Здравствуйте. Меня зовут Любовь Волкова, я системный архитектор департамента разработки бизнес-решений. Время от времени я пишу прикладные посты о серверных продуктах Microsoft (например про мониторинг серверов SharePoint и про обслуживание баз данных, связанных с базами контента, службами и компонентами этой платформы.
Этот пост является первым из двух, в которых я расскажу о важной с точки зрения администрирования порталов SharePoint теме – по тюнингу серверов SQL, нацеленного на достижение высокой производительности. Крайне важно обеспечить тщательное планирование, корректную инсталляцию и последующую настройку SQL-сервера, который будет использоваться для хранения данных, размещенных на корпоративном портале.
В этом посте вы сможете прочитать о планировании инсталляции SQL-сервера. Чуть позже будет опубликована вторая часть, посвященная установке SQL-сервера и последующему конфигурированию.

Перечислим семь основных причин, почему рассматривается вопрос о виртуализации серверов:
Рассматривая вопрос о виртуализации серверов, входящих в состав фермы SharePoint или в состав серверов сетевой инфраструктуры, обеспечивающих аутентификацию пользователей, разрешение имен, управление PKI и др. функции, необходимо помнить о том, что существует возможность виртуализации:
Сводные данные о гостевых операционных системах, поддерживаемых ими версиях SQL-серверов и кластеризации виртуальных машин представлены в таблице ниже:
Отметим, что поддержка гостевой кластеризации осуществляется в версиях операционной системы Windows Server 2008 SP2 и более поздних.
Более подробное описание назначение и архитектуры отказоустойчивого гостевого кластера можно найти здесь, а требований к оборудованию, особенностей поддержки работы в виртуальной среде для конкретных версий SQL-серверов можно получить по ссылкам, приведенным в следующей таблице:
Исследования ESG Labs подтвердили, что производительность SQL Server 2012 OLTP на виртуальных серверах уступает лишь около 6.3% показателям физической платформы.
Hyper-V поддерживает до 64 процессоров на отдельную виртуальную машину, тесты показали увеличение производительности в 6 раз и 5-кратное повышение показателей времени выполнения транзакций. На иллюстрации ниже представлены основные результаты проведенных тестов. С подробным отчетом можно познакомиться здесь.

Hyper-V может быть использована для виртуализации баз данных SQL-сервера больших объемов и поддерживает использование дополнительных возможностей, таких как SR-IOV, Virtual Fibre Channel и Virtual NUMA.
Перечислим главные ее недостатки, которые становятся основными причинами того, что SQL-сервер для SharePoint разворачивается на физическом сервере:
Для обеспечения нормального уровня функционирования SQL-сервера требуется обеспечить достаточное кол-во оперативной памяти. В случае, когда разворачивается только один экземпляр SQL, который выделяется исключительно под работу с базами данных SharePoint, требования минимальны:
SharePoint является мощной платформой для построения портальных решений, имеющая модульную архитектуру. Набор служб и компонентов, обеспечивающих работу корпоративного портала, позволяют выделить перечень баз данных, хранение которых должно быть спланировано. Можно выделить три группы баз данных, различающиеся временем рекомендуемого планирования:
В статье Майкрософт подробно описываются основные характеристики всех базы данных, перечисленных в группах. В таблице ниже приведена рекомендация по настройке режима восстановления для каждой из них с учетом многолетнего опыта технической поддержки, миграций, восстановления баз данных SharePoint:
В идеале на SQL-сервере рекомендуется иметь шесть дисков для размещения следующих файлов:
SharePoint использует SQL-сервер для хранения своих данных, который имеет свои особенности хранения данных. В связи с этим подготовка дисковой подсистемы как на физическом, так и на логическом уровнях, учитывающие эти особенности, будет оказывать огромное влияние на конечную производительность корпоративного портала.
Данные, которые хранит Microsoft SQL Server, разбиваются на страницы размером по 8 КБ, которые в свою очередь группируются в так называемые экстенты (extent) размером по 64 КБ. Подробнее об этом можно узнать здесь. В соответствии с этим настройка дисковой подсистемы заключается в обеспечении целостного размещения экстента на всех физических и логических уровнях дисковой подсистемы.
Первое с чего следует начать – это инициализация RAID. При этом массив, на котором будут располагаться базы данных должен иметь размер страйпа (stripe size) кратный 64 КБ, предпочтительнее если это будет именно 64 КБ.
Процедура выравнивания файловой системы относительно физического её размещения на дисковом массиве имеет очень важное значение при рассмотрении вопроса повышения производительности работы SQL-сервера. Подробно она описана здесь. На любом жёстком диске или SSD первые 63 сектора по 512 байт зарезервированы для размещения файлов, которые создаются в процессе установки операционной системы или при выполнении операций управления дисками, а также с помощью специальных программ — менеджеров разделов жёсткого диска. Суть процедуры выравнивания заключается в подборе такого начального смещения (starting partition offset), при котором в одном страйпе дискового массива умещалось бы целое число кластеров файловой системы. Иначе возможна ситуация, при которой для произведения операции считывания одного кластера данных файловой системы необходимо будет выполнить две операции физического чтения с дискового массива, что в значительной степени ухудшает производительность дисковой подсистемы (потеря в производительности может составлять до 30%). В случае твердотельного накопителя потери производительности будут несколько ниже, но он быстрее выработает свой ресурс ввиду более частых операций чтения-записи.
На иллюстрации ниже отражены особенности выполнения операций чтения/записи для невыравненных разделов на примере страйпа в 64 Кб.
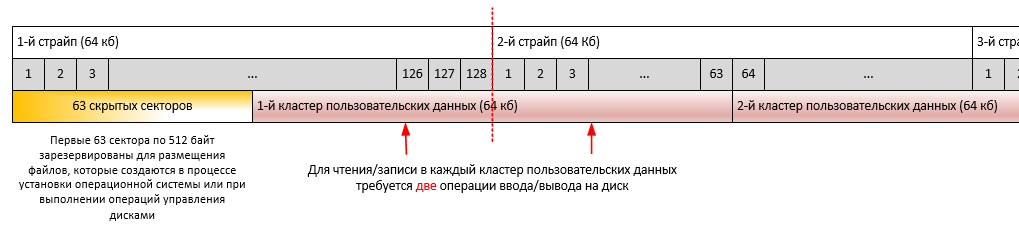
На иллюстрации ниже отражены особенности выполнения операций чтения/записи для выравненных разделов на примере страйпа в 64 Кб.
По умолчанию в Windows Server 2008/2012 смещение разделов составляет 1024 Кб, что хорошо коррелируется с размером страйпов на дисках в 64 Кб, 128 Кб, 256 Кб, 512 Кб и 1024 Кб.
В случае случаях настройки операционных систем из образов, использования различного программного обеспечения для управления разделами дисков могут возникнуть ситуации, связанные с нарушением выравниваний разделов. В связи с этим рекомендуется перед установкой SQL-сервера в качестве дополнительной страховки выполнять перепроверку корреляций, описание которых приведено в следующем разделе.
Partition Offset
Наиболее правильный метод проверки смещения разделов для базовых дисков, — использование утилиты командной строки wmic.exe:
wmic partition get BlockSize, StartingOffset, Name, Index
Для проверки выравнивания разделов для динамических дисков необходимо воспользоваться diskdiag.exe (описание работы с нею приведено в разделе «Dynamic Disk Partition Offsets»).
Stripe Unit Size
В ОС Windows нет стандартных средств определения размера минимального блока данных для записи на диск (stripe unit size). Значение этого параметра необходимо выяснять из документации вендора на жесткий диск или у SAN-администратора. Чаще всего показатели Stripe Unit Size составляют 64 Кб, 128 Кб, 256 Кб, 512 Кб или 1024 Кб. В рассмотренных ранее примерах использовалось значение в 64 Кб.
File Allocation Unit Size
Для определения значения данного показателя необходимо использовать следующую команду отдельно для каждого из дисков (Значение свойства Bytes Per Cluster):
fsutil fsinfo ntfsinfo c:
Для разделов, на которых хранятся файлы данных и файлы журналов транзакций SQL Server значение показателя должно быть 65,536 байт (64 Кб). См. «Оптимизация хранения данных на уровне файловой системы».
Две важных корреляции, в соблюдение которых являются основой оптимальной производительности ввода/вывода на диск. Результаты вычислений для следующих выражений должны составлять целое число:
Наиболее важной является первая корреляция.
Пример невыравненных значений. Смещение раздела (Partition offset) равно 32,256 bytes (31.5 Кб) и размер минимального блока записи данных на диск составляет 65,536 bytes (64 Кб). 32,256 bytes/65,536 bytes=0.4921875. Результат деления не является целым числом, в итоге имеем не выравненные значения Partition_Offset и Stripe_Unit_Size.
Если же смещение раздела (Partition offset) равно 1,048,576 байт (1 Мб), а размер минимального блока записи данных на диск составляет 65,536 байт (64 Кб), то результат деления равен 8, — целое число.
Следующим уровнем, на котором следует организовать оптимальное хранение экстентов, является файловая система. Оптимальными настройками здесь являются файловая система NTFS с размером кластера 65,536 байт (64 КБ). В связи с этим перед инсталляцией SQL-сервера настоятельно рекомендуется выполнить форматирование дисков и задать размер кластера в 65,536 байт (64 Кб) вместо 4096 байт (4Кб) по умолчанию.
Проверить текущие значения для диска можно при помощи следующей команды:
chkdsk c:
Пример вывода результата:
В представленном примере размер кластера равен 4096 байт/1024 = 4 Кб, что не соответствует рекомендациям. Для изменения придется выполнить переформатирование диска. Установку размера кластера можно выполнить в ходе настройки параметров форматирования диска средствами операционной системы Windows:
После этого убедиться в том, что размер кластера теперь соответствует рекомендациям (65536 байт/1024 = 64 кб):

При проектировании размещения файлов системных баз данных SQL-сервера и баз данных SharePoint важное значение будет иметь оптимальность выбора дисков с учетом их ранга, построенного на основе информации о скоростях чтения/записи.
Для тестирования и определения точных данных о скорости чтения/записи файлов с произвольным доступом и с последовательным доступом можно воспользоваться программным обеспечением, аналогичным CrystalDiskMark (например, SQLIO). Обычно приложение позволяет ввести базовые параметры тестирования, как минимум:
Ниже приведен пример полученных результатов выполнения тестов:
Ниже приведено описание содержания выполняемых тестов:
Отметим, что в тестах используется размер единицы записи в 4 Кб, что не полностью соответствует реальной схеме хранения данных SQL-сервером и работе со страницами в 8 кб эктентами в 64Кб. При выполнении нет цели обеспечить абсолютное соответствие полученных результатов реальным данным о тех же операциях, выполняемых SQL-сервером. Основная конечная цель – ранжирование дисков по скорости выполнения операций чтения/записи и получение итоговой таблицы.
Для быстрого принятия решения в ходе инсталляции SQL-сервера, конфигурирования параметров размещения файлов баз данных будет полезным оформить результаты проведения тестирований в виде таблицы отдельно по каждому виду тестов, шаблон которой показан ниже:
Для магнитных дисков (отдельных или в составе RAID), последовательные операции operations (тест Seq Q32) часто превышают результаты других тестов в 10x-100x раз. Эти метрики часто зависят от способа подключения к хранилищу. Необходимо помнить о том, что кол-во Мб/с, заявляемые вендорами – это теоретические ограничения. На практике они обычно меньше заявляемых на 5-20%.
Для твердотельных дисков разница между скоростью последовательных и произвольных операций чтения/записи не должны сильно отличаются друг от друга, как правило не более чем в 2-3 раза. На скорость будут влиять методы подключения, такие как 3Gb SATA, 1Gb iSCSI, or 2/4Gb FC.
Если сервер загружается с локального диска и хранит данные SQL-сервера на другом диске, в план тестирования также необходимо включать оба эти диска. Сравнение показателей тестов CrystalDiskMark диска, на котором хранятся переменные, данные с показателями диска, на котором установлена операционная система, могут продемонстрировать преимущество в производительности второго. В такой ситуации системному администратору необходимо проверить настройки диска или хранилища SAN на предмет корректности и получения оптимальных показателей производительности.
Информация о том, для каких целей используется портал, позволяет корректно расставить приоритеты при выборе дисков для хранения баз данных SharePoint.
Если корпоративный портал пользователями используется главным образом для чтения контента и не наблюдается активный ежедневный прирост контента (например, внешний сайт компании), наиболее производительные диски необходимо выделить под хранение данных, выделив под хранение файлов журналов транзакций менее производительные:
Если корпоративный портал используется для организации совместной работы пользователей, которые ежедневно активно загружают десятки документов, приоритеты будут другими:
Низкая скорость выполнения операций чтения/записи для системной базы данных tempdb SQL-сервера серьезно влияет на общую производительность фермы SharePoint, как следствие на производительность корпоративного портала. Лучшей рекомендацией может стать использование RAID 10 для хранения файлов этой базы данных.
Для сайтов, предназначенных для совместной работы или выполнения большого объема операций обновления, необходимо обратить особое внимание на выбор дисков для хранения файлов баз контента SharePoint. необходимо учесть следующие рекомендации:
Общая формула расчета ожидаемого размера базы данных контента:
((D*V)*S)+(10Kb*(L+(V*D))), где:
Необходимо учитывать дополнительные расходы по хранению:
Не смотря на то что RAID 5 имеет лучшие показатели в разрезе производительность/стоимость, для баз данных SharePoint настоятельно рекомендуется использовать RAID 10, особенно в случае активного использования корпоративного портала для совместной работы пользователей. RAID 5 имеет не очень высокие показатели скорости записи на диск.
Необходимо убедиться в том, что между серверами SQL и SharePoint настроено высокоскоростное соединение.
Первым шагом для повышения производительности сетевого обмена данными на каждом из серверов фермы SharePoint рекомендуется установить по два сетевых адаптера, один из которых выделен для передачи трафика между SQL и SharePoint, а второй под взаимодействие с клиентскими запросами.
Инсталляция серверов SQL и SharePoint на базе Windows Server 2012 и использование функциональной возможности объединения адаптеров в группу даст дополнительные преимущества и может стать вторым серьезным шагом в оптимизации конфигурационных настроек под SharePoint:
Более подробно о настройке объединения адаптеров в группу можно прочитать здесь.
Согласно требованиям к программному обеспечению, ферма SharePoint может быть развернута на базе следующих операционных систем:
Еще в 2007 году в системе Windows Server 2003 SP2 появился набор функций, управляющих производительностью сети и известных под общим названием Scalable Networking Pack (SNP). Данный пакет использовал аппаратное ускорение при обработке сетевых пакетов для обеспечения более высокой пропускной способности. В состав пакета SNP входят функции, известные как Receive Side Scaling (RSS), TCP/IP Chimney Offload (иногда ее называют TOE) и Network Direct Memory Access (NetDMA). Этот функционал операционной системы, позволяющий передать нагрузку по обработке пакетов TCP/IP от процессора на сетевую карту.
Из-за проблем с пакетом SNP в системе Server 2003 SP2 ИТ-сообщество быстро взяло за правило отключать эти функции. Для системы Server 2003 такой подход имел смысл. Но в системах Server 2008, Server 2008 R2 и более поздних версиях операционной системы отключение данных функций зачастую может привести к снижению производительности сети и пропускной способности сервера. Эти функции весьма стабильны в системе Server 2008 R2 (с пакетом SP1 или без него). К сожалению, отключение функций как один из первых шагов в решении сетевых проблем по-прежнему является очень распространенной практикой устранения неполадок, при том что многие проблемы таким образом не решаются.
Технология RSS предоставляет сетевому адаптеру возможность распределения нагрузки сетевой обработки между несколькими ядрами в многоядерных процессорах.
В случае отключения использования механизма RSS, система может понести значительные потери в производительности, что приведет к снижению общей нагрузки и количества сетевых операций, которые способен обработать каждый сервер. Такая ситуация может привести к росту затрат, связанных с покупкой дополнительного оборудования, которое на самом деле не требуется, и с дополнительными расходами на инфраструктуру, сопровождающими приобретение дополнительного оборудования.
По умолчанию в системах Server 2008 R2 и более поздних версиях технология RSS включена. Вы можете узнать, включена глобально технология или нет, анализируя результат следующей команды:
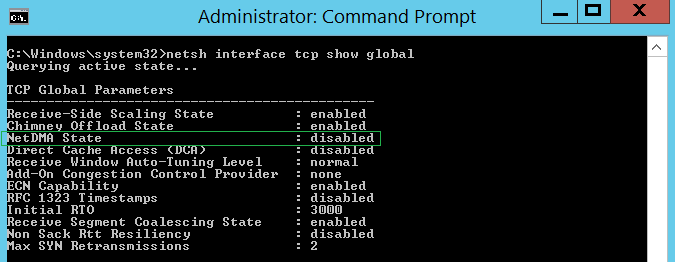
netsh interface tcp show global
Необходимо убедиться в том, что использование технологии RSS также включено и на отдельных сетевых адаптерах через их дополнительные свойства или настройки конфигурации:

RSS также зависит от разгрузок сетевого адаптера, известных под названиями TCP Checksum Offload, IP Checksum Offload, Large Send Offload и UDP Checksum Offload (для протоколов IPv4 и IPv6). Так что, если они были отключены на сетевом адаптере, технология RSS не будет для него использоваться.
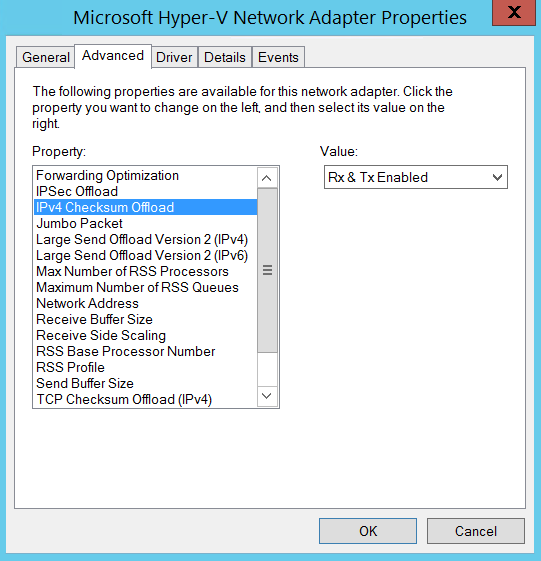
Кроме того, некоторые сетевые адаптеры имеют дополнительные параметры, управляющие количеством процессоров, применяемых в механизмах RSS, а также числом очередей RSS.
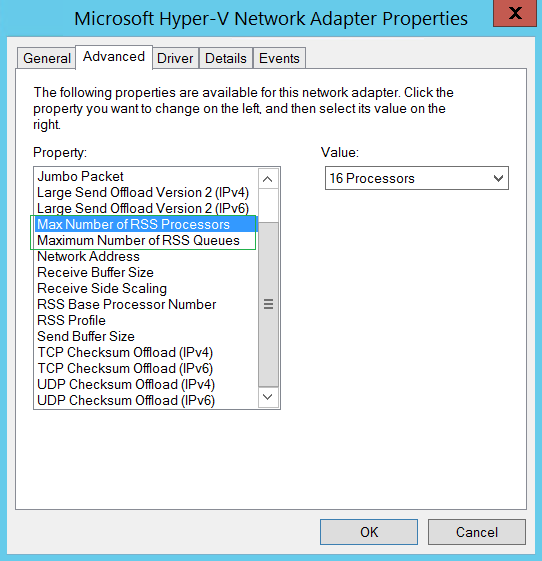
Распространенной ошибкой является установка малого количества процессоров RSS по сравнению с числом процессоров на сервере. Каждый адаптер и производитель имеют свои рекомендации по настройке, поэтому необходимо смотреть документацию производителя, чтобы определить оптимальные настройки для конкретной среды и рабочей нагрузки.
Технология TCP Chimney Offload (часто называемая производителями TCP/IP Offloading или более кратко, — TOE) передает обработку трафика TCP от процессора компьютера сетевому адаптеру, который поддерживает TOE. Передача TCP обработки с центрального процессора на сетевой адаптер может освободить процессор для выполнения функций, больше связанных с работой приложений. TOE может разгрузить обработку как для TCP/IPv4, так и для TCP/IPv6 соединений, если сетевой адаптер это поддерживает.
Из-за задержек, связанных с передачей обработки TCP/IP сетевому адаптеру (более подробно можно прочитать об этом здесь), технология TOE максимально эффективна для приложений, которые устанавливают долговременные соединения и передают большие объемы данных. Серверы, выполняющие долговременные соединения, такие как репликация базы данных, работа с файлами или выполнение функций резервного копирования, являются примерами компьютеров, которые могут получить выгоду от использования TOE.
Серверы с недолгими соединениями, такие как веб-серверы SharePoint фактически ничего не выигрывают от данной технологии. В связи с этим рекомендуется отключить использование TCP Chimney Offload.
Проверить глобальные настройки TCP можно при помощи следующей команды:
netsh interface tcp show global
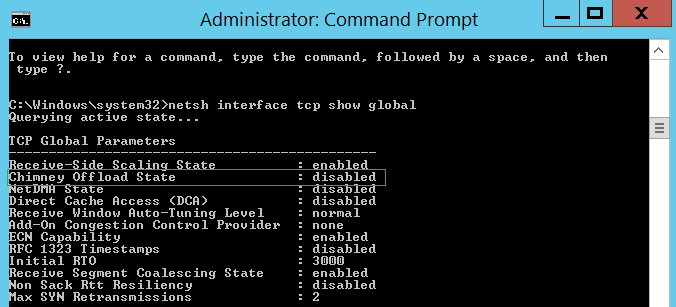
Отключить использования TOE для TCP можно при помощи команды:
netsh int tcp set global chimney=disable
Перед принятием решения об отключении использования TOE рекомендуется предварительно взглянуть на статистику использования TOE для TCP с помощью команды:
Netsh netsh interface tcp show chimneystats
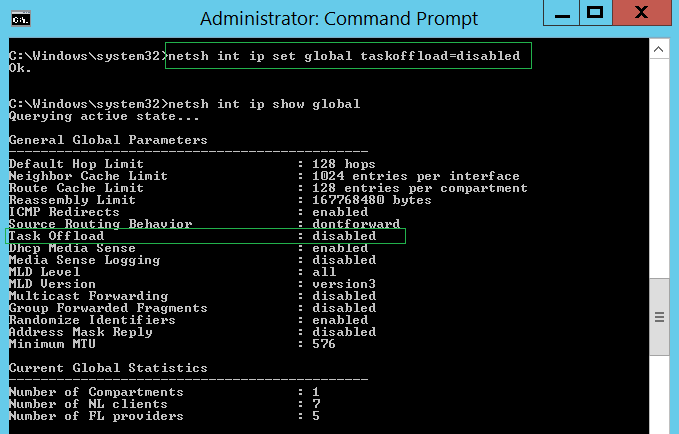
Отключить ТОЕ для IP можно при помощи следующей команды
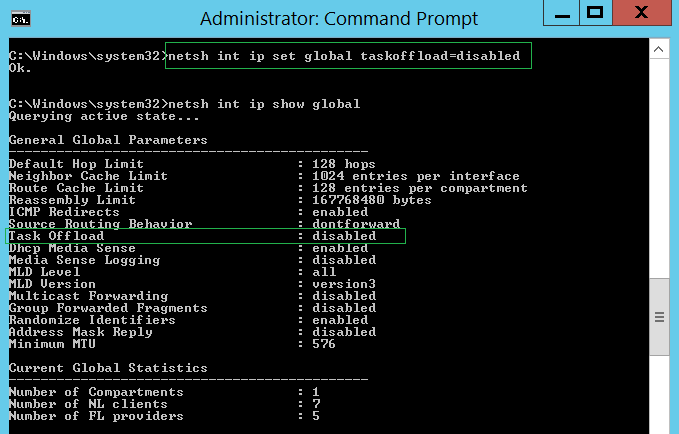
netsh int ip set global taskoffload=disabled
Проверить глобальные настройки IP при помощи другой команды:
netsh int ip show global
NetDMA – достаточно интересная функция. Смысл её применения есть тогда, когда у Вас не поддерживается отключен TOE и необходимо ускорить обработку сетевых подключений. NetDMA позволяет копировать без участия CPU данные из приемных буферов сетевого стека сразу в буферы приложений, чем снимает с CPU данную задачу.
Для того, чтобы использовать NetDMA, необходимо оборудование, которое поддерживает этот функционал, – в случае Windows это процессор с поддержкой технологий семейства Intel I/O Acceleration Technology (I/OAT). Включение NetDMA на оборудовании AMD эффекта, увы, не принесёт.
Отметим, что TOE и NetDMA являются взаимоисключающими, эти функции не могут быть одновременно включены в системе.
Для включения NetDMA в Windows 2008 R2 можно использовать следующую команду:
netsh interface tcp set global netdma=enabled
Проверку состояния функционала можно выполнить при помощи другой команды:
netsh interface tcp show global
Windows Server 2008 R2
«Automatic» для TCP Chimney Offload означает, что функция будет включена, если для сетевого адаптера включена настройка «TCP Chimney Offload» в сочетании с использованием высокоскоростного подключения, такого 10 GB Ethernet.
Windows Server 2012, Windows Server 2012 R22
Этот пост является первым из двух, в которых я расскажу о важной с точки зрения администрирования порталов SharePoint теме – по тюнингу серверов SQL, нацеленного на достижение высокой производительности. Крайне важно обеспечить тщательное планирование, корректную инсталляцию и последующую настройку SQL-сервера, который будет использоваться для хранения данных, размещенных на корпоративном портале.
В этом посте вы сможете прочитать о планировании инсталляции SQL-сервера. Чуть позже будет опубликована вторая часть, посвященная установке SQL-сервера и последующему конфигурированию.

Планирование инсталляции SQL-сервера
Виртуализация SQL-сервера
Зачем нужна виртуализация серверов?
Перечислим семь основных причин, почему рассматривается вопрос о виртуализации серверов:
- Увеличение коэффициента использования аппаратного обеспечения. По статистике, большинство серверов загружены на 15-20 процентов при выполнении ими повседневных задач. Использование нескольких виртуальных серверов на одном физических позволит увеличить его до 80 процентов, обеспечив при этом существенную экономию на приобретении аппаратного обеспечения.
- Уменьшение затрат на замену аппаратного обеспечения. Поскольку виртуальные сервера отвязаны от конкретного оборудования, при обновлении парка физических серверов не требуется повторная установка и настройка программного обеспечения. Виртуальная машина может быть просто скопирована на другой сервер.
- Повышение гибкости использования виртуальных серверов. В случае если необходимо использование нескольких серверов (к примеру, для тестирования и работы в продуктовой среде) при изменяющейся нагрузке, виртуальные сервера являются лучшим решением, так как они могут быть безболезненно перенесены на другие платформы, когда физический сервер испытывает повышенные нагрузки.
- Повышение управляемости серверной инфраструктуры. Существует множество продуктов для управления виртуальной инфраструктурой, позволяющих централизованно управлять виртуальными серверами и обеспечивать балансировку нагрузки и «живую» миграцию.
- Обеспечение высокой доступности. Подготовка резервных копий виртуальных машин и их восстановление занимает значительно меньшее время и является более простой процедурой. Также, при выходе из строя оборудования, резервная копия виртуального сервера может быть сразу запущена на другом физическом сервере.
- Экономия на обслуживающем персонале. Упрощение управления виртуальными серверами в перспективе влечет за собой экономию на специалистах, обслуживающих инфраструктуру компании. Если два человека с помощью средств для управления виртуальными серверами могут делать то, что делали четверо, зачем вам два лишних специалиста, получающих не менее $15000 в год? Тем не менее, нужно учитывать, что для подготовки квалифицированных кадров в сфере виртуализации тоже нужны немалые деньги.
- Экономия на электроэнергии. Для малых компаний этот фактор, конечно же, не имеет особого значения, однако для крупных ЦОД, где затраты на поддержание большого парка серверов включают в себя расходы на электроэнергию (питание, системы охлаждения), этот момент имеет немалое значение. Концентрация нескольких виртуальных серверов на одном физическом уменьшит эти затраты.
Поддержка виртуализации SQL-северов
Рассматривая вопрос о виртуализации серверов, входящих в состав фермы SharePoint или в состав серверов сетевой инфраструктуры, обеспечивающих аутентификацию пользователей, разрешение имен, управление PKI и др. функции, необходимо помнить о том, что существует возможность виртуализации:
- Active Directory Domain Services;
- Веб-серверов и серверов приложений SharePoint (Front-End Web Server и Application Server);
- SQL Server Services;
- Любого компонента SQL, ADS, SharePoint 2013.
Сводные данные о гостевых операционных системах, поддерживаемых ими версиях SQL-серверов и кластеризации виртуальных машин представлены в таблице ниже:
| Версия SQL-сервера | Поддерживаемые гостевые операционные системы Windows Server | Поддержка на Hyper-V | Поддержка гостевой кластеризации |
|---|---|---|---|
| SQL Server 2008 SP3 | 2003 SP2, 2003 R2 SP2, 2008 SP2, 2008 R2 SP1, 2012, 2012 R2 | Да | Да |
| SQL Server 2008 R2 SP2 | 2003 SP2, 2008 SP2, 2008 R2 SP1, 2012, 2012 R2 | Да | Да |
| SQL Server 2012 SP1 | 2008 SP2, 2008 R2 SP1, 2012, 2012 R2 | Да | Да |
| SQL Server 2014 | 2008 SP2, 2008 R2 SP1, 2012, 2012 R2 | Да | Да |
Отметим, что поддержка гостевой кластеризации осуществляется в версиях операционной системы Windows Server 2008 SP2 и более поздних.
Более подробное описание назначение и архитектуры отказоустойчивого гостевого кластера можно найти здесь, а требований к оборудованию, особенностей поддержки работы в виртуальной среде для конкретных версий SQL-серверов можно получить по ссылкам, приведенным в следующей таблице:
| Версия SQL-сервера | Ссылка на документацию |
|---|---|
| SQL Server 2008 SP3 | Hardware & Software Requirements, Hardware Virtualization & Guest Clustering Support |
| SQL Server 2008 R2 SP2 | Hardware & Software Requirements, Hardware Virtualization & Guest Clustering Support |
| SQL Server 2012 SP1 | Hardware & Software Requirements, Hardware Virtualization & Guest Clustering Support |
| SQL Server 2014 | Hardware & Software Requirements, Hardware Virtualization & Guest Clustering Support |
Производительность SQL-серверов при виртуализации
Исследования ESG Labs подтвердили, что производительность SQL Server 2012 OLTP на виртуальных серверах уступает лишь около 6.3% показателям физической платформы.
Hyper-V поддерживает до 64 процессоров на отдельную виртуальную машину, тесты показали увеличение производительности в 6 раз и 5-кратное повышение показателей времени выполнения транзакций. На иллюстрации ниже представлены основные результаты проведенных тестов. С подробным отчетом можно познакомиться здесь.
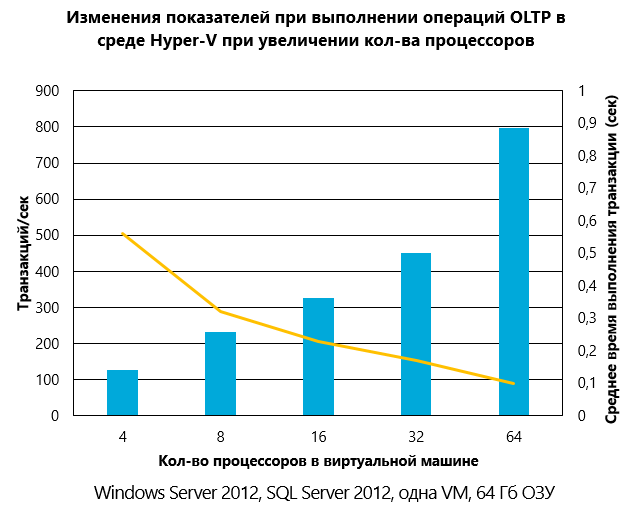
Hyper-V может быть использована для виртуализации баз данных SQL-сервера больших объемов и поддерживает использование дополнительных возможностей, таких как SR-IOV, Virtual Fibre Channel и Virtual NUMA.
Недостатки виртуализации SQL-серверов
Перечислим главные ее недостатки, которые становятся основными причинами того, что SQL-сервер для SharePoint разворачивается на физическом сервере:
- Необходимость перестройки подхода к работе с надежностью системы. Действительно, так как на одном физическом сервере одновременно запущены несколько виртуальных машин, то выход из строя хоста приводит к одновременному отказу всех ВМ и работающих на них приложений.
- Балансировка нагрузки. Если виртуальная машина SQL-сервер обычно использует много вычислительных ресурсов процессора (или памяти), что сказывается на работе других виртуальных машин и приложений хоста, которым также требуется процессорное время (память). Даже в случае размещения на хосте только виртуальной машины с SQL-сервером, настройка оптимального уровня производительности требует целого комплекса действий. Подробнее об этом можно узнать в статье Майкла Оти, доступной по ссылке. Администраторам приходится распределять нагрузку, устанавливая правила, по которым запущенные виртуальные машины будут автоматически перемещаться на менее нагруженные сервера или же «разгружать» загруженные.
ОЗУ & ЦПУ
Для обеспечения нормального уровня функционирования SQL-сервера требуется обеспечить достаточное кол-во оперативной памяти. В случае, когда разворачивается только один экземпляр SQL, который выделяется исключительно под работу с базами данных SharePoint, требования минимальны:
| Малая ферма SharePoint (контент до 500 Гб) | Средняя ферма SharePoint (контент от 501 Гб до 1 Тб) | Большая ферма SharePoint (контент 1-2 Тб) | Очень большая ферма SharePoint (контент 2-5 Тб) | Особые случаи | |
|---|---|---|---|---|---|
| ОЗУ | 8 Гб | 16 Гб | 32 Гб | 64 Гб | 64 Гб |
| ЦПУ | 4 | 4 | 8 | 8 | 8 |
Планирование размера, размещения и общих требований к базам данных для SharePoint
SharePoint является мощной платформой для построения портальных решений, имеющая модульную архитектуру. Набор служб и компонентов, обеспечивающих работу корпоративного портала, позволяют выделить перечень баз данных, хранение которых должно быть спланировано. Можно выделить три группы баз данных, различающиеся временем рекомендуемого планирования:
- Перед инсталляцией SQL-сервера. К этой группе относятся все системные базы данных SQL-сервера, база контента SharePoint (по умолчанию одна).
- Перед инсталляцией SharePoint-сервера. К этой группе относятся база данных конфигурации SharePoint, база контента Центра Администрирования SharePoint.
- Перед развертыванием приложения-службы, хранящей данные в базе/базах данных. Примеры: служба управляемых метаданных, служба профилей пользователей, поиск и др.
- Перед созданием дополнительных баз контента SharePoint.
В статье Майкрософт подробно описываются основные характеристики всех базы данных, перечисленных в группах. В таблице ниже приведена рекомендация по настройке режима восстановления для каждой из них с учетом многолетнего опыта технической поддержки, миграций, восстановления баз данных SharePoint:
| |
|
|
|---|---|---|
| База данных master |
Простой |
Простой |
| Шаблон базы данных model |
Полный доступ |
Простой. Как правило настройка выполняется однократно или очень редко. Вполне достаточно выполнять резервную копию после внесения изменений |
| База данных msdb |
Простой |
Простой |
| База данных tempdb |
Простой |
Простой |
| База данных контента Центра администрирования |
Полный доступ |
Простой. |
| База данных конфигурации |
Полный доступ |
Изменения обычно активно вносятся на этапе первоначальной или точечной настройки служб и компонентов фермы SharePoint, что имеет четкие непродолжительные временные границы. Более рационально выполнять резервную копию после внесения завершенных блоков изменений. |
| База данных службы управления приложениями |
Полный доступ |
Простой. Как правило в ферме SharePoint устанавливается от 0 до небольшого кол-ва приложений (1-5) SharePoint. Установки приложений обычно существенно разнесены по времени. Более рационально выполнять полное резервное копирование базы данных после инсталляции отдельного приложения |
| База данных службы параметров подписки |
Полный доступ |
Простой. Как правило приложения SharePoint устанавливаются на небольшом кол-ве сайтов (1-5). Установки приложений обычно существенно разнесены по времени. Более рационально выполнять полное резервное копирование базы данных после инсталляции отдельного приложения. Полный. Если предполагается установка приложений на неограниченном кол-ве веб-узлов, инсталляции выполняются часто |
| Служба подключения к бизнес-данным |
Полный доступ |
Простой. Настройка и внесение изменений, связанных с работой данной службы обычно непродолжительна по времени и выполняется однократно или небольшое кол-во раз. Более рационально выполнять полное резервное копирование базы данных после завершенных блоков создания/редактирования моделей данных, внешних типов контента и списков внешних данных |
| База данных приложения-службы управляемых метаданных |
Полный доступ |
Простой в случае использования справочников с редко изменяемым содержимым. Полный доступ в случае внесения изменений в наборы терминов на регулярной основе (активное создание и редактирование иерархических справочников, тегитирование элементов списков и документов). |
| База данных приложения-службы перевода SharePoint |
Полный доступ |
Простой. |
| Power Pivot Database |
Полный доступ |
Полный доступ |
| База данных PerformancePoint Services |
Полный доступ |
Простой в случае работы с набором панелей индикаторов, в настройки которых редко вносятся изменения. Полный доступ в случае интенсивного создания/изменения панелей индикаторов |
| База данных администрирования поиска |
Простой |
Простой. Настройка и внесение изменений, связанных с работой данной службы обычно непродолжительна по времени и выполняется однократно или небольшое кол-во раз. Более рационально выполнять полное резервное копирование базы данных после завершенных блоков настроек, изменений схемы поиска |
| База данных отчетов аналитики |
Простой |
Простой, если анализ результатов поиска и интеллектуальная адаптация выдачи результатов, предложений поиска не является критичными. Полный доступ, если поиск по порталу и его постоянная персонализированная работа являются критичными для бизнеса |
| База данных обхода |
Простой |
Простой. Восстановление этой базы из резервной копии или посредством мастера восстановления чаще всего будет намного дольше в сравнении со сбросом индекса и полным обходом контента |
| База данных ссылок |
Простой |
Простой, если анализ результатов поиска и интеллектуальная адаптация выдачи результатов, предложений поиска не является критичными. Полный доступ, если поиск по порталу и его постоянная персонализированная работа являются критичными для бизнеса |
| База данных Secure Store |
Полный доступ |
Простой. Настройка и внесение изменений, связанных с работой данной службы обычно непродолжительна по времени и выполняется однократно или небольшое кол-во раз. Более рационально выполнять полное резервное копирование базы данных после завершенных блоков настроек. |
| База данных приложения-службы состояний |
Полный доступ |
Простой. Ввиду того, что эта база данных обеспечивает хранение временных состояний для форм InfoPath, веб-частей службы Visio и не предназначена для продолжительного хранения этой информации. Корректность данных в этой базе имеет значение на момент просмотра пользователем конкретной формы InfoPath или Visio-диаграммы посредством веб-части. |
| База данных сбора данных об использовании и работоспособности |
Простой |
Простой или Полный доступ. Зависит от требований к допустимому для организации уровню потери данных. |
| База данных профилей |
Простой |
Простой, если нет бизнес-критичного функционала, работа которого требует работы с самыми актуальным данными о профилях пользователей Полный доступ, если ситуация обратная. |
| База данных синхронизации профилей |
Простой |
Простой, если время восстановления занимает меньше времени в сравнении с перенастройкой подключений и выполнением полной синхронизации профилей Полный доступ, если ситуация обратная |
| База данных социальных тегов |
Простой |
Простой, если работа с социальным контентом не является бизнес-критичным функционалом Полный доступ, если ситуация обратная |
| База данных Word Automation |
Полный доступ |
Полный доступ |
Количество дисков
В идеале на SQL-сервере рекомендуется иметь шесть дисков для размещения следующих файлов:
- Файлы данных базы данных tempdb;
- Файл журналов транзакций базы данных tempdb;
- Файлы данных баз данных SharePoint;
- Файлы журналов транзакций баз данных SharePoint;
- Операционная система;
- Файлы других приложений.
Подготовка дисковой подсистемы
SharePoint использует SQL-сервер для хранения своих данных, который имеет свои особенности хранения данных. В связи с этим подготовка дисковой подсистемы как на физическом, так и на логическом уровнях, учитывающие эти особенности, будет оказывать огромное влияние на конечную производительность корпоративного портала.
Данные, которые хранит Microsoft SQL Server, разбиваются на страницы размером по 8 КБ, которые в свою очередь группируются в так называемые экстенты (extent) размером по 64 КБ. Подробнее об этом можно узнать здесь. В соответствии с этим настройка дисковой подсистемы заключается в обеспечении целостного размещения экстента на всех физических и логических уровнях дисковой подсистемы.
Первое с чего следует начать – это инициализация RAID. При этом массив, на котором будут располагаться базы данных должен иметь размер страйпа (stripe size) кратный 64 КБ, предпочтительнее если это будет именно 64 КБ.
Выравнивание разделов жёсткого диска или твердотельного накопителя SSD
Процедура выравнивания файловой системы относительно физического её размещения на дисковом массиве имеет очень важное значение при рассмотрении вопроса повышения производительности работы SQL-сервера. Подробно она описана здесь. На любом жёстком диске или SSD первые 63 сектора по 512 байт зарезервированы для размещения файлов, которые создаются в процессе установки операционной системы или при выполнении операций управления дисками, а также с помощью специальных программ — менеджеров разделов жёсткого диска. Суть процедуры выравнивания заключается в подборе такого начального смещения (starting partition offset), при котором в одном страйпе дискового массива умещалось бы целое число кластеров файловой системы. Иначе возможна ситуация, при которой для произведения операции считывания одного кластера данных файловой системы необходимо будет выполнить две операции физического чтения с дискового массива, что в значительной степени ухудшает производительность дисковой подсистемы (потеря в производительности может составлять до 30%). В случае твердотельного накопителя потери производительности будут несколько ниже, но он быстрее выработает свой ресурс ввиду более частых операций чтения-записи.
На иллюстрации ниже отражены особенности выполнения операций чтения/записи для невыравненных разделов на примере страйпа в 64 Кб.
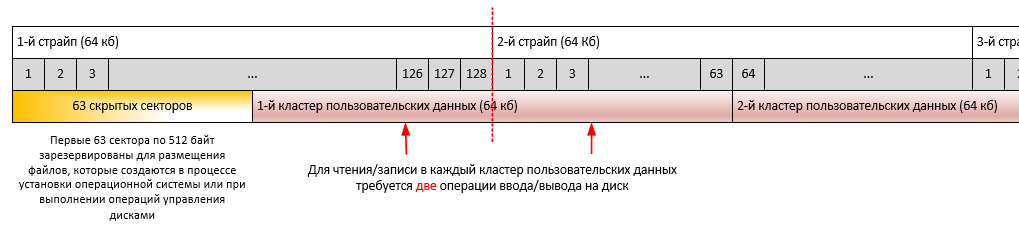
На иллюстрации ниже отражены особенности выполнения операций чтения/записи для выравненных разделов на примере страйпа в 64 Кб.
По умолчанию в Windows Server 2008/2012 смещение разделов составляет 1024 Кб, что хорошо коррелируется с размером страйпов на дисках в 64 Кб, 128 Кб, 256 Кб, 512 Кб и 1024 Кб.
В случае случаях настройки операционных систем из образов, использования различного программного обеспечения для управления разделами дисков могут возникнуть ситуации, связанные с нарушением выравниваний разделов. В связи с этим рекомендуется перед установкой SQL-сервера в качестве дополнительной страховки выполнять перепроверку корреляций, описание которых приведено в следующем разделе.
Важные корреляции: Partition Offset, File Allocation Unit Size, Stripe Unit Size
Partition Offset
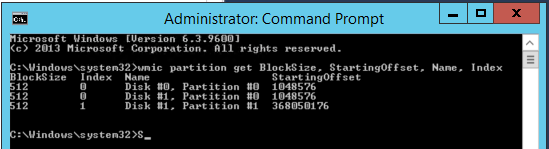
Наиболее правильный метод проверки смещения разделов для базовых дисков, — использование утилиты командной строки wmic.exe:
wmic partition get BlockSize, StartingOffset, Name, Index
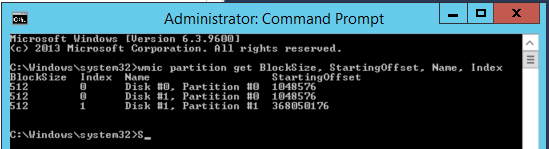
Для проверки выравнивания разделов для динамических дисков необходимо воспользоваться diskdiag.exe (описание работы с нею приведено в разделе «Dynamic Disk Partition Offsets»).
Stripe Unit Size
В ОС Windows нет стандартных средств определения размера минимального блока данных для записи на диск (stripe unit size). Значение этого параметра необходимо выяснять из документации вендора на жесткий диск или у SAN-администратора. Чаще всего показатели Stripe Unit Size составляют 64 Кб, 128 Кб, 256 Кб, 512 Кб или 1024 Кб. В рассмотренных ранее примерах использовалось значение в 64 Кб.
File Allocation Unit Size
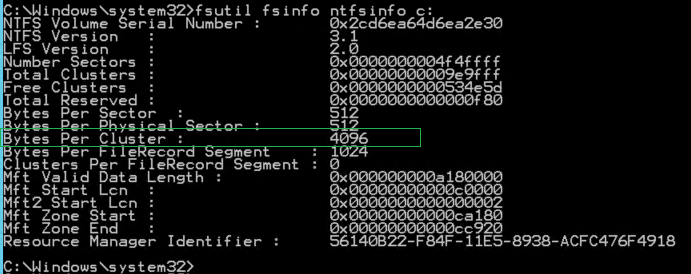
Для определения значения данного показателя необходимо использовать следующую команду отдельно для каждого из дисков (Значение свойства Bytes Per Cluster):
fsutil fsinfo ntfsinfo c:
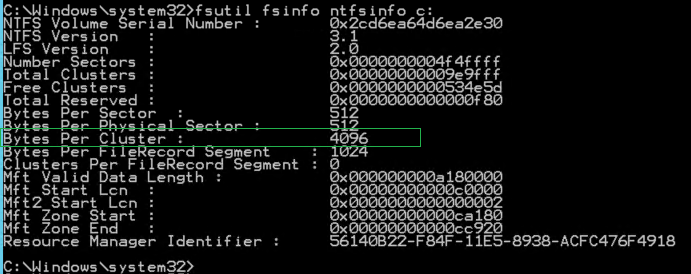
Для разделов, на которых хранятся файлы данных и файлы журналов транзакций SQL Server значение показателя должно быть 65,536 байт (64 Кб). См. «Оптимизация хранения данных на уровне файловой системы».
Две важных корреляции, в соблюдение которых являются основой оптимальной производительности ввода/вывода на диск. Результаты вычислений для следующих выражений должны составлять целое число:
- Partition_Offset ÷ Stripe_Unit_Size
- Stripe_Unit_Size ÷ File_Allocation_Unit_Size
Наиболее важной является первая корреляция.
Пример невыравненных значений. Смещение раздела (Partition offset) равно 32,256 bytes (31.5 Кб) и размер минимального блока записи данных на диск составляет 65,536 bytes (64 Кб). 32,256 bytes/65,536 bytes=0.4921875. Результат деления не является целым числом, в итоге имеем не выравненные значения Partition_Offset и Stripe_Unit_Size.
Если же смещение раздела (Partition offset) равно 1,048,576 байт (1 Мб), а размер минимального блока записи данных на диск составляет 65,536 байт (64 Кб), то результат деления равен 8, — целое число.
Оптимизация хранения данных на уровне файловой системы
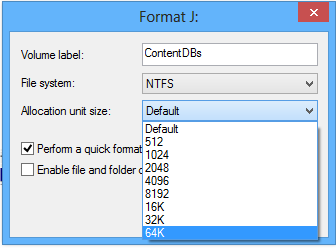
Следующим уровнем, на котором следует организовать оптимальное хранение экстентов, является файловая система. Оптимальными настройками здесь являются файловая система NTFS с размером кластера 65,536 байт (64 КБ). В связи с этим перед инсталляцией SQL-сервера настоятельно рекомендуется выполнить форматирование дисков и задать размер кластера в 65,536 байт (64 Кб) вместо 4096 байт (4Кб) по умолчанию.
Проверить текущие значения для диска можно при помощи следующей команды:
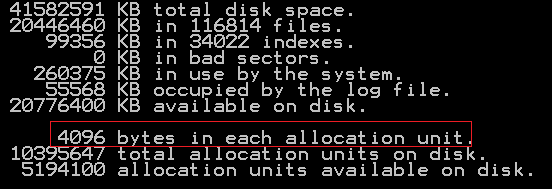
chkdsk c:
Пример вывода результата:
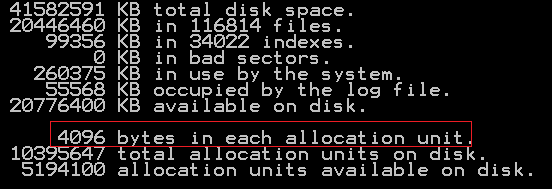
В представленном примере размер кластера равен 4096 байт/1024 = 4 Кб, что не соответствует рекомендациям. Для изменения придется выполнить переформатирование диска. Установку размера кластера можно выполнить в ходе настройки параметров форматирования диска средствами операционной системы Windows:
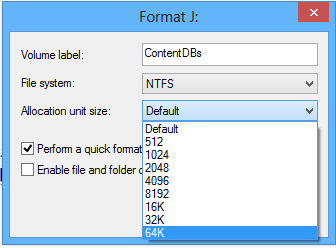
После этого убедиться в том, что размер кластера теперь соответствует рекомендациям (65536 байт/1024 = 64 кб):

Ранжирование дисков на основе данных о скорости чтения/записи
При проектировании размещения файлов системных баз данных SQL-сервера и баз данных SharePoint важное значение будет иметь оптимальность выбора дисков с учетом их ранга, построенного на основе информации о скоростях чтения/записи.
Для тестирования и определения точных данных о скорости чтения/записи файлов с произвольным доступом и с последовательным доступом можно воспользоваться программным обеспечением, аналогичным CrystalDiskMark (например, SQLIO). Обычно приложение позволяет ввести базовые параметры тестирования, как минимум:
- Количество тестов. Тестов должно быть несколько для получения более точного среднего значения.
- Размер файла, который должен быть использован в ходе выполнения тестов. Рекомендуется установить значение, превышающее объем оперативной памяти сервера, чтобы избежать использование только кэша. Кроме того, полученные цифры позволят получить статистику по выполнению обработки файлов больших размеров, что является актуальным для многих корпоративных порталов с интенсивной совместной работой пользователей над контентом.
- Имя диска, на который будут выполняться операции чтения/записи;
- Список тестов, которые необходимо выполнить.
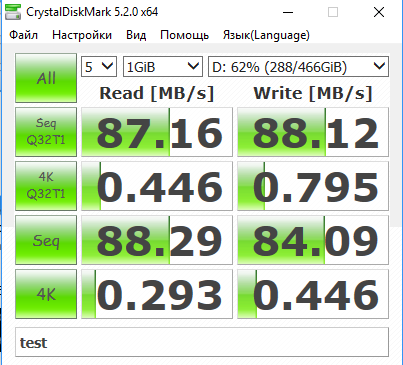
Ниже приведен пример полученных результатов выполнения тестов:
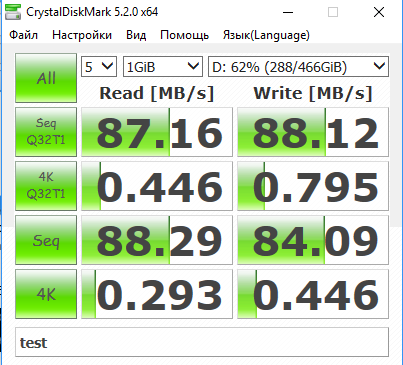
Ниже приведено описание содержания выполняемых тестов:
- Seq Q32 – скорость выполнения чтения/записи в файлы с последовательным доступом. Для SQL-сервера это такие операции, как резервное копирование, сканирование таблиц, дефрагментация индексов, чтение/запись файлов транзакций.
- 4K QD32 – скорость выполнения большого кол-ва случайных операций чтения/записи с данными малых размеров (4 Кб) в один и тот же момент времени. Результаты теста позволяют судить о показателях диска при выполнении транзакций в ходе работы OLTP-сервера, имеющего высокую загрузку.
- 512K — скорость выполнения большого кол-ва операций чтения/записи с данными больших размеров (4 Кб) в один и тот же момент времени. Результаты этого теста можно не учитывать, т.к. к работе SQL-сервера как такового отношения не имеют.
- 4K – скорость выполнения небольшого кол-ва случайных операций чтения/записи с данными малых размеров (4 Кб) в один и тот же момент времени. Результаты теста позволяют судить о показателях диска при выполнении транзакций в ходе работы OLTP-сервера с небольшой загрузкой.
Отметим, что в тестах используется размер единицы записи в 4 Кб, что не полностью соответствует реальной схеме хранения данных SQL-сервером и работе со страницами в 8 кб эктентами в 64Кб. При выполнении нет цели обеспечить абсолютное соответствие полученных результатов реальным данным о тех же операциях, выполняемых SQL-сервером. Основная конечная цель – ранжирование дисков по скорости выполнения операций чтения/записи и получение итоговой таблицы.
Для быстрого принятия решения в ходе инсталляции SQL-сервера, конфигурирования параметров размещения файлов баз данных будет полезным оформить результаты проведения тестирований в виде таблицы отдельно по каждому виду тестов, шаблон которой показан ниже:
| Диски с сортировкой по скорости выполнения операций чтения/записи от самого быстрого к самому медленному <Название теста> | |||
|---|---|---|---|
| 0 | I: | 20GB | VHD фиксированного размера |
| 1 | H: | 20GB | VHD фиксированного размера |
| 2 | G: | 50GB | |
| 3 | F: | 200GB | |
| 4 | C: | 80GB | Операционная система |
| 5 | E: | 2TB | |
| 6 | D: | 100GB |
Как интерпретировать результаты тестов CrystalDiskMark?
Для магнитных дисков (отдельных или в составе RAID), последовательные операции operations (тест Seq Q32) часто превышают результаты других тестов в 10x-100x раз. Эти метрики часто зависят от способа подключения к хранилищу. Необходимо помнить о том, что кол-во Мб/с, заявляемые вендорами – это теоретические ограничения. На практике они обычно меньше заявляемых на 5-20%.
Для твердотельных дисков разница между скоростью последовательных и произвольных операций чтения/записи не должны сильно отличаются друг от друга, как правило не более чем в 2-3 раза. На скорость будут влиять методы подключения, такие как 3Gb SATA, 1Gb iSCSI, or 2/4Gb FC.
Если сервер загружается с локального диска и хранит данные SQL-сервера на другом диске, в план тестирования также необходимо включать оба эти диска. Сравнение показателей тестов CrystalDiskMark диска, на котором хранятся переменные, данные с показателями диска, на котором установлена операционная система, могут продемонстрировать преимущество в производительности второго. В такой ситуации системному администратору необходимо проверить настройки диска или хранилища SAN на предмет корректности и получения оптимальных показателей производительности.
Расстановка приоритетов при выборе дисков
Информация о том, для каких целей используется портал, позволяет корректно расставить приоритеты при выборе дисков для хранения баз данных SharePoint.
Если корпоративный портал пользователями используется главным образом для чтения контента и не наблюдается активный ежедневный прирост контента (например, внешний сайт компании), наиболее производительные диски необходимо выделить под хранение данных, выделив под хранение файлов журналов транзакций менее производительные:
| Скорость/Сценарий использования | Существенно преобладание просмотра контента над его редактированием (внешний веб-сайт) |
|---|---|
| Наибольшая производительность | Файлы данных и файлы журналов транзакций базы данных Tempdb |
| ... | Файлы баз данных |
| ... | Файлы данных службы поиска за исключением базы данных администрирования |
| Наименьшая производительность | Файлы журналов транзакций баз данных контента SharePoint |
Если корпоративный портал используется для организации совместной работы пользователей, которые ежедневно активно загружают десятки документов, приоритеты будут другими:
| Скорость/Сценарий использования | Преобладание редактирования контента над его чтением (внешний веб-сайт) |
|---|---|
| Наибольшая производительность | Файлы данных и файлы журналов транзакций базы данных Tempdb |
| ... | Файлы журналов транзакций баз данных контента SharePoint |
| ... | Файлы данных службы поиска за исключением базы данных администрирования |
| Наименьшая производительность | Файлы данных баз данных контента |
Рекомендации по типам дисков для хранения баз данных для фермы SharePoint
Рекомендации по выбору диска для tempdb
Низкая скорость выполнения операций чтения/записи для системной базы данных tempdb SQL-сервера серьезно влияет на общую производительность фермы SharePoint, как следствие на производительность корпоративного портала. Лучшей рекомендацией может стать использование RAID 10 для хранения файлов этой базы данных.
Рекомендации по дискам для интенсивно использующихся баз контента
Для сайтов, предназначенных для совместной работы или выполнения большого объема операций обновления, необходимо обратить особое внимание на выбор дисков для хранения файлов баз контента SharePoint. необходимо учесть следующие рекомендации:
- Размещение файлов данных и журналов транзакций для баз контента на разных физических дисках
- Учесть в проектировании портальных решений рост размеров контента. Наиболее оптимальным является поддержка размера каждой отдельной базы контента до 200 ГБ.
- Для интенсивно использующихся баз контента SharePoint рекомендуется использовать несколько файлов данных, размещая их на отдельных дисках. Во избежание внезапных системных сбоев в работе баз данных настоятельно рекомендуется не использовать настройку ограничения размера баз данных.
Расчет ожидаемого размера базы данных контента
Общая формула расчета ожидаемого размера базы данных контента:
((D*V)*S)+(10Kb*(L+(V*D))), где:
- D – кол-во документов с учетом личных сайтов, документов и страниц в библиотеках, прогноза по увеличению кол-ва в ближайший год;
- V – кол—во версий документов;
- S – средний размер документов (если возможно выяснить);
- 10 Kb – константа, ожидаемое SharePoint 2013 кол-во метаданных для одного документа;
- L – ожидаемое кол-во элементов списков с учетом прогноза по увеличению кол-ва в ближайший год.
Необходимо учитывать дополнительные расходы по хранению:
- Ведение аудита, время хранения данных аудита + прогнозы по росту данных аудита;
- Корзина, время хранения данных в корзине сайта и коллекции сайтов.
Рекомендации по выбору RAID
Не смотря на то что RAID 5 имеет лучшие показатели в разрезе производительность/стоимость, для баз данных SharePoint настоятельно рекомендуется использовать RAID 10, особенно в случае активного использования корпоративного портала для совместной работы пользователей. RAID 5 имеет не очень высокие показатели скорости записи на диск.
Оптимизация передачи данных по сети
Необходимо убедиться в том, что между серверами SQL и SharePoint настроено высокоскоростное соединение.
Выделенные сетевые адаптеры и их объединения в группы
Первым шагом для повышения производительности сетевого обмена данными на каждом из серверов фермы SharePoint рекомендуется установить по два сетевых адаптера, один из которых выделен для передачи трафика между SQL и SharePoint, а второй под взаимодействие с клиентскими запросами.
Инсталляция серверов SQL и SharePoint на базе Windows Server 2012 и использование функциональной возможности объединения адаптеров в группу даст дополнительные преимущества и может стать вторым серьезным шагом в оптимизации конфигурационных настроек под SharePoint:
- Отказоустойчивость на уровне сетевого адаптера и, соответственно, сетевого трафика. Выход из строя сетевого адаптера группы не приводит к потери сетевого соединения, сервер переключает сетевой трафик на работоспособные адаптеры группы.
- Агрегирование полосы пропускания адаптеров, входящих в группу. При выполнении сетевых операций, например, копирования файлов, система потенциально может задействовать все адаптеры группы, повышая производительность сетевого взаимодействия.
Более подробно о настройке объединения адаптеров в группу можно прочитать здесь.
Согласно требованиям к программному обеспечению, ферма SharePoint может быть развернута на базе следующих операционных систем:
- 64-разрядный выпуск Windows Server 2008 R2 с пакетом обновления 1 (SP1) Standard, Enterprise или Datacenter
- 64-разрядный выпуск Windows Server 2012 Standard или Datacenter
- С выходом первого пакета обновления для Microsoft SharePoint Server 2013 стала доступна установка серверов SharePoint 2013 на базе 64-разрядного выпуска операционной системы Windows Server 2012 R2.
Scalable Networking Pack
Еще в 2007 году в системе Windows Server 2003 SP2 появился набор функций, управляющих производительностью сети и известных под общим названием Scalable Networking Pack (SNP). Данный пакет использовал аппаратное ускорение при обработке сетевых пакетов для обеспечения более высокой пропускной способности. В состав пакета SNP входят функции, известные как Receive Side Scaling (RSS), TCP/IP Chimney Offload (иногда ее называют TOE) и Network Direct Memory Access (NetDMA). Этот функционал операционной системы, позволяющий передать нагрузку по обработке пакетов TCP/IP от процессора на сетевую карту.
Из-за проблем с пакетом SNP в системе Server 2003 SP2 ИТ-сообщество быстро взяло за правило отключать эти функции. Для системы Server 2003 такой подход имел смысл. Но в системах Server 2008, Server 2008 R2 и более поздних версиях операционной системы отключение данных функций зачастую может привести к снижению производительности сети и пропускной способности сервера. Эти функции весьма стабильны в системе Server 2008 R2 (с пакетом SP1 или без него). К сожалению, отключение функций как один из первых шагов в решении сетевых проблем по-прежнему является очень распространенной практикой устранения неполадок, при том что многие проблемы таким образом не решаются.
Receive Side Scaling
Технология RSS предоставляет сетевому адаптеру возможность распределения нагрузки сетевой обработки между несколькими ядрами в многоядерных процессорах.
В случае отключения использования механизма RSS, система может понести значительные потери в производительности, что приведет к снижению общей нагрузки и количества сетевых операций, которые способен обработать каждый сервер. Такая ситуация может привести к росту затрат, связанных с покупкой дополнительного оборудования, которое на самом деле не требуется, и с дополнительными расходами на инфраструктуру, сопровождающими приобретение дополнительного оборудования.
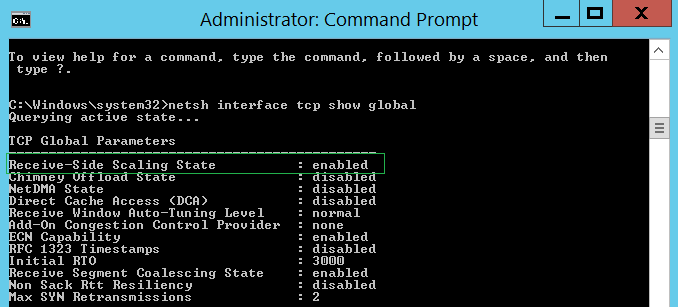
По умолчанию в системах Server 2008 R2 и более поздних версиях технология RSS включена. Вы можете узнать, включена глобально технология или нет, анализируя результат следующей команды:
netsh interface tcp show global
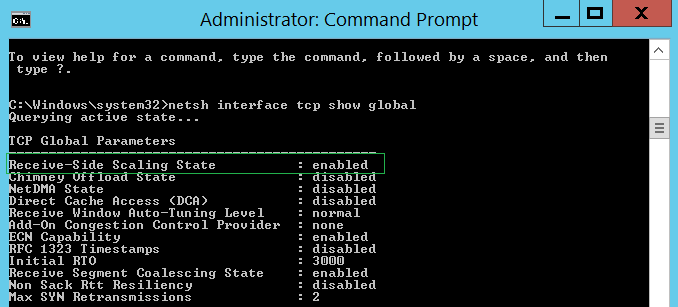
Необходимо убедиться в том, что использование технологии RSS также включено и на отдельных сетевых адаптерах через их дополнительные свойства или настройки конфигурации:

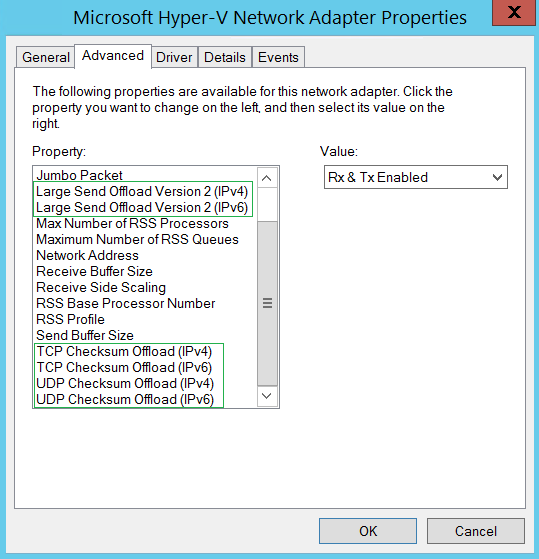
RSS также зависит от разгрузок сетевого адаптера, известных под названиями TCP Checksum Offload, IP Checksum Offload, Large Send Offload и UDP Checksum Offload (для протоколов IPv4 и IPv6). Так что, если они были отключены на сетевом адаптере, технология RSS не будет для него использоваться.

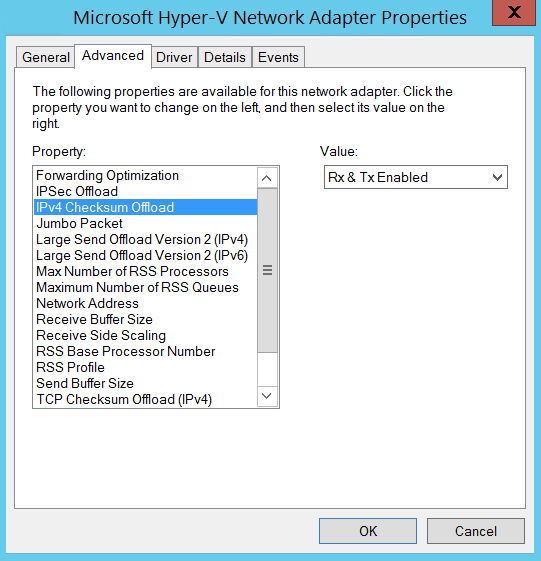
Кроме того, некоторые сетевые адаптеры имеют дополнительные параметры, управляющие количеством процессоров, применяемых в механизмах RSS, а также числом очередей RSS.
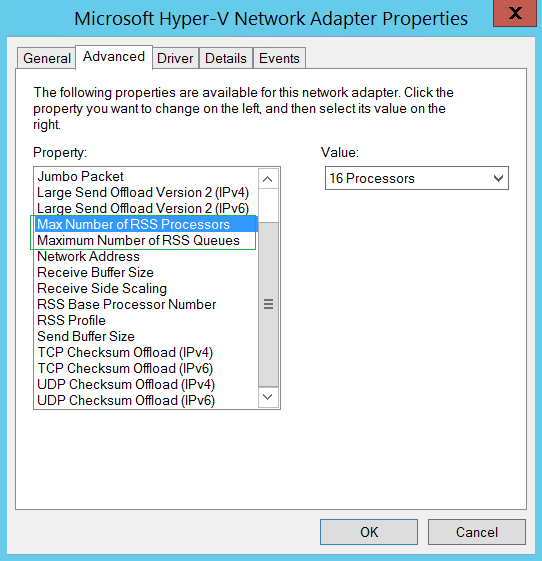
Распространенной ошибкой является установка малого количества процессоров RSS по сравнению с числом процессоров на сервере. Каждый адаптер и производитель имеют свои рекомендации по настройке, поэтому необходимо смотреть документацию производителя, чтобы определить оптимальные настройки для конкретной среды и рабочей нагрузки.
TCP/IP Chimney Offload
Технология TCP Chimney Offload (часто называемая производителями TCP/IP Offloading или более кратко, — TOE) передает обработку трафика TCP от процессора компьютера сетевому адаптеру, который поддерживает TOE. Передача TCP обработки с центрального процессора на сетевой адаптер может освободить процессор для выполнения функций, больше связанных с работой приложений. TOE может разгрузить обработку как для TCP/IPv4, так и для TCP/IPv6 соединений, если сетевой адаптер это поддерживает.
Из-за задержек, связанных с передачей обработки TCP/IP сетевому адаптеру (более подробно можно прочитать об этом здесь), технология TOE максимально эффективна для приложений, которые устанавливают долговременные соединения и передают большие объемы данных. Серверы, выполняющие долговременные соединения, такие как репликация базы данных, работа с файлами или выполнение функций резервного копирования, являются примерами компьютеров, которые могут получить выгоду от использования TOE.
Серверы с недолгими соединениями, такие как веб-серверы SharePoint фактически ничего не выигрывают от данной технологии. В связи с этим рекомендуется отключить использование TCP Chimney Offload.
Проверить глобальные настройки TCP можно при помощи следующей команды:
netsh interface tcp show global
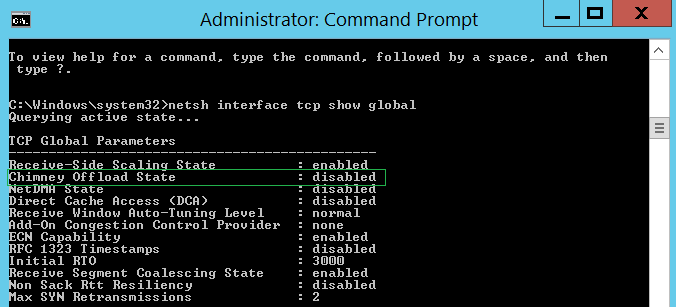
Отключить использования TOE для TCP можно при помощи команды:
netsh int tcp set global chimney=disable
Перед принятием решения об отключении использования TOE рекомендуется предварительно взглянуть на статистику использования TOE для TCP с помощью команды:
Netsh netsh interface tcp show chimneystats
Отключить ТОЕ для IP можно при помощи следующей команды
netsh int ip set global taskoffload=disabled
Проверить глобальные настройки IP при помощи другой команды:
netsh int ip show global
Network Direct Memory Access
NetDMA – достаточно интересная функция. Смысл её применения есть тогда, когда у Вас не поддерживается отключен TOE и необходимо ускорить обработку сетевых подключений. NetDMA позволяет копировать без участия CPU данные из приемных буферов сетевого стека сразу в буферы приложений, чем снимает с CPU данную задачу.
Для того, чтобы использовать NetDMA, необходимо оборудование, которое поддерживает этот функционал, – в случае Windows это процессор с поддержкой технологий семейства Intel I/O Acceleration Technology (I/OAT). Включение NetDMA на оборудовании AMD эффекта, увы, не принесёт.
Отметим, что TOE и NetDMA являются взаимоисключающими, эти функции не могут быть одновременно включены в системе.
Для включения NetDMA в Windows 2008 R2 можно использовать следующую команду:
netsh interface tcp set global netdma=enabled
Проверку состояния функционала можно выполнить при помощи другой команды:
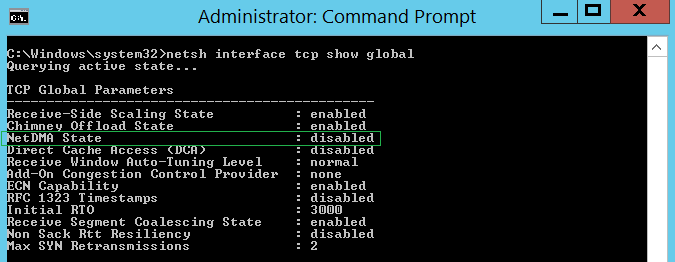
netsh interface tcp show global
Настройки SNP по умолчанию
Windows Server 2008 R2
| Параметр | Значение по умолчанию |
|---|---|
| TCP Chimney Offload | automatic |
| RSS | enabled |
| NetDMA | enabled |
«Automatic» для TCP Chimney Offload означает, что функция будет включена, если для сетевого адаптера включена настройка «TCP Chimney Offload» в сочетании с использованием высокоскоростного подключения, такого 10 GB Ethernet.
Windows Server 2012, Windows Server 2012 R22
| Параметр | Значение по умолчанию |
|---|---|
| TTCP Chimney Offload | disable |
| RSS | enabled |
| NetDMA | Не поддерживается |
