Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.

Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet's Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
Далее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:
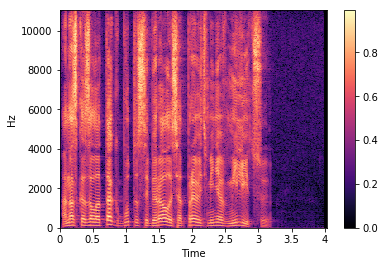
Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
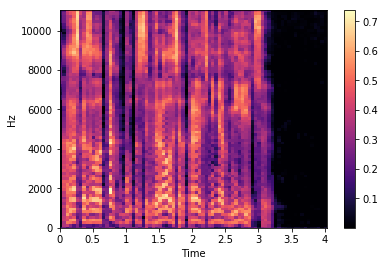
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
А сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Оригинал:
Восстановленный сигнал:
На мой вкус, результат стал хуже. Авторы Tacotron (первая версия также использует этот алгоритм) отмечали, что использовали алгоритм Гриффина-Лима как временное решение для демонстрации возможностей архитектуры. WaveNet и ему подобные архитектуры позволяют синтезировать речь лучшего качества. Но они более тяжеловесные и требуют определенных усилий для обучения.
DCTTS, который мы выбрали, состоит из двух практически независимых нейронных сетей: Text2Mel и Spectrogram Super-resolution Network (SSRN).
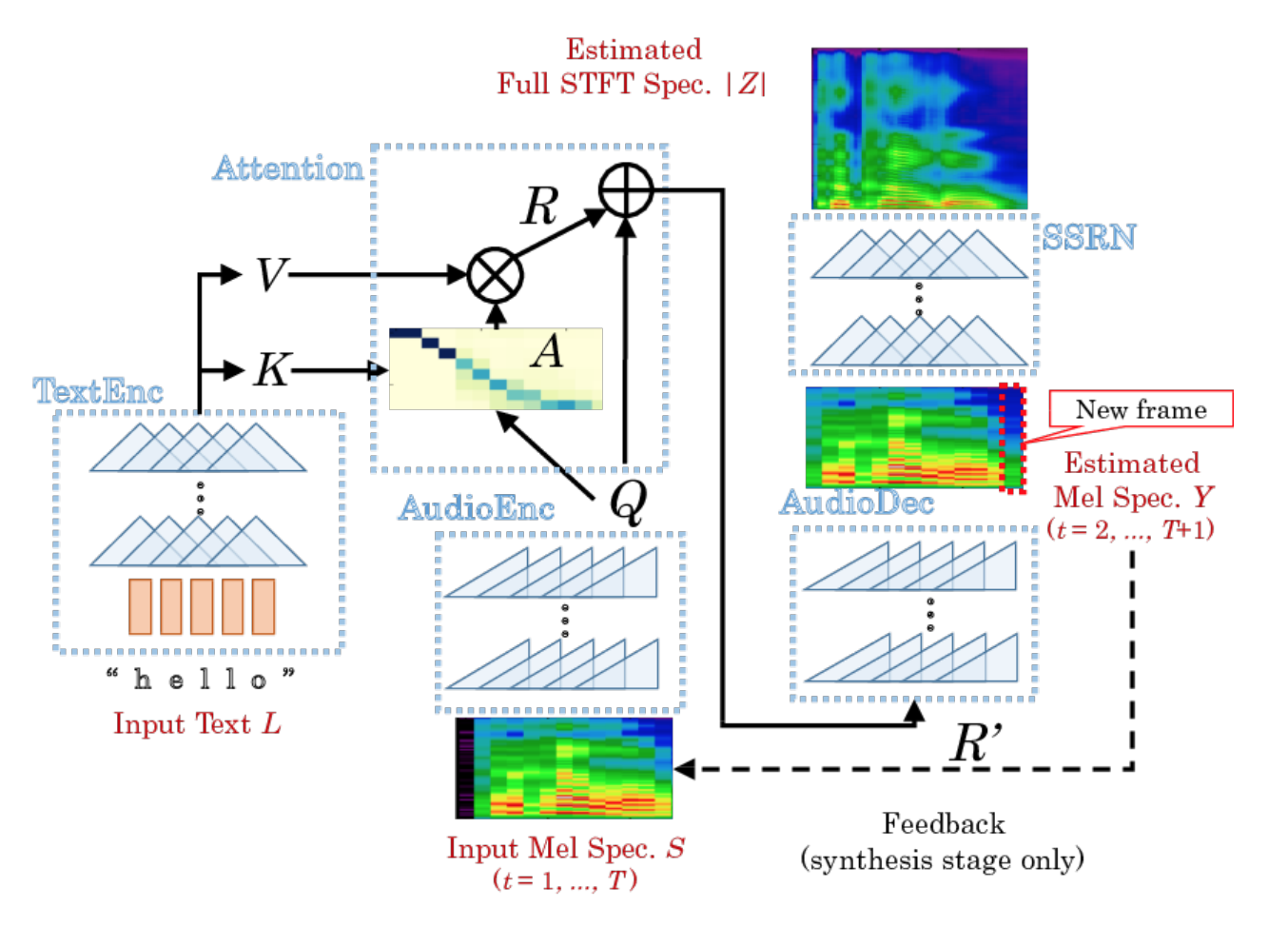
Text2Mel предсказывает мел-спектр по тексту, используя механизм внимания (Attention), который увязывает два энкодера (TextEnc, AudioEnc) и один декодер (AudioDec). Обратите внимание, что Text2Mel восстанавливает именно разреженный мел-спектр.
SSRN восстанавливает из мел-спектра полноценный амплитудный спектр, учитывая пропуски кадров и восстанавливая частоту дискретизации.
Последовательность вычислений довольно подробно описана в оригинальной статье. К тому же есть исходный код реализации, так что всегда можно отладиться и вникнуть в тонкости. Обратите внимание, что автор реализации отошел в некоторых местах от статьи. Я бы выделил два момента:
Я взял голос, включающий в себя 8 часов записей (несколько тысяч файлов). Оставил только записи, которые:
У меня получилось чуть больше 5 часов. Посчитал для всех записей нужные спекты и поочередно запустил обучение Text2Mel и SSRN. Все это делается довольно безхитростно:
Обратите внимание, что в оригинальном репозитории prepro.py именуется как prepo.py. Мой внутренний перфекционист не смог этого терпеть, так что я его переименовал.
DCTTS содержит только сверточные слои, и в отличие от RNN реализаций, вроде Tacotron, учится значительно быстрее.
На моей машине с Intel Core i5-4670, 16 Gb RAM и GeForce 1080 на борту 50 тыс. шагов для Text2Mel учится за 15 часов, а 75 тыс. шагов для SSRN — за 5 часов. Время требуемое на тысячу шагов в процессе обучения у меня почти не менялось, так что можно легко прикинуть, сколько потребуется времени на обучение с большим количеством шагов.
Размер батча можно регулировать параметром hp.B. Периодически процесс обучения у меня валился с out-of-memory, так что я просто делил на 2 размер батча и перезапускал обучение с нуля. Полагаю, что проблема кроется где-то в недрах TensorFlow (я использовал не самый свежий) и тонкостях реализации батчинга. Я с этим разбираться не стал, так как на значении 8 все падать перестало.
После того, как модели обучились, можно наконец запустить и синтез. Для этого заполняем файлик с фразами и запускаем:
Я немного поправил реализацию, чтобы генерировать фразы из нужного файла.
Результаты в виде WAV-файлов будут сохранены в директорию samples. Вот примеры синтеза системой, которая получилась у меня:
Результат превзошел мои личные ожидания по качеству. Система расставляет ударения, речь получается разборчивой, а голос узнаваем. В целом получилось неплохо для первой версии, особенно с учетом того, что для обучения использовалось всего 5 часов обучающих данных.
Остаются вопросы по управляемости таким синтезом. Пока невозможно даже исправить ударение в слове, если оно неверное. Мы жестко завязаны на максимальную длину фразы и размер мел-спектрограммы. Нет возможности управлять интонацией и скоростью воспроизведения.
Я не выкладывал мои изменения в коде оригинальной реализации. Они коснулись только загрузки обучающих данных и фраз для синтеза уже по готовой системе, а также значений гиперпараметров: алфавит (hp.vocab) и размер батча (hp.B). В остальном реализация осталась оригинальная.
В рамках рассказа я совсем не коснулся темы продакшн реализации таких систем, до этого полностью E2E-системам синтеза речи пока очень далеко. Я использовал GPU c CUDA, но даже в этом случае все работает медленнее реального времени. На CPU все работает просто неприлично медленно.
Все эти вопросы будут решаться в ближайшие годы крупными компаниями и научными сообществами. Уверен, что это будет очень интересно.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Синтез речи
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Лингвистика
- Нормализация текста. Для начала нам нужно развернуть все сокращения, числа и даты в текст. 50е годы XX века должно превратиться в пятидесятые годы двадцатого века, а г. Санкт-Петербург, Большой пр. П.С. в город Санкт-Петербург, Большой проспект Петроградской Стороны. Это должно происходить так естественно, как если бы человека попросили прочитать написанное.
- Подготовка словаря ударений. Расстановка ударений может производиться по правилам языка. В английском ударение часто ставится на первый слог, а в испанском — на предпоследний. При этом из этих правил существует целая масса исключений, не поддающихся какому-то общему правилу. Их обязательно нужно учитывать. Для русского языка в общем смысле правил расстановки ударения вообще не существует, так что без словаря с расставленными ударениями совсем никуда не деться.
- Снятие омографии. Омографы — это слова, которые совпадают в написании, но различаются в произношении. Носитель языка легко расставит ударения: дверной замок и замок на горе. А вот ключ от замка — задача посложнее. Полностью снять омографию без учета контекста невозможно.
Просодика
- Выделение синтагм и расстановка пауз. Синтагма представляет относительно законченный по смыслу отрезок речи. Когда человек говорит, он обычно вставляет паузы между фразами. Нам нужно научиться разделять текст на такие синтагмы.
- Определение типа интонации. Выражение завершенности, вопроса и восклицания — самые простые интонации. А вот выразить иронию, сомнение или воодушевление задача куда сложнее.
Фонетика
- Получение транскрипции. Так как в конечном итоге мы работаем с произнесением, а не с написанием, то очевидно вместо букв (графем), логично использовать звуки (фонемы). Преобразование графемной записи в фонемную — отдельная задача, состоящая из множества правил и исключений.
- Вычисление параметров интонации. В этот момент нужно решить как будет меняться высота основного тона и скорость произнесения в зависимости от расставленных пауз, подобранной последовательности фонем и типа выражаемой интонации. Помимо основного тона и скорости есть и другие параметры, с которыми можно долго экспериментировать.
Акустика
- Подбор звуковых элементов. Системы синтеза оперируют так называемыми аллофонами — реализациями фонемы, зависящими от окружения. Записи из обучающих данных нарезаются на кусочки по фонемной разметке, которые образуют аллофонную базу. Каждый аллофон характеризуется набором параметров, таких как контекст (фонемы соседи), высота основного тона, длительность и прочие. Сам процесс синтеза представляет собой подбор правильной последовательности аллофонов, наиболее подходящих в текущих условиях.
- Модификация и звуковые эффекты. Для получившихся записей иногда нужна постобработка, какие-то специальные фильтры, делающие синтезируемую речь чуть ближе к человеческой или исправляющие какие-то дефекты.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Реализации
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
- Tacotron (версии 1, 2).
- DeepVoice (версии 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet's Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Данные для обучения
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Начнем
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
from hyperparams import Hyperparams as hp
batch_size = hp.B # размер батча берем из гиперпараметровДалее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Текст
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
['a', 'b', 'c']В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
{
'a': [0, 1],
'b': [2, 3],
'c': [4, 5]
}Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
[[0, 1], [0, 1], [2, 3], [2, 3], [4, 5], [4, 5]]Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
# Алфавит задается в файле с гиперпараметрами
vocab = "E абвгдеёжзийклмнопрстуфхцчшщъыьэюя-" Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
- Я не добавлял в алфавит знаки препинания. С одной стороны, мы действительно их не произносим. С другой, по знакам препинания мы делим фразу на части (синтагмы), разделяя их паузами. Как система произнесет казнить нельзя помиловать?
- В алфавите нет цифр. Мы ожидаем, что они будут развернуты в числительные перед подачей на синтез, то есть нормализованы. Вообще все E2E-архитектуры, которые я видел, требуют именно нормализованный текст.
- В алфавите нет латинских символов. Английский система уметь произносить не будет. Можно попробовать транслитерацию и получить сильный русский акцент — пресловутый лет ми спик фром май харт.
- В алфавите есть буква ё. В данных, на который я обучал систему, она стояла там, где нужно, и я решил этот расклад не менять. Однако, в тот момент, когда я оценивал получившиеся результаты, выяснилось, что теперь перед подачей на синтез эту букву тоже нужно ставить правильно, иначе система произносит именно е, а не ё.
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Звук
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
# Получаем сигнал фиксированной частоты дискретизации
y, sr = librosa.load(wavename, sr=hp.sr)
# Обрезаем тишину по краям
y, _ = librosa.effects.trim(y)
# Pre-emphasis фильтр
y = np.append(y[0], y[1:] - hp.preemphasis * y[:-1])
# Оконное преобразование Фурье
linear = librosa.stft(y=y,
n_fft=hp.n_fft,
hop_length=hp.hop_length,
win_length=hp.win_length)
# Амплитудный спектр
mag = np.abs(linear)
# Мел-спектр
mel_basis = librosa.filters.mel(hp.sr, hp.n_fft, hp.n_mels)
mel = np.dot(mel_basis, mag)
# Переводим в децибелы
mel = 20 * np.log10(np.maximum(1e-5, mel))
mag = 20 * np.log10(np.maximum(1e-5, mag))
# Нормализуем
mel = np.clip((mel - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1)
mag = np.clip((mag - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1)
# Транспонируем и приводим к нужным типам
mel = mel.T.astype(np.float32)
mag = mag.T.astype(np.float32)
# Добиваем нулями до правильных размерностей
t = mel.shape[0]
num_paddings = hp.r - (t % hp.r) if t % hp.r != 0 else 0
mel = np.pad(mel, [[0, num_paddings], [0, 0]], mode="constant")
mag = np.pad(mag, [[0, num_paddings], [0, 0]], mode="constant")
# Понижаем частоту дискретизации для мел-спектра
mel = mel[::hp.r, :]
Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:
Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
def griffin_lim(spectrogram, n_iter=hp.n_iter):
x_best = copy.deepcopy(spectrogram)
for i in range(n_iter):
x_t = librosa.istft(x_best,
hp.hop_length,
win_length=hp.win_length,
window="hann")
est = librosa.stft(x_t,
hp.n_fft,
hp.hop_length,
win_length=hp.win_length)
phase = est / np.maximum(1e-8, np.abs(est))
x_best = spectrogram * phase
x_t = librosa.istft(x_best,
hp.hop_length,
win_length=hp.win_length,
window="hann")
y = np.real(x_t)
return yА сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
# Транспонируем
mag = mag.T
# Денормализуем
mag = (np.clip(mag, 0, 1) * hp.max_db) - hp.max_db + hp.ref_db
# Возвращаемся от децибел к аплитудам
mag = np.power(10.0, mag * 0.05)
# Восстанавливаем сигнал
wav = griffin_lim(mag**hp.power)
# De-pre-emphasis фильтр
wav = signal.lfilter([1], [1, -hp.preemphasis], wav)Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Оригинал:
Восстановленный сигнал:
На мой вкус, результат стал хуже. Авторы Tacotron (первая версия также использует этот алгоритм) отмечали, что использовали алгоритм Гриффина-Лима как временное решение для демонстрации возможностей архитектуры. WaveNet и ему подобные архитектуры позволяют синтезировать речь лучшего качества. Но они более тяжеловесные и требуют определенных усилий для обучения.
Обучение
DCTTS, который мы выбрали, состоит из двух практически независимых нейронных сетей: Text2Mel и Spectrogram Super-resolution Network (SSRN).
Text2Mel предсказывает мел-спектр по тексту, используя механизм внимания (Attention), который увязывает два энкодера (TextEnc, AudioEnc) и один декодер (AudioDec). Обратите внимание, что Text2Mel восстанавливает именно разреженный мел-спектр.
SSRN восстанавливает из мел-спектра полноценный амплитудный спектр, учитывая пропуски кадров и восстанавливая частоту дискретизации.
Последовательность вычислений довольно подробно описана в оригинальной статье. К тому же есть исходный код реализации, так что всегда можно отладиться и вникнуть в тонкости. Обратите внимание, что автор реализации отошел в некоторых местах от статьи. Я бы выделил два момента:
- Появились дополнительные слои для нормализации (normalization layers), без которых, по словам автора, ничего не работало.
- В реализации используется механизм исключения (dropout) для лучшей регуляризации. В статье этого нет.
Я взял голос, включающий в себя 8 часов записей (несколько тысяч файлов). Оставил только записи, которые:
- В текстовках содержат только буквы, пробелы и дефисы.
- Длина текстовок не превышает hp.max_N.
- Длина мел-спектров после разреживания не превышает hp.max_T.
У меня получилось чуть больше 5 часов. Посчитал для всех записей нужные спекты и поочередно запустил обучение Text2Mel и SSRN. Все это делается довольно безхитростно:
$ python prepro.py
$ python train.py 1
$ python train.py 2Обратите внимание, что в оригинальном репозитории prepro.py именуется как prepo.py. Мой внутренний перфекционист не смог этого терпеть, так что я его переименовал.
DCTTS содержит только сверточные слои, и в отличие от RNN реализаций, вроде Tacotron, учится значительно быстрее.
На моей машине с Intel Core i5-4670, 16 Gb RAM и GeForce 1080 на борту 50 тыс. шагов для Text2Mel учится за 15 часов, а 75 тыс. шагов для SSRN — за 5 часов. Время требуемое на тысячу шагов в процессе обучения у меня почти не менялось, так что можно легко прикинуть, сколько потребуется времени на обучение с большим количеством шагов.
Размер батча можно регулировать параметром hp.B. Периодически процесс обучения у меня валился с out-of-memory, так что я просто делил на 2 размер батча и перезапускал обучение с нуля. Полагаю, что проблема кроется где-то в недрах TensorFlow (я использовал не самый свежий) и тонкостях реализации батчинга. Я с этим разбираться не стал, так как на значении 8 все падать перестало.
Результат
После того, как модели обучились, можно наконец запустить и синтез. Для этого заполняем файлик с фразами и запускаем:
$ python synthesize.pyЯ немного поправил реализацию, чтобы генерировать фразы из нужного файла.
Результаты в виде WAV-файлов будут сохранены в директорию samples. Вот примеры синтеза системой, которая получилась у меня:
Выводы и ремарки
Результат превзошел мои личные ожидания по качеству. Система расставляет ударения, речь получается разборчивой, а голос узнаваем. В целом получилось неплохо для первой версии, особенно с учетом того, что для обучения использовалось всего 5 часов обучающих данных.
Остаются вопросы по управляемости таким синтезом. Пока невозможно даже исправить ударение в слове, если оно неверное. Мы жестко завязаны на максимальную длину фразы и размер мел-спектрограммы. Нет возможности управлять интонацией и скоростью воспроизведения.
Я не выкладывал мои изменения в коде оригинальной реализации. Они коснулись только загрузки обучающих данных и фраз для синтеза уже по готовой системе, а также значений гиперпараметров: алфавит (hp.vocab) и размер батча (hp.B). В остальном реализация осталась оригинальная.
В рамках рассказа я совсем не коснулся темы продакшн реализации таких систем, до этого полностью E2E-системам синтеза речи пока очень далеко. Я использовал GPU c CUDA, но даже в этом случае все работает медленнее реального времени. На CPU все работает просто неприлично медленно.
Все эти вопросы будут решаться в ближайшие годы крупными компаниями и научными сообществами. Уверен, что это будет очень интересно.
