И снова здравствуйте. Сегодня мы продолжаем делиться материалом, приуроченным к запуску курса «Сетевой инженер», который стартует уже в начале марта. Мы видим, что многих заинтересовала первая часть статьи «Машинно-синестетический подход к обнаружению сетевых DDoS-атак» и сегодня хотим поделиться с вами второй — завершающей частью.
3.2 Классификация изображений в проблеме обнаружения аномалий
Следующим шагом является решение проблемы классификации полученного изображения. В общем, решение задачи обнаружения классов (объектов) в изображении состоит в том, чтобы использовать алгоритмы машинного обучения для построения моделей классов, а затем алгоритмы для поиска классов (объектов) в изображении.

Построение модели состоит из двух этапов:
a) Извлечение характерных признаков для класса: построение векторов характерных признаков для элементов класса.

Рис. 1
b) Обучение полученным особенностям модели для последующих задач распознавания.
Описание объекта класса выполняется с использованием векторов признаков. Векторы сформированы из:
а) информация о цвете (ориентированная градиентная гистограмма);
b) контекстная информация;
c) данные о геометрическом расположении частей объекта.
Алгоритм классификации (прогнозирования) можно разделить на два этапа:
a) Извлечение признаков из изображения. На этом этапе выполняются две задачи:
b) ассоциирование изображения с определенным классом. Формальное описание класса, то есть набор признаков, которые выделены их тестовыми изображениями, используется в качестве входных данных. На основании этой информации классификатор решает, принадлежит ли изображение к классу, и оценивает степень достоверности для заключения.
Методы классификации. Методы классификации варьируются от преимущественно эвристических подходов до формальных процедур, основанных на методах математической статистики. Не существует общепринятой классификации, но можно выделить несколько подходов к классификации изображений:
Для реализации, представленной в этой статье, авторы выбрали алгоритм «мешок слов», учитывая следующие причины:
Для анализа видеопотока, спроецированного с трафика, мы использовали наивный байесовский классификатор [25]. Он часто используется для классификации текстов с помощью модели «мешок слов». В этом случае подход аналогичен анализу текстов, вместо слов используются только дескрипторы. Работу этого классификатора можно разделить на две части: этап обучения и этап прогнозирования.
Фаза обучения. Каждый кадр (изображение) подается на вход алгоритма поиска дескриптора, в этом случае масштабно-инвариантное преобразование признаков (SIFT — scale-invariant feature transform) [26]. После этого выполняется задача корреляции особых точек между кадрами. Особая точка на изображении объекта — это точка, которая, скорее всего, появится на других изображениях этого объекта.
Для решения проблемы сравнения особых точек объекта на разных изображениях используется дескриптор. Дескриптор является структурой данных, идентификатором особой точки, отличающей ее от остальных. Он может или не может быть инвариантным относительно преобразований изображения объекта. В нашем случае дескриптор инвариантен относительно перспективных преобразований, то есть масштабирования. Дескриптор позволяет сравнивать особую точку объекта на одном изображении с такой же особой точкой на другом изображении этого объекта.
Затем набор дескрипторов, полученных из всех изображений, упорядочивается по группам по сходству с использованием метода кластеризации k-средних [26, 27]. Это делается для того, чтобы обучить классификатор, который выдаст заключение о том, представляет ли изображение аномальное поведение.
Ниже приведен пошаговый алгоритм обучения классификатора дескриптора изображения:
Шаг 1. Извлечение всех дескрипторов из множеств с атакой и без атаки.
Шаг 2. Кластеризация всех дескрипторов посредством метода k-средних в n кластеров.
Шаг 3. Расчет матрицы A (m, k), где m — количество изображений, а k — количество кластеров. Элемент (i; j) будет хранить значение того, как часто дескрипторы из j-го кластера появляются на i-м изображении. Такая матрица будет называться матрицей частоты появления.
Шаг 4. Расчет весов дескрипторов по формуле tf idf [28]:
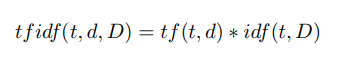
Здесь tf (“term frequency”) — частота появления дескриптора в этом изображении и определяется как
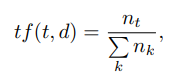
где t — дескриптор, k — количество дескрипторов в изображении, nt — количество дескрипторов t в изображении. Кроме того, idf («обратная частота документа») является обратной частотой изображения с заданным дескриптором в образце и определяется как

где D — количество изображений с заданным дескриптором в образце, {di ∈ D, t ∈ di} — количество изображений в D, где t находится в условиях nt! = 0.
Шаг 5. Подстановка соответствующих весов вместо дескрипторов в матрицу А.
Шаг 6. Классификация. Мы используем усиление наивных байесовских классификаторов (adaboost).
Шаг 7. Сохранение обученной модели в файл.
Шаг 8. На этом завершается этап обучения.
Фаза прогнозирования. Различия между фазой обучения и фазой прогнозирования невелики: дескрипторы извлекаются из изображения и соотносятся с имеющимися группами. На основе этого соотношения строится вектор. Каждый элемент этого вектора является частотой появления дескрипторов из этой группы на изображении. Анализируя этот вектор, классификатор может сделать прогноз об атаке с определенной вероятностью.
Общий алгоритм прогнозирования на основе пары классификаторов представлен ниже.
Шаг 1. Извлечение всех дескрипторов из изображения;
Шаг 2. Кластеризация полученного набора дескрипторов;
Шаг 3. Расчет вектора [1, k];
Шаг 4. Расчет веса для каждого дескриптора по формуле tf idf, представленной выше;
Шаг 5. Замена частоты встречаемости в векторах на их вес;
Шаг 6. Классификация результирующего вектора по ранее обученному классификатору;
Шаг 7. Вывод о наличии аномалии в наблюдаемой сети на основе прогноза классификатора.
4. Оценка эффективности обнаружения
Задача оценки эффективности предложенного способа была решена экспериментально. В эксперименте использовался ряд параметров, установленных опытным путем. Для кластеризации были использованы 1000 кластеров. Сгенерированные изображения имели 1000 на 1000 пикселей.
4.1 Экспериментальный набор данных
Для экспериментов была собрана установка. Она состоит из трех устройств, соединенных каналом связи. Блок-схема установки показана на рисунке 2.
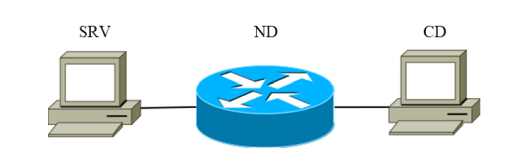
Рис.1
Устройство SRV играет роль атакующего сервера (в дальнейшем именуемого целевым сервером). В качестве целевого сервера последовательно использовались устройства, перечисленные в таблице 1 с кодом SRV. Второе — это сетевое устройство, предназначенное для передачи сетевых пакетов. Характеристики устройства приведены в Таблице 1 под кодом ND-1.
Таблица 1. Характеристики сетевого устройства

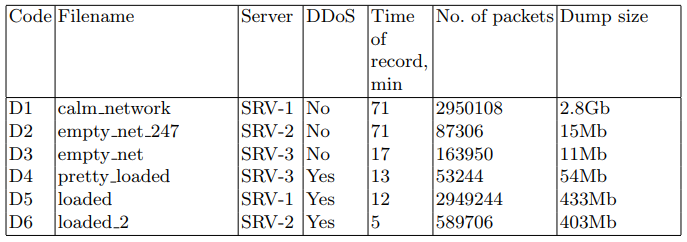
На целевых серверах сетевые пакеты были записаны в файл PCAP для последующего использования в алгоритмах обнаружения. Для этой задачи использовалась утилита tcpdump. Наборы данных описаны в таблице 2.
Таблица 2. Наборы перехваченных сетевых пакетов
На целевых серверах использовалось следующее программное обеспечение: дистрибутив Linux, веб-сервер nginx 1.10.3, СУБД postgresql 9.6. Для эмуляции загрузки системы было написано специальное веб-приложение. Приложение запрашивает базу данных с большим объемом данных. Запрос предназначен для минимизации использования различного кеширования. В ходе экспериментов были сформированы запросы к этому веб-приложению.
Атака была произведена с третьего клиентского устройства (таблица 1) с использованием утилиты Apache Benchmark. Структура фонового трафика во время атаки и в остальное время представлена в таблице 3.
Таблица 3. Функции фонового трафика
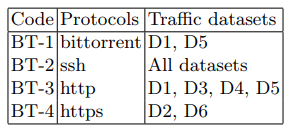
В качестве атаки мы реализуем версию распределенного DoS HTTP GET-флуда. Такая атака, по сути, является генерацией постоянного потока GET-запросов, в данном случае с устройства CD-1. Для его генерации мы использовали утилиту ab из пакета apache-utils. В результате были получены файлы, содержащие информацию о состоянии сети. Основные характеристики этих файлов представлены в таблице 2. Основные параметры сценария атаки приведены в таблице 4.
Из полученного дампа сетевого трафика были получены наборы сгенерированных изображений TD # 1 и TD # 2, которые использовались на этапе обучения. Образец TD # 3 использовался для фазы прогнозирования. Сводка тестовых наборов данных представлена в таблице 5.
4.2 Критерии эффективности
Основными параметрами, оцененными в ходе этого исследования, были:
Таблица 4. Особенности DDoS-атаки

Таблица 5. Наборы тестовых изображений

а) DR (Detection Rate) — количество обнаруженных атак по отношению к общему количеству атак. Чем выше этот параметр, тем выше эффективность и качество ADS.
b) FPR (False Positive Rate) — количество «нормальных» объектов, ошибочно классифицированных как атака, по отношению к общему количеству «нормальных» объектов. Чем ниже этот параметр, тем выше эффективность и качество системы обнаружения аномалий.
c) CR (Complex rate) — это комплексный показатель, который учитывает комбинацию параметров DR и FPR. Поскольку в рамках исследования параметры DR и FPR были приняты равными по важности, комплексный показатель был рассчитан следующим образом: CR = (DR + FPR) / 2.
На классификатор было подано 1000 изображений, помеченных как «аномальные». На основании результатов распознавания DR рассчитывали в зависимости от размера обучающей выборки. Были получены следующие значения: для TD#1 DR = 9,5% и для TD#2 DR = 98,4%. Далее, вторая половина изображений («нормальные») были классифицированы. На основании результата рассчитывали FPR (для TD#1 FPR = 3,2% и для TD#2 FPR = 4,3%). Таким образом, были получены следующие комплексные показатели эффективности: для TD#1 CR = 53,15% и для TD#2 CR = 97,05%.
5. Выводы и будущие исследования
Из результатов экспериментов видно, что предлагаемый способ обнаружения аномалий показывает высокие результаты в обнаружении атак. Например, на большой выборке значение комплексного показателя эффективности достигает 97%. Однако этот метод имеет некоторые ограничения в применении:
1. Значения DR и FPR показывают чувствительность алгоритма к размеру обучающего набора, что является концептуальной проблемой для алгоритмов машинного обучения. Увеличение выборки приводит к улучшению показателей обнаружения. Однако не всегда возможно реализовать достаточно большую обучающую выборку для конкретной сети.
2. Разработанный алгоритм является детерминированным, одно и то же изображение классифицируется каждый раз с одинаковым результатом.
3. Показатели эффективности подхода достаточно хороши для подтверждения концепции, но количество ложных срабатываний также велико, что может привести к трудностям практической реализации.
Чтобы преодолеть ограничение, описанное выше (пункт 3), предполагается изменить наивный байесовский классификатор на сверточную нейронную сеть, что, по мнению авторов, должно привести к повышению точности алгоритма обнаружения аномалий.
Традиционно ждём ваши комментарии и приглашаем всех на день открытых дверей, который пройдет уже в следующий понедельник.
3.2 Классификация изображений в проблеме обнаружения аномалий
Следующим шагом является решение проблемы классификации полученного изображения. В общем, решение задачи обнаружения классов (объектов) в изображении состоит в том, чтобы использовать алгоритмы машинного обучения для построения моделей классов, а затем алгоритмы для поиска классов (объектов) в изображении.

Построение модели состоит из двух этапов:
a) Извлечение характерных признаков для класса: построение векторов характерных признаков для элементов класса.

Рис. 1
b) Обучение полученным особенностям модели для последующих задач распознавания.
Описание объекта класса выполняется с использованием векторов признаков. Векторы сформированы из:
а) информация о цвете (ориентированная градиентная гистограмма);
b) контекстная информация;
c) данные о геометрическом расположении частей объекта.
Алгоритм классификации (прогнозирования) можно разделить на два этапа:
a) Извлечение признаков из изображения. На этом этапе выполняются две задачи:
- Поскольку изображение может содержать объекты многих классов, нам нужно найти всех представителей. Для этого можно использовать скользящее окно, которое проходит через изображение от верхнего левого до нижнего правого угла.
- Изображение масштабируется, поскольку масштаб объектов на изображении может изменяться.
b) ассоциирование изображения с определенным классом. Формальное описание класса, то есть набор признаков, которые выделены их тестовыми изображениями, используется в качестве входных данных. На основании этой информации классификатор решает, принадлежит ли изображение к классу, и оценивает степень достоверности для заключения.
Методы классификации. Методы классификации варьируются от преимущественно эвристических подходов до формальных процедур, основанных на методах математической статистики. Не существует общепринятой классификации, но можно выделить несколько подходов к классификации изображений:
- методы объектного моделирования на основе деталей;
- методы «мешка слов»;
- методы сопоставления пространственных пирамид.
Для реализации, представленной в этой статье, авторы выбрали алгоритм «мешок слов», учитывая следующие причины:
- Алгоритмы моделирования на основе деталей и сопоставления пространственных пирамид чувствительны к положению дескрипторов в пространстве и их взаимному расположению. Эти классы методов эффективны в задачах обнаружения объектов на изображении; однако из-за характерных особенностей входных данных они плохо применимы к проблеме классификации изображений.
- Алгоритм «мешок слов» широко апробирован в других областях знаний, он показывает хорошие результаты и достаточно прост в реализации.
Для анализа видеопотока, спроецированного с трафика, мы использовали наивный байесовский классификатор [25]. Он часто используется для классификации текстов с помощью модели «мешок слов». В этом случае подход аналогичен анализу текстов, вместо слов используются только дескрипторы. Работу этого классификатора можно разделить на две части: этап обучения и этап прогнозирования.
Фаза обучения. Каждый кадр (изображение) подается на вход алгоритма поиска дескриптора, в этом случае масштабно-инвариантное преобразование признаков (SIFT — scale-invariant feature transform) [26]. После этого выполняется задача корреляции особых точек между кадрами. Особая точка на изображении объекта — это точка, которая, скорее всего, появится на других изображениях этого объекта.
Для решения проблемы сравнения особых точек объекта на разных изображениях используется дескриптор. Дескриптор является структурой данных, идентификатором особой точки, отличающей ее от остальных. Он может или не может быть инвариантным относительно преобразований изображения объекта. В нашем случае дескриптор инвариантен относительно перспективных преобразований, то есть масштабирования. Дескриптор позволяет сравнивать особую точку объекта на одном изображении с такой же особой точкой на другом изображении этого объекта.
Затем набор дескрипторов, полученных из всех изображений, упорядочивается по группам по сходству с использованием метода кластеризации k-средних [26, 27]. Это делается для того, чтобы обучить классификатор, который выдаст заключение о том, представляет ли изображение аномальное поведение.
Ниже приведен пошаговый алгоритм обучения классификатора дескриптора изображения:
Шаг 1. Извлечение всех дескрипторов из множеств с атакой и без атаки.
Шаг 2. Кластеризация всех дескрипторов посредством метода k-средних в n кластеров.
Шаг 3. Расчет матрицы A (m, k), где m — количество изображений, а k — количество кластеров. Элемент (i; j) будет хранить значение того, как часто дескрипторы из j-го кластера появляются на i-м изображении. Такая матрица будет называться матрицей частоты появления.
Шаг 4. Расчет весов дескрипторов по формуле tf idf [28]:
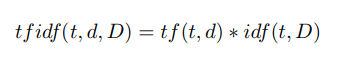
Здесь tf (“term frequency”) — частота появления дескриптора в этом изображении и определяется как
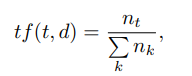
где t — дескриптор, k — количество дескрипторов в изображении, nt — количество дескрипторов t в изображении. Кроме того, idf («обратная частота документа») является обратной частотой изображения с заданным дескриптором в образце и определяется как
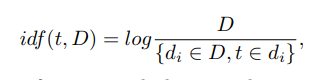
где D — количество изображений с заданным дескриптором в образце, {di ∈ D, t ∈ di} — количество изображений в D, где t находится в условиях nt! = 0.
Шаг 5. Подстановка соответствующих весов вместо дескрипторов в матрицу А.
Шаг 6. Классификация. Мы используем усиление наивных байесовских классификаторов (adaboost).
Шаг 7. Сохранение обученной модели в файл.
Шаг 8. На этом завершается этап обучения.
Фаза прогнозирования. Различия между фазой обучения и фазой прогнозирования невелики: дескрипторы извлекаются из изображения и соотносятся с имеющимися группами. На основе этого соотношения строится вектор. Каждый элемент этого вектора является частотой появления дескрипторов из этой группы на изображении. Анализируя этот вектор, классификатор может сделать прогноз об атаке с определенной вероятностью.
Общий алгоритм прогнозирования на основе пары классификаторов представлен ниже.
Шаг 1. Извлечение всех дескрипторов из изображения;
Шаг 2. Кластеризация полученного набора дескрипторов;
Шаг 3. Расчет вектора [1, k];
Шаг 4. Расчет веса для каждого дескриптора по формуле tf idf, представленной выше;
Шаг 5. Замена частоты встречаемости в векторах на их вес;
Шаг 6. Классификация результирующего вектора по ранее обученному классификатору;
Шаг 7. Вывод о наличии аномалии в наблюдаемой сети на основе прогноза классификатора.
4. Оценка эффективности обнаружения
Задача оценки эффективности предложенного способа была решена экспериментально. В эксперименте использовался ряд параметров, установленных опытным путем. Для кластеризации были использованы 1000 кластеров. Сгенерированные изображения имели 1000 на 1000 пикселей.
4.1 Экспериментальный набор данных
Для экспериментов была собрана установка. Она состоит из трех устройств, соединенных каналом связи. Блок-схема установки показана на рисунке 2.
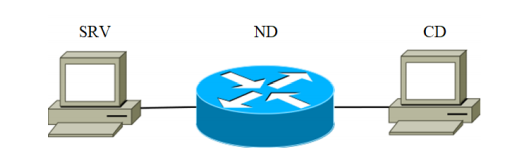
Рис.1
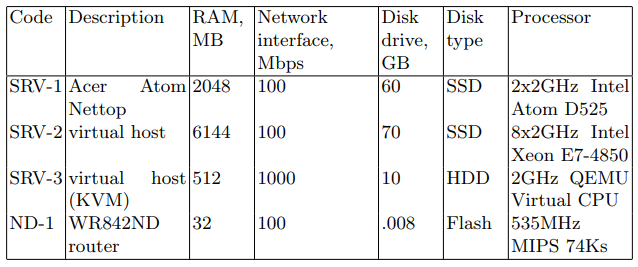
Устройство SRV играет роль атакующего сервера (в дальнейшем именуемого целевым сервером). В качестве целевого сервера последовательно использовались устройства, перечисленные в таблице 1 с кодом SRV. Второе — это сетевое устройство, предназначенное для передачи сетевых пакетов. Характеристики устройства приведены в Таблице 1 под кодом ND-1.
Таблица 1. Характеристики сетевого устройства
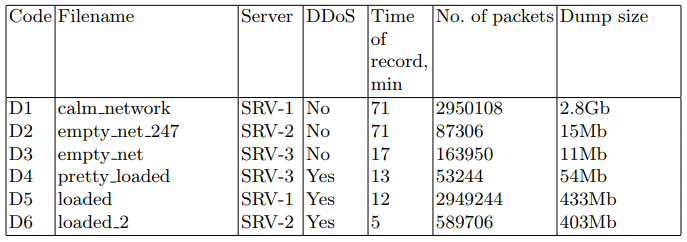
На целевых серверах сетевые пакеты были записаны в файл PCAP для последующего использования в алгоритмах обнаружения. Для этой задачи использовалась утилита tcpdump. Наборы данных описаны в таблице 2.
Таблица 2. Наборы перехваченных сетевых пакетов
На целевых серверах использовалось следующее программное обеспечение: дистрибутив Linux, веб-сервер nginx 1.10.3, СУБД postgresql 9.6. Для эмуляции загрузки системы было написано специальное веб-приложение. Приложение запрашивает базу данных с большим объемом данных. Запрос предназначен для минимизации использования различного кеширования. В ходе экспериментов были сформированы запросы к этому веб-приложению.
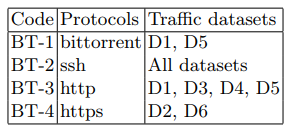
Атака была произведена с третьего клиентского устройства (таблица 1) с использованием утилиты Apache Benchmark. Структура фонового трафика во время атаки и в остальное время представлена в таблице 3.
Таблица 3. Функции фонового трафика
В качестве атаки мы реализуем версию распределенного DoS HTTP GET-флуда. Такая атака, по сути, является генерацией постоянного потока GET-запросов, в данном случае с устройства CD-1. Для его генерации мы использовали утилиту ab из пакета apache-utils. В результате были получены файлы, содержащие информацию о состоянии сети. Основные характеристики этих файлов представлены в таблице 2. Основные параметры сценария атаки приведены в таблице 4.
Из полученного дампа сетевого трафика были получены наборы сгенерированных изображений TD # 1 и TD # 2, которые использовались на этапе обучения. Образец TD # 3 использовался для фазы прогнозирования. Сводка тестовых наборов данных представлена в таблице 5.
4.2 Критерии эффективности
Основными параметрами, оцененными в ходе этого исследования, были:
Таблица 4. Особенности DDoS-атаки

Таблица 5. Наборы тестовых изображений

а) DR (Detection Rate) — количество обнаруженных атак по отношению к общему количеству атак. Чем выше этот параметр, тем выше эффективность и качество ADS.
b) FPR (False Positive Rate) — количество «нормальных» объектов, ошибочно классифицированных как атака, по отношению к общему количеству «нормальных» объектов. Чем ниже этот параметр, тем выше эффективность и качество системы обнаружения аномалий.
c) CR (Complex rate) — это комплексный показатель, который учитывает комбинацию параметров DR и FPR. Поскольку в рамках исследования параметры DR и FPR были приняты равными по важности, комплексный показатель был рассчитан следующим образом: CR = (DR + FPR) / 2.
На классификатор было подано 1000 изображений, помеченных как «аномальные». На основании результатов распознавания DR рассчитывали в зависимости от размера обучающей выборки. Были получены следующие значения: для TD#1 DR = 9,5% и для TD#2 DR = 98,4%. Далее, вторая половина изображений («нормальные») были классифицированы. На основании результата рассчитывали FPR (для TD#1 FPR = 3,2% и для TD#2 FPR = 4,3%). Таким образом, были получены следующие комплексные показатели эффективности: для TD#1 CR = 53,15% и для TD#2 CR = 97,05%.
5. Выводы и будущие исследования
Из результатов экспериментов видно, что предлагаемый способ обнаружения аномалий показывает высокие результаты в обнаружении атак. Например, на большой выборке значение комплексного показателя эффективности достигает 97%. Однако этот метод имеет некоторые ограничения в применении:
1. Значения DR и FPR показывают чувствительность алгоритма к размеру обучающего набора, что является концептуальной проблемой для алгоритмов машинного обучения. Увеличение выборки приводит к улучшению показателей обнаружения. Однако не всегда возможно реализовать достаточно большую обучающую выборку для конкретной сети.
2. Разработанный алгоритм является детерминированным, одно и то же изображение классифицируется каждый раз с одинаковым результатом.
3. Показатели эффективности подхода достаточно хороши для подтверждения концепции, но количество ложных срабатываний также велико, что может привести к трудностям практической реализации.
Чтобы преодолеть ограничение, описанное выше (пункт 3), предполагается изменить наивный байесовский классификатор на сверточную нейронную сеть, что, по мнению авторов, должно привести к повышению точности алгоритма обнаружения аномалий.
Ссылки
1. Mohiuddin A., Abdun N.M., Jiankun H.: A survey of network anomaly detection techniques. In: Journal of Network and Computer Applications. Vol. 60, p. 21 (2016)
2. Afontsev E.: Network anomalies, 2006 nag.ru/articles/reviews/15588 setevyie-anomalii.html
3. Berestov A.A.: Architecture of intelligent agents based on a production system to protect against virus attacks on the Internet. In: XV All-Russian Scientific Conference Problems of Information Security in the Higher School System”, pp. 180?276 (2008)
4. Galtsev A.V.: System analysis of traffic to identify anomalous network conditions: The thesis for the Candidate Degree of Technical Sciences. Samara (2013)
5. Kornienko A.A., Slyusarenko I.M.: Intrusion Detection Systems and Methods: Current State and Direction of Improvement, 2008 citforum.ru/security internet/ids overview/
6. Kussul N., Sokolov A.: Adaptive anomaly detection in the computer systems users behavior using Markov chains of variable order. Part 2: Methods of detecting anomalies and the results of experiments. In: Informatics and Control Problems. Issue 4, pp. 83?88 (2003)
7. Mirkes E.M.: Neurocomputer: draft standard. Science, Novosibirsk, pp. 150-176 (1999)
8. Tsvirko D.A. Prediction of a network attack route using production model methods, 2012 academy.kaspersky.ru/downloads/academycup participants/cvirko d. ppt
9. Somayaji A.: Automated response using system-call delays. In: USENIX Security Symposium 2000, pp. 185-197, 2000
10. Ilgun K.: USTAT: A Real-time Intrusion Detection System for UNIX. In: IEEE Symposium on Research in Security and Privacy, University of California (1992)
11. Eskin E., Lee W., and Stolfo S. J.: Modeling system calls for intrusion detection with dynamic window sizes. In: DARPA Information Survivability Conference and Exposition (DISCEX II), June 2001
12. Ye N., Xu M., and Emran S. M.: Probabilistic networks with undirected links for anomaly detection. In: 2000 IEEE Workshop on Information Assurance and Security, West Point, NY (2000)
13. Michael C. C. and Ghosh A.: Two state-based approaches to program-based anomaly detection. In: ACM Transactions on Information and System Security. No. 5(2), 2002
14. Garvey T.D., Lunt T.F.: Model-based Intrusion Detection. In: 14th Nation computer security conference, Baltimore, MD (1991)
15. Theus M. and Schonlau M.: Intrusion detection based on structural zeroes. In: Statistical Computing and Graphics Newsletter. No. 9(1), pp. 12?17 (1998)
16. Tan K.: The application of neural networks to unix computer security. In: IEEE International Conference on Neural Networks. Vol. 1, pp. 476?481, Perth, Australia (1995)
17. Ilgun K., Kemmerer R.A., Porras P.A.: State Transition Analysis: A Rule-Based Intrusion Detection System. In: IEEE Trans. Software Eng. Vol. 21, no. 3, (1995)
18. Eskin E.: Anomaly detection over noisy data using learned probability distributions. In: 17th International Conf. on Machine Learning, pp. 255?262. Morgan Kaufmann, San Francisco, CA (2000)
19. Ghosh K., Schwartzbard A., and Schatz M.: Learning program behavior profiles for intrusion detection. In: 1st USENIX Workshop on Intrusion Detection and Network Monitoring, pp. 51?62, Santa Clara, California (1999)
20. Ye N.: A markov chain model of temporal behavior for anomaly detection. In: 2000 IEEE Systems, Man, and Cybernetics, Information Assurance and Security Workshop (2000)
21. Axelsson S.: The base-rate fallacy and its implications for the difficulty of intrusion detection. In: ACM Conference on Computer and Communications Security, pp. 1?7 (1999)
22. Chikalov I, Moshkov M, Zielosko B.: Optimization of decision rules based on methods of dynamic programming. In Vestnik of Lobachevsky State University of Nizhni Novgorod, no. 6, pp. 195-200
23. Chen C.H.: Handbook of pattern recognition and computer vision. University of Massachusetts Dartmouth, USA (2015)
24. Gantmacher F. R.: Theory of matrices, p. 227. Science, Moscow (1968)
25. Murty M.N., Devi V.S: Pattern Recognition: An Algorithmic. Pp. 93-94 (2011)
2. Afontsev E.: Network anomalies, 2006 nag.ru/articles/reviews/15588 setevyie-anomalii.html
3. Berestov A.A.: Architecture of intelligent agents based on a production system to protect against virus attacks on the Internet. In: XV All-Russian Scientific Conference Problems of Information Security in the Higher School System”, pp. 180?276 (2008)
4. Galtsev A.V.: System analysis of traffic to identify anomalous network conditions: The thesis for the Candidate Degree of Technical Sciences. Samara (2013)
5. Kornienko A.A., Slyusarenko I.M.: Intrusion Detection Systems and Methods: Current State and Direction of Improvement, 2008 citforum.ru/security internet/ids overview/
6. Kussul N., Sokolov A.: Adaptive anomaly detection in the computer systems users behavior using Markov chains of variable order. Part 2: Methods of detecting anomalies and the results of experiments. In: Informatics and Control Problems. Issue 4, pp. 83?88 (2003)
7. Mirkes E.M.: Neurocomputer: draft standard. Science, Novosibirsk, pp. 150-176 (1999)
8. Tsvirko D.A. Prediction of a network attack route using production model methods, 2012 academy.kaspersky.ru/downloads/academycup participants/cvirko d. ppt
9. Somayaji A.: Automated response using system-call delays. In: USENIX Security Symposium 2000, pp. 185-197, 2000
10. Ilgun K.: USTAT: A Real-time Intrusion Detection System for UNIX. In: IEEE Symposium on Research in Security and Privacy, University of California (1992)
11. Eskin E., Lee W., and Stolfo S. J.: Modeling system calls for intrusion detection with dynamic window sizes. In: DARPA Information Survivability Conference and Exposition (DISCEX II), June 2001
12. Ye N., Xu M., and Emran S. M.: Probabilistic networks with undirected links for anomaly detection. In: 2000 IEEE Workshop on Information Assurance and Security, West Point, NY (2000)
13. Michael C. C. and Ghosh A.: Two state-based approaches to program-based anomaly detection. In: ACM Transactions on Information and System Security. No. 5(2), 2002
14. Garvey T.D., Lunt T.F.: Model-based Intrusion Detection. In: 14th Nation computer security conference, Baltimore, MD (1991)
15. Theus M. and Schonlau M.: Intrusion detection based on structural zeroes. In: Statistical Computing and Graphics Newsletter. No. 9(1), pp. 12?17 (1998)
16. Tan K.: The application of neural networks to unix computer security. In: IEEE International Conference on Neural Networks. Vol. 1, pp. 476?481, Perth, Australia (1995)
17. Ilgun K., Kemmerer R.A., Porras P.A.: State Transition Analysis: A Rule-Based Intrusion Detection System. In: IEEE Trans. Software Eng. Vol. 21, no. 3, (1995)
18. Eskin E.: Anomaly detection over noisy data using learned probability distributions. In: 17th International Conf. on Machine Learning, pp. 255?262. Morgan Kaufmann, San Francisco, CA (2000)
19. Ghosh K., Schwartzbard A., and Schatz M.: Learning program behavior profiles for intrusion detection. In: 1st USENIX Workshop on Intrusion Detection and Network Monitoring, pp. 51?62, Santa Clara, California (1999)
20. Ye N.: A markov chain model of temporal behavior for anomaly detection. In: 2000 IEEE Systems, Man, and Cybernetics, Information Assurance and Security Workshop (2000)
21. Axelsson S.: The base-rate fallacy and its implications for the difficulty of intrusion detection. In: ACM Conference on Computer and Communications Security, pp. 1?7 (1999)
22. Chikalov I, Moshkov M, Zielosko B.: Optimization of decision rules based on methods of dynamic programming. In Vestnik of Lobachevsky State University of Nizhni Novgorod, no. 6, pp. 195-200
23. Chen C.H.: Handbook of pattern recognition and computer vision. University of Massachusetts Dartmouth, USA (2015)
24. Gantmacher F. R.: Theory of matrices, p. 227. Science, Moscow (1968)
25. Murty M.N., Devi V.S: Pattern Recognition: An Algorithmic. Pp. 93-94 (2011)
Традиционно ждём ваши комментарии и приглашаем всех на день открытых дверей, который пройдет уже в следующий понедельник.
