениями из таблицы ClientTransactions объединять в tumbling window (не хочу называть это “прыгающим окном”) с данными геолокации из таблицы ClientLocation и обогащать сведениями о клиенте из материализованной на предыдущем шаге таблицы Clients. Если сведения о клиенте не найдены, игнорировать событие, иначе – записывать обогащенное событие в Elasticsearch для дальнейшей аналитики. Для облегчения задачи заранее внесем в постановку допущения: мы не будем работать с событиями удаления и обновления записей (заинтересованный читатель может добавить этот функционал в рамках самостоятельных исследований).
В реализации попробуем (само собой – сугубо в научных целях!) смешать табличный и стримовый API Apache Flink, ощутив все многообразие этого фреймворка.
А вот и общая схема процесса:

Берем молоток, сооружаем docker compose
В первую очередь подготовим инфраструктуру для будущих экспериментов. Нам на помощь приходит docker compose, в YAML которого мы разместим все необходимые сервисы. Нам понадобятся следующие контейнеры (запаситесь оперативной памятью!):
PostgreSQL – собственно, мастер-источник изменений;
Elasticsearch – для записи результатов и промежуточных событий;
Kibana – для визуализации содержимого индексов Elasticsearch;
Job Manager кластера Apache Flink (в количестве одной штуки) – для управления кластером Flink;
Task Manager кластера Apache Flink (в количестве одной штуки) – для выполнения DAG-графа операторов CDC-джоба.
Готовый файл docker-compose.yml можно найти по ссылке на GitHub.
Как упоминалось ранее, Apache Flink работает в кластере, состоящем из нескольких узлов, главными из которых являются Job Manager и Task Manager. Для Task Manager мы в явном виде укажем количество слотов (читай – потоков) исполнения джоба (для нашей степени параллелизма хватит и одного):
FLINK_PROPERTIES=
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
Для корректного захвата событий из WAL Postgres необходимо, чтобы параметр wal_level базы данных был не ниже уровня logical. Дефолтное значение – minimal, скорее всего, вам придется его изменить. Подробнее об этом можно почитать здесь.
ALTER SYSTEM SET wal_level = logical;
В нашем docker-compose.yml эта настройка вынесена в раздел command сервиса Postgres:
command:
- "postgres"
- "-c"
- "wal_level=logical"
Второй немаловажный момент при создании таблиц PostgreSQL – применение этой настройки:
ALTER TABLE <table name>
REPLICA IDENTITY FULL;
А вот и объяснение (в виде выдержки из логов CDC-джоба Flink), почему это важно для корректной работы коннектора:
REPLICA IDENTITY for 'accounts.Clients' is 'FULL'; UPDATE AND DELETE events will contain the previous values of all the columns
Обратите внимание, что мы используем образ PostgreSQL из поставки Debezium – debezium/postgres. Он содержит предустановленные плагины декодирования WAL: wal2json и postgres-decoderbufs. В нашем проекте мы будем использовать postgres-decoderbufs.
Немного деталей
CDC-джобы будем запускать в так называемом session-cluster’е Apache Flink. Это разновидность кластера, которая может обслуживать сразу несколько джобов и своего рода противовес job-cluster’у, который создается для выполнения только одного приложения.
На рисунке изображена детальная диаграмма проектируемого джоба. Как и договорились, попробуем использовать все многообразие инструментов Apache Flink.
Захватывать изменения таблиц Postgres будем с помощью Flink SQL, каждый тип обновлений (для информации по клиентам, транзакциям и локациям) будем публиковать в свой индекс Elasticsearch в целях аудита. Далее, используя DataStream API, в окне небольшого размера начнем объединять события локаций и транзакций по ключу в виде идентификатора клиента. Полученные объединения снова передадим в окно, где свяжем их со сведениями о клиенте. Если все данные удалось объединить, запишем итоговый агрегат в Elasticsearch.
Для удобства навигации по Elasticsearch вынесем интересующие нас индексы на дэшборд Kibana.

Забегая вперед, продемонстрирую и граф нашего приложения, сгенерированный веб-интерфейсом Flink (об этом чуть ниже):

Привыкаем к окружению, начинаем разработку
Для начала небольшой дисклеймер. Все исходники проекта (docker-compose, DDL таблиц PostgreSQL, тестовые данные, код) можно найти в репозитории GitHub. Я не буду детально останавливаться на каждой строке, код снабжен короткими комментариями и не представляет сложности. Однако, мы обязательно будем акцентироваться на отдельных моментах, рассматривая их подробнее.
Для начала клонируйте репозиторий и перейдите в папку docker. Запустите docker compose и дождитесь создания всех контейнеров.
Пока контейнеры запускаются, я немного расскажу о структуре нашего проекта. Проект собирается при помощи SBT и использует Flink Scala API. Джоб Flink мы будем упаковывать в fat-jar (я не очень люблю такой подход, но именно этот вариант выбрал в качестве примера) с помощью плагина sbt-assembly и загружать в кластер Apache Flink с помощью веб-интерфейса. Для сборки артефакта нужно запустить SBT shell в этой папке и выполнить команду assembly.
Итак, наш арсенал:
По адресу localhost:8081 вас будет ждать Web UI Apache Flink. Это основной GUI, который позволит запускать приложения, собранные на предыдущем шаге;
Elasticsearch живет на localhost:9200, но в него мы будем смотреть с помощью Kibana, которая находится неподалеку - на localhost:5601;
Postgres по традиции обитает на localhost:5432, подключаться к нему можно как вам удобно, я привык к pgAdmin.
В папке расположен файл end-to-end.sql. Это комплект DDL и insert’ов с тестовыми данными. Выполним все его команды для базы данных account вплоть до первых INSERT (не включая их самих). После этого базы данных будет готова к дальнейшим экспериментам.

Попробуем собрать fat-jar с приложением Flink и запустить его в нашем мини-кластере. Откроем sbt и выполним команду assembly в соответствующей папке проекта. Сборка толстого JAR может занять некоторое время, а его размер – с легкостью перевалить за сотню мегабайт, поэтому не пугайтесь. Ищите собранный JAR в /target папке, он будет называться Flink Project-assembly-0.1-SNAPSHOT.jar (если вы не успели внести какие-либо изменения в проект).
Идем на localhost:8081 и восхищаемся красоте Flink WebUI. В левом меню нажимаем на кнопку Submit New Job.

В появившемся окне без промедления кликаем на синей кнопке Add New в правом верхнем углу. В модальном окне выбираем путь к толстому JAR и нажимаем Ok. Чтобы загрузить приложение в кластер, потребуется некоторое время, после чего перед нами предстанет список доступных для запуска джобов:

Выбираем наш, убеждаемся, что в качестве точки входа указан класс ru.neoflex.flink.cdc.demo.PostgresCdcJob и решительно кликаем на Submit. Если вы обладаете достаточным везением и строго следовали инструкции, спустя пару секунд в нижней части GUI вы увидите что-то похожее на:

Поздравляю, приложение запущено! Время проверить его в деле.
Чтобы “завести” поток событий, нужно добавить несколько новых записей в каждую из трех таблиц. После этого остается только наблюдать за изменениями, которые будут публиковаться в индексах Elasticsearch.
В конце эксперимента мы должны увидеть четыре индекса:
locations-index: для аудита по появлению новых событий локации;
aggregations-index: для аудита по появлению новых конечных агрегатов объединения;
clients-index: для аудита по появлению новых сведений о клиентах;
transactions-index: для аудита по появлению новых сведений о клиентах.
Выполняем первый INSERT в таблицу ClientLocation:
INSERT INTO accounts."ClientLocation" VALUES
(1, '40.689015, -74.045110', 'New York', 1621744725),
(5, '19.903092, -75.097198', 'Guantánamo', 1625244725)
Обратите внимание, что ключами для объединения событий является идентификатор в первом столбце.
Расчехляем Kibana, переходим по адресу и видим, что создан индекс с именем locations-index, содержащий две записи:

Последовательно выполняем два оставшихся INSERT’а для таблиц ClientTransaction и Clients. Снова заглядываем в Kibana: сначала вы скорее всего увидите только два новых индекса – для счетов и транзакций. Это так называемые записи аудита, в них мы фиксируем все события появления новых записей в отслеживаемых таблицах.
Но спустя некоторое время (после закрытия окна объединения tumbling window), вы увидите четвертый индекс – aggregations-index, он содержит агрегированные события записей по ключу (см. диаграмму приложения выше).
Для каждого индекса создадим index pattern в Kibana и посмотрим на их содержимое:

Так выглядит событие добавления нового местоположения клиента:

А так – добавление нового клиента:

И, наконец, итоговый результат объединения всех сведений о пользователе:

Каждое из этих событий (кроме последнего) было сгенерировано CDC-коннектором Apache Flink на базе новых строк в соответствующих таблицах. Агрегированное событие стало результатом объединения трех Data Stream: сведений о клиенте, транзакций и местоположений. На этом эксперимент можно считать успешно завершенным, но все же остались вопросы. Давайте чуть пристальнее взглянем на код проекта.
Препарирование кода
Итак, вам наверняка интересно, как быстро можно подключить коннектор к таблице и начать получать изменения? Ответ: быстрее, чем вы могли бы себе представить.
Основной класс приложения – ru.neoflex.flink.cdc.demo.PostgresCdcJob, давайте с него и начнем.
Так выглядит код, который создает таблицу Flink Table API, содержащую изменения таблицы Clients Postgres:
tableEnv.executeSql(
"CREATE TABLE clients (id INT, name STRING, surname STRING, gender STRING, address STRING) " +
"WITH ('connector' = 'postgres-cdc', " +
"'hostname' = 'postgres', " +
"'port' = '5432', " +
"'username' = 'test', " +
"'password' = 'test', " +
"'database-name' = 'account', " +
"'schema-name' = 'accounts', " +
"'table-name' = 'Clients'," +
"'debezium.slot.name' = 'clients_cdc')"
)
Определяем структуру таблицы, в которую нужно добавлять изменения, и в блоке WITH задаем параметры соединения (подробнее о них – здесь).
Я очень хотел продемонстрировать работу с Flink DataStream API, поэтому далее (это было не обязательно – то же самое можно выполнить на “чистом” Flink SQL) мы выбираем все записи из вновь созданного представления clients и получаем Flink Table с именем clients.
// Updates from clients
val clients: Table = tableEnv.sqlQuery("SELECT * FROM clients")
Эта магия позволяет не только отслеживать новые записи в таблице Postgres, но и предварительно считывать все ранее существовавшие строки из снэпшота (вы можете проверить это самостоятельно, запустив приложение на заранее наполненной базе данных).
Далее преобразуем таблицу в Data Stream:
// Clients to change stream
val clientsDataStream: DataStream[Row] = tableEnv.toChangelogStream(clients)
Аналогичным образом поступаем и с другими таблицами. К каждому из полученных Data Stream прикрепляем Sink Elasticsearch’а для публикации событий аудита, предварительно преобразовав табличные Row в заранее подготовленные кейс-классы:
// Send Clients to Elasticsearch for monitoring purposes
val clientsStream: DataStream[Client] = clientsDataStream.map { row =>
Client(
row.getFieldAs[Integer]("id"),
row.getFieldAs[String]("name"),
row.getFieldAs[String]("surname"),
row.getFieldAs[String]("gender"),
row.getFieldAs[String]("address")
)
}
clientsStream.addSink(elasticSinkClientBuilder.build)
Дальнейшие манипуляции довольно просты: мы объединяем Data Stream’ы транзакций и местоположений:
// Joining transactions on locations
val preAggregateStream: DataStream[AggregatedInfo] = transactionsStream
.join(locationsStream)
.where(_.id)
.equalTo(_.id)
.window(TumblingProcessingTimeWindows.of(Time.minutes(2)))
.apply { (transaction, location) =>
AggregatedInfo(
transaction.id,
"",
"",
"",
location.coordinates,
location.nearestCity,
transaction.amount
)
}
А затем объединяем этот Data Stream со стримом информации о клиентах. Результат записываем в индекс Elasticsearch:
// Joining aggregate on client info
val fullyAggregatedStream: DataStream[AggregatedInfo] = clientsStream
.join(preAggregateStream)
.where(_.id)
.equalTo(_.id)
.window(TumblingProcessingTimeWindows.of(Time.minutes(5)))
.allowedLateness(Time.seconds(30))
.apply { (clientInfo, preAggregate) =>
AggregatedInfo(
clientInfo.id,
clientInfo.name,
clientInfo.surname,
clientInfo.gender,
preAggregate.coordinates,
preAggregate.nearestCity,
preAggregate.amount
)
}
На этом все, потоковая агрегация на основе CDC готова.
Отдельное внимание стоит обратить на следующие классы:
ru.neoflex.flink.cdc.demo.secondary.PostgresSource – реализация CDC-источника для DataStream API (на мой взгляд, довольно сырая из-за десериализации события изменения таблицы SourceRecord в виде строки, использовать этот вариант весьма и весьма затруднительно);
ru.neoflex.flink.cdc.demo.secondary.ElasticSink – комплект коннекторов к Elasticsearch, где в качестве для работы с Json использован Circe.
Также советую трепетно относиться к соответствию версий зависимостей коннекторов CDC и Apache Flink (подробности ищите в build.sbt). Ваш покорный слуга провел немало радостных часов в поисках совместимых наборов.
Выводы
Паттерн Change Data Capture может стать отличным подспорьем в создании распределенных систем при его правильном применении. Если вы уже адаптировали потоковую обработку в своей архитектуре (или только собираетесь это сделать), обратите внимание на фреймворк Apache Flink и его CDC-коннекторы. Итоговое решение может быть весьма компактным и простым в разработке и поддержке за счет небольшого количества компонентов и унифицированных API Apache Flink. Среди особых преимуществ стоит выделить поддержку семантик гарантированной доставки событий (at-least-once и exactly-once) и минимальные уровни задержки. Фактически, можно заявлять о поддержке real-time обработки изменений в базах данных.
Экосистема Apache Flink активно развивается: в частности, CDC-коннекторы являются плодом труда разработчиков Alibaba – компании, которая владеет Aliexpress. Новые релизы выходят с завидной периодичностью, а mailing list Apache Flink является одним из самых активных среди всех продуктов Apache.
