

В PostgreSQL есть два типа данных: JSON и JSONB. Первый формат является текстовым хранилищем, в котором json хранится "as is", второй — бинарным, в нем ключи отсортированы (сначала по длине ключа, а потом по его названию), дубликаты удалены, а пробелы удалены. Этот SQL-запрос иллюстрирует различие между JSON и JSONB:

Тип JSONB имеет богатую поддержку, облегчающую работу разработчиков приложений, для него есть встроенные индексы, кроме того, существует расширение Jsquery, в котором реализован язык запросов к JSONB и дополнительные индексы. Когда у меня спрашивают, чем пользоваться, я всегда советую JSONB, так как он позволяет работать очень эффективно.
Однако у постгреса есть серьёзная проблема, которая сказывается и на производительности JSONB — это TOAST, и о ней я говорил в первой части. Сегодня я расскажу о том, как мы улучшили JSONB для того, чтобы существенно повысить его производительность.
Пример 1. Популярная ошибка
Ее делают, когда торопятся и создают таблицу из JSON, но ID используют внутри. Мы сравнили производительность двух схем, с ID снаружи и внутри JSON:
")
На изображении мы видим, что график красного цвета (то есть время доступа) постоянен и близок к нулю. А время доступа к ID, который лежит в JSON (график желтого цвета) — зависит от размера JSON. Причем зависит линейно — чем длиннее JSON, тем медленнее чтение, более того, эта кривая резко уходит вверх при больших размерах JSONB.
При создании таблицы хорошая практика использовать уникальный ключ (ID) вне JSON для избежания оверхедов JSON, так где это не требуется, например, при операциях связывания таблиц по уникальному ключу.
Пример 2. IMDB-тест
Мы взяли Internet Movie Database, доступную базу данных о кинематографе и выбрали оттуда 4 ключа. Короткие: id (название фильма, самый популярный ключ), imdb_id (внутренний id базы данных) и height (рост актера в см). Из длинных взяли тоже довольно популярный ключ roles (список ролей, размером до мегабайта). Запись выглядит примерно так:
Typical IMDB «name» document
{
"id": "Connors, Steve (V)",
"roles": [
{
"role": "actor",
"title": "Copperhead Creek (????)"
},
{
"role": "actor",
"title": "Ride the Wanted Trail (????)"
}
],
“height”: “171 cm”,
"imdb_id": 1234567
}После чего мы измерили время доступа к ключу для каждой строчки, повторив запрос 1000 раз, чтобы надежно измерить производительность:

На графике слева (время доступа vs “raw” размера JSON) можно наблюдать 3 участка: inline (размер JSON < 2 Kb), compressed inline (размер сжатого JSON < 2Kb) и то, что TOAST’ится, то есть, размер JSON даже после сжатия > 2 Kb. Сначала мы видим плоский график — там не нужно ни сжатие, ни TOAST, далее идет рост из-за необходимости декомпрессии сжатого JSON, а когда мы начинаем доставать чанки из TOAST, склеивать их и разжимать, то получаем дальнейший рост. На графике справа показана зависимость размер JSON на диске от “сырого” размера - все что, выше 2 Kb (синий цвет) - это зона TOAST, ниже находятся две зоны - то, что помещается в 2Kb несжатым (“raw”) и после сжатия (зеленый цвет).
Отсюда мы поняли:
Нужна частичная декомпрессия, то есть разжимать следует только тот чанк, который нам необходим.
Мы читаем слишком много чанков, вместо содержащих то, что нам требуется.
Это мы и сделали в JSONB, с помощью множества проведенных экспериментов, реализовав проект по улучшению хранилища TOAST. Покажу, что у нас получилось на примере IMDB.
JSONB deTOAST: Улучшения
Частичная декомпрессия Jsonb
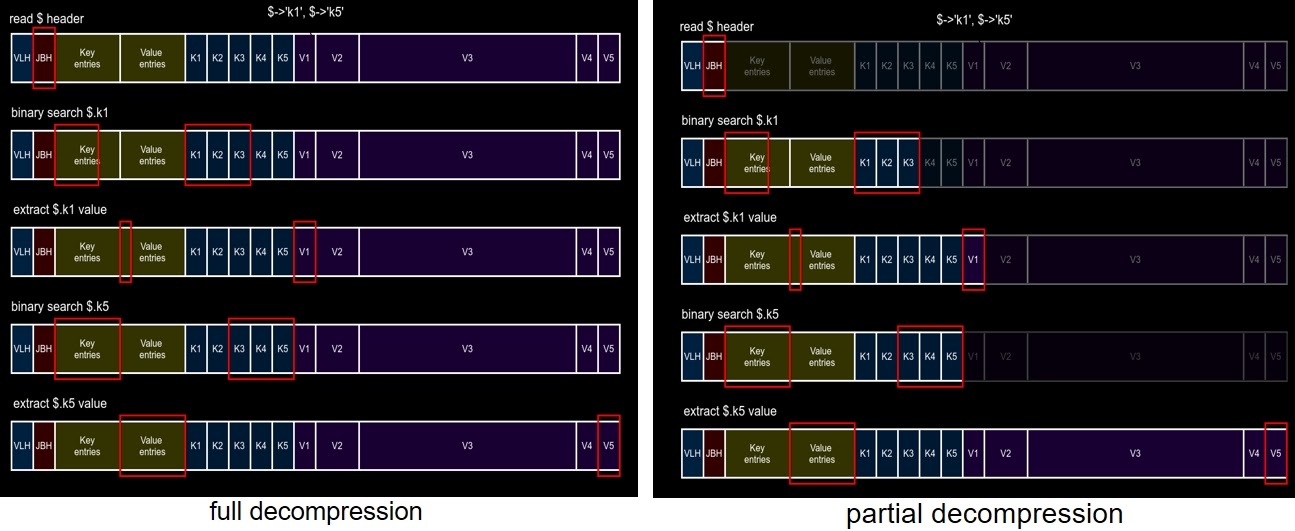
JSONB устроен так, что вначале лежат ключи, а потом идут значения. На рисунке слева показан поиск ключей K1 и K5 в JSON, который состоит из пяти ключей (значение третьего ключа является самым большим), для варианта полной декомпрессии (как это работает в современном потсгресе). В обоих случаях приходится читать весь JSON, в то время как на правой картинке показан случай частичной декомпрессии, когда для того, чтобы получить значение ключа K1, требуется читать только необходимую часть JSON, хотя для ключа K5 (последний ключ) эта оптимизация не работает.
Теперь посмотрим, что изменилось на графике IMDB (слева — то, что было, а справа — изменения):
")
Видно, что упали (ускорились) ключ id (синий) и рост актера (желтый), так как они короткие. А внутреннее id (красное) и роли (зеленое, самый большой кусок) остались вверху, потому что длинный ключ roles блокирует ключ imdb_id.
Сортировка ключей по длине
В существующем JSONB ключи отсортированы по их названию, а не по значению, в то время как типичный паттерн использования JSON — это работа с метаданными, которые обычно имеют короткое значение, поэтому, может случиться, что одно большое значение будет мешать доступу к метаданным в конце, как в нашем примере, большое значение V3 будет мешать доступу к V4 и V5.
В JSONB мы отсортировали ключи по их длине. И сделали так, что JSONB сам меняет за вас хранение внутри: сначала лежат короткие метаданные, наиболее используемые ключи. В результате значения лежат не как V1,V2,V3,V4,V5, а как V1, V4, V5, V2, V3, поэтому для доступа к ключу K5 читать придется меньше!

На примере IMDB ниже мы видим, что теперь красный ключ imdb_id «упал», потому что встал впереди roles (зеленого цвета). Это связано с тем, что roles большие и оказались сзади после сортировки:
")
По цифрам же мы получили ускорение в несколько порядков для длинных JSONB.
Частичный deTOASTing
Дальше мы сделали частичный deTOAST, чтобы читать только нужные чанки. Это привело к тому, что время доступа к ключам перестало зависеть от размера JSON:
")
Если на графике слева видно, что была некоторая зависимость от размера JSON для коротких ключей, то на графике справа ее фактически нет, потому что мы берем только тот чанк, который нам нужен.
Inline TOAST
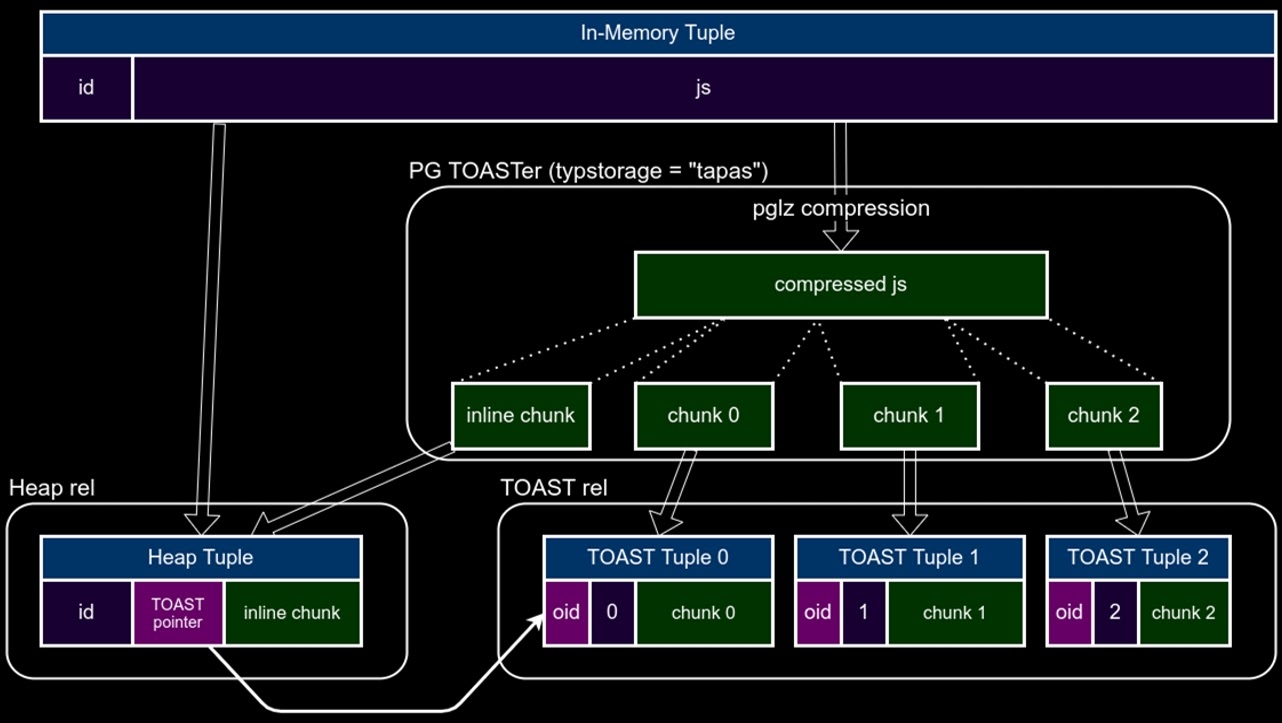
При TOAST tuple (строка) сжимается до tuple pointer, то есть вместо самого значения там лежит pointer на чанки. Остальное место в tuple, которое есть в странице вашей таблице, не используется. Мы решили часть первого чанка положить обратно в таблицу — насколько хватит места. Теперь есть большая вероятность, что после сортировки по длине ключа именно короткие ключи окажутся в inline, и доступ к ним вообще не будет затрагивать TOAST-хранилище.
Мы добавили к TOAST pointer место для хранение, которое называется Inline chunk. На самом деле это начальный кусок первого чанка. Мы вернули его в таблицу, надеясь, что все короткие ключи (метаданные) попадут туда:
И действительно произошли и другие улучшения. Красная и жёлтая части ушли вниз, и мы ускорились со 100 микросекунд до 1 микросекунды — те же 2 порядка, но поведение стало другое:
")
Но также мы видим, что на графике видна ступенька на месте начала сжатия . Ее мы будем убирать с помощью расшаренных чанков (Shared TOAST).
Shared TOAST или частичное обновление JSONB
Самое вкусное — это шаринг чанков. Как я рассказывал про TOAST в первой части, если вы заапдейтили какой-то ключ, у вас перепишется всё — вся строка и все чанки продублируются, появится новая версия. Увеличится не только размер таблицы. Все это еще запишется в WAL (Write-Ahead Log). Если у вас был JSON 10 Мб, и вы поменяли один байт, то занимаемое двумя версиями строки место увеличится до 20 Мб, и еще 10 Мб уйдет в WAL — а это очень дорого.
Мы сделали так, чтобы менялся только тот чанк, в котором произошло изменение, а все остальные чанки использовались (shared) старой и новой версиями строки:

В этом случае копируются не все TOAST-чанки. У нас создается новая версия только того чанка, который нужен. Также здесь мы реализовали еще и in-place update: если данные свою длину не меняли, мы пытаемся их оставить на месте и записать новое значение (своего рода diff) в inline (не в TOAST, а в heap).
В результате так же улучшился и доступ к TOAST. На графике ниже мы видим, что исчезла ступенька, в гордом одиночестве остались одни roles, то есть длинный ключ. А все остальные теперь не зависят от размера JSON, который здесь меняется от 0 до 1 Мб:
. Было — стало.")
Обновление JSONB
Частичное обновление JSONB с помощью SHARED TOAST мы изучали на синтетическом примере из-за простоты интерпретации результатов. Тестовые данные выглядели как key1, большой массив key2, key3, массив key4. Как и раньше, слева — оригинальный постгрес (master), а справа — с оптимизацией SHARED TOAST. Видно, что оптимизация привела к тому, что время обновления для коротких ключей перестало зависеть от размера JSONB, а время обновления для длинных (TOAST) ключей зависит только от их размера (не общего размера JSONB) На следующем рисунке заметно, что количество записей в журнал (WAL) при обновлении коротких и ключей среднего размера сильно уменьшилось.


Все оптимизации доступа к JSONB на одной картинке:
")
Здесь слева — текущая версия постгреса , дальше мы делаем частичную декомпрессию, сортируем ключи, частично deTOAST’им, дальше делаем inline TOAST, shared TOAST — все 5 оптимизаций на одном графике. Тут мы видим насколько сильно вырастает производительность — изменения до 3-х порядков !
Нужно подчеркнуть, что здесь осталась полная совместимость с JSONB, то есть старый и новый JSONB могут сосуществовать, потому что JSONB внутренне расширяем. Его бинарный формат сделан так, что он сам понимает, какую версию JSONB читает.
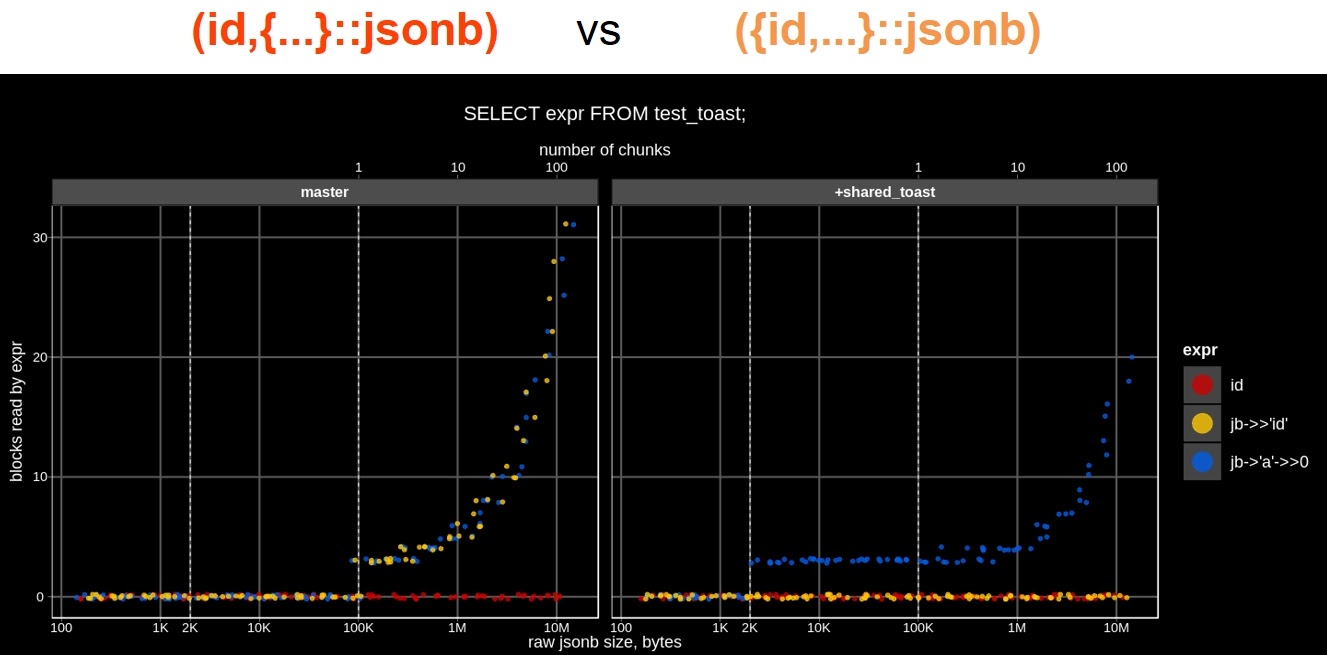
При этом мы не оптимизировали с длинными ключами (и вряд ли сможем). Но короткие ключи, те самые метаданные, за которые мы боролись, стали вести себя совсем по-другому. Теперь в том самом примере, с которого мы начинали (ID вне JSON и ID внутри JSON), ситуация улучшилась:

Видно небольшую просадку производительности (график желтого цвета чуть выше, чем красный). Она объясняется тем, что нам все-таки надо достать данные из JSON. И хотя время доступа к длинному ключа так и продолжает расти с ростом размера JSONB, ID можно держать внутри JSON. Конечно, держать снаружи лучше, но разница уже не такая, как была. По количеству прочитанных блоков разницы нет, вы читаете ID, который находится вне JSON, или читаете ID, который находится внутри JSON:
Резюме и ссылки
Так, шаг за шагом, мы оптимизировали JSONB, причем с обратной совместимостью. Это привело к значительному (в 10 раз) ускорению для SELECTs и гораздо более дешевому апдейту.
Это наталкивает на мысль, что мы находимся на правильном пути к OLTP JSONB. Можно действительно не только быстро читать, делать точечное чтение, но и апдейтить, чего не хватает многим людям. Если хотите попробовать сами, то все для этого найдете на Github.
Тот же подход может быть применен к любым типам данных, у которых есть возможность рандомного доступа к частям, например, массивы, hstore, фильмы. Можно сделать документ pdf, в заголовке которого имеются ссылки на страницы, что позволит легко делать доступ к любой странице, не скачивая весь файл.
Можно сделать appendable bytea (бинарный тип), и там будет даже 1000-кратный рост производительности. Это доступно в отдельной ветке, можно потестировать, мы всегда готовы к сотрудничеству.
С обобщенным API для JSON мы сделали возможность реализовать GIN-индексы для JSON. Как известно, GIN-индекс существует только для JSONB, а с помощью этого API можно сделать и для JSON. Об этом у нас есть два обширных доклада: раз и два. В них есть описание и других проектов, например, расширение синтаксиса, новые индексы, обобщенный API для JSON.
Что дальше?
Мы хотим сделать больше бенчмарков. Понятно, что они должны быть либо общепризнанными, как YCSB (известный бенчмарк для неструктурированных БД) , либо типичными use cases.
И нам интересно, какие use cases есть у вас, как вы используете JSON — просто положить и взять? Или как-то еще? Что вы делаете с длинными массивами? Нам очень важно знать, что оптимизировать, чтобы мы не изобретали «сферического коня в вакууме».
Конечно, также надо сделать бенчмарк Postgres с Mongo — это очень важно. Я уже несколько раз встречал людей, которые используют Postgres, но часть данных держат в Mongo, потому что... Часто в Postgres люди используют реляционные структуру и данные, а в Mongo держат мусор — JSON. Улучшая Postgres, мы стремимся к тому, чтобы часть «монгоидов» все-таки пришла к Postgres. Нам очень важно работать с реальными пользователями.
Еще мы хотим расширить подход shared TOAST, чтобы поддерживать строки, массивы и массивы jsonb. Сейчас мы поддерживаем только корневые объекты, а надо идти по иерархии, потому что JSON может быть развесистым деревом, и было бы классно вытаскивать не всё, а только определенные веточки.
Предстоит большая работа по pluggable TOAST. Потому что пока неясно, как всё, о чем я рассказал, интегрировать в ядро Postgres, то есть отдать сообществу. Мало сделать ссылку на GitHub и сказать — берите. Надо бороться за то, чтобы сообщество это приняло.
И дальше нужно понять, как интегрировать этот все в CORE. Как сделать новый API, как сделать так, чтобы TOAST знал внутреннее устройство типа данных? Как лучше сжимать данные каждого типа? Например, если это просто integer, то с ним можно ничего не делать. Если это JSON, то надо использовать то, что мы сделали. Для массива нужно что-то другое.
Вообще стоит подумать над новым storage, в котором вообще нет TOAST, например, WiredElephant – storage, оптимизированный для древоподобных структур, в которых есть большие атрибуты.
Нам нужны Ваши кейсы — тестовые данные и запросы! Если вы можете анонимизировать их и предоставить нам, будем рады сотрудничеству.
Видео моего выступления на HighLoad ++ Весна 2021:
Следующее повышение цен на HighLoad++ Foundation 2022 — 1 февраля. Вы можете забронировать билеты и выкупить их позже по той же цене. Планируйте свое участие — расписание и полный список тем с тезисами уже на сайте. Конференция пройдет 17 и 18 марта в Москве в Крокус Экспо.
