
В посте я хочу напомнить о сложностях работы с AGI, рассказать о самых интересных идеях участников, топовых решениях и поделиться мнением, что не так с текущими попытками создать AGI.

Кто-то с ужасом, а кто-то с нетерпением ждет ИИ как в произведениях фантастов. С личностью, эмоциями, энциклопедическими знаниями и главное – с интеллектом, то есть способностями к логическим выводам, оперированию абстрактными понятиями, выделению закономерностей в окружающем мире и превращению их в правила. Как мы знаем, именно такой ИИ теоретики называют «сильным» или ещё AGI. Пока это далеко не мейнстримное направление в машинном обучении, но руководители многих больших компаний уже считают, что сложность их бизнеса превысила когнитивные способности менеджеров и без «настоящего ИИ» двигаться вперёд станет невозможно. Идут дискуссии, что же это такое, каким он должен быть, как сделать тест чтобы уж точно понять, что перед нами AGI, а не очередной blackbox, который лучше человека решает локальную задачу – например, распознавание лица на фотографии.
Вызов
В ноябре 2019 года создатель Keras Франсуа Шолле написал статью «Об оценке интеллекта». На хабре краткий пересказ уже выложила Rybolos. Ключевой практический элемент статьи — датасет для проверки способности алгоритмов к абстрактному мышлению в человеческом смысле. «Просто поглядеть» на него можно здесь.
Примеры задач из датасета; наверху — вход, внизу– ответ



Для человека эти задачи легко решаемы и напоминают блок из теста на IQ – они сводятся к набору трансформаций над картинками от 30x30 до 1x1: продолжить узор, восстановить удаленный кусок, обрезать, закрасить замкнутые области, найти лишний объект и т.д.
Соревнование
Не заставило себя долго ждать и само соревнование на Kaggle на основе этого датасета, призы в котором были не самые большие — в зависимости от скора $5K-8K за первое место. Для сравнения — в проходившем параллельно соревновании DFDC победивший Селим Сефербеков получил полмиллиона долларов.
Тем не менее, соревнование привлекло несколько грандмастеров Kaggle: rohanrao (H20), kazanova (H20, кстати третье место в глобальном рейтинге Kaggle), boliu0 (NVIDIA), titericz (NVIDIA), tarunpaparaju, много очень сильных ребят из ODS, в том числе Влада Голубева и Илью Ларченко, которые взяли третье место. Всего до LeaderBoard дошли 914 команд.
Участникам предлагалось обучить модель на 400 задачах, в каждой из которых есть train (три-пять картинок), ответ и тест (одна-две картинки и соответственно один-два ответа). Этот датасет вручную разметил Davide Bonin на комбинации из 192 элементарных трансформаций.
Такой же по объему датасет (400 задач) предлагался для валидации (eval), впрочем, на нем можно было и обучаться – особенно с учетом того, что задачи на нем отличались от обучающего. То есть сочетание трансформаций на тесте могли не встречаться на трейне, например вместо операции crop – crop + resize. В лидерборде было 100 задач, при этом на каждое задание можно было выдавать три варианта ответа, достаточно чтобы хотя бы один был верным.
Интересные идеи
CNN c TensorFlow Lattice
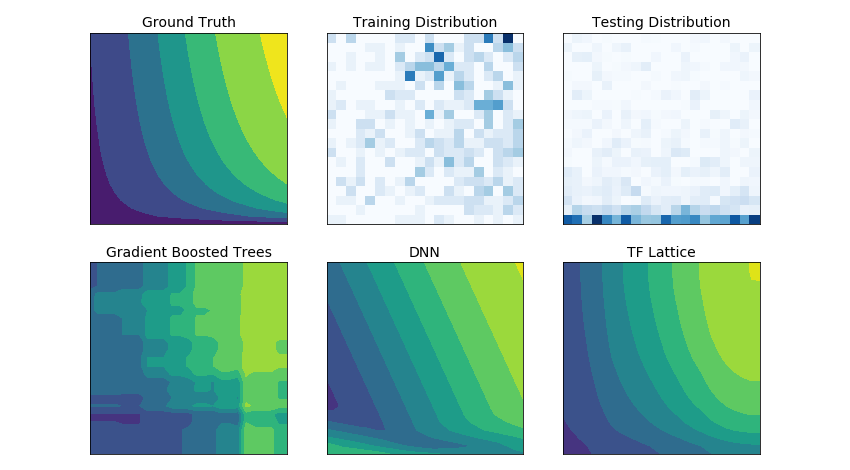
Не попали в лидерборд.TensorFlow Lattice позволяет накладывать достаточно жесткие ограничения на фичи при обучении сеток: монотонность, взаимную важность, выпуклость, взаимное доверие, унимодальность. Это существенно увеличивает способности сеток к экстраполяции и сглаживает разделяющие поверхности. Для привлечения внимания — картинка про сравнение разделяющих поверхностей разных моделей на одной задаче из блога TensorFlow Core.
В решении предлагалось взять сверточную сеть, так как CNN широко применяется для решения задач на картинках вроде выделения объектов. Идея была любопытная, но решение сработало на тесте ровно никак:

Вариационные автоэнкодеры
Заняли 131 место из 914 в лидерборде. Похожая идея наложить ограничения, но не на пространство признаков как в TF Lattice, а на пространство скрытых переменных, то есть использовать вариационные автоэнкодеры. О них на хабре есть отличная статья.
Это решение было доработано и дошло до LeaderBoard.На картинке в первой строке – входное изображение, во второй – правильный ответ, в третьей – результат работы модели.

Генетический алгоритм

Занял 631 место из 914 в лидерборде. В этом кейсе в качестве генов реализовано одиннадцать трансформаций — DSL генетического алгоритма. В ходе селекции по стратегии элитизма отбираются наиболее сильные гены:
- Сначала случайно выбирается и запускается одна трансформация из одиннадцати. Сохраняется лучшее решение.
- К этой трансформации случайным образом добавляются следующие, и обновляется список сильнейших генов.
- Процесс продолжается, пока не будет найдено решение: последовательность трансформаций, приводящих к правильному ответу.
Авторы рассматривают задачу как многокритериальную оптимизацию – насколько близкой получилась ширина и высота выходных картинок, совпадение цветов и положение клеток.
Несмотря на то, что такой подход что-то выбил на LB (631/914), реализация генетического алгоритма для большего числа элементарных трансформаций будет работать существенно дольше. Это, скорее всего, и стало препятствием к развитию этого решения.
Графовый подход
 Занял 165 место из 914 на лидерборде. Одна из наиболее человекообразных идей
Занял 165 место из 914 на лидерборде. Одна из наиболее человекообразных идей
– выделить на исходных изображениях объекты и далее работать с их трансформациями. Для выделения объектов применялся алгоритм k-clique-communities algorithm графовой библиотеки networkx, и справился он на отлично:



К сожалению, ноутбук с трансформациями автор не оставил, есть только выделение объектов, однако автор вошел в топ-19 на лидерборде.
Языковая модель
Заняла 592 место из 914 на лидерборде. На начало 2019 года BERT — state-of-the-art языковая модель. За последние месяцы было множество её усовершенствований: RoBERTa, DistilBERT, ALBERT и другие. Здесь идея решения основывается на двух фактах:
- Способности BERT работать с последовательностями.
- Механизме attention, который можно научить вычленять связи даже между достаточно удаленными элементами последовательности в противовес идее о влиянии на элемент только нескольких соседних.
В некоторых задачах идея сработала, пример ниже.
Обучающие примеры: слева – входная картинка, справа – правильный ответ.

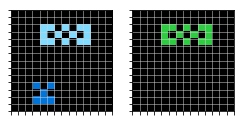
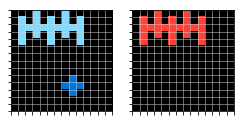


А вот результат работы обученной модели (справа):
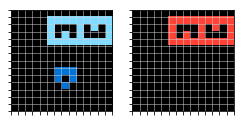
Жаль, что на других задачах результаты не были такими хорошими.
Работающие решения
Эх, а как хотелось верить в способность моделей вытаскивать простые логические правила. Да и еще в интрепретируемом виде. В итоге поиск решения участниками свелся к написанию правил (трансформаций) для решения конкретных кейсов, поиску по форуму и объединению в свой ноутбук таких решений.
Например, задание про изменение цветов при сохранении размера изображения: ноутбук Zoltan, занявшего в итоге шестое место, вошел в решение Влада Голубева и Ильи Ларченко, которые заняли третье место. Решение по сути представляет объединение нескольких, в том числе публичных. Так, идеи Ильи описаны в его репозитории, он декомпозировал задачи на абстракции (цвета, блоки, маски), в терминах которых для которых реализовал трансформации, решающие 32 задания. К этому добавляются решения Влада – как с похожим подходом на правилах и трансформациях, так и модель xgboost.
Пример работы решения
Обучающие примеры; слева – входная картинка, справа – правильный ответ.



А вот результат работы решения:

Достаточно похожим выглядит решение , взявшее второе место:
- Определить на входе тип задания (из шести по классификации автора) и параметры входных изображений.
- Иногда упростить задание – например, поменять один цвет или повернуть объекты.
- Перебирать в цикле различные трансформации (реализовано 51) и их комбинации чтобы выбрать три максимально близкие к ответу картинки.
- Выполнить преобразования, обратные тем, что были на шаге 2, к трем кандидатам.
- Иногда имеет смысл сделать аугментацию – например, из исходных примеров сделать задачи монохромными или только с одной формой.
Чемпион и 10 000 строк кода
Первое место занял icecuber, который захардкодил 100 правил из обучающего датасета и 100 правил из теста, выделил 42 основных трансформации, добавил аугментацию данных и жадный перебор вариантов с кучей технических трюков для ускорения (например, часть комбинаций трансформаций приводит к одинаковому результату, здесь можно сэкономить) с остановкой при достижении четырех трансформаций на задачу. Cамо решение и его описание.
Что в итоге?
На фоне вала статей и выступлений на конференциях A* об успехах в задачах создания сложных моделей по нескольким примерам результаты соревнования оказались совершенно неожиданными и обескураживающими.
В ноябре 2019 мне посчастливилось посетить ICCV2019 в высокотехнологичном Сеуле, где каждый второй доклад был посвящен задаче ZSL. Были ожидания, что в соревновании ARC достаточно применить одну из раскрученных в научном сообществе техник. Может, я был невнимателен, но, к своему разочарованию, не увидел среди решений участников такого подхода.
Так как уже в процессе соревнований участники делятся идеями и наработками, участие в челлендже казалось отличным способом узнать, какие подходы сейчас на переднем крае в области создания сложных моделей с минимальной обучающей выборкой или без таковой: zero-shot learning (ZSL), one-shot learning, few-shot learning, prototype learning и domain shift. Конечно, перечисленные проблемы подразумевают изменение доменной области, а не самой задачи — классификация остается классификацией. Но это самое проработанное направление в части обобщения моделей.
Сами мы решили попробовать GAN-архитектуру поверх feature extractor, которая у нас так и не зашла. Однако, примерно за три-четыре недели до конца соревнования стало понятно, что выигрывают решения на правилах. Обсудив внутри, мы пришли к выводу что, потратив кучу времени на написание, мы вряд ли повысим свои компетенции в современных методах, поэтому направили энергию на другие задачи.
В тысячный раз подтвердился тезис о прикладном характере машинного обучения — это набор инструментов, который надо уметь применять четко понимая задачу. В то же время бессмысленно применять даже самые крутые инструменты к непонятной задаче. Можно провести аналогию со станком, ЧПУ и 3D-принтером: несмотря на то, что область применения на каждом этапе растет, пока даже близко нет волшебной палочки, способной создать абсолютно любой предмет.
Чтобы обучить машину, мало придумать ей абстрактный язык (DSL или набор трансформаций), придумать функцию потерь и показать пару примеров. Челлендж прошёл, но осталось разочарование: то, что маркетологи до сих пор продают как AI, на поверку оказывается набором инженерных хитростей. Флёр волшебства окончательно растаял.
