 В этой книге вы найдете ключевые принципы, алгоритмы и компромиссы, без которых не обойтись при разработке высоконагруженных систем для работы с данными. Материал рассматривается на примере внутреннего устройства популярных программных пакетов и фреймворков. В книге три основные части, посвященные, прежде всего, теоретическим аспектам работы с распределенными системами и базами данных. От читателя требуются базовые знания SQL и принципов работы баз данных.
В этой книге вы найдете ключевые принципы, алгоритмы и компромиссы, без которых не обойтись при разработке высоконагруженных систем для работы с данными. Материал рассматривается на примере внутреннего устройства популярных программных пакетов и фреймворков. В книге три основные части, посвященные, прежде всего, теоретическим аспектам работы с распределенными системами и базами данных. От читателя требуются базовые знания SQL и принципов работы баз данных.В обзорном посте рассматривается раздел «Знание, истина и ложь».
Если у вас нет опыта работы с распределенными системами, то последствия этих проблем могут оказаться весьма дезориентирующими. Узел сети ничего не знает наверняка — он способен только делать предположения на основе получаемых (или не получаемых) им по сети сообщений. Один узел в силе узнать состояние другого узла (какие данные на нем хранятся, правильно ли он работает), только обмениваясь с ним сообщениями. Если удаленный узел не отвечает, то нет никакого способа выяснить его состояние, поскольку невозможно отличить сетевые проблемы от проблем в узле.
Обсуждения этих систем граничат с философией: что в нашей системе правда, а что ложь? Можем ли мы полагаться на это знание, если механизмы познания и измерения ненадежны? Должны ли программные системы подчиняться законам физического мира, например закону причины и следствия?
К счастью, нам не требуется искать смысл жизни. Для распределенной системы можно описать допущения относительно поведения (модель системы) и спроектировать ее так, чтобы она соответствовала этим допущениям. Существует возможность проверки корректной работы алгоритмов в рамках определенной модели системы. А значит, надежность вполне достижима, даже если лежащая в основе системы модель обеспечивает очень мало гарантий.
Однако хотя можно обеспечить должную работу системы при ненадежной модели, сделать это непросто. В оставшейся части главы мы обсудим понятия знания и истины в распределенных системах, что поможет нам разобраться с нужными допущениями и гарантиями. В главе 9 мы перейдем к рассмотрению ряда примеров распределенных систем и алгоритмов, которые обеспечивают конкретные гарантии при конкретных допущениях.
Истина определяется большинством
Представьте сеть с асимметричным сбоем: узел получает все отправляемые ему сообщения, но все его исходящие сообщения задерживаются или вообще отбрасываются. И хотя он отлично работает и получает запросы от других узлов, эти другие не получают его ответов. Как следствие, по истечении некоторого времени ожидания другие узлы объявляют его неработающим. Ситуация превращается в какой-то кошмар: наполовину отключенный от сети узел насильно тащат «накладбище», а он отбивается и кричит: «Я жив!». Но, поскольку никто его криков не слышит, похоронная процессия неуклонно продолжает движение.
В чуть-чуть менее кошмарном сценарии наполовину отключенный от сети узел может заметить отсутствие подтверждений доставки своих сообщений от других узлов и понимает, что имеет место сбой сети. Тем не менее другие узлы ошибочно объявляют наполовину отключенный узел неработающим, а он не способен ничего с этим поделать.
В качестве третьего сценария представьте узел, приостановленный на долгое время в связи с длительной всеобъемлющей сборкой мусора. Все его потоки вытесняются из памяти процессом сборки мусора и приостанавливаются на минуту, и, следовательно, запросы не обрабатываются, а ответы не отправляются. Другие узлы ждут, повторяют отправку, теряют терпение, в конце концов объявляют узел неработающим и «отправляют его в катафалк». Наконец процесс сборки мусора завершает работу и потоки узла возобновляют работу как ни в чем не бывало. Остальные узлы удивляются «воскрешению» в полном здравии объявленного «мертвым» узла и начинают радостно болтать с очевидцами этого. Сначала данный узел даже не понимает, что прошла целая минута и он был объявлен «мертвым», — с его точки зрения с момента последнего обмена сообщениями с другими узлами прошло едва ли не мгновение.
Мораль этих историй: узел не может полагаться только на свое собственное мнение о ситуации. Распределенная система не может всецело полагаться на один узел, поскольку он способен отказать в любой момент, приведя к отказу и невозможности восстановления системы. Вместо этого многие распределенные алгоритмы основывают свою работу на кворуме, то есть решении большинства узлов (см. пункт «Операции записи и чтения по кворуму» подраздела «Запись в базу данных при отказе одного из узлов» раздела 5.4): принятие решений требует определенного минимального количества «голосов» от нескольких узлов. Данное условие позволяет снизить зависимость от любого одного конкретного узла.
Это включает принятие решений об объявлении узлов неработающими. Если кворум узлов объявляет другой узел неработающим, то он считается таковым, пусть и прекрасно работает в то же время. Отдельные узлы обязаны подчиняться решениям кворума.
Обычно кворум представляет собой абсолютное большинство от более чем половины узлов (хотя существуют и другие разновидности кворумов). Кворум по большинству позволяет системе работать в случае сбоев отдельных узлов (при трех узлах допустим отказ одного, при пяти — отказ двух). Такой способ безопасен, поскольку система может насчитывать только одно большинство — два большинства одновременно, чьи решения конфликтуют, невозможны. Мы обсудим использование кворумов подробнее, когда доберемся до алгоритмов консенсуса в главе 9.
Ведущий узел и блокировки
Зачастую системе необходимо наличие только одного экземпляра чего-либо. Например:
- только один узел может быть ведущим для секции базы данных, чтобы избежать ситуации разделения вычислительных мощностей (см. подраздел «Перебои в обслуживании узлов» раздела 5.1);
- только одна транзакция или один клиент может удерживать блокировку на конкретный ресурс или объект, чтобы предотвратить конкурентную запись в него и его порчу;
- только один пользователь может зарегистрировать конкретное имя пользователя, поскольку оно должно идентифицировать пользователя уникальным образом.
Реализация этого в распределенной системе требует осторожности: даже если узел уверен в своей «избранности» (ведущий узел секции, владелец блокировки, обработчик запроса, успешно завладевшего именем пользователя), совсем не факт, что с этим согласен кворум остальных узлов! Узел ранее мог быть ведущим, но если затем другие узлы объявили его неработающим (например, вследствие разрыва сети или паузы на сборку мусора), то его вполне могли «понизить в должности» и выбрать другой ведущий узел.
Случай, когда узел продолжает вести себя как «избранный», несмотря на то, что кворум остальных узлов объявил его неработающим, может привести к проблемам в недостаточно тщательно спроектированной системе. Подобный узел способен отправлять сообщения другим узлам в качестве самозваного «избранного», и если другие узлы с этим согласятся, то система в целом может начать работать неправильно.
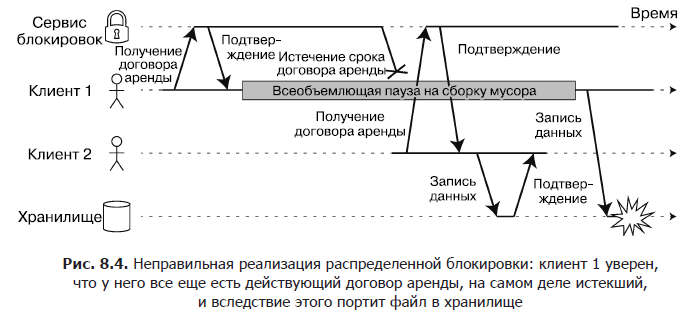
Например, на рис. 8.4 показана ошибка с порчей данных вследствие неправильной реализации блокировки (это отнюдь не теоретическая ошибка: она часто возникает в СУБД HBase). Допустим, мы хотели бы убедиться, что одновременно обратиться к находящемуся в сервисе хранения файлу может только один клиент, поскольку, если несколько клиентов сразу попытаются выполнить в него запись, файл будет испорчен. Мы попытаемся реализовать это с помощью обязательного получения клиентом договора аренды от сервиса блокировок до обращения к файлу.
Описанная проблема представляет собой пример того, что мы обсуждали в подразделе «Паузы при выполнении процессов» раздела 8.3: если арендующий клиент приостанавливается слишком надолго, то срок его договора аренды истекает. После этого другой клиент может получить договор аренды на тот же файл и начать запись в него данных. После возобновления работы приостановленный клиент верит (ошибочно), что у него все еще есть действующий договор аренды, и переходит к записи в файл. В результате операции записи двух клиентов перемешиваются и файл портится.
Ограждающие маркеры
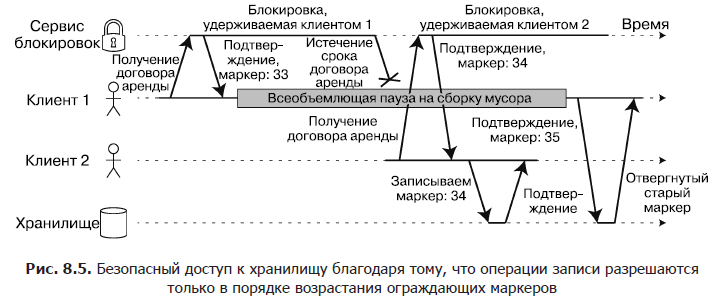
При использовании блокировки или договора аренды для защиты доступа к какому-либо ресурсу, например файловому хранилищу на рис. 8.4, необходимо убедиться, что узел, ошибочно считающий себя «избранным», не нарушит работу всей остальной системы. Для этой цели существует достаточно простой метод, показанный на рис. 8.5. Он называется ограждением (fencing).
Представим, что при каждом предоставлении блокировки или договора аренды сервер блокировок также возвращает ограждающий маркер (fencing token), представляющий собой номер, наращиваемый при каждом предоставлении блокировки (например, его может наращивать сервис блокировок). Кроме того, потребуем, чтобы клиент при каждой отправке запроса на запись сервису хранения включал в текущий запрос такой маркер.
На рис. 8.5 клиент 1 получает договор аренды с маркером 33, после чего надолго приостанавливается, и срок договора аренды истекает. Клиент 2 получает договор аренды с маркером 34 (номер монотонно возрастает), после чего отправляет запрос на запись сервису хранения, включая в запрос этот маркер. Позднее клиент 1 возобновляет работу и отправляет сервису хранения операцию записи с маркером 33. Однако сервис хранения помнит, что уже обработал операцию записи с большим номером маркера (34) и отклоняет данный запрос.
При использовании в качестве сервиса блокировок ZooKeeper в роли ограждающего маркера можно задействовать идентификатор транзакции zxid или версию узла cversion. Поскольку ZooKeeper гарантирует их монотонное возрастание, они обладают нужными для этого свойствами.
Обратите внимание: этот механизм требует, чтобы сам ресурс принимал активное участие в проверке маркеров, отклоняя все операции записи с маркерами, более старыми, чем уже обработанные, — проверки статуса блокировки на самих клиентах недостаточно. Можно обойти ограничение и для ресурсов, не поддерживающих явным образом ограждающие маркеры (например, в случае сервиса хранения файлов ограждающий маркер включается в имя файла). Однако некоторая проверка все равно нужна, во избежание обработки запросов без защиты блокировкой.
Проверка маркеров на стороне сервера может показаться недостатком, но, вполне вероятно, это не так уж плохо: для сервиса было бы неразумно считать, что все его клиенты всегда «ведут себя хорошо», поскольку клиенты часто запускают люди совсем не с такими приоритетами, как у владельцев сервиса. Следовательно, для любого сервиса будет хорошей идеей защищаться от непредумышленных неправильных действий со стороны клиентов.
Византийские сбои
Ограждающие маркеры способны обнаруживать и блокировать узел, непреднамеренно выполняющий ошибочные действия (например, потому, что еще не обнаружил истечение срока его договора аренды). Однако узел, умышленно желающий подорвать системные гарантии, может легко это сделать, отправив сообщение с поддельным маркером.
В этой книге мы предполагаем, что узлы ненадежны, но «добропорядочны»: они могут работать медленно или не отвечать вообще (вследствие сбоя), их состояние может быть устаревшим (из-за паузы на сборку мусора или сетевых задержек), но если узел вообще отвечает, то он «говорит правду» (соблюдает правила протокола в рамках имеющейся у него информации).
Проблемы распределенных систем значительно усугубляются при наличии риска, что узлы могут «лгать» (отправлять произвольные сбойные или поврежденные ответы) — например, если узел может заявить о получении определенного сообщения, когда на самом деле этого не было. Подобное поведение носит название византийского сбоя (Byzantine fault), и задача достижения консенсуса в подобной, не заслуживающей доверия среде известна как задача византийских генералов (Byzantine generals problem).
Система защищена от византийских сбоев, если продолжает работать правильно даже в случае нарушения работоспособности некоторых узлов и не соблюдения ими протокола или при вмешательстве злоумышленников в работу сети. Это может быть важно в следующих обстоятельствах.
- В авиакосмической отрасли данные в памяти компьютеров или регистрах CPU могут портиться вследствие радиации, что приводит к отправке непредсказуемых ответов другим узлам. Поскольку отказ системы способен привести к катастрофическим последствиям (например, к падению самолета и гибели всех на борту или к столкновению ракеты с Международной космической станцией), системы управления полетом должны быть защищены от византийских сбоев.
- Часть участников системы с множеством участвующих организаций могут попытаться сжульничать или обмануть остальных. В подобных обстоятельствах узлу не следует слепо верить сообщениям других узлов, поскольку они могут быть отправлены со злым умыслом. Например, одноранговые сети, такие как Bitcoin и другие блочные цепи, можно рассматривать как способ для не доверяющих друг другу сторон договориться, произошла ли транзакция, не полагаясь на какой-либо центральный орган.
Однако в таких системах, которые мы обсуждаем в данной книге, обычно можно без опаски допустить, что византийских сбоев тут нет. В вашем ЦОДе все узлы контролируются вашей организацией (поэтому они, будем надеяться, доверенные), а уровни радиации достаточно низки для того, чтобы порча памяти не представляла серьезной проблемы. Протоколы создания защищенных от византийских сбоев систем достаточно сложны, и подобные встроенные системы требуют поддержки на аппаратном уровне. В большинстве серверных информационных систем защищенные от византийских сбоев решения слишком дорого стоят, чтобы имело смысл их использовать.
В то же время веб-приложениям имеет смысл ожидать произвольного и злонамеренного поведения от находящихся под контролем конечных пользователей клиентов, например браузеров. Поэтому проверка вводимых данных, контроль корректности и экранирование вывода столь важны: например, для предотвращения внедрения SQL-кода (SQL injection) и межсайтового выполнения сценариев (cross-site scripting). Однако при этом обычно не применяются защищенные от византийских сбоев протоколы, а серверу просто делегируются полномочия принятия решения, допустимо ли поведение клиента. В одноранговых сетях, где подобного центрального органа нет, защищенность от византийских сбоев более уместна.
Можно рассматривать ошибки в программном обеспечении как византийские сбои, однако если одно и то же ПО используется во всех узлах, то алгоритмы защиты от византийских сбоев вас не спасут. Большинство таких алгоритмов требуют квалифицированного большинства из более чем двух третей нормально работающих узлов (то есть в случае четырех узлов может не работать максимум один). Чтобы решить проблему ошибок с помощью такого подхода, вам пришлось бы использовать четыре независимые реализации одного и того же программного обеспечения и надеяться на присутствие ошибки только в одной из них.
Аналогично кажется заманчивым, чтобы сам протокол защищал нас от уязвимостей, нарушений требований безопасности и злонамеренных действий. К сожалению, в большинстве систем это нереально. Если злоумышленник сумеет получить несанкционированный доступ к одному узлу, то очень вероятно, что сможет получить доступ и к остальным, поскольку на них, скорее всего, работает одно и то же программное обеспечение. Следовательно, традиционные механизмы (аутентификация, контроль доступа, шифрование, брандмауэры и т. д.) остаются основной защитой от атак.
Слабые формы «лжи». Хотя мы предполагаем, что узлы преимущественно «добропорядочны», имеет смысл добавить в ПО механизмы защиты от слабых форм «лжи» — например, некорректных сообщений вследствие аппаратных проблем, ошибок в программном обеспечении и неправильных настроек. Подобные механизмы нельзя считать полномасштабной защитой от византийских сбоев, ведь они не смогут спасти от решительно настроенного злоумышленника, но это простые и практичные шаги по усилению надежности. Вот несколько примеров.
- Порча сетевых пакетов иногда происходит из-за проблем с аппаратным обеспечением или ошибок в операционной системе, драйверах, маршрутизаторах и т. п. Обычно поврежденные пакеты перехватываются при проверке контрольных сумм, встроенной в протоколы TCP и UDP, но иногда ускользают от проверки. Для обнаружения порчи пакетов обычно достаточно простых мер, например контрольных сумм в протоколе уровня приложения.
- Открытые для общего доступа приложения должны тщательно контролировать корректность вводимых пользователями данных, например проверять, находятся ли значения в допустимом диапазоне, и ограничивать длину строк во избежание отказа в обслуживании вследствие выделения слишком больших объемов памяти. Для сервиса, применяемого внутри организации, за брандмауэром, достаточно менее строгих проверок вводимых данных, но некоторый простейший контроль значений (например, при синтаксическом разборе протокола) не помешает.
- NTP-клиенты можно настроить для использования адресов нескольких серверов. Во время синхронизации клиент обращается ко всем из них, подсчитывает их ошибки и убеждается, что существует определенный промежуток времени, с которым согласно большинство серверов. Если большинство серверов функционируют нормально, то неправильно настроенный NTP-сервер, возвращающий ошибочное время, расценивается как аномалия и исключается из синхронизации. Применение нескольких серверов повышает отказоустойчивость протокола NTP по сравнению с одним сервером.
Модели системы на практике
Для решения задач распределенных систем было разработано множество алгоритмов, например, мы рассмотрим решения для задачи консенсуса в главе 9. Чтобы принести какую-то пользу, эти алгоритмы должны уметь справляться с различными сбоями распределенных систем, которые мы обсуждали в этой главе.
Алгоритмы должны как можно меньше зависеть от особенностей аппаратного обеспечения и настроек ПО системы, на которой они работают. Это, в свою очередь, требует формализации типов вероятных сбоев. Для этого мы опишем модель системы — абстракцию, описывающую принимаемые алгоритмом допущения.
Что касается допущений по хронометражу, часто используются три системные модели.
- Синхронная. Предполагает ограниченность сетевых задержек, пауз процессов и расхождения часов. Это не подразумевает идеальной синхронизации часов или нулевой сетевой задержки, а просто означает, что длительность сетевых задержек, пауз процессов и расхождения часов никогда не превышает определенной фиксированной верхней границы. Синхронная модель нереалистична для большинства применяемых на практике систем, поскольку (как обсуждалось в данной главе) неограниченные задержки и паузы иногда случаются.
- Частично синхронная. Означает, что большую часть времени система ведет себя как синхронная, но иногда выходит за рамки заданной длительности сетевых задержек, пауз процессов и расхождения часов [88]. Это вполне реалистичная модель для большинства систем: значительную часть времени сети и процессы функционируют нормально — в противном случае вообще ничего бы не работало. Однако нужно учитывать такой факт: любые допущения относительно хронометража время от времени рассыпаются в прах. В подобном случае сетевые задержки, паузы и ошибки часов могут достигать произвольно больших значений.
- Асинхронная. В этой модели алгоритм не имеет права строить какие-либо временные допущения — на самом деле тут даже отсутствуют часы (так что нет и понятия времени ожидания). Некоторые алгоритмы можно приспособить для асинхронной модели, но она очень ограничивает разработчика.
Но, помимо проблем с хронометражем, следует учитывать и возможные отказы узлов. Вот три наиболее распространенные модели системы для узлов.
- Модель «отказ — остановка». Здесь алгоритм считает, что сбой узла может быть только фатальным. То есть узел способен перестать отвечать в любой момент, после чего его работа уже никогда не будет возобновлена.
- Модель «отказ — восстановление». Предполагается, что сбой узла может произойти в любой момент, но затем узел, вероятно, снова начнет отвечать через неизвестный период времени. В этой модели предполагается: у узлов имеется надежное хранилище (то есть энергонезависимый носитель информации), данные в котором не теряются при сбоях (в то время как находящиеся в оперативной памяти данные считаются потерянными).
- Византийские (произвольные) сбои. Узлы могут делать все, что им заблагорассудится, включая попытки обмана других узлов и умышленного введения их в заблуждение, как описано в последнем подразделе.
Для моделирования реальных систем обычно лучше всего подходит частично синхронная модель типа «сбой — восстановление». Но как с ней справляются распределенные алгоритмы?
Корректность алгоритмов
Чтобы дать определение корректности (correctness) алгоритма, я опишу его свойства. Например, у результатов работы алгоритма сортировки есть следующее свойство: для любых двух различных элементов выходного списка элемент слева меньше, чем элемент справа. Это просто формальный способ описания сортировки списка.
Аналогично формулируются свойства, которые требуются от корректного распределенного алгоритма. Например, при генерации ограждающих маркеров для блокировки можно требовать от алгоритма следующие свойства:
- уникальность — никакие два запроса ограждающего маркера не приводят к возврату одинакового значения;
- монотонное возрастание значений — если запрос x возвращает маркер tx, а запрос y возвращает маркер ty, причем x завершается до начала выполнения y, то tx < ty;
- доступность — узел, с которым не произошел фатальный сбой, запросивший ограждающий маркер, в конце концов получает ответ на свой запрос.
Алгоритм корректен в некоторой модели системы при условии, что всегда удовлетворяет этим свойствам во всех ситуациях, способных, как мы предполагаем, возникнуть в данной модели системы. Но имеет ли это смысл? Если со всеми узлами произойдет фатальный сбой или все сетевые задержки внезапно затянутся до бесконечности, то никакой алгоритм ничего не сможет сделать.
Функциональная безопасность и живучесть
Для прояснения этой ситуации необходимо выделять два различных вида свойств: функциональной безопасности (safety) и живучести (liveness). В только что приведенном примере свойства уникальности и монотонного возрастания значений относятся к функциональной безопасности, а доступность — к живучести.
Чем отличаются эти две разновидности свойств? Отличительный признак: присутствие в определении свойств живучести фразы «в конце концов» (и да, вы совершенно правы: конечная согласованность — свойство живучести).
Функциональная безопасность часто неформально описывается фразой «ничего плохого не произошло», а живучесть — «со временем случится что-то хорошее». Однако лучше не увлекаться слишком сильно подобными неформальными определениями, поскольку слова «плохой» и «хороший» субъективны. Подлинные определения функциональной безопасности и живучести математически точны.
- Если свойство функциональной безопасности нарушается, то существует конкретный момент времени этого нарушения (например, при нарушении свойства уникальности можно определить конкретную операцию, при которой возвращен дублирующий маркер). При нарушении свойства функциональной безопасности ущерб уже был нанесен, ничего сделать с этим нельзя.
- Свойство живучести же, наоборот, может не быть привязанным к какому-либо моменту времени (например, узел мог отправить запрос, но все еще не получить ответа), но всегда есть надежда, что оно будет удовлетворено в дальнейшем (например, путем получения ответа).
Преимущество разделения на свойства функциональной безопасности и живучести — в упрощении работы со сложными моделями систем. В случае распределенных алгоритмов часто требуют, чтобы свойства функциональной безопасности соблюдались всегда, во всех возможных ситуациях модели системы. То есть даже в случае фатального сбоя всех узлов или всей сети алгоритм должен гарантировать, что не вернет неправильный результат (то есть соблюдаются свойства функциональной безопасности).
Однако для свойств живучести вероятны уточнения: например, можно сказать, что ответ на запрос должен быть возвращен только в случае отсутствия фатального сбоя большинства узлов и если сеть в конце концов восстановилась после перебоя в обслуживании. Определение частично синхронной модели требует, чтобы система постепенно вернулась в синхронное состояние, то есть любой период прерывания работы сети длится только ограниченное время, после чего она восстанавливается.
Привязка моделей систем к реальному миру
Свойства функциональной безопасности и живучести, а также модели систем очень удобны для определения корректности распределенного алгоритма. Однако при реализации алгоритма на практике жестокая реальность вступает в свои права и становится ясно, что модель системы — лишь упрощенная абстракция реальности.
Например, алгоритмы в модели «фатальный сбой — восстановление» обычно предполагают: находящиеся в надежных хранилищах данные переживают фатальные сбои. Однако что будет в случае повреждения данных на диске или стирания данных из-за аппаратной ошибки или неправильной настройки [91]? А если в прошивке сервера содержится ошибка и он перестанет «видеть» свои жесткие диски после перезагрузки, хотя они и подключены к серверу должным образом?
Алгоритмы кворума (см. пункт «Операции записи и чтения по кворуму» подраздела «Запись в базу данных при отказе одного из узлов» раздела 5.4) полагаются на то, что узлы запоминают данные, хранение которых декларировали. Возможность «амнезии» узла и забывания им ранее сохраненных данных нарушает условия кворума, а следовательно, и корректность алгоритма. Вероятно, нужна новая модель системы с допущением, что надежное хранилище в большинстве случаев переживает фатальные сбои, но иногда способно терять данные. Однако обосновать эту модель сложнее.
В теоретическом описании алгоритма может быть объявлено, что определенные вещи просто не должны случаться — и в невизантийских системах мы как раз и делаем допущения относительно того, какие сбои могут происходить, а какие — нет. Однако на практике в реализации иногда требуется включить код для обработки случая, когда произошло нечто, предполагавшееся невозможным, даже если эта обработка сводится к printf(«Тебе не повезло») и exit(666), то есть к тому, что разгребать все придется оператору-человеку. (В этом, по мнению некоторых, заключается разница между компьютерными науками и программной инженерией.)
Это не значит, что теоретические, абстрактные системы ничего не стоят — как раз наоборот. Они исключительно полезны при извлечении из всей сложности реальной системы приемлемого множества сбоев, которые можно рассмотреть с целью понять задачу и попытаться решить ее систематически. Доказать корректность алгоритма можно путем демонстрации того, что его свойства всегда соблюдаются в некой модели системы.
Доказательство корректности алгоритма не означает, что его реализация в реальной системе всегда будет вести себя корректно. Но это очень хороший первый шаг, поскольку теоретический анализ позволит выявить проблемы в алгоритме, которые могут оставаться скрытыми в реальной системе и проявить себя только в случае краха допущений (например, относительно хронометража) вследствие каких-то необычных обстоятельств. Теоретический анализ и эмпирическая проверка одинаково важны.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Программирование
