Apache Kafka широко используется в самых разных сферах автопрома. В этой статье мы рассмотрим реальные примеры развёртывания в разных контекстах, включая подключенные транспортные средства, умное производство и инновационные услуги перевозок, и в разных компаниях, включая автопроизводителей, вроде Audi, BMW, Porsche и Tesla, и провайдеров сервисов мобильности — Uber, Lyft и Here Technologies.

BMW — умные цеха и Индустрия 4.0
На Kafka Summit 2021 Феликс Бём (Felix Böhm), ответственный за цифровизацию заводов и облачную трансформацию в BMW, рассказал, как они применяют данные в движении при производстве. Здесь приводятся основные моменты его выступления. Если интересно, посмотрите интервью целиком на Youtube.
Разделение данных IoT и производства
У BMW есть критичные рабочие нагрузки на границе сети (на заводах) и в публичном облаке. Kafka обеспечивает разделение, прозрачность и инновации, а Confluent добавляет стабильности с помощью своих продуктов и опыта. Без стабильности на производстве не обойтись – каждая минута простоя обходится в целое состояние. Прочтите статью Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real-Time Data Lake, чтобы узнать, как Kafka повышает коэффициент общей эффективности оборудования (OEE) на производстве.
Логистика и цепочка поставок на заводах по всему миру
Это пример того, как можно оптимизировать управление цепочкой поставок в реальном времени.
Решение предоставляет информацию о запасах, как физически, так и в системах ERP, вроде SAP. Just-in-Time и Just-in-Sequence — это ключевые принципы для многих критичных применений.
Преимущества решения для BMW:
Данные IoT не смешиваются с остальными данными и доставляются в нужное место.
Данные собираются один раз, обрабатываются, а затем используются многократно (разными консьюмерами, в разное время и разными способами — в реальном времени, пакетами, по запросу).
Легко масштабируемая обработка данных в реальном времени позволяет сократить время вывода новых продуктов на рынок.
Настоящее разделение между разными интерфейсами — это уникальное преимущество Kafka по сравнению с другими платформами для обмена сообщениями, такими как IBM MQ, Rabbit MQ или MQTT-брокерами. Если интересно, можно почитать об этом в статье о предметно-ориентированном программировании с Kafka.
BMW — машинное обучение и обработка естественного языка (NLP)
Ещё один потрясающий проект, не связанный с предыдущим, — BMW создали платформу сервисов NLP промышленного класса на базе Kafka. В основе решения лежит экосистема Kafka как уровень оркестрации и обработки в различных сервисах NLP:

Приложения Kafka Streams отвечают за предварительную обработку, чтобы можно было консолидировать и обогащать входящие текстовые и речевые наборы данных. Различные платформы и технологии машинного обучения и глубокого обучения потребляют события для обработки языка, например, для преобразования речи в текст.
Это похоже на то, что делают другие компании. Универсального решения по машинному обучению не существует. Для разных вариантов применения, даже в рамках NLP, нужны разные технологии. Модель нужно не только обучить, но и развернуть, а затем отслеживать. Python решает не все задачи в сфере Data Science. В статье Apache Kafka + ksqlDB + TensorFlow for Data Scientists via Python + Jupyter Notebook я рассуждаю о том, как решить проблему impedance mismatch между дата-сайентистами и разработчиками.
BMW использует платформу NLP для разных нужд, в том числе для анализа цифровых контрактов, разработки подходящих инструментов для работы, машинного перевода и автоматизации техподдержки.

См. выступление представителей BMW на Kafka Summit об использовании Kafka с глубоким обучением и NLP.
Audi — подключенные автомобили
Audi создают инфраструктуру для подключённых автомобилей с помощью Apache Kafka. См. их выступление на Kafka Summit:
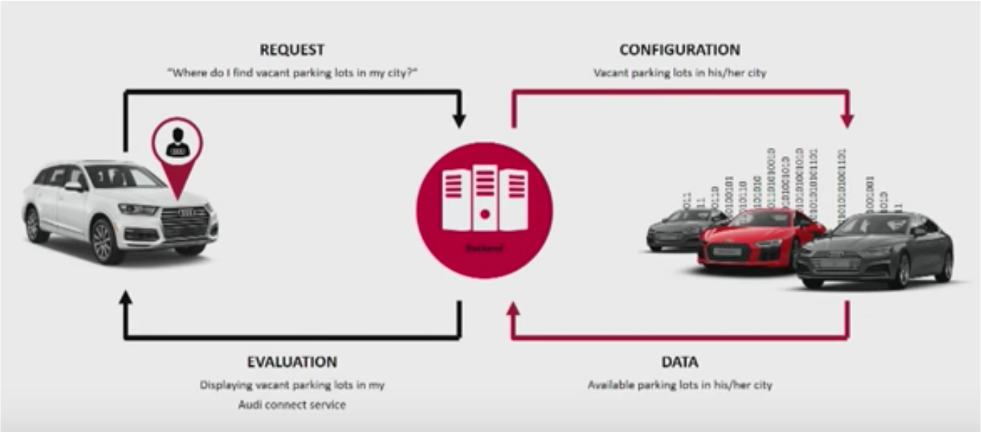
Варианты применения: анализ данных в реальном времени, роевой интеллект, совместная работа с партнерами и прогнозирующий ИИ.
Это идеальный пример модных «цифровых двойников»: все данные с сенсоров на подключённых автомобилях обрабатываются в реальном времени и сохраняются для последующего анализа и отчетности. Узнайте больше о Kafka для архитектуры цифровых двойников.
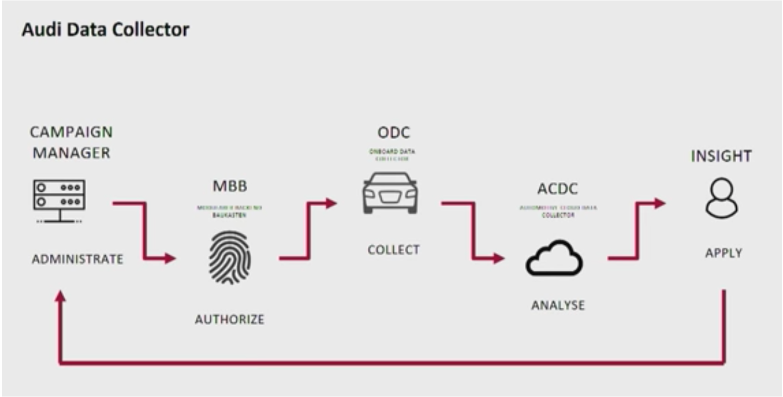
Архитектура с кластерами Kafka называется Audi Data Collector:
Tesla — подключено всё — промышленный IoT, автомобили, энергетика
Tesla делает не только машины, но и инновационный софт. Они создают энергетическую инфраструктуру для автомобилей, строя станции Telsa Supercharger, производя солнечную энергию на гигафабриках и так далее. Они обрабатывают и анализируют данные с автомобилей, из умных электросетей и заводов и интегрируют их с остальными бэкенд-сервисами в реальном времени.
Tesla создали инфраструктуру платформы данных на основе Kafka для обработки триллионов значений с миллионов устройств в день. Tesla рассказали об истории и эволюции своего применения Kafka на Kafka Summit в 2019 году:
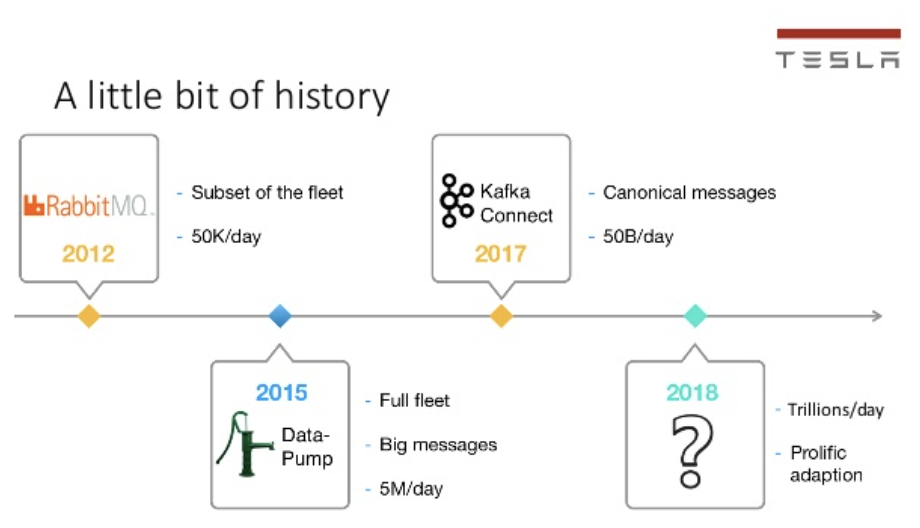
Почему Tesla использует Kafka?
Telsa используют Kafka, потому что она удовлетворяет их требованиям (цитата с выступления на Kafka Summit):
«Просто работает».
Гибкое использование пакетов.
Один поток, одно приложение.
Разные уровни свободы при масштабировании.
Это ещё одно доказательство того, что Kafka — испытанное и надёжное решение для объёмных рабочих нагрузок IoT, которое подходит для разных отраслей и разных вариантов применения.
Porsche — анализ клиентов и персонализированное обслуживание
My Porsche — это инновационная и современная омниканальная цифровая платформа от Porsche для повышения лояльности клиентов. Вот что говорят в Porsche:
«Клиенты хотят по-новому взаимодействовать с автопроизводителями, у них очень изменились желания и потребности. Сегодня они хотят использовать различные цифровые каналы и ожидают бесшовного взаимодействия с брендом онлайн и офлайн».
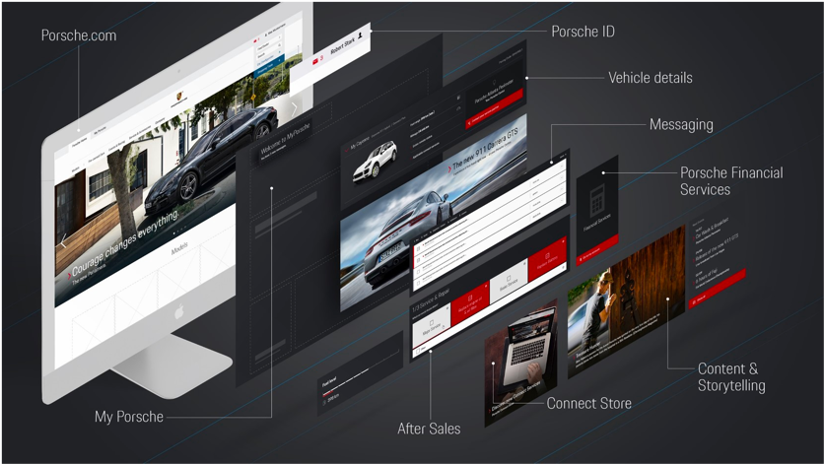
Разработчики из Porsche Dev опубликовали несколько крайне интересных статей о своей архитектуре. Вот хорошая схема:

Kafka обеспечивает реальное разделение приложений, а потому де факто становится стандартом для микросервисов и предметно-ориентированного программирования. С её помощью можно создавать независимые, слабо связанные, хорошо масштабируемые, высокодоступные и надёжные приложения.
Вот как в Porsche описывают применение компанией Apache Kafka в цепочке поставок:
«Тренд на потоковую передачу данных открывает новые возможности для аналитики в реальном времени. В Porsche технологии потоковой передачи данных всё чаще применяются в самых разных контекстах, например, для гарантийного обслуживания и продаж, в производстве и цепочке поставок, в подключённых автомобилях и на станциях зарядки» — рассказывает Сридар Мамелла (Sridhar Mamella) (директор по потоковой передаче данных Porsche).
Как видно на схеме архитектуры выше, не нужно спорить, что лучше — REST / HTTP или потоковая обработка событий/Kafka. Я уже писал о том, что для большинства архитектур микросервисов требуется Apache Kafka и API Management для REST. HTTP и Kafka прекрасно дополняют друг друга.
Porsche — централизованная платформа в основе data-driven компании
Porsche разработали стратегию централизованной платформы в ЦОД, облаках и регионах (очень крутая штука под названием Streamzilla), чтобы стать data-driven компанией. В выступлении на Kafka Summit они подробно рассказывают об этой платформе:

Например, у них есть интересное решение на базе Apache Kafka для OTA-обновлений для послепродажного обслуживания и других сценариев:

Очень советую послушать подкаст, в котором ребята из Porsche рассказывают, как создали Streamzilla для быстрой передачи данных.
DriveCentric — CRM для автодилеров
Не только автопроизводители любят Apache Kafka. Поставщики и сторонние разработчики тоже используют её для создания инноваций. Один из примеров — DriveCentric, масштабируемая CRM в реальном времени для автодилеров.
Это решение для комплексного клиентского опыта и взаимодействия по всем каналам. Некоторые преимущества: вовлечённость увеличивается, циклы продаж сокращаются, бизнес растёт. Это, кстати, ещё одно доказательство того, что Kafka стала стандартом для разделённых микросервисов и омниканального взаимодействия.
DriveCentric хотели сосредоточиться на бизнесе, а не на инфраструктуре, поэтому начали с Confluent Cloud — (единственного) по-настоящему бессерверного предложения для Kafka. Если вы ещё не понимаете разницу между частично управляемой и полностью управляемой Kafka, почитайте обсуждение бессерверных предложений Kafka на облачном рынкеили общее сравнение вендоров Kafka.
Uber / Lyft / Otonomo / Here Technologies — инновационные сервисы мобильности
И без того огромный рынок сервисов мобильности растёт с невероятной скоростью. Здесь происходит больше всего инноваций, связанных с улучшением клиентского опыта. Об этом можно написать отдельную статью, но мы ограничимся несколькими примерами:
Uber использует Kafka для триллионов сообщений и нескольких петабайт данных в день, чтобы создавать транспортную инфраструктуру в реальном времени по всему миру.
Lyft тоже использует Kafka везде, например, для потоковой аналитики, чтобы реализовывать сопоставление с картой, а также рассчитывать предполагаемое время прибытия и стоимость в реальном времени.
Компания Here Technologies, принадлежащая консорциуму немецких автопроизводителей (Audi, BMW, Daimler) и Intel, собирает данные геолокации, например, о дорогах, зданиях, парках и схемах дорожного движения. Их открытый API предоставляет нативный интерфейс Kafka вместо немасштабируемого REST/HTTP. Поэтому потоковая передача с API Management для Kafka становится всё более актуальной.
Otonomo — это открытая платформа API для данных с автомобилей, которая ускоряет вывод новых сервисов на рынок. Kafka входит в их центральную инфраструктуру и отвечает за интеграцию и обработку больших объёмов данных с автомобилей.
FREE NOW (ранее — mytaxi) — это совместное предприятие BMW и Daimler Mobility и провайдер MaaS (мобильность как услуга). Что-то вроде европейской версии Uber.
FREE NOW — потоковая аналитика в реальном времени в облаке
Сценарий FREE NOW очень похож на другие приложения заказа такси: требуется корреляция огромных объёмов данных из разных источников в реальном времени, без перерывов. Идеальный вариант для экосистемы Kafka. В примере ниже показано, как они используют потоковую обработку для расчёта стоимости поездки в зависимости от спроса на месте в реальном времени:
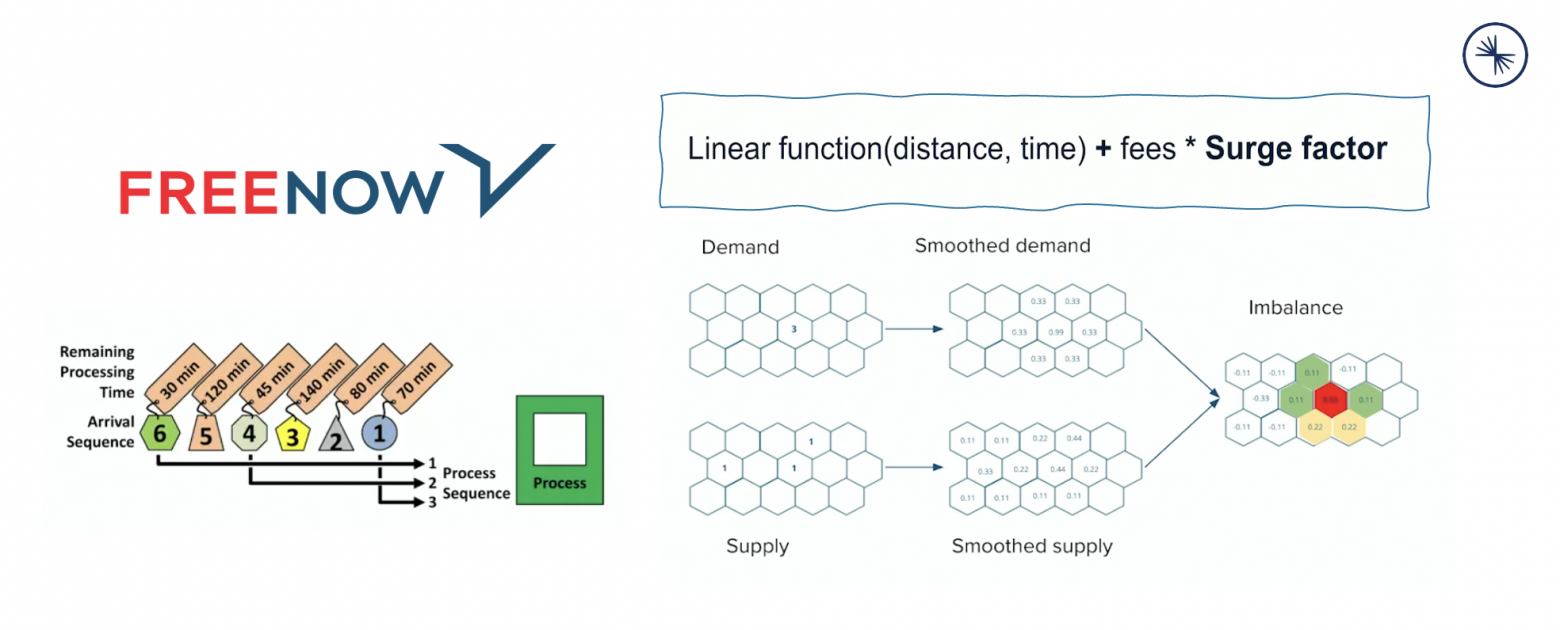
Интересные выдержки из выступления FREE NOW на Kafka Summit:
Stateful потоковая обработка с помощью Confluent Cloud, Kafka Connect, Kafka Streams, Schema Registry.
Эластичность и масштабируемость нативных облачных приложений с использованием возможностей Kafka и Kubernetes.
Динамическое ценообразование, выявление мошенничества, аналитика в реальном времени для маркетинговых кампаний и т. д.
Информация о поездке, расположении и эффективности бизнеса.
Для каких сценариев Kafka не подходит
Многочисленные реальные примеры доказывают, как хорошо Kafka и её экосистема подходят для автопрома. А в каких сценариях Kafka не вариант?
ИТ-системы автомобиля жёсткого реального времени и критичные для безопасности. В Kafka бывают пики задержки и используется недетерминированная сеть (как в большинстве ИТ-фреймворков). Kafka работает в мягком реальном времени, с задержкой более 10 мс. Этого достаточно для большинства вариантов использования, если речь не идёт о критичности для безопасности. Apache Kafka не работает в жёстком реальном времени, но используется повсюду в автопроме и промышленном IoT.
Интеграция на «последней миле». Kafka интегрируется с ОТ-средой (станки, ПЛК, сенсоры и т. д.). Фреймворки, вроде PLC4X, предлагают коннектор Kafka Connect. Некоторые клиенты используют Eclipse Kura для интеграции с IoT. Confluent REST Proxy и другие шлюзы могут подключаться к умным устройствам и мобильным приложениям. При этом в большинстве случаев интеграция на «последней миле» реализуется с помощью специальных платформ IoT или HTTP-прокси. Сама по себе Kafka не может подключаться к сотням тысяч устройств и не поддерживает низкоуровневые проприетарные legacy-протоколы. Кроме того, Kafka не очень хорошо работает в ненадёжных сетях. Я писал об этом несколько статей, в том числе об интеграции PLC4X, интеграции MQTT, архивации данных с помощью Kafka и т. д.
Видео с презентацией: Apache Kafka in the Automotive Industry.
Мода на данные в движении в автопроме
Apache Kafka стала центральной нервной системой многих приложений в разных сферах автопрома. Мы рассмотрели реальные примеры развёртывания в разных контекстах, включая подключенные автомобили, умное производство и инновационные сервисы мобильности, и в разных компаниях, включая автопроизводителей вроде Audi, BMW, Porsche и Tesla, и провайдеров MaaS — Uber, Lyft и Here Technologies.
Изучение Kafka со Слёрмом
— Курс «Apache Kafka База»: познакомимся с технологией, научимся настраивать распределённый отказоустойчивый кластер, отслеживать метрики, равномерно распределять нагрузку.
— Интенсив «Apache Kafka для разработчиков». Это углублённый интенсив с практикой на Java или Golang и платформой Spring+Docker+Postgres. Интенсив даёт понимание, как организовать работу микросервисов и повысить общую надежность системы. Сейчас записи интенсива доступны со скидкой в 45%.
— Есть бесплатные видеоуроки.
