
В первой статье мы развернули сервер MySQL под управлением ОС Linux. Однако, одного сервера для серьезной инсталляции будет явно недостаточно, так как отсутствие реплик накладывает некоторые ограничения на эффективность использование СУБД. Например, инсталляция, состоящая из одного сервера, не обладает отказоустойчивостью. В случае сбоя мы можем рассчитывать только на резервную копию, если она есть. Кроме того, построение отчетов, выполнение того же бэкапа и другие ресурсоемкие операции создают нагрузку на сервер, снижая его производительность. А для серьезных систем отдельно можно упомянуть необходимость горизонтального масштабирования. Даже если ваш сервер живет в облаке, ресурсы этого облака не бесконечны, и вы можете столкнуться с тем, что вам не хватает ядер или памяти, а добавить уже нельзя.
Эти доводы нас подводят к тому, что необходимо реплицировать данные с основного сервера для того, чтобы иметь рабочую копию данных на случай сбоя, а также второй узел, на котором можно запускать ресурсоемкие операции, не опасаясь просадки производительности.
Также в целях оптимизации производительности можно также настроить секционирование больших таблиц.
В этой статье мы сначала настроим репликацию данных на второй сервер, а затем рассмотрим различные варианты секционирования.
Зачем реплицировать
Но сначала мы немного поговорим о теории – в данном случае о том, какие механизмы синхронизации бывают. Под репликацией мы будем понимать процесс копирования данных из одного источника на множество других. При репликации изменения, сделанные в одной копии объекта, могут быть распространены в другие копии. Репликация может быть синхронной или асинхронной (как вариант полусинхронной).
При синхронной репликации, если основная реплика обновляется, все другие реплики того же фрагмента данных тоже обновляются в одной и той же транзакции. Логически это означает, что существует лишь одна версия данных. Например, если мы помещаем данные в базу, мы должны дождаться пока данные не будут помещены в 50% реплик + 1 реплика, иначе коммит не произойдет. Синхронные репликации создают дополнительную нагрузку при выполнении транзакций и могут вызывать проблемы, связанные с доступностью данных.
На рисунке ниже, коммит будет получен только после выполнения шага 4.
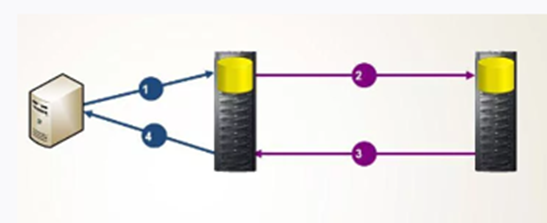
И в завершении этого абзаца скажу главное о синхронной репликации в MySQL – ее нет!
Особенностью асинхронной репликации является то, что обновление одной реплики распространяется на другие спустя некоторое время, а не в той же транзакции. При асинхронной репликации у нас появляется задержка, или время ожидания, в течение которого отдельные реплики могут быть фактически неидентичными.
Рассмотрим на примере, как работает асинхронная репликация.
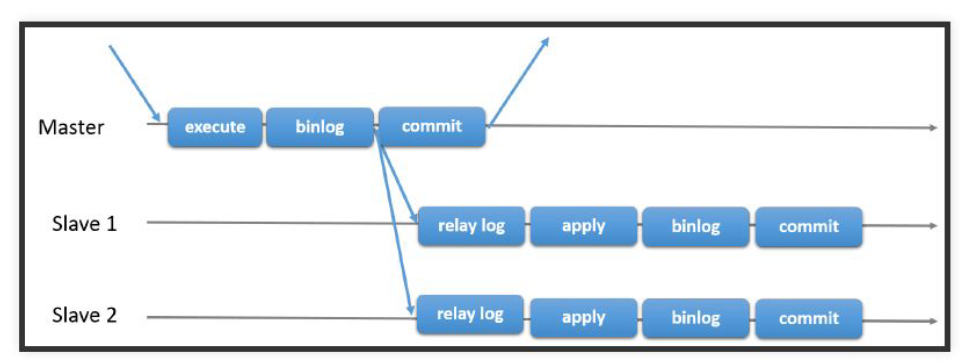
Запрос выполняется на мастере, далее бинлог мастера передается по запросу через потоки в relay log на Slave. При этом, на мастере происходит коммит. На слейве Relay Log проигрывается, применяется и сохраняется и затем на нем тоже происходит коммит. Очевидным недостатком такого подхода является наличие задержки на стороне подчиненного сервера.
Полусинхронная репликация предполагает коммит на Мастере только после получения доставки relay log на все подчиненные серверы.
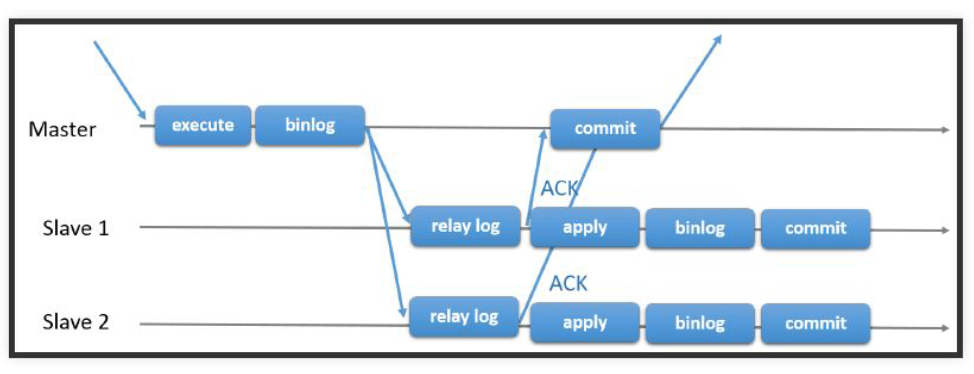
При таком подходе у нас задержки меньше (реплики меньше отстают), но снижается скорость работы Мастера из-за необходимости ждать подтверждения от подчиненных узлов.
В MySQL мы можем выбрать, какую репликацию хотим использовать асинхронную или полусинхронную. Но выбор должен быть сделан для всей БД.
Настраиваем асинхронную репликацию
В качестве примера настройки репликации мы выполним синхронную репликацию между двумя серверами MySQL. Информация по узлам представлена на следующей схеме:
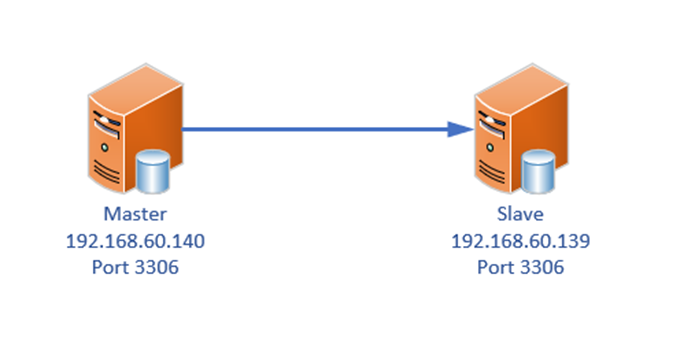
Перед началом у нас уже должны быть развернуты СУБД на обоих серверах и созданы тестовые таблицы. Прежде, чем начать настройку репликации необходимо убедиться в наличии соединения на нижних уровнях модели OSI. Проще говоря проверить пинг на IP адреса и телнет на порты 3306.
Сначала выполняем настройки на Мастере.
Узнаем его ID
select @@server_id;Должна быть 1.
Далее идем в файл конфигов /etc/mysql/mysql.conf.d/mysqld.cnf и правим значение bind-address
nano /etc/mysql/mysql.conf.d/mysqld.cnf
bind-address = 192.168.60.140
Рестартуем базу.
service mysql restartДалее выполняем на Мастере следующие команды:
create user repl@192.168.60.139 IDENTIFIED WITH caching_sha2_password BY 'oTUSlave#2020';
GRANT REPLICATION SLAVE ON *.* TO repl@192.168.60.139;
SELECT User, Host FROM mysql.user;
SHOW MASTER STATUS;Мы создали пользователя repl и дали ему права на репликацию на 192.168.60.139.
Теперь настраиваем подчиненный узел. Если спросить у него ID то мы получим значение 1, а нам необходимо его поменять. Для этого правим /etc/mysql/mysql.conf.d/mysqld.cnf:
nano /etc/mysql/mysql.conf.d/mysqld.cnf
server_id = 2И перезапускаем mysql.
sudo service mysql restartДалее на слейве выполняем следующие команды:
CHANGE MASTER TO MASTER_HOST='192.168.60.140', MASTER_USER='repl', MASTER_PASSWORD='oTUSlave#2020', MASTER_LOG_FILE='binlog.000004', MASTER_LOG_POS=900, GET_MASTER_PUBLIC_KEY = 1;
START SLAVE;Не забудьте указать GET_MASTER_PUBLIC_KEY = 1 , иначе получите ошибку из-за отсутствия публичного ключа.
Посмотрим состояние:
show slave status\G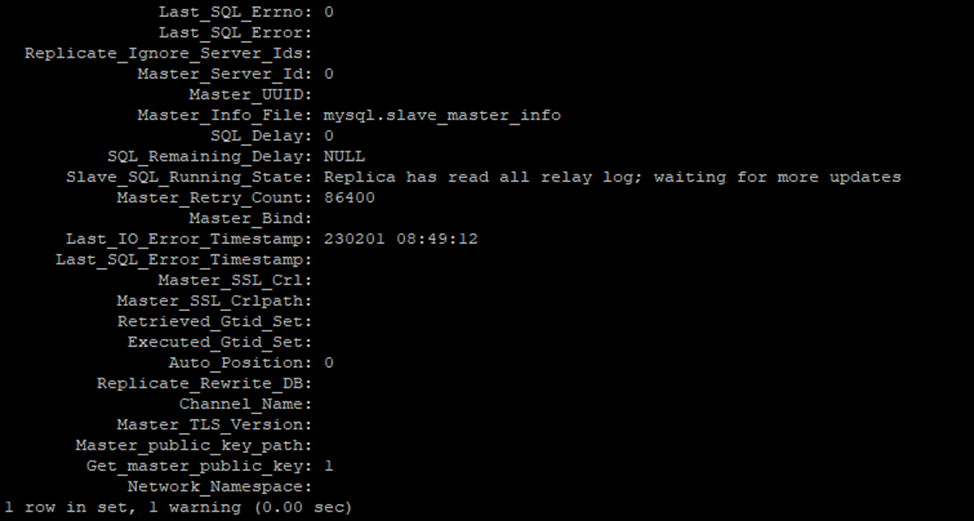
Также можно посмотреть статусы репликации с помощью следующих команд:
use performance_schema;
show tables like '%replic%';И в завершение настройки рекомендуется включать для слейва следующий параметр, иначе на нем можно будет вносить изменения, что будет не очень хорошо для целостности данных.
set global innodb_read_only = ONСекционирование
Секционирование, также используют термин Партиционирование (Partitioning) – разбиение таблицы на секции, по ключу секционирования. Обычно этот механизм используют для разбиения больших таблиц на логические части по выбранным критериям с целью ускорения процесса выборки данных. Преимуществом партиционирования является возможность сохранять большее количество данных в одной таблице, чем может быть записано на одиночном диске или файловой системе. С помощью секционирования можно легко удалить не нужные данные, удалив соответствующий раздел. Наоборот, процесс добавления новых данных в некоторых случаях может быть значительно облегчен, при добавлении нового раздела специально для этих данных.
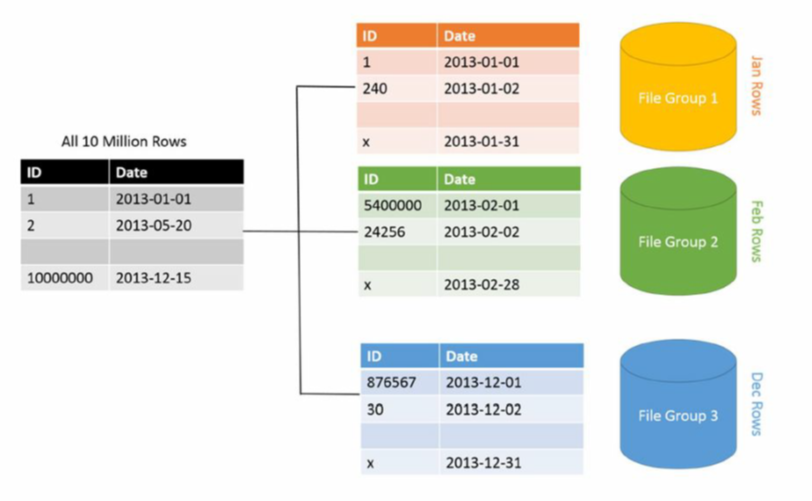
Если рассматривать секционирование непосредственно в MySQL, то на нижнем уровне для myISAM таблиц, это будут физически разные файлы, по 3 на каждую партицию (описание таблицы, файл индексов, файл данных). Для innoDB таблиц в конфигурации по умолчанию – разные пространства таблиц в файлах innoDB.
В MySQL предусмотрены четыре способа «разделения» данных:
RANGE
LIST
HASH
KEY
Рассмотрим каждый из них подробнее:
RANGE
Секционирование по диапазону значений. Если у нас в поле file_id хранятся значения для записей, то мы можем создать несколько разделов, в каждом из которых будут записи из определенных диапазонов file_id.
PARTITION BY RANGE (file_id) (
PARTITION f0 VALUES LESS THAN (10),
PARTITION f1 VALUES LESS THAN (20),
PARTITION f3 VALUES LESS THAN (30)
);LIST
Секционирование по точному списку значений. Задаем список значений и по ним данные помещаются в разделы:
PARTITION BY LIST(file_id) (
PARTITION pOne VALUES IN (3,5,6,9,17),
PARTITION pTwo VALUES IN (1,2,10,11,19,20)
)HASH
При использовании метода HASH у вас нет возможности как-то повлиять на разделение данных, вы просто указываете по какому полю строить хэш.
PARTITION BY HASH(file_id)
PARTITIONS 4;KEY
Аналогично HASH, но по ключу. То есть, производится выборка по указанному ключевому полю.
PARTITION BY KEY(s1)
PARTITIONS 10;Выбор метода секционирования как правило зависит от структуры данных в базе, а также от времени заполнения таблиц. Если необходимо просто разделить данные по времени, то лучше всего подойдет RANGE, LIST подойдет там, где необходимо разделить данные по определенному признаку. Оставшиеся два типа подойдут при необходимости равномерного распределения данных.
Заключение
В этой статье мы рассмотрели виды репликации данных, используемых в MySQL. Но при этом осталась за кадром такая интересная тема, как траблшутинг. Мы вернемся к ней в последующих статьях по администрированию БД.
Секционирование поможет ускорить работу базы, а также может пригодиться при выполнении бэкапов, о которых мы будем говорить в следующей статье.
В заключение рекомендую к посещению открытое занятие, посвященное погружению в PostgreSQL. Урок будет включать в себя:
Знакомство с базой данных – особенности, немножко истории, полезность и актуальность.
Способы развертывания и установки, сама установка.
Практическая часть: рассмотрим особенность, присущую этой базе данных – например, способ хранения данных, разбор сложной задачи и различных вариантов построения архитектуры ее решения.
Записаться можно на странице курса «Базы данных».
