В DataStax работают над созданием производительной модели данных для Apache Cassandra. В чём заключается эта работа и как её делать правильно, на конференции Cassandra Day Russia 2021 рассказал Артём Чеботко, Solutions Architect в DataStax.

Речь пойдет о разработке производительной модели данных для Apache Cassandra. Над этой задачей я долгое время работаю в DataStax. Есть довольно большое количество проектов и use cases, в которых нужна была производительная модель данных. Мы поговорим о методологии и как это сделать правильно.
Начнем с более простых вещей. Обсудим, как Cassandra хранит данные, чтобы понимать, на что нужно особенно обращать внимание. Потом обсудим методологию. Здесь также есть 3 примера, о которых я хотел бы поговорить. Они разные, в них есть разные оптимизации, которые можно обсудить.
Как Cassandra хранит данные
Если вы уже использовали Cassandra или были на воркшопе, вы знаете, что есть KEYSPACE — это как схема всей базы данных. Внутри будут таблицы. Конечно, есть replication strategy, когда можно использовать несколько дата-центров и различные replication factors для каждого из них.

В данном примере у нас есть DC-WEST — один дата-центр с replication factor 3. И DC-EAST с replication factor 5. Все это на KEYSPACE. Далее все таблицы, которые мы создадим в KEYSPACE, будут использовать эту replication strategy.
Внутри KEYSPACE мы создаем таблицы. Вот пример Create Table — одна из них.

десь вроде как ничего необычного. Очень похожа на SQL: 4 колонки, 4 поля в этой таблице. Есть primary key — первичный ключ — который, однако, состоит из 2 ключей. Первый — year. Он в дополнительных скобках, это называется partition key, или ключ раздела. Второй — name. Это clustering key, или ключ кластеризации, ключ сортировки.
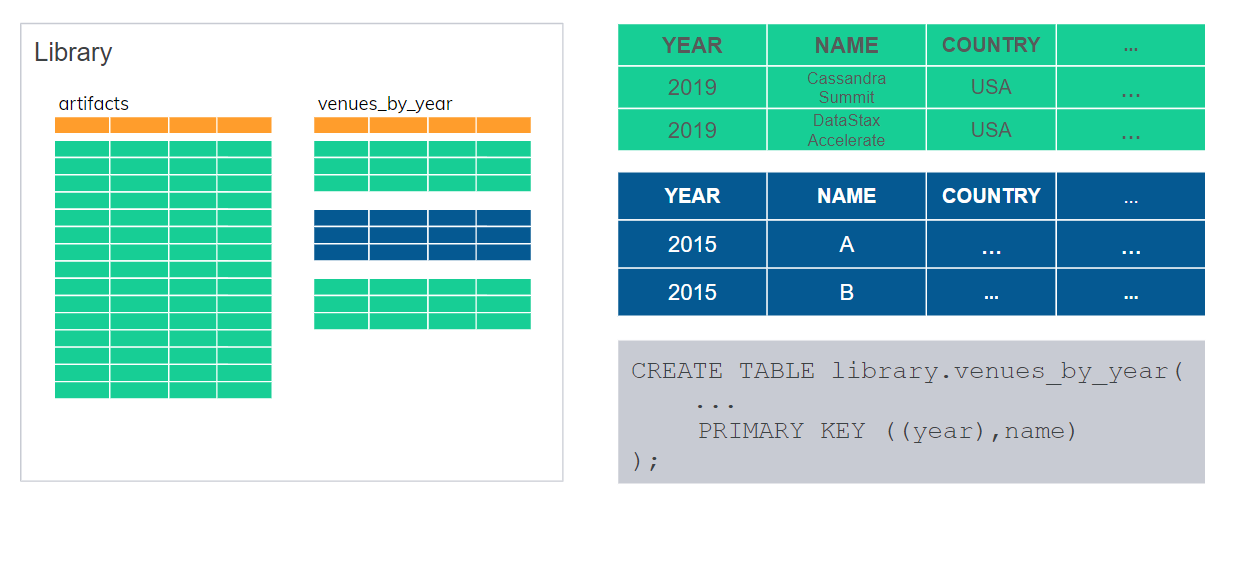
Partition key YEAR используется для того, чтобы разделить нашу таблицу на разделы. В каждом разделе может быть от одной и более строк. В данном случае YEAR является partition key. У нас получается несколько partition. Например, 2015 год определяет partition, и все строки для 2015 года будут храниться в одной partition. И где-то мы будем хранить их на кластере.
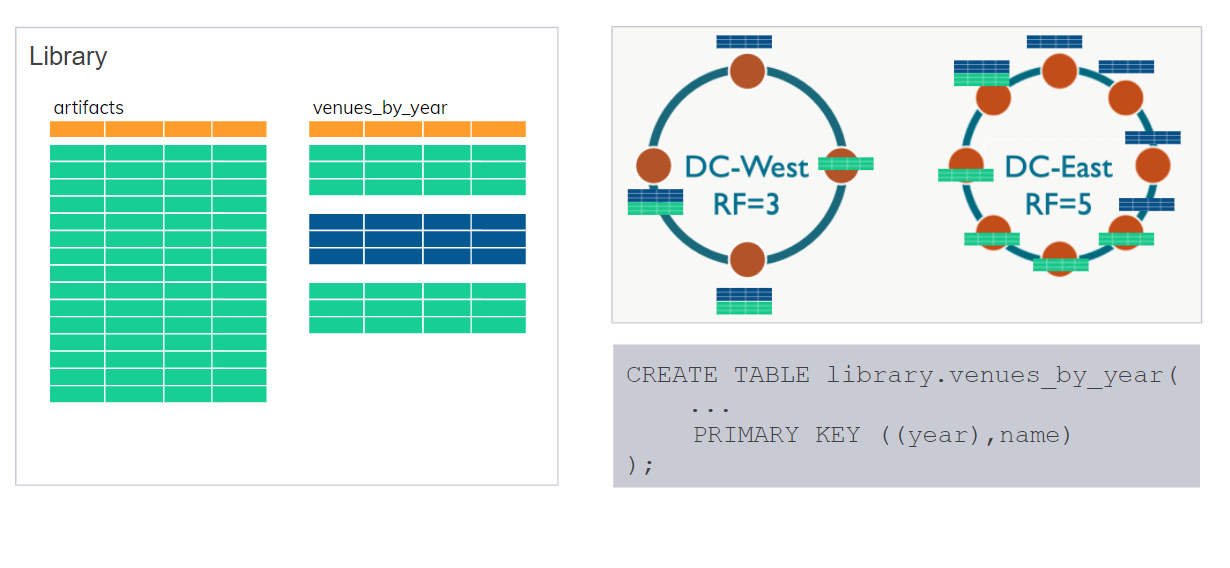
Как и где — Cassandra решает самостоятельно, автоматически и использует, опять же, replication factor. Допустим, синяя наша partition — в одном дата-центре есть 3 копии, в другом дата-центре есть 5 копий. Также и 1-я partition тоже будет 3 копии. На основе partition key Cassandra решает, какой сервер будет хранить эти данные, и также решает, какие реплики.
Мы увидели только что KEYSPACE, таблицу — это мы использовали Cassandra Query Language, который очень похож на Structured Query Language, SQL.
Поскольку мы будем определять схемы базы данных, быстро обсудим Create Table, а также запросы.

Здесь опять же важно отметить partition key, который обязательно, то есть primary key обязательно состоит из partition key и, возможно, дополнительно может быть clustering key. Делает большую разницу, если есть этот clustering key.
Колонки имеют типы данных, они могут быть статическими. Статическое не означает, что значение нельзя поменять. Это больше означает, что если в одном разделе у нас несколько строк, но все они должны иметь одно и то же значение для какой-то колонки, то мы ее объявляем статической. Статическая колонка описывает всю partition, а не отдельную строку в этой partition.
Далее у нас есть clustering order by — фактически мы говорим, как сортировать данные строки внутри partition, внутри одного раздела. Сортировка, конечно, возможна только на clustering key. Cassandra организует, непосредственно хранит данные в отсортированном виде. Поэтому, когда мы будем их оттуда доставать, никакой сортировки не будет происходить, так что это будет очень эффективная процедура.
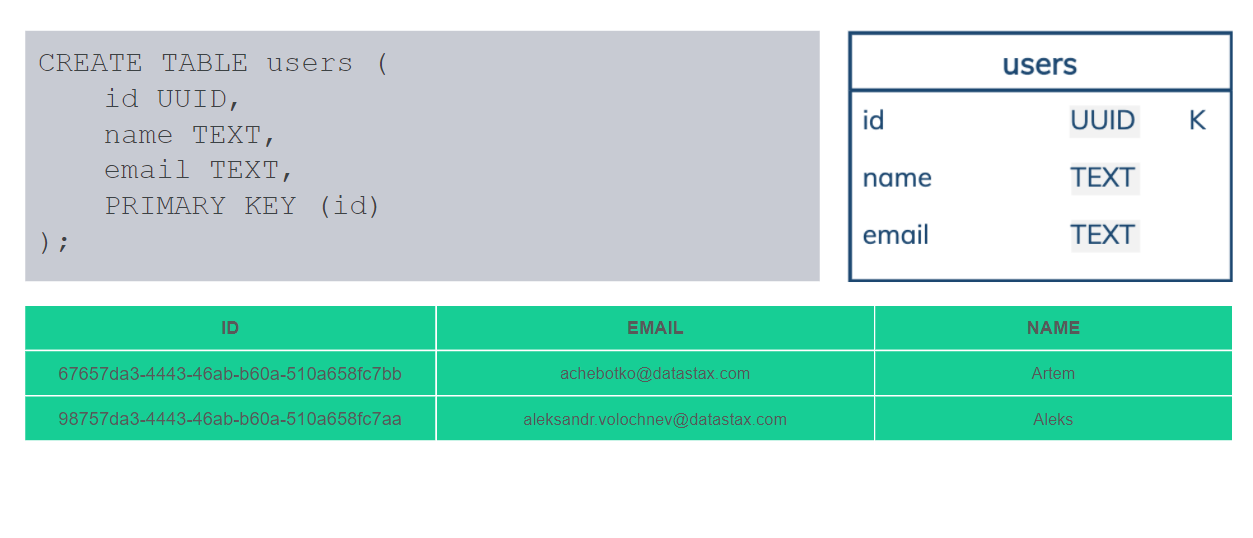
Два вида разделов, два вида partitions. Все зависит от того, какой у нас primary key. В данном случае у нас primary key состоит только из ID, и это обязательный partition key. Фактически в каждом partition будет только одна строка. Не может быть больше одной. Такие таблицы называются «Таблицы с разделами, в которых может быть только одна строка» — Single-Row Partitions. Это обычное дело для реляционной базы данных, обычное дело для Cassandra. Но есть еще также partitions с несколькими строками, больше 1. Мы называем их Multi-Row Partitions.
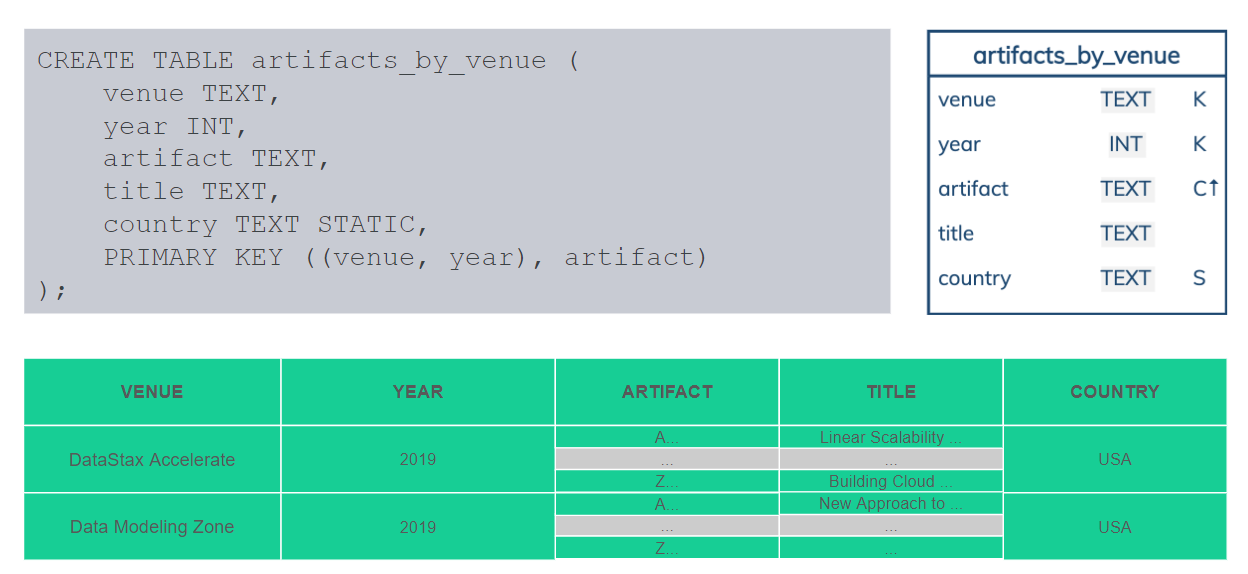
Как раз эти таблицы, в которых есть и partition key, и clustering key, они как раз являются одним из важнейших элементов в Cassandra, в ее схеме баз данных. Потому что мы можем фактически группировать данные и хранить их вместе. Потом также их запросом доставать вместе. Это является очень эффективным. Нам не нужно обращаться к 10 серверам, чтобы получить данные. Мы желательно их будем хранить в одной partition и будем доставать эту partition наиболее эффективным способом с одного сервера или с какой-то реплики.
В данном случае у нас композитный partition key. Venue и year — это как «конференция» и «год». Вот наша конференция DataStax Accelerate. И partition key определяет раздел. В разделе хранится много строк, и каждая строка идентифицируется артефактом — какой-то идентификатор презентации или статьи. Если есть дополнительный title, название презентации — это тоже будет часть обычных данных в строке. Они все разные.
А вот Country это пример статической колонки, где значение будет описывать больше partition, чем индивидуальные строки. Все эти артефакты были презентованы в одной и той же стране, потому что конференция была в этой стране.
Еще я хотел бы обратить внимание на визуализацию. Мы будем ее использовать. Что она означает? Название таблицы, 5 колонок, типы данных, также есть K — это partition key, С — clustering key, стрелка — ascending или descending, как мы отсортировали, в каком порядке — возрастающий или нет. S — статическая колонка.
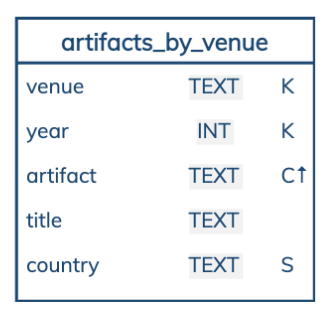
Два типа разделов, два типа таблиц. Также интересно посмотреть, как мы можем создавать запросы на CQL. Синтаксис очень похож на SQL: здесь есть select, from, where, group by, order by, limit. Есть allow filtering — это немножко другое.

Select — это проекция, from — указываем таблицу. Но в случае Cassandra только одна таблица. В запросе мы можем использовать только одну таблицу. Это значит, что у нас не будет join — соединений, union — объединений, intersection — пересечений. Никаких операторов, которые используют 2 аргумента и больше, не может быть. Это важно, потому что мы не сможем, допустим, делать join, соответственно, мы должны организовывать данные без join.
Оператор where — мы можем использовать только колонки, которые являются частью primary key. Непосредственно нам придется использовать partition key — и это будет для равенства. Также мы можем использовать — необязательно — clustering key, колонки, для равенства/неравенства. Также индексированные поля. Но индексация имеет определенные только use cases, они не очень распространенные, мы их не будем затрагивать здесь.
Group by также может быть на primary key колонках, но он нас не особо интересует сейчас.
Order by — это сортировка. Опять же Cassandra не будет сортировать данные, она их хранит в отсортированном виде. Либо мы их оттуда достаем в этом же виде, либо мы просто меняем. Мы читаем либо с начала этот раздел, либо с конца. Сортировка внутри каждого раздела. Не во всей таблице.
Limit — сколько мы хотим достать строк.
Аllow filtering — это фактически флаг, который разрешает нам сканировать всю таблицу. И это то, что мы не будем делать. Нельзя делать, потому что данные большие, они хранятся на кластере, и мы не хотим сканировать всю таблицу, потому что это будет очень неэффективный запрос.
Примеры запросов, которые мы можем использовать на этой таблице artefacts_by_venue.

Мы можем спросить все artefacts, где мы знаем venue чему-то равно, year чему-то равно, то есть partition key. Мы можем спросить partition key и clustering key — в данном случае равенство. Также можем неравенство на clustering key. Но заметьте: мы не можем пропустить partition key и сделать запрос только на clustering key.
Примеры того, что мы не можем сделать.

Эти запросы не будут работать, потому что мы не можем сделать запрос только на venue. Потому что надо использовать весь partition key, чтобы Cassandra могла решить, непосредственно где данные, на каком сервере хранятся. Нельзя пропустить в partition key, нельзя только на clustering key.
И предпоследние два мы используем venue, year — это partition key, но title не проиндексирован, он не часть primary key, мы не можем это делать. И нельзя просто на статической колонке типа Country. Много есть ограничений. Когда мы организовываем данные, когда моделируем и создаем схему, нам нужно учитывать эти ограничения.

Primary key является одним из важных элементов, на который нам придется обращать много внимания. Во-первых, он гарантирует уникальность строк, а также он состоит из partition key, который гарантирует уникальность partition и говорит о том, как будут данные распределены, будут ли у нас большие partition. Он влияет на это все.
И clustering key позволяет нам делать сортировку и неравенство (когда мы используем неравенство в предикатах и запросах). Конечно, у нас нет join, значит как-то нужно организовывать данные, чтобы они хранились все в нужном разделе, чтобы мы их оттуда доставали. Вы, наверное, уже слышали о денормализации, как это делать. Но мы не будем вдаваться в подробности в этой презентации.
Методология моделирования данных
Давайте поговорим о методологии — как моделировать данные правильно. В данном случае мы рассмотрим ее в общем, не сможем много вдаваться в детали, потому что нам не хватит времени. Но на примерах некоторые детали мы увидим.
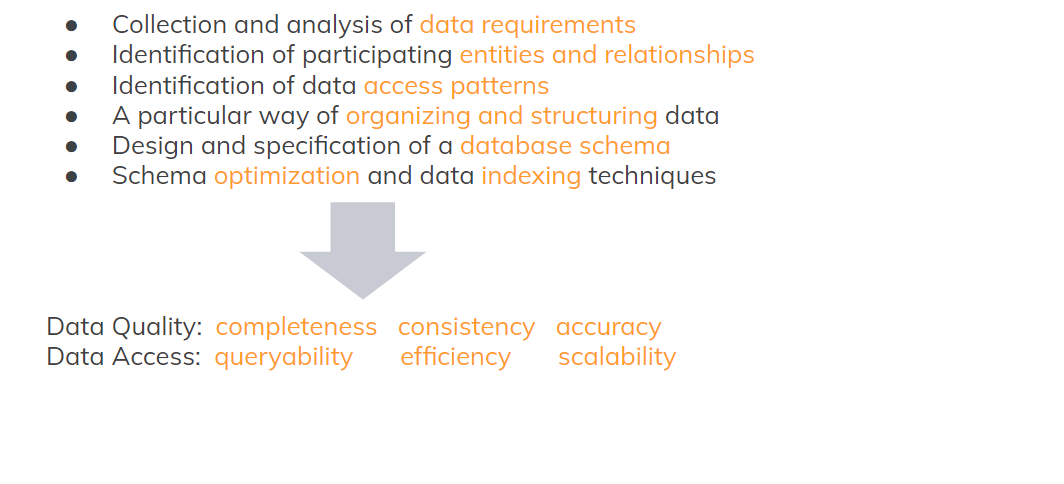
Моделирование данных — довольно сложный процесс. Его часто путают с созданием схемы базы данных. Схема — это фактически последний этап моделирования данных. Начинается все с того, чтобы понять — какие данные у нас вообще есть, какие к ним требования. Собрать примеры, если есть. Если нет — придется разговаривать с людьми, которые работают в этой области (не обязательно специалистами по моделированию). И собирать информацию о том, какие данные нужно.
Обычно это сущность, связи, фактические объекты и как они взаимодействуют. Нам нужно также понять, как мы будем использовать эти данные — access patterns я их называю. Это фактически шаблоны доступа к данным. Это, возможно, запросы, но это могут быть и транзакции, мутации и т. д. Эту информацию нам тоже нужно понять, потому что она будет определять, как наши данные будут храниться.
Потом мы уже можем думать о таблицах и каких-то оптимизациях — как это сделать более эффективно — и создавать уже схему на конечном этапе.
Конечно, модель данных имеет огромное значение для Cassandra для того, чтобы хранить данные в полном объеме и для согласованности (consistency) данных, и чтобы не было ошибок, чтобы мы могли их оттуда доставать запросами. Мы только что видели — join не поддерживаются. Эффективность, масштабированность имеют очень большое значение.
Поскольку процесс очень сложный, мы организовали его в методологию — взяли тулы, методы, модели и организовали их вместе, чтобы можно было повторять этот процесс для разных проблем. Разные проблемы моделирования, но процесс остается один и тот же.
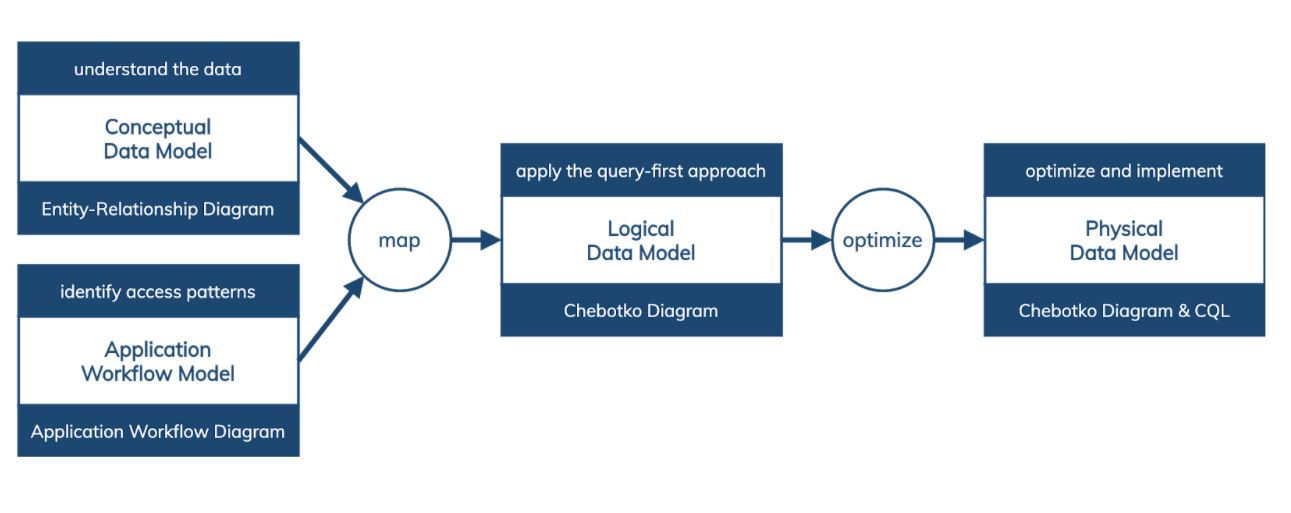
На самом высоком уровне у нас есть 4 цели:
- Нужно понять данные.
- Идентифицировать шаблоны доступа данных, то есть понять, как используются эти данные.
- Использовать эту информацию, чтобы создать логическую модель данных.
- Оптимизировать это все и получить конечную схему.
Результат решения этих четырёх задач будет равен четырём моделям:
- Conceptual Data Model.
- Application Workflow Model.
- Logical Data Model.
- Physical Data Model.
Каждую модель удобно представить каким-то образом: либо это Entity-Relationship Diagram (сущность-связь), Application Workflow Diagram (поток работ), Chebotko Diagram и Chebotko Diagram&CQL.
Увидеть эту модели и понять очень легко. Более сложно — как перейти от одной модели к другой.
Частый вопрос, который здесь возникает: «Что первично — создавать Conceptual Data Model или Application Workflow Model»? Обычно нужно это делать параллельно. Если сфокусироваться только на приложении, мы можем недостаточно понимать данные, чтобы даже те же запросы правильно и аккуратно сформировать и описать. Это процесс одновременный, скорее всего. Мы будем для начала смотреть, конечно, на концептуальную модель данных.
Вопрос: в каких случаях использование индексов можно не считать антипаттерном? И consistency level также, который применяют для получения данных от индексов?
Ответ: Мы пропустили индексы, потому что очень немного у них применений. Потому что они могут быть довольно неэффективными. Подумайте, почему. Почему обычные запросы эффективные? Потому что мы используем partition key, и Cassandra-координатор знает точно, какие реплики в нашем кластере. У нас может быть 100 нодов, а у нас replication factor 3, и по partition key мы знаем, что эти 3 реплики — у них есть данные. В случае secondary index мы можем не знать partition key, и нам придется спросить у всех 100 серверов, поэтому это неэффективно.
Когда это может быть эффективно?
- У нас есть partition key и индексированная колонка
- Мы можем позволить себе неэффективные запросы. Как правило, это не для OLTP-транзакций, то есть не для приложения в реальном времени, а для анализа данных. Анализ очень легко совместим с Cassandra, поскольку у нас есть несколько дата-центров. Автоматически данные копируются в них. В одном из дата-центров может быть кроме Cassandra — Spark, или еще какой-то фреймворк для анализа данных. Мы можем анализировать данные в том дата-центре только и никогда не повлиять на работу другого дата-центра, который работает, допустим, только с реальными данными.
И в consistency level разницы особо никакой. Фактически то же самое, что и для обычных запросов. Нет никаких особых исключений для индексов.
Это было небольшое отступление, индексы мы не используем, как правило.
Примеры моделирования данных
На DataStax Academy у нас много примеров, успеем обсудить 2. В конце каждого примера есть сценарий, в котором мы создаем эту базу данных. Здесь все в браузере, можете сами это сделать потом и изучить: понять, как эти запросы были созданы.
Интернет вещей
Первый пример — это Internet of Things или интернет вещей. Что там есть? Какие-то приборы, сенсоры, датчики. Может быть, у нас есть умный дом с термостатами, в которых есть сенсоры и которые, может быть, могут автоматически менять температуру и подстраиваться искусственным интеллектом. Могут быть какие-то системы безопасности, которые следят, открыта дверь или закрыта, система пожарной безопасности и т. д.
По ссылке вы можете прочитать более подробно.
Мы не будем создавать концептуальную модель данных, мы просто прочитаем существующую. Что она нам скажет о данных, с которыми нам придется столкнуться?
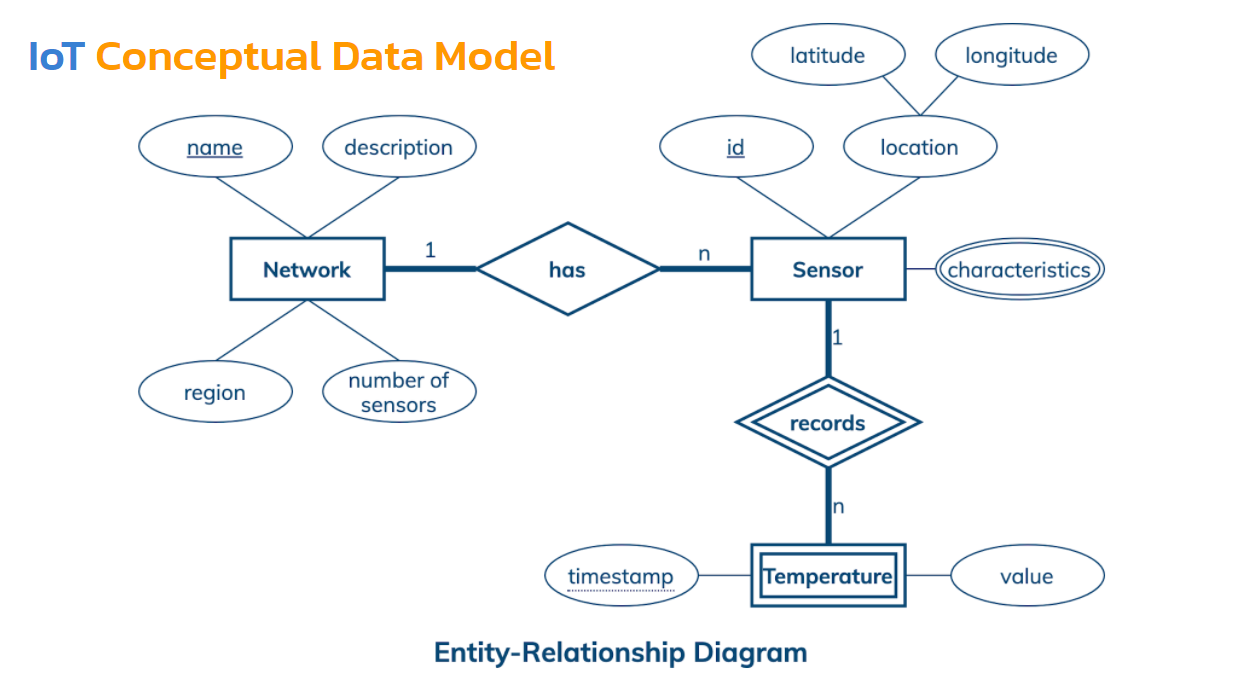
У нас есть сети, в которых содержатся какие-то датчики или сенсоры. Эти сенсоры записывают какие-то измерения — в данном случае температуру.
Также мы можем сказать, что в сети может существовать много сенсоров, но каждый сенсор должен принадлежать только одной сети. Сенсор может делать много измерений, но каждое измерение должно быть записано одним сенсором. Очень просто, но информация уже точная, легко ей с кем-то поделиться и понять.
Кроме этого у нас есть атрибуты, которые станут колонками в будущем. Некоторые из них подчеркнуты — это ключ, идентификатор. Имя сети — это идентификатор, оно уникально. Есть также описание, регион и другие атрибуты. У сенсора есть ID — это его идентификатор. Есть также местоположение, которое фактически состоит из координат — широта и долгота. Есть атрибут — двойная линия — означает, что может иметь множество значений, иметь разные характеристики: это может быть список, множество, карта в будущем. Но мы знаем, что можем хранить там множество значений.
Температура с двумя сплошными означает, что сущность слабая, у нее недостаточно атрибутов, чтобы сформировать ключ — идентифицировать уникально. Она берет один из атрибутов у сильной сущности, у сенсора. ID и timestamp вместе дают ключ-идентификатор для одного измерения. Частичный ключ — timestamp — подчеркнут здесь точечной линией.
Мы уже на самом деле покрыли больше половины всяких элементов, которые на диаграмме Entity-Relationship (сущность-связь), и изучить это не так сложно. Вот такие данные, которые мы будем хранить. Это один из самых простых примеров, который у нас есть.
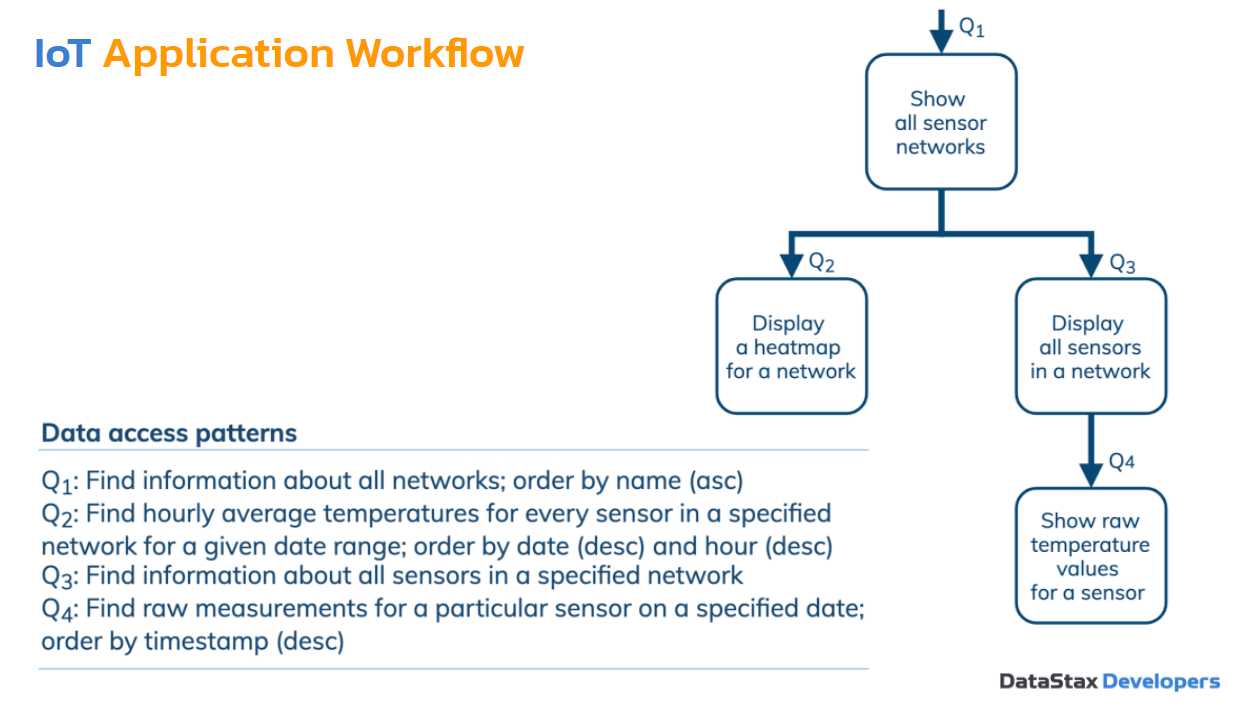
Application Workflow Model — это модель приложения. Это поток работ: сначала один шаг или процесс выполняется, потом следующий и следующий.
Обычно Application Workflow очень легко создать. Особых деталей нам не надо. Нас интересует последовательность. И второе: поскольку это приложение не просто какое-либо любое — это приложение, которое использует запросы. Оно основано на том, что оно что-то делает с данными, которые хранятся в базе данных. Оно непосредственно работает с базой данных. Практически на каждом шагу нам приходится использовать какой-либо запрос или data access pattern. Это может быть необязательно запрос, это может быть мутация или транзакция, batch.
У нас есть 4 шага, 4 процесса и 4 запроса в данном случае. Конечно, могут быть случаи, когда 1 шаг — несколько запросов. Какие у нас здесь запросы?
- Нам нужно найти информацию о всех сенсорных сетях.
- Нам нужно найти карту температур. Что это означает? Нам нужно найти среднюю температуру за каждый час для каждого сенсора в определенной сети за определенный период времени. Кажется, сложно. Еще нам потом надо будет отсортировать по дате и часу. Это самый сложный запрос.
- Третий запрос: найти информацию о всех сенсорах в сети.
- Четвертый: найти все измерения для определенного сенсора на определенную дату.
Мы имеем эти две модели. Методология определяет правила, как можно получить логическую модель данных. На чем основаны эти правила? В основном смотрим на запросы и решаем: для второго сложного запроса у нас есть сеть и даты. Но даты — это период времени: больше/меньше. Дату придется использовать как clustering key, а сеть может быть partition key. Кроме всего этого, мы храним там измерения. Если мы вернемся к измерениям, то мы видим, что там измерение определяется ID сенсора.
Посмотрим, что у нас получается в виде логической модели данных. Фактически мы заменили наши процессы таблицами, которые могут поддерживать запросы, о которых мы только что говорили в Application Workflow. Первый запрос — нам нужно достать все сети. Второй запрос — зная сеть и период времени, нам нужно достать все средние измерения за каждый час для каждого сенсора. Если вас интересует конкретное правило, как мы это сделали, есть шаблоны на DataStax Academy.
Далее sensors_bynetwork — это довольно легко. Network — это partition key, и каждый сенсор будет определяться отдельной строкой в этом partition. Temperatures by_sensor — зная сенсор и дату, мы сможем достать значение с определенным timestamp. Мы добавили его, потому что он + сенсор уникально идентифицирует одно измерение. Если мы случайно забыли timestamp поставить как clustering key, тогда у нас просто всего лишь одно значение. У нас будет таблица, где разделы будут хранить только одну строку. Это не подойдет.
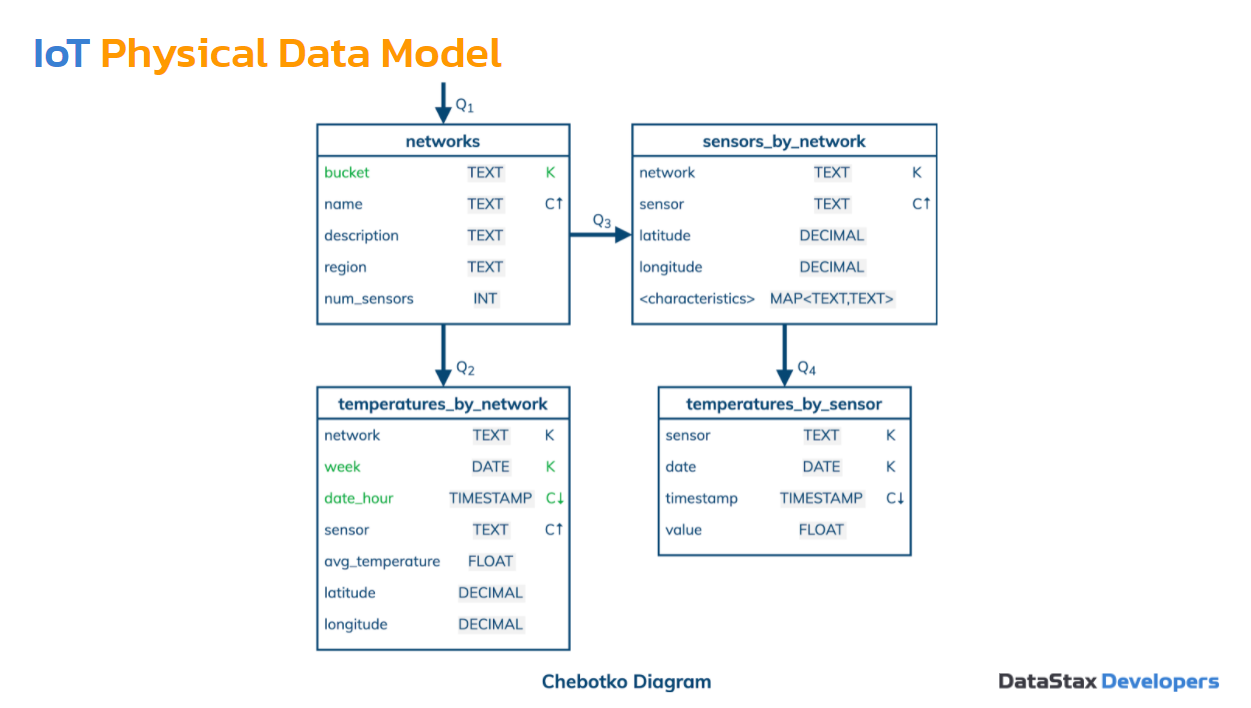
Физическая модель данных, как она меняется? Мы добавляем типы данных, что обычно очень легко. Наши характеристики стали картой — это более интересный здесь тип данных. Здесь мы использовали 3 разных оптимизации. Две из них особо интересны — они противоположны. В первой оптимизации мы добавили bucket — он становится partition key, а name — clustering key. Мы взяли много partition с логической модели и объединили их в одну. В этой таблице будет всего одна partition. Bucket — это суррогатная колонка, и она будет иметь одно и то же значение для всех строк, одну partition.
Наша задача: достать все networks — информацию о всех сетях. Это наиболее эффективно сделать, если мы достаем с partition.
Какая вторая оптимизация для второго запроса? Здесь мы добавили week — значение недели. Это может быть первым днем недели. Это дата как часть partition key. Мы делаем обратный процесс. Вместо того чтобы объединить много partition в одно, мы берем одну partition и разделяем ее на несколько. Для чего мы это сделали? Один из видов анализа логической модели данных — определить размер раздела и решить, большой он или нет. У нас есть специальные формулы для этого, но как правило, обычно их не нужно использовать. Можно приблизительно на уровне моделирования понять, какой будет размер.
Как правило, мы не хотим, чтобы в разделе было больше 100 000 строк или 100 МБ данных. Строки могут быть тоже разные. Допустим, в одной строке может быть 5 колонок, а в какой-то другой таблице может быть 100 колонок. То есть 100 000 строк где-то — это всего лишь 10 МБ. А где-то 100 000 строк — 1 ГБ. На это нужно обращать внимание.
Вернемся назад к логической модели и подумаем, сколько строк может быть в одном разделе в этой таблице? Допустим, если у нас есть сеть, и каждый час мы будем делать измерения или записывать средние измерения — то есть 24 раза в день. Но кроме того, это измерение мы будем записывать для каждого сенсора. Если у нас 1 000 сенсоров в нашей сети — в день 24 * 1 000 = 24 000 измерений только в один день. Если мы так и оставим эту таблицу, то через месяц у нас будет очень много строк, и это будет становиться проблемой. Поэтому мы добавили сюда неделю, и каждую неделю мы начинаем новый раздел. То есть мы разбили этот раздел на несколько. Это вторая оптимизация.
Третья оптимизация — дата и час. Мы можем их объединить вместе — нет смысла их хранить отдельно. Мы используем timestamp — упростили нашу модель данных немного.
Вопрос: что делать, если нужны запросы вида like и какой-то шаблон, регулярные выражения?
Есть у нас secondary indexes, которые их могут поддерживать, но опять же мы говорили, что secondary indexes не очень эффективны. Если нужно определенное количество таких запросов, и они имеют ограничения, то это можно сделать и в Cassandra путем моделирования. Допустим, хранить частично данные, первую, вторую букву. Конечно, есть другие индексы — solar indexes, можно индексировать колонки данных в Cassandra, которые поддерживают это.
Конечно, диаграмма — это хорошо. Давайте посмотрим, во что это все вылилось в виде CQL. Моделирование данных для сенсоров. Даже печатать ничего не нужно. Нажимаем, создаем KEYSPACE, создаем все эти таблицы. Их очень легко теперь понять, что с ними делать, потому что у нас есть эта диаграмма, где все типы данных, названия колонок, partition key, clustering key — все это мы решили на уровне логической и физической модели. Последний шаг — превратить все это в CQL или может быть даже, как в предыдущей презентации, использовать Stargate API для создания схемы — это все возможно.
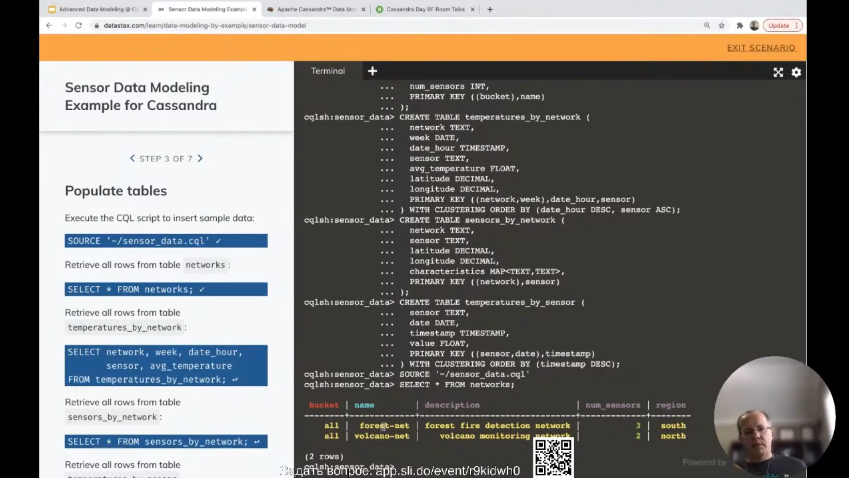
У нас есть 2 сети здесь: одна в лесу, другая наблюдает за вулканом. Это, конечно, игрушечные данные. Посмотрим для интереса первый запрос, как мы достаем обе сети из одной partition, т.е. bucket = all. Фактически это искусственная колонка, которую мы придумали, и она использует одно и то же значение, чтобы все наши сети были в одной partition.
Второй пример более сложный. У нас есть сеть forest-net, есть интервал данных, и он внутри одной недели. Запрос будет выглядеть так: network = forest-net, неделя равна тому-то. Дата или час меньше или равно такого-то значения. Сделали и достали эти данные. Очень быстро с одного раздела.
Вы можете спросить, а что же случится, если у нас период времени будет на несколько недель? Или часть одной недели и часть другой? Это будет 2 partition, 2 раздела. Решение здесь, как это сделать. Это либо 2 запроса: сначала к одной неделе, потом ко второй. Мы достали данные из двух разделов. Это можно объединить даже в один запрос, используя in, что мы не обсудили в начале. Используя in, мы указываем, что запрос будет на 2 недели. Довольно просто это сделать, хотя запрос казался вначале немного сложным.
Демо, которое я вам показал, есть онлайн, его можно посмотреть более подробно.
Инвестиционное Портфолио
Следующий пример — инвестиционное портфолио. Есть брокерская фирма, у нас там счет. Мы будем покупать и продавать акции.
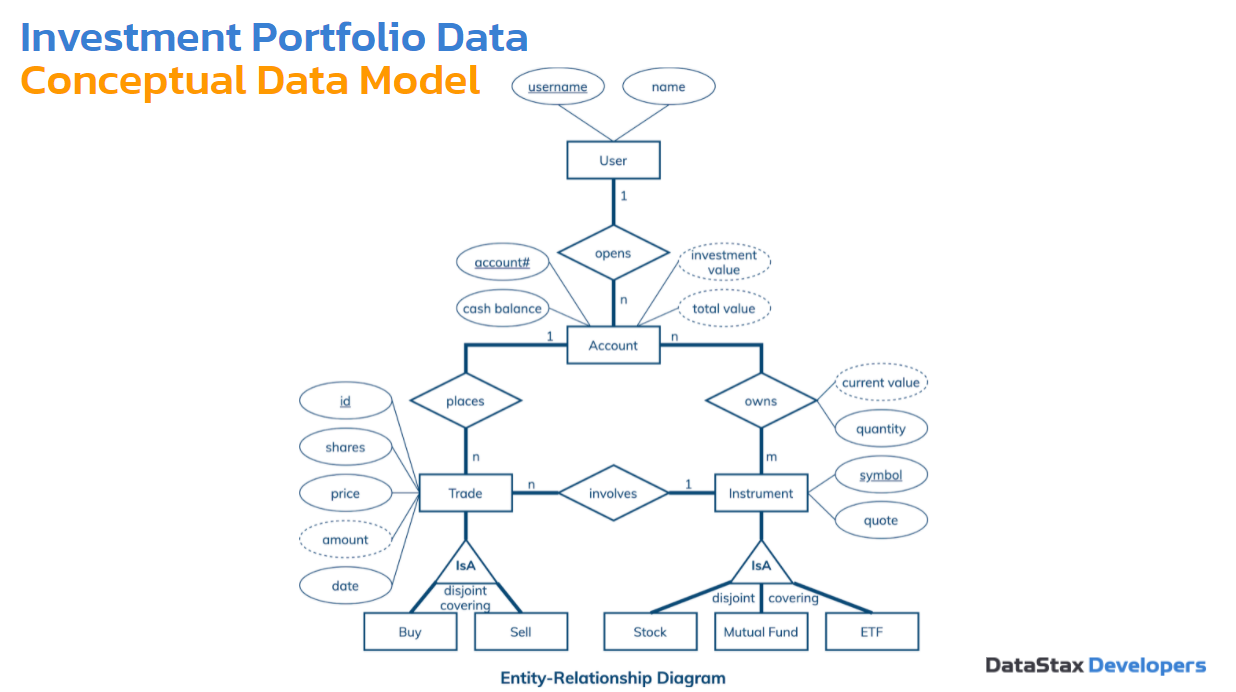
Концептуальная модель может показаться немного больше здесь, но опять же ее легко читать. Есть пользователи — они могут открывать счета. Один пользователь может открыть много счетов, один счет принадлежит одному пользователю. Может быть транзакция, есть два вида — «купить» или «продать». Это какой-то инструмент. Может быть акции, mutual funds (взаимные фонды), ETF (Exchange-traded fund). Это не столь важно. Допустим, акции.
Счет держит эти инструменты. Кроме обычных keys, username, номер счета, символ акции, у нас есть такие атрибуты — прерывающиеся линии. Их значения должны будут вычисляться динамически на основе других атрибутов. Например, стоимость инструмента и количество. Полный баланс на счету будет зависеть от того, сколько наличных на нем есть и сколько стоят инвестиции. Это не сильно меняет нам что-то, кроме того, что нам нужно решить: будем ли мы эти атрибуты хранить в базе данных, или мы их будем вычислять в приложении динамически. Довольно удобно посмотреть на это и сразу понять, нужно нам об этом вообще беспокоиться или нет.
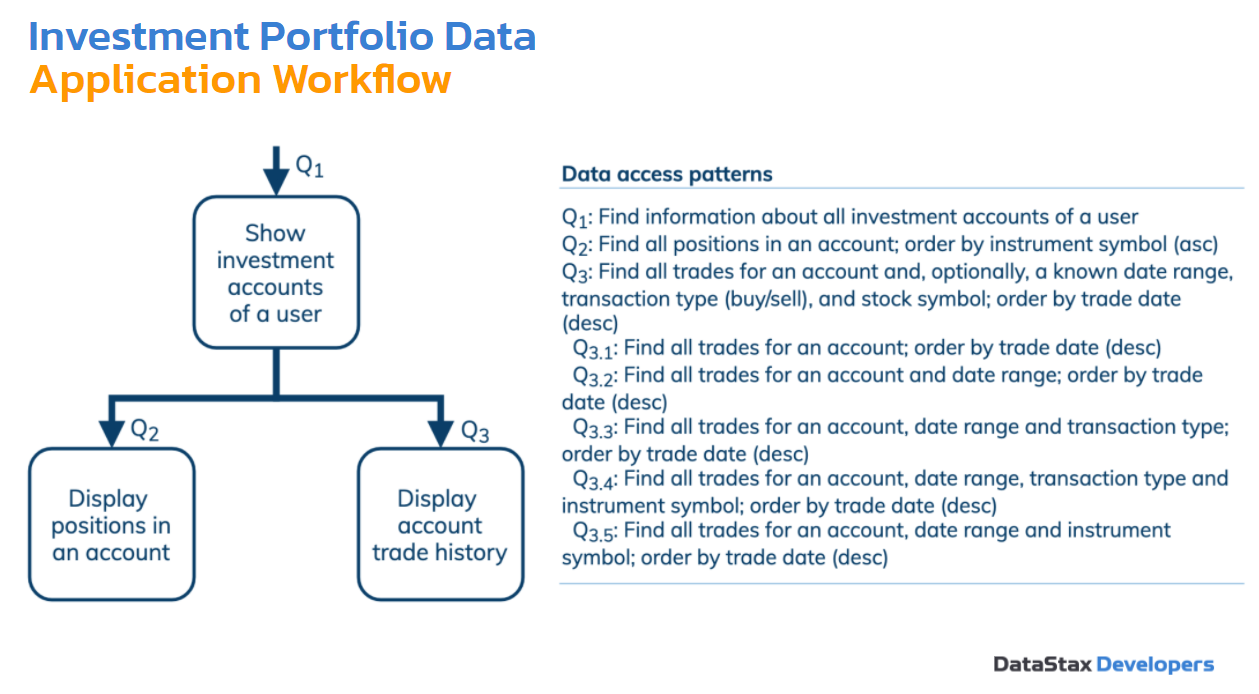
Очень простой Workflow здесь — всего 3 запроса. Мы хотим увидеть все счета пользователя. Мы хотим увидеть, какие позиции на счету, акции. В третьем случае мы хотим исследовать запросы по истории транзакции — покупки и продажи. В один день мы купили столько акций, в другой день их продали. Мы это хотим узнать. И третий запрос подразделяется на 5 запросов. Возможно, нам понадобятся 5 таблиц, посмотрим. Нам нужно доставать наши транзакции для счета, сортировать по датам. Второй подзапрос — использовать период времени. Третий подзапрос — интересует тип транзакции: покупка или продажа. Четвертый запрос — инструмент + тип транзакции + период времени + счет. И пятый — счет + период времени + инструмент. Все время мы сортируем по датам.
Как это будет выглядеть, когда мы организуем это все в таблице?
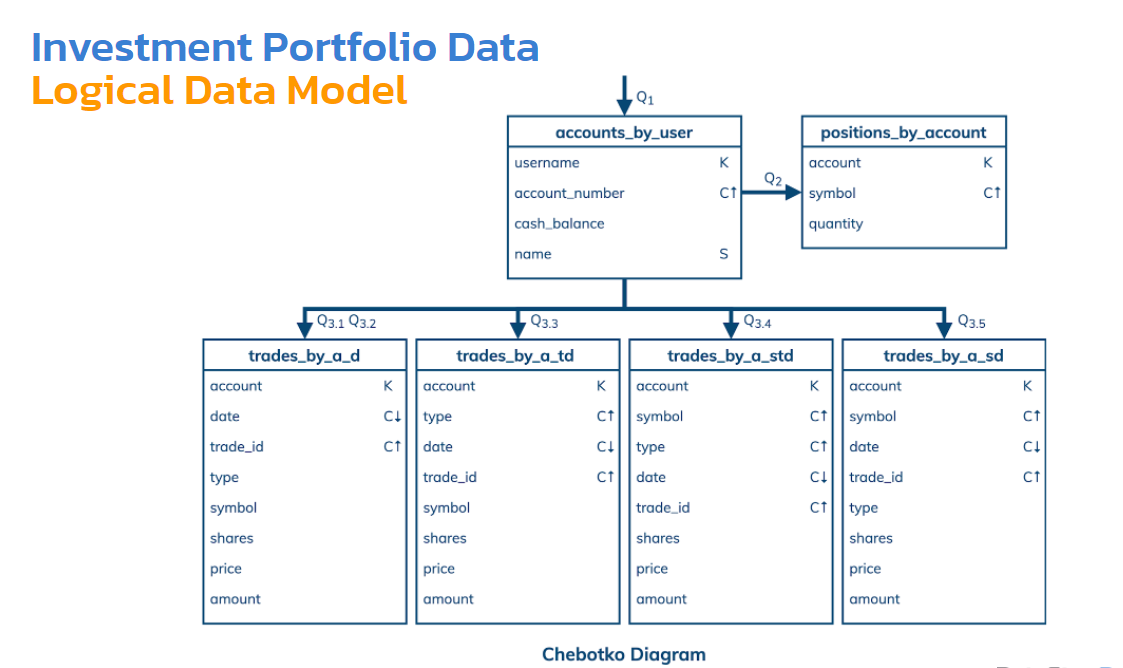
Мы обошлись только 4 таблицами для 3-го запроса. Одна из таблиц может отвечать и на 3.1 и на 3.2. Даже глядя на эту таблицу, я могу сказать, что я могу запросы создавать либо на основе счета, либо на основе счета и даты. Trade_id — это id этой транзакции. Здесь нужно лишь для того, чтобы гарантировать: каждая строка имеет уникальный ключ. Каждая строка в этой partition — это на самом деле транзакция, и она должна идентифицироваться с помощью trade_id.
Вот такая диаграмма, которая фактически описывает нашу схему. Какие оптимизации здесь могут быть? Как минимум десяток. Наиболее важные из них — чтобы у нас не было больших разделов. Есть всегда смысл быстро решить — может или не может быть большой раздел. Это обычный анализ, который нам нужно смотреть.
Допустим, для таблицы trades_by_a_d сколько здесь может быть строк в одном разделе? То есть для одного счета сколько может быть строк? Дата там нужна для сортировки, а каждая строка — это отдельная транзакция. Все зависит от того, какие в реальном приложении у нас есть требования. Если мы подразумеваем, что этот счет принадлежит человеку, он вряд ли может сделать более 100 000 транзакций даже за всю жизнь — это очень много. Но если этот счет принадлежит автоматизированному алгоритму — у робота каждую секунду может пройти несколько транзакций— нам нужно уже беспокоиться. В данном случае мы считаем, что здесь у нас человек, а не робот, который вряд ли сможет сделать более 100 000 транзакций.
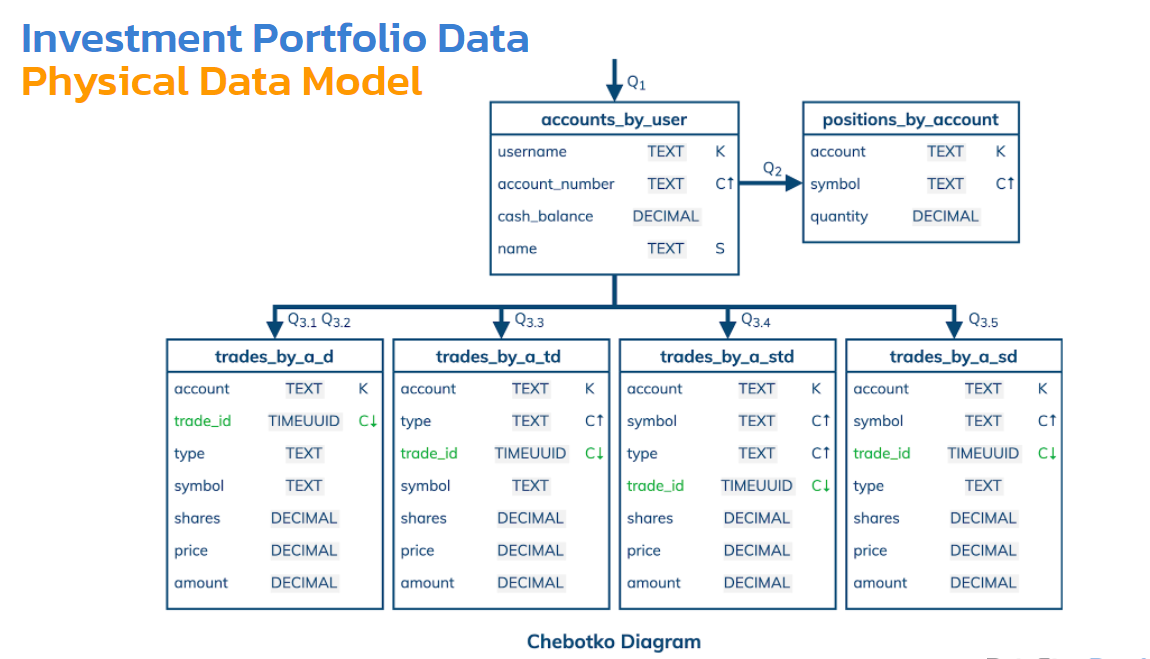
Единственная оптимизация, которую мы здесь использовали — мы опять взяли дату и trade_id и вместе их соединили. Trade_id — это тип данных TIMEUUID. Это фактически один из видов UUID — это универсальный идентификатор. Он генерируется с помощью timestamp, то есть временной метки. Ее можно очень просто достать, сейчас посмотрим.
Быстро создаем таблички, загружаем какие-то данные. Третий запрос более интересен.
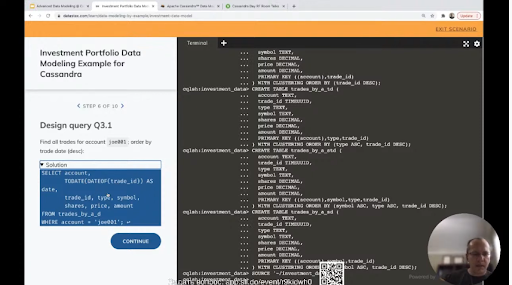
Как мы достаем дату? Сортировка по данным будет простая, но как мы дату достанем из TIMEUUID? Мы превращаем TIMEUUID в timestamp и превращаем в дату.
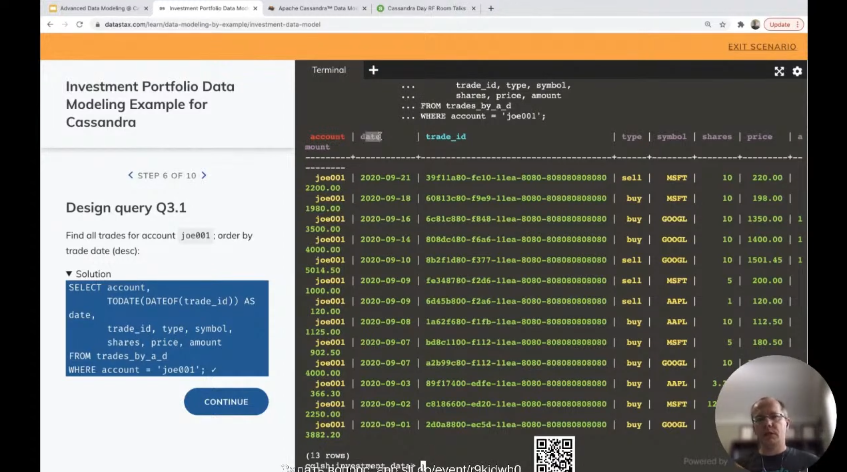
Видите, здесь дата, которая выглядит как обычная дата, хотя у нас нет такой колонки. Мы ее создали динамически и достали эту дату из TIMEUUID — этого непонятного значения, которое нам особо ни о чем не говорит.
Если у нас есть интервал данных, опять же интервал дат — дата у нас в TIMEUUID, она не отдельно хранится. Здесь есть trade_id > maxTIMEUUID — специальная функция, которая нам позволяет задать запрос, неравенство. И идет сравнение на уровне дат, на уровне timestamp. Сортировка на этих самых timestamp и дат. Данные отсортированы.
Вопрос: при денормализации данных растет риск нарушения консистентности данных в результате ошибки разработчика. Есть средства автоматизации проверки работы с моделью?
Ответ: Почему вообще нормализация используется? Есть аномалии — когда нам нужен update или insert данных в несколько мест. И мы забываем об этом, и у нас получается ошибка. То же самое здесь: trades — у нас 4 разных таблицы, которые хранят одни и те же транзакции, но хранят их по-разному. Чтобы мы могли их доставать запросами тоже по-разному. Как эта проблема решается? Есть baches, которые гарантируют атомарность. Но baches нужно использовать, как правило, если все запросы внутри baches, все мутации будут относиться к одной partition, к одной таблице. Тогда это будет суперэффективно.
Но если они начинают делать доступ к нескольким partition и к нескольким таблицам, тогда это становится менее эффективно. И проще делать insert в каждую таблицу отдельно в application и retry, если что-то случилось. В очень редких случаях может что-то случиться — весь дата-центр упал, и нам придется какие-то меры принимать, чтобы консистентность данных восстановить. Для этого используется Spark или другие приложения, которые могут считать данные с одного и проверить, что они существуют в другом. Фактически это join в Spark, один из таких вариантов.
