
Это гостевая публикация от Пэдди Байерса (Paddy Byers), сооснователя и технического директора Ably — платформы для стриминга данных в реальном времени. Оригинал статьи опубликован в блоге Ably.
Люди хотят быть уверены в надежности используемого сервиса. Однако в реальности отдельные компоненты неизбежно отказывают, и у нас должна быть возможность продолжать работу, несмотря на это.
В этой статье мы подробно рассмотрим концепции надежности и отказоустойчивости, которые стали определяющими при разработке платформы Ably.
Для начала дадим несколько определений:
Надежность — cтепень того, насколько пользователи могут положиться на продукт или сервис для решения своих задач. Доступность и устойчивость являются видами надежности.
Доступность — степень готовности продукта или сервиса к эксплуатации по требованию. Это понятие часто сcодят к обеспечению необходимого излишка ресурсов с учетом статистически независимых отказов.
Устойчивость — cпособность продукта или сервиса соответствовать заявленным характеристикам в процессе использования. Это значит, что система не просто готова к эксплуатации: благодаря дополнительным мощностям, предусмотренным в ходе проектирования, она может продолжать работать под нагрузкой, как и ожидают пользователи.
Отказоустойчивость — способность системы сохранять надежность (доступность и устойчивость) при отказе отдельных компонентов или сбоях в подсистемах.
Отказоустойчивые системы спроектированы таким образом, чтобы смягчать воздействие неблагоприятных факторов и оставаться надежными для конечного пользователя. Методы обеспечения отказоустойчивости могут использоваться для улучшения доступности и устойчивости.
Понятие доступности в широком смысле можно трактовать как гарантию безотказной работы в течение определенного времени. В свою очередь, устойчивость определяет качество этой работы, то есть гарантирует максимально эффективное сохранение функциональности и возможности взаимодействовать с пользователем в неблагоприятных условиях.
Если сервис не способен безотказно работать по требованию, значит, ему не хватает доступности. А если он готов к работе, но при этом отклоняется от заявленных характеристик в процессе использования, значит, не хватает устойчивости. Методы проектирования отказоустойчивых систем направлены на устранение этих недостатков и обеспечение бесперебойной работы системы как для бизнеса, так и для отдельных пользователей.
Доступность, устойчивость и состояние компонентов системы
Чаще всего в основе методов проектирования отказоустойчивых систем лежит понятие избыточности, подразумевающее наличие большего числа компонентов или мощностей, чем необходимо для работы сервиса. Ключевые вопросы здесь — какой вид избыточности выбрать и как ею управлять.
В физическом мире традиционно различают:
ситуации, угрожающие доступности, когда можно остановить и затем возобновить работу сервиса — например, остановить автомобиль, чтобы сменить покрышку;
ситуации, угрожающие устойчивости, когда бесперебойная работа сервиса является жизненно важной и обеспечивается постоянным использованием резервных компонентов — как, например, в случае с авиационными двигателями.
Разные требования к обеспечению бесперебойной работы определяют способ удовлетворения потребности в дополнительных мощностях.
В контексте распределенных систем, таких как Ably, существует аналогичное различие между компонентами, работающими с сохранением состояния и без сохранения состояния.
Компоненты, работающие без сохранения состояния, выполняют свои функции без привязки к долгоживущему состоянию. Каждое обращение к сервису выполняется независимо от предыдущих. Добиться отказоустойчивости таких компонентов сравнительно просто: нужно обеспечить доступность необходимых ресурсов, чтобы обращение к сервису выполнялось даже в условиях отказа некоторых из них.
Компоненты, работающие с сохранением состояния, непосредственно зависят от текущего состояния сервиса. Именно оно обеспечивает связь между текущим, прошлым и будущим обращениями. Для таких компонентов, как авиационные двигатели, смысл отказоустойчивости заключается в обеспечении бесперебойной работы, то есть в поддержании требуемого состояния сервиса. Это гарантирует их устойчивость.
Далее мы приведем примеры для каждой из описанных ситуаций и расскажем об инженерных задачах, которые приходится решать, чтобы обеспечить отказоустойчивость на практике.
Отказы неизбежны и естественны
В проектировании отказоустойчивых систем отказы воспринимаются как штатная ситуация. Нужно понимать, что в крупномасштабных системах они рано или поздно случаются. Отказы отдельных компонентов следует воспринимать как неизбежность и всегда быть к ним готовыми.
В отличие от физического мира, отказы в цифровых системах обычно не определяются двумя состояниями. Обычные показатели устойчивости компонентов (например, среднее время безотказной работы) к таким системам не применимы. Сервисы выходят из строя постепенно, после нескольких сбоев. Классический пример здесь — задача византийских генералов.
Предположим, что один из компонентов системы начал работать с перебоями и выдавать неверный результат. Или внешние партнеры не сообщали вам об отказе, пока ситуация не стала серьезной, и это сильно осложнило вашу работу.
Обеспечение устойчивости к таким отказам требует тщательного анализа, инженерного искусства и иногда человеческого участия. Каждую потенциальную неполадку необходимо выявить, классифицировать, а затем обеспечить возможность для ее скорейшего устранения или предотвратить ее с помощью масштабного тестирования и разумных проектных решений. Основная сложность при проектировании отказоустойчивых систем состоит в том, чтобы определить природу неполадок, понять, как их отследить и ликвидировать (особенно если отказы носят частичный или периодический характер), и в конечном счете сделать работу сервиса бесперебойной и максимально эффективной.
Сервисы без сохранения состояния
Сервисные слои без сохранения состояния не нуждаются в бесперебойной работе отдельных компонентов. Доступность ресурсов напрямую связана с доступностью всего слоя. Доступ к дополнительным ресурсам, отказы которых статистически не зависят друг от друга, — ключ к поддержанию работы системы. По возможности слои проектируются без сохранения состояния — это главный фактор для обеспечения не только доступности, но и масштабируемости.
Таким объектам достаточно иметь несколько независимо доступных компонентов, чтобы сервис продолжал работать. Без привязки к состоянию устойчивость отдельных составляющих не имеет значения.
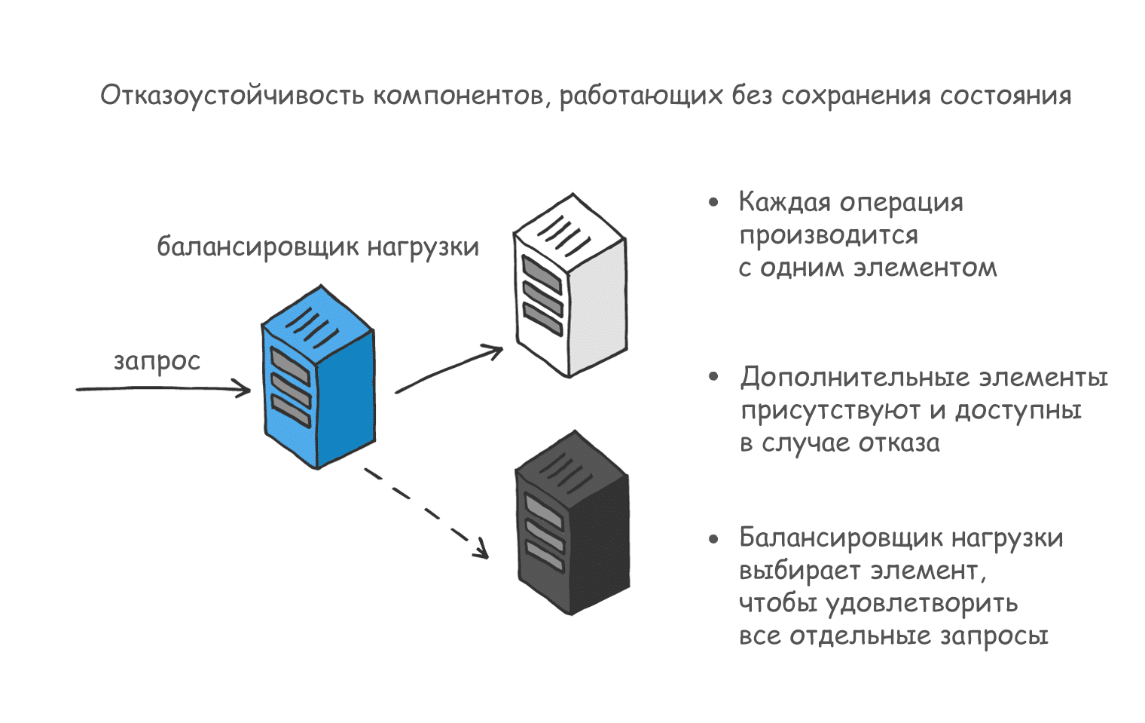
Однако простого наличия дополнительных ресурсов недостаточно — их нужно эффективно использовать. Необходимо иметь возможность определять их доступность и распределять между ними нагрузку.
Таким образом, надо задать себе следующие вопросы:
Как сохранить работоспособность системы после разных типов отказов?
Какой уровень избыточности возможно обеспечить?
Какие ресурсы и показатели производительности необходимы, чтобы его поддерживать?
Каких эксплуатационных расходов требует управление этим уровнем избыточности?
Выбранное решение должно удовлетворять следующим критериям:
Требования клиентов к высокой доступности сервиса
Уровень эксплуатационных расходов для бизнеса
Инженерная целесообразность
Дополнительные компоненты и отношения между ними необходимо проектировать, настраивать и эксплуатировать таким образом, чтобы все отказы были статистически независимыми. Согласно простым расчетам, при увеличении уровня избыточности вероятность катастрофического отказа уменьшается по экспоненте. Если сбои возникают статистически независимо друг от друга, они не имеют накопительного эффекта и вероятность полного отказа системы на порядок снижается с добавлением каждого дополнительного ресурса.
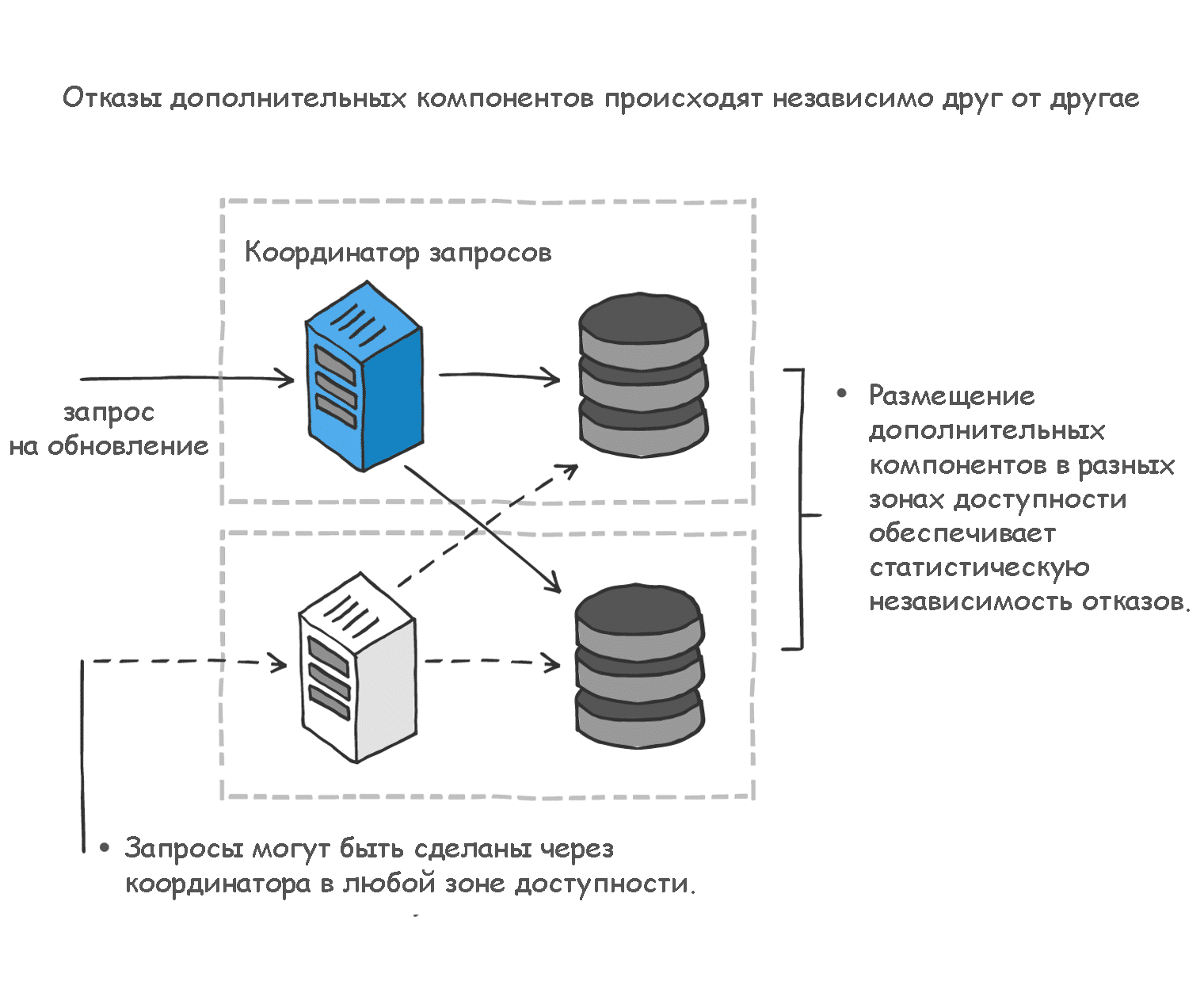
Чтобы увеличить степень статистической независимости отказов в Ably, мы распределили мощности по множественным зонам доступности в разных регионах. Оказывать услуги из нескольких зон доступности в одном регионе проще — AWS делает это практически без усилий. Зоны доступности в целом хорошо позволяют поддерживать независимость отказов, но их создание само по себе предполагает обеспечение необходимой избыточности для поддержания высокого уровня доступности.
Однако это еще не все. Мы не можем полностью положиться на один регион — иногда несколько зон доступности отказывают одновременно или все они становятся недоступными из-за локальных проблем со связью. А иногда региональные ограничения мощности делают поддержку сервисов невозможной. Поэтому мы обеспечиваем доступность нашего сервиса, предоставляя его из множества регионов. Это лучший способ гарантировать статистическую независимость отказов.
Обеспечение избыточности сразу для нескольких регионов работает не так хорошо, как поддержка множества зон доступности. Например, нет смысла распределять запросы между регионами с помощью балансировщика нагрузки, поскольку он сам находится в конкретном регионе и может стать недоступным.
Вместо этого мы используем комплекс мер, чтобы всегда направлять запросы клиентов туда, где все исправно работает и сервис доступен. Как правило, это ближайший регион, но если он недоступен, их можно перенаправить и дальше.
Сервисы с сохранением состояния
В Ably устойчивость определяется бесперебойной работой сервисов с сохранением состояния, и добиться этого намного сложнее, чем просто обеспечить доступность.
Работа таких сервисов напрямую зависит от конкретного состояния, которое устанавливается при каждом обращении к ним. Стабильность этих состояний обеспечивает корректную работу сервиса на уровне целого слоя. Это значит, что отказоустойчивости сервисов без сохранения состояния можно добиться, применяя к ним стандартные категории устойчивости. Чтобы не потерять текущие состояния в случае отказа, необходимо обеспечить постоянный уровень избыточности. Выявление и исправление дефектов позволяет устранить возможность возникновения византийских отказов с помощью механизмов достижения консенсуса.
Самая простая аналогия здесь — полет на самолете. Если он упадет, это будет катастрофой, потому что вы в своем текущем состоянии находитесь в этом конкретном самолете. Так что именно от него вы ожидаете бесперебойной работы. В случае отказа состояние будет потеряно, и вы не сможете пересесть в другой самолет.
Когда работа сервиса зависит от состояния, при переключении на запасной ресурс он должен иметь возможность начать с того же места, где закончил. Поддержание текущего состояния становится необходимостью, и в этом случае одной доступности недостаточно.
В Ably мы предоставляем достаточно резервных мощностей для ресурсов без сохранения состояния, чтобы удовлетворить требования клиентов к доступности. Однако объектам с сохранением состояния необходимы не только дополнительные ресурсы, но и четкие инструкции по их использованию, чтобы обеспечить гарантированную функциональную бесперебойность сервиса.
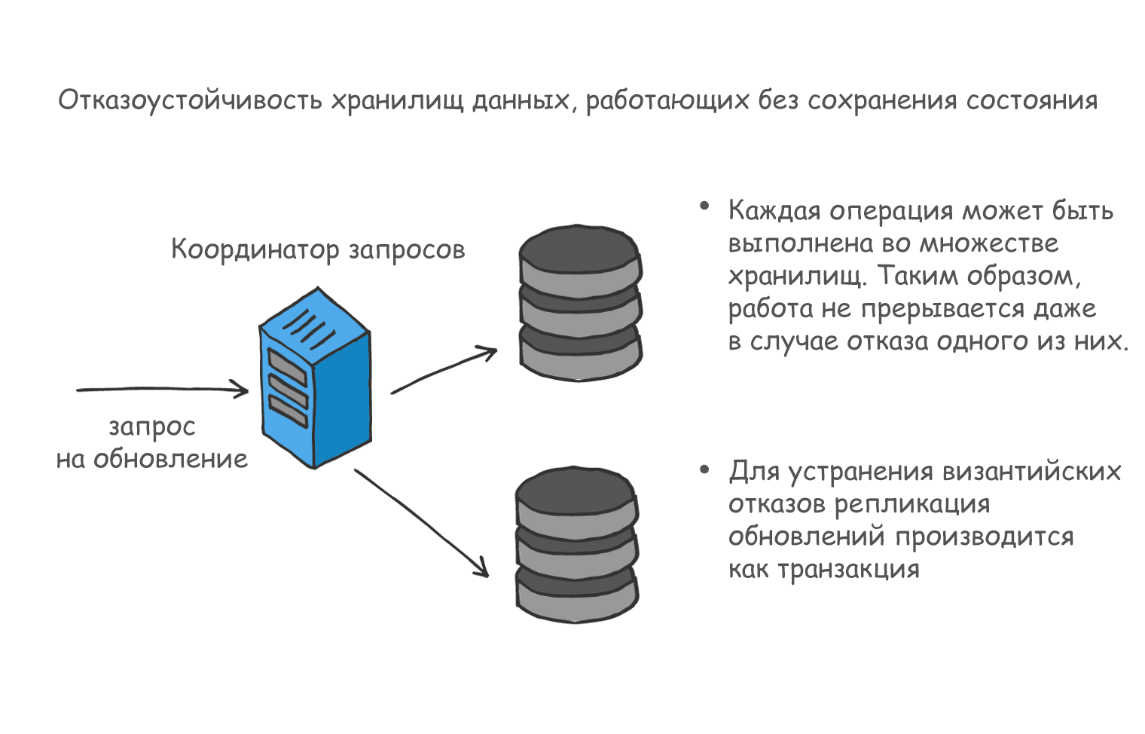
Например, если обработка информации для определенного канала ведется на определенном инстансе, входящем в кластер, то в случае отказа этого инстанса (что приведет к изменению роли канала) для продолжения работы понадобятся дополнительные механизмы.
Они действуют на нескольких уровнях. На первом из них задача такого механизма — гарантировать, что для обработки информации канала будет назначен другой, исправный ресурс. На следующем уровне необходимо убедиться, что новый ресурс продолжил работу с той же точки, где она была прервана. Далее каждый из упомянутых механизмов работает с определенным уровнем избыточности, чтобы обеспечить соблюдение общих требований к сервису.
Эффективность механизмов обеспечения бесперебойной работы напрямую влияет на поведение сервиса и контроль этого поведения в рамках предоставления услуги. Возьмем конкретную проблему из приведенного выше сценария: в случае с каждым отправленным сообщением вам необходимо точно знать, завершена его обработка или нет.
Когда клиент отправляет сообщение в Ably, сервис принимает его и уведомляет, была попытка публикации успешной или нет. В этом случае главный вопрос в контексте обеспечения доступности будет таким:
«В течение какой доли времени сервис может принимать (и обрабатывать) сообщения, а не отклонять их?»
Минимальный целевой показатель доступности для нас — 99,99; 99,999 или даже 99,9999 %.
Если вы попытались опубликовать сообщение и мы уведомили вас, что попытка не удалась, это говорит о нехватке доступности. Это плохо, но, по крайней мере, вы в курсе ситуации.
А вот если мы ответили: «Да, мы получили ваше сообщение», но не смогли выполнить последующую обработку, это уже другой тип отказа, связанный с невозможностью обеспечить гарантированный функционал сервиса. Это нехватка устойчивости, которая является для распределенных систем намного более серьезной проблемой. Ее решение требует масштабных и сложных инженерно-технических работ.
Архитектурный подход к обеспечению устойчивости
Следующие две иллюстрации наглядно демонстрируют архитектурный подход, который мы внедрили в Ably для оптимального использования избыточности при обработке сообщений.
Размещение роли с сохранением состояния
Обычно горизонтальное масштабирование достигается путем распределения задач в масштабируемом кластере вычислительных ресурсов. Сущности, работающие без сохранения состояния, можно распределить среди доступных ресурсов с некоторыми ограничениями: место выполнения каждой назначенной операции должно определяться с учетом балансировки нагрузки, близости расположения и других соображений оптимизации.
В случае с операциями, которые выполняются с сохранением состояния, этот фактор необходимо учитывать при размещении ролей — например, определить для всех сущностей, задействованных в обработке данных, конкретное местоположение каждой назначенной роли.
Конкретный пример — обработка сообщений, передаваемых по каналу. Когда канал активен, для него назначается ресурс, который выполняет эту операцию. Поскольку этот процесс выполняется с сохранением состояния, мы можем добиться хорошей производительности: мы достаточно знаем о сообщении во время его обработки, так что нам нет необходимости просматривать его — остается просто отправить.
Чтобы как можно более равномерно распределить каналы по доступным ресурсам, мы используем последовательное хеширование. При этом соответствующая служба обзора кластеров обеспечивает согласование между такими параметрами, как работоспособность узлов и их членство в хеш-кольце.
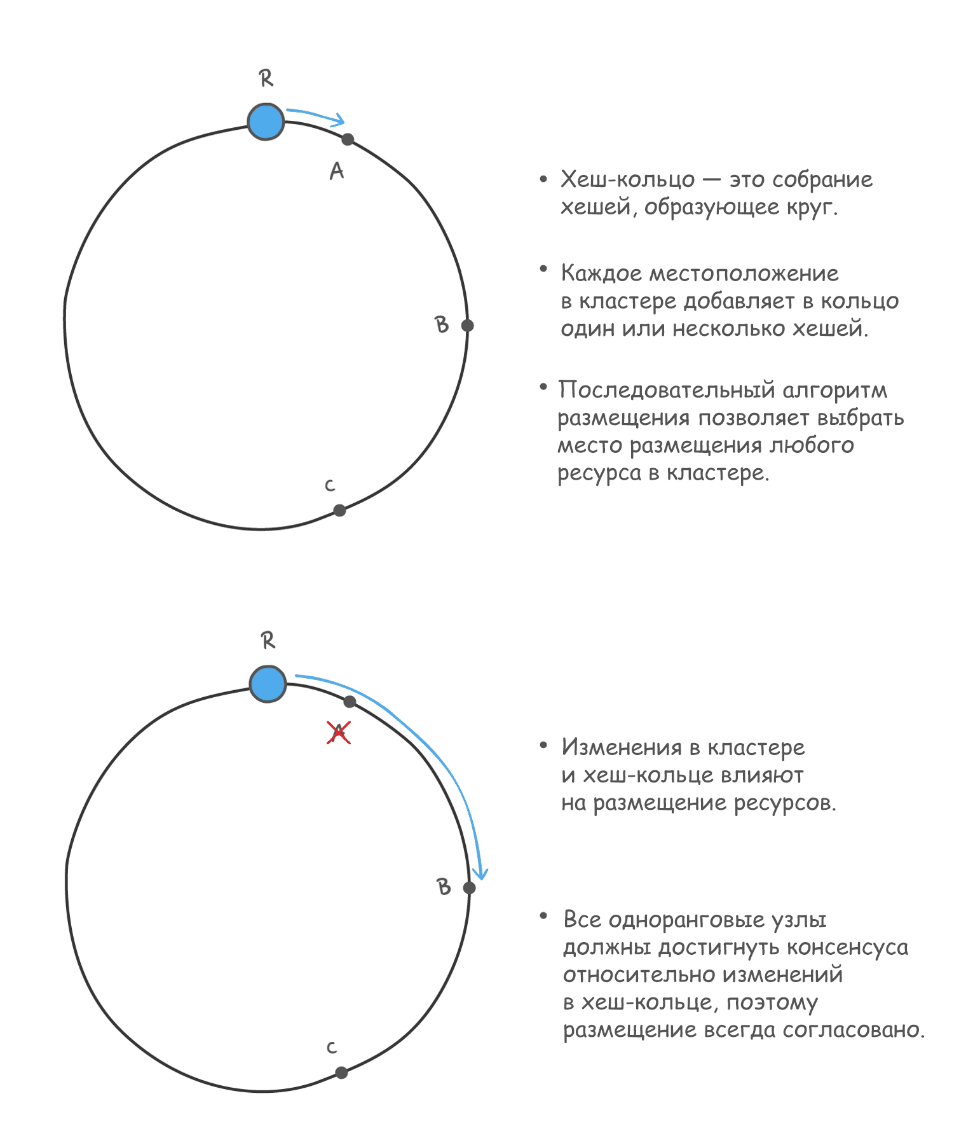
Это становится возможным благодаря последовательному алгоритму размещения в хеш-кольце
Механизм размещения позволяет определить не только первоначальное расположение роли, но и место, куда она переместится в результате таких событий, как отказ узла. Таким образом, динамический механизм размещения ролей играет ключевую роль в обеспечении устойчивости и бесперебойной работы сервиса.
Выявить, хешировать, продолжить
Первый шаг к уменьшению риска отказов — выявление неполадок. Как было сказано выше, это обычно вызывает затруднения, потому что требует почти мгновенного согласования между распределенными сущностями. Как только сбой обнаружен, состояние хеш-кольца обновляется и определяет новое расположение для отказавшего ресурса, где он продолжит работу с тем же каналом и в том же состоянии.
Даже если роль не была выполнена и произошла потеря состояния, нужно обеспечить его поддержку (с необходимой избыточностью), чтобы восстановить непрерывное выполнение роли. Именно эта непрерывность позволяет сервису сохранять устойчивость к отказам такого рода. Состояние всех сообщений в очереди сохраняется во время перемещения роли. Если вместо этого у нас получилось просто переназначить роль, сохранив состояние, значит, мы обеспечили доступность сервиса — но не его устойчивость.
Слой обеспечения постоянства канала
Когда сообщение опубликовано, мы обрабатываем его, определяем, была ли попытка публикации успешной, а затем отвечаем на запрос к сервису. Гарантированная устойчивость в этом случае означает уверенность в том, что, как только сообщение принято, все последующие операции по пересылке будут выполнены по умолчанию. В свою очередь, это значит, что мы подтверждаем публикацию сообщения, только когда уверены, что оно сохранено с обеспечением постоянства, с применением необходимой избыточности и не будет утеряно.
Во-первых, данные о приеме сообщения записываются как минимум в двух разных зонах доступности. Во-вторых, к этим зонам доступности предъявляются те же требования избыточности при последующем процессе обработки данных. Это главный принцип работы слоя обеспечения постоянства в Ably: мы записываем сообщение в нескольких местах и следим за тем, чтобы процесс записи был транзакционным. Мы прекращаем его, только убедившись, что попытка записи была неудачной или однозначно успешной. Зная это, мы можем быть уверены, что дальнейшая обработка будет произведена даже при отказе ролей, ответственных за этот процесс.
Тот факт, что сообщение сохранено в нескольких зонах доступности, позволяет предположить, что отдельные независимые отказы в них не приведут к потере данных. Для подобного размещения необходима координация между зонами доступности. А уверенность в том, что запись данных в нескольких местах действительно является транзакционной, требует достижения распределенного консенсуса на всем слое обеспечения постоянства при обработке сообщений.
Благодаря нашей математической модели при отказе узла мы точно знаем, сколько времени уйдет на выявление причины сбоя, достижение консенсуса и последующего перемещения роли. Эти данные вкупе с частотой отказов для каждой зоны доступности позволяют создать вероятностную модель возникновения комплексного сбоя, который может привести к потере текущего состояния сервиса. Описанные базовые принципы позволяют нам гарантировать устойчивость работы сервиса с вероятностью 99,999 999 %.
Вопросы внедрения отказоустойчивости
Даже если у вас есть теоретическое представление о том, как добиться определенного уровня отказоустойчивости, существует несколько практических и инженерных вопросов, которые необходимо рассматривать в контексте всей системы. Ниже мы приводим несколько примеров. Чтобы узнать больше по этой теме, прочитайте нашу статью Подводные камни масштабирования распределенных систем: проектирование системы в реальных условиях.
Достижение консенсуса в глобально распределенных системах
Описанные выше механизмы, такие как алгоритм размещения ролей, могут быть эффективными только в том случае, если все участвующие в них сущности находятся в согласии по поводу топологии кластера, а также статуса и работоспособности каждого узла.
Это классическая проблема достижения консенсуса: члены кластера, каждый из которых сам может пережить отказ, должны договориться о статусе одного из них. Протоколы достижения консенсуса, такие как Raft или Paxos, широко известны и имеют прочную теоретическую базу. Однако на практике в них существует ряд ограничений, касающихся масштабирования и ширины канала связи. В частности, они не эффективны в сетях, которые охватывают множество регионов, потому что их производительность падает, как только задержка при передаче данных между одноранговыми узлами становится слишком большой.
Поэтому наши одноранговые узлы используют протокол Gossip: он отказоустойчив, способен к работе в нескольких регионах и позволяет достичь согласования по прошествии некоторого времени. Gossip позволяет распространять между регионами данные о топологии сети и создает ее карту. Достигнутый таким образом консенсус об общем состоянии используется в качестве основы для распространения данных на уровне всего кластера.
Работоспособность не определяется двумя состояниями
Классическая теория, которая легла в основу разработки протоколов Paxos и Raft, базируется на том, что при отказе или проблемах с работоспособностью сущности не просто сбоят или перестают отвечать на запросы. Вместо этого они могут выдавать отдельные симптомы неполадок, такие как отклонение запросов, высокий процент ошибок или в целом нестабильное и некорректное поведение (см. Задача византийских генералов). Эта проблема стоит очень остро и касается даже взаимодействия клиентов с сервисом.
Когда клиент пытается подключиться к конечной точке в том или ином регионе, может оказаться, что этот регион недоступен. При полном отсутствии доступа мы понимаем, что это простой отказ, можем выявить его и перенаправить клиента в другую точку инфраструктуры. Но на практике такой регион может просто демонстрировать частичное ухудшение качества работы в отдельные моменты времени. Таким образом, клиент не сможет решить проблему самостоятельно. Для этого ему нужно знать, куда его перенаправили и когда он сможет повторить попытку воспользоваться сервисом с предыдущей конечной точки.
Это еще один пример общей проблемы обеспечения отказоустойчивости распределенных систем: в них множество подвижных элементов, каждый из которых создает добавочную сложность. Если один из них выйдет из строя или его статус изменится, как достигнуть консенсуса по поводу наличия изменений, их природы и последующего плана действий?
Проблема доступности ресурсов
Говоря простым языком, она заключается в том, что обеспечить избыточные мощности можно только при условии доступности ресурсов. Периодически возникают ситуации, когда конкретный регион не может получить доступ к необходимым ресурсам и приходится перенаправлять запрос в другой регион.
Однако иногда проблема становится более сложной — когда вы понимаете, что механизмы обеспечения отказоустойчивости сами по себе требуют привлечения дополнительных ресурсов.
Например, это может быть механизм перемещения ролей из-за изменения топологии. В его работе задействуются такие ресурсы, как мощности процессора и оперативная память затрагиваемых инстансов.
Но что если отказ произошел как раз из-за нехватки ресурсов процессора или памяти? Вы пытаетесь решить проблему, но для этого нужны процессор и память! Таким образом, есть множество областей, в которых необходимо иметь достаточный запас дополнительных ресурсов, чтобы вовремя принимать меры противодействия отказам.
Проблема масштабирования ресурсов
Добавим к сказанному выше, что проблема может возникнуть не только с доступностью ресурсов, но и вследствие частоты запросов на их масштабирование. В стабильной, работоспособной системе у вас может быть N каналов, N подключений, N сообщений и N мощностей для их обработки. Теперь представим, что произошел отказ, который привел к сбою в работе кластера из N инстансов. Если объем работ, необходимых для компенсации сбоя, составляет N², то затраты на поддержку резервных мощностей примут и вовсе неподъемный объем, так что единственным возможным решением станет переключение на другой регион или кластер.
Тривиальные механизмы обеспечения отказоустойчивости могут демонстрировать сложность O(N²) или даже хуже, и это необходимо учитывать при поиске решения проблемы. Это еще одно напоминание о том, что отказ может произойти не только в результате поломки — его причиной может стать слишком большой масштаб, сложность инфраструктуры и другие факторы нерационального использования ресурсов.
Заключение
Отказоустойчивость — это подход к созданию системы, позволяющий ей выдерживать и минимизировать влияние неблагоприятных событий и условий эксплуатации, неизменно обеспечивая уровень обслуживания, ожидаемый пользователями.
Говоря об инжиниринге надежности в физическом мире, мы, как правило, разделяем понятия доступности и устойчивости. Существуют широко известные методы достижения этих состояний посредством обеспечения отказоустойчивости и избыточности. В Ably мы используем аналогичные определения компонентов системы, выделяя те, что работают без сохранения состояния и с сохранением состояния.
Отказоустойчивость компонентов, работающих без сохранения состояния, достигается так же, как доступность в физическом мире — путем обеспечения дополнительных ресурсов, отказы которых статистически независимы друг от друга. Отказоустойчивость компонентов, работающих с сохранением состояния, можно сравнить с устойчивостью: она определяется поддержанием бесперебойной работы сервиса. Непрерывность состояния — важнейший параметр отказоустойчивости, поскольку от него зависит корректная и бесперебойная работа сервиса.
Для достижения отказоустойчивости системные отказы следует воспринимать как рутинные и ожидаемые события, а не как что-то необычное. В отличие от теоретических моделей, использующих бинарную концепцию «успешная работа — отказ», работоспособность реальной системы не определяется этими двумя состояниями и требует комплексного подхода к отказоустойчивости, сочетающего теоретические знания и практические навыки.
Сервис Ably включает множество слоев, на каждом из которых применяется целый ряд механизмов обеспечения отказоустойчивости. Перечень инженерных проблем, с которыми мы столкнулись, включал в числе прочего размещение ролей с сохранением состояния, выявление отказов, хеширование и возможность постепенного восстановления сервиса. Мы также гарантируем непрерывность работы сервиса на слое обеспечения постоянства: например, то, что дальнейшая обработка сообщения будет продолжена, после того как мы подтвердили его получение.
Практическое проектирование отказоустойчивых систем подразумевает решение ряда реальных инженерных проблем. Среди них проблемы доступности и масштабирования инфраструктуры, достижение консенсуса и координация постоянно меняющейся топологии кластеров и узлов глобально распределенной системы, неожиданные и трудноопределяемые сбои в работе каждой сущности.
Разрабатывая платформу Ably с учетом описанных здесь принципов, мы стремились создать лучшее в своем классе корпоративное решение. Поэтому сейчас мы можем обеспечить клиентам гарантированно высокий уровень обслуживания благодаря доступности, устойчивости, надежности и отказоустойчивости нашего сервиса.
Перевод материала подготовлен в рамках курса "Highload Architect". Всех желающих приглашаем на день открытых дверей онлайн, где вы сможете узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса. Регистрация здесь
