
Database scaling is a continually coming future. DBMS get improved and better scaled on hardware platforms, while the hardware platforms themselves increase the performance, number of cores, and memory — Achilles is trying to catch up with the turtle, but has not caught up yet. The database scaling challenge manifests itself in all its magnitude.
Postgres Professional had to face the scaling problem not only theoretically, but also in practice: through their customers. Even more than once. It's one of these real-life cases that this article
will discuss.
Many thanks to Elena Indrupskaya for the translation. Russian version is here.
PostgreSQL scales well on NUMA systems in the case of a single motherboard with multiple processors and multiple data buses. You can read about some optimizations here and here.
However, there is another group of systems: they have several motherboards that exchange data using the interconnect and run one instance of the OS; for the user this design looks like a single machine. And although formally such systems can also be referred to NUMA, in essence, they are closer to supercomputers because access to the local memory of a node drastically differs from access to the memory of a neighboring node.
The PostgreSQL community believes that the cause of the issues is the only instance of Postgres running on such architectures, and there is no systematic approach to resolving them yet. Designers of shared-memory oriented software initially presumed that access times to local and remote memory would be more or less comparable. When we work with many nodes, it doesn’t make sense to rely on shared memory as on a fast communication channel: because of latency, it is much «cheaper» to send a request to perform a certain action to the node where the data of interest is located than to send the data through the bus. So, cluster solutions are relevant for supercomputers and for multi-node systems in general.
This does not mean that the combination of multi-node systems and the shared-memory architecture, which is typical for Postgres, should be trashed. After all, if Postgres processes spend most of their time performing complex computations locally, this architecture will be even more efficient. In our situation, the customer had already purchased a powerful multi-node server, and we had to resolve PostgreSQL issues on it.
And the issues were serious: execution of simplest write queries (to change several field values in one row) took from a few minutes to an hour. These issues came out full force exactly due to a large number of cores and accordingly, to massive parallelism in query execution with a relatively slow exchange between nodes.
Therefore, the article will be somewhat dual-purpose:
- To share experiences on: what if on a multi-node system, the database seriously slows down. What to begin with, how to diagnose, where to go.
- Tell how the problems of the PostgreSQL database itself can be solved with a high level of parallelism. Among the rest, how a change to the algorithm of acquiring locks affects the efficiency of PostgreSQL.
The server and database
The system consisted of 8 blades with 2 sockets each. More than 300 cores in total (hyper-threading not taken into account). The fast bus (the manufacturer's proprietary technology) connected the blades. Not that a supercomputer, but the configuration was impressive for a single DBMS instance. The load was also rather big. More than 1 terabyte of data. About 3000 transactions per second. More than 1000 connections to Postgres.
Having started analyzing hour-long write waits, first we made sure that writing to disk could not cause the delay. As soon as unclear delays began to occur, the tests were done exclusively on
tmpfs. The picture did not change. So the disk was not to blame.Starting to collect diagnoses: views
Since the issues were most likely due to the high concurrency of processes that try to access the same objects, the first thing to check was the locks. For this check, PostgreSQL has
pg.catalog.pg_locks and pg_stat_activity views. Starting as early as with version 9.6, the second one includes the information on what the process is waiting for (Amit Kapila, Ildus Kurbangaliev) — wait_event_type. Possible values for this field are described here.But first, let's just count:
postgres=# SELECT COUNT(*) FROM pg_locks;count
—---—
88453
(1 row)postgres=# SELECT COUNT(*) FROM pg_stat_activity;count
—---—
1826
(1 row)postgres=# SELECT COUNT(*) FROM pg_stat_activity WHERE state='active'; count
—---—
1005
(1 row)And these are actual figures. It reached 200 000 locks. At the same time, the following locks were acquired for the ill-fated query:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid=580707 GROUP BY mode;count | mode
—-----+---------------—
93 | AccessShareLock
1 | ExclusiveLockWhen reading the buffer, the DBMS uses the
share lock, and when writing — the exclusive lock. That is, write locks made less than 1% of all queries. In the pg_locks view, the kinds of locks do not always appear as described in the user documentation.Here is a table of matches:
AccessShareLock = LockTupleKeyShare
RowShareLock =LockTupleShare
ExclusiveLock = LockTupleNoKeyExclusive
AccessExclusiveLock = LockTupleExclusiveThe query «SELECT mode FROM pg_locks» showed that 234 INSERTs were waiting for execution of the CREATE INDEX command (without the CONCURRENTLY keyword) and 390 INSERTs were awaiting the
buffer content lock. A possible solution is to «teach» INSERTs from different sessions to reduce buffer overlapping.It's time to involve perf
The
perf utility collects pretty much diagnostic information. In the record… mode, it writes system event statistics to files (by default they are in ./perf_data), and in the report mode, it analyzes the collected data; for example, you can filter events by being related to postgres or to a given pid:$ perf record-u postgres or
$ perf record-p 76876 and then, say
$ perf report > ./my_resultsAs a result we will see something like
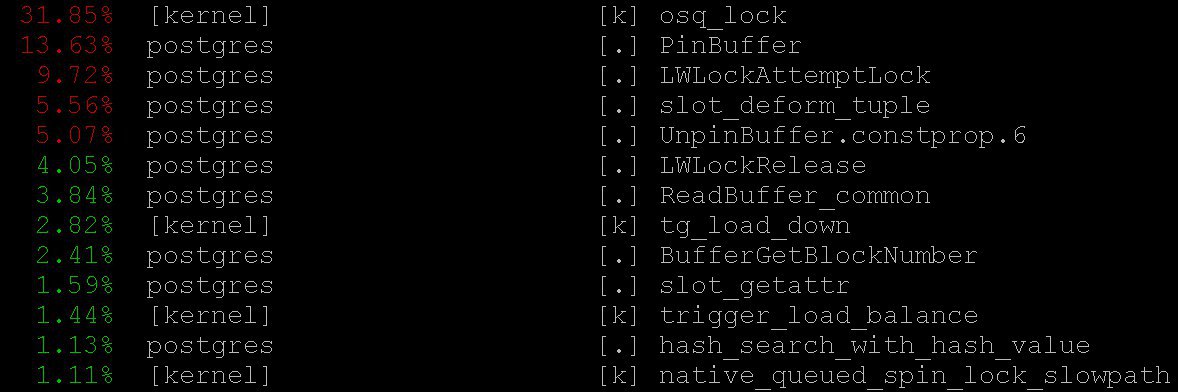
Usage of
perf for PostgreSQL diagnostics is described, for example, here, as well as in pg wiki.In our situation, important information was obtained even in the simplest mode —
perf top, which certainly worked a la top command of the operating system. With perf top, we've seen that the processor spends most of the time in kernel locks, as well as in the PinBuffer() and LWLockAttemptLock() functions.PinBuffer() is a function that increments the count of references to the buffer (mapping of a data page to RAM), through which Postgres processes know what buffers can be evicted and which cannot.LWLockAttemptLock() is a function to acquire LWLock. LWLock is a kind of lock with two levels – shared and exclusive – and without deadlock detection; locks are preallocated in shared memory, and waiting processes are queued.These functions were already optimized considerably in PostgreSQL 9.5 and 9.6. Spinlocks inside them were replaced with a direct use of atomic operations.
Flame graphs
No way without them: even if they were useless, they would have still been worth telling about since they are extremely elegant. Moreover, they are useful! Here goes an illustration from
github – not from the case discussed (neither we nor the customer are ready to disclose details yet).
These impressive pictures very clearly show what the processor cycles are spent on. The same
perf can collect data, but flame graph clearly visualizes the data and builds trees based on the collected call stacks. You can read about profiling with flame graphs, for example, here and download everything you need here.In our situation, we could see a huge number of
nestloops on the flame graphs. It seems like JOINs of a large number of tables in numerous parallel read queries caused a large number of access share locks.Statistics collected by
perf show where the CPU cycles are spent. And although we've seen that most of the CPU time passes in the locks, we did not see what exactly leads to such long waits of the locks because we do not understand where exactly the waits of the locks occur — CPU time is not spent in waits.In order to see the waits themselves, we can query the
pg_stat_activity system view.SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;revealed that:
LWLockTranche | buffer_content | UPDATE *************
LWLockTranche | buffer_content | INSERT INTO ********
LWLockTranche | buffer_content | \r
| | insert into B4_MUTEX
| | values (nextval('hib
| | returning ID
Lock | relation | INSERT INTO B4_*****
LWLockTranche | buffer_content | UPDATE *************
Lock | relation | INSERT INTO ********
LWLockTranche | buffer_mapping | INSERT INTO ********
LWLockTranche | buffer_content | \r(here asterisks just replace the details of the query that we do not share).
The values are visible for
buffer_content (lock on the contents of buffers) and for buffer_mapping (locks on parts of the shared_buffers hash table).To GDB for help
But why are there so many waits for these locks? For more detailed information about locks, we had to use the
GDB debugger. With GDB, we can get a stack of calls to specific processes. Using sampling, i.e., having collected a certain number of random call stacks, you can get an idea of the stacks where the longest waits happen.Let's consider the process of collecting statistics. We will consider the «manual» collection of statistics, although in real life special scripts are used to do it automatically.
First, it is necessary to attach
gdb to the PostgreSQL process. To do this, you need to find pid of the server process, say, from$ ps aux | grep postgrespostgres 2025 0.0 0.1 172428 1240 pts/17 S jul23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/datapid:igor_le:~$gdb -p 2025Once inside the debugger, we type
bt [that is, backtrace] or where. And we get a lot of information of this kind:(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from
/lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks (
data=0x110e6e8 "2018-06-01 15:35:38 MSK [524647]: [392-1]
db=bp,user=bp,app=[unknown],client=192.168.70.163
(http://192.168.70.163) LOG: relation 23554 new block 493:
248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393-1]
db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2
0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60
<errordata>) at elog.c:3024 #3 EmitErrorReport () at
elog.c:1479</errordata>Having gathered statistics, which included call stacks from all Postgres processes that were collected repeatedly at different points in time, we saw that 3706 seconds (about an hour) were spent awaiting the
buffer partition lock inside the relation extension lock, that is, a lock on a piece of the buffer manager's hash table that was needed to evict the former buffer in order to later replace it with a new one, corresponding to the extended part of the table. A certain number was also noticeable for buffer content lock, which corresponded to the wait of the lock of B-tree index pages for insertion.
At first, there were two explanations for such a monstrous waiting time:
- Someone else acquired this
LWLockand got stuck. But this is unlikely. Because nothing complicated happens inside the buffer partition lock. - We came across some sort of pathologic behavior of
Lwlock. That is, although none acquired the lock for too long, the wait for it lasted unnecessarily long.
Diagnostic patches and treatment of trees
By reducing the number of simultaneous joins, we would certainly reduce the flow of requests for locks. But it would be like a surrender. Instead, Alexander Korotkov, chief architect of Postgres Professional (he certainly helped to prepare this article), proposed a series of patches.
First of all, it was necessary to get a more detailed picture of the disaster. Although off-the-shelf tools are pretty universal, company's own diagnostic patches still prove useful.
A patch was written to add detailed logging of the time spent in
relation extension and of what happens inside the RelationAddExtraBlocks() function. This way we get to know what the time inside RelationAddExtraBlocks() is spent on.And another patch was written in support of the previous, which reports in
pg_stat_activity on what we are doing now in relation extension. It was done like this: when relation is extended, application_name becomes RelationAddExtraBlocks. This process is now convenient to analyze in maximum details using gdb bt and perf.As for treatment patches (rather than diagnostic), two of them were written. The first patch changed the behavior of
B‐tree leaf locks: previously, in an insert query, the leaf was locked as share, and only then acquired exclusive. Now it acquires exclusive from the beginning. Now this patch is already committed for PostgreSQL 12. Thanks to the committer status, which Alexander Korotkov received last year — the second PostgreSQL committer in Russia and the second in the company.The value of
NUM_BUFFER_PARTITIONS was also increased from 128 to 512 to reduce the load on the mapping locks: the hash table of the buffer manager was divided into smaller pieces with a view of decreasing the load on each particular piece.After applying this patch, locks on the contents of the buffers were gone, but despite the increase of
NUM_BUFFER_PARTITIONS, there remained buffer_mapping locks, that is, to recall, locks on pieces of the buffer manager's hash table:locks_count | active_session | buffer_content | buffer_mapping
----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐
12549 | 1218 | 0 | 15And this is not much. B‐tree was no longer a bottleneck. The extension of
heap came to the forefront.Treatment of conscience
Then Alexander suggested the following hypothesis and solution:
We are waiting too long on the
buffer partition lock during the buffer eviction. It is possible that on the same buffer partition lock there lies some highly demanded page, for example, the root of some B‐tree. At this location, there is a persistent flow of requests for the shared-lock from read queries.The wait queue in
LWLock is «not fair». Since as many shared locks as you want can be acquired at the same time, if shared lock is already acquired then next shared locks do not wait in line. Therefore, if the flow of shared locks is intensive enough to not leave gaps between them, the wait of the exclusive lock goes virtually to infinity.To fix this, we can try to offer the patch for «gentleman» behavior of locks. It stirs the conscience of
shared locker-s and they honestly stand in line when exclusive lock is already standing there (interestingly, heavyweight locks — hwlock — have no trouble with the conscience: they always honestly stand in line)locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec
‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------
173985 | 1802 | 0 | 569 | 0 | 0Everything is OK! There are no long
INSERTs. However, locks on pieces of hash tables remain. Well, it can’t be helped — these are the properties of the bus of our little supercomputer.This patch was also offered to the community. But regardless of the future of these patches in the community, nothing prevents them from getting into next versions of Postgres Pro Enterprise, which are designed right for customers with heavily loaded systems.
Lesson learned
Upstanding lightweight
share locks, which let exclusive locks into the queue, resolved the issue of hour-long delays on a multi-node system. The hash table of the buffer manager failed to work because of a too heavy flow of share lock-s, which left no chance for the locks needed to evict the old buffers and load the new ones. Issues with the extension of the buffer for database tables only was the result of this. Previously, it was possible to fix a weakness with access to the root of B-tree.PostgreSQL was not created with an eye to NUMA-architectures and supercomputers. Accommodating Postgres to these architectures is a huge job, which would (and will possibly) require coordinated efforts of many people and even companies. But troublesome consequences of these architectural problems can be mitigated. And we have to: the load types that resulted in delays such as those described are quite typical, and we continue to receive similar distress alerts from other places. Similar troubles manifested themselves before — on systems with fewer cores, but the consequences were just not so terrible, and the symptoms were treated differently and with other patches. Now another treatment is available: although not universal, but definitely useful.
So, when PostgreSQL works with the memory of the whole system as local, no high-speed bus between nodes can be compared with the time of access to local memory. Uneasy problems arise because of this, often urgent, but interesting. And the experience of solving them is useful not only to the solvers, but also for the whole community.

