
Аникин Денис (danikin, Mail.Ru)

Сегодня я расскажу, как сэкономить на базах данных огромные деньги, например, миллион долларов, как это сделали мы. Для начала вопрос: почему чаще используют именно базы данных, а не файлики?
Базы данных – это хранилище, более структурированное, чем файл, и обладающее рядом некоторых фич, которых у файла нет.

Там можно делать запросы, там есть транзакции, индексирование, таблицы, устойчивые, более-менее надежные хранилища. На самом деле, базы данных – это более удобно, чем файлы.
Представьте, у вас есть приложение, оно работает с базой данных, оно нагружает эту базу данных пока только на чтение, т.е. там не очень большое количество записей, но большое количество селектов.
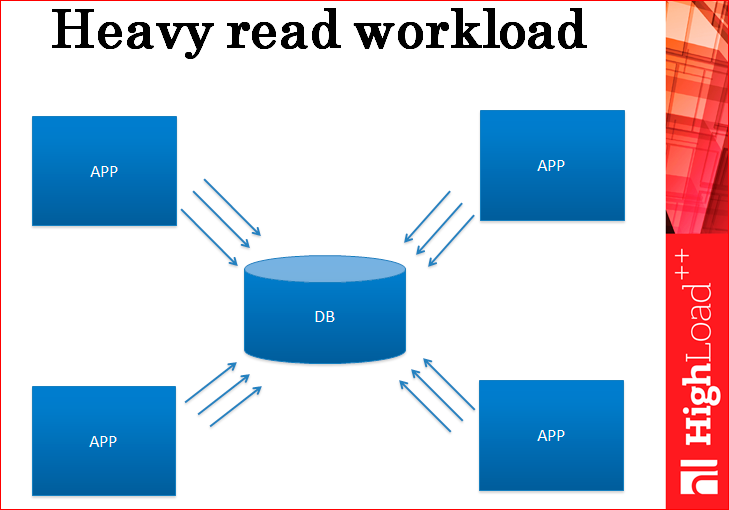
В конечном итоге, у вас база данных перегружается и не может справляться с нагрузкой.
Что обычно в таких случаях делают? Еще один сервер. Это репликация. Т.е., по сути, вы доставляете реплики ровно в таком количестве, чтобы они держали вашу нагрузку.
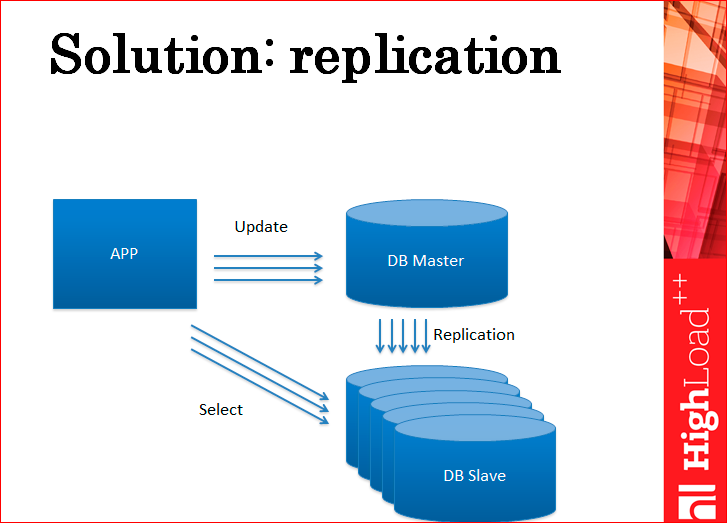
Вы всю нагрузку на чтение уводите на реплики. Соответственно, нагрузку на запись вы оставляете на мастере. Эта схема может, в принципе, масштабировать нагрузку на чтение практически до бесконечности.
Дальше у нас происходит нагрузка на запись.
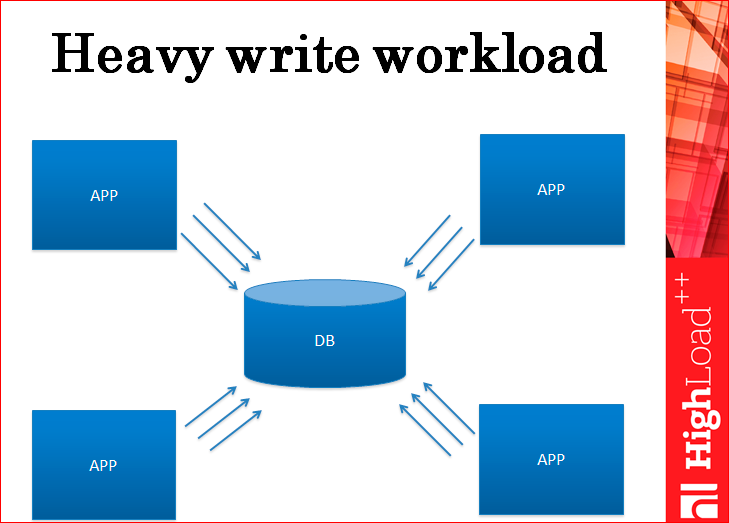
И нагрузка на запись, опять же, достигает какого-то предела, когда база данных уже не может ее держать. Поможет в данном случае репликация? Нет. Какая бы не была репликация – мастер-слейв или мастер-мастер – она не поможет нагрузке на записи, потому что каждая запись должна пройти на все сервера. Даже если там мастер-мастер, значит, сколько у вас идет суммарно запросов на весь ваш кластер, ровно столько же пойдет на каждый из серверов, т.е. вы этим ничего не выиграете.
Какие есть еще идеи?
Шардинг.
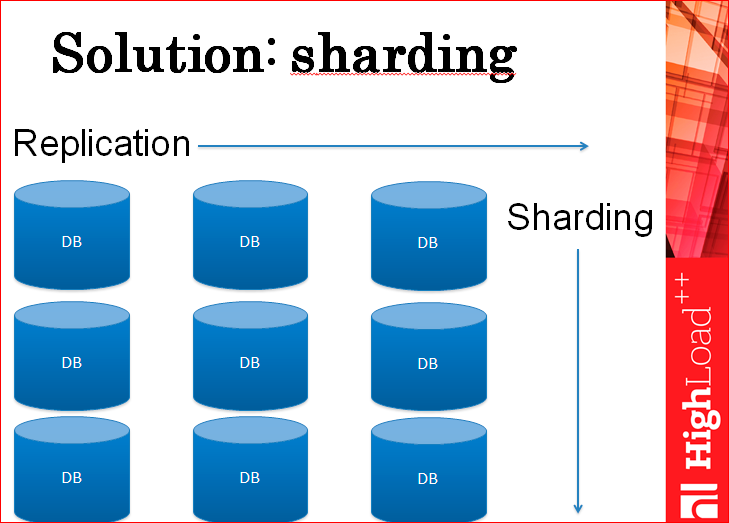
На самом деле, шардингом можно решить проблему нагрузки на запись и масштабировать почти до бесконечности.
Есть много разных способов шардинга – можно резать по базам данных, можно резать по таблицам, можно резать внутри одной таблицы. Способов – миллион. Каждый использует тот способ, который ему удобней.
По сути, у вас получается такой двухмерный кластер из баз данных, т.е. у вас много-много шардов и у каждого несколько реплик. Вы доставляете шарды, реплики, и варьируете совершенно любую нагрузку.
Но дальше у вас происходит проблема. Ваша следующая проблема – это ваш босс. Что ему в этом может не нравиться? Вроде как, все работает, все шардируется, реплицируется, но что ему не нравится? Деньги. Ему все нравится, кроме того, что это стоит очень дорого, потому что вы доставляете, доставляете, доставляете сервера, и он за это платит.
Вы ему говорите: «Чувак, ты не понимаешь, у меня тут технология, у меня тут шардинг, репликация… Оно масштабируется бесконечно – это очень крутая система».
Он вам говорит: «Да-да, но мы теряем деньги, если так пойдет дальше, у нас просто не будет денег, чтобы покупать сервера баз данных. Нам придется закрыться».
Что же делать?
На самом деле, нагрузка на базу данных часто бывает устроена так, что какие-то элементы данных на чтение нагружаются очень-очень сильно – они называются «горячие данные».
Кэширование – это то, что частично решает нашу проблему.
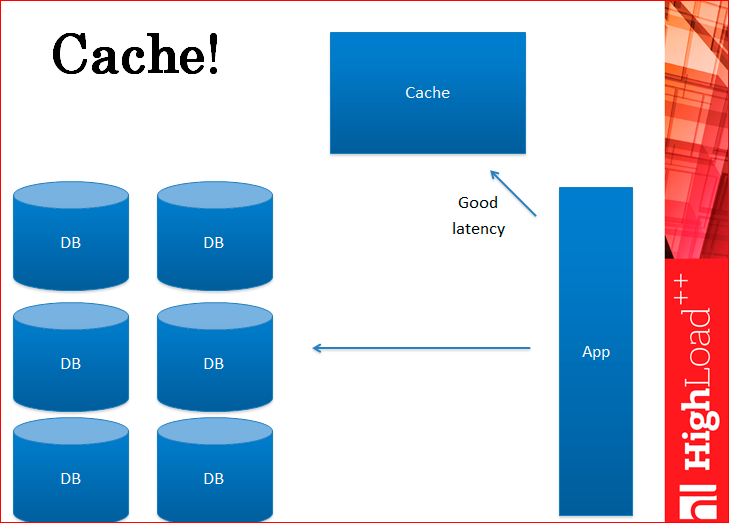
Вы можете убрать часть реплик и таким образом чуть-чуть удовлетворить вашего босса. Кстати говоря, вы получаете и лучший лейтенси, т.е. запросы отрабатывают быстрее, потому что кэш работает быстрее, чем базы данных.
Но… какая есть проблема? Проблема несогласованности – одна из самых больших проблем, которая есть с кэшем.
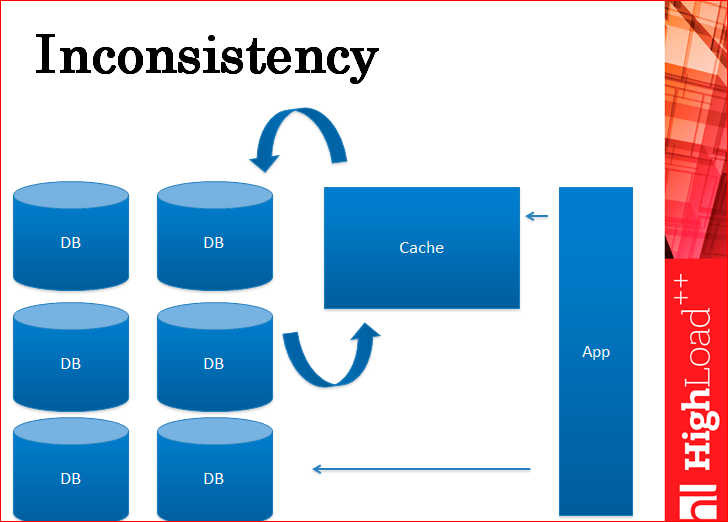
Это самая первая проблема, которая тут же видна.
Смотрите, у вас приложение отдельно пишет в кэш, например, в Memcached и отдельно пишет в базу. Т.е. кэш не является репликой базы, кэш является отдельной сущностью. Тут нарисованы стрелочки между кэшем и базой, которые на самом деле виртуальны, т.е. никакой репликации между ними нет. Все делается на уровне приложения. Соответственно, это приводит к несогласованности данных.
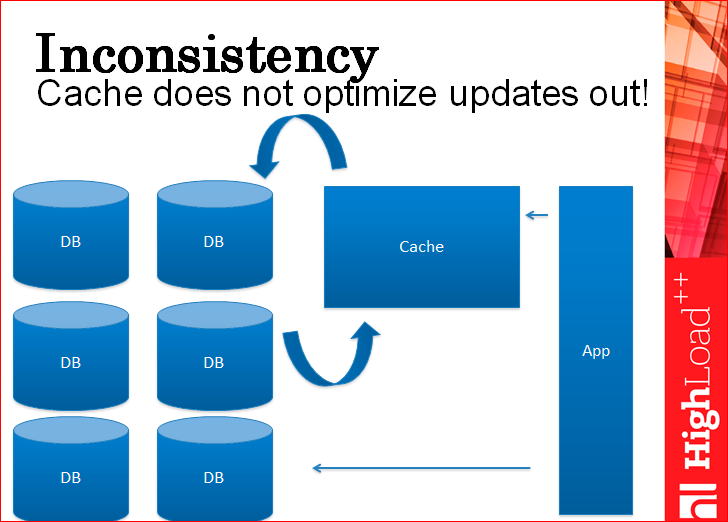
И, кстати, у вас все еще остается шардинг, потому что кэш записи не оптимизирует, потому что в кэше нельзя ничего хранить, через него все пролетает насквозь в базу данных. Ну, не насквозь, а сбоку от него, но пролетает.
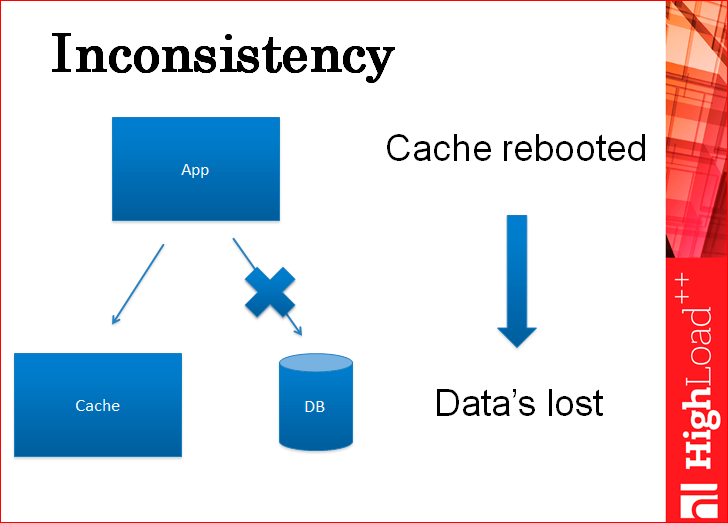
Тут картинка, чтоб показать вам, что вы можете писать сначала в базу, потом в кэш, или сначала в кэш, потом в базу. В обоих случаях у вас будет несогласованность. Смотрите: вы пишете данные в кэш, после этого ваше приложение благополучно падает и в базу их записать не успевает. Приложение поднимается и работает с теми данными, которые уже в кэше, а в базе данных их нет, но никто про это не знает. Когда кэш перезагружается (а он когда-нибудь перезагружается), вы получаете из базы данных при пустом кэше устаревшие данные.
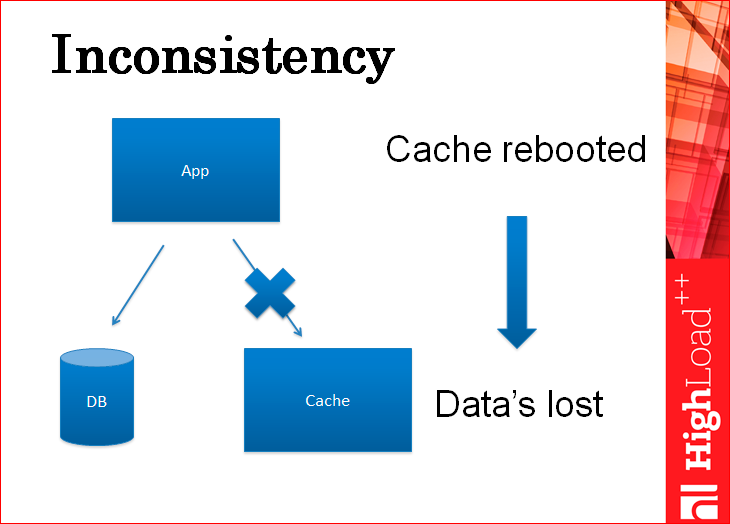
Как ни странно, если писать в обратном порядке – сначала в базу, потом в кэш, будет ровно такая же проблема: записали в базу, приложение упало, в кэше старые данные, все работает со старыми данными, кэш перезагрузился, потянул из базы новые данные, как бы другую ветку данных, которые не целостные, которые не соответствуют тем изменениям, которые были сделаны поверх другой копии…
Т.е. с кэшем есть как минимум две проблемы: нет целостности данных, и вам все еще нужен шардинг.
Какие есть еще проблемы с кэшем? Какие вы кэшем внесли проблемы в тот момент, когда ваш босс начал сердиться? Проблема такая: кэш – это не база данных.

У вас до кэша была база данных, там были запросы, транзакции, и все эти штуки из кэша почти все пропадают, у вас приложение работает уже с кэшем. Индексы и таблицы остаются, не во всех кэшах есть вторичные индексы, не во всех кэшах есть таблицы, но как-то криво-косо поверх key-value и то и другое можно поддержать, поэтому мы считаем, что эти свойства соблюдены, а остального всего нет.
Теперь по поводу проблемы нецелостности данных. Что с ней сделать? Как сделать так, чтобы данные обновлялись и в кэше и в базе целостно? Умный кэш.
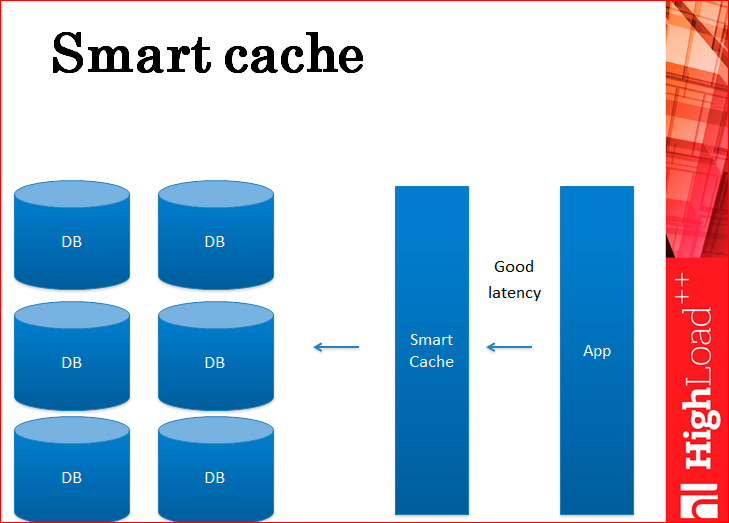
Что такое умный кэш? На самом деле, многие из вас, скорее всего, это делают – это, по сути, кэш, который сам общается с базой данных. Т.е. это не отдельный демон Memcached, а какой-то ваш самописный демон, который внутри себя все кэширует и сам пишет в базу. Приложение в базу не пишет, оно работает полностью через кэш.
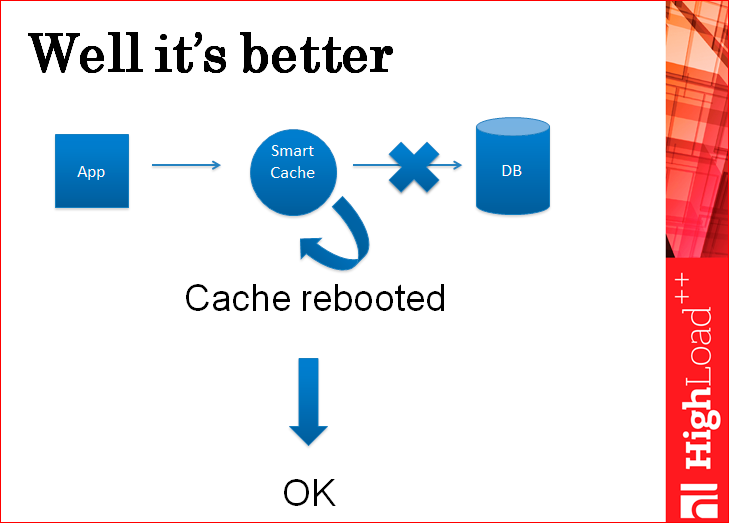
Это решает проблему нецелостности, потому что кэш сначала пишет в базу, а потом пишет в себя. Если он в базу не записал, отдал ошибку – все хорошо. Это конечно не хорошо, но данные целостные. После того, как кэш записал в базу, он в себя запишет данные обязательно, потому что он пишет в память, такого, чтобы данные не записались в память практически никогда не бывает. Вернее, бывает, когда на сервере бьется память и в этот момент все падает, и все равно вы теряете весь кэш, по крайней мере, целостность данных не теряется.
Но есть один кейс, когда даже при таком умном кэше данные можно потерять.
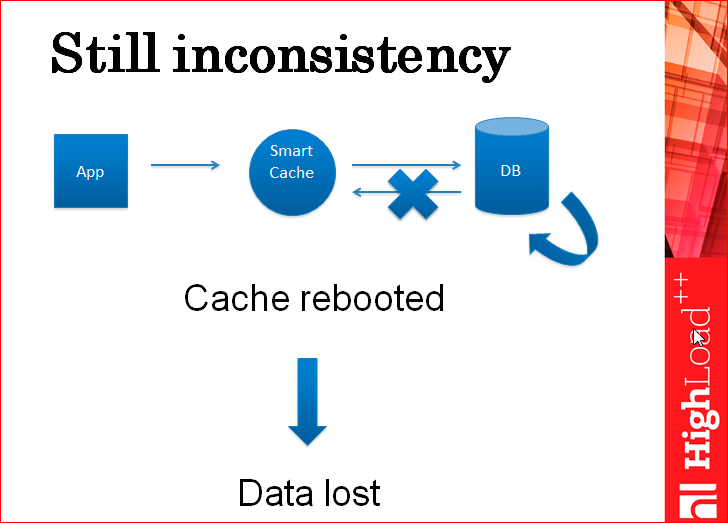
Приложение пишет в кэш, кэш пишет в базу, база внутри себя применяет эту запись, дальше она отдает ответ кэшу, и в этот момент рвется сеть. Кэш считает, что запись в базу не прошла, в себя данные не пишет, отдает пользователю ошибку. После этого кэш начинает работать с теми данными, которые есть в нем, а после его перезагрузки он подцепляет из базы данных опять устаревшие данные.
Это редкий кейс, но такое тоже бывает. Т.е. умный кэш не решает до конца проблему нецелостности данных. И вам все еще нужен шардинг.
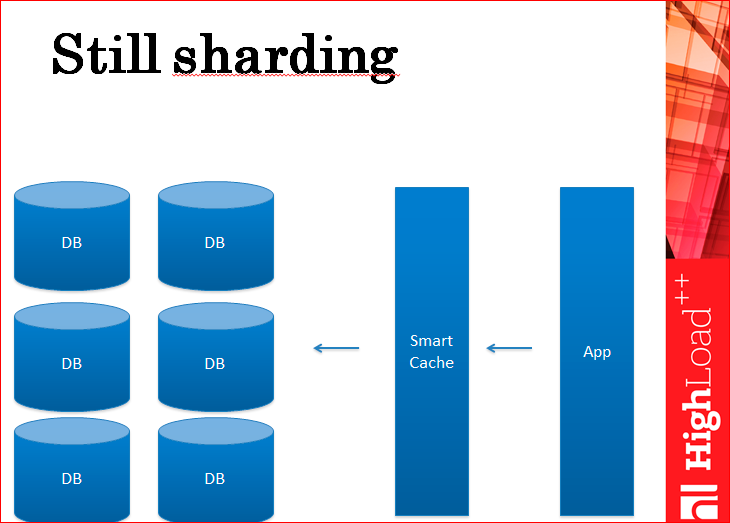
Шардинг – это когда у вас есть база данных, которая на одном сервере, и вы ее просто режете. Вы ее режете на кусочки и эти кусочки укладываете по разным серверам, физическим серверам. Это уменьшает нагрузку на запись, потому что нагрузка на запись идет на конкретный кусочек. Т.е. у вас, по сути, все CPU, например, всех серверов участвуют в обработке этой нагрузки, а не CPU только одного сервера.
Шардинг у вас все равно остается, а вы помните, что ваш босс не любит шардинг, потому что это очень дорого, потому что много-много серверов и у каждого еще реплики.
Итак, нецелостность данных, к сожалению, остается с кэшем, шардинг все еще нужен, свойств баз данных нет.
Какая еще очень неприятная проблема с кэшем есть? Холодный старт.

Это супер неприятная проблема, когда кэш поднимается с нуля, чистый, голый, без данных… Он бесполезен, также как машина, полностью заваленная снегом – в нее вначале нужно залезть, а еще ее нужно завести. Холодный старт полностью убивает кэш, все запросы напрямую летят в базу данных.
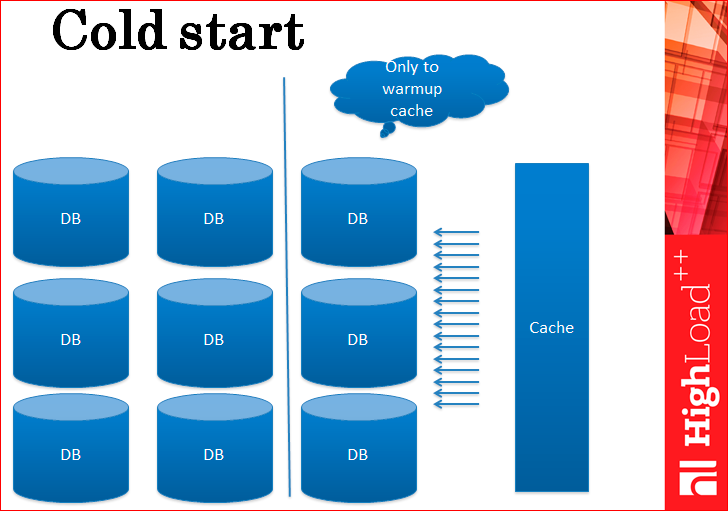
Приходится делать действие, которое, опять же, ваш босс не одобряет, но что поделаешь? Приходится доставлять реплики только для того, чтобы прогреть кэш. На самом деле, этот слой реплик – для каждого вашего шарда вы доставляете по реплике – только для того, чтобы прогреть кэш. Вы не можете эти сервера отключить или выкинуть, когда кэш прогрет, потому что вдруг сервер с кэшем перезагрузится ночью? Все равно все должно работать ночью, эти сервера должны тут же пойти в нагрузку и обеспечивать прогрев кэша. Кэш прогрелся, и они уже не нужны, но опять их никуда не деть.
Четыре проблемы с кэшем:

Вопрос: как прогреть кэш? Кэш всегда должен быть прогрет, чтобы он имел смысл. Через базу данных его прогревать как-то не аккуратненько, потому что много-много реплик, и они все его греют-греют – слишком дорого они его греют.
Персистенс – правильное слово. Кэш лучше просто не охлаждать, его нужно персистить, потому что кэш – хорошее и быстрое решение, за исключением нескольких проблем, включая проблему холодного старта, включая то, что он иногда недогрет, так пусть он будет всегда согрет. Как, например, в Сибири некоторые люди не глушат машины, чтобы они были всегда заведенные, потому что иначе ты ее потом не заведешь – примерно из той же оперы.
Какой самый простой способ персистента для кэша?
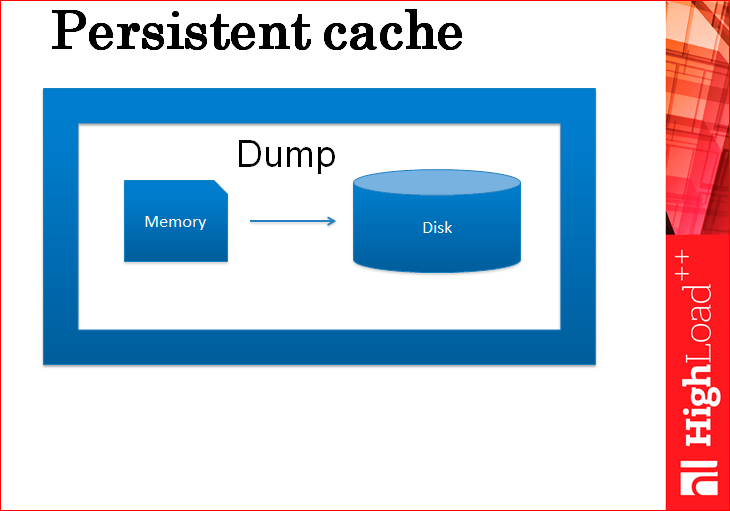
Это просто dump данных. Т.е., на самом деле, мы каждый раз, может быть, в минуту, или, например, раз в 5 минут дампим весь кэш полностью на диск, прямо целиком. Как вам это решение? Отстой, потому что теряется консистентность. Вы раз в 5 минут дампите, у вас как бы сервер поднимается, и он теряет свое изменение за 5 минут. Через базу данных их прогревать нельзя, и даже непонятно, откуда эти изменения взять. И это не единственная проблема.
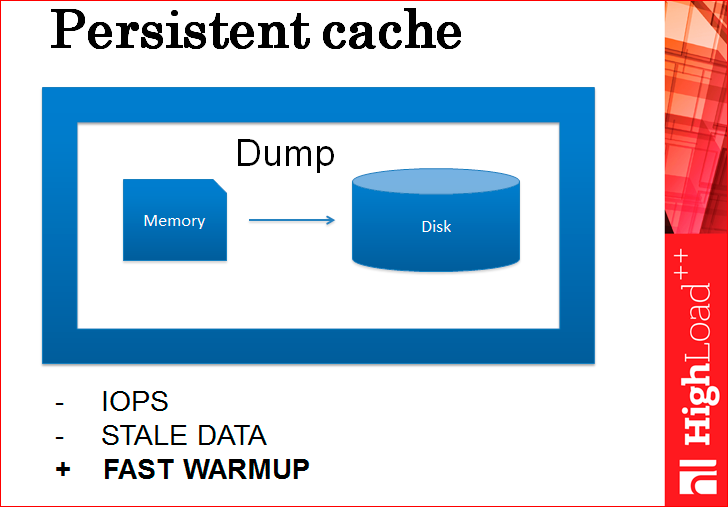
Вторая проблема – это то, что по IOPS’ам будет плохо, т.е. постоянно будете нагружать диск. Дампами, дампами и еще раз дампами, постоянными. Чем вы хотите иметь более целостные данные, тем чаще будете дампить. Какой-то не очень приятный путь.
Как лучше персистить кэш?
Лог. Нужно просто вести лог.
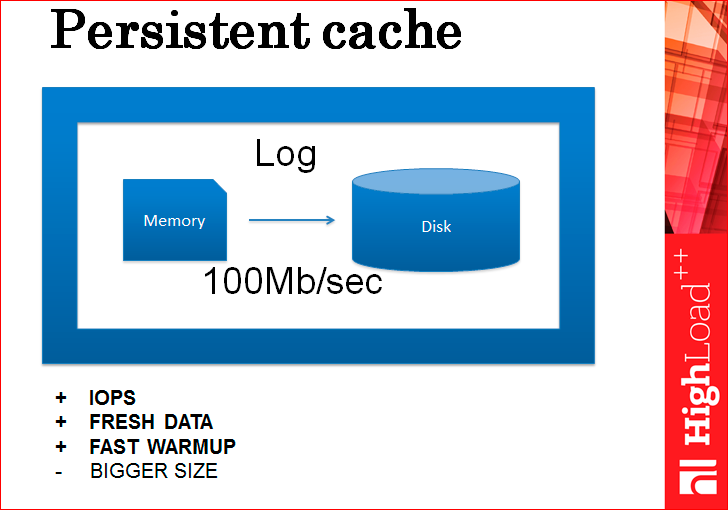
Т.е. зачем нам дампить, давайте вести лог, давайте каждое изменение кэша будет логироваться на диск, каждое.
Если вы думаете, что это медленно (всегда есть мнение, что кэш – это что-то такое быстрое, а когда там появляется диск, то это становится как-то медленно), так вот, на самом деле, это не медленно, потому что даже самый обычный крутящийся магнитный диск, не SSD, пишет со скоростью 100 Мб/с, последовательно пишет. Если размер транзакции, скажем, 100 байт, то это 1 млн транзакций в секунду. Это неимоверная скорость, которая удовлетворит почти всех присутствующих в этой аудитории, может быть даже меня. Поэтому даже один диск с этой задачей вполне справляется, но есть другая проблема, что этот лог разрастается очень сильно, потому что, например, идет 10 инсертов, потом 10 делитов тех же самых данных, они должны все схлопнуться, а в логе они не схлопываются. Или идет 100 апдейтов одного и того же элемента данных, опять же нужен только последний, а в логе хранятся все. Как эту проблему решить? Сшепшоты делать.
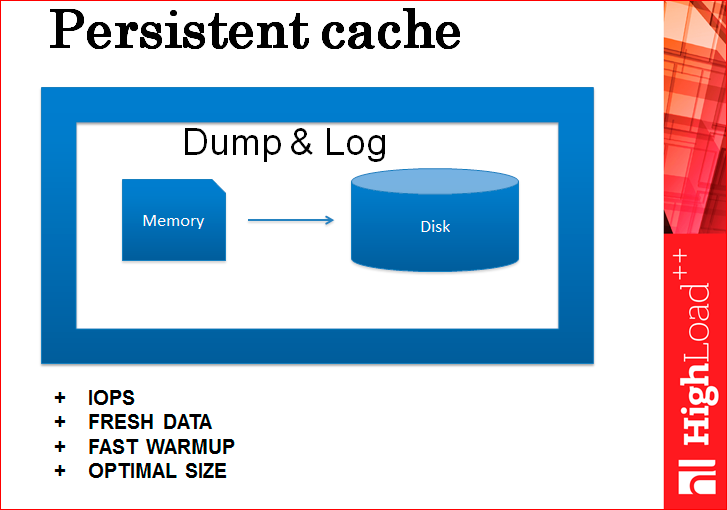
Нужно соединить два этих метода – Dump и Log воедино. Т.е. мы раз в неделю дампим, или когда нам этого хочется, а все остальное время только пишем лог. В дамп мы еще запоминаем id последней примененной записи из лога или последней записи из лога, которая в этом снепшоте еще есть. И когда у нас сервер перезагружается, мы поднимаем с диска dump, восстанавливаем его в памяти и сверху накатываем тот кусок лога, который после этой записи. Все, кэш восстановлен и прогрет сразу.
Кстати, этот прогрев происходит быстрее, чем из базы данных. Вот такого рода прогрев при перезагрузке потом полностью попадет в диск, потому что это линейное чтение файла – 100 Мб/с. Даже на магнитных дисках это очень быстро.
Все, проблема холодного старта решена, но это только одна проблема, к сожалению. Хотя кэш прогрет, есть еще 3 проблемы.

Давайте подумаем, как решить первые две – проблемы неконсистентности и шардинга?
Идея использовать кэш как базу данных – это очень правильное направление. Действительно, зачем нам в этом месте наша основная база данных? MySQL или Oracle – зачем она нам нужна? Давайте подумаем.
Нужна, наверное, для 2-х вещей:
- мы считаем, что база данных надежно хранит данные, не как кэш, а надежно, т.е. там, наверное, есть какая-то магия;
- то, что в базе данных есть репликация. У кэшей обычно репликации нет. Соответственно, кэш сервера вышел из строя или просто перезагрузился, и пока он не поднимет все с диска, это быстрее, чем прогрев, но все равно будет down time – это тоже плохо, а репликации там нет.
По первому пункту – надежное хранение. Если разобраться, то что хранит база данных? База данных хранит горячие и холодные данные – это по сути все, что она хранит. Горячие данные – это обычно маленькие-маленькие и очень-очень горячие, которым 10-100 тысяч RPS, а холодные данные – это такие большие и холодные, к ним очень мало обращений.
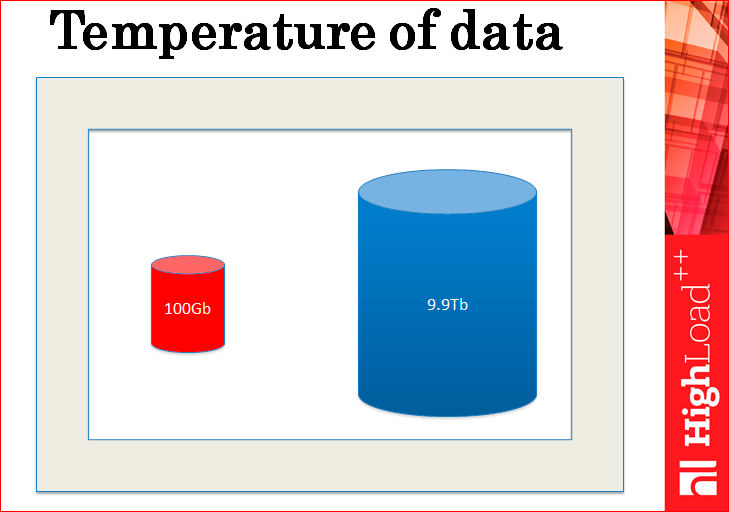
Всегда получается так, что холодные данные большие, а горячие – маленькие. Это закон жизни.
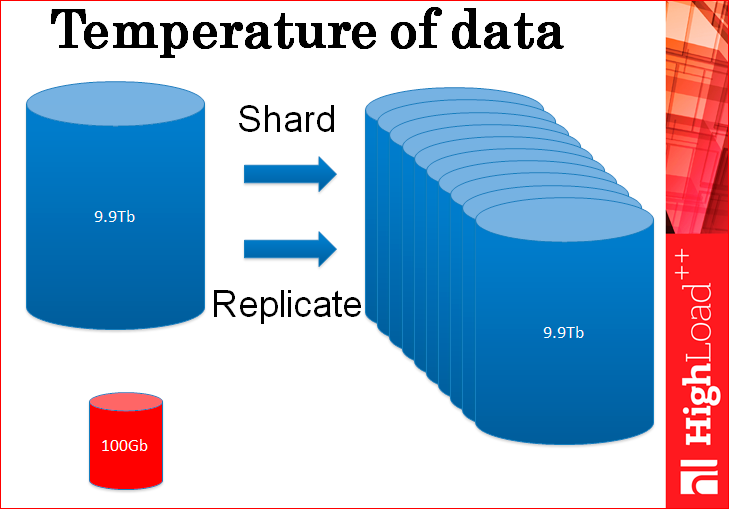
По сути, вы реплицируете и шардируете вашу базу данных в большом количестве копий только лишь для того, чтобы обрабатывать этот маленький кусочек горячих данных, потому что к остатку холодных данных нет большого количества запросов, он нормально себя чувствует. Но вы все это реплицируете только ради горячих данных.
Зачем мы делаем все это копирование? Мы можем, наверное, копировать только горячие данные?
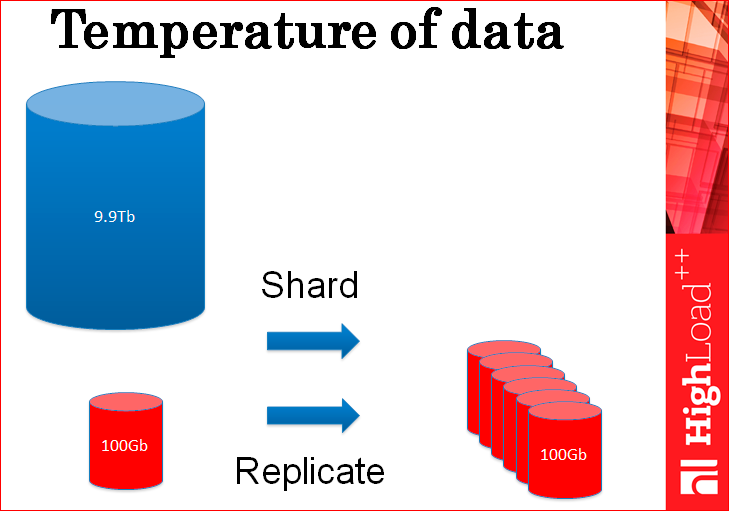
Но и тут та же самая проблема – ведь нагрузка идет именно на горячие данные и поэтому, если вы будете реплицировать и шардировать только их, проблема никуда не исчезнет, вам нужно ровно столько же серверов, чтобы обработать всю эту огромную нагрузку.
И ваш босс все еще злой, потому что у вас все еще есть шардинг.
На самом деле, мы говорим, что базы данных надежно хранят данные, но наш кэш сейчас тоже надежно хранит данные, потому что у него есть транзакшн лог – файл, в который пишутся все изменения. Это не что иное, как лог транзакции, это то же самое, что есть у любой базы данных, это ровно то, за счет чего обеспечивается надежное хранение в любой базе данных, никакой магии, и у кэша есть то же самое.
Репликации нет. Это, конечно, плохо, но давайте подумаем, почему кэш не может быть первичным источником данных? Потому что нет репликации? Хорошо, мы ее сделаем.
Почему еще кэш не может быть первичным источником данных? Потому что он не обладает свойствами баз данных? Мы тоже можем это сделать, мы можем все эти свойства баз данных поддержать, и кэш будет ими обладать. Помните картинку «Кэш – это не база данных»?

Кэш может быть базой данных. Он может всеми этими свойствами обладать.
В кэше нужно держать только горячие данные, куда идет много-много обращений, потому что вы шардируете и реплицируете эти холодные данные вместе со всей базой только для того, чтобы обслужить горячие данные. Но если вы будете только горячие данные шардировать, это проблему не решит, потому что это все равно упирается в количество запросов на горячие данные, т.е кэш может быть базой данных.
Собственно, что мы и сделали, и назвали эту базу данных Tarantool.

Мы разработали специальную базу данных для горячих данных, которая является кэшем, но при этом у него есть персистенс, транзакции (такие же, как у взрослых баз данных), репликация, у него даже есть хранимые процедуры. Т.е. все основные свойства базы данных у Tarantool’а есть. И поэтому мы его используем как первичный источник для горячих данных. Мы эти данные не дублируем нигде. У нас Tarantool, у него есть реплика, эти данные бэкапятся, как и для любой базы данных, но они не дублируются нигде, ни в каких других базах данных. Это такой всегда горячий кэш с персистентом и со свойствами баз данных, т.е. он все эти проблемы решает.
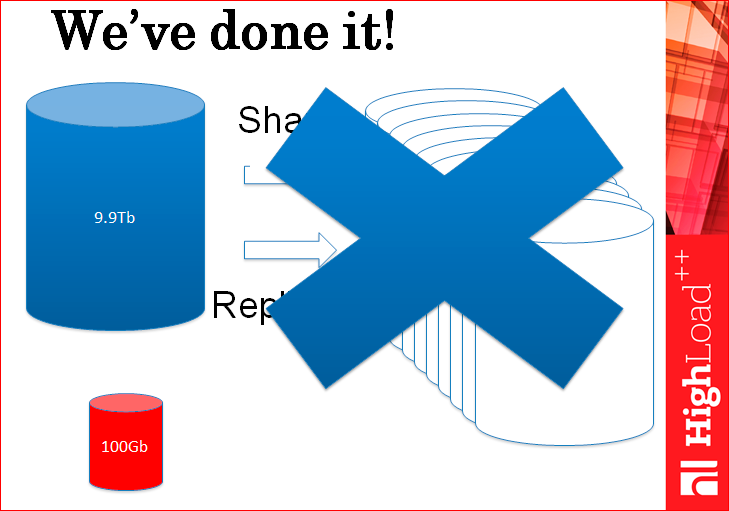
По сути, нам не нужны сейчас все эти сотни серверов с шардингом и с репликами, у нас просто наша задача разделилась,
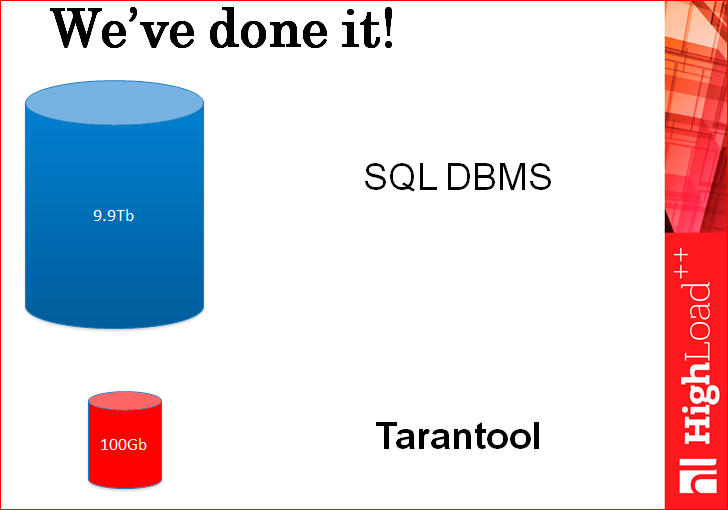
Мы просто используем правильный инструмент для правильной задачи, т.е. холодные данные хранятся в хранилище. Например, в SQL хранилищах, которые были созданы десятки лет назад именно для холодных данных, потому что тогда не было такого количества запросов в секунду на данные, никто про это не думал. А горячие данные хранятся в том хранилище, которые специально задизайнено для горячих данных в Tarantool.

Тут, в принципе, на слайде все написано – наш путь, через который мы прошли, но факт в том, что для большинства задач были достаточны 2 инстанса всего Tarantool – один мастер, второй – реплика, потому что нагрузка, которая идет на одну из баз данных, на один инстанс, она, скорее всего, обеспечит всю вашу полосу нагрузки, которая шла раньше на весь ваш кластер SQL серверов.

И еще тут один психологический момент – не очень хочется уходить из уютного мира баз данных в неуютный новый мир кэшей. В базе данных транзакции и т.д. Тогда, когда ваш босс злой, вы доставили кэш и как-то сразу стало неуютно. И как раз Tarantool возвращает этот уют, т.е. он, мало того, что решает проблемы неконсистанси и холодного старта. Он, как бы, возвращает вас в мир баз данных для горячих данных.
Теперь кейс в почте Mail.ru.
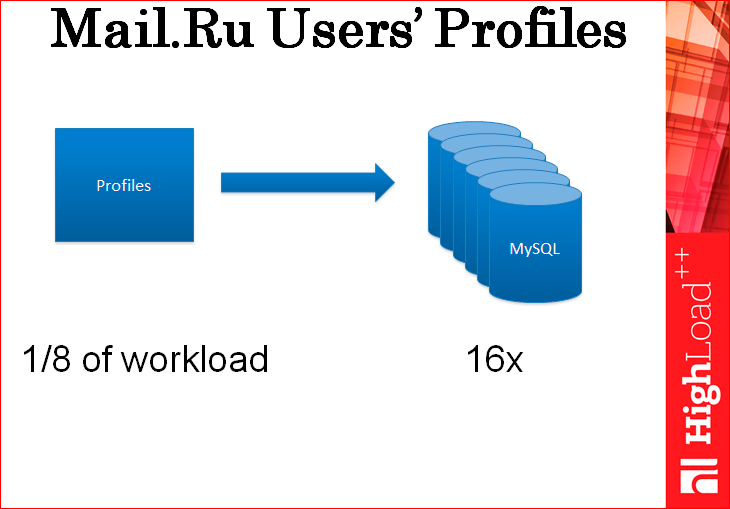
Кейс был такой: нам нужно было хранить профили пользователей. Профили пользователей – это такие маленькие кусочки информации – от 500 байт до 1 Кб на пользователя. Мы изначально стали для этого дела использовать MySQL. И стали дублировать всю нагрузку на профили, которые у нас до этого лежали в старом хранилище, на чтение и на запись на ферму из MySQL. Мы поставили ферму из 16-ти MySQL, все пошардили заранее и туда пустили нагрузку. И оказалось, что на 1/8 от всей нашей нагрузки эти 16 серверов уперлись в полки. В основном, они уперлись в полку по процессору.

Мы пытались их тюнить так и сяк, но по факту, все, что мы достигли – это 16 серверов на 1/8 нагрузки, т.е. на весь кластер, на всю нагрузку потребовалось бы 128 MySQL серверов. Мы подумали, что это дороговато – это больше 1 млн. долларов. И мы просто поставили несколько серверов с Tarantool и туда пустили всю нагрузку. В тестовых целях, дублировали. И оказалось, что они без проблем ее тянут целиком. Даже одного сервера было достаточно. Поставили просто 4, потому что мастер, реплика + еще пара, на всякий случай. Мы обычно перезакладываемся всегда по нагрузке.
Собственно, вот она экономия миллиона долларов – просто мы в 60 раз снизили количество серверов, которое нам нужно. При этом даже пользователю стало лучше, потому что кэши обычно работают с лучшим лэйтенси.

У нас суммарно в облаке и почте больше 120 инстансов Tarantool, серверов прямо с Tarantool, которые используются для разных фич, для очень большого количества фич. Если бы мы все это хранили в MySQL или в любом другом SQL, то это были бы сотни миллионов долларов, просто, если экстраполировать имеющиеся цифры.
Мораль моего всего выступления: нужно использовать правильный инструмент, для правильной работы, т.е. нужно использовать базы данных для холодных данных и кэши с персистентом, как Tarantool, для горячих данных. И сэкономить на этом 1 млн. долларов.

Тут краткое Summary о том, что мы сделали. Мы шардировали, реплицировали, уперлись в деньги, стали кэшировать, потеряли консистенси и еще кое-что… Сделали персистент кэш, это не база данных, но он может быть базой данных, отделили горячие от холодных данных, холодные – в MySQL, горячие – в Tarantool, спасли 1 млн. долларов и, как бонус, получили лучший юзер експириенс, потому что все стало быстрее.
Контакты
» anikin@corp.mail.ru
» danikin
» Блог компании Mail.ru
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
В этом году Денис подал заявку под названием "Почему Tarantool такой оптимальный?". Обещается срыв покровов :) Константин Осипов так прокомментировал этот доклад — «он такой быстрый, потому что ни делает НИЧЕГО!» :) Послушаем, поспорим!
Весь Программный комитет HighLoad++ продолжает дружно рекомендовать платформу Tarantool. Это одна из замечательных наших (российских) разработок и, как минимум, заслуживает внимания.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
