Всем привет. Друзья, делимся с вами переводом статьи, подготовленным специально для студентов курса «Data Engineer». Поехали!

Сегодняшний пост основан на задаче, которой я недавно занимался на работе. Я был действительно рад, воплотить её и описать проделанную работу в формате блогпоста, поскольку это дало мне возможность позаниматься дата-инжинирингом, а также сделать что-то, что было бы весьма полезным для моей команды. Не так давно я обнаружил, что в наших системах хранится достаточно большой объем пользовательского лога, связанных с одним из наших продуктов для работы с данными. Оказалось, что никто не использовал эти данные, поэтому я сразу заинтересовался тем, что мы могли бы узнать, если бы начали регулярно анализировать их. Однако на пути было несколько проблем. Первая проблема заключалась в том, что данные хранились во многих различных текстовых файлах, которые не были доступны для мгновенного анализа. Вторая проблема заключалась в том, что они были сохранены в закрытой системе, поэтому я не мог использовать ни один из моих любимых инструментов для анализа данных.
Мне предстояло решить, как сделать доступ для нас проще и привнести хоть какую-нибудь ценность, встроив этот источник данных в некоторые из наших решений по взаимодействию с пользователями. Поразмыслив некоторое время, я решил сконструировать конвейер для передачи этих данных в облачную базу данных, чтобы я и команда могли получить к ним доступ и начать генерировать какие-либо выводы. После того, как я закончил специализацию Data Engineering в Coursera некоторое время назад, я горел желанием использовать в проекте некоторые инструменты из курса.
Таким образом размещение данных в облачной базе данных казалось разумным способом решения моей первой проблемы, но что я мог сделать с проблемой номер 2? К счастью, был способ перенести эти данные в среду, где я мог получить доступ к таким инструментам, как Python и Google Cloud Platform (GCP). Однако это был долгий процесс, поэтому мне нужно было сделать что-то, что позволило бы мне продолжать разработку, пока я ждал окончания передачи данных. Решение, к которому я пришел, заключалось в создании поддельных данных с использованием библиотеки Faker в Python. Я никогда раньше не пользовался этой библиотекой, но быстро понял, насколько она полезна. Использование этого подхода позволило мне начать писать код и тестировать конвейер без фактических данных.
С учетом уже сказанного, в этом посте я расскажу, как я построил описанный выше конвейер, используя некоторые из технологий, доступных в GCP. В частности, я буду использовать Apache Beam (версию для Python), Dataflow, Pub/Sub и Big Query для сбора пользовательских логов, преобразования данных и передачи их в базу данных для дальнейшего анализа. В моем случае мне была нужна только пакетная функциональность Beam, поскольку мои данные не поступали в режиме реального времени, поэтому Pub/Sub не требовался. Однако я остановлюсь на потоковой версии, так как это то, с чем вы можете столкнуться на практике.
Google Cloud Platform предоставляет набор действительно полезных инструментов для обработки больших данных. Вот некоторые из инструментов, которые я буду использовать:
В GCP доступно большое количество инструментов, поэтому может быть сложно охватить их все, включая их предназначение, но тем не менее вот краткое изложение для справки.
Давайте визуализируем компоненты нашего конвейера на рисунке 1. На высоком уровне мы хотим собирать пользовательские данные в режиме реального времени, обрабатывать их и передавать в BigQuery. Логи создаются, когда пользователи взаимодействуют с продуктом, отправляя запросы на сервер, которые затем и логируются. Эти данные могут быть особенно полезны для понимания того, как пользователи взаимодействуют с нашим продуктом и правильно ли они работают. В целом, конвейер будет содержать следующие этапы:
Beam делает этот процесс очень простым, независимо от того, есть ли у нас потоковый источник данных или же файл CSV, и мы хотим выполнить пакетную обработку. Позже вы увидите, что в коде присутствуют лишь минимальные изменения, необходимые для переключения между ними. Это одно из преимуществ использования Beam.
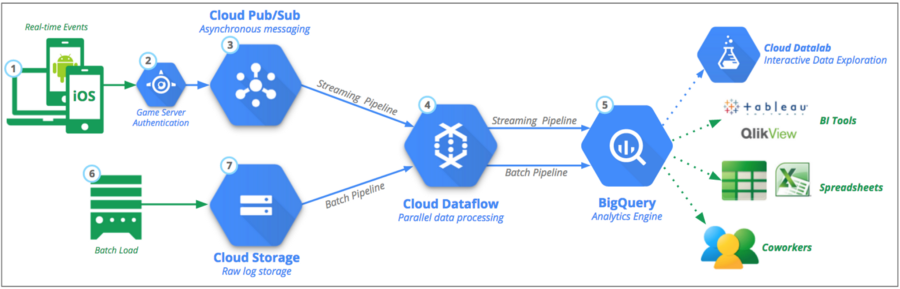
Рисунок 1: Основной конвейер данных
Как я уже упоминал ранее, из-за ограниченного доступа к данным я решил создать псевдоданные в том же формате, что и фактические. Это было действительно полезное упражнение, так как я мог написать код и протестировать конвейер, пока я ожидал данные. Предлагаю взглянуть на документацию Faker, если вы хотите узнать, что еще может предложить эта библиотека. Наши пользовательские данные будут в целом похожи на пример ниже. На основе этого формата мы можем построчно генерировать данные для имитации данных в реальном времени. Эти журналы дают нам такую информацию, как дата, тип запроса, ответ от сервера, IP-адрес и т. д.
Основываясь на строке выше, мы хотим создать нашу переменную LINE, используя 7 переменных в фигурных скобках ниже. Мы также будем использовать их как имена переменных в нашей схеме таблиц чуть позже.
Если бы мы выполняли пакетную обработку, код был бы очень похожим, хотя нам нужно было бы создать набор образцов в некотором временном диапазоне. Чтобы использовать фейкер, мы просто создаем объект и вызываем нужные нам методы. В частности, Faker был полезен для создания IP-адресов, а также веб-сайтов. Я использовал следующие методы:
Конец первой части.
В ближайшие дни поделимся с вами продолжением статьи, а сейчас традиционно ждем комментарии ;-).
Вторая часть

Apache Beam и DataFlow для конвейеров реального времени
Сегодняшний пост основан на задаче, которой я недавно занимался на работе. Я был действительно рад, воплотить её и описать проделанную работу в формате блогпоста, поскольку это дало мне возможность позаниматься дата-инжинирингом, а также сделать что-то, что было бы весьма полезным для моей команды. Не так давно я обнаружил, что в наших системах хранится достаточно большой объем пользовательского лога, связанных с одним из наших продуктов для работы с данными. Оказалось, что никто не использовал эти данные, поэтому я сразу заинтересовался тем, что мы могли бы узнать, если бы начали регулярно анализировать их. Однако на пути было несколько проблем. Первая проблема заключалась в том, что данные хранились во многих различных текстовых файлах, которые не были доступны для мгновенного анализа. Вторая проблема заключалась в том, что они были сохранены в закрытой системе, поэтому я не мог использовать ни один из моих любимых инструментов для анализа данных.
Мне предстояло решить, как сделать доступ для нас проще и привнести хоть какую-нибудь ценность, встроив этот источник данных в некоторые из наших решений по взаимодействию с пользователями. Поразмыслив некоторое время, я решил сконструировать конвейер для передачи этих данных в облачную базу данных, чтобы я и команда могли получить к ним доступ и начать генерировать какие-либо выводы. После того, как я закончил специализацию Data Engineering в Coursera некоторое время назад, я горел желанием использовать в проекте некоторые инструменты из курса.
Таким образом размещение данных в облачной базе данных казалось разумным способом решения моей первой проблемы, но что я мог сделать с проблемой номер 2? К счастью, был способ перенести эти данные в среду, где я мог получить доступ к таким инструментам, как Python и Google Cloud Platform (GCP). Однако это был долгий процесс, поэтому мне нужно было сделать что-то, что позволило бы мне продолжать разработку, пока я ждал окончания передачи данных. Решение, к которому я пришел, заключалось в создании поддельных данных с использованием библиотеки Faker в Python. Я никогда раньше не пользовался этой библиотекой, но быстро понял, насколько она полезна. Использование этого подхода позволило мне начать писать код и тестировать конвейер без фактических данных.
С учетом уже сказанного, в этом посте я расскажу, как я построил описанный выше конвейер, используя некоторые из технологий, доступных в GCP. В частности, я буду использовать Apache Beam (версию для Python), Dataflow, Pub/Sub и Big Query для сбора пользовательских логов, преобразования данных и передачи их в базу данных для дальнейшего анализа. В моем случае мне была нужна только пакетная функциональность Beam, поскольку мои данные не поступали в режиме реального времени, поэтому Pub/Sub не требовался. Однако я остановлюсь на потоковой версии, так как это то, с чем вы можете столкнуться на практике.
Введение в GCP и Apache Beam
Google Cloud Platform предоставляет набор действительно полезных инструментов для обработки больших данных. Вот некоторые из инструментов, которые я буду использовать:
- Pub/Sub — это служба обмена сообщениями, использующая шаблон Издатель-Подписчик (Publisher-Subscriber), которая позволяет нам получать данные в режиме реального времени.
- DataFlow — это сервис, который упрощает создание конвейеров данных и автоматически разрешает такие задачи, как масштабирование инфраструктуры, что означает, что мы можем сосредоточиться только на написании кода для нашего конвейера.
- BigQuery — это облачное хранилище данных. Если вы знакомы с другими базами данных на SQL, с BigQuery долго разбираться не придется.
- И наконец, мы будем использовать Apache Beam, а именно, сосредоточимся на Python версии для создания нашего конвейера. Этот инструмент позволит нам создать конвейер для потоковой или пакетной обработки, который интегрируется с GCP. Он особенно полезен для параллельной обработки и подходит для задач типа извлечения, преобразования и загрузки (ETL), поэтому, если нам нужно перемещать данные из одного места в другое с выполнением преобразований или вычислений, Beam — хороший выбор.
В GCP доступно большое количество инструментов, поэтому может быть сложно охватить их все, включая их предназначение, но тем не менее вот краткое изложение для справки.
Визуализация нашего конвейера
Давайте визуализируем компоненты нашего конвейера на рисунке 1. На высоком уровне мы хотим собирать пользовательские данные в режиме реального времени, обрабатывать их и передавать в BigQuery. Логи создаются, когда пользователи взаимодействуют с продуктом, отправляя запросы на сервер, которые затем и логируются. Эти данные могут быть особенно полезны для понимания того, как пользователи взаимодействуют с нашим продуктом и правильно ли они работают. В целом, конвейер будет содержать следующие этапы:
- Данные логов наших пользователей публикуются в Pub/Sub-разделе.
- Мы подключимся к Pub/Sub и преобразуем данные в соответствующий формат, используя Python и Beam (шаги 3 и 4 на рисунке 1).
- После преобразования данных Beam затем подключится к BigQuery и добавит их в нашу таблицу (шаги 4 и 5 на рисунке 1).
- Для проведения анализа мы можем подключиться к BigQuery, используя различные инструменты, такие как Tableau и Python.
Beam делает этот процесс очень простым, независимо от того, есть ли у нас потоковый источник данных или же файл CSV, и мы хотим выполнить пакетную обработку. Позже вы увидите, что в коде присутствуют лишь минимальные изменения, необходимые для переключения между ними. Это одно из преимуществ использования Beam.

Рисунок 1: Основной конвейер данных
Создание псевдоданных с помощью Faker
Как я уже упоминал ранее, из-за ограниченного доступа к данным я решил создать псевдоданные в том же формате, что и фактические. Это было действительно полезное упражнение, так как я мог написать код и протестировать конвейер, пока я ожидал данные. Предлагаю взглянуть на документацию Faker, если вы хотите узнать, что еще может предложить эта библиотека. Наши пользовательские данные будут в целом похожи на пример ниже. На основе этого формата мы можем построчно генерировать данные для имитации данных в реальном времени. Эти журналы дают нам такую информацию, как дата, тип запроса, ответ от сервера, IP-адрес и т. д.
192.52.197.161 - - [30/Apr/2019:21:11:42] "PUT /tag/category/tag HTTP/1.1" [401] 155 "https://harris-lopez.com/categories/about/" "Mozilla/5.0 (Macintosh; PPC Mac OS X 10_11_2) AppleWebKit/5312 (KHTML, like Gecko) Chrome/34.0.855.0 Safari/5312"Основываясь на строке выше, мы хотим создать нашу переменную LINE, используя 7 переменных в фигурных скобках ниже. Мы также будем использовать их как имена переменных в нашей схеме таблиц чуть позже.
LINE = """\
{remote_addr} - - [{time_local}] "{request_type} {request_path} HTTP/1.1" [{status}] {body_bytes_sent} "{http_referer}" "{http_user_agent}"\
"""Если бы мы выполняли пакетную обработку, код был бы очень похожим, хотя нам нужно было бы создать набор образцов в некотором временном диапазоне. Чтобы использовать фейкер, мы просто создаем объект и вызываем нужные нам методы. В частности, Faker был полезен для создания IP-адресов, а также веб-сайтов. Я использовал следующие методы:
fake.ipv4()
fake.uri_path()
fake.uri()
fake.user_agent()
from faker import Faker
import time
import random
import os
import numpy as np
from datetime import datetime, timedelta
LINE = """\
{remote_addr} - - [{time_local}] "{request_type} {request_path} HTTP/1.1" [{status}] {body_bytes_sent} "{http_referer}" "{http_user_agent}"\
"""
def generate_log_line():
fake = Faker()
now = datetime.now()
remote_addr = fake.ipv4()
time_local = now.strftime('%d/%b/%Y:%H:%M:%S')
request_type = random.choice(["GET", "POST", "PUT"])
request_path = "/" + fake.uri_path()
status = np.random.choice([200, 401, 404], p = [0.9, 0.05, 0.05])
body_bytes_sent = random.choice(range(5, 1000, 1))
http_referer = fake.uri()
http_user_agent = fake.user_agent()
log_line = LINE.format(
remote_addr=remote_addr,
time_local=time_local,
request_type=request_type,
request_path=request_path,
status=status,
body_bytes_sent=body_bytes_sent,
http_referer=http_referer,
http_user_agent=http_user_agent
)
return log_lineКонец первой части.
В ближайшие дни поделимся с вами продолжением статьи, а сейчас традиционно ждем комментарии ;-).
Вторая часть
