Привет, Хабр!
Наши читатели не могли не заметить нашего растущего интереса к языку Go. Наряду с книгой из предыдущего поста, у нас найдется на эту тему немало интересного. Сегодня мы хотим предложить вам перевод материала «для профи», в котором демонстрируются интересные аспекты ручного управления памятью на Go, а также одновременное выполнение операций над памятью на Go и C++.
В Dgraph Labs язык Go использовали с момента основания компании в 2015. Спустя пять лет и 200 000 строк кода на Go, готовы с радостью сообщить, что не ошиблись с Go. Этот язык вдохновляет не только как инструмент для создания новых систем, но даже стимулирует писать на Go те скрипты, которые традиционно писались на Bash или Python. Оказывается, Go позволяет создать базу чистого, удобочитаемого, удобного при поддержке кода, который –что наиболее важно – эффективен и удобен для конкурентной обработки.
Однако с Go есть одна проблема, проявляющаяся уже на первых этапах работы: управление памятью. У нас не появилось никаких нареканий на сборщик мусора Go, но, притом, насколько он упрощает жизнь разработчикам, ему присущи те же проблемы, что и другим сборщикам мусора: он просто не может потягаться в эффективности с ручным управлением памятью.
Когда памятью управляешь вручную, она расходуется меньше, при этом расход памяти предсказуем и позволяет избежать безумных всплесков расхода памяти, когда резко выделяется новый большой кусок памяти. При использовании памяти в Go были замечены все вышеперечисленные проблемы с автоматическим управлением памятью.
Таким языкам как Rust удается закрепиться отчасти потому, что в них обеспечивается безопасное ручное управление памятью. Это можно только приветствовать.
По опыту автора выделение памяти вручную и отслеживание потенциальных утечек в памяти дается легче, чем попытки оптимизировать использование памяти средствами, касающимися сборки мусора. Ручная сборка мусора вполне стоит связанных с ней хлопот при создании таких баз данных, которые дают практически неограниченную масштабируемость.
Из любви к Go и из необходимости избежать сборки мусора с применением Go GC, нам пришлось изыскивать инновационные способы ручного управления памятью в Go. Разумеется, большинству пользователей Go никогда не придется управлять памятью вручную, и мы рекомендуем так не поступать кроме тех случаев, когда это действительно нужно. А когда вам это понадобится – нужно знать, как это делается.
Этот раздел написан по образцу раздела вики-статьи Cgo о преобразовании массивов C в сегменты Go. Мы могли бы воспользоваться malloc для выделения памяти в C и при помощи unsafe передать ее в Go, при этом нам совершенно не понадобилось бы вмешательство со стороны сборщика мусора Go.
Однако, вышеописанное возможно с оговоркой, которая отмечена в golang.org/cmd/cgo.
Поэтому вместо malloc мы воспользуемся его аналогом
Для начала мы просто реализовали в простейшем виде функции Calloc и Free, которые выделяют и высвобождают байтовые сегменты для Go через Cgo. Чтобы протестировать эти функции, был разработан и опробован непрерывный тест использования памяти. Этот тест в виде бесконечного цикла повторял цикл выделения/высвобождения памяти, при котором сначала выделялись фрагменты памяти, имевшие случайный размер, пока общий объем выделенной памяти не достигал 16GB, а потом происходило постепенное высвобождение этих фрагментов, пока не оставался выделен всего 1GB памяти.
Эквивалентная программа на C работала как и ожидалось. В
Было выдвинуто предположение, что это объясняется фрагментацией памяти из-за отсутствия «осведомленности о потоках» в вызовах
Мы переключили свои API на использование
Просто чтобы закрепить, что мы используем jemalloc и избегаем конфликта имен, добавляем при установке префикс
На этой иллюстрации показано, что выделение памяти Go при помощи
Ближе к завершению программы (небольшая рябь с правого края), после того, как вся выделенная память была высвобождена, программа
Чтобы установить jemalloc, скачайте ее отсюда, а затем запустите следующие команды:
Весь код
Этот код вошел в состав пакета Ristretto. Чтобы получающийся код мог переключаться на работу с jemalloc для выделения байтовых фрагментов, добавлен тег сборки
Теперь у нас есть способ выделить и высвободить байтовый сегмент, и далее мы воспользуемся им для компоновки структур в Go. Можно начать с простейшего примера (полный код).
В вышеприведенном примере мы выложили структуру Go на память, выделенную в C, при помощи
С объемом памяти Go, выделяемым по умолчанию, видно, что 31 MiB из кучи выделено на связный список с 2M объектов, но ничего не выделено через
Воспользовавшись тегом сборки
Вышеприведенный код отлично справляется с выделением памяти в Go. Но это делается за счет снижения производительности. Прогнав оба экземпляра с
Такое замедление производительности можно связать с тем, что при каждом акте выделения памяти выполнялись вызовы Cgo, а каждый вызов Cgo сопряжен с некоторыми издержками. Чтобы справиться с ними, была написана библиотека Allocator, также входящая в пакет ristretto/z. Эта библиотека за один вызов выделяет более крупные сегменты памяти, в каждом из которых умещается много мелких объектов, что позволяет обойтись без дорогостоящих вызовов Cgo.
Allocator начинает работу с буфером и, как только он будет израсходован, создает новый буфер вдвое крупнее первого. Он ведет внутренний список всех выделенных буферов. Наконец, когда пользователь закончит работу с данными, мы можем вызвать Release, чтобы высвободить все эти буферы одним махом. Обратите внимание: Allocator нисколько не перемещает память. Так гарантируется, что все имеющиеся у нас указатели на struct продолжают действовать.
Хотя, такое управление памятью и может показаться топорным по сравнению с тем, как работают
Что у Allocator получается по-настоящему хорошо – так это задешево выделять миллионы структур, а потом высвобождать их, когда работа будет готова, не привлекая к этой работе кучу Go. Если запустить показанную выше программу с новым тегом сборки allocator, то она будет работать еще быстрее, чем версия с памятью Go.
В Go 1.14 и выше флаг
Возникла и еще одна проблема при управлении памятью. Бывает так, что память выделяется в одном месте, а высвобождается совсем в другом. Вся связь между двумя этими точками может осуществляться через структуры, а выделять их можно не иначе, кроме как путем передачи конкретного объекта
НЕ ссылайтесь на память, выделенную Go, из памяти, выделенной вручную.
При выделении структуры вручную, как показано выше, важно обеспечить, чтобы внутри этой структуры не было ссылок на память, выделенную Go. Давайте немного видоизменим вышеприведенную структуру:
Воспользуемся функцией
Память, выделенная Go, подпадает под сборку мусора, поскольку ни одна действительная структура Go не указывает на нее. Ссылки стоят только из памяти, выделенной в C, а куча Go не содержит ни одной подходящей ссылки, что и провоцирует вышеуказанную ошибку. Таким образом, если вы создаете структуру и вручную выделяете память под нее, то важно гарантировать, чтобы все рекурсивно доступные поля также выделялись вручную.
Например, если вышеуказанная структура использовала байтовый сегмент, то мы выделяли этот сегмент при помощи Allocator, а также избегали смешивания памяти Go с памятью C.
Все эти 1B узлов вручную выделены в
Чтобы справляться с такими практическими ситуациями, создан
Еще важнее, что
Для сортировки мы исходно пытались получать смещения сегментов из
Важнейший фактор, ограничивавший нашу работу, заключался в том, что размеры у всех сегментов были неодинаковыми. Более того, мы могли обращаться к этим сегментам лишь в последовательном порядке, а не в обратном и не в случайном, не имея возможности рассчитывать и сохранять смещения заранее. Большинство алгоритмов для сортировки на месте предполагают, что все значения имеют одинаковый размер, к ним можно обращаться в произвольном порядке, и ничто не мешает менять их местами.
Учитывая такие ограничения, был сделан вывод, что лучше всего для выполнения поставленной задачи подходит алгоритм сортировки слиянием. При использовании сортировки слиянием можно работать в буфере, совершая операции в последовательном порядке, при этом дополнительные затраты памяти составят всего половину размера буфера. Оказалось, это не только дешевле, чем переносить отступы в память, но и значительно повышает предсказуемость в том, что касается накладных расходов при использовании памяти (половина размера буфера). Еще лучше, что издержки, требуемые для выполнения сортировки слиянием, сами отображаются на память.
Есть и еще один очень положительный эффект от использования сортировки слиянием. При сортировке на основе смещений приходится держать смещения в памяти, пока мы перебираем их и обрабатываем буфер, в результате чего давление на память только возрастает. При сортировке слиянием вся дополнительная память, которая нам требовалась, высвобождается к моменту начала перебора, а это значит, что и на обработку буфера у нас будет больше памяти.
z.Buffer также поддерживает и выделение памяти через
Все это обсуждение будет неполным, если не затронуть тему утечек памяти. Ведь, если мы выделяем память вручную, то утечки памяти будут неизбежны во всех тех случаях, когда мы забудем высвободить память. Как же их отловить?
Мы давно пользовались простым решением – использовали атомарный счетчик, отслеживающий количество байт, выделенных при таких вызовах. В таком случае можно быстро узнать, сколько памяти мы выделили вручную в программе с помощью
Когда удавалось найти утечку, мы поначалу пытались пользоваться профилировщиком памяти jemalloc. Но вскоре стало понятно, что это не помогает – он не видит весь стек вызовов, так как утыкается в границу Cgo. Все, что видит профилировщик – это акты выделения и высвобождения памяти, идущие от одних и тех же вызовов
Благодаря среде выполнения Go, нам быстро удалось построить простую систему для отлавливания вызывающих сторон в
При помощи описанных приемов достигается золотая середина. Мы можем выделять память вручную в критически важных путях кода, сильно зависящих от доступной памяти. В то же время, мы можем пользоваться достоинствами автоматической сборки мусора в не столь критичных путях. Даже если вы не слишком хорошо умеете обращаться с Cgo или jemalloc, вы можете применять описанные приемы со сравнительно крупными фрагментами памяти в Go – эффект будет сопоставимым.
Все библиотеки, упомянутые выше, доступны по лицензии Apache 2.0 в пакете Ristretto/z. Тест памяти и демонстрационный код находятся в папке contrib.
Наши читатели не могли не заметить нашего растущего интереса к языку Go. Наряду с книгой из предыдущего поста, у нас найдется на эту тему немало интересного. Сегодня мы хотим предложить вам перевод материала «для профи», в котором демонстрируются интересные аспекты ручного управления памятью на Go, а также одновременное выполнение операций над памятью на Go и C++.
В Dgraph Labs язык Go использовали с момента основания компании в 2015. Спустя пять лет и 200 000 строк кода на Go, готовы с радостью сообщить, что не ошиблись с Go. Этот язык вдохновляет не только как инструмент для создания новых систем, но даже стимулирует писать на Go те скрипты, которые традиционно писались на Bash или Python. Оказывается, Go позволяет создать базу чистого, удобочитаемого, удобного при поддержке кода, который –что наиболее важно – эффективен и удобен для конкурентной обработки.
Однако с Go есть одна проблема, проявляющаяся уже на первых этапах работы: управление памятью. У нас не появилось никаких нареканий на сборщик мусора Go, но, притом, насколько он упрощает жизнь разработчикам, ему присущи те же проблемы, что и другим сборщикам мусора: он просто не может потягаться в эффективности с ручным управлением памятью.
Когда памятью управляешь вручную, она расходуется меньше, при этом расход памяти предсказуем и позволяет избежать безумных всплесков расхода памяти, когда резко выделяется новый большой кусок памяти. При использовании памяти в Go были замечены все вышеперечисленные проблемы с автоматическим управлением памятью.
Таким языкам как Rust удается закрепиться отчасти потому, что в них обеспечивается безопасное ручное управление памятью. Это можно только приветствовать.
По опыту автора выделение памяти вручную и отслеживание потенциальных утечек в памяти дается легче, чем попытки оптимизировать использование памяти средствами, касающимися сборки мусора. Ручная сборка мусора вполне стоит связанных с ней хлопот при создании таких баз данных, которые дают практически неограниченную масштабируемость.
Из любви к Go и из необходимости избежать сборки мусора с применением Go GC, нам пришлось изыскивать инновационные способы ручного управления памятью в Go. Разумеется, большинству пользователей Go никогда не придется управлять памятью вручную, и мы рекомендуем так не поступать кроме тех случаев, когда это действительно нужно. А когда вам это понадобится – нужно знать, как это делается.
Создание памяти при помощи Cgo
Этот раздел написан по образцу раздела вики-статьи Cgo о преобразовании массивов C в сегменты Go. Мы могли бы воспользоваться malloc для выделения памяти в C и при помощи unsafe передать ее в Go, при этом нам совершенно не понадобилось бы вмешательство со стороны сборщика мусора Go.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]Однако, вышеописанное возможно с оговоркой, которая отмечена в golang.org/cmd/cgo.
Замечание: в нынешней реализации есть баг. Тогда как код на Go в состоянии записать nil или указатель C (но не указатель Go) в память C, такая реализация иногда может вызывать ошибку времени выполнения, если содержимое памяти C покажется указателем Go. Следовательно, избегайте передавать неинициализированную память C в код Go, если в коде Go будут храниться значения указателей. Сбрасывайте в ноль память C, прежде чем передавать ее в Go.
Поэтому вместо malloc мы воспользуемся его аналогом
calloc, слегка более тяжеловесным. calloc работает точно как malloc, с той оговоркой, что сбрасывает память на ноль, прежде, чем вернуть ее вызывающей стороне.Для начала мы просто реализовали в простейшем виде функции Calloc и Free, которые выделяют и высвобождают байтовые сегменты для Go через Cgo. Чтобы протестировать эти функции, был разработан и опробован непрерывный тест использования памяти. Этот тест в виде бесконечного цикла повторял цикл выделения/высвобождения памяти, при котором сначала выделялись фрагменты памяти, имевшие случайный размер, пока общий объем выделенной памяти не достигал 16GB, а потом происходило постепенное высвобождение этих фрагментов, пока не оставался выделен всего 1GB памяти.
Эквивалентная программа на C работала как и ожидалось. В
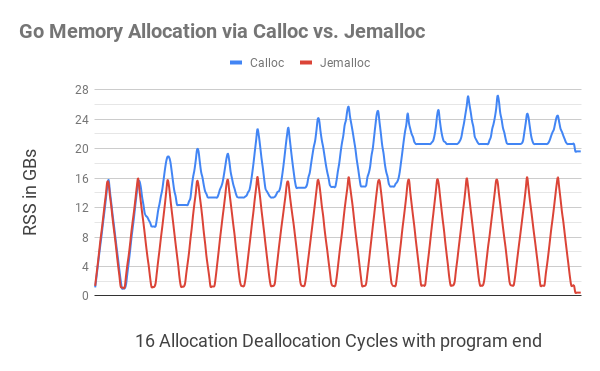
htop просматривалось, как объем памяти, выделенный процессу (RSS) сначала добирается до 16GB, затем опускается до 1 GB, далее вновь растет до 16 GB и так далее. Однако, программа Go, использующая Calloc и Free, после каждого цикла использовала все больше памяти (см. схему ниже). Было выдвинуто предположение, что это объясняется фрагментацией памяти из-за отсутствия «осведомленности о потоках» в вызовах
C.calloc, реализованных по умолчанию. Чтобы избежать этого, было решено попробовать jemalloc.jemalloc
jemalloc– это универсальная реализацияmalloc, в которой делается акцент на предохранении от фрагментации и поддержке масштабируемой конкурентности.jemallocвпервые начала использоваться во FreeBSD в 2005 году в качестве аллокатораlibcи с тех пор нашла применение во многих приложениях благодаря своему предсказуемому поведению. — jemalloc.net
Мы переключили свои API на использование
jemalloc с вызовами calloc и free. Причем, такой вариант работал прекрасно: jemalloc нативно поддерживает потоки почти без фрагментации памяти. Тест памяти, в рамках которого проверялись циклы выделения и высвобожде памяти, оставался в пределах разумного, не считая небольших издержек, требуемых на запуск теста.Просто чтобы закрепить, что мы используем jemalloc и избегаем конфликта имен, добавляем при установке префикс
je_, так, чтобы наши API теперь вызывали je_calloc и je_free, а не calloc и free.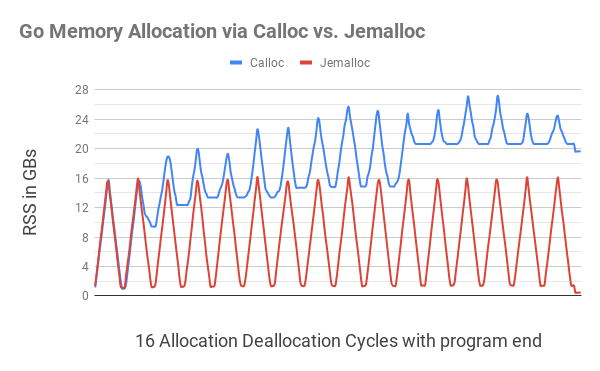
На этой иллюстрации показано, что выделение памяти Go при помощи
C.calloc приводит к серьезной фрагментации памяти, из-за чего к 11-му циклу программа отжирает до 20GB памяти. Эквивалентный код с jemalloc никакой заметной фрагментации не давал, укладываясь в каждом цикле близко к 1GB. Ближе к завершению программы (небольшая рябь с правого края), после того, как вся выделенная память была высвобождена, программа
C.calloc все равно отжирала чуть менее 20GB памяти, тогда как jemalloc обходилась всего 400MB памяти.Чтобы установить jemalloc, скачайте ее отсюда, а затем запустите следующие команды:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto'
make
sudo make installВесь код
Calloc выглядит примерно так:ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw похож на panic, кроме тех случаев, когда он
// гарантирует завершение процесса. Вызов, показанный ниже – именно такой, какой будет выполнять среда выполнения Go, когда не может
// выделить память.
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// Интерпретируем указатель C как указатель на массив Go, затем отрезаем.
return (*[MaxArrayLen]byte)(uptr)[:n:n]Этот код вошел в состав пакета Ristretto. Чтобы получающийся код мог переключаться на работу с jemalloc для выделения байтовых фрагментов, добавлен тег сборки
jemalloc. Чтобы еще сильнее упростить операции развертывания, была обеспечена статическая связь библиотеки jemalloc с любым результирующим двоичным файлом на Go, поставив нужные флаги LDFLAGS.Раскладывание структур Go по байтовым сегментам
Теперь у нас есть способ выделить и высвободить байтовый сегмент, и далее мы воспользуемся им для компоновки структур в Go. Можно начать с простейшего примера (полный код).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}В вышеприведенном примере мы выложили структуру Go на память, выделенную в C, при помощи
newNode. Мы создали соответствующую функцию freeNode, которая позволяет высвободить память, как только мы закончим работу над структурой. В структуре на языке Go содержится простейший тип данных int и указатель на следующую узловую структуру, все это можно задать в программе, а затем обращаться к этим сущностям. Мы выделили 2M узловых объектов и создали из них связный список, чтобы продемонстрировать, что jemalloc функционирует как надо.С объемом памяти Go, выделяемым по умолчанию, видно, что 31 MiB из кучи выделено на связный список с 2M объектов, но ничего не выделено через
jemalloc.$ go run .
Allocated memory: 0 Objects: 2000001
node: 0
...
node: 2000000
After freeing. Allocated memory: 0
HeapAlloc: 31 MiBВоспользовавшись тегом сборки
jemalloc, видим, что 30 MiB байт памяти выделено через jemalloc, и после высвобождения связного списка это значение падает до нуля. Go выделяет из памяти всего каких-нибудь 399 KiB, что, вероятно, связано с издержками на запуск программы.$ go run -tags=jemalloc .
Allocated memory: 30 MiB Objects: 2000001
node: 0
...
node: 2000000
After freeing. Allocated memory: 0
HeapAlloc: 399 KiBАмортизация издержек Calloc при помощи Allocator
Вышеприведенный код отлично справляется с выделением памяти в Go. Но это делается за счет снижения производительности. Прогнав оба экземпляра с
time, мы видим, что без jemalloc программа справилась за 1,15 с. С jemalloc она справилась в 5 раз медленнее, за 5,29 с.$ time go run .
go run . 1.15s user 0.25s system 162% cpu 0.861 total
$ time go run -tags=jemalloc .
go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 totalТакое замедление производительности можно связать с тем, что при каждом акте выделения памяти выполнялись вызовы Cgo, а каждый вызов Cgo сопряжен с некоторыми издержками. Чтобы справиться с ними, была написана библиотека Allocator, также входящая в пакет ristretto/z. Эта библиотека за один вызов выделяет более крупные сегменты памяти, в каждом из которых умещается много мелких объектов, что позволяет обойтись без дорогостоящих вызовов Cgo.
Allocator начинает работу с буфером и, как только он будет израсходован, создает новый буфер вдвое крупнее первого. Он ведет внутренний список всех выделенных буферов. Наконец, когда пользователь закончит работу с данными, мы можем вызвать Release, чтобы высвободить все эти буферы одним махом. Обратите внимание: Allocator нисколько не перемещает память. Так гарантируется, что все имеющиеся у нас указатели на struct продолжают действовать.
Хотя, такое управление памятью и может показаться топорным по сравнению с тем, как работают
tcmalloc и jemalloc, такой подход значительно проще. Выделив память, вы не сможете затем высвободить всего одну структуру. Вы сможете высвободить только сразу всю память, используемую Allocator.Что у Allocator получается по-настоящему хорошо – так это задешево выделять миллионы структур, а потом высвобождать их, когда работа будет готова, не привлекая к этой работе кучу Go. Если запустить показанную выше программу с новым тегом сборки allocator, то она будет работать еще быстрее, чем версия с памятью Go.
$ time go run -tags="jemalloc,allocator" .
go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 totalВ Go 1.14 и выше флаг
-race включает проверки выравнивания структур в памяти. У Allocator есть метод AllocateAligned, возвращающий память, и, чтобы пройти эти проверки, указатель должен быть правильно выровнен. Если структура велика, то некоторый объем памяти может при этом теряться, но инструкции CPU начинают работать эффективнее по причине верного разграничения слов.Возникла и еще одна проблема при управлении памятью. Бывает так, что память выделяется в одном месте, а высвобождается совсем в другом. Вся связь между двумя этими точками может осуществляться через структуры, а выделять их можно не иначе, кроме как путем передачи конкретного объекта
Allocator. Чтобы справиться с этим, мы присваиваем уникальный ID каждому объекту Allocator, который эти объекты хранят в ссылке uint64. Каждый новый объект Allocator хранится в глобальном словаре с привязкой к ссылке на себя. Затем объекты Allocator можно вызывать повторно при помощи этой ссылки, и высвобождать, когда данные больше не требуются. Грамотно расставляем ссылки
НЕ ссылайтесь на память, выделенную Go, из памяти, выделенной вручную.
При выделении структуры вручную, как показано выше, важно обеспечить, чтобы внутри этой структуры не было ссылок на память, выделенную Go. Давайте немного видоизменим вышеприведенную структуру:
type node struct {
val int
next *node
buf []byte
}Воспользуемся функцией
root := newNode(val), определенной выше, чтобы вручную выделить узел. Если же затем мы установим root.next = &node{val: val}, выделив таким образом все прочие узлы в связном списке через память Go, то неизбежно получим следующую ошибку сегментирования:$ go run -race -tags="jemalloc" .
Allocated memory: 16 B Objects: 2000001
unexpected fault address 0x1cccb0
fatal error: fault
[signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]Память, выделенная Go, подпадает под сборку мусора, поскольку ни одна действительная структура Go не указывает на нее. Ссылки стоят только из памяти, выделенной в C, а куча Go не содержит ни одной подходящей ссылки, что и провоцирует вышеуказанную ошибку. Таким образом, если вы создаете структуру и вручную выделяете память под нее, то важно гарантировать, чтобы все рекурсивно доступные поля также выделялись вручную.
Например, если вышеуказанная структура использовала байтовый сегмент, то мы выделяли этот сегмент при помощи Allocator, а также избегали смешивания памяти Go с памятью C.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // выделим 16 байт
rand.Read(n.buf)Как справиться с гигабайтами выделенной памяти
Allocator хорош для того, чтобы вручную выделять миллионы структур. Но бывают и такие случаи, когда требуется создавать миллиарды мелких объектов и сортировать их. Чтобы сделать это в Go, даже при помощи Allocator, требуется написать примерно такой код:var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// теперь узлы отсортированы в порядке возрастания значений.Все эти 1B узлов вручную выделены в
Allocator, а это дорогое удовольствие. Также приходится тратиться на каждый сегмент памяти в Go, что само по себе достаточно дорого, так как нам требуется 8GB памяти (8 байт на указатель узла). Чтобы справляться с такими практическими ситуациями, создан
z.Buffer, который можно отображать в памяти на файл, позволяя таким образом Linux подкачивать и убирать страницы памяти по мере того, что требуется системе. Он реализует io.Writer и позволяет нам не зависеть от bytes.Buffer.Еще важнее, что
z.Buffer предоставляет новый способ выделять меньшие сегменты данных. При вызове SliceAllocate(n), z.Buffer запишет длину выделяемого сегмента (n), а затем выделит этот сегмент. Таким образом z.Buffer становится проще понимать границы сегментов и правильно перебирать сегменты при помощи SliceIterate.Сортировка данных переменной длины
Для сортировки мы исходно пытались получать смещения сегментов из
z.Buffer, обращаться к сегментам для сравнения, но сортировать только смещения. Получив смещение, z.Buffer может его считать, найти длину сегмента и вернуть этот сегмент. Таким образом, подобная система позволяет возвращать сегменты в отсортированном виде, не прибегая ни к каким перетасовкам памяти. При всей инновационности, этот механизм оказывает значительное давление на память, поскольку нам все равно приходится платить штраф в 8GB памяти лишь затем, чтобы перенести интересующие нас смещения в память Go.Важнейший фактор, ограничивавший нашу работу, заключался в том, что размеры у всех сегментов были неодинаковыми. Более того, мы могли обращаться к этим сегментам лишь в последовательном порядке, а не в обратном и не в случайном, не имея возможности рассчитывать и сохранять смещения заранее. Большинство алгоритмов для сортировки на месте предполагают, что все значения имеют одинаковый размер, к ним можно обращаться в произвольном порядке, и ничто не мешает менять их местами.
sort.Slice в Go работает аналогичным образом, соответственно, плохо подходила для z.Buffer.Учитывая такие ограничения, был сделан вывод, что лучше всего для выполнения поставленной задачи подходит алгоритм сортировки слиянием. При использовании сортировки слиянием можно работать в буфере, совершая операции в последовательном порядке, при этом дополнительные затраты памяти составят всего половину размера буфера. Оказалось, это не только дешевле, чем переносить отступы в память, но и значительно повышает предсказуемость в том, что касается накладных расходов при использовании памяти (половина размера буфера). Еще лучше, что издержки, требуемые для выполнения сортировки слиянием, сами отображаются на память.
Есть и еще один очень положительный эффект от использования сортировки слиянием. При сортировке на основе смещений приходится держать смещения в памяти, пока мы перебираем их и обрабатываем буфер, в результате чего давление на память только возрастает. При сортировке слиянием вся дополнительная память, которая нам требовалась, высвобождается к моменту начала перебора, а это значит, что и на обработку буфера у нас будет больше памяти.
z.Buffer также поддерживает и выделение памяти через
Calloc, а также автоматическое отображение на память после превышения некоторого предела, указанного пользователем. Поэтому инструмент хорошо работает с данными любого размера.buffer := z.NewBuffer(256<<20) // Начнем с 256MB выделенных через Calloc.
buffer.AutoMmapAfter(1<<30) // Автоматический mmap по достижении 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// Перебор узлов в порядке возрастания значений.
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})Отлавливание утечек в памяти
Все это обсуждение будет неполным, если не затронуть тему утечек памяти. Ведь, если мы выделяем память вручную, то утечки памяти будут неизбежны во всех тех случаях, когда мы забудем высвободить память. Как же их отловить?
Мы давно пользовались простым решением – использовали атомарный счетчик, отслеживающий количество байт, выделенных при таких вызовах. В таком случае можно быстро узнать, сколько памяти мы выделили вручную в программе с помощью
z.NumAllocBytes(). Если к концу тестирования памяти у нас еще оставалась какая-то лишняя память, это означало утечку.Когда удавалось найти утечку, мы поначалу пытались пользоваться профилировщиком памяти jemalloc. Но вскоре стало понятно, что это не помогает – он не видит весь стек вызовов, так как утыкается в границу Cgo. Все, что видит профилировщик – это акты выделения и высвобождения памяти, идущие от одних и тех же вызовов
z.Calloc и z.Free.Благодаря среде выполнения Go, нам быстро удалось построить простую систему для отлавливания вызывающих сторон в
z.Calloc и сопоставления их с вызовами z.Free. Такая система требует мьютексных блокировок, поэтому мы решили не активировать ее по умолчанию. Вместо этого мы воспользовались флагом сборки leak, чтобы включить отладочные сообщения об утечках в сборках для разработчика. Таким образом автоматически выявляются утечки и выводится в консоль, где именно они возникли. // Если включено обнаружение утечек.
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// спровоцируем утечку, чтобы продемонстрировать, как она фиксируется. Первое
// число указывает размер выделенной области, за ним следует функция и номер
// строки, в которой было выполнено выделение.
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91Вывод
При помощи описанных приемов достигается золотая середина. Мы можем выделять память вручную в критически важных путях кода, сильно зависящих от доступной памяти. В то же время, мы можем пользоваться достоинствами автоматической сборки мусора в не столь критичных путях. Даже если вы не слишком хорошо умеете обращаться с Cgo или jemalloc, вы можете применять описанные приемы со сравнительно крупными фрагментами памяти в Go – эффект будет сопоставимым.
Все библиотеки, упомянутые выше, доступны по лицензии Apache 2.0 в пакете Ristretto/z. Тест памяти и демонстрационный код находятся в папке contrib.
