
Константин Осипов (kostja )

Как родилась идея доклада? Я не очень люблю выступать и рассказывать про фичи, особенно про будущие фичи. Выясняется, что и люди не особо любят это слушать. Они любят слушать про то, как все устроено. Это доклад о том, как все устроено или должно быть, с моей точки зрения, устроено в современной СУБД.
Я попробую сделать так, чтобы мы смогли с макроуровня спуститься на микроуровень, т.е. каким образом, сначала отбрасывая макропроблемы, мы можем создать себе пространство для выбора на среднем уровне и микроуровне.

На макроуровне – это то, как должна быть устроена современная СУБД. Почему у нас сегодня есть возможность создавать новые базы данных, почему нельзя взять текущую и удовлетвориться ее производительностью, подтюнить или написать для нее патч? Просто взять и написать патч, который бы ее ускорил, если она медленная? Из какого пространства решений мы выбираем?
Дальше, после того, как мы какие-то базовые архитектурные принципы зафиксировали, нам нужно спуститься ниже и поговорить об инженерии. Помимо того, что есть базы данных, которые обрабатывают транзакции с помощью многоверсионного контроля версий, базы данных, которые обрабатывают транзакции с помощью блокировок, то, как ты реализовал этот алгоритм (условно говоря, насколько прямые у тебя руки) напрямую влияет на производительность. Если первый фактор дает тебе десятки раз масштабирования роста производительности, второй фактор дает тебе 2-3 раза, но тоже немаловажно, потому что когда потом с твоим решением выйдут на сцену, тебе не будет стыдно, что тот же Redis, хотя он конструктивно проще, не уделывает тебя как Тузик грелку, потому что, несмотря на то, что там миллион фич, ты не проседаешь по производительности и т.д. Это инженерия.
2-ая часть доклада – это про алгоритм и структуру данных, т.е. как мы фиксируем какие-то базовые инженерные подходы, работаем с тредами и т.д. И говорим, как мы реализуем те структуры данных, которые были бы самыми быстрыми и позволяли бы обрабатывать и хранить данные быстрее всего и качественнее всего.
3-я и 4-ая части – самые зубодробительные, потому что там я пытаюсь хотя бы по верхам рассказать про наши алгоритмы и структуры данных, которые мы реализовали.
Архитектура СУБД. С чего стоит начать? Почему есть окно возможностей в 2015 году для современной базы данных.

Напомню базовые требования, это то пространство, в котором мы можем играть. Есть требования ACID, которым мы должны удовлетворять. Любая база данных, которая считает, что она может скипнуть ACID, на мой взгляд, не подлежит серьезному рассмотрению, т.е. это такая поделка на коленке, потому что рано или поздно становится понятно, что нужно все-таки не терять данные, которые тебе дают, нужно быть дружелюбной для пользователей, нужно быть консистентной и т.д. Это академическое определение, но на самом деле даже в ACID на таком маленьком слайде – бездны, т.е. о нем можно говорить 2-3-4 часа.
Что такое DURABILTY? Я всегда, когда об этом рассуждаю, говорю, что такое DURABILTY в плане ядерной войны. DURABLE ли ваша база данных в случае атаки вероятного противника? Или ISOLATION – что это такое? Почему мы говорим, что хотим, чтобы видимость двух транзакций друг на друга не влияла? А что, если я хитрый парень, у меня есть 2 лаптопа, я и с одного лаптопа приконнектился, и с другого. В одном лаптопе я сказал begin, insert, потом я посмотрел, что туда вставил, на основе этого принял решение, во втором лаптопе сделал begin, insert уже тех данных, что я глазками своими посмотрел. Какой я хитрый, я обманул ISOLATION. Есть ли тут какие-то гарантии? Но, тем не менее, это правила игры.
И одно из них, самое фундаментальное, которое очень серьезно влияет на производительность – это Isolation. Почему? Потому что изоляция транзакций друг от друга – это такая штука, которая влияет на очень много вещей сразу. Т.е. можно сделать так, чтобы кто-то читал свою версию данных и не мешал другому человеку (как работает Postgres, MySQL с InnoDB). Но как только речь заходит о записи, то у нас происходит дилемма. У нас нет способа обеспечить изоляцию двух участников, которые пытаются обновлять одни и те же данные и при этом полностью изолировать друг от друга с алгоритмичной точки зрения.

Нам необходимо в том или ином виде сигнализировать другому участнику, что одновременно кто-то еще работает с этими данными. Формализуется это в теории через понятие расписания (я привел пример расписания). У нас есть data items, т.е. X и Y – это наши данные, 1 и 2 – это наши участники, r и w – это обозначение операций. Участники читают или пишут данные, E – это расписание, по которому они работают.

В конечном итоге, единственный внушительный способ обеспечить изоляцию – это блокировки, т.е. фундаментом для баз данных 20-ти, 30-тилетней давности было то, что они базируются вокруг теоремы о двухфазных блокировках.

Т.е. мы говорим о том, что для того, чтобы добиться сериального расписания участники должны захватывать блокировки на те объекты, которые они меняют. При этом есть многоверсионный конкаренси контрол, который позволяет нам в некоторых случаях этих блокировок избежать или отложить их захват, т.е. мы можем в конце, на момент коммита уже проверить, валидировать каким-то образом, что не была нарушена целостность. Т.е. блокировки сильно на участников не влияют, но, тем не менее, даже в многоверсионном конкаренси контроле, в таких алгоритмах требуются в определенных сценариях блокировки на несуществующие объекты. Самый строгий режим сериализации – в классических СУБД это называется serializable, там все равно требуется захватывать блокировки.

Это фундаментальный механизм, и он зафиксирован в академическом сообществе через теорему о двухфазных блокировках, которая более-менее является фундаментальной, т.е. нам нужно эти блокировки накапливать. Классические СУБД построены вокруг этой схемы.

Помимо этого, классические СУБД изначально были построены во вселенной, где соотношение «диск – память» совсем другая, не такая, как сейчас. Условно говоря, можно было иметь 640 Кб памяти и 100 Мб диск – и это было хорошо. Т.е. отношение где-то 1 к 100. Сейчас отношение часто 1 к 1000, т.е. изменились эти отношения. А скорости изменились еще более радикально, т.е. если раньше оперативная память была всего лишь в 100 раз быстрее диска, то сейчас она в 1000 или в 10000 раз быстрее диска. Произошло радикальное изменение соотношений, из которых приходилось выбирать.
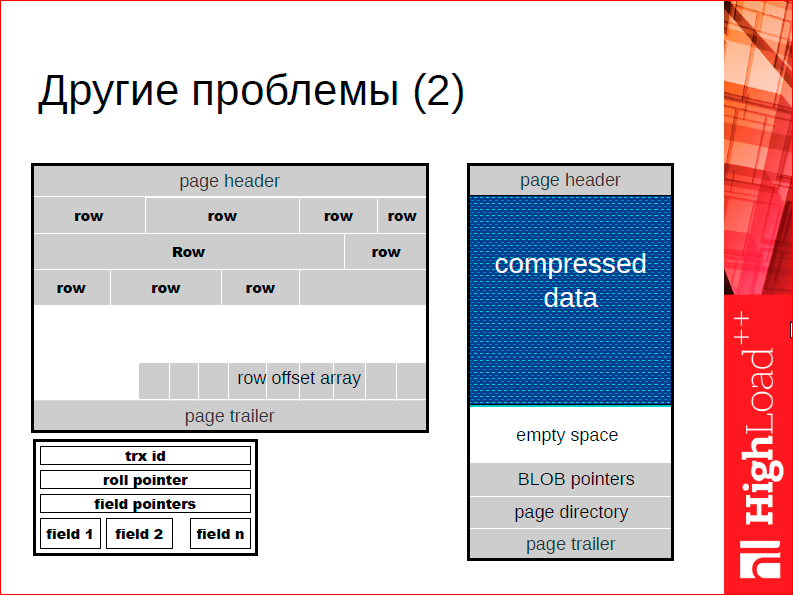
Классический пример того, почему это имеет значение, – это то, что классические СУБД устроены по принципу двухуровневого хранения, т.е. у вас есть какое-то представление данных на диске и у вас есть представление данных в памяти. Память фактически кэширует ваше представление на диске. У вас неизбежно возникает необходимость трейдоффа между тем, чтоб эффективно работать с диском и эффективно работать с памятью.
В частности, чтоб эффективно работать с диском… Обратите внимание на белое пространство на слайде – это типичная страничка типичной СУБД, которая хранит строчки. Обычно страничка недозаполнена, потому что у нас дисковое пространство не дорогое, а стоимость записи на диск растет не пропорционально размеру, который мы записываем, а пропорционально количеству обращений к диску. Соответственно, нам имеет смысл иметь дырки на диске, потому что не страшно, запишем мы эту дырку, записать дырку нам ничего не стоит.
В оперативной памяти история совсем другая. Там важно, чтобы данные занимали как можно меньше пространства, потому что стоимость обращений более-менее одинаковая. Оперативная память имеет более-менее одинаковую цену рандомного доступа, соответственно, нам имеет смысл делать вещи как можно более компактными. Одним из таких факторов является то, что если вы сделаете с нуля СУБД для оперативной памяти, то вам имеет смысл пересмотреть более-менее фундаментальные алгоритмы и структуры данных, на которых вы делаете, т.е. вы можете от этих дырок избавится – это только один из примеров.
Кстати, если говорить об этом примере, получается интересная история. Многие говорят: «Зачем нам СУБД X, мы пользуемся СУБД Y и просто добавим ей памяти». Я видел такие сценарии, когда люди берут базы данных, которые предназначены для секондари сторадж, т.е. для дисковой базы MySQL, Postgres, Mongo, дают ей определенный объем памяти, у них все влезает в память, и они счастливы. Только экономический расчет здесь сразу ущербен, потому что если делать базу данных в памяти, то типичный memory footprint, т.е. объем занимаемой памяти может быть в разы меньше просто за счет того, что нет всех оферхедов, связанных с хранением на диске. Экономически это неправильно – брать СУБД, которая предназначена для хранения на диске, выбрасывать деньги и помещать все данные в памяти.

Мои такие измышления основаны не на пустом месте. В 2008 году вышла статья одного из классиков мира СУБД, с анализом деятельности, которую СУБД проводит в разных подсистемах, т.е. сколько процентов усилий и на что приходится у СУБД. Были выделены основные подсистемы блокировки, latching – это те же самые блокировки, но только на более низком уровне, когда нам нужно блокировать не данные, а процессы, которые между собой взаимодействуют. И в этой статье делается вывод, что лишь 12% современная СУБД тратит на полезную работу, все остальное она тратит на эти магические буквы ACID и на взаимодействие с устаревшими архитектурами, т.е. на работу, построенную по принципу устаревших архитектур. Именно из этого графика исходит это окно возможностей, которое позволяет ускорить СУБД в десятки раз при этом без потери функционала или без существенной потери функционала.
Как же мы можем избавиться от всех этих локинг, летчинг и т.п. штук? Как мы можем избавиться от оверхеда на перегон данных с дисков памяти и на изменение форматов представления? Вот те базисы, которые я выписал и которые легли на основу архитектуры Tarantool:

На самом деле, это не уникальная архитектура. Если вы посмотрите на Memcached, на Redis, на VoltDB, окажется что мы не одни такие, т.е. дальше мы берем и начинаем соревноваться, условно говоря, в своей лиге. Мы уходим в свою лигу, в которой мы говорим, что:
- у нас 100% данных хранится в RAM,
- мы выполняем транзакции последовательно так, чтобы нам не было необходимости брать блокировки; у нас нет самого понятия блокировки, мы просто отдаем тот объем RAM, который у нас отведен на транзакцию, она им эксклюзивно пользуется, потом мы выполняем следующую транзакцию.
Мы, все равно, говорим, что будем шардировать данные, т.е. у нас горизонтальное масштабирование – это норма, поэтому мы даже не пытаемся сделать так, чтобы база данных работала эффективно на одной машине. Одна машина сегодня – это все-таки супер компьютер. 48 ядер, которые имеют разную стоимость доступа к оперативной памяти, т.е. если вы к одному участку из одного ядра обращаетесь – у вас одна цена, к тому же самому участку из другого ядра – у вас другая цена обращения. Это уже суперкомпьютер, и говорить, что эффективная работа на одном компьютере – это та же самая задача, что 10-20 лет назад, уже не приходится, поэтому мы не будем решать эту проблему вообще.
Есть во всей этой истории один интересный момент. Мы говорим, что у нас в памяти есть СУБД, которая выполняет транзакции последовательно. Что же происходит? Если во время выполнения транзакции нам нужно данные не терять, мы должны их записывать в журнал, т.е. эту работу мы отменить не можем. У нас остается журнал, журнал хранится на диске. Если мы будем писать каждую транзакцию в журнал, одну за другой, то мы все равно упремся в проблему производительности, потому что диск медленный, т.е. то, что мы мало используем CPU, нам ничего не дает, диск медленный. Нам нужно придумать, как журнал писать большими объемами, по 100, по 1000 транзакций за раз, тогда мы сможем разнести эту стоимость записи на множество транзакций и повысить фрупут, т.е. пропускную способность. Мы таким образом не повысим производительность, т.е. для каждой транзакции latency у нас останется тем же самым и будет соответствовать стоимости записи на диск, но объем и пропускную способность мы так можем повысить.

Возникает проблема: каким образом откатывать транзакции, если запись журнала не удалась? Я, в принципе, не встречал данные технологии в литературе, но в Tarantool используется аналогия, связанная с кинолентой. Допустим, у нас есть транзакция, которая уже завершилась в памяти, и нам нужно записать ее в журнал. Эта транзакция ждет своей очереди, пока медленный диск ее запишет. В этот момент пришла другая транзакция, которая читает или обновляет те же самые данные. Что с ней делать? Запретить ей выполняться? Если мы запретим ей выполняться, у нас производительность резко упадет. Если мы разрешим ей выполняться, может оказаться, что транзакция, которая ждет своей очереди, не записалась, закончилось место на диске. Что нам тогда делать? Откатывать. \
Откат в Tarantool устроен по принципу обратной раскрутки, т.е. все транзакции выполняются в оптимистическом режиме одна за другой, не ожидая друг друга. Как только происходит какая-то ошибка, ошибка происходит много позже, спустя какое-то время после того, как транзакция выполнилась в памяти. Мы останавливаем наш конвейер и раскручиваем его в обратную сторону. Выкидываем все, что фактически видело «грязные» данные и перезапускаем конвейер. Это безумно дорогая операция. Возможно, потеряется 10000 транзакций под большой нагрузкой, но т.к. она случается крайне редко (в эксплуатации она не случается никогда), вы просто следите за местом на диске.
Ну, «никогда» – это категорично, но фактически, если вы следите за оборудованием, она не случается. Это издержка, на которую стоит идти. И вообще, в целом, когда проектируешь систему, нужно ее проектировать вокруг наиболее вероятного сценария. Если пытаешься стоимость архитектурных решений сделать одинаковой, просто перечисли: а что если будет откат, что если будет коммит, что если будет еще что-то?.. Если код соответствует этому, то скорее всего, эффективной системы не построить, потому что вы будете по худшему случаю себя оценивать.
Зафиксировав т.о. эти базовые принципы, мы переходим к аспектам инженерии. Что хочется сказать про инженерию.

На конференции будет доклад про базу данных в памяти, она называется ChronicleMap, и ChronicleMap интересна тем, что цель, которую перед собой ставили инженеры этой СУБД – это достичь микросекундной latency на обновление СУБД. Задача была в первую очередь, чтобы обновление занимало гораздо меньше времени. В нашем случае ситуация немного другая. И мы этот трейдофф решаем в другую пользу. О чем здесь идет речь? Представим себе, что вам нужно добраться на конференцию, и пробок нет, что вы возьмете? Вы возьмете такси, и это будет быстрее. Вы воспользуетесь общественным транспортом – это будет дешево. Почему общественный транспорт дешев? Потому что он размазывает стоимость на множество участников. Происходит вагонизация, т.е. вы вместе со всеми разделяете стоимость эксплуатации. И в нашем случае цель именно такая.
Если другие СУБД ставят перед собой задачу, допустим, иметь очень низкий latency, но, возможно, не максимальный throughput, т.е. пропускную способность, в нашей ситуации мы говорили, что тот latency, который нам дает оперативная память для нас достаточно – это, допустим, несколько миллисекунд на обработку одного запроса. Это тот параметр, на который мы хотим выйти и в остальном мы хотим оптимизировать throughput, т.е. пропускную способность. Мы делаем так, чтобы максимальное количество запросов разделяло издержки между собой. Что это значит с точки аспектов инженерии?
У нас есть медленная сеть, и сеть, по сути, дорогая. Она дорогая по обмену, потому что мы живем в древнем мире операционных систем сорокалетней давности, и нет способа сходить в сеть, не заглянув в ядро. У нас есть диск, который тоже очень дорогой, сама запись диска медленная, но нам диск писать надо, потому что это единственный способ сохранять данные, чтобы они пережили отказ по питанию. Еще у нас есть транзакшн процессор, который работает в одном треде и выполняет транзакции одну за другой, т.е. транзакшн процессор – это наш конвейер. Каким образом нам сделать так, чтобы этот конвейер у нас простаивал минимально?
Если у нас конвейер на каждый запрос будет обращаться в сеть, потом обращаться на диск, а скорее всего это нужно сделать 2 раза, т.е. ему нужно прочитать запрос, обработать его, записать на диск, ответить, дать результат клиенту. Т.е. в сеть мы обращаемся 2 раза, один раз на диск. Вся эта катавасия займет очень много времени. Нам нужно сделать так, чтобы мы из сети читали максимально быстро, относительно одного запроса – максимально дешево. Что мы для этого делаем? Мы говорим, что наш протокол полностью асинхронен, мы работаем в режиме пайплайнинга, т.е. мы можем из одного коннекта читать запросы множества клиентов и отвечать всем клиентам одновременно. Т.е. каждый клиент получает свой ответ, мы мультипликсируем все это на одном сокете и у нас пайплайнинг идет на каждом уровне, т.е. конвейеризация на каждом уровне работы. И это очень существенный трейдофф, вокруг которого строится СУБД. Поэтому мы работаем в одном треде, поэтому мы даем более низкий latency, чем какие-то другие решения, которые малтитредад, но мы за счет этого снижаем издержки на один запрос.

С точки зрения реализации необходимо найти способ параллелизации парадигмы, в которой мы будем существовать, в которой мы будем все это параллелить. Такой парадигмой является одна из следующих.

Мы фактически должны выбрать что-то из этого. Если мы говорим, что у нас есть конкурентные треды, мы каким-то образом между этими тредами обмениваемся информацией, нам нужно выбрать способ обмена.
Почему это особенно важно в нашем случае? Потому что выбор способа обмена между тредами влияет не только на эти издержки, которые более-менее явные – поход в ядро, поход на диск, поход в сеть, но он имеет такие неявные вещи, например, как часто мы флашим кэш, кэш процессора, т.е. мы с кэшем хорошо работаем или плохо? И с учетом того, что это происходит неявно, фактически это поиск в тумане. Что-то изменил – кэш начал работать чуть лучше, у тебя чуть увеличилась производительность.
Фактически мы сейчас в каком мире живем? Помимо этой большой оперативной памяти, с которой мы имеем дело, у нас от 16 до 32-х Мб кэша 3-го уровня, которая разделяется между всеми ядрами, и чем эффективней мы начнем использовать кэш 3-го уровня, тем лучше мы будем работать. Таким образом, наша задача – сделать так, чтоб кэш 3-го уровня реально работал, работал эффективно.
Вот, у нас есть такой выбор (см. слайд выше), и если мы говорим о парадигмах, мы должны выбрать какую-то парадигму, в которой все это закодировано.
Забегая вперед, я скажу, что мы выбрали последнюю парадигму – это actor model, почему?

Что можно сказать о локах? Я программировал с использованием мутексов всю свою сознательную жизнь – прекрасный инструмент. Одна из существенных проблем мутексов для эффективного программирования – это проблема композабилити. О чем здесь речь? Представьте, что у вас есть критическая секция, которую вы, допустим, вставляете в конкурентную структуру данных. Структура данных работает с кучей тредов. Вы берете эту критическую секцию, инкапсулируете ее в какой-то метод. У вас есть метод insert в какую-то конкурентную структуру данных. Далее у вас есть еще некая макроструктура, которая пользуется этой структурой данных, и она также должна работать в критической секции, т.е. она должна быть также конкурентна. Блокировки не позволяют вам просто взять и вызвать один метод из другого, вы должны 10 раз продумать, почему? Не приведет это к дедлокам или к каким-нибудь другим проблемам, которые я здесь описал. Откуда это может все возникнуть? Вы просто не можете произвольным образом использовать код, который использует блокировки друг из друга, у вас теряется основное свойство программирования, когда мы можем совершать инкапсуляции, докомпозировать проблемы в более мелкие. На самом деле wait-free алгоритмы решают одну проблему – проблему дедлоков. Wait-free алгоритмы не дедлочатся, потому что они не ждут. Но они не решают других проблем? связанных с алгоритмами? построенными вокруг модели блокировок.

Дедлок – это цикл ожидания. Мы из какого-то места кода используем локи в порядке А, В, из другого места кода мы используем локи в порядке В, А. Опа! И у нас под нагрузкой все это схлопнулось – дедлок.
Что такое конвоирование и хотспоты? Это относится, в том числе, и к wait-free алгоритмам. В чем проблема? Вы написали свою программу в предположении, что это критическая секция работает с двумя тредами. У нее, допустим, есть продьюсер-тред, консьюмер-тред, эти треды обращаются к этой критической секции в среднем… Допустим, у них нагрузка в 1000 запросов в секунду. Соответственно, они обращаются к критической секции 1000 раз в секунду – у вас все работает. Дальше у вас обстоятельства меняются. Меняется железо или меняется работа, которую выполняют треды, или меняется окружение, с которым они работают, т.е. у вас появляется еще неизвестное в этой системе. Мы говорим о композабилити, т.е. вы начинаете систему расширять и настраивать, и ваша критическая секция внезапно становится горячей. Допустим, какая-то мелкая вещь, которая под критической секцией фактически две переменные обновляет, но она начинает дергаться, не 1000 раз в секунду, как вы планировали, а 10000 раз в секунду, 100000 раз в секунду, и вокруг нее происходит постоянная борьба, снимаются треды с управления и т.д. Что может произойти дальше?
Вы можете попробовать поиграть с приоритетами или порядком, т.е. вы говорите, что какие-то запросы более приоритетны, какие-то менее приоритетны. Это может привести к тому, что более приоритетные запросы к критической секции начинают вытеснять менее приоритетные. Менее приоритетные никогда не выполняются – это голодание.
Конвоирование – это, как раз, та ситуация, когда у вас маленькая критическая секция вложена в большую и из-за этого к маленькой критической секции не пробиться.
Есть множество разных ситуаций, которые так или иначе выражаются в одном выводе – локи не компоузебл. Система написана вокруг блокировок и, если это является основным примитивом программирования, из этого нельзя строит масштабируемые системы.
Это было понятно не только мне, но и создателям Erlang’а, которые сделали его 30-40 лет назад. По большому счету, если говорить о том инструменте, на котором должен быть написан Tarantool – это инструмент, наверное, называется Erlang.

В целом, один из подходов, который может разрешить проблему композабилити, – это подход функционального программирования, когда критические секции явно не задаются, а во время выполнения параллелизмы определяются на основании функциональных зависимостей. Другими словами, вы нигде не берете никаких локов, но если у вас одна и та же функция является функциональной зависимостью от другой, то вы можете распараллелить ее выполнение прозрачно для автора.
Этим пользуются всякие функциональные языки, которые умеют это достаточно хорошо делать. У вас нет общих данных, и поэтому у вас нет конфликтов по общим данным, т.е. функциональное программирование, вроде как, подходит.
Но, к сожалению, если говорить о системном программировании, т.е. поженить функциональный подход и системное программирование, то сред, на которых можно основываться, у нас сегодня нет.
Таким образом, мы приходим к модели, которую я заспойлил в самом начале, а это именно то, на чем нам нужно останавливаться, что позволяет нам делать компоузебл систему и делать ее дешево.

Чем привлекательна Actor model, т.е. модель обмена сообщениями между независимыми участниками? У нас однотредовая система, в этой системе уже есть кооперативная многозадачность, т.е. на уровне одного треда мы создали микропотоки, которые линейно выполняются, а взаимодействовать между собой они могут как через общую память, потому что там нет никаких проблем, но они могут взаимодействовать между собой так же и через посылку сообщений.
Нам осталось решить проблему для взаимодействия между тредами. Вернемся к картинке «Система массового сообщения»:
У нас есть Network тред, Transaction Processor тред, Write Ahead Logging тред и для каждого запроса в каждом треде концептуально есть какая-то сущность – actor, актер. Задача актера в network треде – взять запрос, распарсить его, проанализировать его корректность и отправить сообщение «выполни этот запрос» Transaction processor’у. Transaction processor берет запрос, проверяет нет ли там duplicate key, нет ли там каких-то еще constraint violation, выполняет какие-то триггеры, вставляет его везде, и говорит: «Ок» соответствующему ему бади в write ahead log – запиши этот запрос на диск. Он берет запрос и записывает на диск.
В буквальном смысле, если бы мы так делали, мы бы обменивались сообщениями на каждый запрос. Мы хотим сократить это, т.е. мы в этой парадигме хотим, чтобы действительно сущности в нашей программе обменивались сообщениями, но издержки на этот обмен были минимальными, т.е. нам нужен какой-то способ мультиплексировать обмен. И Actor model за счет того, что она инкапсулирует обмен сообщениями, позволяет сообщения передавать пачками. Т.е. мы берем Actor model, говорим, что для того, чтобы что-то сделать, нужно послать сообщения между соответствующими Actor’ами в разных тредах, и под капотом каждый раз, когда происходит посылка сообщения, мы соответствующего Actor’а соспейдим, т.е. снимаем его с управления и передаем управление следующему Actor’у. Таким образом, на основе корутин в каждом треде у нас постоянно происходит работа, но также постоянно происходит переключение между Actor’ами.
Почему это для меня является центральным моментом? Я даже нарисовал красивый гиперкуб на слайде «Actor model» (см. выше), на котором я пытаюсь подчеркнуть важность именно такой парадигмы. В чем свойство гиперкуба? В том, что количество связей там растет пропорционально количеству узлов, т.е. не квадратично, а пропорционально.
Если взять Tarantool, то вершинами в этом гиперкубе можно считать отдельные треды. Мы хотим сделать так, чтоб связность между тредами была низкой, таким образом, мы через линки между вершинами образуем связи между тредами. И наша задача – поддерживать низкое количество связей, чтобы обмен был дешевым.
Если вспомнить какие-то древние суперкомпьютеры типа Крея, и вы посмотрите на дизайн, окажется, что они на самом деле были построены по принципу гиперкубов. Вообще, если смотреть на обычные механические телефонные свичи, они пытаются решить ту же самую проблему – как в наше трехмерное пространство уместить мультиплексирование множества взаимодействующих сущностей и сделать это эффективно. Это получается уже какое-то пространственное мышление, а не инженерное.
Почему нарисован 4-х мерный гиперкуб? Я говорил только об одном треде и взаимодействии в одном треде, но при шардировании появляется та же самая проблема – запрос приходит на любой узел в кластере, и этот узел должен взаимодействовать со всеми узлами для того, чтобы этот запрос обработать. Имеем ту же самую проблему квадратичного роста количества связей, т.е. у нас n квадрат связей от количества участников. И единственный способ это количество связей контролировать – это каким-то образом загнать его в такое пространство.
Почему эта модель является хорошей с точки зрения современной системы? Посмотрите, если взять типичный чип, эта штучка в центре – это кэш 3-го уровня:

Очень занятным в этом смысле является спор между поклонниками архитектур CISC и RISC в 2015 году. Я обеими руками выступаю за ARM процессоры – у них лучшее энергосбережение и т.д., но меня смешит спор про архитектуры, потому что, по большому счету, современный CPU – это огромный кэш 3-го уровня, все остальное – это 15 % от чипа. Спор про то, какой процессор эффективней в этой истории – тот, кто работает с кэшем 3-го уровня лучше, тот и эффективен.
Почему Actor model хороша, в том числе, для современного железа? Если посмотреть на доступ к кэшу 3-го уровня, то чем меньше мы туда лезем, тем лучше. Каждый раз, когда мы вынуждены послать какое-то сообщение, т.е. синхронизировать два конкурентных процесса, мы должны так или иначе залочить эту шину обмена, чтобы обеспечить консистентность данных. Например, в Intel меняешь данные в одном процессе, и они в конечном итоге поменяются во всех. Поэтому нам лучше всего редко менять разделяемые данные. Идея с мультиплексированием обмена сообщениями состоит ровно в этом – чтобы разделить эту стоимость, лочить шину обмена от 1000 до 10000 раз в секунду. Это нормальная производительность, дает приемлемый для нас latency в 1-2 мс на обработку запроса, таким образом, снижаются издержки на обмен.
Часть 3 посвящена памяти, все-таки, мы – СУБД в памяти, и мы должны очень много внимания посвящать памяти.

Зачем были части 1 и 2? Я пытался показать, каким образом мы от всего пространства решений спускаемся на уровень ниже.
Сейчас мы упростили себе проблему – у нас нет конкурентности, у нас есть память, которую должен обрабатывать один тред. Нет памяти, разделяемой между тредами, весь обмен между тредами происходит за счет обмена сообщениями.
Что же делать дальше? Как сделать так, чтобы в одном треде работа с памятью была эффективной?
На слайде я показал, чем не подходит классический менеджер. Допустим, у нас есть свой, какие требования к нему мы предъявляем?

Наши уникальные требования, в первую очередь, это поддержка квот. Мы гарантируем пользователю, что мы не выходим за отведенную нам память. Если происходит ошибка, часто возникает вопрос: «а вы крэшитесь, если у вас кончается память?». Можем, если есть ошибка в коде, но в целом, если кончается память, система перестает сохранять данные, но продолжает работать – отдавать текущие данные. Это одна из целей.
Вторая цель. Есть такая штука как компактификация журнала. Нам нужно периодически сбрасывать на диск весь наш снимок, всю нашу память для того, чтобы ускорить восстановление, т.е. для этого нам нужны консистентные снимки памяти. Более того, нам нужны консистентные снимки, если мы хотим поддерживать так называемые интерактивные транзакции, т.е. транзакция, которая началась на клиенте, работает, если мы хотим делать классический multiversion concurrency control, то для этого тоже нужны консистентные снимки.

Аллокаторы памяти в этом одном треде выстроены по определенной иерархии, и вершины иерархии являются поставщиком памяти уровня ниже. Наш подход заключается в том, что мы пытаемся инкапсулировать как можно меньше при работе с памятью, т.е. мы предоставляем программисту СУБД набор инструментов, подходящий для соответствующих ситуаций. На вершине иерархии находится объект, который глобален, в принципе, их может быть много, у нас их сейчас два – память (квота) под данные и квота под runtime.
Квота под runtime у нас сейчас не ограничена, но ее можно задать. Глобальным объектом на вершине иерархии является квота. Квота – это очень простой объект, в котором хранятся две величины – разрешенный пользователям объем и текущий потребленный объем. Это объект конкурентный, и он разделяется между этими тремя тредами.
Пользователем квоты является так называемая арена. Арена выглядит таким образом:

Фактически это диспетчер памяти, который умеет работать только с очень большими кусками памяти в 4 Мб. При этом задачей арены является поставлять память уровням ниже. Арена устроена так, что с ней также можно работать из множества тредов, т.е. одна арена может быть источником памяти для множества тредов. Она конкурентна. Причем, фактически, основная функция, которая выполняется – это управление адресным пространством. Мы хотим, чтобы адресное пространство было выровненное и не было фрагментированным, поэтому при старте, мы приаллоцируем определенный объем адресного пространства, но также можем выйти за пределы этого приаллоцированного объема, если квота была увеличена после старта.
Следующим уровнем (и это первый уровень, который работает на уровне каждого треда) является кэш slab’ов. Арена умеет работать только со slab’ами одного размера, причем фактически это максимальный размер. У нас от размера арены зависит такая переменная, как максимальный объем данных, который вы можете поместить в систему. Т.е. если у вас тапл занимает 8 Мбайт, то вам нужно увеличить эту штуку. Текущее ограничение не очень красивое, я расскажу, как мы его собираемся убрать.
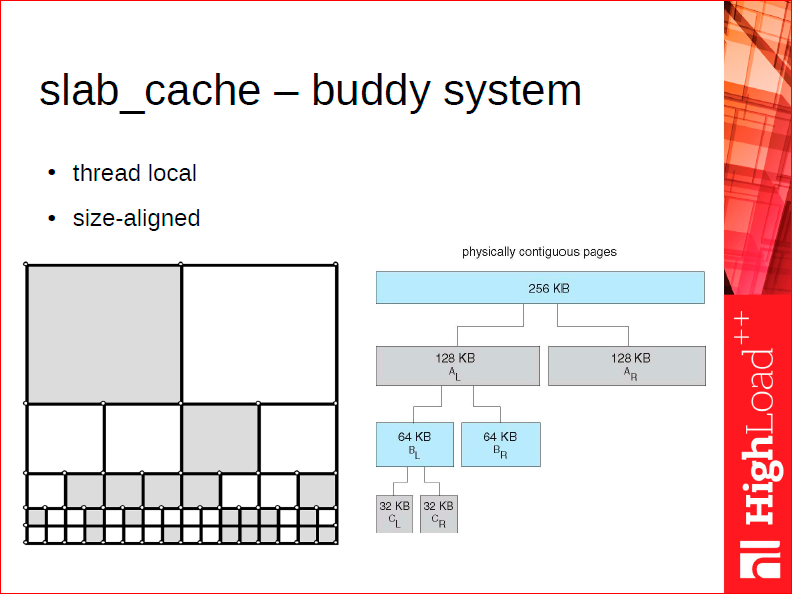
Часто такие большие куски памяти не нужны, нужны маленькие кусочки для каких-то аллокаторов нижнего уровня. Для этого у нас существует thread local аллокатор, который называет slab_cache, и который работает по так называемой buddy system.
Принцип buddy аллокатора следующий. Во время аллокации очень серьезной проблемой является проблема фрагментации памяти после того, как мы аллоцировали кучу памяти, потом ее освобождали, т.е. у нас есть частично заполненные куски. Допустим, вот наш большой slab в 4 Мб, который мы начинаем использовать. Buddy slab_cache умеет возвращать только куски, которые являются степенью двойки от 2 Кб до 4 Мб в дефолтном случае. Его преимуществом является то, что когда вы возвращаете кусок назад, т.е. вы им попользовались и вернули, он умеет находить его соседа – buddy. Если сосед тоже свободен, он объединяет двух соседей, т.е. он умеет дешевым образом находить и дефрагментировать память после деаллокации. Таким образом, в общем случае у вас память останется дефрагментированной достаточно долгое время, потому что во время работы со slab cache’ом, мы умеем ее обратно схлопывать.
Важный момент, который помогает в этом, – то, что мы предпочитаем адреса в более низком диапазоне адресного пространства при аллокации, т.е. при аллокации, вообще, на всех уровнях, мы стараемся найти первый наименьший свободный адрес. Если у вас система достаточно долго проработала, после этого она освободила какую-то память, потом она начинает аллоцировать память еще, мы стараемся сделать так, чтобы данные переехали вниз адресного пространства. Это тоже решает вопросы с фрагментацией.

Аллокатором более низкого уровня является классический pool аллокатор – object pool, который просто берет у slab cache объекты, slab’ы, допустим, 2 Кб, 4 Кб, эти slab’ы размещает и без какого-либо оверхеда умеет аллоцировать в них объекты одинакового размера. Его основное ограничение – он не умеет аллоцировать объекты разного размера.
Допустим, у нас есть объект connection или объект fiber, или объект user, которые достаточно горячие – часто алоцируются и деалоцируются. Мы хотим, чтобы аллокация таких объектов была сравнима с аллокацией их на стеке, и для этого мы используем выделенные mempool’ы. Не всегда можно обойтись выделенным mempool’ом, потому что не всегда система такая, что мы знаем размер объекта заранее.

И конкретно для данных мы пользуемся основанным на mempool’e классическим slab аллокатором, но на самом деле он достаточно занятным образом подтюнен. В классическом slab аллокаторе размер объекта не известен во время деаллокации. У нас такого ограничения нет, мы знаем размер данных, которые мы деаллоцируем. За счет этого мы можем использовать slab’ы разного размера для разных типоразмеров объекта. Посмотрите на картинке – есть объекты размера 24 байт или до 24 байт – для них мы используем, допустим, slab’ы 4 Кб. Объекты размера 32 – по-прежнему slab’ы 4 Кб, 40 – по прежнему slab’ы 4 Кб, 48 – мы уже используем slab’ы 8 Кб. Таким образом, у нас может быть очень много таких типоразмеров маппинг, которые не отъедают память.
Классическая проблема обычного slab аллокатора – то, что он вынужден для каждого типоразмера завести хотя бы один slab. Т.е. если у вас, допустим, 200 типоразмеров, то размер slab’а у вас 4 Мб, вы саллоцировали по одному объекту в каждом типоразмере – у вас уже – фигак! – 800 Мб в памяти занято чем-то, но оно не занято, оно начало использоваться. Потом эта система масштабируется, но в целом это не очень хорошая история. Поэтому обычно у классических slab аллокаторов – это трейдоффы между фрагментацией внутренней и внешней – сколько типоразмеров завести – много или мало. У нас этот трейдофф гораздо меньше, мы можем позволить себе шаг роста сделать на каждые 8 байт, т.е. фрагментации внутренней практически нет. На каждые 8 байт у нас есть свой slab.
Далее, мы сделали библиотеку доступной независимо от tarantool. Ее url – github.com/tarantool/small, пожалуйста, можете посмотреть коды, она очень маленькая, что тоже является, на мой взгляд, преимуществом. Содержится сама в себе и все, что я здесь недорассказал, вы можете просто rtfs.

Какой еще есть вид аллокации? У нас есть замечательный аллокатор, которым нельзя освободить память. Очень приятно, не надо думать об этом – аллоцируешь память и все. На деле, можно просто освободить всю память, которая была когда-либо аллоцирована в этом аллокаторе – это называется region аллокатор, региональный, т.е. он работает по принципу obj-стека. В JCC есть множество похожих аллокаторов в разных системах, в том числе, и open source. Важное преимущество нашей в том, что она вся выстроена в единую иерархию. Т.е. region аллокатор также пользуется slab кэшем как провайдером для своих slab’ов.
Почему нельзя написать такой хороший класс string, почему каждый программист пишет свой класс string? Потому что воедино сведены множество аспектов: аспект работы с памятью, один из немаловажный аспектов – копирование, какая семантика копирования, аспект работы с символами и т.д. Т.е. множество проблем решаются одним классом. Естественно, если делаешь такой универсальный инструмент, нельзя его сделать идеальным для всех случаев.
Если на всю эту историю посмотреть исключительно с точки зрения аллокации памяти, то чем строка, или просто буфер отличается от аллокатора? Да ничем. Чем аллокатор отличается от контейнера? У контейнера есть итерация, у аллокатора ее по умолчанию почему-то нет. У наших аллокаторов вы можете итерировать по объектам, в чем проблема? Мы знаем, какие объекты аллоцированы, а какие нет. Аллокатор – это контейнер, регион аллокатора – это строка. Это динамически растущий буфер. И в этом смысле, если говорить о стратегиях аллокации, их более-менее конечное количество, т.е. когда ваша строчка переполнилась, вы можете удваивать размер аллоцированного буфера, или вы можете использовать что-то типа каната, т.е. у вас строка может состоять из сегментов. Либо вы можете никогда не заморачиваться об освобождении памяти – просто копировать память на новое место и успокаиваться на этом. Так делает реаллок – он обнаруживает, что «у меня все еще есть «хвостик», который дефрагментированный оверхед, и который я могу использовать, и я не буду делать никакой реаллокации». Т.е. у вас фиксированное количество стратегий. И для этого фиксированного количества стратегий для работы с буферами, мы просто сделали три структуры. Это все сделано на Си, который эти стратегии реализует, т.е. удваивание при росте, сегменты и просто копирование на новое место.
Таким образом, у нас есть такой фундамент. Мы приходим к тому, что на этом фундаменте мы можем строить те структуры, в которых мы будем хранить данные и переходим к 4-ой части нашего доклада. Самая зубодробительная, изюминка, как вы видите, присутствует. О чем же здесь пойдет речь?
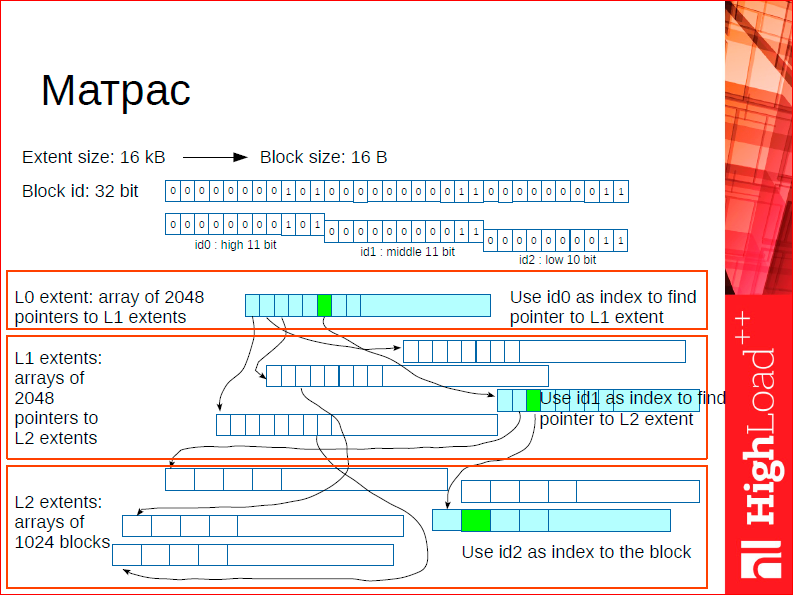
Есть одна структура данных, которая находится на границе между контейнером, аллокатором и деревом – эта структура данных у нас называется почему-то матрас. Почему матрас? Это такая хитрая аббревиатура (вы увидите, что мы падки на подобного рода вещи). Сама система называется small – это small object allocation. Матрас – это memory address translation. Т.е. матрас – это такая user space tlb. Это некая система, которая аллоцирует память и занимается трансляцией адресов в 32-х битное пространство. Причем, что важно, если у нас был бы просто транслятор, у нас есть, условно говоря, 8-ми байтный адрес, и мы хотим ему давать 32-х битные идентификаторы. Неизбежно нам нужно где-то хранить это отображение, нам нужно где-то хранить адреса. У нас используется лишняя память. Мы от этого избавляемся за счет матраса. Матрас одновременно является и аллокатором, и системой трансляции. Он аллоцирует объект, который обязан быть выровнен по размеру, он может быть либо 16 байт, либо 32, либо 64 и т.д. – должен быть степенью двойки. И возвращает его 32-х битный идентификатор. Как он работает?
По сути, это 3-х уровневое дерево. На первом уровне находится root блок и в root блоке хранятся указатели на extent’ы первого уровня. Общее количество таких extent’ов – 2048, потому что мы под адресацию в root блоке используем первые 11 бит 32-х битного числа. Попадая в extent, т.е. во второй уровень дерева, мы определяем то место, где конкретно хранится наш адрес – для этого наша память, т.е. для этого мы используем вторые 11 бит адреса. Это позволяет нам прыгнуть еще ниже, и в этом конкретном же месте находится наша память, т.е. там находится не указатель, а именно сама память, которая была выделена.
При деаллокациии мы работаем с этой системой как с классическим деревом, т.е. у нас есть лист свободных объектов. На самом деле, здесь освобождения окончательного не происходит никогда, но естественно освобожденные блоки складываются во free листы и их всегда можно повторно использовать. Производительность такой структуры данных – 10 млн. операций в секунду на более-менее среднем оборудовании. Именно из-за этого мы так боремся за хорошую работу с кэшами, потому что мы хотим, чтобы такая штука полностью влезла в l-3 кэш, тогда она будет работать эффективно.
Какое еще важное свойство у этой системы? Мы сделали ее многоверсионной, т.е. есть возможность поддерживать несколько версий одной и той же структуры данных. Для того чтобы сделать снепшот, мы можем заморозить матрас. Вы пробовали морозить ваш матрас? Мы замораживаем структуру данных, все обновления происходят с новой ее версией, мы замораживаем ее по классическому принципу многоверсионных деревьев – когда нам идет обращение на изменение к какому-то extent’у матраса, мы делаем копию, у нас copy on write классический при заморозке. После того, как происходит разморозка, т.е. мы сделали снепшот, мы добавляем размороженные сегменты в free лист и все. И начинаем ее повторно использовать. Возвращаясь, мы замораживаем эту структуру данных, получаем консистентную итерацию по всей памяти, которая была через нее аллоцирована.
Что тут важно? В этой структуре мы уже аллоцируем объекты наших индексов, т.е. наши индексы устроены так, что они всегда аллоцированы через матрас. Нас спрашивают, насколько Tarantool быстрее std::map? Вообще, быстрее, я про это расскажу. Но немаловажно, что мы еще и масштабируемся лучше, чем std::map через вот эту штуку.
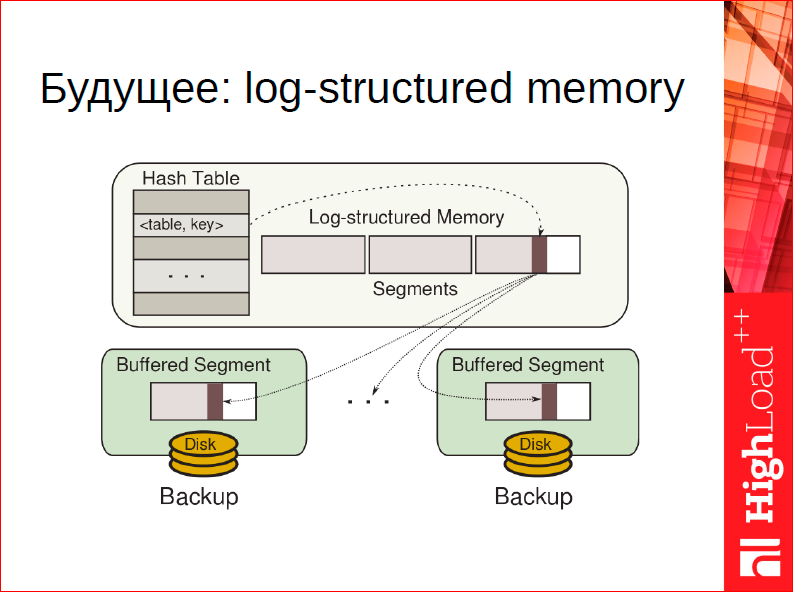
Если вспомнить эту нудную историю про многоуровневые аллокаторы, матрас как концепция позволит нам выкинуть (мы собираемся сделать это в релизе 1.7), по крайней мере, для хранения данных всю эту иерархию и весь этот slab аллокатор целиком. Потому что, если есть возможность транслировать адреса, т.е. подменять адреса на лету, можно просто сделать аллокатор, основанный на garbage collection, который заточен под наши нужды конкретно для данных.
Как такой аллокатор может быть устроен? Представьте, что у вас аллокация устроена по лог-принципу, т.е. для вас аллокация – это просто запись в некоем бесконечном журнале. Она всегда случается в конце журнала. Вы всегда аллоцируете, дописывая в конец: взяли 10 байт – прекрасно, взяли 15 – прекрасно, у вас нет никакого оверхеда, никакой фрагментации, вам всегда максимум, что нужно, выровнять границы слова, другой фрагментации у вас нет. Журнал полностью компактен. Шикарно.
Что же делать, когда память освобождается? Память освобождается, значит, где-то какие-то extent’ы журнала становятся фрагментированными, т.е. там есть как занятые куски, так и освобожденные. Что можно сделать? Можно взять наиболее дефрагментированный extent и полностью его переписать, полностью скопировать его в конец, выкинуть все свободное пространство, все освобожденные блоки, занятые блоки перекинуть в конец, подменить в матрасе адреса – все работает.
Мы уже сделали прототип такой штуки, к сожалению, он на практике работает медленнее, чем управление памятью вручную, но прекрасная сторона этого дела, что вообще нет никаких ручек, т.е. у нас сейчас есть slab аллокатор, который пользователь должен крутить. Здесь у вас фрагментации нет никакой, максимум ручка для пользователя, которую мы можем дать в этой ситуации – это как активно мы хотим дефрагментировать старую память. Мы собираемся сделать это. Таким образом, матрас является фундаментальной штукой в архитектуре, мы на его основе собираемся строить дальнейшие структуры.
Что же мы уже построили?
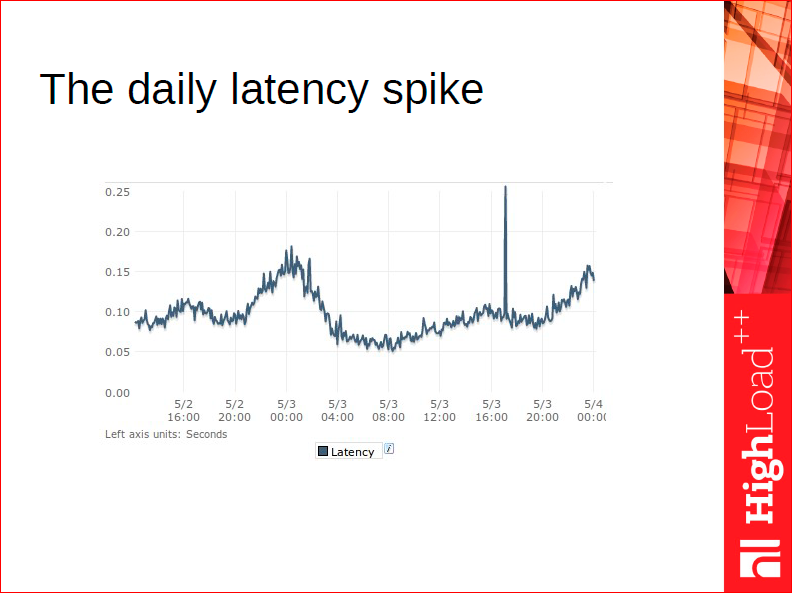
Прежде чем я расскажу о наших хэшах, поговорим о классических хэшах. Что характерно для начинающего веб-программиста? Нам всем хорошо известно, что хэш – это самая быстрая структура данных – у нее асимптотически константная стоимость поиска. Прекрасно, мы начинаем использовать хэш абсолютно для всего. Запиливаем нашу маленькую систему, она идет в продакшн, а потом мы начинаем искать ведьм. Ведьм в виде вот таких прыжков во времени ответа, которые случаются раз в день, раз в два, раз в неделю, когда уборщица цветы полила, мы не знаем, откуда они идут, почему они не случаются на наших тестах? Мы не можем эту систему смоделировать, они случаются только в продакшне.
Я об этом с таким сарказмом говорю, потому что в своей жизни я видел это неоднократно, когда С++ программист берет хэш, хранит в нем, например, всех пользователей. Потом вечером народу прибавляется на сайте, количество пользователей увеличивается, происходит ресайз хэша. Пока ресайз хэша происходит, все курят, все ждут, мы его видим вот так на графике, поэтому классические хэши просто не подходят для СУБД, потому что если у вас огромное количество данных, вы не можете себе позволить делать ресайз.

Тут мы подходим к самой зубодробительной истории во всей презентации – именно то, как устроен наш хэш с линейным ростом. Т.е. наш хэш не ресайзится никогда. Точнее, он ресайзится всегда, он ресайзится на каждую вставку. Как это работает?
Начнем с того, что базовым объектом хэша является структурка из 16 байт. Значение 8 байт – либо это ключ, либо это указатель на данные, и два 32-х битных числа – хэш от ключа и указатель на следующий элемент. Он в правом верху слайда сделан.
Дальше ключевым параметром хэша является маска. Маска – это та степень двойки, которая покрывает текущий размер. Т.е. если у нас текущий размер хэша, в котором сейчас 3 элемента, то маской будет 4, если в хэше 4 элемента – 4, 5 элементов – маска 8. Таким образом, у нас есть виртуальный размер хэша. И виртуальный размер хэша ресайзится классически, но это только число, фактически этой директории с хэш таблицей у нас нет. При каждой вставке мы добавляем 1 элемент в хэш.
Еще важный элемент – есть указатель на текущий бакет, который можно ресайзить. Допустим, у нас количество элементов в хэше – 2, указателем на текущий бакет будет 0. Мы добавили новый элемент, мы при этом делаем сплит нулевому бакету и передвигаем указатель на следующий, мы добавляем следующий элемент, мы делаем сплит первому бакету, и у нас появляется 4 бакета, и мы рестартуем наш счетчик ресайза, у нас 4 бакета – счетчик ресайза находится на нулевом бакете. Добавляем 5-ый элемент, снова сплитаем нулевой бакет. У нас появляется 5 элементов, нулевой бакет засплитан, маска равна 8-ми. Таким образом, добавляем элементы, доходим до 4-х, снова расплитали первые 4 элемента, у нас появилось 8 элементов. Так переустанавливаем счетчик на 0 снова, есть указатель на текущий бакет, которым будем сплитать при вставке, и каждая вставка приводит к сплиту.
Дальше может произойти следующая вещь – мы можем попасть при вставке на оверфлоу, т.е. мы можем попасть на оверфлоу чейн, т.е. на коллизионную цепочку. Мы можем при вставке попасть ровно на тот бакет, который мы ресайзим – тогда все вообще хорошо, мы просто вставляем новое значение по биту, либо мы можем попасть в бакет, который мы не ресайзим при хэшировании, но у нас есть гарантия, что у нас есть место куда вставить. При каждой вставке мы добавляем 1 элемент.
Еще на всю эту систему можно посмотреть следующим образом: этот cоver или маска определяет значимые биты в хэше, которые учитываются при положении значения в хэше. Когда мы ее удваиваем, у нас следующий бит становится значимым, и мы ресайзим, постепенно учитывая этот значимый бит.
Поищите в литературе «линейное хеширование для двухуровневого хранения для диска». Вы найдете достаточно явное объяснение. Я впервые познакомился с этой системой, когда работал в MySQL, и мы называли это Monty Hash, потому что это именно так был сделан хэш в MySQL. И мы долгое время им пользовались.
В чем собственно главный поинт? Сделать так, чтобы затраты на ресайз хэш таблицы были равномерно распределены, и они не влияли на общую производительность.
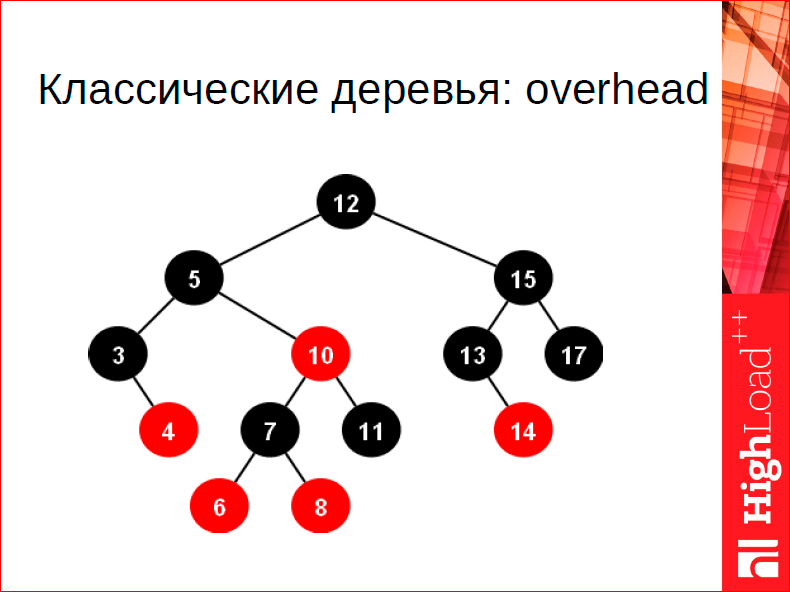
Деревья у нас тоже особенные. Что в них особенного? В Tarantool 1.3 и 1.4 использовались классические деревья для оперативной памяти, и они достаточно неплохие, но что плохого в классическом дереве? Две вещи: первая – это оверхед на указателе, каждая вершина имеет два указателя, а это слишком дорого, 16 байт тратить на одно значение, которое мы храним в дереве – это дорого, мы не хотим этого. Второе – это сбалансированность. Даже AVL деревья достаточно хорошо сбалансированы, но по сравнению с B деревом, о котором буду рассказывать дальше, баланс неудовлетворительный, я потом покажу цифры – баланс недостаточный, т.е. можно на существенное количество, на 30-40% баланс улучшить. И как следствие такой организации, они совершенно недружелюбны к кэшу, т.е. каждый переход по дереву наиболее вероятно приведет к тому, что вам потребуется кэш лайн, которого у вас в кэше нет, потому что, вероятно, что ваши узлы каким-то образом случайно размазаны по адресному пространству, соответственно вы предиктору не можете ничего сказать хорошего про то, по какому адресу вы обратитесь. Поэтому мы сделали свои деревья – это B+* деревья:

В чем идея? В том, что в каждом блоке мы храним не один элемент, а много – 20 элементов, в среднем, может быть, 40. И мы делаем это хранение таким, чтобы это хорошо ложилось на кэш, чтобы мы могли в блоке искать возможность, не переходя по кэш линиям, чтобы оно все уместилось в кэш лайн.
Далее, мы храним элементы только в листьях для того, чтобы этот заголовок дерева сделать как можно компактнее, чтоб он опять же уместился в кэш. Мы листы прошиваем насквозь, делая итерацию по дереву быстрой. Т.е. для того, чтобы итерировать по дереву, нам нужно возвращаться к вершине, мы итерируем по листьям. И мы используем матрас для аллокации, для того, чтобы иметь возможность замораживать деревья, для того, чтобы указатели были 32-х битные на узлы дерева.
Это примерно так устроено:

В среднем, дерево 3-х уровневое, обычно при каких-то более-менее реальных размерах таблицы. Это дерево, которое очень хорошо сбалансировано.
Чем отличается B+дерево, B+* дерево от классических B деревьев, которые хранят в промежуточных вершинах данные и т.д.? Это дерево гарантирует заполненность каждого блока на 2/3, заполненность элементами, для того, чтобы эту заполненность гарантировать при ребалансе. Это классический закон. Если вы хотите заполнить, чтобы у вас средняя была 1/2, вам при перебалансировке достаточно посмотреть на соседа и между текущим узлом и соседним узлом перетасовать каким-то образом элементы. У него в среднем 1/2, у вас в среднем 1/2 – должно поместиться, если не помещается, то вам однозначно нужно делать сплит, и у вас средняя заполненность сохранится, у вас по-прежнему будет 1/2 заполненность. Когда у вас средняя заполненность 2/3, т.е. вы хотите достичь более высокого показателя, вам при перебалансировке нужно смотреть не на одного соседа, а на двух, а то и на трех, зависит от конфигурации. И, соответственно, вы между ними распределяете ваши данные. Перебалансировка такого дерева достаточно дорогая, но зато дерево очень хорошо сбалансировано.
Какие у нас есть результаты?

У нас низкий оверхед на единицу хранения, и у нас очень хорошая сбалансированность, т.е. при поиске у нас в среднем 1.1 log(N) операций сравнения. Более того, эти операции сравнения очень хорошо работают с кэшем, потому что все эти блоки дерева хорошо влезают в кэш.
На самом деле, дерево настолько хорошее, что мы иногда даже не понимаем, что быстрее – хэш или дерево в 1.6. Хэш сейчас по нашим измерениям примерно на 30-40% быстрее, т.е. там логарифмическая сложность, а там – константная, а выигрыш всего 40 %, потому что этот логарифм выражается по факту всего лишь в просмотре 2-3-х кэшлайнов, а в хэше это может быть среднее значение 2 кэшлайна просмотров. Т.е. стоимость структуры данных измеряется у нас не в классических операциях, а в том, насколько качественно они работают с кэшом.
Контакты
» kostja
» Блог компании Mail.ru
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
Константин — член Программного комитета HighLoad++ и наш постоянный докладчик. В 2016 году Костя будет рассказывать про новый движок хранения в Tarantool в докладе "Хранение данных на виниле".
Кстати, весь Программный комитет HighLoad++ дружно рекомендует платформу Tarantool. Это одна из замечательных наших (российских) разработок и, как минимум, заслуживает внимания.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Вы и база данных Tarantool?
20.57% Никак от слова «совсем»43
62.2% Я слышал про это базу данных, но пока не использовал130
7.66% Я пробовал ковырять, но ничего толком не наковырял16
3.35% Всё серьезно, мы планируем использовать Tarantool в нашем проекте7
6.22% Мы уже используем Tarantool в нашем проекте!13
Проголосовали 209 пользователей. Воздержались 29 пользователей.
